 Gepostet von Denis Tsyplakov , Solution Architect, DataArt
Gepostet von Denis Tsyplakov , Solution Architect, DataArtIn DataArt arbeite ich auf zwei Arten. Im ersten Fall helfe ich Menschen, Systeme zu reparieren, die auf die eine oder andere Weise und aus verschiedenen Gründen defekt sind. Im zweiten Teil helfe ich dabei, neue Systeme so zu gestalten, dass sie in Zukunft nicht kaputt gehen, oder realistischer war es schwieriger, sie kaputt zu machen.
Wenn Sie nicht etwas grundlegend Neues tun, zum Beispiel die weltweit erste Internet-Suchmaschine oder künstliche Intelligenz, die den Start von Atomraketen steuert, ist es ganz einfach, ein gutes Systemdesign zu erstellen. Es reicht aus, alle Anforderungen zu berücksichtigen, das Design ähnlicher Systeme zu betrachten und ungefähr das Gleiche zu tun, ohne ernsthafte Fehler zu machen. Es klingt nach einer übermäßigen Vereinfachung des Problems, aber erinnern wir uns, dass auf dem Hof das Jahr 2019 ist und es für fast alles „Standardrezepte“ für das Systemdesign gibt. Ein Unternehmen kann komplexe technische Aufgaben bewältigen - beispielsweise eine Million heterogener PDF-Dateien verarbeiten und Kostentabellen daraus herausnehmen -, aber die Systemarchitektur ist selten sehr originell. Die Hauptsache dabei ist, keinen Fehler bei der Bestimmung des von uns gebauten Systems zu machen und die Auswahl der Technologien nicht zu verpassen.
Typische Fehler treten regelmäßig im letzten Absatz auf, von denen ich einige in einem Artikel diskutieren werde.
Was ist die Schwierigkeit bei der Auswahl eines technischen Stacks? Das Hinzufügen einer Technologie zum Projekt macht es schwieriger und bringt einige Einschränkungen mit sich. Dementsprechend sollte das Hinzufügen eines neuen Tools (Framework, Bibliothek) nur erfolgen, wenn dieses Tool nützlicher als schädlich ist. In Gesprächen mit Teammitgliedern über das Hinzufügen von Bibliotheken und Frameworks verwende ich oft scherzhaft den folgenden Trick: „Wenn Sie dem Projekt eine neue Abhängigkeit hinzufügen möchten, stellen Sie eine Schachtel Bier für das Team bereit. Wenn Sie der Meinung sind, dass sich diese Abhängigkeit von einer Kiste Bier nicht lohnt, fügen Sie sie nicht hinzu. “
Angenommen, wir erstellen eine bestimmte Anwendung, beispielsweise in Java, und um die Daten zu ändern, fügen wir dem Projekt die TimeMagus-Bibliothek (ein fiktives Beispiel) hinzu. Die Bibliothek ist ausgezeichnet, sie bietet uns viele Funktionen, die in der Standardklassenbibliothek nicht verfügbar sind. Wie kann eine solche Entscheidung schädlich sein? Schauen wir uns die möglichen Szenarien an:
- Nicht alle Entwickler kennen eine nicht standardmäßige Bibliothek. Die Einstiegsschwelle für neue Entwickler ist höher. Die Wahrscheinlichkeit steigt, dass ein neuer Entwickler einen Fehler macht, wenn er ein Datum mit einer unbekannten Bibliothek bearbeitet.
- Die Größe der Verteilung nimmt zu. Wenn die Größe der durchschnittlichen Anwendung auf Spring Boot leicht auf 100 MB anwachsen kann, ist dies keineswegs eine Kleinigkeit. Ich habe Fälle gesehen, in denen aus Gründen einer Methode eine 30-MB-Bibliothek in das Distributionskit gezogen wurde. Sie begründeten dies folgendermaßen: "Ich habe diese Bibliothek in einem früheren Projekt verwendet, und dort gibt es eine bequeme Methode."
- Je nach Bibliothek kann sich die Startzeit erheblich verlängern.
- Der Bibliotheksentwickler kann seine Idee aufgeben, dann beginnt die Bibliothek mit der neuen Java-Version in Konflikt zu geraten, oder es wird ein Fehler darin erkannt (der beispielsweise durch das Ändern von Zeitzonen verursacht wird), und es wird kein Patch veröffentlicht.
- Die Bibliothekslizenz steht irgendwann im Widerspruch zur Lizenz Ihres Produkts (überprüfen Sie die Lizenzen für alle von Ihnen verwendeten Produkte?).
- Jar hell - Die TimeMagus-Bibliothek benötigt die neueste Version der SuperCollections-Bibliothek. Nach einigen Monaten müssen Sie die Bibliothek für die Integration mit einer Drittanbieter-API verbinden, die nicht mit der neuesten Version von SuperCollections funktioniert und nur mit Version 2.x funktioniert. Sie können keine API verbinden. Es gibt keine andere Bibliothek für die Arbeit mit dieser API.
Auf der anderen Seite bietet uns die Standardbibliothek praktische Tools zum Bearbeiten von Datumsangaben. Wenn Sie beispielsweise keinen exotischen Kalender pflegen oder die Anzahl der Tage von heute bis zum „zweiten Tag des dritten Neumondes im Vorjahr des hochfliegenden Adlers“ berechnen müssen, ist dies möglicherweise sinnvoll Verwenden Sie keine Bibliothek von Drittanbietern. Selbst wenn es wunderbar und im Projektmaßstab ist, sparen Sie bis zu 50 Codezeilen.
Das betrachtete Beispiel ist recht einfach und ich denke, es ist einfach, eine Entscheidung zu treffen. Es gibt jedoch eine Reihe von Technologien, die in aller Munde sind, und ihre Verwendung ist offensichtlich, was die Auswahl erschwert - sie bieten dem Entwickler wirklich ernsthafte Vorteile. Dies muss jedoch nicht immer eine Gelegenheit sein, sie in Ihr Projekt zu ziehen. Schauen wir uns einige davon an.
Docker
Vor dem Aufkommen dieser wirklich coolen Technologie gab es bei der Bereitstellung von Systemen viele unangenehme und komplexe Probleme im Zusammenhang mit Versionskonflikten und obskuren Abhängigkeiten. Mit Docker können Sie eine Momentaufnahme des Systemstatus packen, in die Produktion einbinden und dort ausführen. Dadurch können die genannten Konflikte vermieden werden, was natürlich großartig ist.
Zuvor war dies auf monströse Weise geschehen, und einige Aufgaben wurden überhaupt nicht gelöst. Sie haben beispielsweise eine PHP-Anwendung, die die ImageMagick-Bibliothek zum Arbeiten mit Bildern verwendet, Ihre Anwendung benötigt außerdem bestimmte php.ini-Einstellungen und die Anwendung selbst wird über Apache httpd gehostet. Es gibt jedoch ein Problem: Einige reguläre Routinen werden durch Ausführen von Python-Skripten von cron implementiert, und die von diesen Skripten verwendete Bibliothek steht in Konflikt mit den in Ihrer Anwendung verwendeten Bibliotheksversionen. Mit Docker können Sie Ihre gesamte Anwendung zusammen mit Einstellungen, Bibliotheken und einem HTTP-Server in einen Container packen, der Anforderungen an Port 80 bedient, und Routinen in einen anderen Container. Alles zusammen wird perfekt funktionieren und Sie können den Konflikt der Bibliotheken vergessen.
Sollte ich Docker verwenden, um jede Anwendung zu packen? Meine Meinung: Nein, das ist es nicht wert. Das Bild zeigt eine typische Zusammensetzung einer in AWS bereitgestellten Docker-Anwendung. Die Rechtecke hier geben die Isolationsschichten an, die wir haben.
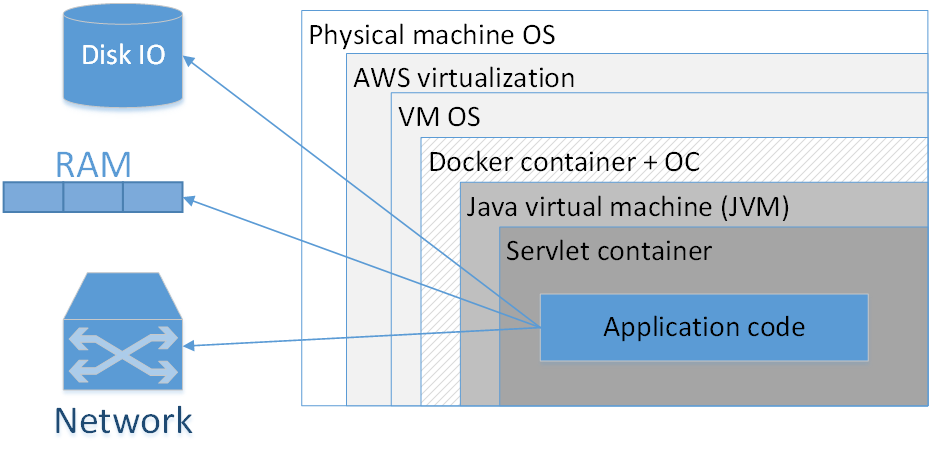
Das größte Rechteck ist die physische Maschine. Als nächstes folgt das Betriebssystem der physischen Maschine. Dann - der Amazonian Virtualizer, dann das Betriebssystem der virtuellen Maschine, dann der Docker-Container, gefolgt vom Container-Betriebssystem, der JVM, dann dem Servlet-Container (wenn es sich um eine Webanwendung handelt) und Ihr Anwendungscode befindet sich bereits darin. Das heißt, wir sehen bereits einige Isolationsschichten.
Die Situation wird noch schlimmer aussehen, wenn wir uns das Akronym JVM ansehen. JVM ist seltsamerweise die Java Virtual Machine, das heißt, wir haben immer mindestens eine virtuelle Maschine in Java. Das Hinzufügen eines zusätzlichen Docker-Containers bietet erstens oft keinen so spürbaren Vorteil, da die JVM selbst uns bereits ziemlich gut von der externen Umgebung isoliert und zweitens nicht ohne Kosten ist.
Ich habe vor zwei Jahren Zahlen aus einer IBM-Studie genommen, wenn nicht sogar falsch. Kurz gesagt, wenn es um Festplattenvorgänge, Prozessorauslastung oder Speicherzugriff geht, fügt Docker fast keinen Overhead hinzu (buchstäblich ein Bruchteil eines Prozent), aber wenn wir über Netzwerklatenz sprechen, sind die Verzögerungen ziemlich spürbar. Sie sind nicht gigantisch, aber je nachdem, welche Anwendung Sie haben, können sie Sie unangenehm überraschen.
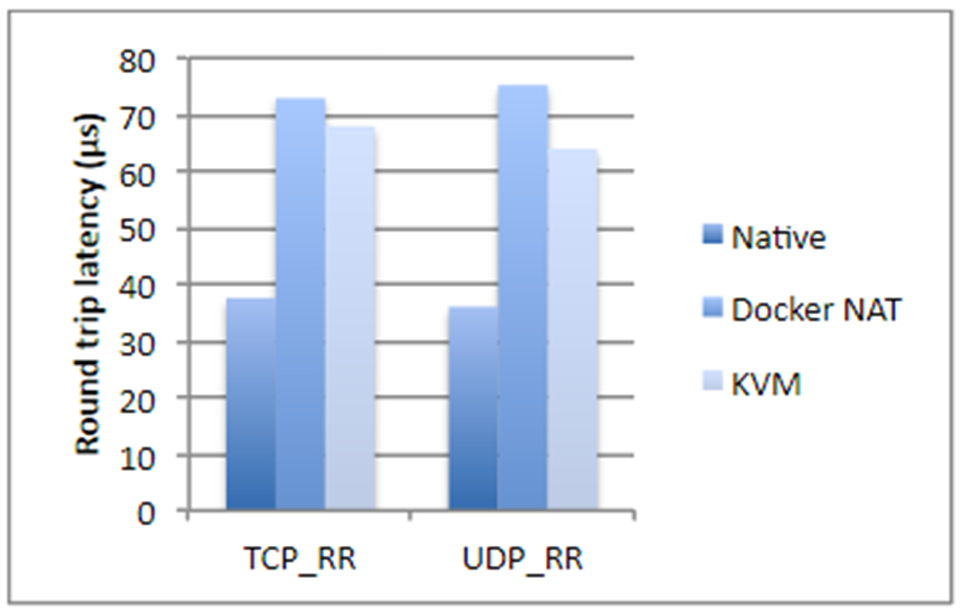
Außerdem verbraucht Docker zusätzlichen Speicherplatz, nimmt einen Teil des Speichers ein und verlängert die Startzeit. Alle drei Punkte sind für die meisten Systeme unkritisch - normalerweise gibt es viel Speicherplatz und Speicher. Die Startzeit ist in der Regel auch kein kritisches Problem, Hauptsache, die Anwendung startet. Es gibt jedoch immer noch Situationen, in denen der Speicher möglicherweise knapp wird und die Gesamtstartzeit des Systems, das aus zwanzig abhängigen Diensten besteht, bereits recht groß ist. Dies wirkt sich außerdem auf die Hostingkosten aus. Und wenn Sie im Hochfrequenzhandel tätig sind, passt Docker kategorisch nicht zu Ihnen. Im Allgemeinen ist es besser, keine Anwendung anzudocken, die empfindlich auf Netzwerkverzögerungen von bis zu 250 bis 500 ms reagiert.
Mit dem Docker ist die Analyse von Problemen in Netzwerkprotokollen spürbar kompliziert, nicht nur die Verzögerungen nehmen zu, sondern alle Timings werden unterschiedlich.
Wann wird Docker wirklich benötigt?
Wenn wir verschiedene Versionen der JRE haben und es schön wäre, die JRE mitzuziehen. Es gibt Zeiten, in denen Sie eine bestimmte Java-Version ausführen müssen (nicht „das neueste Java 8“, sondern etwas Spezifischeres). In diesem Fall empfiehlt es sich, die JRE mit der Anwendung zu packen und als Container auszuführen. Grundsätzlich ist klar, dass aufgrund von JAVA_HOME usw. verschiedene Versionen von Java auf das Zielsystem gestellt werden können. Docker ist jedoch in diesem Sinne viel praktischer, da Sie die genaue Version der JRE kennen, alles zusammen gepackt ist und mit einer anderen JRE die Anwendung nicht einmal versehentlich startet .
Docker ist auch erforderlich, wenn Sie Abhängigkeiten von einigen Binärbibliotheken haben, z. B. für die Bildverarbeitung. In diesem Fall ist es möglicherweise eine gute Idee, alle erforderlichen Bibliotheken mit der Java-Anwendung selbst zu packen.
Der folgende Fall bezieht sich auf ein System, das eine komplexe Zusammenstellung verschiedener Dienste darstellt, die in verschiedenen Sprachen geschrieben sind. Sie haben ein Stück auf Node.js, einen Teil in Java, eine Bibliothek in Go und zusätzlich eine Art maschinelles Lernen in Python. Dieser ganze Zoo muss sorgfältig und sorgfältig abgestimmt werden, um seinen Elementen beizubringen, sich gegenseitig zu sehen. Abhängigkeiten, Pfade, IP-Adressen - all dies muss in der Produktion gemalt und sorgfältig hervorgehoben werden. In diesem Fall hilft Ihnen Docker natürlich sehr. Darüber hinaus ist es einfach schmerzhaft, es ohne seine Hilfe zu tun.
Docker bietet einige Annehmlichkeiten, wenn Sie in der Befehlszeile viele verschiedene Parameter angeben müssen, um die Anwendung zu starten. Auf der anderen Seite machen Bash-Skripte dies sehr gut, oft aus einer einzigen Zeile. Entscheiden Sie, welche Sie besser verwenden möchten.
Das Letzte, was Ihnen sofort einfällt, ist die Situation, in der Sie beispielsweise Kubernetes verwenden und das System orchestrieren müssen, dh eine bestimmte Anzahl verschiedener Mikrodienste auslösen, die automatisch nach bestimmten Regeln skaliert werden.
In allen anderen Fällen reicht Spring Boot aus, um alles in eine einzige JAR-Datei zu packen. Und im Prinzip ist das Springboot-Glas eine gute Metapher für den Docker-Container. Dies ist natürlich nicht dasselbe, aber in Bezug auf die einfache Bereitstellung sind sie sich sehr ähnlich.
Kubernetes
Was ist, wenn wir Kubernetes verwenden? Mit dieser Technologie können Sie zunächst eine große Anzahl von Mikrodiensten auf verschiedenen Computern bereitstellen, verwalten, automatisch skalieren usw. Es gibt jedoch viele Anwendungen, mit denen Sie die Orchestrierung steuern können, z. B. Puppet, CF-Engine, SaltStack und andere. Kubernetes selbst ist sicherlich gut, kann aber einen erheblichen Overhead verursachen, mit dem nicht jedes Projekt leben kann.
Mein Lieblingswerkzeug ist Ansible, kombiniert mit Terraform, wo Sie es brauchen. Ansible ist ein ziemlich einfaches deklaratives leichtes Werkzeug. Es erfordert keine Installation spezieller Agenten und verfügt über die verständliche Syntax von Konfigurationsdateien. Wenn Sie mit Docker Compose vertraut sind, werden sofort überlappende Abschnitte angezeigt. Und wenn Sie Ansible verwenden, müssen Sie nicht vorab rezerezieren - Sie können Systeme mit klassischeren Mitteln bereitstellen.
Es ist klar, dass es sich dennoch um unterschiedliche Technologien handelt, aber es gibt einige Aufgaben, bei denen sie austauschbar sind. Und ein gewissenhafter Designansatz erfordert eine Analyse, welche Technologie für das zu entwickelnde System besser geeignet ist. Und wie wird es in ein paar Jahren besser sein, es zu erreichen.
Wenn die Anzahl der verschiedenen Dienste auf Ihrem System gering und ihre Konfiguration relativ einfach ist, Sie beispielsweise nur eine JAR-Datei haben und keine plötzliche, explosive Zunahme der Komplexität feststellen, müssen Sie möglicherweise mit klassischen Bereitstellungsmechanismen auskommen.
Dies wirft die Frage auf: "Warten Sie, wie ist eine JAR-Datei?". Das System sollte aus möglichst vielen atomaren Mikrodiensten bestehen! Mal sehen, wer und was das System mit Microservices machen soll.
Microservices
Erstens ermöglichen Microservices eine größere Flexibilität und Skalierbarkeit sowie eine flexible Versionierung einzelner Teile des Systems. Angenommen, wir haben eine Anwendung, die seit vielen Jahren in Produktion ist. Die Funktionalität wächst, aber wir können sie nicht umfassend weiterentwickeln. Zum Beispiel.
Wir haben eine Anwendung in Spring Boot 1 und Java 8. Eine wunderbare, stabile Kombination. Aber das Jahr ist 2019, und ob es uns gefällt oder nicht, wir müssen auf Spring Boot 2 und Java 12 umsteigen. Selbst der relativ einfache Übergang eines großen Systems zur neuen Version von Spring Boot kann sehr mühsam sein, aber es geht darum, über den Abgrund von Java 8 nach Java zu springen 12 Ich möchte nicht reden. Das heißt, theoretisch ist alles einfach: Wir migrieren, beheben die aufgetretenen Probleme, testen alles und führen es in der Produktion aus. In der Praxis kann dies mehrere Monate Arbeit bedeuten, die dem Unternehmen keine neuen Funktionen bringen. Wie Sie wissen, funktioniert ein kleiner Wechsel zu Java 12 ebenfalls nicht. Hier kann uns die Microservice-Architektur helfen.
Wir können eine kompakte Gruppe von Funktionen unserer Anwendung einem separaten Service zuordnen, diese Gruppe von Funktionen auf einen neuen technischen Stack migrieren und sie in relativ kurzer Zeit in die Produktion einbinden. Wiederholen Sie den Vorgang Stück für Stück, bis die alten Technologien vollständig erschöpft sind.
Microservices können auch eine Fehlerisolierung bieten, wenn eine heruntergefallene Komponente nicht das gesamte System ruiniert.
Microservices ermöglichen es uns, einen flexiblen technischen Stack zu haben, dh nicht alles monolithisch in einer Sprache und einer Version zu schreiben und bei Bedarf einen anderen technischen Stack für einzelne Komponenten zu verwenden. Natürlich ist es besser, wenn Sie einen einheitlichen technischen Stack verwenden, aber dies ist nicht immer möglich, und in diesem Fall können Microservices hilfreich sein.
Microservices bieten auch eine technische Möglichkeit, eine Reihe von Managementproblemen zu lösen. Zum Beispiel, wenn Ihr großes Team aus separaten Gruppen besteht, die in verschiedenen Unternehmen arbeiten (in verschiedenen Zeitzonen sitzen und verschiedene Sprachen sprechen). Microservices helfen dabei, diese organisatorische Vielfalt durch Komponenten zu isolieren, die separat entwickelt werden. Die Probleme eines Teils des Teams bleiben innerhalb eines Dienstes und werden nicht über die gesamte Anwendung verteilt.
Microservices sind jedoch nicht die einzige Möglichkeit, diese Probleme zu lösen. Seltsamerweise haben sich vor einigen Jahrzehnten für die Hälfte von ihnen die Leute Klassen ausgedacht, und wenig später - Komponenten und das Inversion of Control-Muster.
Wenn wir uns Spring ansehen, sehen wir, dass es sich tatsächlich um eine Microservice-Architektur innerhalb eines Java-Prozesses handelt. Wir können eine Komponente deklarieren, die im Wesentlichen eine Dienstleistung ist. Wir haben die Möglichkeit, eine Suche über @Autowired durchzuführen. Es gibt Tools zum Verwalten des Komponentenlebenszyklus und die Möglichkeit, Komponenten aus einem Dutzend verschiedener Quellen separat zu konfigurieren. Im Prinzip erhalten wir fast alles, was wir mit Microservices haben - nur innerhalb eines Prozesses, was die Kosten erheblich senkt. Eine reguläre Java-Klasse ist derselbe API-Vertrag, mit dem Sie auch Implementierungsdetails isolieren können.
Genau genommen sind Microservices in der Java-Welt OSGi am ähnlichsten - dort haben wir eine fast exakte Kopie von allem, was sich in Microservices befindet, außer der Möglichkeit, verschiedene Programmiersprachen und Codeausführung auf verschiedenen Servern zu verwenden. Aber selbst wenn wir innerhalb der Möglichkeiten von Java-Klassen bleiben, haben wir ein ziemlich leistungsfähiges Werkzeug, um eine große Anzahl von Isolationsproblemen zu lösen.
Selbst in einem „Management“ -Szenario mit Teamisolation können wir ein separates Repository erstellen, das ein separates Java-Modul mit einem eindeutigen externen Vertrag und einer Reihe von Tests enthält. Dies verringert die Fähigkeit eines Teams, das Leben eines anderen Teams versehentlich zu verkomplizieren, erheblich.
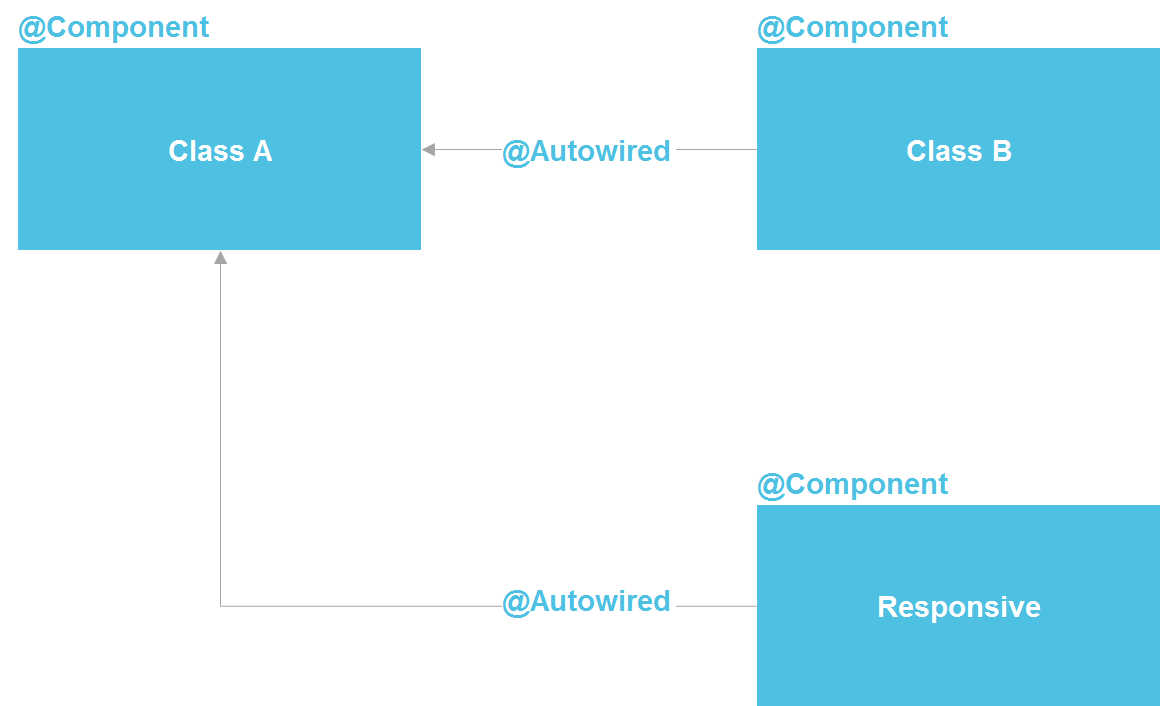
Ich habe wiederholt gehört, dass es unmöglich ist, Implementierungsdetails ohne Microservices zu isolieren. Aber ich kann antworten, dass es in der gesamten Softwareindustrie nur darum geht, die Implementierung zu isolieren. Zu diesem Zweck wurde zuerst das Unterprogramm erfunden (in den 50er Jahren des letzten Jahrhunderts), dann Funktionen, Verfahren, Klassen und später Mikrodienste. Die Tatsache, dass Microservices in dieser Reihe zuletzt erschienen sind, macht sie jedoch nicht zum höchsten Entwicklungspunkt und verpflichtet uns nicht, immer auf ihre Hilfe zurückzugreifen.
Bei der Verwendung von Microservices sollte auch berücksichtigt werden, dass Anrufe zwischen ihnen einige Zeit dauern. Dies ist oft unwichtig, aber ich habe einen Fall gesehen, in dem der Kunde die Systemantwortzeit von 3 Sekunden anpassen musste. Es war eine vertragliche Verpflichtung, eine Verbindung zu einem Drittanbieter-System herzustellen. Die Anrufkette durchlief mehrere Dutzend atomare Mikrodienste, und der Aufwand für HTTP-Anrufe ermöglichte es nicht, innerhalb von 3 Sekunden zu schrumpfen. Im Allgemeinen müssen Sie verstehen, dass jede Aufteilung von monolithischem Code in eine Reihe von Diensten zwangsläufig die Gesamtsystemleistung beeinflusst. Nur weil Daten nicht "kostenlos" zwischen Prozessen und Servern teleportiert werden können.
Wann werden Microservices benötigt?
In welchen Fällen muss eine monolithische Anwendung wirklich in mehrere Mikrodienste unterteilt werden? Erstens, wenn Ressourcen in Funktionsbereichen unausgewogen eingesetzt werden.
Zum Beispiel haben wir eine Gruppe von API-Aufrufen, die Berechnungen durchführen, die viel Prozessorzeit erfordern. Und es gibt eine Gruppe von API-Aufrufen, die sehr schnell ausgeführt werden, für deren Speicherung jedoch eine umständliche 64-GB-Datenstruktur erforderlich ist. Für die erste Gruppe benötigen wir eine Gruppe von Maschinen mit insgesamt 32 Prozessoren, für die zweite Gruppe reicht eine Maschine mit 64 GB Arbeitsspeicher aus (OK, es gibt zwei Maschinen für Fehlertoleranz). Wenn wir eine monolithische Anwendung haben, benötigen wir 64 GB Speicher auf jedem Computer, was die Kosten für jeden Computer erhöht. Wenn diese Funktionen in zwei separate Dienste unterteilt sind, können wir Ressourcen sparen, indem wir den Server für eine bestimmte Funktion optimieren. Die Serverkonfiguration sieht möglicherweise folgendermaßen aus:

Microservices werden benötigt und wenn wir einen engen Funktionsbereich ernsthaft skalieren müssen. Zum Beispiel werden hundert API-Methoden 10 Mal pro Sekunde aufgerufen, und beispielsweise werden vier API-Methoden 10 Tausend Mal pro Sekunde aufgerufen. Eine Skalierung des gesamten Systems ist häufig nicht erforderlich, dh wir können natürlich alle 100 Methoden auf viele Server multiplizieren. Dies ist jedoch in der Regel spürbar teurer und komplizierter als die Skalierung einer engen Gruppe von Methoden. Wir können diese vier Anrufe in einen separaten Dienst aufteilen und ihn nur auf eine große Anzahl von Servern skalieren.
Es ist auch klar, dass wir möglicherweise einen Microservice benötigen, wenn wir einen separaten Funktionsbereich geschrieben haben, beispielsweise in Python. Da sich herausstellte, dass einige Bibliotheken (z. B. für maschinelles Lernen) nur in Python verfügbar sind und wir sie in einen separaten Dienst aufteilen möchten. Es ist auch sinnvoll, einen Microservice zu erstellen, wenn ein Teil des Systems fehleranfällig ist. Es ist natürlich gut, Code so zu schreiben, dass im Prinzip keine Fehler auftreten, aber die Gründe können extern sein. Und niemand ist vor seinen eigenen Fehlern sicher. In diesem Fall kann der Fehler in einem separaten Prozess isoliert werden.
Wenn Ihre Anwendung keine der oben genannten Voraussetzungen erfüllt und in absehbarer Zeit nicht erwartet wird, ist eine monolithische Anwendung höchstwahrscheinlich am besten für Sie geeignet. Das einzige - ich empfehle, es so zu schreiben, dass Funktionsbereiche, die nicht miteinander in Beziehung stehen, im Code nicht voneinander abhängen. Damit können bei Bedarf nicht miteinander verbundene Funktionsbereiche voneinander getrennt werden. Dies ist jedoch immer eine gute Empfehlung, die die interne Konsistenz erhöht und Sie lehrt, Modulverträge sorgfältig zu formulieren.
Reaktive Architektur und reaktive Programmierung
Ein reaktiver Ansatz ist relativ neu. Der Zeitpunkt seines Erscheinens kann als das Jahr 2014 angesehen werden, in dem
das reaktive Manifest veröffentlicht wurde. Zwei Jahre nach der Veröffentlichung des Manifests war er allen bekannt. Dies ist ein wirklich revolutionärer Ansatz für das Systemdesign. , , , , .
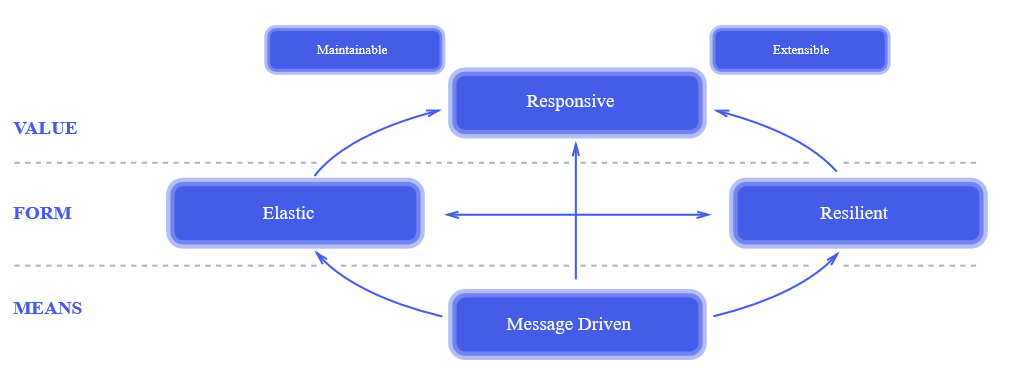
, . , , : « , !?» , , , , «». , 100% , , .
— , — . .
? , .
- , - . - -, , HTTP-. , . , . , , , .
? , HTTP- , ( callback) ( ) . , - ( , HTTP-) .
— . . . . 3 Ghz , , . . . , Java-, HTTP- — 5-10%. , , , , 100 50 $/ — $500 . , , .
, ? .
, . , , , , , , . , , . .
- . , JDBC ( . ADA, R2DBC, ). 90 % , . — HTTP- , . , .
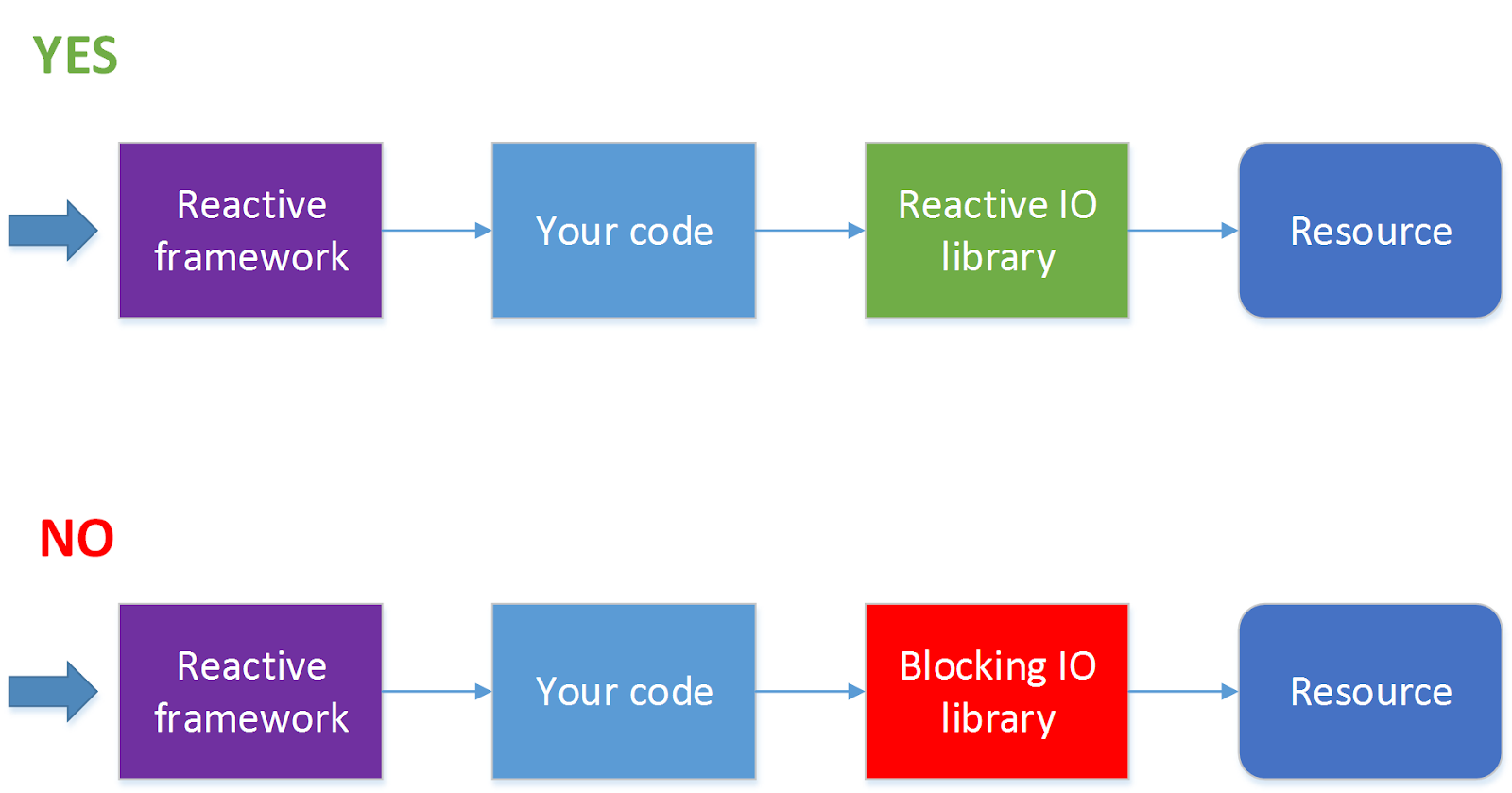
?
, , , ( ) . — - , . , , , HTTP.
, , , , , , .
. , « , » , , , . , , , 10 11 , , , .
Fazit
, . , , , .