
The Guardian ist eine der größten britischen Zeitungen und wurde 1821 gegründet. Seit fast 200 Jahren hat das Archiv eine ganze Menge angesammelt. Glücklicherweise wird nicht alles auf der Website gespeichert - in den letzten Jahrzehnten. Die Datenbank, die die Briten selbst als "Quelle der Wahrheit" für alle Online-Inhalte bezeichneten, enthält etwa 2,3 Millionen Elemente. Und irgendwann erkannten sie die Notwendigkeit einer Migration von Mongo zu Postgres SQL - nach einem heißen Julitag im Jahr 2015 wurden die Failover-Verfahren streng getestet. Die Migration dauerte fast 3 Jahre! ..
Wir haben
einen Artikel übersetzt, der beschreibt, wie der Migrationsprozess verlaufen ist und mit welchen Schwierigkeiten Administratoren konfrontiert sind. Der Prozess ist lang, aber die Zusammenfassung ist einfach: Kommen Sie zur großen Aufgabe und vereinbaren Sie, dass Fehler notwendig sind. Am Ende, drei Jahre später, gelang es den britischen Kollegen, das Ende der Migration zu feiern. Und schlafen.
Erster Teil: Der Anfang
Bei Guardian wird der größte Teil des Inhalts, einschließlich Artikeln, Blogs, Fotogalerien und Videos, in unserem eigenen CMS, Composer, produziert. Bis vor kurzem arbeitete Composer mit der AWS-basierten Mongo DB zusammen. Diese Datenbank war im Wesentlichen eine "Quelle der Wahrheit" für alle Online-Inhalte von Guardian - etwa 2,3 Millionen Elemente. Und wir haben gerade die Migration von Mongo zu Postgres SQL abgeschlossen.
Composer und seine Datenbanken wurden ursprünglich in der Guardian Cloud gehostet, einem Rechenzentrum im Keller unseres Büros in der Nähe von Kings Cross, mit einem Failover an anderer Stelle in London. An einem
heißen Julitag im Jahr 2015 wurden unsere Failover-Verfahren einem ziemlich strengen Test unterzogen.
 Hitze: gut zum Tanzen am Brunnen, katastrophal für das Rechenzentrum. Foto: Sarah Lee / Wächter
Hitze: gut zum Tanzen am Brunnen, katastrophal für das Rechenzentrum. Foto: Sarah Lee / WächterSeitdem ist die Migration von Guardian zu AWS eine Frage von Leben und Tod. Für die Migration in die Cloud haben wir uns für den Kauf von
OpsManager , der Mongo DB-Verwaltungssoftware, entschieden und einen Vertrag über den technischen Support von Mongo unterzeichnet. Wir haben OpsManager verwendet, um Backups zu verwalten, unseren Datenbankcluster zu orchestrieren und zu überwachen.
Aufgrund redaktioneller Anforderungen mussten wir den Datenbankcluster und OpsManager auf unserer eigenen Infrastruktur in AWS ausführen und nicht die von Mongo verwaltete Lösung verwenden. Wir mussten schwitzen, da Mongo keine Tools für die einfache Konfiguration in AWS bereitstellte: Wir haben die gesamte Infrastruktur manuell entworfen und
Hunderte von Ruby-Skripten geschrieben , um Überwachungs- / Automatisierungsagenten zu installieren und neue Datenbankinstanzen zu orchestrieren. Infolgedessen mussten wir im Team ein Team von Schulungsprogrammen zum Datenbankmanagement organisieren - was wir uns von OpsManager erhofft hatten.
Seit dem Übergang zu AWS sind zwei erhebliche Fehler aufgrund von Datenbankproblemen aufgetreten, von denen jeder mindestens eine Stunde lang keine Veröffentlichung auf theguardian.com zuließ. In beiden Fällen konnten uns weder die Mitarbeiter des technischen Supports von OpsManager noch der technische Support von Mongo ausreichend unterstützen, und wir haben das Problem selbst gelöst - in einem Fall dank eines
Mitglieds unseres Teams , das es geschafft hat, die Situation telefonisch aus der Wüste am Stadtrand von Abu Dhabi zu bewältigen.
Jedes der problematischen Probleme verdient einen eigenen Beitrag, aber hier sind die allgemeinen Punkte:
- Achten Sie genau auf die Zeit - blockieren Sie den Zugriff auf Ihre VPC nicht so stark, dass NTP nicht mehr funktioniert.
- Das automatische Erstellen von Datenbankindizes beim Start der Anwendung ist eine schlechte Idee.
- Das Datenbankmanagement ist äußerst wichtig und schwierig - und wir möchten es nicht selbst tun.
OpsManager hat sein Versprechen einer einfachen Datenbankverwaltung nicht eingehalten. Zum Beispiel erforderte die eigentliche Verwaltung von OpsManager selbst - insbesondere das Upgrade von OpsManager Version 1 auf Version 2 - viel Zeit und spezielle Kenntnisse über unser OpsManager-Setup. Aufgrund von Änderungen im Authentifizierungsschema zwischen verschiedenen Versionen von Mongo DB konnte er sein Versprechen von „One-Click-Updates“ nicht einhalten. Wir haben mindestens zwei Monate an Ingenieuren pro Jahr verloren, die die Datenbank verwalten.
All diese Probleme, zusammen mit der erheblichen jährlichen Gebühr, die wir für den Supportvertrag und OpsManager gezahlt haben, zwangen uns, nach einer alternativen Datenbankoption mit den folgenden Merkmalen zu suchen:
- Minimaler Aufwand für die Verwaltung der Datenbank.
- Verschlüsselung in Ruhe.
- Ein akzeptabler Migrationspfad mit Mongo.
Da auf allen anderen Diensten AWS ausgeführt wird, ist Dynamo, die NoSQL-Datenbank von Amazon, die naheliegende Wahl. Leider unterstützte Dynamo zu diesem Zeitpunkt keine Verschlüsselung im Ruhezustand. Nachdem wir ungefähr neun Monate auf das Hinzufügen dieser Funktion gewartet hatten, gaben wir diese Idee auf, indem wir uns für die Verwendung von Postgres auf AWS RDS entschieden.
"Aber Postgres ist kein Dokumenten-Repository!" - Sie sind empört ... Nun ja, dies ist kein Repository von Docks, aber es enthält Tabellen, die JSONB-Spalten ähneln und Indizes in den Feldern des JSON-Blob-Tools unterstützen. Wir hofften, dass wir mit JSONB mit minimalen Änderungen an unserem Datenmodell von Mongo nach Postgres migrieren können. Wenn wir in Zukunft zu einem relationaleren Modell übergehen wollten, hätten wir darüber hinaus eine solche Chance. Eine weitere großartige Sache bei Postgres ist, wie gut es funktioniert hat: Für jede Frage, die wir hatten, wurde die Antwort in den meisten Fällen bereits in Stack Overflow gegeben.
In Bezug auf die Leistung waren wir uns sicher, dass Postgres dies tun könnte: Composer ist ein Tool ausschließlich zum Aufzeichnen von Inhalten (es schreibt jedes Mal, wenn ein Journalist den Druck beendet, in die Datenbank), und normalerweise überschreitet die Anzahl der gleichzeitigen Benutzer mehrere Hundert nicht - was das System nicht erfordert super hohe Leistung!
Teil zwei: Die Content-Migration von zwei Jahrzehnten verlief ohne Ausfallzeiten
PlanenDie meisten Datenbankmigrationen implizieren dieselben Aktionen, und unsere war keine Ausnahme. Folgendes haben wir getan:
- Neue Datenbank erstellt.
- Sie haben eine Möglichkeit zum Schreiben in eine neue Datenbank (neue API) erstellt.
- Wir haben einen Proxyserver erstellt, der Datenverkehr sowohl an die alte als auch an die neue Datenbank sendet, wobei die alte als Hauptdatenbank verwendet wird.
- Datensätze aus der alten Datenbank in die neue verschoben.
- Sie machten die neue Datenbank zur Hauptdatenbank.
- Die alte Datenbank wurde entfernt.
Angesichts der Tatsache, dass die Datenbank, in die wir migriert haben, die Funktionsweise unseres CMS ermöglichte, war es wichtig, dass die Migration unseren Journalisten so wenig Probleme wie möglich bereitet. Am Ende enden die Nachrichten nie.
Neue APIDie Arbeiten an der neuen Postgres-basierten API begannen Ende Juli 2017. Dies war der Beginn unserer Reise. Aber um zu verstehen, wie es war, müssen wir zuerst klären, wo wir angefangen haben.
Unsere vereinfachte CMS-Architektur sah ungefähr so aus: eine Datenbank, eine API und mehrere damit verbundene Anwendungen (z. B. eine Benutzeroberfläche). Der Stack wurde gebaut und arbeitet seit 4 Jahren auf der Basis von
Scala ,
Scalatra Framework und
Angular.js .
Nach einigen Analysen kamen wir zu dem Schluss, dass wir vor der Migration des vorhandenen Inhalts eine Möglichkeit benötigen, die neue PostgreSQL-Datenbank zu kontaktieren, um die alte API betriebsbereit zu halten. Schließlich ist Mongo DB unsere „Quelle der Wahrheit“. Sie diente uns als Lebensader, während wir mit der neuen API experimentierten.
Dies ist einer der Gründe, warum es nicht Teil unserer Pläne war, auf der alten API aufzubauen. Die Trennung der Funktionen in der ursprünglichen API war minimal, und die spezifischen Methoden, die für die Arbeit mit Mongo DB erforderlich sind, konnten sogar auf Controller-Ebene gefunden werden. Infolgedessen war die Aufgabe, einer vorhandenen API einen anderen Datenbanktyp hinzuzufügen, zu riskant.
Wir sind in die andere Richtung gegangen und haben die alte API dupliziert. So wurde APIV2 geboren. Es war eine mehr oder weniger genaue Kopie der alten Mongo-bezogenen API und enthielt dieselben Endpunkte und Funktionen. Wir haben
doobie verwendet , die reine JDBC-Feature-Layer für Scala,
Docker zum lokalen Ausführen und Testen hinzugefügt und die Protokollierung von Vorgängen und die Aufteilung der Verantwortung verbessert. APIV2 sollte eine schnelle und moderne Version der API sein.
Ende August 2017 wurde eine neue API bereitgestellt, die PostgreSQL als Datenbank verwendete. Das war aber nur der Anfang. Es gibt Artikel in Mongo DB, die vor über zwei Jahrzehnten erstellt wurden und alle in die Postgres-Datenbank migriert werden mussten.
Die MigrationWir sollten in der Lage sein, jeden Artikel auf der Website zu bearbeiten, unabhängig davon, wann er veröffentlicht wurde. Daher existieren alle Artikel in unserer Datenbank als eine einzige „Quelle der Wahrheit“.
Obwohl alle Artikel in der
Guardian Content API (CAPI) enthalten sind , die die Anwendungen und die Website bedient, war es für uns äußerst wichtig, ohne Störungen zu migrieren, da unsere Datenbank unsere „Quelle der Wahrheit“ ist. Wenn etwas mit dem Elasticsearch CAPI-Cluster passiert ist, würden wir es aus der Composer-Datenbank neu indizieren.
Daher mussten wir vor dem Deaktivieren von Mongo sicherstellen, dass dieselbe Anforderung für die auf Postgres ausgeführte API und die auf Mongo ausgeführte API identische Antworten zurückgibt.
Dazu mussten wir den gesamten Inhalt in die neue Postgres-Datenbank kopieren. Dies wurde mithilfe eines Skripts durchgeführt, das direkt mit den alten und neuen APIs interagierte. Der Vorteil dieser Methode war, dass beide APIs bereits eine gut getestete Schnittstelle zum Lesen und Schreiben von Artikeln in und aus Datenbanken bereitstellten, anstatt etwas zu schreiben, das direkt auf die jeweiligen Datenbanken zugegriffen hat.
Die grundlegende Migrationsreihenfolge war wie folgt:
- Holen Sie sich Inhalte von Mongo.
- Poste Inhalte auf Postgres.
- Holen Sie sich Inhalte von Postgres.
- Stellen Sie sicher, dass die Antworten von ihnen identisch sind.
Eine Datenbankmigration kann nur dann als erfolgreich angesehen werden, wenn Endbenutzer nicht bemerkt haben, dass dies geschehen ist, und ein gutes Migrationsskript immer der Schlüssel zu einem solchen Erfolg ist. Wir brauchten ein Skript, das:
- Führen Sie HTTP-Anforderungen aus.
- Stellen Sie sicher, dass nach der Migration eines Teils des Inhalts die Antwort beider APIs gleich ist.
- Beenden Sie, wenn ein Fehler auftritt.
- Erstellen Sie ein detailliertes Betriebsprotokoll, um Probleme zu diagnostizieren.
- Starten Sie nach einem Fehler an der richtigen Stelle neu.
Wir haben mit
Ammonite begonnen . Sie können damit Skripte in der Scala-Sprache schreiben, die den Kern unseres Teams bildet. Es war eine gute Gelegenheit, mit etwas zu experimentieren, das wir vorher nicht benutzt hatten, um zu sehen, ob es für uns nützlich sein würde. Obwohl Ammonite es uns erlaubte, eine vertraute Sprache zu verwenden, fanden wir einige Mängel bei der Arbeit daran. Intellij
unterstützt derzeit Ammonite, hat dies jedoch während unserer Migration nicht getan, und wir haben die automatische Vervollständigung und den automatischen Import verloren. Darüber hinaus konnte das Ammonite-Skript lange Zeit nicht ausgeführt werden.
Letztendlich war Ammonite nicht das richtige Werkzeug für diesen Job, sondern wir haben das sbt-Projekt für die Migration verwendet. Dies ermöglichte es uns, in einer Sprache zu arbeiten, in der wir uns sicher waren, und mehrere Testmigrationen durchzuführen, bevor wir in der Hauptarbeitsumgebung starteten.
Unerwartet war, wie nützlich es war, die Version der API zu überprüfen, die auf Postgres ausgeführt wird. Wir haben einige schwer zu findende Fehler und Grenzfälle gefunden, die wir zuvor nicht gefunden haben.
Schneller Vorlauf bis Januar 2018, wenn es Zeit ist, die vollständige Migration in unserer vorgefertigten CODE-Umgebung zu testen.
Wie bei den meisten unserer Systeme besteht die einzige Ähnlichkeit zwischen CODE und PROD in der Version der Anwendung, die gestartet wird. Die AWS-Infrastruktur, die CODE unterstützt, war viel weniger leistungsfähig als PROD, einfach weil sie viel weniger Arbeitsbelastung verursacht.
Wir hofften, dass die Testmigration in der CODE-Umgebung uns helfen würde:
- Schätzen Sie, wie lange die Migration in der PROD-Umgebung dauern wird.
- Bewerten Sie, wie sich die Migration (wenn überhaupt) auf die Produktivität auswirkt.
Um genaue Messungen dieser Indikatoren zu erhalten, mussten wir die beiden Umgebungen in völlige gegenseitige Übereinstimmung bringen. Dies beinhaltete die Wiederherstellung einer Mongo DB-Sicherung von PROD auf CODE und die Aktualisierung der von AWS unterstützten Infrastruktur.
Die Migration von etwas mehr als 2 Millionen Datenelementen hätte viel länger dauern müssen, als es ein normaler Arbeitstag zulässt. Deshalb haben wir das Skript für die Nacht auf dem
Bildschirm ausgeführt .
Um den Fortschritt der Migration zu messen, haben wir strukturierte Abfragen (mithilfe von Token) an unseren ELK-Stack (Elasticsearch, Logstash und Kibana) gesendet. Von dort aus konnten wir detaillierte Dashboards erstellen, indem wir die Anzahl der erfolgreich übertragenen Artikel, die Anzahl der Abstürze und den Gesamtfortschritt verfolgten. Außerdem wurden alle Indikatoren auf dem großen Bildschirm angezeigt, sodass das gesamte Team die Details sehen konnte.
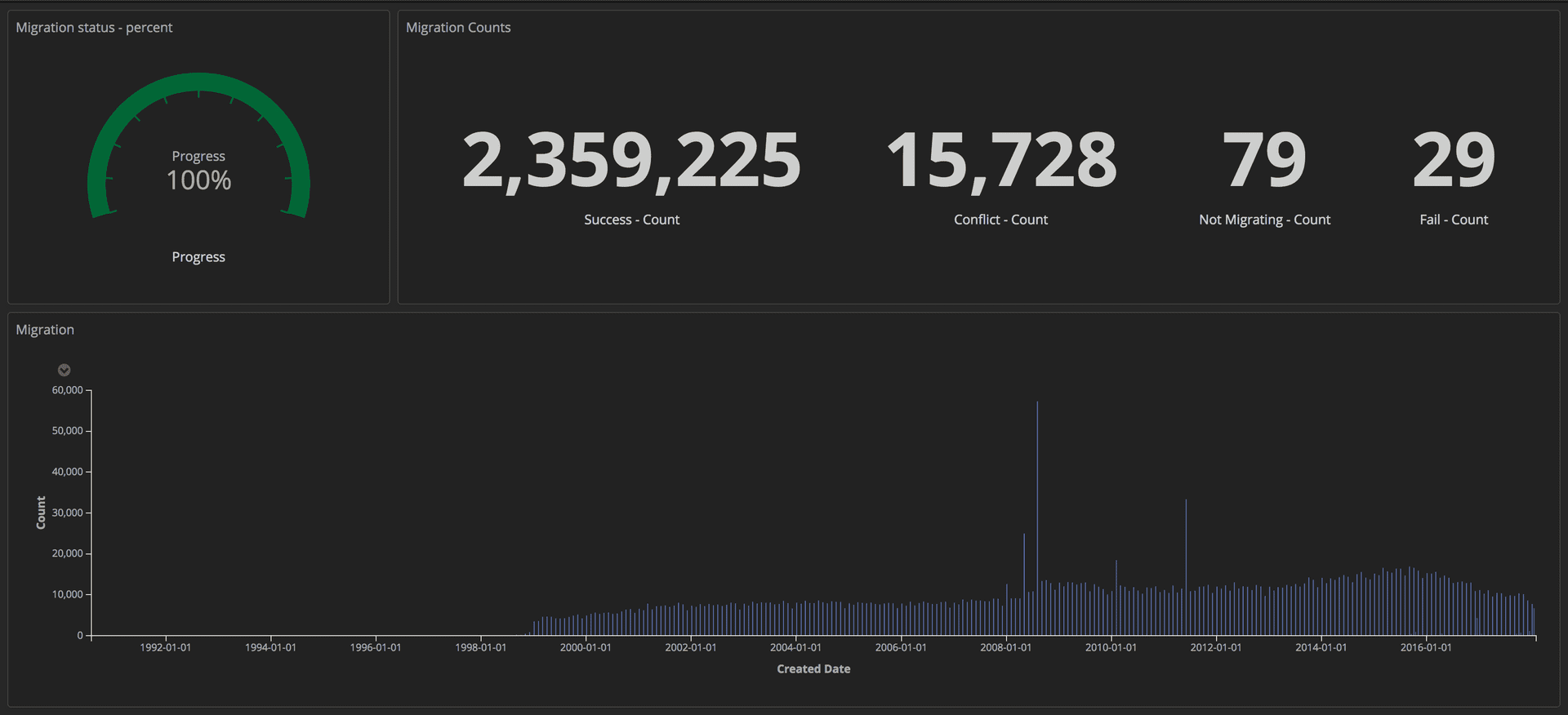 Dashboard mit dem Fortschritt der Migration: Editorial Tools / Guardian
Dashboard mit dem Fortschritt der Migration: Editorial Tools / GuardianNach Abschluss der Migration haben wir in Postgres und Mongo nach Übereinstimmungen für jedes Dokument gesucht.
Dritter Teil: Proxies und Start auf Prod
ProxiesNachdem die neue API, die auf Postgres ausgeführt wird, gestartet wurde, mussten wir sie mit realen Verkehrs- und Datenzugriffsmustern testen, um ihre Zuverlässigkeit und Stabilität sicherzustellen. Es gab zwei Möglichkeiten, dies zu tun: Aktualisieren Sie jeden Client, der auf die Mongo-API zugreift, so, dass er auf beide APIs zugreift. oder führen Sie einen Proxy aus, der dies für uns erledigt. Wir haben Proxies auf Scala mit
Akka Streams geschrieben .
Der Proxy war ganz einfach:
- Empfangen Sie Datenverkehr vom Load Balancer.
- Leiten Sie den Datenverkehr zur Haupt-API um und umgekehrt.
- Leiten Sie denselben Datenverkehr asynchron an eine zusätzliche API weiter.
- Berechnen Sie die Abweichungen zwischen den beiden Antworten und zeichnen Sie sie in einem Protokoll auf.
Anfänglich verzeichnete der Proxy viele Diskrepanzen, einschließlich einiger schwer zu findender, aber wichtiger Verhaltensunterschiede in den beiden APIs, die behoben werden mussten.
Strukturierte ProtokollierungBei Guardian protokollieren wir mit dem
ELK- Stack (Elasticsearch, Logstash und Kibana). Die Verwendung von Kibana gab uns die Möglichkeit, das Magazin auf die für uns bequemste Weise zu visualisieren. Kibana verwendet
die Abfragesyntax von Lucene , die ziemlich einfach zu erlernen ist. Wir stellten jedoch schnell fest, dass es unmöglich war, die Journaleinträge im aktuellen Setup zu filtern oder zu gruppieren. Beispielsweise konnten wir diejenigen nicht herausfiltern, die aufgrund von GET-Anforderungen gesendet wurden.
Wir haben uns entschieden, strukturiertere Daten an Kibana zu senden, nicht nur Nachrichten. Ein Protokolleintrag enthält mehrere Felder, z. B. den Zeitstempel und den Namen des Stapels oder der Anwendung, die die Anforderung gesendet hat. Das Hinzufügen neuer Felder ist sehr einfach. Diese strukturierten Felder werden als Marker bezeichnet und können mithilfe der
Logstash-Logback-Encoder- Bibliothek implementiert werden. Für jede Anforderung haben wir nützliche Informationen (z. B. Route, Methode, Statuscode) extrahiert und eine Karte mit zusätzlichen Informationen erstellt, die für das Protokoll erforderlich sind. Hier ist ein Beispiel:
import akka.http.scaladsl.model.HttpRequest import ch.qos.logback.classic.{Logger => LogbackLogger} import net.logstash.logback.marker.Markers import org.slf4j.{LoggerFactory, Logger => SLFLogger} import scala.collection.JavaConverters._ object Logging { val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger] private def setMarkers(request: HttpRequest) = { val markers = Map( "path" -> request.uri.path.toString(), "method" -> request.method.value ) Markers.appendEntries(markers.asJava) } def infoWithMarkers(message: String, akkaRequest: HttpRequest) = rootLogger.info(setMarkers(akkaRequest), message) }
Zusätzliche Felder in unseren Protokollen ermöglichten es uns, informative Dashboards zu erstellen und den Diskrepanzen mehr Kontext hinzuzufügen, wodurch wir einige kleinere Inkonsistenzen zwischen den beiden APIs identifizieren konnten.
Verkehrsreplikation und Proxy-RefactoringNach dem Übertragen des Inhalts in die CODE-Datenbank haben wir eine fast exakte Kopie der PROD-Datenbank erhalten. Der Hauptunterschied war, dass CODE keinen Verkehr hatte. Um den tatsächlichen Datenverkehr in die CODE-Umgebung zu replizieren, haben wir das Open-Source-Tool
GoReplay (im
Folgenden als gor bezeichnet) verwendet. Es ist sehr einfach zu installieren und flexibel an Ihre Anforderungen anzupassen.
Da der gesamte Datenverkehr zu unseren APIs zuerst an Proxys ging, war es sinnvoll, gor auf Proxy-Containern zu installieren. Im Folgenden erfahren Sie, wie Sie gor in Ihren Container laden und wie Sie den Datenverkehr auf Port 80 überwachen und an einen anderen Server senden.
wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz tar -xzf gor_0.16.0_x64.tar.gz gor sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
Für eine Weile funktionierte alles einwandfrei, aber sehr bald gab es eine Fehlfunktion, als der Proxy für einige Minuten nicht mehr verfügbar war. In der Analyse haben wir festgestellt, dass alle drei Proxy-Container regelmäßig gleichzeitig hängen. Zuerst dachten wir, der Proxy stürze ab, weil gor zu viele Ressourcen verwendet. Bei einer weiteren Analyse der AWS-Konsole stellten wir fest, dass Proxy-Container regelmäßig, jedoch nicht gleichzeitig hingen.
Bevor wir uns näher mit dem Problem befassten, versuchten wir, einen Weg zu finden, um gor auszuführen, diesmal jedoch ohne zusätzliche Belastung des Proxys. Die Lösung kam von unserem sekundären Stack für Composer. Dieser Stapel wird nur im Notfall verwendet und von unserem
Arbeitsüberwachungstool ständig getestet. Diesmal funktionierte die Wiedergabe des Datenverkehrs von diesem Stapel zu CODE mit doppelter Geschwindigkeit problemlos.
Neue Erkenntnisse haben viele Fragen aufgeworfen. Der Proxy wurde als temporäres Tool erstellt, sodass er möglicherweise nicht so sorgfältig entwickelt wurde wie andere Anwendungen. Darüber hinaus wurde es mit
Akka Http erstellt , mit dem keiner unserer Mitarbeiter vertraut war. Der Code war chaotisch und voller schneller Lösungen. Wir haben beschlossen, viele Umgestaltungen vorzunehmen, um die Lesbarkeit zu verbessern. Dieses Mal haben wir For-Generatoren anstelle der wachsenden verschachtelten Logik verwendet, die wir zuvor verwendet haben. Und noch mehr Protokollierungsmarker hinzugefügt.
Wir hofften, dass wir das Einfrieren der Proxy-Container verhindern können, wenn wir uns eingehend mit den Ereignissen im System befassen und die Logik des Betriebs vereinfachen. Das hat aber nicht funktioniert. Nachdem wir zwei Wochen lang versucht hatten, den Proxy zuverlässiger zu machen, fühlten wir uns gefangen. Es war notwendig, eine Entscheidung zu treffen. Wir haben uns entschlossen, das Risiko einzugehen und den Proxy so zu belassen, wie er ist, da es besser ist, Zeit für die Migration selbst zu verwenden, als zu versuchen, eine Software zu reparieren, die in einem Monat unnötig wird. Wir haben diese Lösung mit zwei weiteren Fehlern bezahlt - jeweils fast zwei Minuten -, aber es musste getan werden.
Schneller Vorlauf bis März 2018, als wir die Migration zu CODE bereits abgeschlossen haben, ohne die API-Leistung oder die Client-Erfahrung in CMS zu beeinträchtigen. Jetzt könnten wir darüber nachdenken, Proxies von CODE abzuschreiben.
Der erste Schritt bestand darin, die Prioritäten der API so zu ändern, dass der Proxy zuerst mit Postgres interagierte. Wie oben erwähnt, wurde dies durch eine Änderung der Einstellungen entschieden. Es gab jedoch eine Schwierigkeit.
Composer sendet nach dem Aktualisieren des Dokuments Nachrichten an den Kinesis-Stream. Zum Senden von Nachrichten ist nur eine API erforderlich, um eine Duplizierung zu verhindern. Zu diesem Zweck haben die APIs in der Konfiguration ein Flag: true für die von Mongo unterstützte API und false für die unterstützten Postgres. Es reichte nicht aus, den Proxy so zu ändern, dass er zuerst mit Postgres interagierte, da die Nachricht erst an den Kinesis-Stream gesendet wurde, wenn die Anfrage Mongo erreichte. Es ist zu lange her.
Um dieses Problem zu lösen, haben wir HTTP-Endpunkte erstellt, um die Konfiguration aller Instanzen des Load Balancers im laufenden Betrieb sofort zu ändern. Dadurch konnten wir die Haupt-API sehr schnell verbinden, ohne die Konfigurationsdatei bearbeiten und erneut bereitstellen zu müssen. Darüber hinaus kann dies automatisiert werden, wodurch die menschliche Interaktion und die Wahrscheinlichkeit von Fehlern verringert werden.
Jetzt wurden alle Anfragen zuerst an Postgres gesendet und API2 interagierte mit Kinesis. Ersetzungen können durch Konfigurationsänderungen und erneute Bereitstellung dauerhaft vorgenommen werden.
Der nächste Schritt bestand darin, den Proxy vollständig zu entfernen und die Clients zu zwingen, ausschließlich auf die Postgres-API zuzugreifen. Da wir viele Kunden haben, war es nicht möglich, jeden von ihnen einzeln zu aktualisieren. Daher haben wir diese Aufgabe auf die DNS-Ebene angehoben. Das heißt, wir haben einen CNAME in DNS erstellt, der zuerst auf den ELB-Proxy verweist und dann auf die ELB-API verweist. Dadurch konnte eine einzelne Änderung vorgenommen werden, anstatt jeden einzelnen API-Client zu aktualisieren.
Es ist Zeit, den PROD zu bewegen. Obwohl es ein wenig beängstigend war, ist dies das Hauptarbeitsumfeld. Der Vorgang war relativ einfach, da alles durch Ändern der Einstellungen entschieden wurde. Durch Hinzufügen einer Stufenmarkierung zu den Protokollen wurde es außerdem möglich, zuvor erstellte Dashboards durch einfaches Aktualisieren des Kibana-Filters neu zu profilieren.
Proxys und Mongo DB deaktivierenNach 10 Monaten und 2,4 Millionen migrierten Artikeln konnten wir endlich die gesamte Infrastruktur im Zusammenhang mit Mongo deaktivieren. Aber zuerst mussten wir das tun, worauf wir alle gewartet hatten: den Proxy töten.
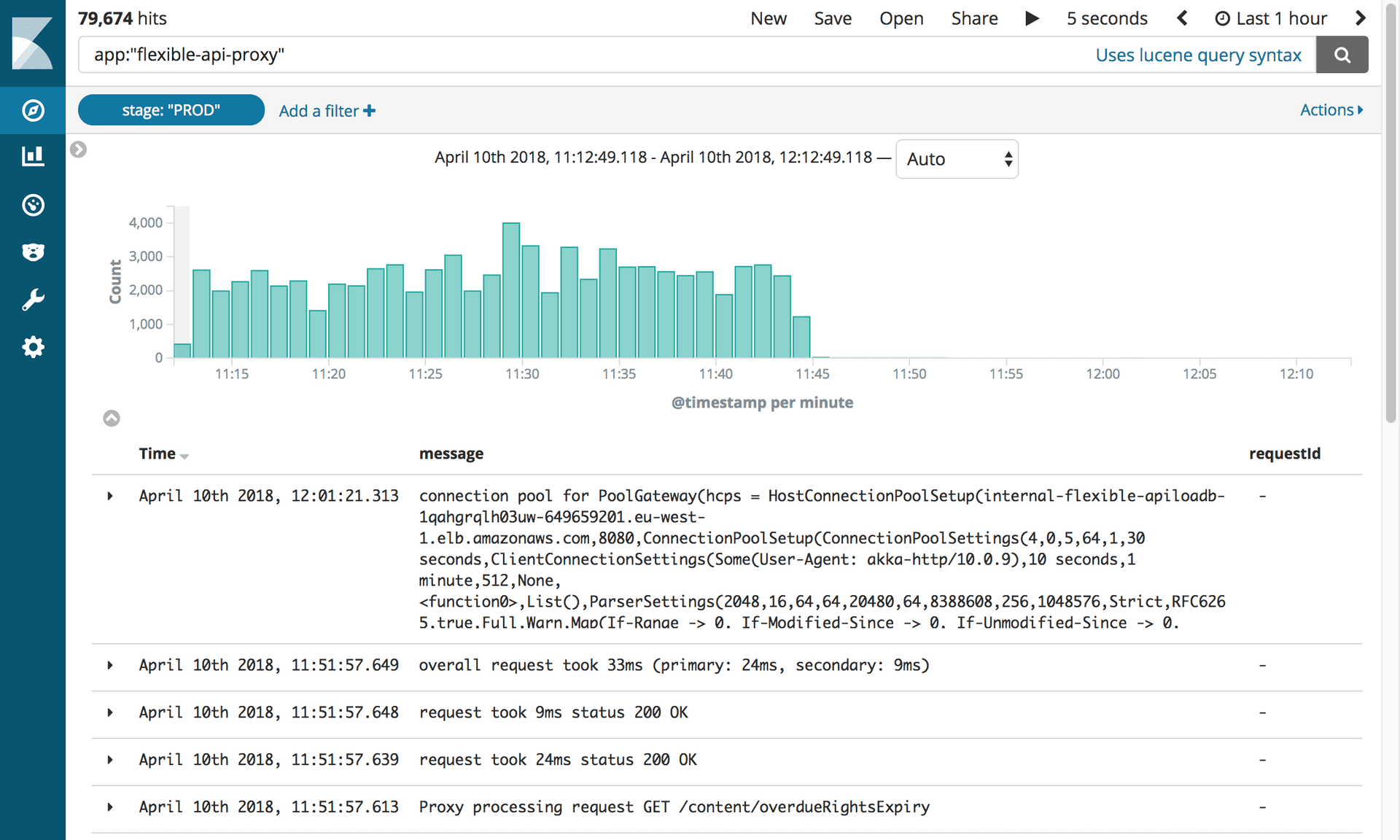 Protokolle zum Deaktivieren des flexiblen API-Proxys. Foto: Editorial Tools / Guardian
Protokolle zum Deaktivieren des flexiblen API-Proxys. Foto: Editorial Tools / GuardianDiese kleine Software verursachte uns so viele Probleme, dass wir uns danach sehnten, sie bald zu trennen! Wir mussten lediglich den CNAME-Datensatz aktualisieren, um direkt auf den APIV2-Load-Balancer zu verweisen.
Das gesamte Team versammelte sich um einen Computer. Es war nur ein Tastendruck erforderlich. Alle hielten den Atem an! Völlige Stille ... Klick! Die Arbeit ist erledigt. Und nichts flog! Wir alle atmeten freudig aus.
Das Entfernen der alten Mongo DB-API war jedoch mit einem weiteren Test verbunden. Wir wollten unbedingt den alten Code entfernen und stellten fest, dass unsere Integrationstests nie an die Verwendung der neuen API angepasst wurden. Alles wurde schnell rot. Glücklicherweise waren die meisten Probleme mit der Konfiguration verbunden und wir konnten sie leicht beheben. Es gab mehrere Probleme mit PostgreSQL-Abfragen, die von den Tests erfasst wurden. Als wir darüber nachdachten, was getan werden könnte, um diesen Fehler zu vermeiden, haben wir eine Lektion gelernt: Wenn Sie eine große Aufgabe starten, versöhnen Sie sich damit, dass es Fehler geben wird.
Danach funktionierte alles reibungslos. Wir haben alle Instanzen von Mongo von OpsManager getrennt und sie dann getrennt. Das einzige was noch zu tun war, war zu feiern. Und schlafen.