Fantastic Dizzy ist ein Puzzle-Plattformspiel, das 1991 von Codemasters entwickelt wurde. Sie ist Teil der
Dizzy-Serie . Trotz der Tatsache, dass die Dizzy-Serie immer noch beliebt ist und Amateurspiele (
Dizzy Age ) erstellt, scheint niemand an der umgekehrten Entwicklung der ursprünglichen Spiele beteiligt gewesen zu sein.
Ich habe einige einfache Tools geschrieben, um die Ressourcen des Originalspiels zu extrahieren, anzuzeigen und zu verpacken. Auf
GitHub veröffentlichte Tools.
EXE auspacken
Die Binärdatei PCDIZZY.EXE ist im Microsoft
EXEPack- Format
gepackt . Obwohl es viele Linux-Tools gibt, die solche ausführbaren Dateien dekomprimieren können, scheint keines die für Fantastic Dizzy verwendete Version zu unterstützen. Daher habe ich zum Entpacken der ausführbaren Datei die DOS-Version von
UNP verwendet . Nach dem Entpacken der ausführbaren Datei kann sie auf die IDA heruntergeladen werden. Praktischerweise funktionierte die entpackte Version der Binärdatei immer noch gut, sodass sie mit dem DOSBox-Debugger debuggt werden konnte.
Datendateien
Es gibt zwei Datendateien im Spiel: DIZZY.NDX und DIZZY.RES. Erweiterungen sowie Dateigrößen geben uns einen Hinweis darauf, was sie enthalten könnten. Die NDX-Datei ist ungefähr 8 KB groß und die RES-Datei ist ungefähr 800 KB groß. Da das Spiel in C geschrieben ist, können wir offene Anrufe in der IDA durchsuchen, um zu sehen, wo die Datendateien geöffnet sind. In DOS-Spielen, die in Assembler geschrieben wurden, müssen Sie dazu nach Anweisungen in 21h suchen (um die Datei ah = 3d zu öffnen). Die Dizzy-Binärdatei enthält eine Wrapper-Funktion um fopen, mit der Sie den Hauptnamen und die Dateierweiterung angeben können. Es führt uns zu folgendem Codeblock:
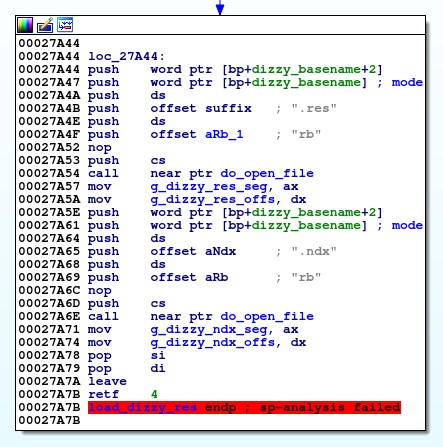
Es lädt die Dateien DIZZY.RES und DIZZY.NDX und speichert auch Dateizeiger in globalen Variablen. Beim Reverse Engineering von DOS-Binärdateien tritt ein lästiges Problem auf: Die darin enthaltenen Register sind 16-Bit-Register, in einigen Fällen können Zeiger jedoch 32-Bit-Register sein. Hier sind die FILE * -Zeiger 32 Bit groß und werden von do_open_file an ax: dx zurückgegeben. Beachten Sie, dass Zeichenfolgen auch 32-Bit-Zeiger sind und dizzy_basename an die aufrufende Funktion auf dem Stapel übergeben wird (und diese verwirrte IDA-Autoanalyse - sie wurde als Modusargument für fopen angesehen).
Indem Sie die Vorkommen von g_dizzy_res / ndx in xrefs nachschlagen, können Sie feststellen, wo die Dateien gelesen werden. Der DOSBox-Debugger ist an dieser Stelle nützlich, da eine hohe Wahrscheinlichkeit für viele zufällige Dateilesevorgänge besteht und die Verwendung der IDA zur Bestimmung der Leseversätze ein ziemlich monotoner Prozess wäre. Eine gute Anleitung zum Erstellen und Verwenden des DOSBox-Debuggers finden Sie
hier .
Wenn Sie den IDA- und den DOSBox-Debugger zusammen verwenden, wird deutlich, dass die NDX-Datei als Index für die RES-Datei verwendet wird. Jeder Eintrag in der NDX-Datei benötigt 16 Bytes. Es speichert die Fragmentkennung, ihre Größe und ihren Versatz in der RES-Datei. Wenn Sie sich ansehen, wie die RES-Daten gelesen werden, sehen Sie, dass das Flag-Byte zuerst in der NDX-Datei überprüft wird. Wenn das Bit 0x80 nicht gesetzt ist, werden Daten direkt aus der RES-Datei gelesen, andernfalls wird ein komplexerer Codepfad ausgeführt. Das Flag ist für die meisten Fragmente gesetzt, daher können wir mit hoher Wahrscheinlichkeit davon ausgehen, dass es eine Art Komprimierung bezeichnet, die für diese Fragmente verwendet wird.
Komprimierung
Der Komprimierungspfad beginnt mit dem Lesen von zwei 32-Bit-Wörtern aus der Basis des RES-Fragments, die die Anfangs- und Endgröße angeben, und dann wird die Dekomprimierungsfunktion aufgerufen. Im Jahr 1991 waren einfache Lauflängencodierung (RLE) und Wörterbuchkomprimierung beliebt, wie beispielsweise verschiedene Liv-Zempel-Algorithmen. Der Beginn des Auspackzyklus sieht folgendermaßen aus:
Token zum Entpacken werden mit der Funktion get_next_token erhalten, die den nächsten Teil der Quelldaten in ax: dx mit einer Verschiebung um cl liest. Das cl-Register wird als Position der Bitverschiebung verwendet und kehrt nach Erreichen von acht auf Null zurück. Zu Beginn des Zyklus wird das Token gelesen und das untere Bit überprüft. Wenn das Flag gesetzt ist, ist der Code einfach:
Es speichert nur das aktuelle Byte, empfängt das nächste Token und arbeitet weiter. Wenn das Flag gelöscht wird, wird ein längerer Codepfad ausgewählt, der mit dem Befehl rep movsb endet. Dies zeigt an, dass bei der Komprimierung eine Art Wörterbuch verwendet wird.
Der Komprimierungsalgorithmus ist aus mehreren Gründen interessant. Erstens wird eine Codierung mit variabler Bitlänge verwendet. Der Absolutwert wird als 1 Flag und als 8-Bit-Datenwert codiert. Seltsamerweise ist der Bitstrom als Little Endian codiert. Dies erschwert die Analyse der Dekomprimierung ein wenig, indem die RES-Datei in einem Hex-Editor beobachtet wird. Wenn beispielsweise die ersten drei Bytes eines Fragments als Absolutwerte codiert sind, sind die Daten wie folgt angeordnet:
: AAAAAAAA BBBBBBBB CCCCCCCC DDDDDDDD 1: 6543210F 7 2: 543210F 76 3: 43210F 765
Außerdem kann der Entpacker das Byte beim Lesen überspringen, wenn der Zähler cl beim Empfang des nächsten Tokens auf Null zurückkehrt. Ich weiß nicht, ob dies eine Optimierung, ein Fehler oder ein vom Spieleentwickler erstellter Hack ist, um das Problem mit meinen Tools zu beheben.
Wenn das Flag gelöscht ist, kopiert der Entpacker den ersten Teil der entpackten Daten. In diesem Fall codieren die folgenden Bits die Länge und den Versatz, von dem kopiert werden soll. Der Offset wird in 10 oder 13 Bit codiert, und die gewünschte Option gibt das Flag an. Dies scheint eine sehr seltsame Wahl zu sein, da es den Code ein wenig kompliziert und bestenfalls nur 2 Bits spart.
Das Codieren der Länge der Serie sieht etwas seltsam aus. Der Entpacker liest die Bits, bis sie das Nullbit erreichen. Dann beträgt die Anzahl der zum Codieren der Länge verwendeten Bits zwei plus die Anzahl der Nicht-Null-Bits. Wenn Sie beispielsweise eine Länge von 58 (0x3a) codieren, sieht der Bitstrom folgendermaßen aus:
11110 111010
Die Codierung erfordert 11 Bit. Kleine Längen werden besser codiert, da die minimale Bitlänge 2 beträgt. Das Kopieren von Längen bis zu 3 erfordert nur 3 Bit zum Codieren, bis zu 7 erfordern 5 Bit und so weiter. Ich weiß nicht genau, ob diese Art der Codierung eine übliche Technik ist.
Der DOSBox-Debugger ist auch sehr nützlich für die Rekonstruktion des Dekomprimierungsalgorithmus. Wenn Sie nicht wissen, wie die dekomprimierten Daten aussehen sollen, ist es schwierig zu verstehen, ob der Entpacker ordnungsgemäß funktioniert. Mit dem Debugger können Sie den gesamten Dekomprimierungsalgorithmus durchlaufen und zum Vergleich einen Speicherauszug entpackten Speichers speichern.
Eine weitere nützliche Funktion ist das Flag in der NDX-Datei, das angibt, dass die Ressource komprimiert ist. Da das ursprüngliche Spiel entpackte Ressourcen unterstützt, können wir die RES-Datei ohne Komprimierungsalgorithmus neu packen. Das Ändern und Umpacken von Fragmenten beim anschließenden Start des Spiels ist eine gute Möglichkeit, unsere Annahmen zu Datenformaten zu testen.
Ebenen
Fantastic Dizzy ist ein Spiel mit einer offenen Welt. Ebenen sind Bereiche mit vertikalem oder horizontalem Bildlauf. Der Spieler bewegt sich zwischen den Levels, erreicht das Ende des Levels oder betritt und verlässt Gebäude. Obwohl die Verweise auf die Fragmente in der RES-Datei über 16-Bit-Kennungen (IDs) erfolgen, enthält die Binärdatei des Spiels tatsächlich eine Tabelle mit übereinstimmenden Ebenennamen mit Fragmentkennungen. Jede Ebene besteht aus mehreren Fragmenten: einem Titel, einer oder mehreren Ebenen, einem Kachelsatz und einer Palette. Hier gibt es wenig Redundanz, da einige Ebenen dieselbe Palette und denselben Kachelsatz verwenden, jedoch nicht dieselben Fragmente wiederverwenden, sodass die RES-Datei viele doppelte Ressourcen enthält.
Ebenen codieren Kacheln für eine Ebene. Für verschiedene Teile der Welt oder für Hintergrundebenen können Sie zusätzliche Ebenen verwenden. Auf der Ebene von tree1.stg gibt es beispielsweise acht Ebenen für verschiedene Teile der Baumkronen und eine gemeinsame Hintergrundebene. Die Unterwasserstände sind jedoch in sea1.stg und sea2.stg unterteilt, von denen jede eine Vordergrundschicht und eine Hintergrundschicht aufweist.
Hintergrundebenen sind Hintergründe mit fester Breite ohne Bildlauf, z. B. ein Wald in einem Teil eines Spiels mit Baumkronen. Die Vordergrund- und Hintergrundkacheln, die sich vor und hinter dem Charakter befinden, werden in derselben Ebene wie die Kacheln codiert, auf denen Sie laufen können. Der Screenshot zeigt beispielsweise das Level von den Baumkronen zu Beginn des Spiels:
BaumkronenhöheEs ist die siebte Schicht von tree1.stg:
Baum der siebten Ebene tree1.stgEs ist erwähnenswert, dass der Spieler vor der Hütte, aber hinter zwei Bäumen vorbeikommen kann. Alle Kachelinformationen sind in einem Kachelkartenarray enthalten, das sich in einer Ebene befindet. Die Kacheln in den Fragmenten der Schicht werden in zwei Bytes codiert, und die unteren 9 Bits werden für den Kachelindex verwendet. Ich habe die oberen Bits nicht vollständig verstanden, aber zumindest enthalten sie Informationen über die Verschiebung der Palette für die Kachel und wahrscheinlich Informationen über Kollisionen.
Als Level im Spiel werden auch Zwischensequenzen, Charakterporträts und ein Bildschirm zur Bestandskontrolle gespeichert. Es scheint, dass diese Technik Standard für DOS-Spiele ist, wahrscheinlich weil sie die Menge an benötigtem Code minimiert.
"Ebene" der BestandsverwaltungSprites
Das Sprite-Format ist nicht besonders interessant. Jedes Sprite ist eine Bitmap mit einem Byte pro Pixel, aber nur 16 Farben pro Sprite. Die Verwendung einer begrenzten Anzahl von Farben war im Zeitalter von 256-Farben-VGA eine übliche Technik, da es für Sprites einfach war, eine Palettenverschiebung durchzuführen oder sie in Ebenen mit anderen Paletten zu verwenden. Außerdem wurde der für Sprites zugewiesene Speicherplatz gespart.
Sprites haben unterschiedliche Größen, daher enthält ein separates Fragment Informationen über die Größe des Sprites und ihre Verschiebungen in x und y. Sprites werden in Gruppen gruppiert, aber die Gruppierung sieht ziemlich willkürlich aus. Ein Satz von Sprites enthält beispielsweise Bildschirmschoner-Grafiken, Inventarobjekte sowie einige Nicht-Spieler-Charaktere. Dies macht das Anzeigen von Sprite-Sets etwas schwierig, da die Palette nicht für alle Sprites gleich ist.
Spielercharakter-SpritesWas bleibt noch übrig?
Es bleibt noch ein paar Dinge zurückzuentwickeln. Ich interessiere mich hauptsächlich für Datendateiformate, aber es gibt einige Aspekte, die ich nicht verstehe:
- Wo befinden sich die Objekte (Schlüssel, Früchte usw.)? Es scheint, dass sie nicht in Ebenenfragmente geschrieben sind. Vielleicht sind sie in der Binärdatei des Spiels gespeichert, weil der Spieler ein Objekt auf einer Ebene aufnehmen und auf eine andere werfen kann.
- Wie Levelkollisionen funktionieren. Ein Spieler kann vor oder hinter einige Kacheln gehen und die Böden können flach oder geneigt sein.
- Wie die Ebenen verbunden sind. Diese Informationen können in der Binärdatei des Spiels gespeichert werden.
- Die Verschiebung der Palette für Kacheln auf den Ebenen ist nicht ganz korrekt. Einige Kacheln zeigen falsche Farben an.
- Jeder Sprite-Satz enthält drei Fragmente: Header, Tabelle und Daten. Fragmente mit einer Tabelle und Daten sind mir klar, aber einige Informationen zu Sprites sind in der Kopfzeile enthalten, z. B. der Versatz um x und y. Ich habe das Format nicht vollständig verstanden.