Hallo Habr! Nachdem wir uns nach langen Ferien ausreichend ausgeruht haben, sind wir wieder bereit, Ihnen auf alle verfügbaren Arten Gutes zu tun. Kollegen aus der IT-Abteilung haben immer etwas zu erzählen, und heute teilen wir Ihnen einen Bericht von Alexander Prizov, Yandex.Money-Systemadministrator, vom JavaJam-Meeting mit.
Wie wir einen Feedback-Fluss aufgebaut haben, um Problemversionen mit Graphite und Moira zu erkennen. Wir zeigen Ihnen, wie Sie Metriken zur Anzahl der Fehler in der Anwendung erfassen und analysieren.
- Hallo allerseits, mein Name ist Alexander Prizov, ich arbeite in der Abteilung für Betriebsautomatisierung in Yandex.Money und heute werde ich Ihnen erzählen, wie wir Informationen über unser System sammeln, verarbeiten und analysieren.
Sie haben sich wahrscheinlich gefragt, warum der Bericht The Second Way heißt (der Name des Berichts über die Besprechung ist ed.). Alles ist ganz einfach. Das Herzstück von DevOps ist eine Reihe von Prinzipien, die bedingt in drei Gruppen unterteilt sind.
Der erste Weg ist das Prinzip des Flusses. Der zweite Weg beinhaltet das Prinzip des Feedbacks. Der dritte Weg ist kontinuierliches Lernen und Experimentieren.
In Bezug auf die Entwicklung und den Betrieb von Softwareprodukten bedeutet Feedback in der Regel Telemetrie, die wir über unser System erfassen. Der häufigste Fall ist die Erfassung und Verarbeitung von Metriken.
Warum brauchen wir diese Metriken? Mithilfe von Metriken erhalten wir Feedback vom System und können wissen, in welchem Zustand sich unser System befindet, ob alles gut läuft, wie sich unsere Änderungen auf den Betrieb ausgewirkt haben und ob zur Lösung bestimmter Probleme Eingriffe erforderlich sind.
Welche Metriken sammeln wir?
Wir sammeln Metriken auf drei Ebenen.
Die Geschäftsebene umfasst Indikatoren, die aus Sicht der Geschäftsaufgaben interessant sind. Beispielsweise können wir Antworten auf Fragen erhalten, z. B. wie viele Benutzer wir registriert haben, wie oft sich Benutzer bei unserem System anmelden und wie viele aktive Benutzer unsere mobile Anwendung hat.
Die nächste Ebene ist die Anwendungsebene . Metriken dieser Ebene werden von Entwicklern am häufigsten angezeigt, da diese Indikatoren eine Antwort auf die Frage geben, wie gut unsere Anwendung funktioniert, wie schnell sie Anforderungen verarbeitet und ob es Leistungseinbußen gibt. Dies umfasst die Antwortzeit, die Anzahl der Anforderungen, die Länge der Warteschlange und vieles mehr.
Und schließlich das Niveau der Infrastruktur . Hier ist alles sehr klar. Mithilfe dieser Metriken können wir den Ressourcenverbrauch abschätzen, vorhersagen und Probleme im Zusammenhang mit der Infrastruktur identifizieren.
Kurz gesagt, ich werde beschreiben, wie wir diese Metriken senden, verarbeiten und wo wir sie speichern. Neben der Anwendung haben wir einen Metrikkollektor. In unserem Fall ist dies der Heka-Dienst, der den UDP-Port abhört und erwartet, dass Metriken im StatsD-Format eingegeben werden.
Das Format von StatsD lautet wie folgt:

Das heißt, wir bestimmen den Namen der Metrik, geben den Wert dieser Metrik an, sie ist 1, 26 usw. und geben ihren Typ an. Insgesamt hat StatsD ungefähr vier oder fünf Typen. Wenn Sie plötzlich interessiert sind, können Sie die Beschreibung dieser Typen im Detail sehen.
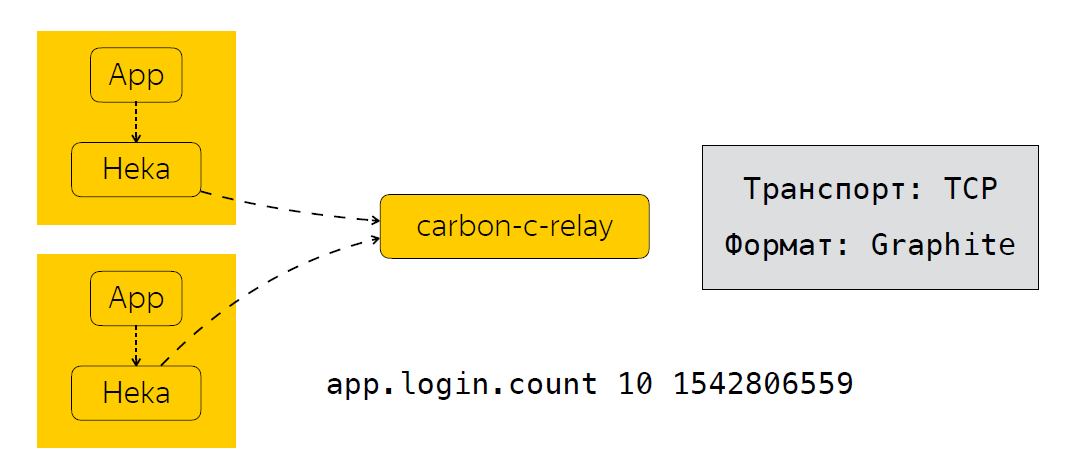
Nachdem die Anwendung die Heka-Daten gesendet hat, werden die Metriken für eine bestimmte Zeit aggregiert. In unserem Fall sind dies 30 Sekunden. Danach sendet Heka Daten an das Carbon-C-Relay, das die Funktion zum Filtern, Weiterleiten und Aktualisieren von Metriken ausführt. Dadurch werden Metriken an unseren Speicher gesendet. Wir verwenden Clickhouse (ja, es wird nicht langsamer ) sowie in Moira. Wenn jemand es nicht weiß, ist dies ein Dienst, mit dem Sie bestimmte Trigger für Metriken konfigurieren können. Ich werde etwas später über Moira sprechen. Also haben wir uns angesehen, welche Metriken wir sammeln, wie wir sie senden und verarbeiten. Der nächste logische Schritt ist die Analyse dieser Metriken.
Wie analysieren wir Metriken?
Ich werde eine reale Situation geben, in der die Analyse von Metriken zu greifbaren Ergebnissen führte. Nehmen Sie den Release-Prozess als Beispiel. Im Allgemeinen umfasst es die folgenden Schritte.
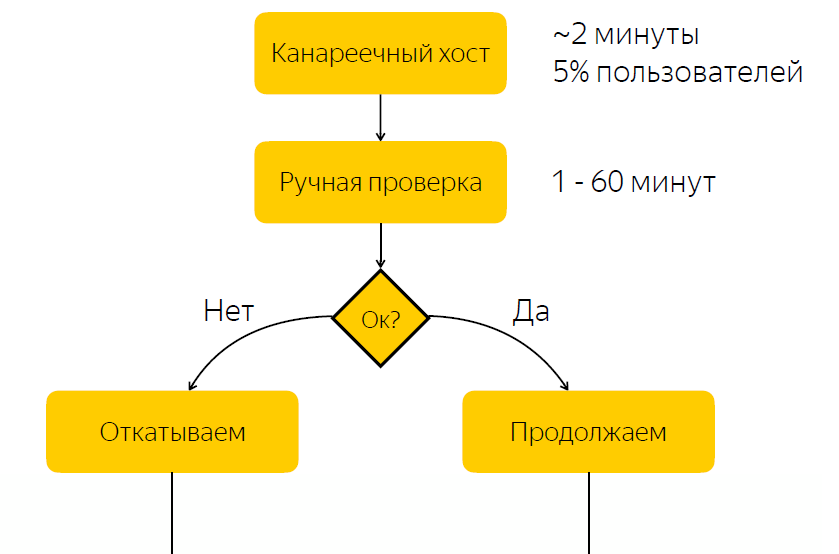
Die Version wird auf dem kanarischen Host bereitgestellt. Es macht etwa fünf Prozent des Benutzerverkehrs aus. Nach Abschluss der Freigabe an den kanarischen Wirt benachrichtigen wir die für die Freigabe verantwortliche Person, dass sie prüfen soll, ob mit der Freigabe alles in Ordnung ist. Und er sollte eine Reaktion geben, auf diese Version reagieren und auf die Schaltfläche klicken, um zu entscheiden, ob diese Version aktiviert oder zurückgesetzt werden soll.
Es ist nicht schwer zu erraten, dass dieses Schema einen erheblichen Nachteil aufweist, nämlich dass wir eine verantwortungsvolle Reaktion erwarten. Wenn die im Moment verantwortliche Person aus irgendeinem Grund nicht schnell reagieren kann, dann, wenn wir eine Fehlerfreigabe haben, kommen für einige Zeit fünf Prozent des Datenverkehrs zum Problemknoten. Wenn mit der Veröffentlichung alles in Ordnung ist, verbringen wir einfach Zeit mit Warten und verlangsamen dadurch den Veröffentlichungsprozess.
Keine Fehler - wir verlangsamen den Release-Prozess
Mit Fehlern - Benutzer Zuneigung
Um dieses Problem zu verstehen, haben wir uns entschlossen herauszufinden, ob es möglich ist, den Entscheidungsprozess darüber zu automatisieren, ob eine Veröffentlichung problematisch ist oder nicht.
Natürlich haben wir uns an unsere Entwickler gewandt, um zu verstehen, wie die Release-Prüfung durchgeführt wird. Es stellte sich heraus, und es scheint logisch genug, dass der Hauptindikator für die Problematik die Zunahme der Anzahl der Fehler in den Protokollen dieser Anwendung ist.
Was haben die Entwickler gemacht? Sie öffneten Kibana, trafen eine Auswahl gemäß der FEHLER-Ebene des Anwendungsblocks, und wenn sie die Listen sahen, dachten sie, dass etwas mit der Anwendung nicht stimmte. Es ist erwähnenswert, dass die Protokolle unserer Anwendung in Elastic gespeichert sind und anscheinend alles recht einfach aussieht. Wir haben die Protokolle in Elastic, wir müssen nur eine Anfrage in Elastic erstellen, eine Auswahl treffen und anhand dieser Daten verstehen, ob die Version problematisch ist oder nicht. Aber diese Entscheidung schien uns nicht sehr gut zu sein.
Warum nicht elastisch?
Zunächst befürchteten wir, dass wir möglicherweise nicht schnell Daten von Elastic empfangen können. Es gibt solche Fälle, zum Beispiel während Stresstests, wenn wir einen großen Datenfluss haben und der Cluster möglicherweise nicht zurechtkommt und es letztendlich zu einer Verzögerung beim Senden von Protokollen für etwa 10 bis 15 Minuten kommt.
Es gab auch sekundäre Gründe, zum Beispiel das Fehlen eines einheitlichen Namens für Indizes. Dies musste im Automatisierungstool berücksichtigt werden. Außerdem können Anwendungen auf verschiedenen Plattformen unterschiedliche Protokollformate haben.
Wir haben uns überlegt, warum wir nicht versuchen sollten, Metriken zu erstellen, anhand derer wir entscheiden können, ob die Veröffentlichung problematisch ist oder nicht. Gleichzeitig wollten wir unsere Entwickler nicht mit Änderungen an der Codebasis belasten. Und wie es uns scheint, haben wir eine ziemlich elegante Lösung gefunden, indem wir log4j einen zusätzlichen Appender hinzugefügt haben.
Wie sieht es aus?
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status="warn" name="${sys:application.name}" > <Properties> <Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property> </Properties> ... <Appenders> <Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP"> <PatternLayout pattern="${logsCountStatsDFormat}"/> </Socket> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="STATSD"/> </Root> </Loggers> </Configuration>
Zuerst bestimmen wir das Format der Metrik, die wir senden. Im Folgenden wird ein zusätzlicher Appender beschrieben, der Einträge in dem oben angegebenen Format über UDP an Port 8125 sendet, dh an Heka. Was gibt uns das? Log4j sendet für jeden Eintrag im Protokoll eine Metrik vom Typ Counter mit einem bestimmten Datensatzlevel ERROR, INFO, WARN usw.
Wir haben jedoch schnell erkannt, dass das Senden einer Metrik an jeden Protokolleintrag eine erhebliche Belastung verursachen kann, und wir haben eine Bibliothek geschrieben, die die Metriken für eine bestimmte Zeit aggregiert und die bereits aggregierte Metrik an den Heka-Service sendet. Tatsächlich fügen wir diesen Appender zu Loggern hinzu, und mit diesem Ansatz wissen wir jetzt, wie viel unsere Anwendung Protokolle zum Leveln schreibt. Wir haben einen einheitlichen Namen für Metriken, unabhängig davon, welche Plattform verwendet wird. Wir können leicht verstehen, wie viele Fehler im Anwendungsprotokoll enthalten sind. Und schließlich konnten wir den Entscheidungsprozess für eine problematische Veröffentlichung automatisieren.
Automatisierung
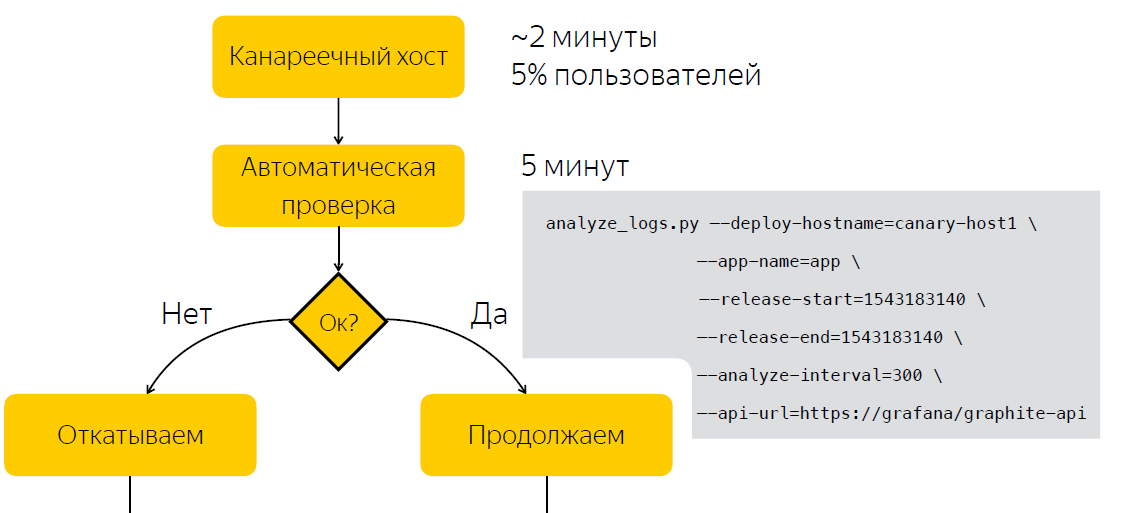
Anstatt nach der Veröffentlichung manuell zu prüfen, warten wir fünf Minuten. Danach erfassen wir Daten über die Anzahl der Einträge in den Anwendungsprotokollen. Nachdem wir das Skript ausgeführt haben, das anhand von zwei Beispielen vor und nach der Veröffentlichung entscheidet, ob die Veröffentlichung problematisch ist. Daher haben wir den Zeitaufwand für die Entscheidungsfindung auf fünf Minuten reduziert.
Neben der Tatsache, dass die Informationen über die Anzahl der Fehler in den Protokollen während der Veröffentlichung nützlich sind, stellte sich heraus, dass es ein netter Bonus ist, dass sie auch während des Vorgangs nützlich sind. So können wir beispielsweise die Anzahl der Fehler in den Protokollen in Grafana visualisieren und anomale Spannungsspitzen in den Anwendungsprotokollen aufzeichnen.
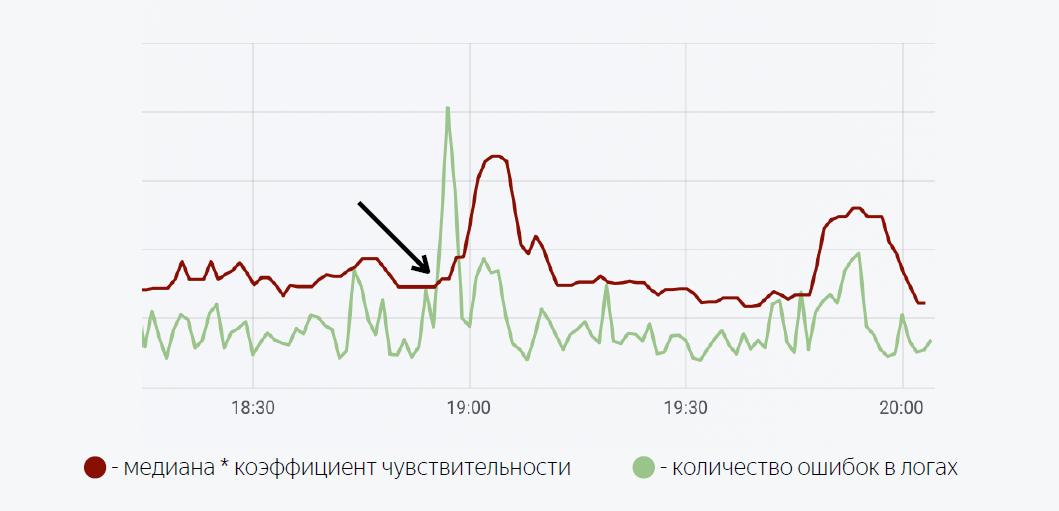
Hier wird ein ziemlich einfaches mathematisches Modell verwendet. Die grüne Linie gibt die Anzahl der Fehler in den Anwendungsprotokollen an. Dunkelrot ist der Median mal der Empfindlichkeitsfaktor. Wenn die Anzahl der Fehler in den Protokollen den Median überschreitet, wird ein Trigger ausgelöst, wenn eine Benachrichtigung über Moira ausgelöst wird.
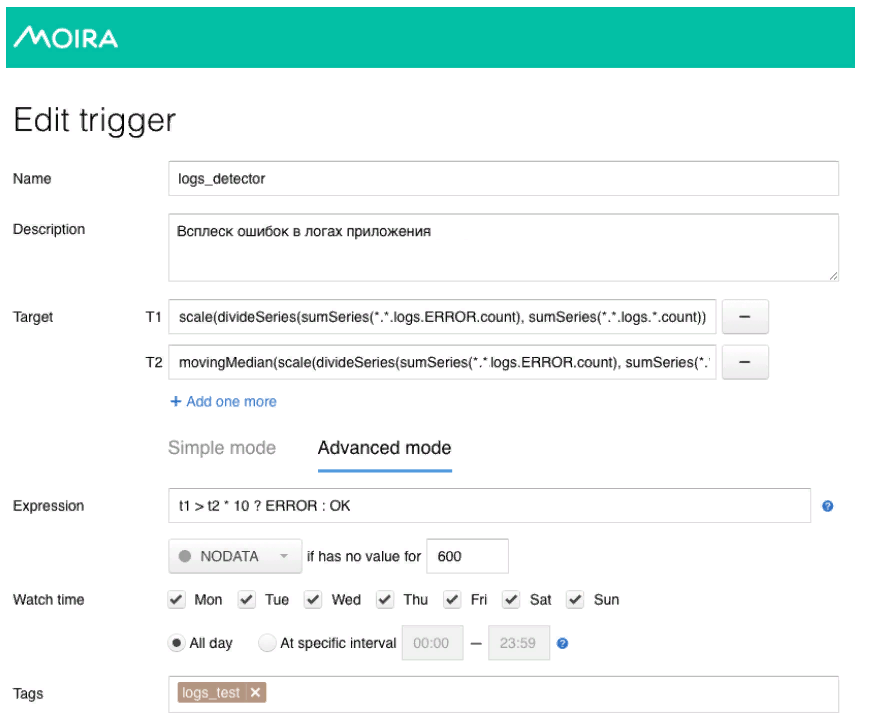
Wie ich versprochen habe, erzähle ich Ihnen ein wenig über Moira, wie es funktioniert. Wir definieren die Zielmetriken, die wir beobachten möchten. Dies ist die Anzahl der Fehler und der sich bewegende Median sowie die Bedingungen, unter denen dieser Trigger funktioniert, dh wenn die Anzahl der Fehler in den Protokollen den Median multipliziert mit dem Empfindlichkeitskoeffizienten überschreitet. Wenn der Auslöser ausgelöst wird, erhält der Entwickler eine Benachrichtigung, dass ein abnormaler Fehlerstoß in der Anwendung aufgezeichnet wurde, und es sollten einige Maßnahmen ergriffen werden.

Was haben wir am Ende? Wir haben einen gemeinsamen Mechanismus für alle unsere Backend-Anwendungen entwickelt, mit dem wir Informationen über die Anzahl der Einträge in den Protokollen einer bestimmten Ebene erhalten können. Mithilfe von Metriken zur Anzahl der Fehler in den Anwendungsprotokollen konnten wir außerdem den Entscheidungsprozess darüber automatisieren, ob die Veröffentlichung problematisch ist oder nicht. Sie haben auch eine Bibliothek für log4j geschrieben, die Sie verwenden können, wenn Sie den von mir beschriebenen Ansatz ausprobieren möchten. Link zur Bibliothek unten.
Das ist wahrscheinlich alles für mich. Vielen Dank.
Nützliche Links
Log4j-count-appender
Moira