Erinnerung
Hallo Habr! Ich mache Sie auf eine weitere Übersetzung meines neuen Artikels aus dem
Medium aufmerksam .
Beim letzten Mal (
erster Artikel ) (
Habr ) haben wir einen Agenten mit Q-Learning-Technologie erstellt, der Transaktionen mit simulierten und realen Austauschzeitreihen durchführt, und versucht zu prüfen, ob dieser Aufgabenbereich für verstärktes Lernen geeignet ist.
Dieses Mal werden wir eine LSTM-Ebene hinzufügen, um Zeitabhängigkeiten innerhalb der Trajektorie zu berücksichtigen und das Belohnungs-Shaping-Engineering basierend auf Präsentationen durchzuführen.
Ich möchte Sie daran erinnern, dass wir zur Überprüfung des Konzepts die folgenden synthetischen Daten verwendet haben:
Synthetische Daten: Sinus mit weißem Rauschen.
Die Sinusfunktion war der erste Ausgangspunkt. Zwei Kurven simulieren den Kauf- und Verkaufspreis eines Vermögenswerts, wobei der Spread die minimalen Transaktionskosten darstellt.
Dieses Mal möchten wir diese einfache Aufgabe jedoch komplizieren, indem wir den Kreditzuweisungspfad erweitern:
Synthetische Daten: Sinus mit weißem Rauschen.
Die Sinusphase wurde verdoppelt.
Dies bedeutet, dass sich die spärlichen Belohnungen, die wir verwenden, über längere Flugbahnen erstrecken müssen. Darüber hinaus verringern wir die Wahrscheinlichkeit, eine positive Belohnung zu erhalten, erheblich, da der Agent eine Folge korrekter Aktionen zweimal länger ausführen musste, um die Transaktionskosten zu überwinden. Beide Faktoren erschweren die Aufgabe für RL selbst unter so einfachen Bedingungen wie einer Sinuswelle erheblich.
Darüber hinaus erinnern wir uns, dass wir diese neuronale Netzwerkarchitektur verwendet haben:
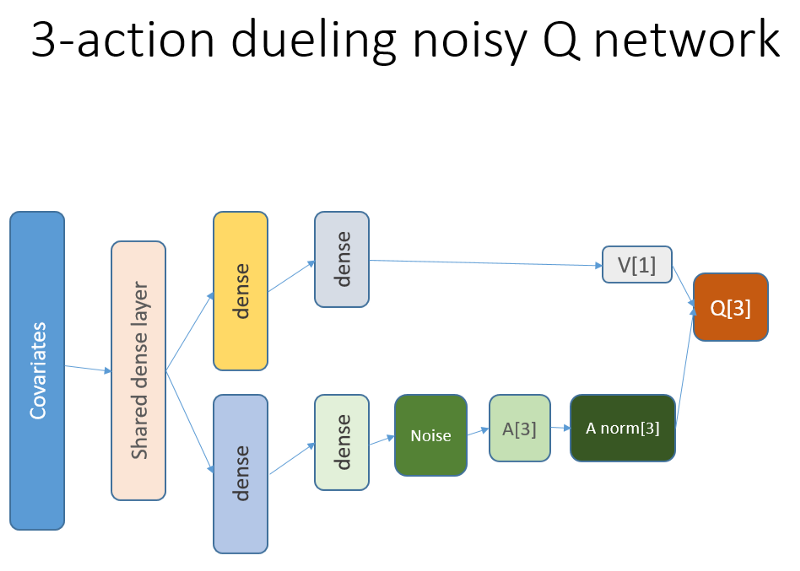
Was wurde hinzugefügt und warum
Lstm
Zunächst wollten wir dem Agenten ein besseres Verständnis für die Dynamik von Änderungen innerhalb der Flugbahn vermitteln. Einfach ausgedrückt, der Agent sollte sein eigenes Verhalten besser verstehen: Was er jetzt und seit einiger Zeit in der Vergangenheit getan hat und wie sich die Verteilung der staatlichen Aktionen sowie die erhaltenen Belohnungen entwickelt haben. Die Verwendung einer Wiederholungsebene kann genau dieses Problem lösen. Willkommen zu der neuen Architektur, mit der neue Experimente gestartet wurden:

Bitte beachten Sie, dass ich die Beschreibung leicht verbessert habe. Der einzige Unterschied zum alten NN besteht in der ersten verborgenen LSTM-Schicht anstelle einer vollständig gebundenen.
Bitte beachten Sie, dass wir mit LSTM in Arbeit die Auswahl von Beispielen für die Reproduktion von Erfahrungen für das Training ändern müssen: Jetzt benötigen wir Übergangssequenzen anstelle von separaten Beispielen. So funktioniert es (dies ist einer der Algorithmen). Wir haben zuvor Punktstichproben verwendet:

Das fiktive Schema des Wiedergabepuffers.
Wir verwenden dieses Schema mit LSTM:

Nun werden Sequenzen ausgewählt (deren Länge wir empirisch angeben).
Nach wie vor und jetzt wird die Stichprobe durch einen Prioritätsalgorithmus reguliert, der auf Fehlern des zeitlich-zeitlichen Lernens basiert.
Das LSTM-Wiederholungsniveau ermöglicht die direkte Verbreitung von Informationen aus Zeitreihen, um ein zusätzliches Signal abzufangen, das in früheren Verzögerungen verborgen ist. Unsere Zeitreihe ist ein zweidimensionaler Tensor mit Größe: die Länge der Sequenz auf der Darstellung unserer Zustandsaktion.
Präsentationen
Das preisgekrönte Engineering Potential Based Reward Shaping (PBRS), basierend auf Potenzial, ist ein leistungsstarkes Tool, um die Geschwindigkeit und Stabilität zu erhöhen und nicht die Optimalität des Richtliniensuchprozesses zur Lösung unserer Umgebung zu verletzen. Ich empfehle, mindestens dieses Originaldokument zum Thema zu lesen:
people.eecs.berkeley.edu/~russell/papers/ml99-shaping.psDas Potenzial bestimmt, wie gut unser aktueller Status im Verhältnis zum Zielstatus ist, in den wir eintreten möchten. Eine schematische Ansicht, wie dies funktioniert:

Es gibt Optionen und Schwierigkeiten, die Sie nach Versuch und Irrtum verstehen könnten, und wir lassen diese Details weg, sodass Sie Ihre Hausaufgaben machen können.
Es ist noch eine weitere Sache zu erwähnen, nämlich dass PBRS durch Präsentationen gerechtfertigt werden kann, die eine Form von Expertenwissen (oder simuliertem Wissen) über das
nahezu optimale Verhalten des Agenten in der Umgebung darstellen. Es gibt eine Möglichkeit, solche Präsentationen für unsere Aufgabe mithilfe von Optimierungsschemata zu finden. Wir lassen die Details der Suche weg.
Die potenzielle Belohnung hat folgende Form (Gleichung 1):
r '= r + gamma * F (s') - F (s)
Dabei ist F das Potenzial des Staates und r die anfängliche Belohnung. Gamma ist der Abzinsungsfaktor (0: 1).
Mit diesen Gedanken fahren wir mit der Codierung fort.Implementierung in R.
Hier ist der neuronale Netzwerkcode, der auf der Keras-API basiert:
Debuggen Sie Ihre Entscheidung auf Ihr Gewissen ...
Ergebnisse und Vergleich
Lassen Sie uns gleich auf die Endergebnisse eingehen.
Hinweis: Alle Ergebnisse sind Punktschätzungen und können bei mehreren Läufen mit unterschiedlichen zufälligen Startseiten unterschiedlich sein.Der Vergleich beinhaltet:
- vorherige Version ohne LSTM und Präsentationen
- einfaches 2-Element-LSTM
- 4-Element-LSTM
- 4-Zellen-LSTM mit generierten PBRS-Belohnungen
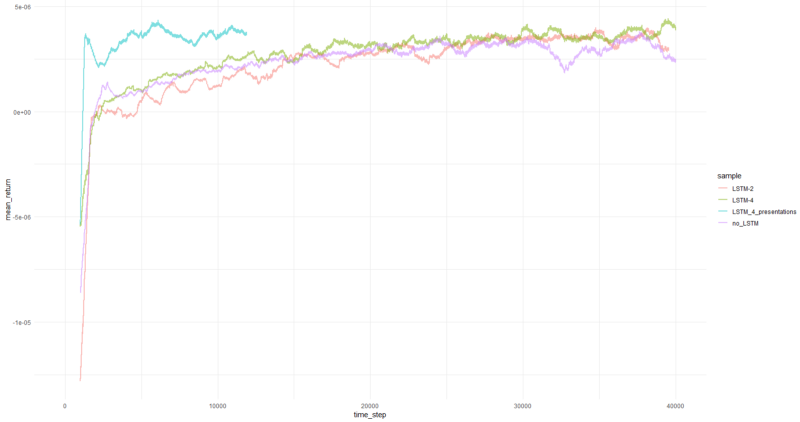
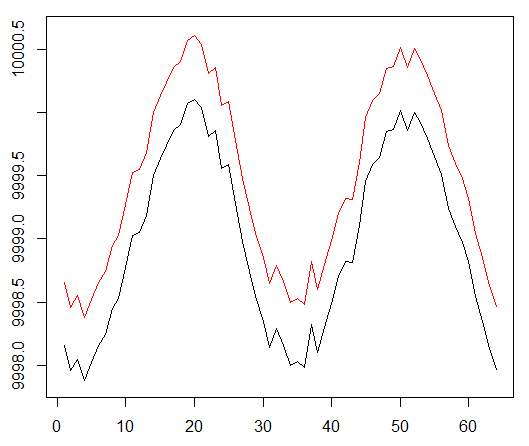
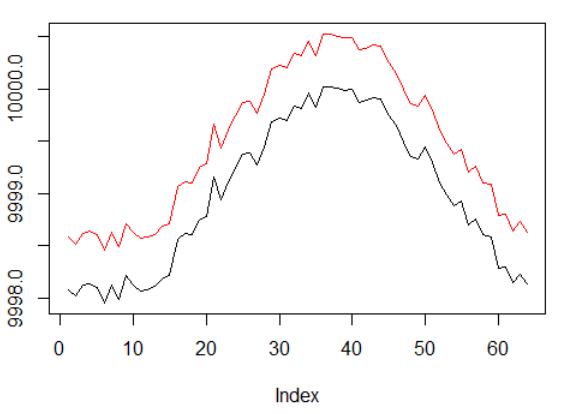
Die durchschnittliche Rendite pro Folge betrug durchschnittlich über 1000 Folgen.
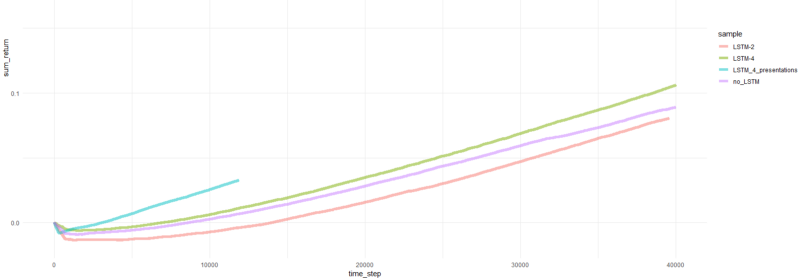
Die gesamte Folge kehrt zurück.
Diagramme für den erfolgreichsten Agenten:

Agentenleistung.
Nun, es ist ziemlich offensichtlich, dass der Agent in Form von PBRS im Vergleich zu früheren Versuchen so schnell und stabil konvergiert, dass er als signifikantes Ergebnis akzeptiert werden kann. Die Geschwindigkeit ist etwa 4-5 mal höher als ohne Präsentationen. Stabilität ist wunderbar.
Bei der Verwendung von LSTM zeigten 4 Zellen eine bessere Leistung als 2 Zellen. Ein 2-Zellen-LSTM schnitt besser ab als eine Nicht-LSTM-Version (dies ist jedoch möglicherweise eine Illusion eines einzelnen Experiments).
Letzte Worte
Wir haben gesehen, dass Wiederholungen und Kapazitätsaufbau helfen. Mir hat besonders gut gefallen, wie gut das PBRS abschneidet.
Glauben Sie niemandem, der mich dazu bringt zu sagen, dass es einfach ist, einen gut konvergierenden RL-Agenten zu erstellen, da dies eine Lüge ist. Jede neue Komponente, die dem System hinzugefügt wird, macht es möglicherweise weniger stabil und erfordert viel Konfiguration und Debugging.
Es gibt jedoch eindeutige Hinweise darauf, dass die Lösung des Problems einfach durch Verbesserung der verwendeten Methoden verbessert werden kann (die Daten blieben erhalten). Es ist eine Tatsache, dass für jede Aufgabe ein bestimmter Bereich von Parametern besser funktioniert als andere. In diesem Sinne beschreiten Sie einen erfolgreichen Lernpfad.
Vielen Dank.