Ich bin Lead DevOps Engineer bei Miro (ex-RealtimeBoard). Ich werde berichten, wie unser DevOps-Team das Problem der täglichen Server-Releases einer monolithischen Stateful-Anwendung gelöst und sie automatisch, für Benutzer unsichtbar und für ihre eigenen Entwickler praktisch gemacht hat.
Unsere Infrastruktur
Unser Entwicklungsteam besteht aus 60 Personen, die in Scrum-Teams aufgeteilt sind, darunter auch das DevOps-Team. Die meisten Scrum-Befehle unterstützen die aktuelle Funktionalität des Produkts und bieten neue Funktionen. Die Aufgabe von DevOps besteht darin, eine Infrastruktur zu erstellen und zu warten, mit der die Anwendung schnell und zuverlässig arbeitet und die es den Teams ermöglicht, Benutzern schnell neue Funktionen bereitzustellen.

Unsere Anwendung ist ein endloses Online-Board. Es besteht aus drei Ebenen: einer Site, einem Client und einem Server in Java, einer monolithischen Stateful-Anwendung. Die Anwendung unterhält eine konstante Web-Socket-Verbindung mit Clients, und jeder Server speichert einen Cache mit offenen Karten.
Die gesamte Infrastruktur - mehr als 70 Server - befindet sich in Amazon: mehr als 30 Server mit unserer Java-Anwendung, Webservern, Datenbankservern, Brokern und vielem mehr. Mit dem Wachstum der Funktionalität muss all dies regelmäßig aktualisiert werden, ohne die Arbeit der Benutzer zu stören.
Das Aktualisieren der Site und des Clients ist einfach: Wir ersetzen die alte Version durch eine neue und beim nächsten Zugriff des Benutzers auf eine neue Site und einen neuen Client. Wenn wir dies jedoch tun, wenn der Server freigegeben wird, kommt es zu Ausfallzeiten. Für uns ist dies nicht akzeptabel, da der Hauptwert unseres Produkts die gemeinsame Arbeit der Benutzer in Echtzeit ist.
Wie unser CI / CD-Prozess aussieht
Der CI / CD-Prozess bei uns ist Git Commit, Git Push, dann automatische Montage, automatisches Testen, Bereitstellen, Freigeben und Überwachen.
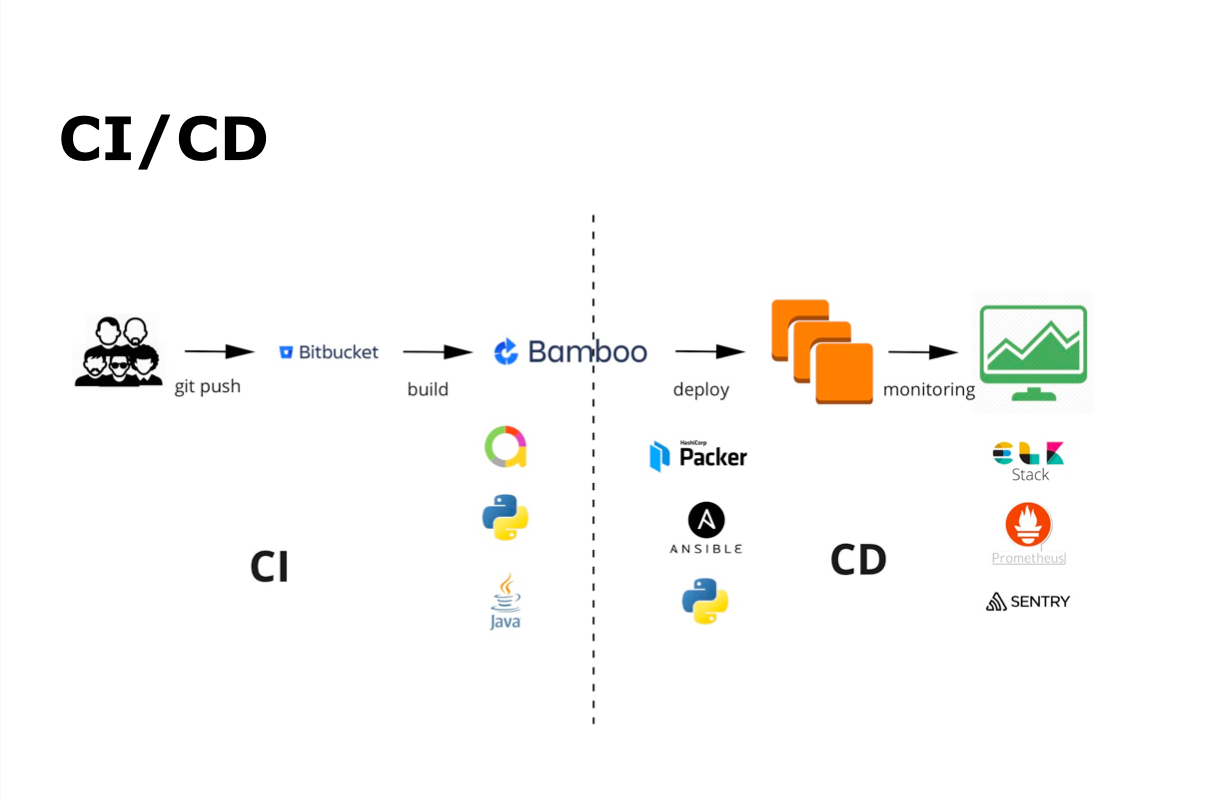
Für die kontinuierliche Integration verwenden wir Bamboo und Bitbucket. Für automatische Tests - Java und Python sowie Allure - zur Anzeige der Ergebnisse automatischer Tests. Für die kontinuierliche Lieferung - Packer, Ansible und Python. Die gesamte Überwachung erfolgt mit ELK Stack, Prometheus und Sentry.
Entwickler schreiben Code und fügen ihn dem Repository hinzu. Anschließend werden die automatische Assemblierung und das automatische Testen gestartet. Gleichzeitig versammelt sich das Team mit anderen Entwicklern und führt eine Codeüberprüfung durch. Wenn alle erforderlichen Prozesse, einschließlich Autotests, abgeschlossen sind, hält das Team den Build im Hauptzweig, und der Build des Hauptzweigs beginnt und wird zum automatischen Testen gesendet. Der gesamte Prozess wird vom Team selbst getestet und ausgeführt.
AMI-Bild
Parallel zum Erstellen und Testen von Builds wird der Build des AMI-Images für Amazon gestartet. Dazu verwenden wir Packer von HashiCorp, ein großartiges OpenSource-Tool, mit dem Sie ein Image einer virtuellen Maschine erstellen können. Alle Parameter werden mit einer Reihe von Konfigurationsschlüsseln an JSON übergeben. Der Hauptparameter sind Builder, die angeben, für welchen Anbieter wir das Image erstellen (in unserem Fall für Amazon).
"builders": [{ "type": "amazon-ebs", "access_key": "{{user `aws_access_key`}}", "secret_key": "{{user `aws_secret_key`}}", "region": "{{user `aws_region`}}", "vpc_id": "{{user `aws_vpc`}}", "subnet_id": "{{user `aws_subnet`}}", "tags": { "releaseVersion": "{{user `release_version`}}" }, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ami_name": "packer-board-ami_{{isotime \"2006-01-02_15-04\"}}" }],
Es ist wichtig, dass wir nicht nur ein Image einer virtuellen Maschine erstellen, sondern es im Voraus mit Ansible konfigurieren: Installieren Sie die erforderlichen Pakete und nehmen Sie die Konfigurationseinstellungen vor, um eine Java-Anwendung auszuführen.
"provisioners": [{ "type": "ansible", "playbook_file": "./playbook.yml", "user": "ubuntu", "host_alias": "default", "extra_arguments": ["--extra_vars=vars"], "ansible_env_vars": ["ANSIBLE_HOST_KEY_CHECKING=False", "ANSIBLE_NOCOLOR=True"] }]
Ansible-Rollen
Früher haben wir das übliche Ansible-Spielbuch verwendet, aber dies führte zu viel sich wiederholendem Code, der schwer auf dem neuesten Stand zu halten war. Wir haben etwas in einem Spielbuch geändert, vergessen, es in einem anderen zu tun, und sind infolgedessen auf Probleme gestoßen. Also haben wir angefangen, Ansible-Rollen zu verwenden. Wir haben sie so vielseitig wie möglich gestaltet, damit wir sie in verschiedenen Teilen des Projekts wiederverwenden und den Code nicht in großen, sich wiederholenden Teilen überladen können. Beispielsweise verwenden wir die Überwachungsrolle für alle Servertypen.
- name: Install all board dependencies hosts: all user: ubuntu become: yes roles: - java - nginx - board-application - ssl-certificates - monitoring
Von Seiten der Scrum-Teams sieht dieser Prozess so einfach wie möglich aus: Das Team erhält in Slack Benachrichtigungen, dass der Build und das AMI-Image zusammengestellt wurden.
Vorabversionen
Wir haben Vorabversionen eingeführt, um den Benutzern Produktänderungen so schnell wie möglich bereitzustellen. Tatsächlich handelt es sich hierbei um kanarische Versionen, mit denen Sie neue Funktionen bei einem kleinen Prozentsatz der Benutzer sicher testen können.
Warum heißen Veröffentlichungen Kanarienvogel? Zuvor nahmen Bergleute, als sie in die Mine hinabstiegen, einen Kanarienvogel mit. Wenn sich Gas in der Mine befand, starb der Kanarienvogel und die Bergleute stiegen schnell an die Oberfläche. So ist es auch bei uns: Wenn mit dem Server etwas schief geht, ist die Version noch nicht fertig und wir können schnell einen Rollback durchführen, und die meisten Benutzer werden nichts bemerken.
Wie die kanarische Freilassung beginnt:- Das Entwicklungsteam von Bamboo klickt auf eine Schaltfläche -> Es wird eine Python-Anwendung aufgerufen, die die Vorabversion startet.
- Es erstellt eine neue Instanz in Amazon aus einem vorbereiteten AMI-Image mit einer neuen Version der Anwendung.
- Instanz wird zu den erforderlichen Zielgruppen und Load Balancern hinzugefügt.
- Mit Ansible wird für jede Instanz eine individuelle Konfiguration konfiguriert.
- Benutzer arbeiten mit der neuen Version der Java-Anwendung.
Auf der Seite der Scrum-Befehle sieht der Startvorgang vor der Veröffentlichung wieder so einfach wie möglich aus: Das Team erhält in Slack Benachrichtigungen, dass der Prozess gestartet wurde, und nach 7 Minuten ist der neue Server bereits in Betrieb. Darüber hinaus sendet die Anwendung das gesamte Änderungsprotokoll der Änderungen in der Version an Slack.
Damit diese Barriere für die Schutz- und Zuverlässigkeitsprüfung funktioniert, überwachen die Scrum-Teams neue Fehler in Sentry. Dies ist eine Open Source-Anwendung zur Fehlerverfolgung in Echtzeit. Sentry lässt sich nahtlos in Java integrieren und verfügt über Konnektoren mit logback und log2j. Wenn die Anwendung gestartet wird, übertragen wir die Version, auf der sie ausgeführt wird, an Sentry. Wenn ein Fehler auftritt, sehen wir, in welcher Version der Anwendung sie aufgetreten ist. Dies hilft Scrum-Teams, schnell auf Fehler zu reagieren und diese schnell zu beheben.
Die Vorabversion sollte mindestens 4 Stunden lang funktionieren. Während dieser Zeit überwacht das Team seine Arbeit und entscheidet, ob die Version für alle Benutzer freigegeben wird.
Mehrere Teams können gleichzeitig ihre Veröffentlichungen veröffentlichen . Dazu vereinbaren sie untereinander, was in die Vorabversion gelangt und wer für die endgültige Veröffentlichung verantwortlich ist. Danach kombinieren die Teams entweder alle Änderungen in einer Vorabversion oder starten mehrere Vorabversionen gleichzeitig. Wenn alle Vorabversionen korrekt sind, werden sie am nächsten Tag als eine Veröffentlichung veröffentlicht.
Veröffentlichungen
Wir machen eine tägliche Veröffentlichung:
- Wir führen neue Server ein.
- Wir überwachen die Benutzeraktivität auf neuen Servern mit Prometheus.
- Enger Zugriff für neue Benutzer auf alte Server.
- Wir übertragen Benutzer von alten auf neue Server.
- Schalten Sie den alten Server aus.
Alles wird mit den Anwendungen Bamboo und Python erstellt. Die Anwendung überprüft die Anzahl der ausgeführten Server und bereitet den Start derselben Anzahl neuer Server vor. Wenn nicht genügend Server vorhanden sind, werden diese aus dem AMI-Image erstellt. Auf ihnen wird eine neue Version bereitgestellt, eine Java-Anwendung gestartet und die Server in Betrieb genommen.
Bei der Überwachung überprüft die Python-Anwendung mithilfe der Prometheus-API die Anzahl der offenen Karten auf neuen Servern. Wenn es versteht, dass alles richtig funktioniert, schließt es den Zugriff auf die alten Server und überträgt Benutzer auf neue.
import requests PROMETHEUS_URL = 'https://prometheus' def get_spaces_count(): boards = {} try: params = { 'query': 'rtb_spaces_count{instance=~"board.*"}' } response = requests.get(PROMETHEUS_URL, params=params) for metric in response.json()['data']['result']: boards[metric['metric']['instance']] = metric['value'][1] except requests.exceptions.RequestException as e: print('requests.exceptions.RequestException: {}'.format(e)) finally: return boards
Der Prozess der Benutzerübertragung zwischen Servern wird in Grafana angezeigt. In der linken Hälfte des Diagramms werden Server angezeigt, die auf der alten Version ausgeführt werden, in der rechten - auf der neuen. Der Schnittpunkt von Diagrammen ist der Moment der Benutzerübertragung.

Das Team überwacht die Veröffentlichung von Slack. Nach der Veröffentlichung wird das gesamte Änderungsprotokoll in einem separaten Kanal in Slack veröffentlicht, und in Jira werden alle mit dieser Version verbundenen Aufgaben automatisch geschlossen.
Was ist Benutzermigration?
Wir speichern den Status des Whiteboards, auf dem Benutzer arbeiten, im Anwendungsspeicher und speichern ständig alle Änderungen an der Datenbank. Um die Karte auf der Ebene der Clusterinteraktion zu übertragen, laden wir sie in den Speicher des neuen Servers und senden dem Client einen Befehl zum erneuten Verbinden. Zu diesem Zeitpunkt trennt sich der Client vom alten Server und stellt eine Verbindung zum neuen Server her. Nach einigen Sekunden sehen Benutzer die Beschriftung - Verbindung wiederhergestellt. Sie arbeiten jedoch weiter und bemerken keine Unannehmlichkeiten.
Was wir gelernt haben, als wir die Bereitstellung unsichtbar gemacht haben
Was haben wir nach einem Dutzend Iterationen erreicht:
- Das Scrum-Team überprüft seinen Code selbst.
- Das Scrum-Team entscheidet, wann die Vorabversion gestartet und einige Änderungen an neue Benutzer übertragen werden sollen.
- Das Scrum-Team entscheidet, ob die Veröffentlichung für alle Benutzer bereit ist.
- Benutzer arbeiten weiter und bemerken nichts.
Dies war nicht sofort möglich, wir traten viele Male auf denselben Rechen und füllten viele Zapfen. Ich möchte die Lektionen teilen, die wir erhalten haben.
Zuerst der manuelle Prozess und erst dann seine Automatisierung. Die ersten Schritte müssen nicht tiefer in die Automatisierung gehen, da Sie automatisieren können, was am Ende nicht nützlich ist.
Ansible ist gut, aber Ansible-Rollen sind besser. Wir haben unsere Rollen so universell wie möglich gestaltet: Wir haben sich wiederholenden Code entfernt, sodass sie nur die Funktionen enthalten, die sie enthalten sollten. Auf diese Weise können Sie erheblich Zeit sparen, indem Sie Rollen wiederverwenden, über die wir bereits mehr als 50 verfügen.
Verwenden Sie den Code in Python erneut und teilen Sie ihn in separate Bibliotheken und Module auf. Auf diese Weise können Sie in komplexen Projekten navigieren und schnell neue Personen in diese eintauchen.
Nächste Schritte
Der unsichtbare Bereitstellungsprozess ist noch nicht abgeschlossen. Hier sind einige der folgenden Schritte:
- Ermöglichen Sie Teams, nicht nur Vorabversionen, sondern alle Veröffentlichungen abzuschließen.
- Führen Sie bei Fehlern automatische Rollbacks durch. Beispielsweise sollte eine Vorabversion automatisch zurückgesetzt werden, wenn in Sentry kritische Fehler festgestellt werden.
- Automatisieren Sie die Freigabe vollständig, wenn keine Fehler vorliegen. Wenn die Vorabversion keine Fehler enthielt, bedeutet dies, dass sie automatisch weiter eingeführt werden kann.
- Fügen Sie eine automatische Code-Überprüfung auf potenzielle Sicherheitsfehler hinzu.