In diesem Artikel stellen wir
Seiten vor , ein sehr verbreitetes Speicherverwaltungsschema, das wir auch in unserem Betriebssystem anwenden. Der Artikel erklärt, warum Speicherisolation erforderlich ist, wie
Segmentierung funktioniert, was
virtueller Speicher ist und wie Seiten das Fragmentierungsproblem lösen. Wir untersuchen auch das Schema von mehrstufigen Seitentabellen in der x86_64-Architektur.
Dieser Blog ist auf
GitHub veröffentlicht . Wenn Sie Fragen oder Probleme haben, öffnen Sie dort die entsprechende Anfrage.
Speicherschutz
Eine der Hauptaufgaben des Betriebssystems besteht darin, Programme voneinander zu isolieren. Beispielsweise sollte ein Browser einen Texteditor nicht stören. Abhängig von der Hardware- und Betriebssystemimplementierung gibt es verschiedene Ansätze.
Beispielsweise verfügen einige ARM Cortex-M-Prozessoren (in eingebetteten Systemen) über
eine Speicherschutzeinheit (MPU), die eine kleine Anzahl (z. B. 8) von Speicherbereichen mit unterschiedlichen Zugriffsberechtigungen definiert (z. B. kein Zugriff, schreibgeschützt, lesbar und) Aufzeichnungen). Bei jedem Zugriff auf den Speicher stellt die MPU sicher, dass sich die Adresse in dem Bereich mit den richtigen Berechtigungen befindet. Andernfalls wird eine Ausnahme ausgelöst. Durch Ändern des Bereichs und der Zugriffsberechtigungen stellt das Betriebssystem sicher, dass jeder Prozess nur auf seinen Speicher zugreifen kann, um die Prozesse voneinander zu isolieren.
Unter x86 werden zwei verschiedene Ansätze zum Schutz des Speichers unterstützt:
Segmentierung und
Paging .
Segmentierung
Die Segmentierung wurde bereits 1978 implementiert, um zunächst den adressierbaren Speicher zu erhöhen. Zu diesem Zeitpunkt unterstützte die CPU nur 16-Bit-Adressen, wodurch die Menge des adressierbaren Speichers auf 64 KB begrenzt wurde. Um dieses Volumen zu erhöhen, wurden zusätzliche Segmentregister eingeführt, von denen jedes eine Versatzadresse enthält. Die CPU fügt diesen Offset bei jedem Speicherzugriff automatisch hinzu und adressiert so bis zu 1 MB Speicher.
Die CPU wählt abhängig von der Art des Speicherzugriffs automatisch ein Segmentregister aus: Das
CS -Codesegmentregister wird zum Empfangen von Anweisungen verwendet, und das
SS Stapelsegmentregister wird für Stapeloperationen (Push / Pop) verwendet. Andere Anweisungen verwenden das
DS -Datensegmentregister oder das optionale
ES Segmentregister. Später wurden zwei zusätzliche Segmentregister
FS und
GS zur freien Verwendung hinzugefügt.
In der ersten Version der Segmentierung enthielten die Register direkt den Offset, und die Zugriffskontrolle wurde nicht durchgeführt. Mit dem Aufkommen des
geschützten Modus hat sich der Mechanismus geändert. Wenn die CPU in diesem Modus arbeitet, speichern die Segmentdeskriptoren den Index in einer lokalen oder globalen Deskriptortabelle, die zusätzlich zur Offsetadresse die Segmentgröße und die Zugriffsberechtigungen enthält. Durch Laden separater globaler / lokaler Deskriptortabellen für jeden Prozess kann das Betriebssystem Prozesse voneinander isolieren.
Durch Ändern der Speicheradressen vor dem eigentlichen Zugriff implementierte die Segmentierung eine Methode, die heute fast überall verwendet wird: Es handelt sich um
virtuellen Speicher .
Virtueller Speicher
Die Idee des virtuellen Speichers besteht darin, Speicheradressen von einem physischen Gerät zu abstrahieren. Anstatt direkt auf das Speichergerät zuzugreifen, wird zuerst ein Konvertierungsschritt ausgeführt. Bei der Segmentierung wird die Versatzadresse des aktiven Segments in der Übersetzungsphase hinzugefügt. Stellen Sie sich ein Programm vor, das in einem Segment mit einem Offset von
0x1111000 auf die Speicheradresse
0x1234000 0x1111000 : In Wirklichkeit geht die Adresse an
0x2345000 .
Um zwischen zwei Arten von Adressen zu unterscheiden, werden Adressen vor der Konvertierung als
virtuell und Adressen nach der Konvertierung als
physisch bezeichnet . Es gibt einen wichtigen Unterschied zwischen ihnen: Physische Adressen sind eindeutig und beziehen sich immer auf denselben eindeutigen Speicherort im Speicher. Virtuelle Adressen hängen dagegen von der Übersetzungsfunktion ab. Zwei verschiedene virtuelle Adressen können sich durchaus auf dieselbe physische Adresse beziehen. Darüber hinaus können identische virtuelle Adressen nach der Konvertierung auf unterschiedliche physische Adressen verweisen.
Ein Beispiel für die nützliche Verwendung dieser Eigenschaft ist der parallele Start desselben Programms zweimal:
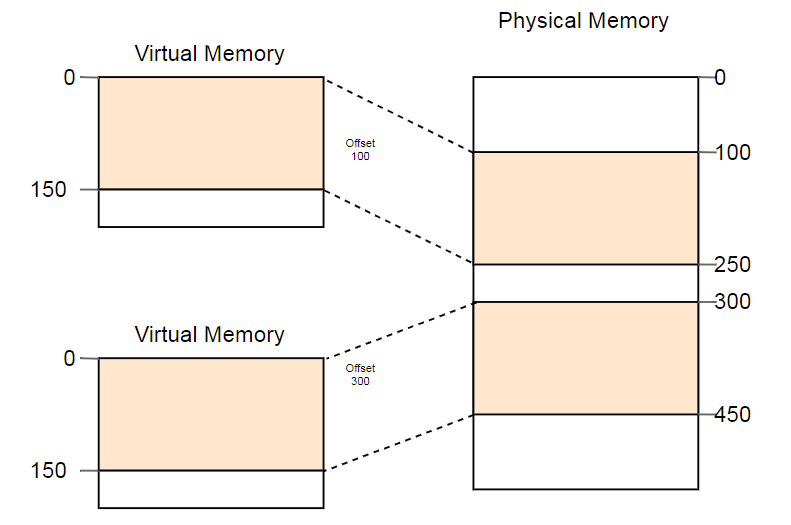
Hier wird dasselbe Programm zweimal ausgeführt, jedoch mit unterschiedlichen Konvertierungsfunktionen. Die erste Instanz hat einen Segmentversatz von 100, sodass ihre virtuellen Adressen 0-150 in physische Adressen 100-250 konvertiert werden. Die zweite Instanz hat einen Offset von 300, wodurch die virtuellen Adressen 0-150 in physische Adressen 300-450 übersetzt werden. Dadurch können beide Programme denselben Code ausführen und dieselben virtuellen Adressen verwenden, ohne sich gegenseitig zu stören.
Ein weiterer Vorteil ist, dass Programme jetzt an beliebigen Stellen im physischen Speicher abgelegt werden können. Somit nutzt das Betriebssystem die gesamte verfügbare Speichermenge, ohne dass Programme neu kompiliert werden müssen.
Fragmentierung
Der Unterschied zwischen virtuellen und physischen Adressen ist eine echte Errungenschaft der Segmentierung. Aber es gibt ein Problem. Stellen Sie sich vor, wir möchten die dritte Kopie des oben gezeigten Programms ausführen:
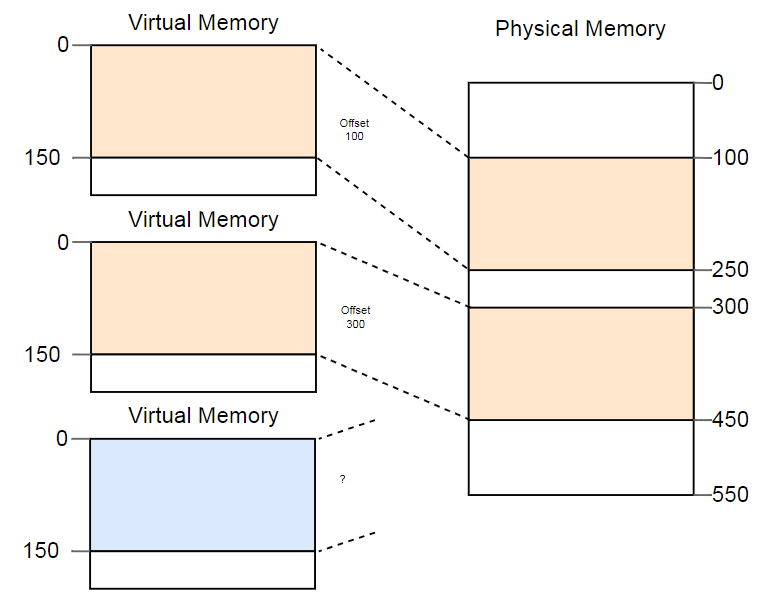
Obwohl im physischen Speicher mehr als genug Speicherplatz vorhanden ist, passt die dritte Kopie nirgendwo hin. Das Problem ist, dass er ein
kontinuierliches Fragment des Speichers benötigt und wir keine separaten freien Abschnitte verwenden können.
Eine Möglichkeit, die Fragmentierung zu bekämpfen, besteht darin, die Programmausführung anzuhalten, verwendete Speicherteile näher aneinander zu verschieben, die Konvertierung zu aktualisieren und dann die Ausführung fortzusetzen:
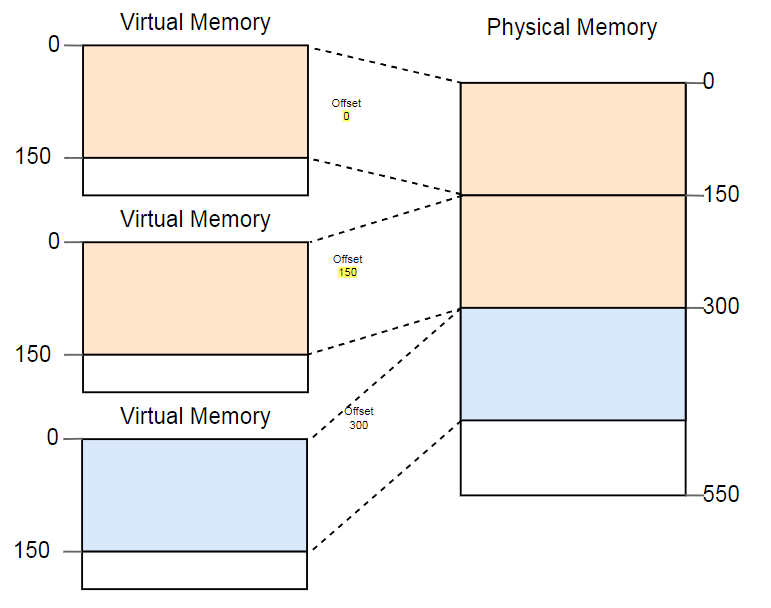
Jetzt ist genügend Platz vorhanden, um die dritte Instanz zu starten.
Der Nachteil dieser Defragmentierung ist die Notwendigkeit, große Speichermengen zu kopieren, was die Leistung verringert. Dieser Vorgang muss regelmäßig durchgeführt werden, bis der Speicher zu fragmentiert ist. Die Leistung wird unvorhersehbar, Programme werden jederzeit gestoppt und reagieren möglicherweise nicht mehr.
Die Fragmentierung ist einer der Gründe, warum die Segmentierung in den meisten Systemen nicht verwendet wird. Tatsächlich wird es auch im 64-Bit-Modus unter x86 nicht mehr unterstützt. Anstelle der Segmentierung werden Seiten verwendet, die das Problem der Fragmentierung vollständig beseitigen.
Seitenorganisation des Gedächtnisses
Die Idee ist, den Raum des virtuellen und physischen Speichers in kleine Blöcke fester Größe zu unterteilen. Virtuelle Speicherblöcke werden als Seiten bezeichnet, und physische Adressraumblöcke werden als Frames bezeichnet. Jede Seite wird einzeln einem Frame zugeordnet, sodass Sie große Speicherbereiche auf nicht benachbarte physische Frames aufteilen können.
Der Vorteil wird offensichtlich, wenn Sie das Beispiel mit einem fragmentierten Speicherplatz wiederholen, diesmal jedoch Seiten anstelle der Segmentierung verwenden:
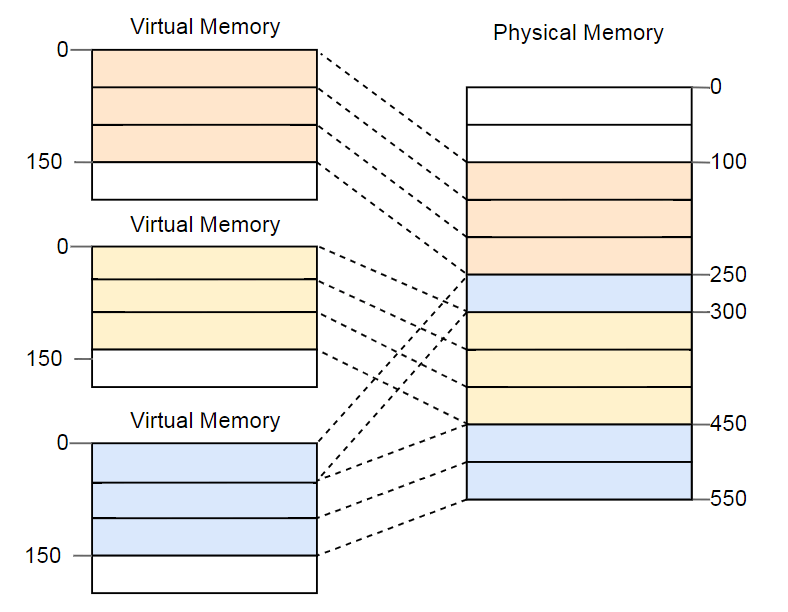
In diesem Beispiel beträgt die Seitengröße 50 Byte, dh jeder der Speicherbereiche ist in drei Seiten unterteilt. Jede Seite wird einem separaten Frame zugeordnet, sodass ein zusammenhängender Bereich des virtuellen Speichers isolierten physischen Frames zugeordnet werden kann. Auf diese Weise können Sie die dritte Instanz des Programms ohne Defragmentierung ausführen.
Versteckte Fragmentierung
Im Vergleich zur Segmentierung verwendet eine Paging-Organisation viele kleine Speicherbereiche mit fester Größe anstelle mehrerer großer Bereiche mit variabler Größe. Jeder Frame hat die gleiche Größe, sodass eine Fragmentierung aufgrund zu kleiner Frames nicht möglich ist.
Dies ist aber nur eine
Erscheinung . Tatsächlich gibt es eine versteckte Form der Fragmentierung, die sogenannte
interne Fragmentierung , da nicht jeder Speicherbereich genau ein Vielfaches der Seitengröße beträgt. Stellen Sie sich im obigen Beispiel ein Programm der Größe 101 vor: Es werden noch drei Seiten der Größe 50 benötigt, sodass 49 Bytes mehr benötigt werden, als Sie benötigen. Aus Gründen der Klarheit wird die Fragmentierung aufgrund der Segmentierung als
externe Fragmentierung bezeichnet .
Es gibt nichts Gutes in der internen Fragmentierung, aber oft ist es ein geringeres Übel als die externe Fragmentierung. Zusätzlicher Speicher wird immer noch verbraucht, aber jetzt müssen Sie ihn nicht mehr defragmentieren, und das Fragmentierungsvolumen ist vorhersehbar (durchschnittlich eine halbe Seite pro Speicherbereich).
Seitentabellen
Wir haben gesehen, dass jede der Millionen möglichen Seiten einzeln einem Frame zugeordnet ist. Diese Adressübersetzungsinformationen müssen irgendwo gespeichert werden. Bei der Segmentierung werden für jeden aktiven Speicherbereich separate Segmentregister verwendet, was bei Seiten nicht möglich ist, da es viel mehr als Register gibt. Stattdessen wird eine Struktur verwendet, die als
Seitentabelle bezeichnet wird .
Für das obige Beispiel sehen die Tabellen folgendermaßen aus:
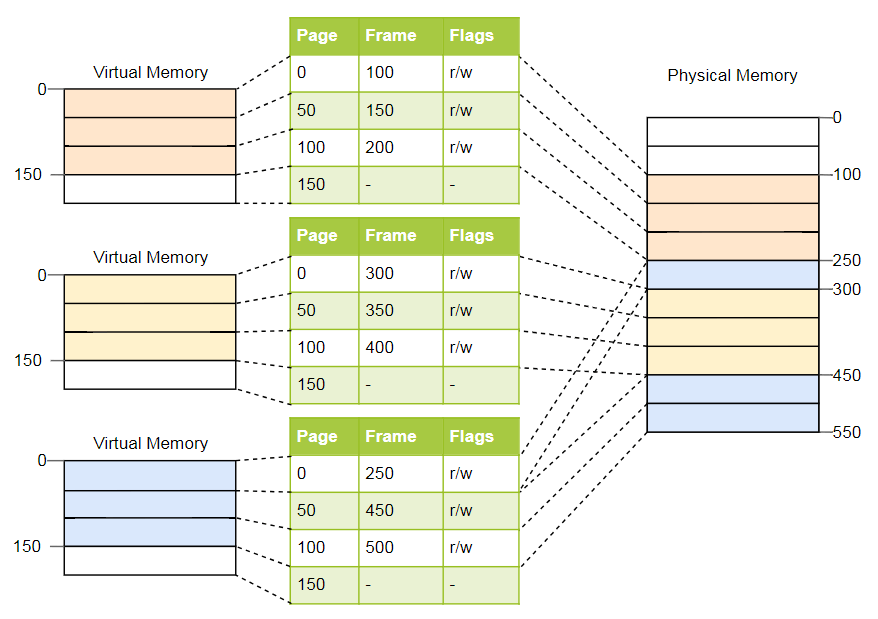
Wie Sie sehen können, hat jede Instanz des Programms eine eigene Seitentabelle. Ein Zeiger auf die aktuell aktive Tabelle wird in einem speziellen Register der CPU gespeichert. Auf
x86 es
CR3 . Vor dem Starten jeder Instanz des Programms muss das Betriebssystem dort einen Zeiger auf die richtige Seitentabelle laden.
Bei jedem Zugriff auf den Speicher liest die CPU den Tabellenzeiger aus dem Register und sucht nach dem entsprechenden Rahmen in der Tabelle. Dies ist eine vollständig Hardwarefunktion, die für ein laufendes Programm vollständig transparent ausgeführt wird. Um den Prozess zu beschleunigen, verfügen viele Prozessorarchitekturen über einen speziellen Cache, der die Ergebnisse der letzten Konvertierungen speichert.
Abhängig von der Architektur können Attribute wie Berechtigungen auch im Flag-Feld der Seitentabelle gespeichert werden. Im obigen Beispiel macht das
r/w Flag die Seite lesbar und beschreibbar.
Überlagerte Seitentabellen
Einfache Seitentabellen haben ein Problem mit großen Adressräumen: Speicher wird verschwendet. Das Programm verwendet beispielsweise vier virtuelle Seiten
0 ,
1_000_000 ,
1_000_050 und
1_000_100 (wir verwenden
_ als Trennzeichen):
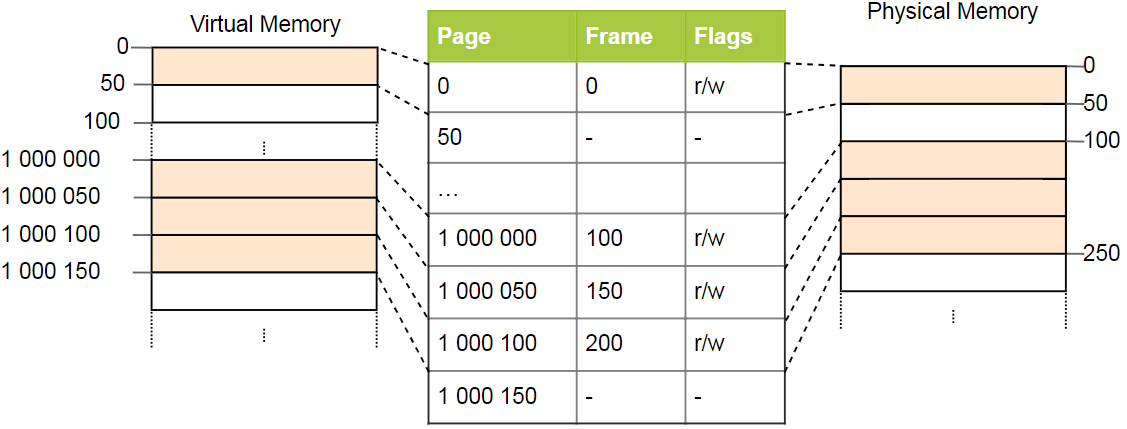
Es sind nur vier physische Frames erforderlich, aber die Seitentabelle enthält mehr als eine Million Datensätze. Leere Datensätze können nicht übersprungen werden, da die CPU während des Konvertierungsprozesses nicht direkt zum richtigen Datensatz wechseln kann (es kann beispielsweise nicht mehr garantiert werden, dass auf der vierten Seite der vierte Datensatz verwendet wird).
Um den Speicherverlust zu verringern, können Sie eine
zweistufige Organisation verwenden . Die Idee ist, dass wir verschiedene Tabellen für verschiedene Bereiche verwenden. Eine zusätzliche Tabelle, die als Seitentabelle der
zweiten Ebene bezeichnet wird, wird zwischen den Adressbereichen und Seitentabellen der ersten Ebene konvertiert.
Dies lässt sich am besten anhand eines Beispiels erklären. Wir definieren, dass jede Seitentabelle der Ebene 1 für einen Bereich der Größe
10_000 . Dann existieren im obigen Beispiel die folgenden Tabellen:
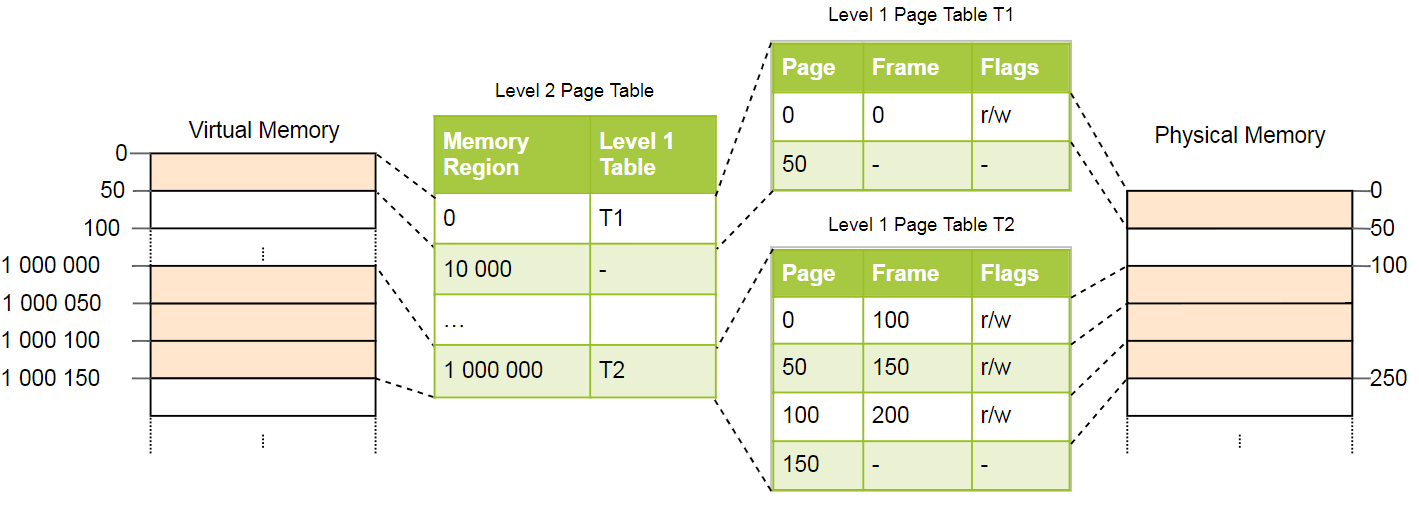
Seite 0 fällt in den ersten Bereich von
10_000 Bytes und verwendet daher den ersten Datensatz in der Seitentabelle der zweiten Ebene. Dieser Eintrag verweist auf die T1-Seitentabelle der ersten Ebene, die bestimmt, dass Seite 0 auf Frame 0 verweist.
Die Seiten
1_000_000 ,
1_000_050 und
1_000_100 fallen in den 100. Byte-Bereich von
10_000 , sodass sie den 100. Datensatz der Seitentabelle der Ebene 2 verwenden. Dieser Datensatz zeigt auf eine andere Tabelle T2 der ersten Ebene, die drei Seiten in die Frames 100, 150 und 200 übersetzt. Hinweis
1_000_050 in den Tabellen der ersten Ebene keinen
1_000_050 beträgt der Datensatz für Seite
1_000_050 beispielsweise nur
50 .
Wir haben noch 100 leere Einträge in der Tabelle der zweiten Ebene, aber das ist viel weniger als die vorherige Million. Der Grund für die Einsparungen ist, dass Sie keine Seitentabellen der ersten Ebene für nicht
10_000 Speicherbereiche zwischen
10_000 und
1_000_000 10_000 1_000_000 .
Das Prinzip von zweistufigen Tabellen kann auf drei, vier oder mehr Ebenen erweitert werden. Im Allgemeinen wird ein solches System als
mehrstufige oder
hierarchische Seitentabelle bezeichnet.
Wenn Sie die Seitenorganisation und die mehrstufigen Tabellen kennen, können Sie sehen, wie die Seitenorganisation in der x86_64-Architektur implementiert ist (wir gehen davon aus, dass der Prozessor im 64-Bit-Modus arbeitet).
Seitenorganisation auf x86_64
Die x86_64-Architektur verwendet eine vierstufige Tabelle mit einer Seitengröße von 4 KB. Unabhängig von der Ebene enthält jede Seitentabelle 512 Elemente. Jeder Datensatz hat eine Größe von 8 Bytes, sodass die Größe der Tabellen 512 × 8 Bytes = 4 KB beträgt.

Wie Sie sehen können, enthält jeder Tabellenindex 9 Bits, was sinnvoll ist, da die Tabellen 2 ^ 9 = 512 Einträge haben. Die unteren 12 Bits sind der 4-Kilobyte-Seitenversatz (2 ^ 12 Bytes = 4 KB). Die Bits 48 bis 64 werden verworfen, sodass x86_64 eigentlich kein 64-Bit-System ist, sondern nur 48-Bit-Adressen unterstützt. Es gibt Pläne, die Adressgröße durch eine
5-Ebenen-Seitentabelle auf 57 Bit zu erweitern, aber ein solcher Prozessor wurde noch nicht erstellt.
Obwohl die Bits 48 bis 64 verworfen werden, können sie nicht auf beliebige Werte gesetzt werden. Alle Bits in diesem Bereich müssen Kopien von Bit 47 sein, um eindeutige Adressen beizubehalten und eine zukünftige Erweiterung zu ermöglichen, beispielsweise auf eine Seitentabelle mit 5 Ebenen. Dies wird als Zeichenerweiterung bezeichnet, da es
einer Zeichenerweiterung in zusätzlichem Code sehr ähnlich ist. Wenn die Adresse falsch erweitert wird, löst die CPU eine Ausnahme aus.
Konvertierungsbeispiel
Schauen wir uns ein Beispiel für die Funktionsweise der Adressübersetzung an:
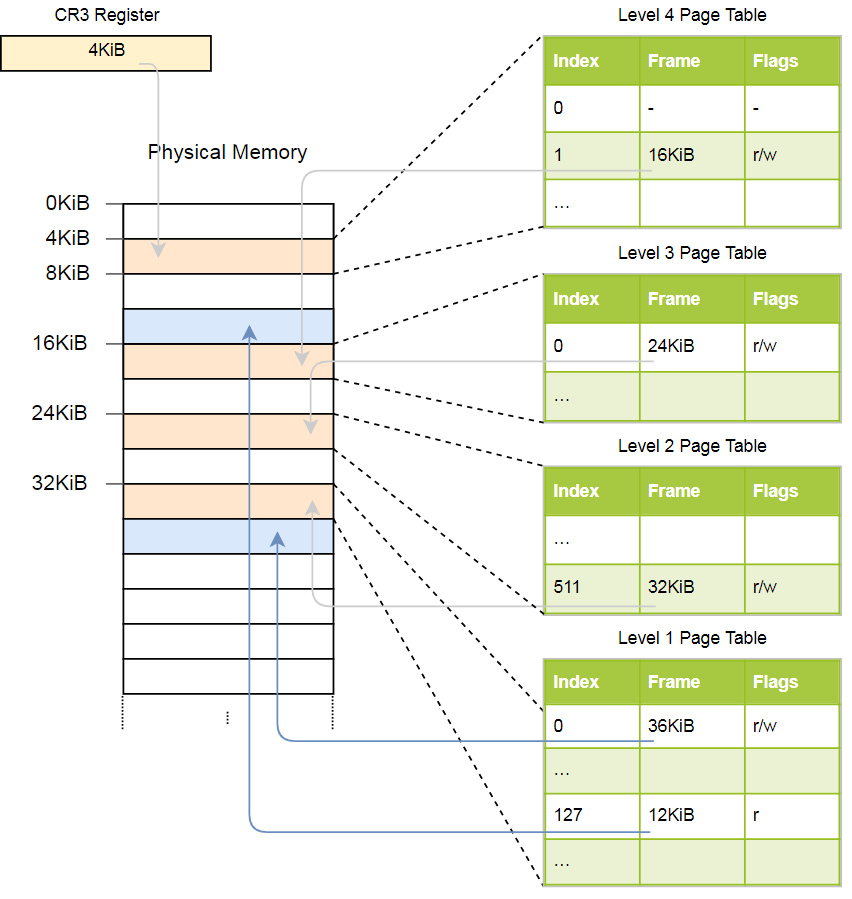
Die physikalische Adresse der aktuell aktiven Seitentabelle von Seiten der Ebene 4, die die
CR3 der
CR3 dieser Ebene ist, wird im
CR3 gespeichert. Jeder Seitentabelleneintrag zeigt dann auf den physischen Rahmen der Tabelle der nächsten Ebene. Ein Tabelleneintrag der Ebene 1 zeigt den angezeigten Rahmen an. Bitte beachten Sie, dass alle Adressen in den Seitentabellen physisch und nicht virtuell sind, da sonst die CPU diese Adressen konvertieren muss (was zu einer unendlichen Rekursion führen kann).
Die obige Hierarchie konvertiert zwei Seiten (in blau). Aus den Indizes können wir schließen, dass die virtuellen Adressen dieser Seiten
0x803fe7f000 und
0x803FE00000 . Mal sehen, was passiert, wenn ein Programm versucht, den Speicher unter der Adresse
0x803FE7F5CE zu lesen. Konvertieren Sie zunächst die Adresse in eine Binärdatei und bestimmen Sie die Seitentabellenindizes und den Offset für die Adresse:

Mit diesen Indizes können wir nun die Hierarchie der Seitentabellen durchgehen und den entsprechenden Frame finden:
- Lesen Sie die Adresse der Tabelle der vierten Ebene aus dem
CR3 . - Der Index der vierten Ebene ist 1, daher betrachten wir den Datensatz mit Index 1 in dieser Tabelle. Sie sagt, dass eine Tabelle der Stufe 3 bei 16 KB gespeichert ist.
- Wir laden die Tabelle der dritten Ebene von dieser Adresse und betrachten den Datensatz mit dem Index 0, der auf die Tabelle der zweiten Ebene mit 24 KB verweist.
- Der Index der zweiten Ebene ist 511, daher suchen wir nach dem letzten Datensatz auf dieser Seite, um die Adresse der Tabelle der ersten Ebene herauszufinden.
- Aus dem Eintrag mit dem Index 127 in der Tabelle der ersten Ebene geht schließlich hervor, dass die Seite einem 12-KB-Frame oder 0xc000 im Hexadezimalformat entspricht.
- Der letzte Schritt besteht darin, der Rahmenadresse einen Offset hinzuzufügen, um die physikalische Adresse zu erhalten: 0xc000 + 0x5ce = 0xc5ce.
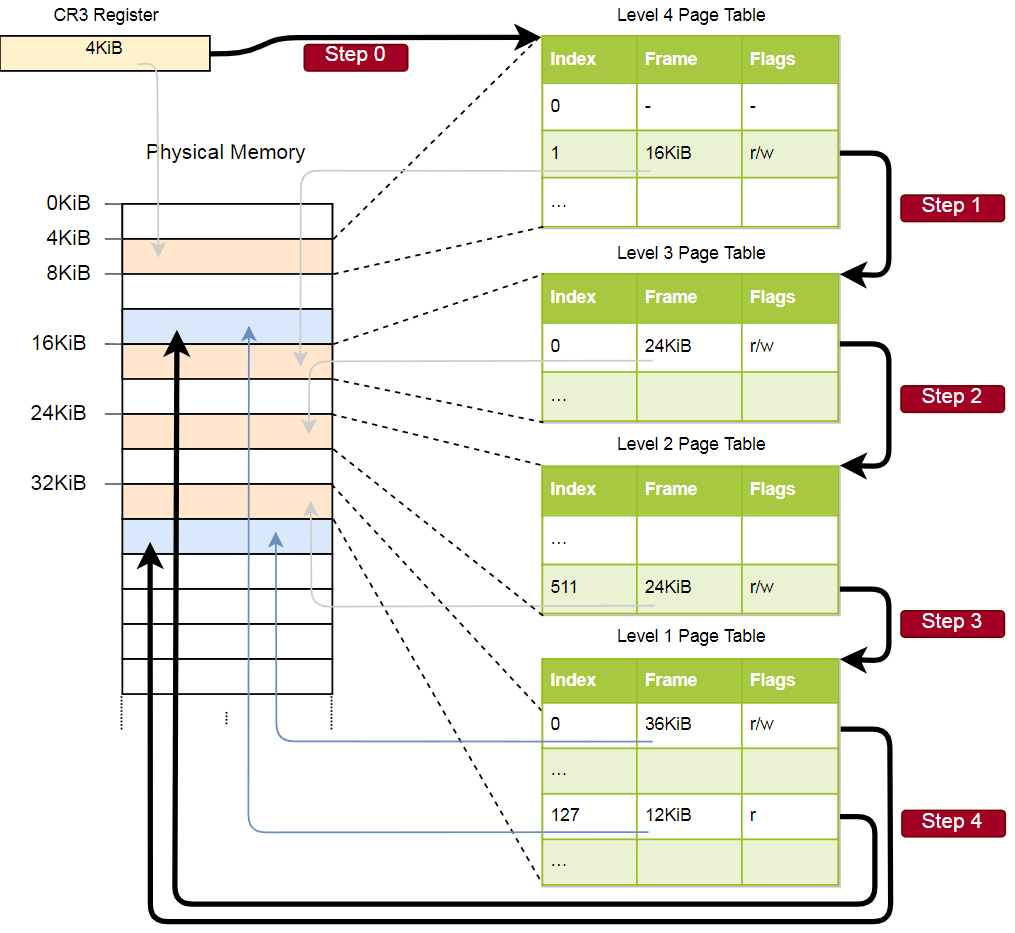
Für die Seite in der Tabelle der ersten Ebene wird das Flag
r angegeben, dh nur das Lesen ist zulässig. Eine Ausnahme wird auf Hardwareebene ausgelöst, wenn wir versuchen, dort aufzunehmen. Die Berechtigungen der übergeordneten Tabellen erstrecken sich auf die niedrigeren Ebenen. Wenn Sie also das Nur-Lese-Flag auf der dritten Ebene setzen, kann keine einzelne nachfolgende Seite der unteren Ebene beschreibbar sein, selbst wenn Flags vorhanden sind, die das Schreiben ermöglichen.
Obwohl in diesem Beispiel nur eine Instanz jeder Tabelle verwendet wird, gibt es normalerweise in jedem Adressraum mehrere Instanzen jeder Ebene. Maximum:
- ein Tisch der vierten Ebene,
- 512 Tabellen der dritten Ebene (da die Tabelle der vierten Ebene 512 Datensätze enthält),
- 512 * 512 Tabellen der zweiten Ebene (da jede der Tabellen der dritten Ebene 512 Einträge enthält) und
- 512 * 512 * 512 Tabellen der ersten Ebene (512 Datensätze für jede Tabelle der zweiten Ebene).
Seitentabellenformat
In der x86_64-Architektur sind Seitentabellen im Wesentlichen Arrays von 512 Einträgen. In der Rust-Syntax:
#[repr(align(4096))] pub struct PageTable { entries: [PageTableEntry; 512], }
Wie im
repr Attribut angegeben, sollten die Tabellen auf der Seite ausgerichtet sein, d. H. Am 4-KB-Rand. Diese Anforderung stellt sicher, dass die Tabelle immer die gesamte Seite optimal ausfüllt, wodurch die Einträge sehr kompakt werden.
Die Größe jedes Datensatzes beträgt 8 Byte (64 Bit) und das folgende Format:
| Bit (s) | Titel | Wert |
|---|
| 0 | vorhanden | Seite im Speicher |
| 1 | beschreibbar | Aufzeichnung erlaubt |
| 2 | Benutzer zugänglich | Wenn das Bit nicht gesetzt ist, hat nur der Kernel Zugriff auf die Seite |
| 3 | Schreiben Sie durch Caching | direkt in den Speicher schreiben |
| 4 | Cache deaktivieren | Deaktivieren Sie den Cache für diese Seite |
| 5 | zugegriffen | Die CPU setzt dieses Bit, wenn die Seite verwendet wird. |
| 6 | schmutzig | Die CPU setzt dieses Bit beim Schreiben auf die Seite |
| 7 | riesige Seite / null | Das Nullbit in P1 und P4 erzeugt 1 KB-Seiten in P3, 2 MB-Seiten in P2 |
| 8 | global | Die Seite wird beim Umschalten des Adressraums nicht aus dem Cache gefüllt (das PGE-Bit des CR4-Registers muss gesetzt sein). |
| 9-11 | verfügbar | Das Betriebssystem kann sie frei verwenden |
| 12-51 | physikalische Adresse | seitenausgerichtete physikalische 52-Bit-Adresse des Frames oder der folgenden Seitentabelle |
| 52-62 | verfügbar | Das Betriebssystem kann sie frei verwenden |
| 63 | keine Ausführung | verbietet die Ausführung von Code auf dieser Seite (das NXE-Bit muss im EFER-Register gesetzt sein) |
Wir sehen, dass nur die Bits 12-51 zum Speichern der physischen Adresse des Rahmens verwendet werden und der Rest als Flags arbeitet oder vom Betriebssystem frei verwendet werden kann. Dies ist möglich, weil wir immer entweder auf eine 4096-Byte-ausgerichtete Adresse oder auf eine ausgerichtete Tabellenseite oder auf den Anfang des entsprechenden Frames verweisen. Dies bedeutet, dass die Bits 0-11 immer Null sind, sodass sie nicht gespeichert werden können. Sie werden einfach auf die Hardwareebene zurückgesetzt, bevor die Adresse verwendet wird. Gleiches gilt für die Bits 52-63, da die x86_64-Architektur nur physische 52-Bit-Adressen (und nur virtuelle 48-Bit-Adressen) unterstützt.
Schauen wir uns die verfügbaren Flags genauer an:
- Das
present Flag unterscheidet angezeigte Seiten von nicht angezeigten. Es kann verwendet werden, um Seiten vorübergehend auf der Festplatte zu speichern, wenn der Hauptspeicher voll ist. Beim nächsten Zugriff auf die Seite tritt eine spezielle PageFault-Ausnahme auf, auf die das Betriebssystem reagiert, indem es die Seite von der Festplatte austauscht. Das Programm funktioniert weiterhin. - Die Flags "
writable und " no execute bestimmen, ob der Seiteninhalt beschreibbar ist oder ausführbare Anweisungen enthält. - Die
accessed und dirty Flags werden vom Prozessor beim Lesen oder Schreiben auf die Seite automatisch gesetzt. Das Betriebssystem kann diese Informationen beispielsweise verwenden, wenn es Seiten austauscht oder wenn überprüft wird, ob sich der Inhalt der Seite seit dem letzten Pumpen auf die Festplatte geändert hat. - Mit den Caches zum
write through caching und disable cache können Sie den Cache für jede Seite einzeln verwalten. - Das
user accessible macht die Seite für Code aus dem Benutzerbereich zugänglich, andernfalls steht sie nur dem Kernel zur Verfügung. Diese Funktion kann verwendet werden, um Systemaufrufe zu beschleunigen und gleichzeitig die Adresszuordnung für den Kernel beizubehalten, während das Benutzerprogramm ausgeführt wird. Aufgrund der Spectre- Sicherheitsanfälligkeit können diese Seiten jedoch von Programmen aus dem Benutzerbereich gelesen werden. global , (. TLB ) (address space switch). user accessible .huge page , 2 3 . 512 : 2 = 512 × 4 , 1 = 512 × 2 . .
Die x86_64-Architektur definiert das Format der Seitentabellen und ihrer Datensätze , sodass wir diese Strukturen nicht selbst erstellen müssen.Assoziativer Übersetzungspuffer (TLB)
Aufgrund der vier Ebenen erfordert jede Adressübersetzung vier Speicherzugriffe. Aus Leistungsgründen speichert x86_64 die letzten Übersetzungen im sogenannten assoziativen Übersetzungspuffer (TLB) zwischen. Auf diese Weise können Sie die Konvertierung überspringen, wenn sie sich noch im Cache befindet.Im Gegensatz zu anderen Prozessor-Caches ist TLB nicht vollständig transparent und aktualisiert oder löscht keine Konvertierungen, wenn der Inhalt von Seitentabellen geändert wird. Dies bedeutet, dass der Kernel den TLB selbst aktualisieren muss, wenn er die Seitentabelle ändert. Zu diesem Zweck gibt es einen speziellen CPU-Befehl namens invlpg(Seite ungültig machen), der die Übersetzung der angegebenen Seite aus dem TLB entfernt, damit sie beim nächsten Mal erneut aus der Seitentabelle geladen wird. TLB wird durch erneutes Laden des Registers vollständig gelöschtCR3das ahmt einen Adressraumschalter nach. Beide Optionen sind über das tlb-Modul in Rust verfügbar.Es ist wichtig, nicht zu vergessen, den TLB nach jedem Seitentabellenwechsel zu bereinigen, da die CPU sonst weiterhin die alte Übersetzung verwendet, was zu unvorhersehbaren Fehlern führt, die nur sehr schwer zu debuggen sind.Implementierung
Eines haben wir nicht erwähnt: Unser Kern unterstützt bereits die Seitenorganisation . Der Bootloader aus dem Artikel „Minimaler Kernel on Rust“ hat bereits eine vierstufige Hierarchie eingerichtet, die jede Seite unseres Kernels einem physischen Frame zuordnet, da die Seitenorganisation im 64-Bit-Modus unter x86_64 erforderlich ist.Dies bedeutet, dass in unserem Kern alle Speicheradressen virtuell sind. Der Zugriff auf den VGA-Puffer unter der Adresse 0xb8000funktionierte nur, weil die Bootloader-ID diese Seite in den Speicher übersetzt hat, dh die virtuelle Seite 0xb8000dem physischen Frame zugeordnet hat 0xb8000.Dank der Seitenorganisation ist der Kernel bereits relativ sicher: Jeder Zugriff über den zulässigen Speicher hinaus verursacht einen Seitenfehler und erlaubt kein Schreiben in den physischen Speicher. Der Loader hat sogar die richtigen Zugriffsberechtigungen für jede Seite festgelegt: Es können nur Seiten mit Code ausgeführt werden, und nur Seiten mit Daten können geschrieben werdenSeitenfehler (PageFault)
Versuchen wir, PageFault aufzurufen, indem wir auf Speicher außerhalb des Kernels zugreifen. Erstellen Sie zunächst einen Fehlerbehandler und registrieren Sie ihn in unserem IDT, um eine bestimmte Ausnahme anstelle eines doppelten Fehlers eines allgemeinen Typs anzuzeigen:
Wenn die Seite fehlschlägt, setzt die CPU automatisch den Fall CR2. Es enthält die virtuelle Adresse der Seite, die den Fehler verursacht hat. Verwenden Sie die Funktion, um diese Adresse zu lesen und anzuzeigen Cr2::read. In der Regel enthält der Typ PageFaultErrorCodemehr Informationen über die Art des Speicherzugriffs, der den Fehler verursacht hat. Aufgrund des LLVM- Fehlers wird jedoch ein ungültiger Fehlercode übertragen. Daher werden diese Informationen vorerst ignoriert. Die Programmausführung kann erst fortgesetzt werden, wenn der Seitenfehler behoben ist. Fügen Sie sie daher am Ende ein hlt_loop.Jetzt erhalten wir Zugriff auf den Speicher außerhalb des Kernels:
Nach dem Start sehen wir, dass der Seitenfehler-Handler aufgerufen wird: Das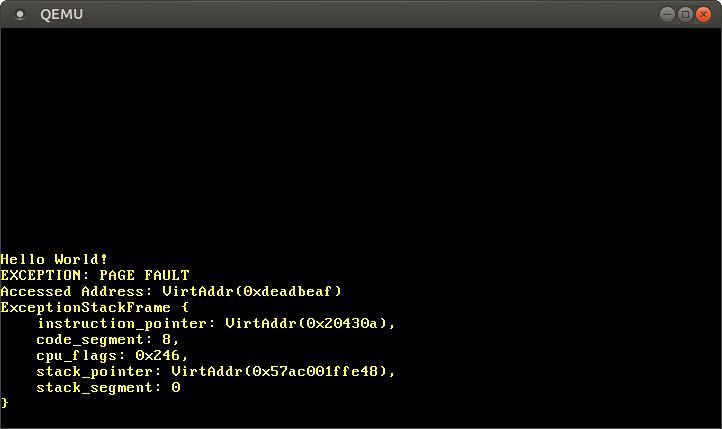 Register
Register CR2enthält wirklich die Adresse, auf die 0xdeadbeafwir zugreifen wollten.Der aktuelle Anweisungszeiger ist 0x20430a, sodass wir wissen, dass diese Adresse auf eine Codepage verweist. Codepages werden vom schreibgeschützten Loader angezeigt, sodass das Lesen von dieser Adresse funktioniert und das Schreiben einen Fehler verursacht. Versuchen Sie, den Zeiger 0xdeadbeafauf Folgendes zu ändern 0x20430a:
Wenn wir die letzte Zeile auskommentieren, können wir sicherstellen, dass das Lesen funktioniert und das Schreiben einen PageFault-Fehler verursacht.Zugriff auf Seitentabellen
Schauen Sie sich nun die Seitentabellen für den Kernel an:
Die Funktion Cr3::readvon x86_64gibt aus dem Register die CR3aktuell aktive Seitentabelle der vierten Ebene zurück. Ein Paar kehrt zurück PhysFrameund Cr3Flags. Wir interessieren uns nur für die erste.Nach dem Start sehen wir folgendes Ergebnis:Level 4 page table at: PhysAddr(0x1000)Daher wird derzeit die aktive Seitentabelle der vierten Ebene im physischen Speicher unter der 0x1000vom Typ angegebenen Adresse gespeichert PhysAddr. Die Frage ist nun: Wie kann man vom Kernel aus auf diese Tabelle zugreifen?Bei der Seitenorganisation ist kein direkter Zugriff auf den physischen Speicher möglich, da Programme sonst den Schutz leicht umgehen und Zugriff auf den Speicher anderer Programme erhalten können. Der einzige Weg, um Zugriff zu erhalten, ist eine virtuelle Seite, die bei in einen physischen Frame übersetzt wird0x1000. Dies ist ein typisches Problem, da der Kernel regelmäßig auf Seitentabellen zugreifen sollte, beispielsweise wenn ein Stapel für einen neuen Thread zugewiesen wird.Die Lösungen für dieses Problem werden im nächsten Artikel ausführlich beschrieben. Nehmen wir zunächst einmal an, dass der Loader eine Methode namens rekursive Seitentabellen verwendet . Die letzte Seite des virtuellen Adressraums ist 0xffff_ffff_ffff_f000, wir verwenden sie, um einige Einträge in dieser Tabelle zu lesen:
Wir haben die Adresse der letzten virtuellen Seite auf einen Zeiger auf reduziert u64. Wie im vorherigen Abschnitt angegeben, hat jeder Seitentabelleneintrag eine Größe von 8 Byte (64 Bit) und u64repräsentiert daher genau einen Eintrag. Mit der Schleife forzeigen wir die ersten 10 Datensätze der Tabelle an. Innerhalb der Schleife verwenden wir einen unsicheren Block, um direkt vom Zeiger zu lesen und den Zeiger offsetzu berechnen.: Nach dem Start sehen wir die folgenden Ergebnisse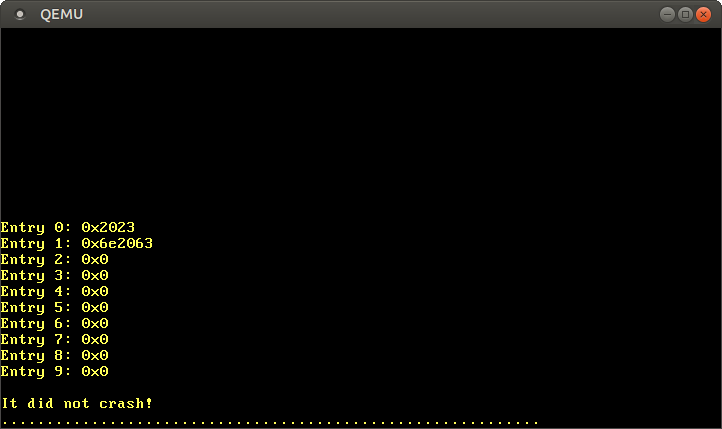 oben beschrieben, wird der Wert in das Format Nach
oben beschrieben, wird der Wert in das Format Nach 0x2023Aufzeichnungsmittel mit Flags 0 present, writable, accessedund die Übersetzung in einem Rahmen 0x2000. Datensatz 1 wird im Frame gesendet 0x6e2000und hat die gleichen Flags plusdirty. Die Einträge 2–9 fehlen, sodass diese virtuellen Adressbereiche keinen physischen Adressen zugeordnet werden.Anstatt direkt mit unsicheren Zeigern zu arbeiten, können Sie einen Typ PageTableaus verwenden x86_64:
0xffff_ffff_ffff_f000 , Rust. - , , .
&PageTable , ,
.
x86_64 , :

— 0 1 3. ,
0x2000 0x6e5000 , . .
Zusammenfassung
Der Artikel enthält zwei Methoden zum Schutz des Speichers: Segmentierung und Seitenorganisation. Die erste Methode verwendet Speicherbereiche mit variabler Größe und leidet unter externer Fragmentierung, die zweite verwendet Seiten mit fester Größe und ermöglicht eine wesentlich detailliertere Kontrolle über Zugriffsrechte.Eine Seitenorganisation speichert Seitenübersetzungsinformationen in Tabellen mit einer oder mehreren Ebenen. Die x86_64-Architektur verwendet vierstufige Tabellen mit einer Seitengröße von 4 KB. Das Gerät umgeht automatisch die Seitentabellen und speichert die Konvertierungsergebnisse im assoziativen Übersetzungspuffer (TLB) zwischen. Beim Ändern von Seitentabellen sollte eine Bereinigung erzwungen werden.Wir haben erfahren, dass unser Kern die Seitenorganisation bereits unterstützt und dass durch den nicht autorisierten Zugriff auf den Speicher PageFault gelöscht wird. Wir haben versucht, auf die derzeit aktiven Seitentabellen zuzugreifen, konnten jedoch nur auf die Tabelle der vierten Ebene zugreifen, da Seitenadressen physische Adressen speichern und wir nicht direkt vom Kernel aus darauf zugreifen können.Was weiter?
Der folgende Artikel basiert auf den grundlegenden Grundlagen, die wir jetzt gelernt haben. Um über den Kernel auf Seitentabellen zuzugreifen, wird eine erweiterte Technik namens rekursive Seitentabellen verwendet, um die Tabellenhierarchie zu durchlaufen und eine programmatische Adressübersetzung zu implementieren. In diesem Artikel wird auch erläutert, wie Sie neue Übersetzungen in Seitentabellen erstellen.