Die Größe der Transistormerkmale nimmt trotz ständiger Gerüchte über den Tod von Moores Gesetz und der Tatsache ab, dass die Industrie wirklich nahe an den physikalischen Grenzen der Miniaturisierung liegt (oder sie sogar mit einigen cleveren Technologietricks durchlaufen hat). Das Gesetz von Moore hat jedoch den Appetit der Benutzer auf Innovation geweckt, der für die Branche schwer zu handhaben ist. Aus diesem Grund skalieren moderne mikroelektronische Produkte nicht nur die Funktionsgröße, sondern verwenden auch eine Reihe anderer Funktionen, die oft sogar komplizierter sind als die Chipskalierung.
Haftungsausschluss: Dieser Artikel ist eine leicht aktualisierte Übersetzung meines eigenen Artikels, der auf dieser Website hier veröffentlicht wurde . Wenn Sie Russisch sprechen, sollten Sie das Original überprüfen. Wenn Sie Englisch sprechen, ist es erwähnenswert, dass Englisch nicht meine Muttersprache ist. Daher bin ich für das Feedback sehr dankbar, wenn Sie im Text etwas Seltsames finden. Ich habe absichtlich "mikroelektronisches Produkt" statt nur "Chip" gesagt, da es in diesem Artikel um die System-in-Package-Technologie (SiP) geht, mit der viele Chips in einem einzigen Paket verbunden werden können.
Der Begriff System in Package ist weitaus weniger beliebt als der Begriff System on Chip (SoC), der routinemäßig von jedem Halbleiterunternehmen verwendet wird, und das aus gutem Grund, da fast jeder moderne Chip irgendwie ein System mit vielen miteinander verschmolzenen Funktionen ist. Die Zeiten der reichlich vorhandenen Chipsätze sind lange vorbei, da die Vorteile von SoC klar sind: weniger Gehäuse auf der Leiterplatte, weniger Fläche (lesen Sie „billiger“), weniger parasitäre Kapazitäten und Induktivitäten (lesen Sie „schneller“), einfacher zu implementieren und zu verwenden, Es ist billiger, einen einzelnen komplexen Chip zu entwerfen und herzustellen als eine Reihe spezifischerer.
Aber nichts ist kostenlos, und SoCs haben offensichtlich einige Nachteile.
Erstens besteht beim Versuch, alle Teile zusammenzufügen, die Gefahr, dass ein Chip zu groß wird, um in ein Paket oder, noch schlimmer, in das Fenster des Fotolithografen zu passen. Die letztere Einschränkung kann übertroffen werden, ist jedoch fast immer unangemessen teuer (wobei Fotokameras der bemerkenswerteste Ausschluss sind).
Hier ist der Kodak Kaf39000 Bildsensor mit einer Fläche von 2000 Quadratmillimetern und Maskenstichen. Der größte nicht genähte Chip ist NVIDIA Volta mit 815 Quadratmillimetern, was nur 20 Millimeter weniger ist als die größtmögliche Größe.
Zweitens, je größer der Chip ist, desto geringer ist die Ausbeute, da jeder einzelne Staubfleck Ihren Tag ruinieren kann. Und weißt du was? Niedrigere Rendite bedeutet höheren Preis.
Drittens, wenn Ihr System heterogene Komponenten wie Prozessorkern, DRAM und HF-Modul enthält, kann die Kombination dieser Komponenten technologisch unmöglich oder wiederum unangemessen teuer sein. Zum Beispiel erfordern DRAM-Zellen spezifische Kondensatoren mit hoher Dichte, und HF-Schaltungen auf Siliziumbasis können nur schlechter sein als ihre Gegenstücke, die auf verschiedenen A3B5-Materialien (GaAs und dergleichen) hergestellt werden. Selbst eine einfache Kombination aus digitaler Verarbeitung und analoger Signalkonditionierung auf demselben Chip führt zu erheblichen Rauschproblemen. Und ich sage nicht einmal über die Tatsache, dass 180-nm-ADC leicht zwei Größenordnungen billiger wäre als das Hinzufügen seines 14-nm-Analogons zum 14-nm-MCU-Chip.
Die Kombination aller oben genannten Faktoren führte zu einer Trendwende von „Wir packen alles in den Single-Chip“ zu einem pragmatischeren Ansatz - und zur schnellen Entwicklung verschiedener Verpackungstechnologien.
Leistung und Ertrag
Das erste Beispiel, das in den Sinn kommt, ist die jüngste Wiedergeburt von AMD, die weithin als Ergebnis ihres Erfolgs mit Multi-Chip-Systemen anerkannt ist (auch unterstützt durch Intels Probleme mit der Ausbeute bei enormen 10-nm-Chips).
Oben abgebildet ist Intels 28-Core-Xeon. Die Chipfläche dieser Prozessoren kann verrückte 456 Quadratmillimeter erreichen, während die maximale Größe von AMD-Chips für acht Kerne nur 200 Quadratmillimeter beträgt. Ihre vielen Kernprodukte sind eigentlich zweischichtige Leiterplatten mit bis zu vier Würfeln im Gehäuse.
Diese Abbildung zeigt die Leiterplatte in EPYC- und Threadripper-Prozessoren. Im Falle eines 16-Kern-Threadrippers haben wir noch vier Chips, aber die Hälfte der Kerne ist deaktiviert. Warum nicht stattdessen einfach zwei Würfel verwenden? Oder kleinere Vierkernwürfel verwenden?
Erstens ist es offensichtlich viel billiger, einen einzigen Chip für alle Zwecke zu haben, als eine Familie zu entwerfen.
Zweitens gilt das Gleiche für Leiterplatten, Gehäuse usw. Es ist einfacher, übermäßige Teile zu deaktivieren, als eine Produktfamilie zu entwerfen.
Drittens und wahrscheinlich am wichtigsten, Ausbeute von 200 Quadratmetern. Der Würfel ist immer noch weit von 100% entfernt, und das Deaktivieren einiger bereits nicht funktionierender Kerne ist ein guter Weg, um diese Defektwürfel zu verwenden. Intel macht dasselbe mit seinen Defektwürfeln, aber ihre Ertragsprobleme sind aufgrund der größeren Chipfläche schwerwiegender.
Hier haben wir noch ein interessanteres Beispiel, wieder von AMD. Fidschi ist eine GPU mit integriertem Hochgeschwindigkeitsspeicher im Paket. Weil kürzere Signalleitungen eine höhere Geschwindigkeit und damit eine höhere Leistung ermöglichen. Das Zusammenfügen verschiedener Chips macht den Unterschied zwischen diesem und dem vorherigen Beispiel aus. Es sind übrigens nicht fünf Würfel im Inneren, wie man vielleicht vorgeschlagen hat, sondern zweiundzwanzig! Schauen wir uns den Querschnitt an:
Die obere Ebene ist der GPU-Chip selbst und ein Stapel von vier Speicherwürfeln, die durch sogenannte TSV (Through-Silicon-Vias) verbunden sind - leitende Kontakte, die den gesamten Chip durchbohren.
So sieht TSV aus.
Die TSV-Technologie wurde für den Speicher entwickelt (man kann nicht zu viel Speicher haben, oder?), Aber sie ist jetzt weit verbreitet, teilweise dank der Chipverlegung unter GPU und Speicher.
Die Düse heißt Silicon Interposer und ist ein Ersatz für Leiterplatten aus Silizium mit wenigen (oder vielen) Metallisierungsgraden und mit TSV. Diese Interposer dienen dazu, mehrere Chips über ihnen mit einem Gehäusesubstrat zu verbinden. Die Siliziumtechnologie ermöglicht eine kleinere Strukturgröße als jede Leiterplatte (bis zu einigen Mikrometern), würde jedoch für eine Siliziumtechnologie als sehr einfach und billig angesehen. Kleinere Strukturgrößen und TSV bedeuten eine bessere Leistung als jede Leiterplatte, während die Ausbeute sehr hoch ist. Interposer (neben MEMS) sind ein sehr interessanter und wichtiger Markt, zumal sie auch die Wiederverwendung alter Geräte für 200-, 150- und sogar 100-mm-Wafer ermöglichen.
Können Sie in der obigen Abbildung übrigens einen Fehler erkennen?Xilinx ist ein weiterer Pionier der 3D-Integration. Ihre Produkte ähneln denen von AMD (insbesondere Produkte mit erheblichem Speicher) und aus demselben Grund. FPGA ist ein Markt, in dem eine frühzeitige Umstellung auf einen kleineren Prozessknoten einen enormen Vorteil gegenüber dem Wettbewerb bieten kann. Eine drei- bis vierfache Verringerung der Chipgröße soll in frühen Stadien der Prozessknotenlebensdauer eine zwei- oder dreimalige Ertragssteigerung von 20 Prozent auf mehr als die Hälfte bewirken. Darüber hinaus ist FPGA eine komplexe, aber regelmäßige Struktur, die sich ideal zur Untersuchung eines großen Spektrums von Herstellungsproblemen eignet. Dies macht FPGA-Anbieter zu den besten Frühbucher-Kunden für Fabriken, da eine solche Zusammenarbeit für beide Seiten fruchtbar ist. Fab bekommt einen großartigen Testchip, während der Anbieter in der Lage ist, die Konkurrenz für einige Monate zu übertreffen.

Hier sehen wir ein FPGA von Xilinx. Der obere Chip ist ein FPGA-Teil mit Tonnen von 40-Mikrometer-Kontakten zum Zwischen-Chip, der als Interposer bezeichnet wird. Das niedrigste ist ein Paket, das ein Dutzend eigener Metallschichten aufweist.
Enorme Altera FPGA sterben für den Vergleich. Fünfhundertsechzig Quadratmillimeter! Wenn Sie Prozessingenieure in der Nähe sehen, kümmern Sie sich um sie, es besteht die Gefahr eines Herzschlags.
Intel / Altera starren offensichtlich nicht nur auf die Fortschritte der Wettbewerber. Hier ist ihre frische SiP-Lösung namens EMIB (Embedded Multi-Chip Interconnect Bridge). Ein gutes Beispiel ist Intel Stratix 10 FPGA.
EMIB verbindet einen FPGA-Chip (allerdings nur einen), Speicherwürfel und Peripheriewürfel. Was ist EMIB? Ein typischer Interposer ist viel billiger als ein "rechnerischer" Chip mit der gleichen Größe wie der Interposer, der einen viel größeren Prozessknoten verwendet. Interposer ist jedoch immer noch enorm und daher ziemlich teuer. Kann man es kleiner machen?
Intels Antwort lautet "Ja, wir können". Die Idee hinter EMIB ist es, einige kleine Interposer anstelle eines einzigen großen zu verwenden und diese in das Paket zu integrieren.
Hier ist eine kleine Galerie von Produkten, die mit Interposern erstellt wurden. Schauen Sie, wie riesig sie sind und wie Xilinx aus Stücken hergestellt wird.
Mehr als nur Leistung
Die folgende Abbildung zeigt den ADC von Analog Devices und ein schematisches Diagramm. Sieht aus wie eine typische Leiterplatte, nur kleiner, oder? Ja, es ist eine Leiterplatte, aber die Verwendung von bloßen Würfeln anstelle von Paketen ermöglicht es, Parasiten und deren Einfluss auf die Leistung zu verringern. Die Tatsache, dass die gesamte Karte in Analog Devices entworfen wurde, bietet auch eine zusätzliche Schutzschicht gegen Systemdesignfehler und führt zu einer besseren Benutzererfahrung.

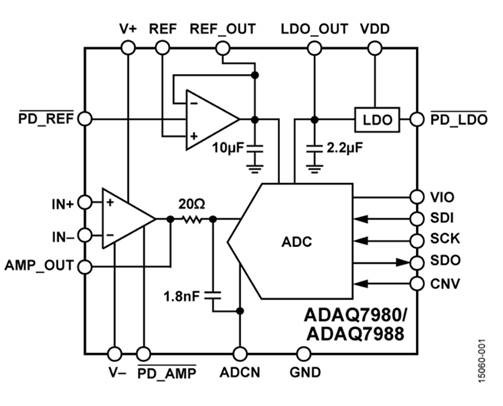
Es gibt auch einen Trick: Sehen Sie zwei übereinander verpackte Würfel? Der höhere integriert aktive Komponenten (Transistoren) des ADC und wahrscheinlich eines dualen Operationsverstärkers, während der untere Chip aus passiven (Widerständen und Kondensatoren) besteht. Das Platzieren von Passiven auf einem separaten Werkzeug ermöglicht es, sie viel größer zu machen und daher die Parametervariation zu verringern, ohne das Hauptwerkzeug größer und teurer zu machen. Das Verringern der Parametervariation ist eine große Sache für analoge Schaltungen und wird hier billig erreicht.
Alles könnte auf einem einzigen Chip ausgeführt werden (und wird häufig ausgeführt, insbesondere auf eingebetteten ADCs), aber ein solcher Chip ist größer (was "teurer" und "mit geringerer Ausbeute" bedeuten könnte), und die Technologie muss alle unterstützen notwendige Optionen (was aufgrund der größeren Anzahl von Masken auch „teurer“ bedeutet). Wenn Sie viele heterogene Blöcke auf demselben Chip kombinieren, müssen Sie sich außerdem mit deren gegenseitigem Einfluss auseinandersetzen. Der Einfluss des digitalen Rauschens auf analoge Teile ist wahrscheinlich der wichtigste, aber nicht der einzige.
Zusätzliche Funktionalität des Pakets
Wie wir bereits gesehen haben, kann die Verpackung das Produkt billiger machen und sogar verbessern. Aber was ist, wenn wir die Verpackung als sinnvollen Bestandteil des Produkts verwenden?
Intel hat in seinen Haswell-Mikroprozessoren den sogenannten FIVR (Fully Integrated Voltage Regulator) implementiert. Das Ziel von FIVR ist es, eine relativ hohe Eingangsspannung (1,8 V) in eine niedrige und in Echtzeit steuerbare Kernversorgungsspannung umzuwandeln. Aktive Komponenten sind auf dem Chip, während passive Komponenten (Kondensatoren und Induktivitäten) in das Prozessorpaket integriert sind.
Die integrierte Induktivität bereitet den Chipdesignern Kopfschmerzen, da sie schlecht, groß und mit geringer Induktivität ist. Es wird in Hochfrequenz-Chips verwendet, aber es gibt fast keine Möglichkeit der Energieübertragung. Intel löste das Problem, indem Dutzende kleiner Induktoren in das Prozessorpaket integriert wurden. Diese Induktivitäten arbeiten bei 160 MHz ohne ferromagnetische Kerne. Auf diese Weise hat Intel die Lieferanforderungen für sein Gerät erheblich vereinfacht.
Intel verschrottete jedoch letztendlich FIVR und kehrte zu einem traditionelleren Versorgungsansatz für neuere Generationen zurück. Es gab einige Gerüchte, dass FIVR zurück sein kann, aber am Ende waren es nur Gerüchte.
Eine weitere Möglichkeit zur Integration von Passiven in Verpackungen ist LTCC (Niedertemperatur-Cofired Ceramic). Es gibt einige Einschränkungen und Probleme (wie begrenzte Nennwerte und Genauigkeit), aber diese Technologie wird aktiv weiterentwickelt. Das mehrschichtige LTCC-Paket sieht folgendermaßen aus:
Hier sind alle Arten von passiven Komponenten vertreten, auch Metallkühlkörper (ein Paket für Leistungs-HF-ICs). Man kann sagen, dass es sich nicht nur um ein Gehäuse handelt, sondern um eine Mischung aus Gehäuse und Keramikplatine. Diese Dinge sind für HF-Schaltungen sehr beliebt und in kleinen Mengen relativ billig.
Was noch?
Es gibt viele potenzielle Anwendungen für Systeme im Paket, und es ist unmöglich, alle aufzulisten. Es ist auch erwähnenswert, dass sie erheblich billiger sind als neue Prozessknoten, was ihre kommerzielle Attraktivität steigert.
Optoelektronische Systeme sind das letzte Beispiel für diesen Artikel. Die Fähigkeit, optischen Empfänger / Sender (oft auf Verbundhalbleiter aufgebaut) mit Siliziumversorgungs- und Steuerchips zu kombinieren, ist sehr vielversprechend. Das Bild unten zeigt einen Prototyp einer in IMEC entwickelten optischen Verbindung mit 400 Gbit / s (und 1 Tbit / s wird für die Zukunft versprochen).
Es gibt auch unzählige andere Anwendungen wie Interposer mit integrierten Kapillaren zur Wasserkühlung (nicht nur für Spiele und Bergbau, sondern auch für Leistungsschalter und Laser), integriertes MEMS und nur Gott weiß was noch. Und natürlich können wir uns dem allgegenwärtigen Internet der Dinge nicht entziehen, in dem geringe Größe, geringe Verluste und die Fähigkeit, Funk- und Rechenblöcke zusammen zu integrieren, von entscheidender Bedeutung sind.
Das Chip-Paket wird von vielen als der nächste große Schritt in der Mikroelektronik angesehen, und wir werden wahrscheinlich in naher Zukunft viele gute Ideen sehen.