Anfang 2018 haben wir aktiv den Prozess der Digitalisierung von Produktion und Prozessen im Unternehmen gestartet. In der Petrochemie ist dies nicht nur ein Modetrend, sondern ein neuer Evolutionsschritt zur Steigerung von Effizienz und Wettbewerbsfähigkeit. Angesichts der Besonderheiten des Geschäfts, das ohne Digitalisierung gute wirtschaftliche Ergebnisse erzielt, stehen die Digitalisierer vor einer schwierigen Aufgabe: Es ist eine mühsame Aufgabe, etablierte Prozesse im Unternehmen zu ändern.
Unsere Digitalisierung begann mit der Schaffung von zwei Zentren und ihren entsprechenden Funktionsblöcken.
Dies ist die „Digital Technology Function“, die alle Produktbereiche umfasst: Digitalisierung von Prozessen, IIoT und Advanced Analytics sowie ein Datenverwaltungszentrum, das zu einem unabhängigen Bereich geworden ist.

Die Hauptaufgabe des Datenbüros besteht darin, die auf Daten basierende Entscheidungskultur (ja, ja, datengesteuerte Entscheidung) vollständig umzusetzen und im Prinzip alles zu rationalisieren, was mit der Arbeit mit Daten zu tun hat: Analyse, Verarbeitung , Speicherung und Berichterstattung. Die Besonderheit ist, dass alle unsere digitalen Tools nicht nur ihre eigenen Daten aktiv nutzen müssen, dh diejenigen, die sie selbst generieren (z. B. mobile Umwege oder IIoT-Sensoren), sondern auch externe Daten, mit einem klaren Verständnis dafür, wo und warum sie benötigt werden zu verwenden.
Mein Name ist Artyom Danilov, ich bin der Leiter der Abteilung Infrastruktur und Technologie in SIBUR. In diesem Beitrag werde ich Ihnen erklären, wie und worauf wir ein großes Datenverarbeitungs- und Speichersystem für den gesamten SIBUR aufbauen. Zunächst werden wir nur über die Architektur auf höchster Ebene sprechen und darüber, wie Sie Teil unseres Teams werden können.
Hier sind die Bereiche, die die Arbeit in einem Datenbüro umfassen:
1. Arbeiten Sie mit DatenHier arbeiten die Leute, die aktiv an der Bestandsaufnahme und Katalogisierung unserer Daten beteiligt sind. Sie verstehen, welche Anforderungen eine bestimmte Funktion hat, können bestimmen, welche Art von Analyse erforderlich sein kann, welche Metriken für Entscheidungen überwacht werden sollten und wie Daten in einem bestimmten Geschäftsbereich verwendet werden.
2. BI- und DatenvisualisierungDie Richtung ist eng mit der ersten verbunden und ermöglicht es Ihnen, die Ergebnisse der Arbeit der Jungs aus dem ersten Team zu visualisieren.
3. Richtung der DatenqualitätskontrolleHier werden Tools zur Datenqualitätskontrolle vorgestellt und die gesamte Methodik dieser Kontrolle implementiert. Mit anderen Worten, die Mitarbeiter von hier implementieren Software, schreiben verschiedene Prüfungen und Tests, verstehen, wie Gegenprüfungen zwischen verschiedenen Systemen stattfinden, notieren die Funktionen der Mitarbeiter, die für die Datenqualität verantwortlich sind, und legen eine gemeinsame Methodik fest.
4. Management von NSIWir sind ein großes Unternehmen. Wir haben viele verschiedene Arten von Verzeichnissen - und Auftragnehmern und Materialien sowie ein Verzeichnis von Unternehmen ... Glauben Sie mir im Allgemeinen, es gibt mehr als genug Verzeichnisse.
Wenn ein Unternehmen aktiv etwas für seine Aktivitäten kauft, verfügt es normalerweise über spezielle Prozesse zum Ausfüllen dieser Verzeichnisse. Andernfalls wird das Chaos ein solches Niveau erreichen, dass es unmöglich ist, mit dem Wort „vollständig“ zu arbeiten. Wir haben auch ein solches System (MDM).
Hier sind die Probleme. Angenommen, in einer der regionalen Abteilungen, von denen wir viele haben, sitzen Mitarbeiter und geben Daten in das System ein. Tragen Sie von Hand bei, mit allen Konsequenzen, die sich aus dieser Methode ergeben. Das heißt, sie müssen Daten eingeben und überprüfen, ob alles in der richtigen Form und ohne Duplikate im System angekommen ist. Gleichzeitig müssen Sie beim Ausfüllen einiger Details und erforderlicher Felder einige Dinge unabhängig voneinander suchen und googeln. Sie haben beispielsweise eine Firmen-TIN und benötigen weitere Informationen - Sie überprüfen diese durch spezielle Dienste und das Register.
All diese Daten sind natürlich schon irgendwo, also wäre es richtig, sie einfach automatisch abzurufen.
Zuvor hatte das Unternehmen im Prinzip keine einzige Position, ein klares Team, das dies tun würde. Es gab viele verstreute Abteilungen, die Daten manuell eingaben. Für solche Strukturen ist es jedoch normalerweise schwierig, überhaupt zu formulieren, was genau und wo genau im Prozess der Arbeit mit Daten geändert werden muss, damit alles perfekt ist. Daher überprüfen wir das Format und die Verwaltungsstruktur des NSI.
5. Implementierung des Data Warehouse (Datenknoten)Genau das haben wir in diesem Bereich begonnen.
Definieren wir sofort die Begriffe, da sich sonst die von mir verwendeten Phrasen mit einigen anderen Konzepten überschneiden können. Grob gesagt, Datenknoten = Data Lake + Data Warehouse. Ein wenig weiter werde ich dies genauer offenbaren.
Architektur
Zunächst haben wir versucht herauszufinden, mit welchen Daten wir arbeiten sollen - welche Systeme gibt es, welche Sensoren. Wir haben verstanden, wie Streaming-Daten (das generieren die Unternehmen selbst aus all ihren Geräten, dies ist IIoT usw.) und klassische Systeme, verschiedene CRM-, ERP- und dergleichen aussehen würden.
Wir haben festgestellt, dass die Daten in den aktuellen Systemen nicht direkt genug sind, um ein sehr großes Volumen zu haben, aber mit der Einführung digitaler Tools und IIoT wird es viele davon geben. Und es wird auch sehr heterogene Daten aus klassischen Buchhaltungssystemen geben. Deshalb haben sie sich die Architektur eines solchen Plans ausgedacht.

Weitere Details zu den Blöcken.
Lagerung
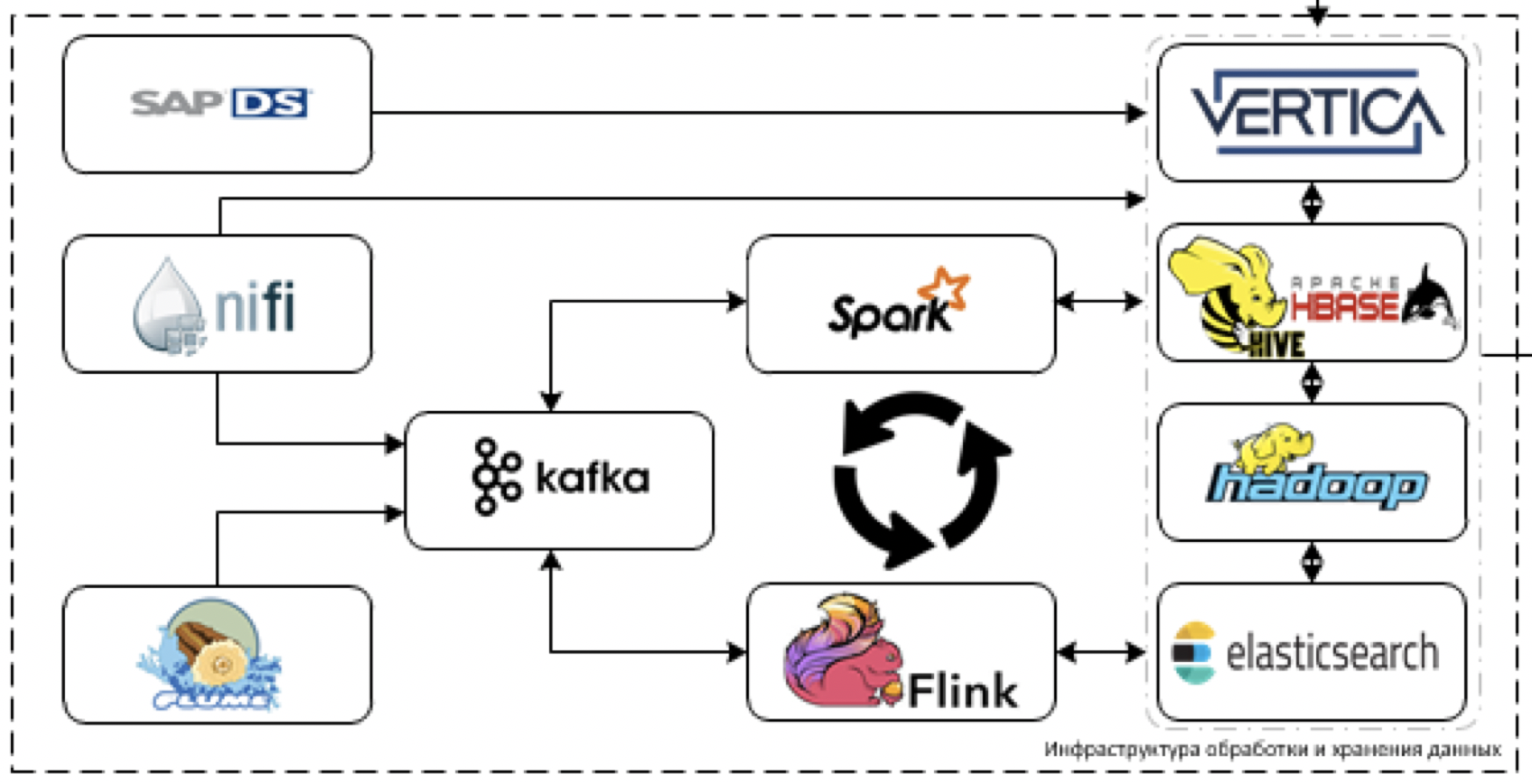
Dies ist der Kern unserer Plattform. Was wird verwendet, um Daten zu verarbeiten und zu speichern. Die Herausforderung besteht darin, Daten von mehr als 60 verschiedenen Systemen herunterzuladen, wenn sie mit der Bereitstellung beginnen. Das heißt, es gibt im Allgemeinen alle Daten, die für einige Entscheidungen nützlich sein können.
Beginnen wir mit der Extraktion und Verarbeitung von Daten. Für diese Zwecke planen wir, das NiFi-ETL-Tool für Streaming- und Paketdaten sowie Streaming-Verarbeitungstools zu verwenden: Flume für den anfänglichen Datenempfang und -decodierung, Kafka für die Pufferung, Flink- und Spark-Streaming als Haupttools für die Datenstromverarbeitung.
Am schwierigsten mit SAP-Stack-Systemen zu arbeiten. Sie müssen Daten mit einem separaten ETL-Tool - SAP Data Services - aus SAP abrufen.
Als Speicherwerkzeuge planen wir die Verwendung der Cloudera Hadoop-Plattform (HDFS, HBASE, Hive, Impala selbst), des analytischen DBMS von Vertica und im Einzelfall der Elasticsearch.
Grundsätzlich verwenden wir den fortschrittlichsten Stack. Ja, Sie können versuchen, Tomaten auf uns zu werfen und den so genannten modernsten Stapel zu verspotten, aber tatsächlich - das ist es.
Wir sind nicht auf die Legacy-Entwicklung beschränkt, können jedoch aufgrund der expliziten Unternehmensorientierung unserer Plattform nicht den neuesten Stand in einer industriellen Lösung nutzen. Vielleicht ziehen wir Horton nicht, sondern beschränken uns auf Clouder. Wo immer möglich, versuchen wir definitiv, ein neueres Werkzeug zu ziehen.

SAS-Datenqualität wird verwendet, um die Datenqualität zu steuern, und Airflow wird verwendet, um all diese Vorteile zu verwalten. Wir überwachen die gesamte Plattform über den ELK-Stack. Wir planen, die Visualisierung größtenteils in Tableau durchzuführen, einige vollständig statische Berichte in SAP BO.
Wir wissen bereits, dass ein Teil der Aufgaben nicht mit Standard-BI-Lösungen realisiert werden kann, da eine sehr ausgefeilte Echtzeitvisualisierung mit vielen Kartonsteuerungen erforderlich ist. Daher werden wir unser eigenes Visualisierungsframework schreiben, das in in Entwicklung befindliche digitale Produkte eingebettet werden könnte.
Über die digitale Plattform
Wenn Sie etwas breiter schauen, bauen unsere Kollegen aus der digitalen Technologiefunktion jetzt eine einzige digitale Plattform auf, deren Aufgabe es ist, schnell unsere eigenen Anwendungen zu entwickeln.
Der Datensee ist eines der Elemente dieser Plattform.
Im Rahmen dieser Aktivität müssen wir eine praktische Schnittstelle für den Zugriff auf Analysedaten implementieren. Daher planen wir die Implementierung der Daten-API und des Produktionsobjektmodells für einen bequemeren Zugriff auf Produktionsdaten.
Was machen wir noch und wen brauchen wir?
Neben dem Speichern und Verarbeiten von Daten funktioniert das gesamte maschinelle Lernen sowie das IIoT-Framework auf unserer Plattform. Der See wird sowohl als Datenquelle für Trainings- und Arbeitsmodelle als auch als Kapazität für Arbeitsmodelle dienen. Ein ML-Framework, das auf der Plattform funktioniert, ist bereits fertig.

Im Moment habe ich ein Team, ein paar Architekten und 6 Entwickler, daher suchen wir aktiv nach neuen Leuten (ich brauche
Datenarchitekten und
Dateningenieure ), die uns bei der Entwicklung der Plattform helfen. Sie müssen nicht im Vermächtnis herumstöbern (Vermächtnis ist hier nur am Eingang von den Systemen), der Stapel ist frisch.
Dort werden die Feinheiten sein - es liegt in den Integrationen. Das Alte mit dem Neuen zu verbinden, damit es gut funktioniert und Probleme löst, ist eine Herausforderung. Darüber hinaus müssen verschiedene Metriken erfunden, erarbeitet und aufgehängt werden.
Die Datenerfassung erfolgt in allen wichtigen Systemen - 1C, SAP und vielen anderen. Basierend auf den hier gesammelten Daten werden alle Analysen, alle Vorhersagen und alle digitalen Berichte erstellt.
Kurz gesagt, wir möchten, dass die Daten wirklich cool funktionieren. Zum Beispiel Marketing und Vertrieb - sie haben Leute, die alle Statistiken von Hand sammeln. Das heißt, sie sitzen und pumpen aus 5 verschiedenen Systemen unterschiedliche Daten in verschiedenen Formaten aus, laden sie aus 5 verschiedenen Programmen herunter und entladen sie dann in Excel. Dann fassen sie die Informationen in einheitlichen Excel-Tabellen zusammen und versuchen irgendwie, sie zu visualisieren.
Im Allgemeinen benötigt der Wagen die ganze Zeit. Wir wollen solche Probleme mit unserer Plattform lösen. In den folgenden Beiträgen erfahren Sie ausführlich, wie wir die Elemente miteinander verbunden und den korrekten Betrieb des Systems eingerichtet haben.
Übrigens, neben
Architekten und
Dateningenieuren in diesem Team werden wir uns freuen zu sehen: