Viele sind misstrauisch gegenüber der Aussicht, selbst etwas zu forken und zu schreiben. Oft ist der Preis zu hoch. Es ist besonders seltsam, von Ihren eigenen JDKs zu hören, die angeblich in jedem ziemlich großen Unternehmen vorhanden sind. Was zum Teufel tobt mit Fett? Dieser Artikel wird eine detaillierte Geschichte über das Unternehmen sein, die all dies echte wirtschaftliche Vorteile bringt und die schreckliche Arbeit geleistet hat, weil sie:
- Entwicklung einer mandantenfähigen virtuellen Java-Maschine;
- Sie entwickelten einen Mechanismus für den Betrieb von Objekten, die keinen Aufwand für die Speicherbereinigung verursachen.
- Sie haben so etwas wie das ReadyNow-Gegenstück von Azul Zing gemacht;
- Sie haben ihre eigenen Coroutinen mit Erträgen und Fortsetzungen abgewaschen (und sind sogar bereit, ihre Erfahrungen mit Loom zu teilen, über die ich im Herbst geschrieben habe );
- Sie haben an all diesen Wundern ihr eigenes Subsystem der Diagnose angeschraubt.
Wie immer warten Video, Volltextentschlüsselung und Folien unter dem Schnitt auf Sie. Willkommen in der Hölle eines der schwierigsten Bereiche der Anpassung offener Projekte!

Herr Doktor, woher bekommen Sie solche Bilder? O'Reilly Covers Corner: Der KDPV-Hintergrund wird von Joshua Newton zur Verfügung gestellt und zeigt den Sangyang Jaran Sacred Dance in Ubud, Indonesien. Dies ist eine klassische balinesische Aufführung, die aus Feuer- und Trance-Tanz besteht. Ein Mann mit nackten Absätzen bewegt sich um ein Lagerfeuer, gezüchtet auf Kokosnussschalen, schiebt Dinge mit den Füßen und tanzt in Trance unter dem Einfluss eines Pferdegeistes. Perfekte Illustration für Ihr eigenes JDK, oder?
Folien und eine Beschreibung des Berichts (Sie brauchen sie nicht, dieser Habratopike hat alles, was Sie brauchen).
Hallo, mein Name ist Sanhong Lee, ich arbeite bei Alibaba und ich möchte darüber sprechen, welche Änderungen wir an OpenJDK für die Anforderungen unseres Geschäfts vorgenommen haben. Die Post besteht aus drei Teilen. Im ersten werde ich darüber sprechen, wie Java in Alibaba verwendet wird. Der zweite Teil ist meiner Meinung nach der wichtigste - darin werden wir diskutieren, wie wir OpenJDK für die Anforderungen unseres Geschäfts konfigurieren. Der dritte Teil befasst sich mit den Werkzeugen, die wir für die Diagnose erstellt haben.
Bevor ich jedoch zum ersten Teil übergehe, möchte ich Ihnen kurz etwas über unser Unternehmen erzählen.
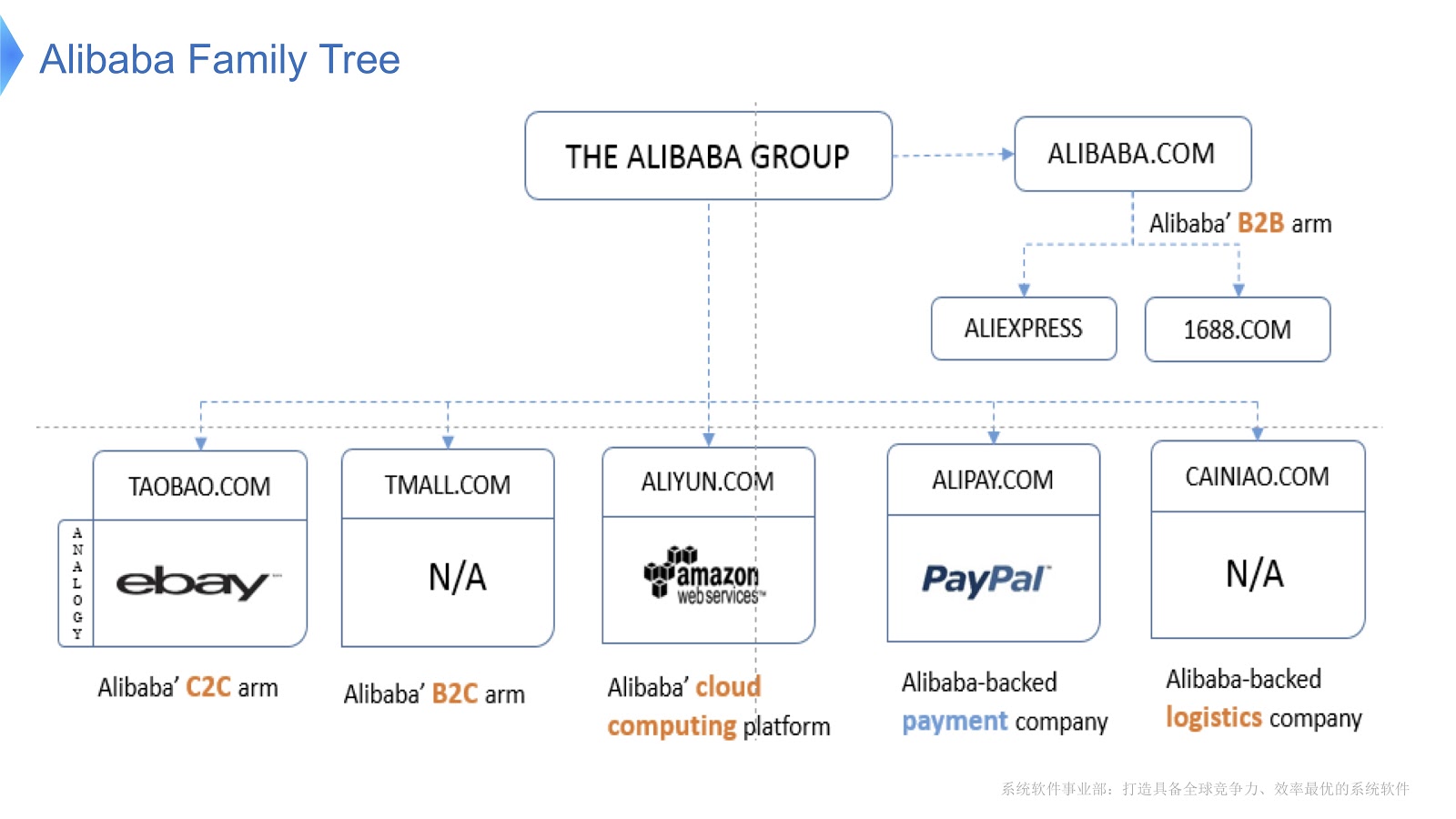
Das Diagramm zeigt die interne Struktur von Alibaba. Es besteht aus verschiedenen Unternehmen, deren Spezialisierung die Organisation des elektronischen Marktes und die Bereitstellung von Finanz- und Logistikplattformen ist. Ich denke, die meisten Menschen in Russland kennen AliExpress. Alibaba verfügt über ein engagiertes Team von Programmierern, die den gesamten verteilten Stack entwickeln und unterstützen und Aliexpress-Kunden auf der ganzen Welt Service bieten.
Um einen Eindruck vom Umfang von Alibabas Arbeit zu bekommen, schauen wir uns an, was am Singles Day in China passiert. Es wird jedes Jahr am 11. November gefeiert und an diesem Tag kaufen die Menschen besonders viele Waren über Alibaba. Soweit ich weiß, ist dies von den Feiertagen auf der ganzen Welt das am meisten einkaufen.
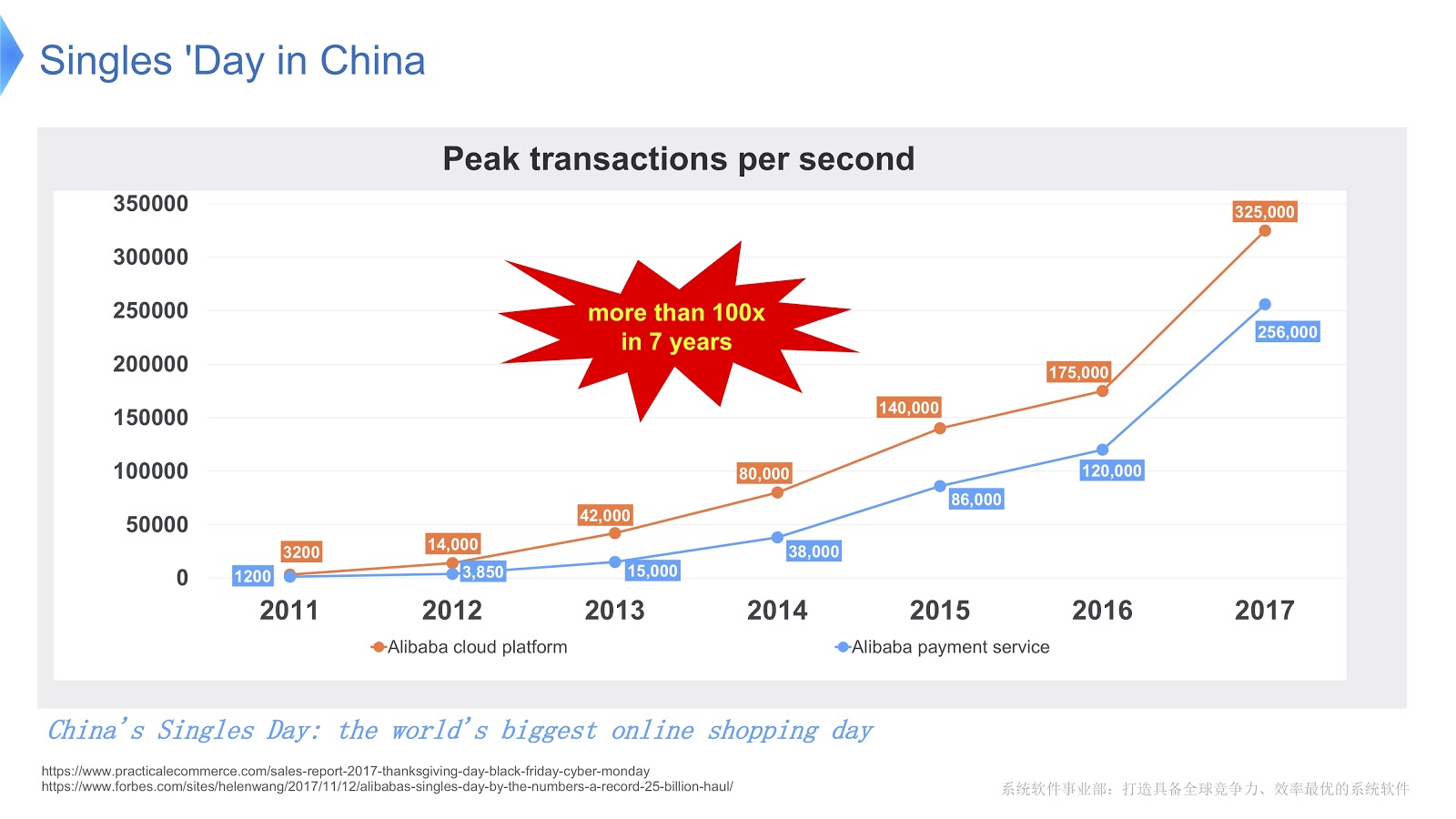
In der Abbildung oben sehen Sie ein Diagramm, das die Belastung unseres Support-Systems zeigt. Die rote Linie zeigt die Arbeit unseres Bestellservices und die maximale Anzahl von Transaktionen pro Sekunde, im letzten Jahr waren es 325.000. Die blaue Linie bezieht sich auf den Zahlungsdienst, und sie hat diese Zahl von 256 Tausend. Ich möchte darüber sprechen, wie der Stack für so viele Transaktionen optimiert werden kann.
Lassen Sie uns die wichtigsten Technologien diskutieren, die in Alibaba mit Java funktionieren. Zunächst muss ich sagen, dass wir eine Reihe von Open-Source-Anwendungen als Grundlage haben. Für die Big-Data-Verarbeitung verwenden wir HBase Hadoop. Als Container verwenden wir Tomcat und OSGi. Java wird in großem Umfang verwendet - Millionen von JVM-Instanzen werden in unserem Rechenzentrum bereitgestellt. Ich muss auch sagen, dass unsere Architektur serviceorientiert ist, dh wir erstellen viele Services, die über RPC-Aufrufe miteinander kommunizieren. Schließlich ist unsere Architektur heterogen. Um die Leistung zu verbessern, werden viele Algorithmen mit C- und C ++ - Bibliotheken geschrieben, sodass sie über JNI-Aufrufe mit Java kommunizieren.

Die Geschichte unserer Arbeit mit OpenJDK begann 2011 während OpenJDK 6. Es gibt drei wichtige Gründe, warum wir uns für OpenJDK entschieden haben. Erstens können wir den Code direkt entsprechend den Anforderungen des Unternehmens ändern. Zweitens, wenn dringende Probleme auftreten, können wir sie selbst schneller lösen, als auf die offizielle Veröffentlichung zu warten. Dies ist für unser Geschäft von entscheidender Bedeutung. Drittens verwenden unsere Java-Entwickler unsere eigenen Tools für schnelles und qualitativ hochwertiges Debuggen und Diagnostizieren.
Bevor ich zu technischen Fragen übergehe, möchte ich die Hauptschwierigkeiten auflisten, die wir überwinden müssen. Erstens haben wir eine große Anzahl von JVM-Instanzen gestartet. In dieser Situation ist die Frage der Reduzierung der Hardwarekosten ein akutes Problem. Zweitens habe ich bereits gesagt, dass wir eine große Anzahl von Transaktionen abwickeln. Dank des Garbage Collectors verspricht Java uns „unendlichen Speicher“. Darüber hinaus gewinnt es dank des JIT-Compilers an Leistung auf niedrigem Niveau. Dies hat aber auch eine Kehrseite: eine längere Zeit für die Müllabfuhr. Darüber hinaus benötigt Java zusätzliche CPU-Zyklen, um Java-Methoden zu kompilieren. Dies bedeutet, dass Compiler um CPU-Zyklen konkurrieren. Beide Probleme verschlechtern sich, wenn die Anwendung komplexer wird.
Die dritte Schwierigkeit besteht darin, dass viele Anwendungen ausgeführt werden. Ich denke, jeder hier ist mit Tools vertraut, die mit OpenJDK geliefert werden, wie JConsole oder VisualVM. Das Problem ist, dass sie uns nicht die genauen Informationen geben, die wir zum Konfigurieren benötigen. Wenn wir diese Tools (z. B. JConsole oder VisualVM) in der Produktion verwenden, ist ein geringer Overhead nicht nur ein Wunsch, sondern eine notwendige Anforderung. Ich musste meine eigenen Diagnosetools schreiben.

Das Bild zeigt die Änderungen, die wir an OpenJDK vorgenommen haben. Schauen wir uns an, wie wir die Schwierigkeiten überwunden haben, über die ich oben gesprochen habe.
Multi-Tenant JVM
Eine Lösung nennen wir eine mandantenfähige JVM. Sie können damit sicher mehrere Webanwendungen in einem Container ausführen. Eine andere Lösung heißt GCIH (GC Invisible Heap). Dies ist ein Mechanismus, mit dem Sie vollwertige Java-Objekte erhalten, für die gleichzeitig keine Kosten für die Speicherbereinigung anfallen. Um die Kosten für Thread-Kontexte zu senken, haben wir außerdem Coroutinen auf unserer Java-Plattform implementiert. Außerdem haben wir einen Mechanismus namens JWarmup geschrieben, dessen Funktion ReadyNow sehr ähnlich ist. Douglas Hawkins scheint ihn in seinem Bericht erwähnt zu haben. Schließlich haben wir unser eigenes Profiling-Tool, ZProfiler, entwickelt.
Schauen wir uns genauer an, wie wir OpenJDK-basierte Mandantenfähigkeit implementieren.
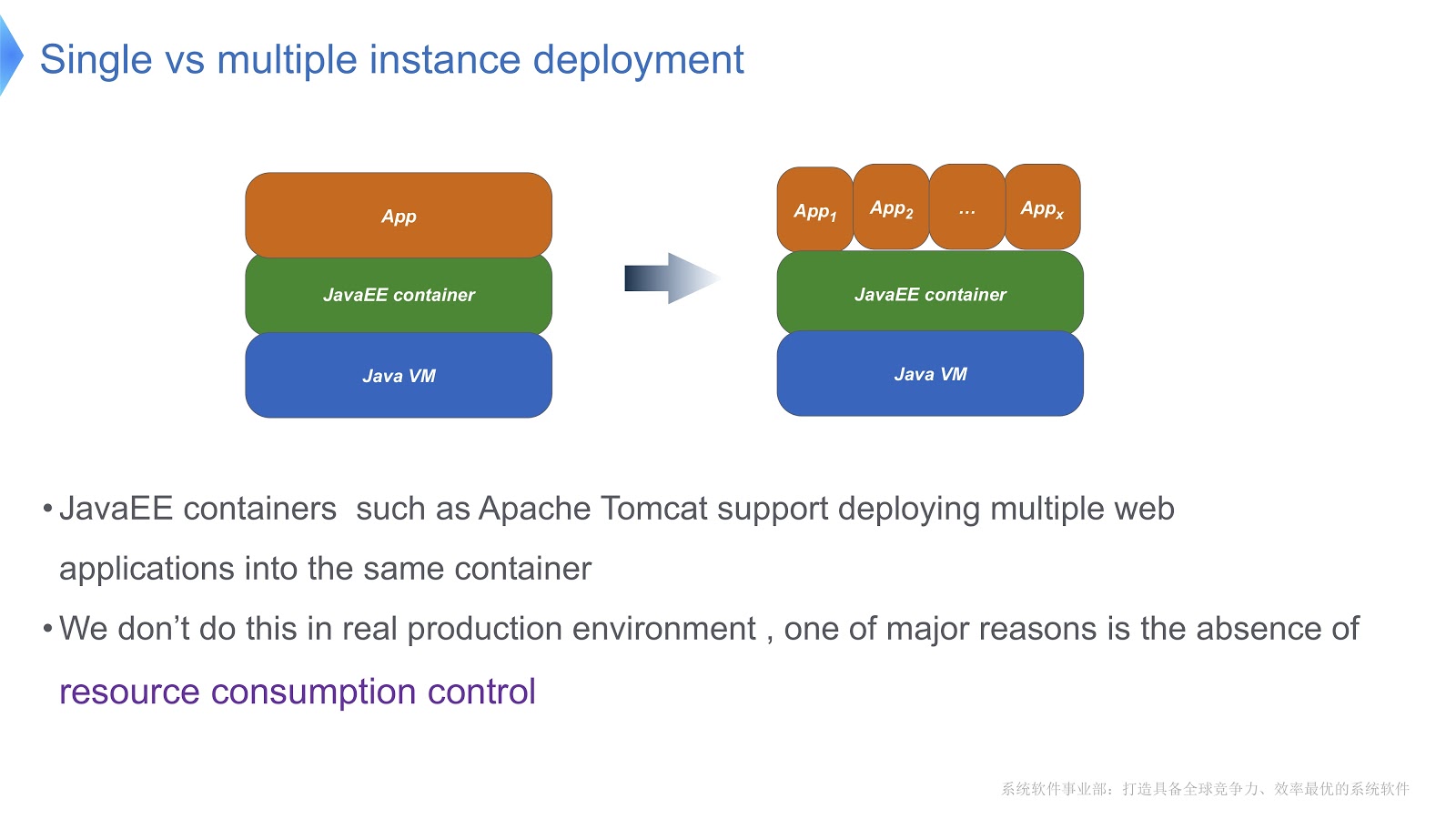
Schauen Sie sich das Bild oben an - ich denke, die meisten von Ihnen kennen dieses Muster. Vergleichen Sie den traditionellen Ansatz mit dem Mandanten. Wenn Ihre Anwendung mit Apache Tomcat ausgeführt wird, können Sie auch mehrere Instanzen im selben Container ausführen. Tomcat bietet jedoch nicht für jeden einen stabilen Ressourcenverbrauch. Angenommen, eine der laufenden Anwendungen benötigt mehr CPU-Zeit als die andere, wie steuern Sie die CPU-Zeitzuweisung? Wie kann sichergestellt werden, dass diese Anwendung die Arbeit anderer nicht beeinträchtigt? Vor allem diese Frage hat uns dazu gebracht, uns der Multitenant-Technologie zuzuwenden.
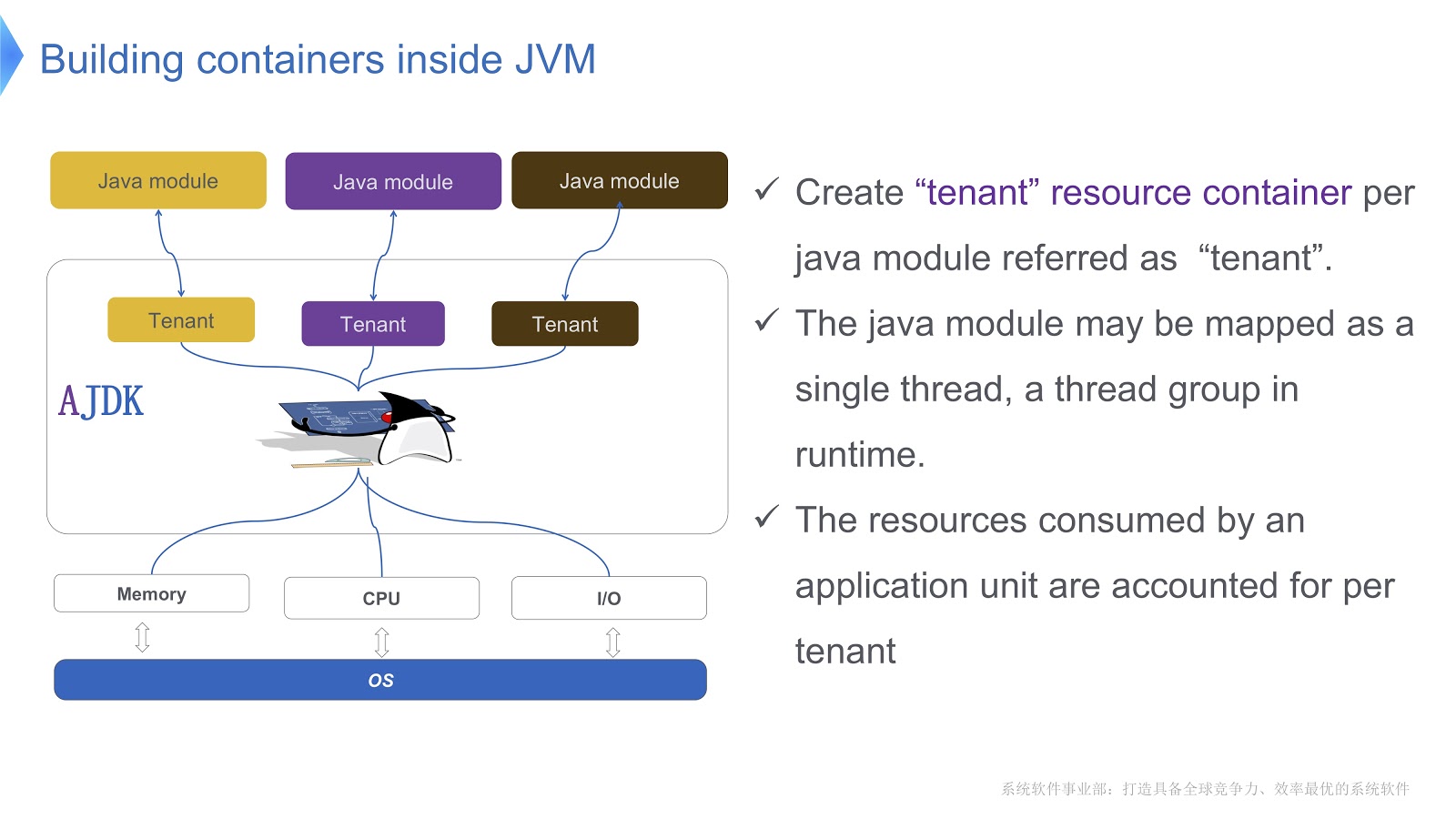
Das Bild zeigt schematisch, wie wir es implementieren. Wir erstellen mehrere Container für Mieter innerhalb der JVM. Jeder dieser Container bietet eine zuverlässige Kontrolle des Ressourcenverbrauchs für jedes Java-Modul. In einem Container können mehrere Module bereitgestellt werden. Jedes Modul kann zur Laufzeit einem Thread oder einer Gruppe von Threads zugeordnet werden.
Schauen wir uns an, wie die Mandantencontainer-API aussieht. Wir haben eine Mandantenkonfigurationsklasse, die Informationen zum Ressourcenverbrauch speichert. Als nächstes gibt es eine Klasse des Containers selbst.
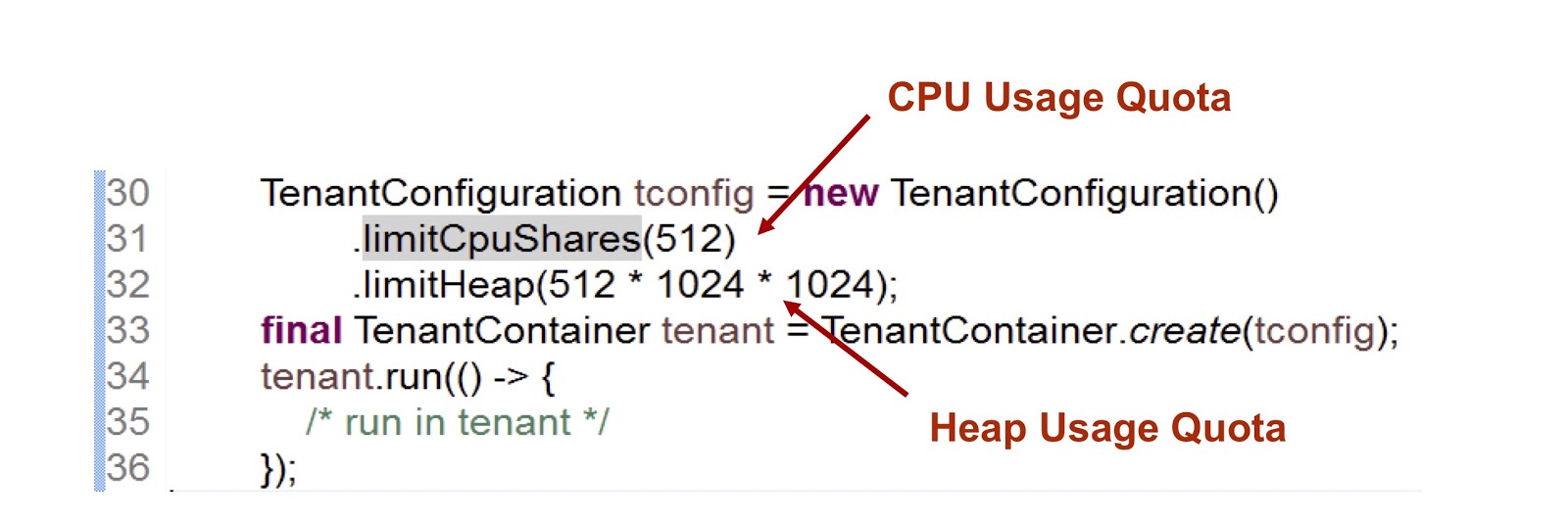
Im dargestellten Code-Snippet erstellen wir einen Mandanten und geben dann an, wie viel Zeit die CPU und der Speicher dafür bereitstellen. Der erste Indikator ist eine Ganzzahl, dh der Anteil der CPU-Zeit, der dem Mandanten zur Verfügung steht. In diesem Fall haben wir 512 angegeben. Bei cgroups verwenden wir einen sehr ähnlichen Ansatz. Darauf werde ich näher eingehen. Die zweite Metrik ist die maximale Heap-Größe, die Mandanten verwenden können.
Überlegen Sie, wie ein Mandant mit einem Thread interagiert. Die TenantContainer Klasse stellt die .run() -Methode .run() Wenn ein Thread in ihn eintritt, wird er automatisch an den Tenant .run() Wenn er ihn verlässt, erfolgt die umgekehrte Prozedur. Der gesamte Code wird also innerhalb der .run() -Methode ausgeführt. Darüber hinaus wird jeder in der .run() -Methode erstellte Thread an den Mandanten des übergeordneten Threads angehängt.
Wir kamen zu einer sehr wichtigen Frage: Wie wird die CPU in einer mandantenfähigen JVM verwaltet? Unsere Lösung wurde gerade auf der Linux x64-Plattform implementiert. Es gibt einen Kontrollgruppenmechanismus, cgroups. Sie können einen Prozess in einer separaten Gruppe auswählen und dann Ihren Ressourcenverbrauch für jede Gruppe angeben. Versuchen wir, diesen Ansatz auf den Kontext der Hotspot-JVM zu übertragen. Bei Hotstpot sind Java-Threads als native Threads organisiert.

Dies ist im obigen Diagramm dargestellt: Jeder Java-Thread steht in einer Eins-zu-Eins-Entsprechung mit dem nativen Thread. In unserem Beispiel haben wir einen TenantA Container, in dem sich zwei native Threads befinden. Um die Verteilung der CPU-Zeit steuern zu können, platzieren wir beide nativen Threads in einer Kontrollgruppe. Aus diesem Grund können wir den Ressourcenverbrauch regulieren, indem wir uns ausschließlich auf die Funktionalität von [Kontrollgruppen] verlassen ( https://en.wikipedia.org/wiki/Cgroups ).
Schauen wir uns ein detaillierteres Beispiel an.
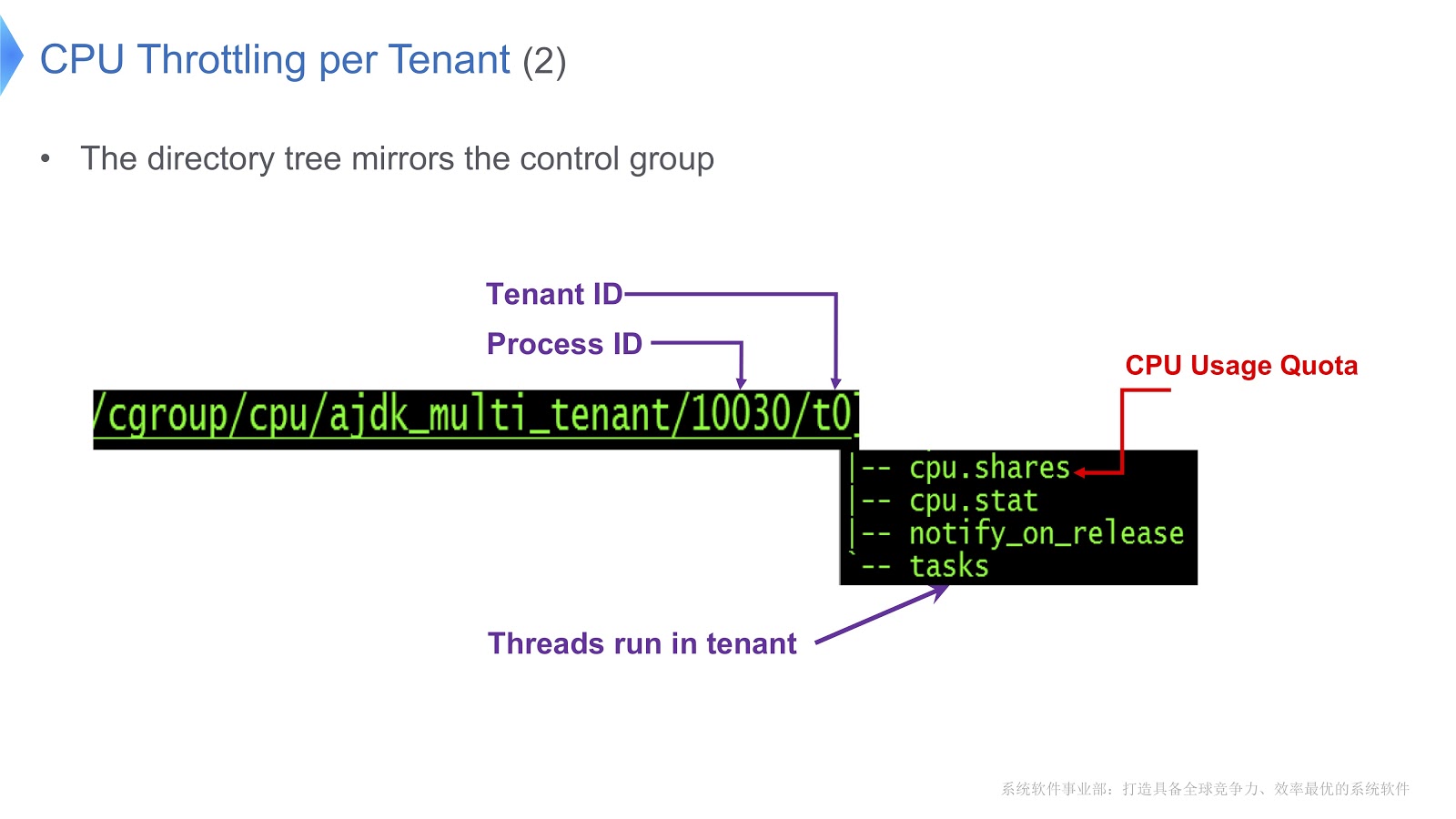
Kontrollgruppen unter Linux werden einem Verzeichnis zugeordnet. In unserem Beispiel haben wir das Verzeichnis /t0 für Tenant 0 erstellt. Dieses Verzeichnis enthält das Verzeichnis /t0/tasks . Alle Threads für t0 befinden sich hier. Eine weitere wichtige Datei ist /t0/cpu.shares . Es gibt an, wie viel Zeit die CPU diesem Mandanten zur Verfügung stellt. Diese gesamte Struktur wird von Kontrollgruppen geerbt - wir haben einfach eine direkte Korrespondenz zwischen dem Java-Thread, dem nativen Thread und der Kontrollgruppe sichergestellt.
Ein weiteres wichtiges Thema betrifft die Verwaltung einer Gruppe jedes Mieters.
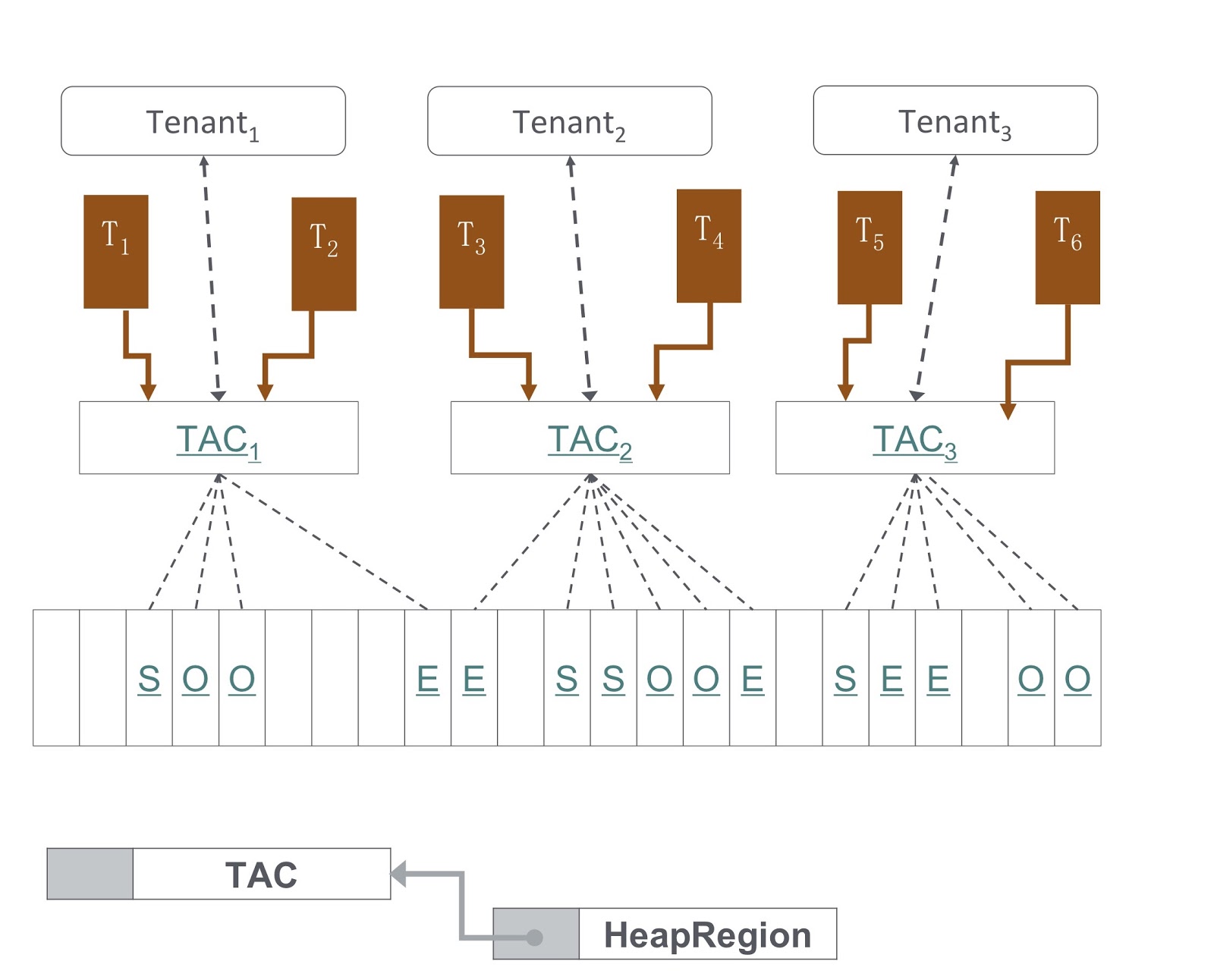
Im Bild sehen Sie ein Diagramm, wie es implementiert wird. Unser Ansatz basiert auf dem G1GC. Am unteren Rand des Bildes unterteilt G1GC den Heap in gleich große Abschnitte. Basierend darauf erstellen wir TACs (Tenant Allocation Contexts), mit denen der Mandant seinen Heap-Bereich verwaltet. Durch TAC begrenzen wir die Größe des Heap-Teils, der dem Mieter zur Verfügung steht. Hier gilt das Prinzip, wonach jeder Abschnitt des Heaps nur Objekte eines Mandanten enthält. Um es zu implementieren, mussten wir Änderungen am Kopierprozess eines Objekts während der Speicherbereinigung vornehmen. Es musste sichergestellt werden, dass das Objekt in den richtigen Abschnitt des Heaps kopiert wurde.
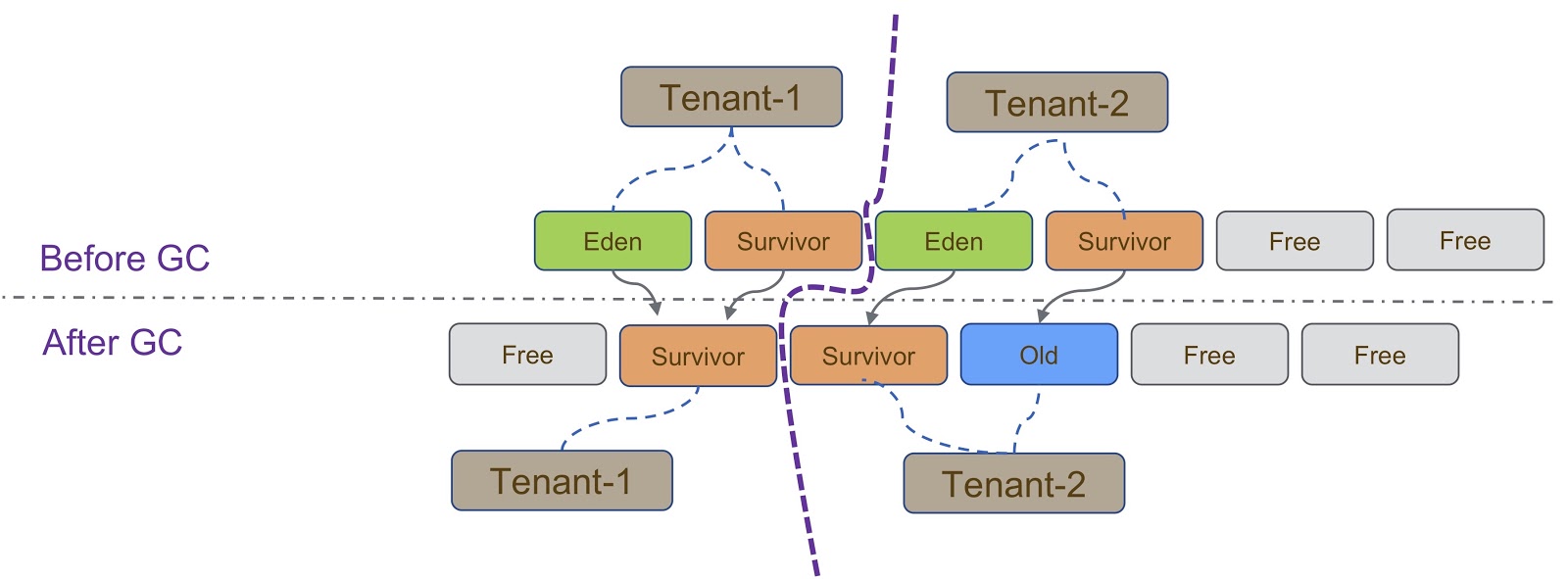
Schematisch ist dieser Vorgang in der obigen Abbildung dargestellt. Wie gesagt, unsere Implementierung basiert auf G1GC. G1GC ist ein kopierender Garbage Collector. Daher müssen wir während der Garbage Collection sicherstellen, dass das Objekt in den richtigen Abschnitt des Heaps kopiert wird. Auf der Folie müssen alle von Tenant-1 erstellten Objekte ähnlich wie Tenant-2 in seinen Teil des Heapspeichers kopiert werden.
Es gibt andere Überlegungen, die sich ergeben, wenn Mieter voneinander isoliert sind. Hier muss ich über TLAB (Thread Local Allocation Buffer) sprechen - einen Mechanismus für die schnelle Zuweisung von Speicher. Der TLAB-Speicherplatz hängt vom Heap-Abschnitt ab. Wie gesagt, verschiedene Mieter haben unterschiedliche Gruppen von Heap-Abschnitten.

Die Einzelheiten der Arbeit mit TLAB werden auf der Folie gezeigt. Wenn ein Thread von Tenant 1 zu Tenant 2 , müssen Sie sicherstellen, dass der richtige Heap-Abschnitt für den TLAB-Bereich verwendet wird. Dies kann auf zwei Arten erreicht werden. Der erste Weg ist, wenn Thread A von Tenant 1 zu Tenant 2 , wir werden nur den alten los und erstellen einen neuen in Tenant 2 . Diese Methode ist relativ einfach zu implementieren, verschwendet jedoch Speicherplatz in TLAB, was unerwünscht ist. Der zweite Weg ist komplizierter - TLAB auf Mieter aufmerksam zu machen. Dies bedeutet, dass wir mehrere TLAB-Puffer für einen Thread haben werden. Wenn Thread A von Tenant 1 zu Tenant 2 , müssen wir den Puffer ändern und den Puffer verwenden, der in Tenant 2 .
Ein weiterer Mechanismus, der im Zusammenhang mit der Abgrenzung von Mietern erwähnt werden muss, ist IHOP (Initiating Thread Occupancy Percent). Ursprünglich wurde der IHOP auf der Grundlage des gesamten Heaps berechnet, bei einem Mechanismus mit mehreren Mandanten muss er jedoch nur auf der Grundlage eines Abschnitts des Heaps berechnet werden.
Schauen wir uns GCIH (GC Invisible Heap) genauer an. Dieser Mechanismus erstellt einen Abschnitt auf dem Heap, der vor dem Garbage Collector verborgen ist und dementsprechend nicht von der Garbage Collection betroffen ist. Diese Site wird vom GCIH-Mandanten verwaltet.

Es ist wichtig zu sagen, dass wir unseren Java-Entwicklern eine öffentliche API zur Verfügung stellen. Ein Beispiel für die Arbeit damit ist auf dem Bildschirm zu sehen. Mit der Methode moveIn() Objekte von einem regulären Heap in einen Teil des GCIH-Heaps verschoben werden. Der Vorteil ist, dass Sie mit diesen Objekten weiterhin wie mit normalen Java-Objekten interagieren können. Ihre Struktur ist sehr ähnlich. Gleichzeitig benötigen sie jedoch nicht die Kosten für die Speicherbereinigung. Meiner Meinung nach müssen Sie das Verhalten des Garbage Collectors an die Anforderungen Ihrer Anwendung anpassen, wenn Sie die Speicherbereinigung beschleunigen möchten.
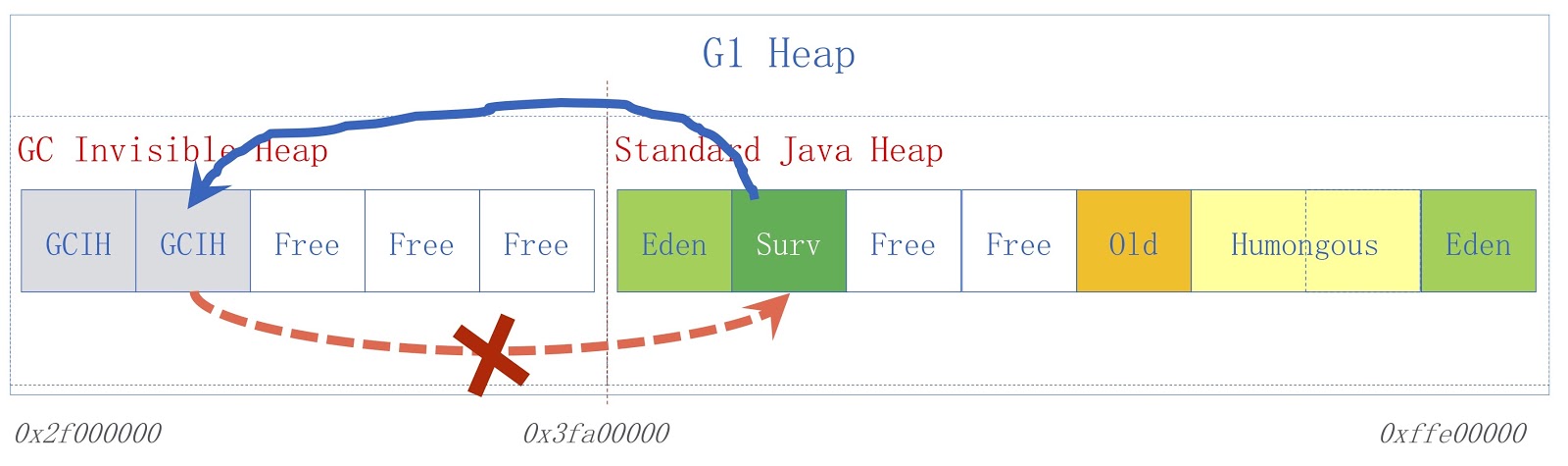
Das Bild zeigt ein hochrangiges GCIH-Schema. Auf der rechten Seite befindet sich ein regulärer Java-Heap, auf der linken Seite der für GCIH zugewiesene Speicherplatz. Links von einem regulären Heap zu Objekten in GCIH sind gültig, Links von GCIH zu einem regulären Heap jedoch nicht. Betrachten Sie ein Beispiel, um zu verstehen, warum dies so ist. Wir haben das Objekt "A" in GCIH, das einen Verweis auf das Objekt "B" in einem regulären Heap enthält. Das Problem ist, dass Objekt B vom Garbage Collector verschoben werden kann. Wie bereits erwähnt, werden in GCIH keine Aktualisierungen vorgenommen. Nachdem der Garbage Collector funktioniert hat, enthält das Objekt "A" möglicherweise einen ungültigen Verweis auf das Objekt "B". Dieses Problem kann mithilfe der Pre-Write-Barriere gelöst werden - sie wurden in einem früheren Bericht erörtert. Angenommen, jemand muss einen Link von einem regulären Java-Heap zu GCIH speichern, bevor das von uns angenommene Speichern zu einer Prädiktorausnahme mit einem Indikator-Flag führt, dass die Regel verletzt wurde.
Für eine bestimmte Anwendung wird in unserer Taobao Personalization Platform, abgekürzt TPP, eine mandantenfähige JVM verwendet. Dies ist ein Empfehlungssystem für unsere E-Shopping-Anwendung. TPP kann mehrere Microservices in einem Container bereitstellen. Mithilfe der mandantenfähigen JVM steuern wir den Speicher und die CPU-Zeit, die für jeden Microservice bereitgestellt werden.
GCIH wird in unserem anderen System, der UM-Plattform, verwendet. Dies ist eine Online-Rabattanwendung. Der Eigentümer dieser Anwendung verwendet GCIH, um GCIH-Daten auf dem lokalen Computer vorab zwischenzuspeichern, um nicht auf Objekte auf dem Remote-Cache-Server oder der Remote-Datenbank zuzugreifen. Infolgedessen entlasten wir das Netzwerk und führen weniger Serialisierung und Deserialisierung durch.
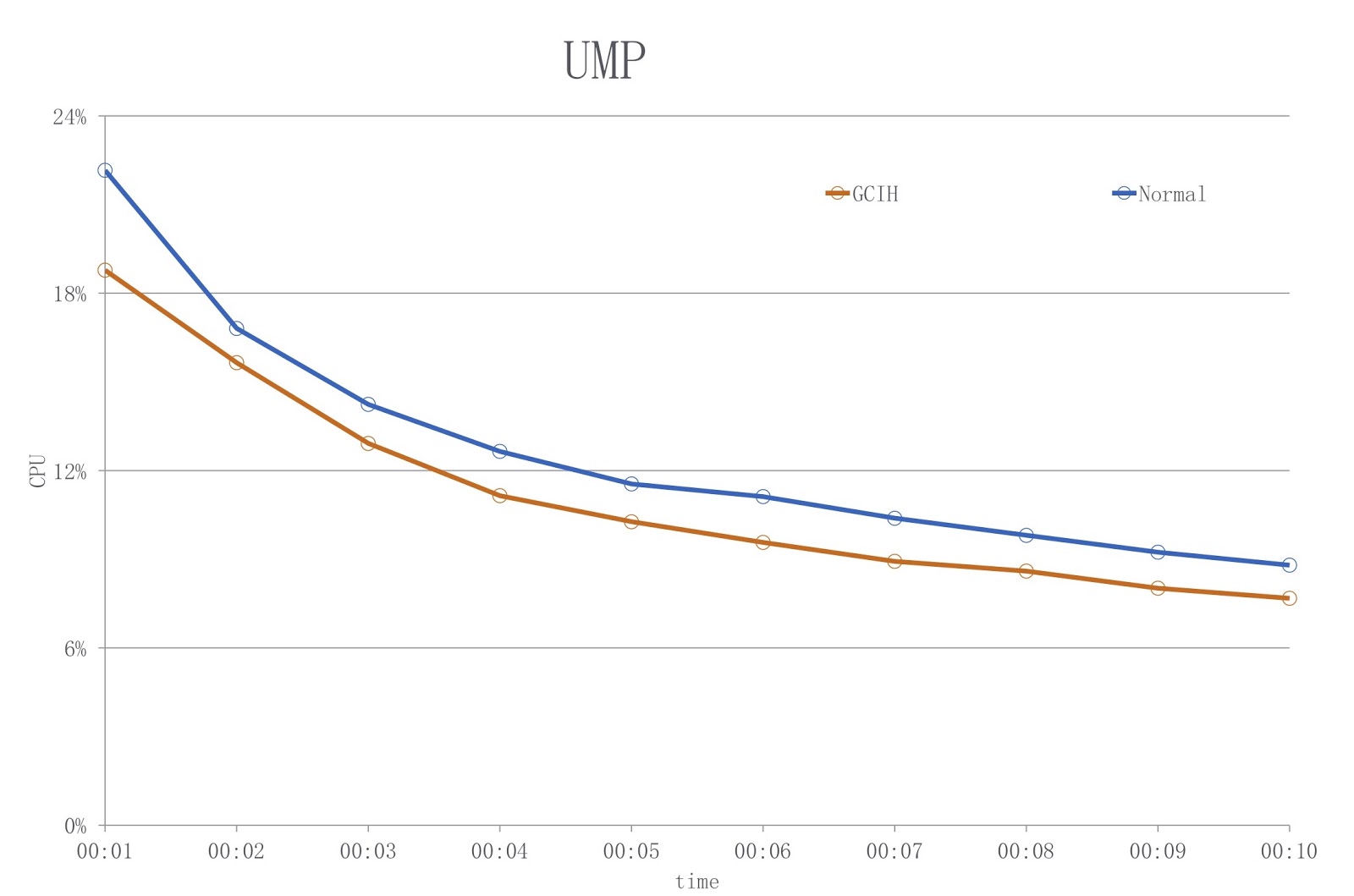
Das Bild zeigt ein Diagramm, in dem die blaue Farbe die Last bei Verwendung eines herkömmlichen JDK und die rote GCIH zeigt. Wie Sie sehen, reduzieren wir die CPU-Auslastung um über 18%.
Soweit ich weiß, wurde ein ähnliches Problem von BellSoft gelöst, und ihre Lösung war ähnlich wie bei GCIH, aber sie verwendeten einen anderen Ansatz, um die Kosten für Serialisierung und Deserialisierung zu senken.
Coroutinen in Java
Kehren wir zu Alibaba zurück und sehen, wie Coroutinen in Java implementiert werden können. Aber lassen Sie uns zuerst über die Ursprünge sprechen, warum wir das tun müssen. In Java war es immer sehr einfach, Multithreading-Anwendungen zu schreiben. Das Problem beim Erstellen solcher Anwendungen ist jedoch, dass, wie gesagt, in Hotspot Java-Threads bereits als native Threads implementiert sind. Wenn Ihre Anwendung viele Threads enthält, sind die Kosten für das Ändern des Thread-Kontexts daher sehr hoch.

Stellen Sie sich ein Beispiel vor, in dem wir 4 E / A-Threads und 200 Threads mit der Logik Ihrer Anwendung haben. Die Tabelle auf dem Bildschirm zeigt die Ergebnisse des Startens dieser einfachen Demo. Sie können sehen, wie viel Zeit die CPU benötigt, um den Kontext zu ändern. Die Lösung für dieses Problem kann die Implementierung von Corutin in Java sein.
Um es bereitzustellen, brauchten wir zwei Dinge. Zunächst musste Alibaba JDK die Unterstützung für die Fortsetzung hinzufügen. Diese Arbeit basierte auf dem JKU-Patch, auf den wir noch näher eingehen werden. Zweitens haben wir einen Sheduler im Benutzermodus hinzugefügt, der für die Fortsetzung im Thread verantwortlich ist. Drittens gibt es in Alibaba viele Anwendungen. Daher ist unsere Lösung für unsere Java-Entwickler sehr wichtig, und es war notwendig, sie für sie absolut transparent zu machen. Dies bedeutet, dass in unserer Geschäftsanwendung praktisch keine Änderungen am Code vorgenommen werden sollten. Wir haben unsere Lösung Wisp genannt. Unsere Implementierung von Coroutinen in Java ist in Alibaba weit verbreitet, daher kann davon ausgegangen werden, dass sie in Java funktioniert. Lernen Sie ihn näher kennen.

Beginnen wir mit dem Beispiel, dessen Code oben dargestellt ist - dies ist eine ganz normale Java-Anwendung. Zunächst wird ein Thread-Pool erstellt. Anschließend wird eine weitere ausführbare Aufgabe erstellt, die den Socket akzeptiert. Danach wird das Lesen aus dem Stream durchgeführt. Als Nächstes erstellen wir eine weitere ausführbare Aufgabe, mit der wir eine Verbindung zum Server herstellen und schließlich Daten in den Stream schreiben. Wie Sie sehen können, sieht alles ganz normal aus. Wenn Sie den Code in einem regulären JDK ausführen, wird jede dieser ausführbaren Aufgaben in einem separaten Thread ausgeführt. Bei unserer Entscheidung wird die Mechanik jedoch völlig anders sein.
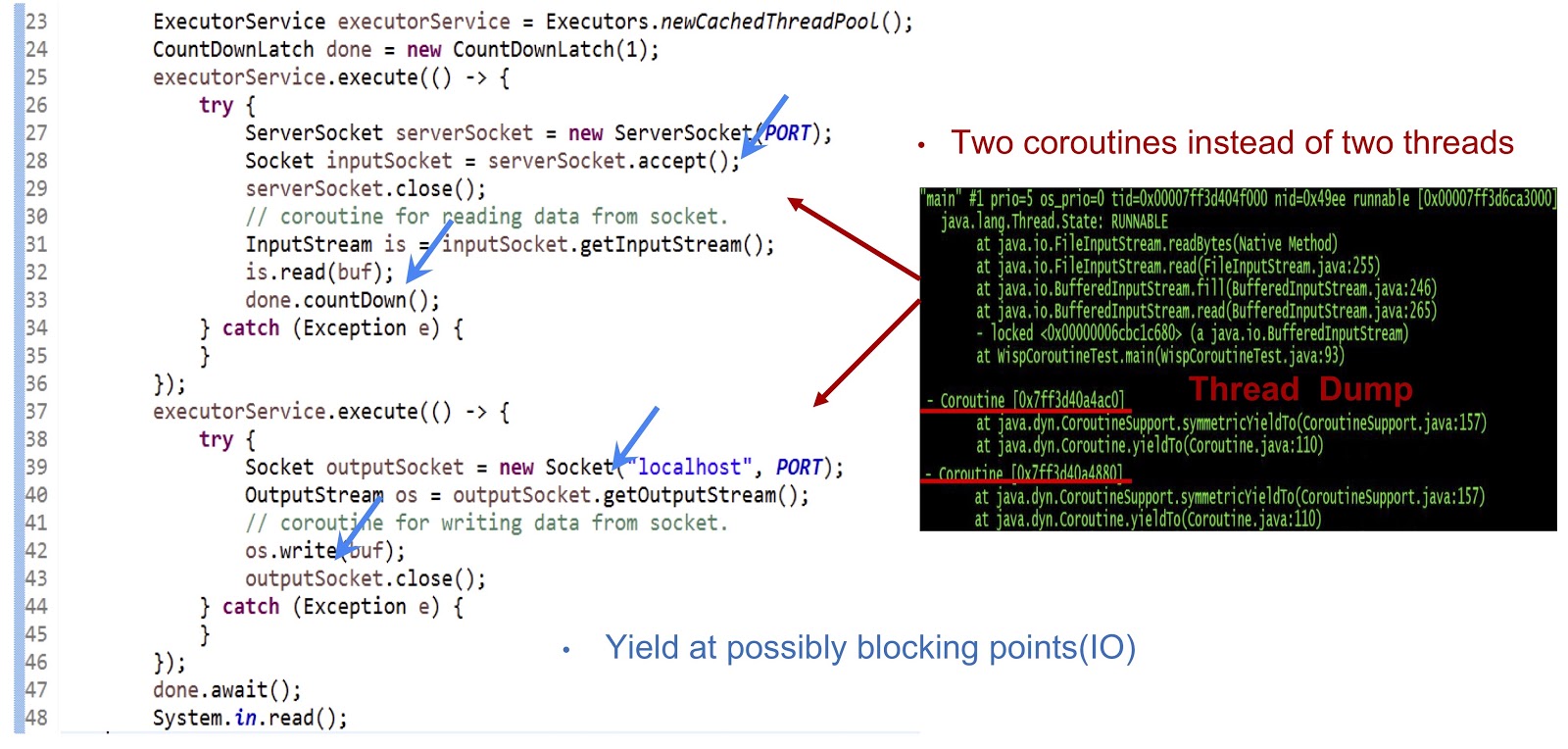
Wie Sie dem Dump des auf der Folie gezeigten Threads entnehmen können, erstellen wir zwei Coroutinen in einem Thread und nicht zwei Threads. Jetzt müssen Sie diese Lösung zum Laufen bringen. Die Hauptsache hier ist, YieldTo-Ereignisse an allen möglichen Blockierungspunkten zu generieren. In unserem Beispiel sind diese Punkte serverSocket.accept() , is.read(buf) , eine Socket-Verbindung und os.write(buf) . Dank der Ertragsereignisse an diesen Punkten können wir die Kontrolle innerhalb desselben Threads von einer Coroutine auf eine andere übertragen. Zusammenfassend ist unser Ansatz, dass wir mit Coroutine eine asynchrone Leistung erzielen, unsere Programmierer jedoch Code synchron schreiben können, da dieser Code viel einfacher und einfacher zu warten und zu debuggen ist.
Schauen wir uns genau an, wie wir die Fortsetzung in Alibaba JDK unterstützt haben. Wie gesagt, diese Arbeit basiert auf einem mehrsprachigen Projekt einer virtuellen Maschine, das von der Community erstellt wurde - es ist gemeinfrei. Wir haben diesen Patch in Alibaba JDK verwendet und einige Fehler behoben, die in unserer Produktionsumgebung aufgetreten sind.
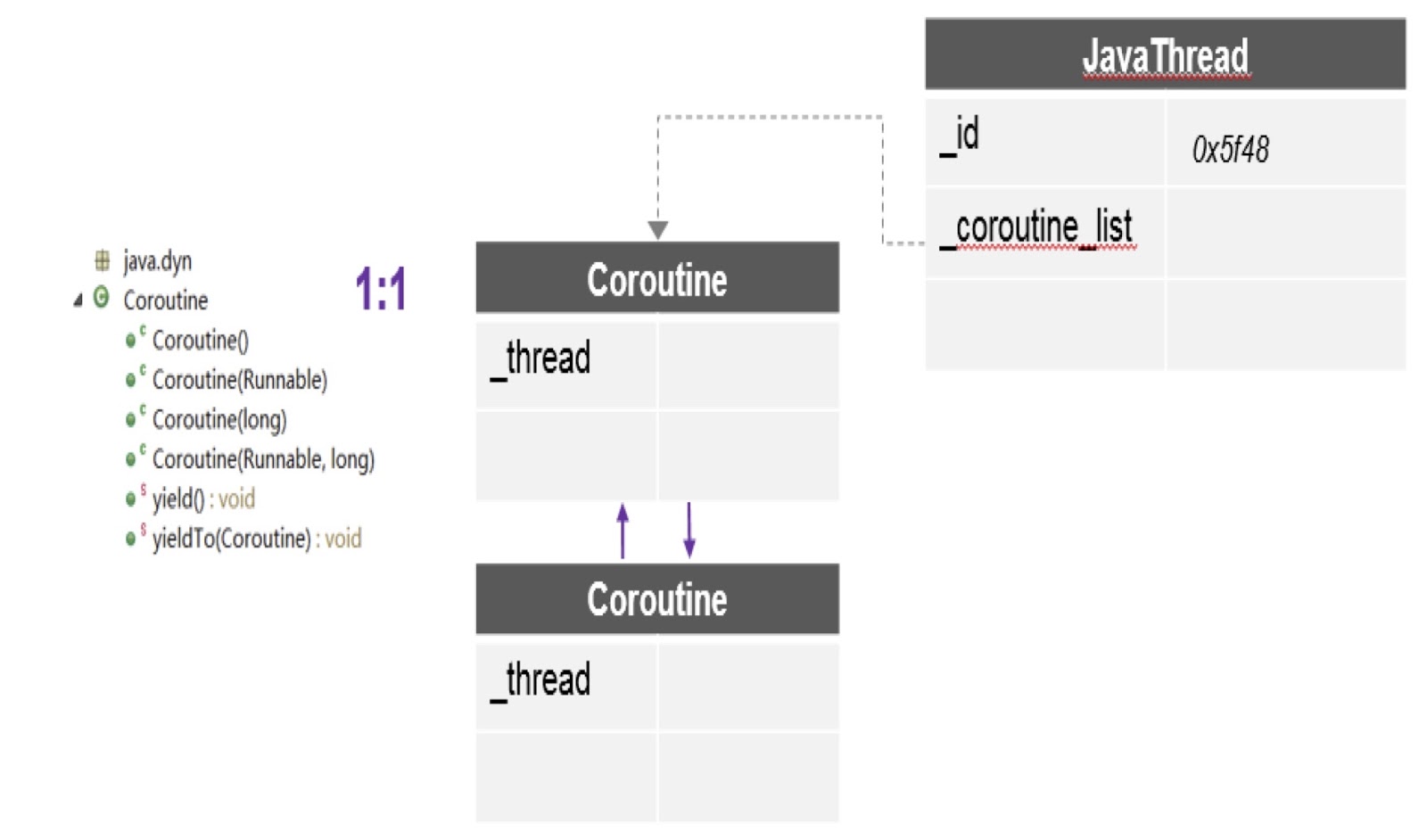
Wie Sie im Diagramm sehen können, kann es hier in einem Thread mehrere Coroutinen geben, und für jeden wird ein separater Stapel erstellt. Darüber hinaus bietet uns der Patch, über den ich gesprochen habe, die wichtigste API --ieldTo, mit deren Hilfe die Kontrolle von einer Coroutine auf eine andere übertragen wird.
Fahren wir fort mit der Implementierung des Benutzermodus-Shedulers für Coroutine. Wir benutzen einen Selektor und registrieren damit mehrere Kanäle. Wenn ein E / A-Ereignis (Socket lesen, Socket schreiben, Socket verbinden oder Socket akzeptieren) auftritt, wird es als Schlüssel für den Selektor geschrieben. Daher erhalten wir am Ende dieses Ereignisses eine Benachrichtigung vom Selektor. Daher verwenden wir einen Selektor, um Coroutinen im Falle einer E / A-Sperre zu planen. Betrachten Sie ein Beispiel, wie dies funktionieren wird.
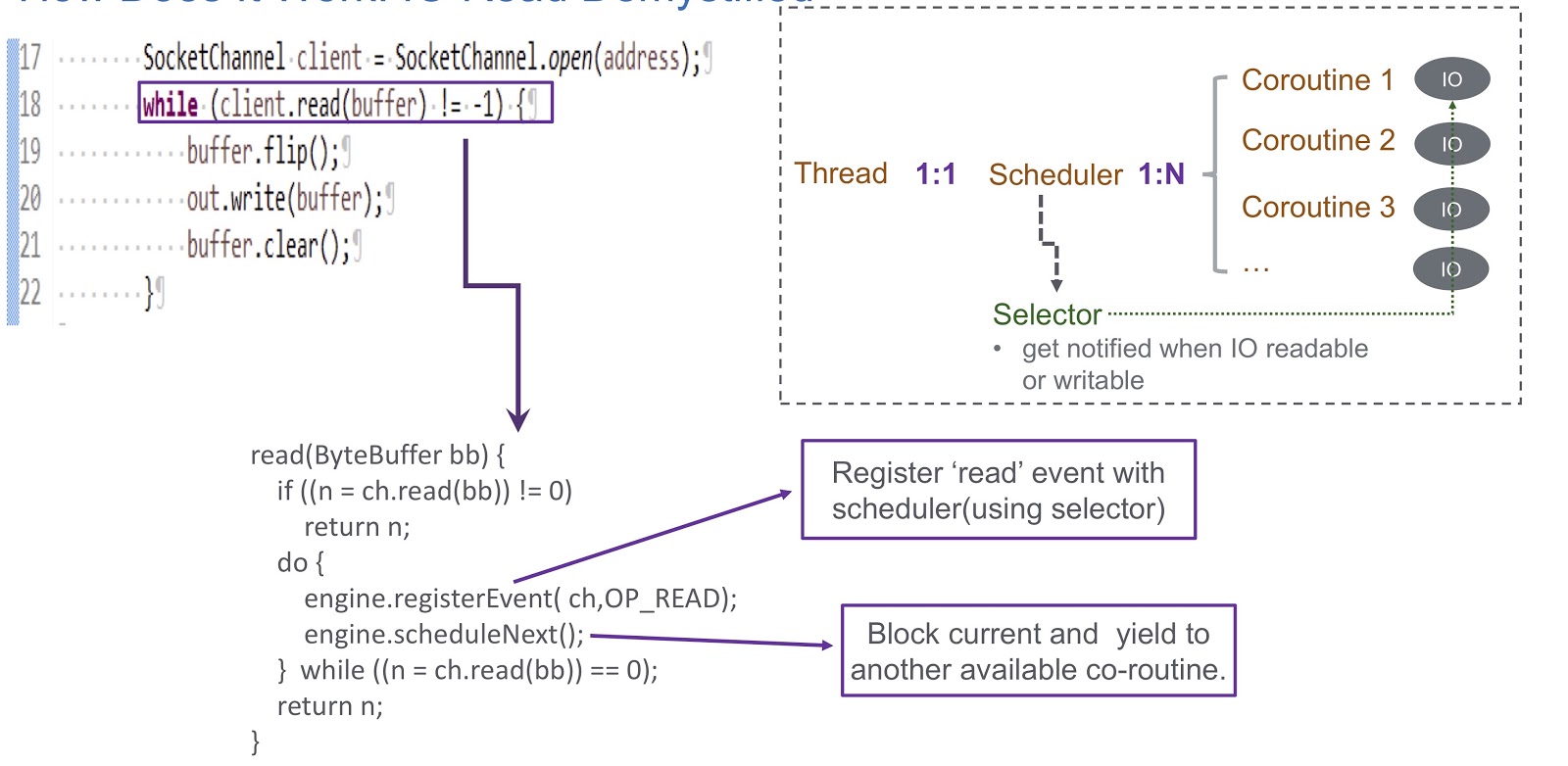
Im Bild sehen wir den Socket und den synchronen Aufruf client.read(buffer) . Am unteren Rand der Folie wird Code geschrieben, der in diesem Aufruf ausgeführt wird. Zunächst wird geprüft, ob vom Kanal gelesen werden kann oder nicht. Wenn ja, geben wir das Ergebnis zurück. Das Interessanteste passiert, wenn nicht gelesen werden kann. Dann registrieren wir das Leseereignis in unserem Scheduler mit Selektor. Dies ermöglicht es, die Ausführung einer anderen Coroutine zu planen. Schauen Sie sich an, wie das passiert. Wir haben einen Thread, in dem ein Scheduler erstellt wird. Der Thread und unsere Coroutine stehen in einer Eins-zu-Eins-Entsprechung miteinander. Mit Sheduler können wir die Coroutinen dieses Threads verwalten. Was passiert, wenn E / A blockiert ist? Wenn E / A-Ereignisse auftreten, erhält der Sheduler eine Warnung und verlässt sich in dieser Situation vollständig auf den Selektor. Nach einem solchen Ereignis erhält der Sheduler die Möglichkeit, die nächste verfügbare Coroutine zu planen.
Lassen Sie uns die Übersicht über unseren Sheduler zusammenfassen, den wir WispEngine genannt haben. Für jeden unserer Threads weisen wir eine separate WispEngine zu. Wenn eine Coroutine-Sperre auftritt, protokollieren wir bestimmte Ereignisse (Socket-Lesen / Schreiben usw.) mit WispEngine. Einige Ereignisse beziehen sich auf das Einparken von Threads, z. B. wenn Sie thread.sleep() mit einer Verzögerung von 100 Millisekunden aufrufen. In diesem Fall wird für Sie ein Thread-Parking-Ereignis generiert, das dann im Selektor registriert wird. Ein weiteres wichtiges Problem ist, wenn der Sheduler die nächste verfügbare Coroutine ernennt. Es gibt zwei Hauptbedingungen. Das erste ist, wenn bestimmte Ereignisse generiert werden, z. B. E / A-Ereignisse oder Timeout-Ereignisse. Hier ist alles ziemlich einfach: Angenommen, Sie rufen thread.sleep() mit einer Verzögerung von 200 Millisekunden auf. Wenn sie ablaufen, hat der Sheduler die Möglichkeit, die nächste verfügbare Coroutine auszuführen. Oder wir können hier über einige object.notify() sprechen, die beispielsweise durch Aufrufen von object.notify() oder object.notifyAll() Die zweite Bedingung ist, wenn der Benutzer neue Anforderungen object.notifyAll() und wir eine Coroutine erstellen, um diese Anforderungen zu bedienen, und der Sheduler dann zuweist seine Umsetzung.
Hier müssen Sie auch über den von uns erstellten Service WispThreadExecutor sprechen.

Auf dem Bildschirm wird ein Beispielcode angezeigt, und wir sehen, dass dies ein regulärer ExecutorService ist, der auf die gleiche Weise erstellt wurde. Die Methoden .execute() und submit submit() sind für ausführbare Aufgaben verfügbar. Das Problem besteht jedoch darin, dass alle ausführbaren Aufgaben, die die Methode submit submit() durchlaufen, in corutin und nicht im Thread ausgeführt werden. Diese Lösung ist für diejenigen, die unsere Anwendung implementieren, vollständig transparent. Sie können unsere API für Coroutinen verwenden.

Ich komme zum letzten schwierigen Teil des Beitrags - wie man das Problem der Synchronisation in Coroutinen löst. Dies ist eine komplexe Frage. Schauen wir uns diese anhand eines vereinfachten Beispiels an. Hier haben wir Coroutine A ( test::foo ) und Corutin test::bar ). Zuerst weisen wir die Ausführung von test:foo Coroutine wait() . Wenn nichts unternommen wird, wird der aktuelle Thread durch den Aufruf von wait() blockiert. Wie aus diesem Dump des Threads ersichtlich ist, tritt ein Deadlock auf, und wir können die nächste auszuführende Coroutine nicht planen.
Wie kann man dieses Problem lösen? Hotspot bietet drei Arten von Sperren. Das erste ist die Schnellverriegelung. Hier wird der Besitzer der Sperre durch die Adresse auf dem Stapel bestimmt. Wie gesagt, jede unserer Coroutinen hat einen eigenen Stapel. Daher müssen wir im Falle einer schnellen Verriegelung keine zusätzlichen Arbeiten ausführen. Es gibt keine ähnliche Unterstützung für vorgespannte Sperren in unserem System. Wir haben es in unserer Produktion versucht und es stellte sich heraus, dass die Leistung ohne ein voreingenommenes Schloss nicht abnimmt. Für uns ist es durchaus geeignet.
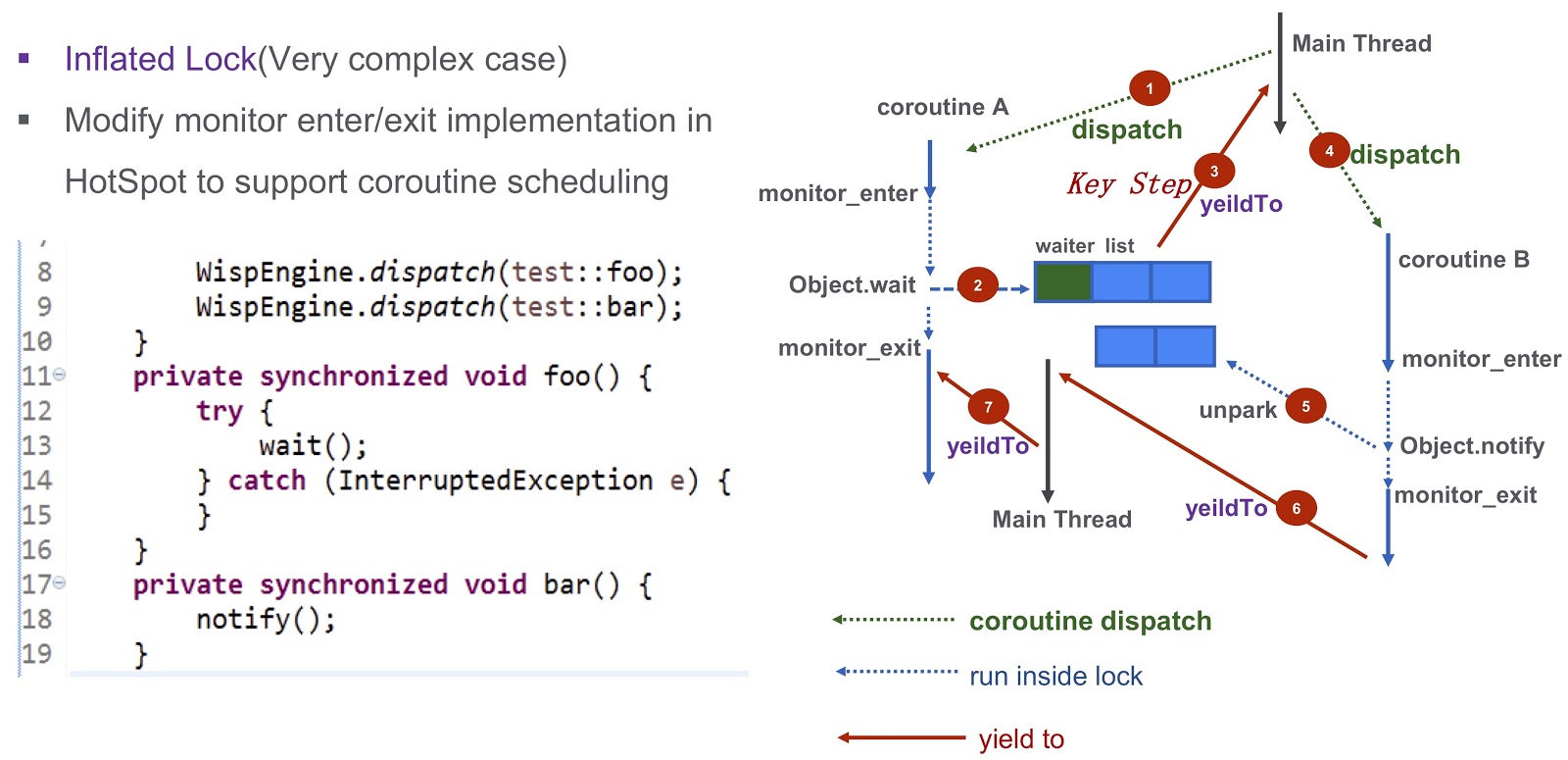
Lassen Sie uns über einen komplizierteren Fall sprechen - aufgeblasenes Schloss. Schauen wir uns noch einmal das Beispiel an, das ich oben zitiert habe. Wir haben Corutin .foo() ) und Corutin B ( .bar() ). Zuerst weisen wir die Ausführung von Coroutine Object.wait , woraufhin es in die Warteliste aufgenommen wird. Danach machen wir einen sehr wichtigen Schritt: Wir generieren das yieldTo Ereignis, das die Kontrolle auf den Haupt-Thread überträgt. Als nächstes starten wir Corutin B Es ruft Object.notify und die entsprechenden unpark Ereignisse werden unpark . Sie werden schließlich Coroutine bar() , kann die Kontrolle an Coroutine
Lassen Sie uns jetzt die Leistung diskutieren. Wir verwenden Coroutinen in einer unserer Carts-Online-Anwendungen. Basierend darauf können wir die Arbeit von Corutin mit der Arbeit von gewöhnlichem JDK vergleichen.
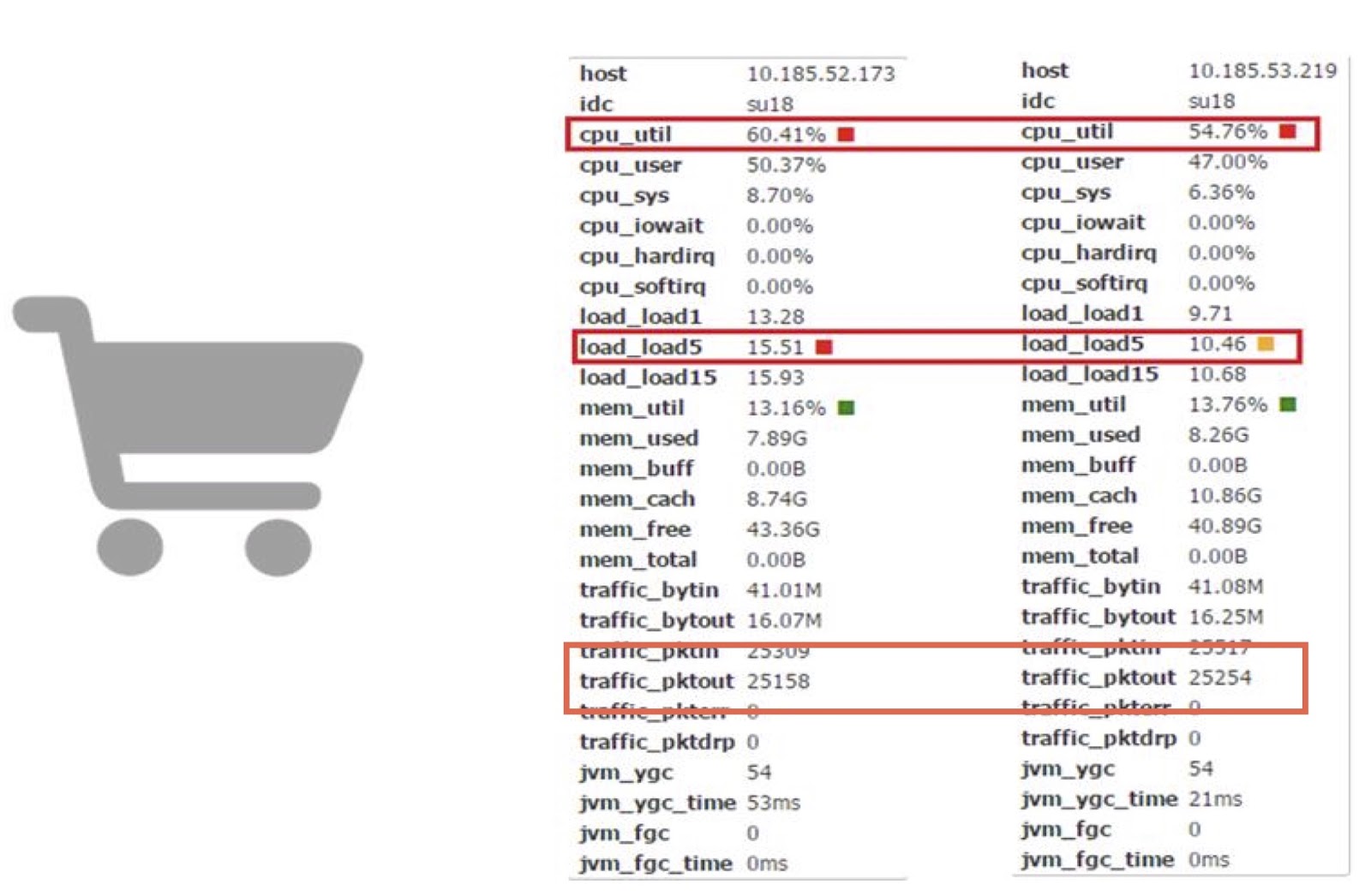
Wie Sie sehen, können wir damit den Prozessorzeitverbrauch um fast 10% senken. Ich verstehe, dass die meisten von Ihnen höchstwahrscheinlich nicht in der Lage sind, solche komplexen Änderungen direkt am JDK-Code vorzunehmen. Die wichtigste Schlussfolgerung hier ist meiner Meinung nach, dass Sie versuchen können, die Produktivität mithilfe der Corutin-Bibliothek zu verbessern, wenn Produktivitätsverluste Geld kosten und die daraus resultierende Menge groß genug ist.
Jarmarm
Fahren wir mit unserem anderen Tool fort - JWarmup. Es ist einem anderen Tool, ReadyNow, sehr ähnlich. Wie wir wissen, gibt es in Java ein Aufwärmproblem - der Compiler benötigt zu diesem Zeitpunkt zusätzliche CPU-Zyklen. Dies verursachte uns Probleme - zum Beispiel ist ein TimeOut-Fehler aufgetreten. Bei der Skalierung verschlimmern sich diese Probleme nur, und in unserem Fall handelt es sich um eine sehr komplexe Anwendung - mehr als 20.000 Klassen und mehr als 50.000 Methoden.
Bevor wir mit der Verwendung von JWarmup begannen, verwendeten die Eigentümer unserer Anwendung simulierte Daten zum Aufwärmen. Auf diesen Daten wurde der JIT-Compiler vor dem Empfang von Anforderungen vorkompiliert. Die simulierten Daten unterscheiden sich jedoch von den tatsächlichen Daten und sind daher für den Compiler nicht repräsentativ. In einigen Fällen trat eine unerwartete Deoptimierung auf, und die Leistung litt darunter. Die Lösung für dieses Problem war JWarmup. Er hat zwei Hauptarbeitsstufen - Aufnahme und Zusammenstellung. Alibaba hat zwei Arten von Umgebungen, Beta und Produktion. Beide erhalten echte Anforderungen von Benutzern, wonach dieselbe Version der Anwendung in diesen beiden Umgebungen bereitgestellt wird. In der Beta-Umgebung werden nur Profildaten gesammelt, auf deren Grundlage eine vorläufige Kompilierung in der Produktion durchgeführt wird.

Lassen Sie uns genauer sehen, welche Art von Informationen wir sammeln. Wir müssen genau aufschreiben, welche Klassen initialisiert werden, welche Methoden kompiliert werden, und diese Daten werden dann in das Protokoll auf der Festplatte geschrieben, auf das der Compiler zugreifen kann. Der schwierigste Moment ist die Initialisierung von Klassen. . — Bar Foo.test() , foo.count . , .
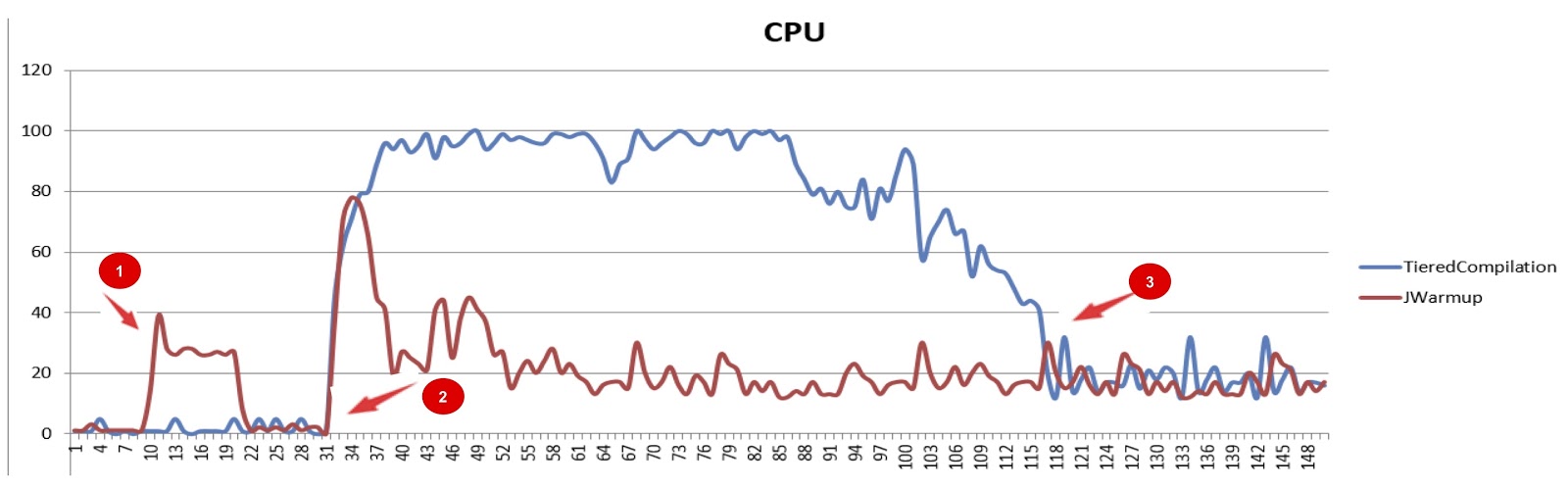
JWarmup (tiered compilation), . , — CPU. JWarmup , CPU, JDK. , , JDK. , , .
JWarmup. , , , groovy-, Java-, . . , , «null check elimination». . , JWarmup , JWarmup, .
, Alibaba.
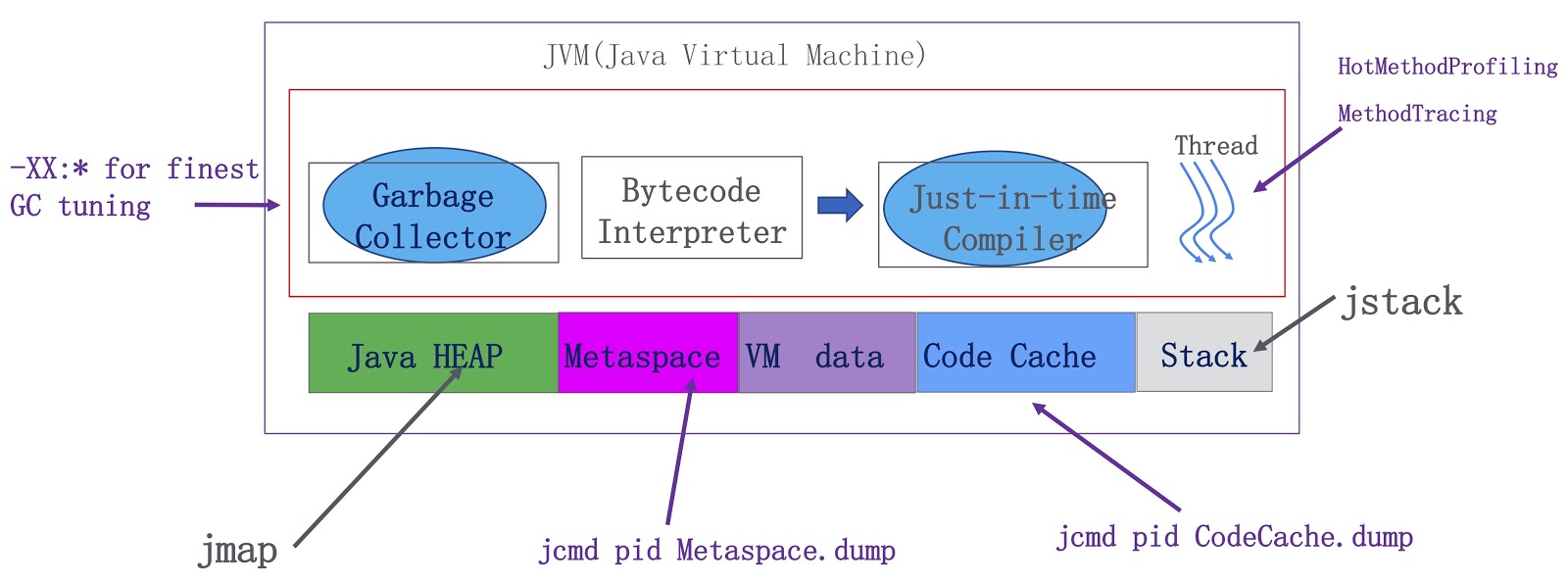
. JVM — , , . Java-, metaspace, VM ( VM) JIT-. OpenJDK. -, , . -, . HotMethodProfiling, , CPU. , , Honest Profiler , , , HotMethodProfiling. MethodTracing. , , . , metaspace . Java-, . metaspace , . Java.
, , ZProfiler.
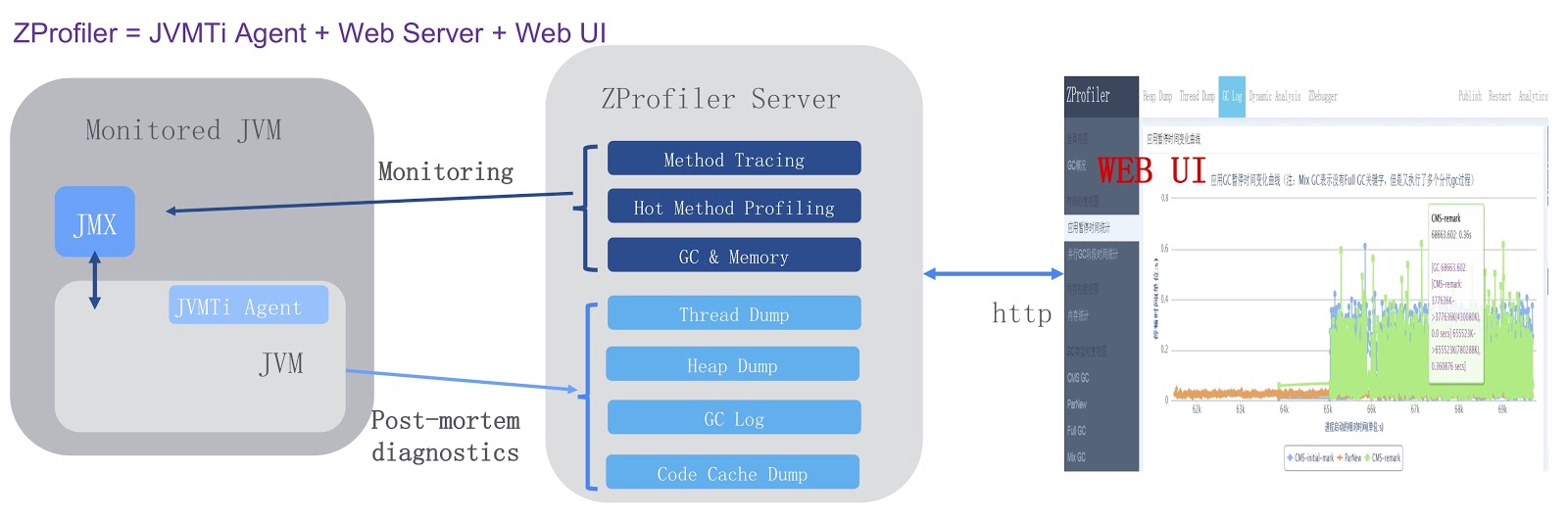
. JVMTi, JVM ( ). , ZProfiler Apache Tomcat. -. ZProfiler JVM. , ZProfiler -UI, . ZProfiler . -, UI JVM. -, ZProfiler post-mortem . , OutOfMemoryError, , JVM ZProfiler, . , , , Eclipse MAT.
. . JVM, GCIH, Alibaba JDK, JWarmup — , ReadyNow Zing JVM. , ZProfiler. , , OpenJDK. , , JWarmup OpenJDK. , OpenJDK Loom, Java. , .
. , , JPoint 2018 . 2019 , JPoint , 5-6 . , Rafael Winterhalter Sebastian Daschner. . , YouTube . JPoint!