Mit der Verbreitung und Entwicklung neuronaler Netze besteht ein zunehmender Bedarf, sie auf eingebetteten Geräten, Robotern und Drohnen mit geringem Stromverbrauch einzusetzen. Mit dem Neural Compute Stick-Gerät in Verbindung mit dem Intel OpenVINO-Framework können wir dieses Problem lösen, indem wir die umfangreichen Berechnungen neuronaler Netze übernehmen. Dank dieser Funktion können Sie auf einfache Weise einen Klassifikator oder Detektor für neuronale Netze auf einem Gerät mit geringem Stromverbrauch wie dem Raspberry Pi in nahezu Echtzeit starten, ohne den Energieverbrauch erheblich zu erhöhen. In diesem Beitrag zeige ich Ihnen, wie Sie mit dem OpenVINO-Framework (in C ++) und dem Neural Compute Stick ein einfaches Gesichtserkennungssystem auf dem Raspberry Pi starten.
Wie üblich ist der gesamte Code auf
GitHub verfügbar.

Ein bisschen über Neural Compute Stick und OpenVINO
Im Sommer 2017 veröffentlichte Intel das NCS-Gerät (
Neural Compute Stick ), mit dem neuronale Netze auf Geräten mit geringem Stromverbrauch betrieben werden können. Nach einigen Monaten konnte es gekauft und getestet werden, was ich auch tat. NCS ist ein kleines Computermodul mit einem Gehäuse in azurblauer Farbe (das auch als Heizkörper fungiert), das über USB mit dem Hauptgerät verbunden ist. Im Inneren befindet sich unter anderem die Intel Myriad
VPU , bei der es sich im Wesentlichen um einen 12-Kern-Parallelprozessor handelt, der für Vorgänge geschärft wurde, die häufig in neuronalen Netzen auftreten. NCS ist nicht zum Trainieren neuronaler Netze geeignet, aber die Inferenz in bereits trainierten neuronalen Netzen ist in der Geschwindigkeit mit der auf der GPU vergleichbar. Alle Berechnungen in NCS werden mit 16-Bit-Gleitkommazahlen durchgeführt, wodurch Sie die Geschwindigkeit erhöhen können. NCS benötigt zum Betrieb nur 1 Watt Leistung, dh bei 5 V wird am USB-Anschluss ein Strom von bis zu 200 mA verbraucht - dies ist sogar weniger als bei der Kamera für den Raspberry Pi (250 mA).

Für die Arbeit mit dem ersten NCS wurde das
Neural Compute SDK (NCSDK) verwendet: Es enthält Tools zum Kompilieren neuronaler Netze im
Caffe- und
TensorFlow- Format im NCS-Format, Tools zum Messen ihrer Leistung sowie die Python- und C ++ - API zur Inferenz.
Dann wurde eine neue Version des NCS-Frameworks veröffentlicht:
NCSDK2 . Die API hat sich stark verändert, und obwohl mir einige Änderungen seltsam erschienen, gab es einige nützliche Neuerungen. Insbesondere wurde die automatische Konvertierung von Float 32 Bit zu Float 16 Bit nach C ++ hinzugefügt (früher mussten Krücken in Form von Code von Numpy eingefügt werden). Auch erschienen Warteschlangen von Bildern und die Ergebnisse ihrer Verarbeitung.
Im Mai 2018 veröffentlichte Intel
OpenVINO (früher Intel Computer Vision SDK genannt). Dieses Framework wurde entwickelt, um neuronale Netze auf verschiedenen Geräten effizient zu starten: Intel-Prozessoren und Grafikkarten,
FPGA sowie der Neural Compute Stick.
Im November 2018 wurde eine neue Version des Beschleunigers veröffentlicht:
Neural Compute Stick 2 . Die Rechenleistung des Geräts wurde erhöht: In der Beschreibung auf der Website versprechen sie eine Beschleunigung auf das 8-fache, ich konnte die neue Version des Geräts jedoch nicht testen. Die Beschleunigung wird erreicht, indem die Anzahl der Kerne von 12 auf 16 erhöht und neue für neuronale Netze optimierte Computergeräte hinzugefügt werden. Es stimmt, ich habe keine Informationen über den Stromverbrauch von Informationen gefunden.
Die zweite Version von NCS ist bereits nicht mit NCSDK oder NCSDK2 kompatibel: OpenVINO, das neben beiden Versionen von NCS mit vielen anderen Geräten arbeiten kann, hat seine Berechtigung bestanden. OpenVINO selbst verfügt über eine hervorragende Funktionalität und umfasst die folgenden Komponenten:
- Modelloptimierer: Python-Skript, mit dem Sie neuronale Netze aus gängigen Deep-Learning-Frameworks in das universelle OpenVINO-Format konvertieren können. Die Liste der unterstützten Frameworks: Caffe , TensorFlow , MXNET , Kaldi (Spracherkennungs-Framework), ONNX (offenes Format zur Darstellung neuronaler Netze).
- Inference Engine: C ++ - und Python-API für die Inferenz neuronaler Netzwerke, abstrahiert von einem bestimmten Inferenzgerät. Der API-Code sieht für CPU, GPU, FPGA und NCS nahezu identisch aus.
- Eine Reihe von Plugins für verschiedene Geräte. Plugins sind dynamische Bibliotheken, die explizit in den Code des Hauptprogramms geladen werden. Das Plugin für NCS interessiert uns am meisten.
- Eine Reihe vorgefertigter Modelle im universellen OpenVINO-Format (die vollständige Liste finden Sie hier ). Eine beeindruckende Sammlung hochwertiger neuronaler Netze: Detektoren von Gesichtern, Fußgängern, Objekten; Erkennen der Ausrichtung von Gesichtern, speziellen Gesichtspunkten, menschlichen Körperhaltungen; super Auflösung; und andere. Es ist erwähnenswert, dass nicht alle von NCS / FPGA / GPU unterstützt werden.
- Model Downloader: Ein weiteres Skript, das das Herunterladen von Modellen im OpenVINO-Format über das Netzwerk vereinfacht (obwohl Sie problemlos darauf verzichten können).
- OpenCV Computer Vision Library optimiert für Intel Hardware.
- Bibliothek für Computer Vision OpenVX .
- Intel Compute Library für tiefe neuronale Netze .
- Intel Math Kernel Library für tiefe neuronale Netze .
- Ein Tool zur Optimierung neuronaler Netze für FPGA (optional).
- Dokumentations- und Beispielprogramme.
In meinen vorherigen Artikeln habe ich darüber gesprochen, wie der YOLO-Gesichtsdetektor auf dem NCS ausgeführt wird
(erster Artikel) sowie wie Sie Ihren SSD-Gesichtsdetektor trainieren und auf dem Raspberry Pi und NCS ausführen
(zweiter Artikel) . In diesen Artikeln habe ich NCSDK und NCSDK2 verwendet. In diesem Artikel werde ich Ihnen erklären, wie Sie etwas Ähnliches tun, aber mit OpenVINO werde ich einen kleinen Vergleich zwischen verschiedenen Gesichtsdetektoren und zwei Frameworks für deren Start durchführen und auf einige Fallstricke hinweisen. Ich schreibe in C ++, weil ich glaube, dass Sie auf diese Weise eine bessere Leistung erzielen können, was im Fall von Raspberry Pi wichtig ist.
Installieren Sie OpenVINO
Nicht die schwierigste Aufgabe, obwohl es Feinheiten gibt. Zum Zeitpunkt des Schreibens unterstützt OpenVINO nur Ubuntu 16.04 LTS, CentOS 7.4 und Windows 10. Ich habe Ubuntu 18 installiert und benötige
kleine Krücken , um es zu installieren. Ich wollte OpenVINO auch mit NCSDK2 vergleichen, dessen Installation ebenfalls Probleme hat: Insbesondere werden die Versionen von Caffe und TensorFlow gestrafft und die Umgebungseinstellungen können leicht beschädigt werden. Am Ende entschied ich mich, einem einfachen Pfad zu folgen und beide Frameworks in einer virtuellen Maschine mit Ubuntu 16 zu installieren (ich verwende
VirtualBox ).
Beachten Sie, dass Sie zum erfolgreichen Verbinden von NCS mit einer virtuellen Maschine VirtualBox-Gast-Add-Ons installieren und die USB 3.0-Unterstützung aktivieren müssen. Ich habe auch einen Universalfilter für USB-Geräte hinzugefügt, wodurch das NCS problemlos verbunden wurde (obwohl die Webcam in den Einstellungen der virtuellen Maschine noch angeschlossen werden muss). Um OpenVINO zu installieren und zu kompilieren, benötigen Sie ein Intel-Konto, wählen Sie eine Framework-Option (mit oder ohne FPGA-Unterstützung) und befolgen Sie die
Anweisungen . NCSDK ist noch einfacher: Es startet
von GitHub (vergessen Sie nicht, den Zweig ncsdk2 für die neue Version des Frameworks auszuwählen). Danach müssen Sie
make install .
Das einzige Problem, auf das ich beim Ausführen von NCSDK2 in einer virtuellen Maschine gestoßen bin, ist ein Fehler der folgenden Form:
E: [ 0] dispatcherEventReceive:236 dispatcherEventReceive() Read failed -1 E: [ 0] eventReader:254 Failed to receive event, the device may have reset
Es tritt am Ende der korrekten Ausführung des Programms auf und hat (wie es scheint) keine Auswirkungen. Anscheinend ist dies ein
kleiner Fehler im Zusammenhang mit VM (dies sollte nicht auf Raspberry sein).
Die Installation auf dem Raspberry Pi unterscheidet sich erheblich. Stellen Sie zunächst sicher, dass Sie Raspbian Stretch installiert haben: Beide Frameworks funktionieren offiziell nur auf diesem Betriebssystem. NCSDK2 muss
im Nur-API-Modus kompiliert werden , andernfalls wird versucht, Caffe und TensorFlow zu installieren, was Ihrer Himbeere wahrscheinlich nicht gefällt. Im Fall von OpenVINO gibt es eine bereits
zusammengestellte Version für Raspberry , die Sie nur zum Entpacken und Konfigurieren der Umgebungsvariablen benötigen. In dieser Version gibt es nur die C ++ - und Python-API sowie die OpenCV-Bibliothek, alle anderen Tools sind nicht verfügbar. Dies bedeutet, dass für beide Frameworks Modelle auf einem Computer mit Ubuntu im Voraus konvertiert werden müssen. Meine
Gesichtserkennungsdemo funktioniert sowohl auf Raspberry als auch auf dem Desktop. Daher habe ich die konvertierten neuronalen Netzwerkdateien meinem GitHub-Repository hinzugefügt, um die Synchronisierung mit Raspberry zu vereinfachen. Ich habe ein Raspberry Pi 2 Modell B, aber es sollte mit anderen Modellen abheben.
Es gibt noch eine weitere Feinheit in Bezug auf das Zusammenspiel von Raspberry Pi und Neural Compute Stick: Wenn es bei einem Laptop ausreicht, das NCS nur in den nächsten USB 3.0-Anschluss zu stecken, müssen Sie für Raspberry ein USB-Kabel finden, andernfalls blockiert NSC die verbleibenden drei USB-Anschlüsse mit seinem Gehäuse. Es ist auch zu beachten, dass Raspberry über alle USB 2.0-Versionen verfügt, sodass die Inferenzrate aufgrund von Kommunikationsverzögerungen geringer ist (ein detaillierter Vergleich wird später erfolgen). Wenn Sie jedoch zwei oder mehr NCS an Raspberry anschließen möchten, müssen Sie höchstwahrscheinlich einen USB-Hub mit zusätzlicher Stromversorgung finden.
Wie sieht OpenVINO-Code aus?
Ziemlich sperrig. Es gibt viele verschiedene Aktionen, angefangen beim Laden des Plug-Ins bis hin zur Inferenz selbst. Deshalb habe ich eine Wrapper-Klasse für den Detektor geschrieben. Der vollständige Code kann auf GitHub angezeigt werden, aber hier liste ich nur die wichtigsten Punkte auf. Beginnen wir in der richtigen Reihenfolge:
Die Definitionen aller benötigten Funktionen befinden sich in der Datei
inference_engine.hpp im
InferenceEngine Namespace.
#include <inference_engine.hpp> using namespace InferenceEngine;
Die folgenden Variablen werden ständig benötigt. Wir benötigen
inputName und
outputName , um die Eingabe und Ausgabe des neuronalen Netzwerks zu adressieren. Im Allgemeinen kann ein neuronales Netzwerk viele Ein- und Ausgänge haben, aber in unseren Detektoren gibt es jeweils einen. Das variable
net ist das Netzwerk selbst, die
request ist ein Zeiger auf die letzte Inferenzanforderung,
inputBlob ist ein Zeiger auf das Eingabedatenarray des neuronalen Netzwerks. Die übrigen Variablen sprechen für sich.
string inputName; string outputName; ExecutableNetwork net; InferRequest::Ptr request; Blob::Ptr inputBlob;
Laden Sie jetzt das erforderliche Plugin herunter - wir benötigen das für NCS und NCS2 zuständige, es kann unter dem Namen "MYRIAD" bezogen werden. Ich möchte Sie daran erinnern, dass ein Plugin im Kontext von OpenVINO nur eine dynamische Bibliothek ist, die auf ausdrückliche Anfrage eine Verbindung herstellt. Der Parameter der
PluginDispatcher Funktion ist eine Liste von Verzeichnissen, in denen nach Plugins
PluginDispatcher werden soll. Wenn Sie die Umgebungsvariablen gemäß den Anweisungen einrichten, reicht eine leere Zeile aus. Als Referenz befinden sich Plugins in
[OpenVINO_install_dir]/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64/ InferencePlugin plugin = PluginDispatcher({""}).getPluginByDevice("MYRIAD");
Erstellen Sie nun ein Objekt zum Laden des neuronalen Netzwerks, berücksichtigen Sie dessen Beschreibung und legen Sie die Größe des Stapels fest (die Anzahl der gleichzeitig verarbeiteten Bilder). Ein neuronales Netzwerk im OpenVINO-Format wird durch zwei Dateien definiert: eine XML-Datei mit einer Beschreibung der Struktur und eine Bin-Datei mit Gewichten. Während wir vorgefertigte Detektoren von OpenVINO verwenden, werden wir später unsere eigenen erstellen. Hier ist
std::string filename der Name der Datei ohne die Erweiterung. Beachten Sie außerdem, dass das NCS nur eine Stapelgröße von 1 unterstützt.
CNNNetReader netReader; netReader.ReadNetwork(filename+".xml"); netReader.ReadWeights(filename+".bin"); netReader.getNetwork().setBatchSize(1);
Dann passiert folgendes:
- Um in das neuronale Netzwerk einzutreten, setzen Sie den Datentyp auf vorzeichenloses 8-Bit-Zeichen. Dies bedeutet, dass wir das Bild in dem Format eingeben können, in dem es von der Kamera stammt, und InferenceEngine sich um die Konvertierung kümmert (NCS führt Berechnungen im Float-16-Bit-Format durch). Dies beschleunigt sich auf dem Raspberry Pi etwas - so wie ich es verstehe, erfolgt die Konvertierung auf dem NCS, sodass die Datenübertragung über USB weniger verzögert wird.
- Wir erhalten die Eingabe- und Ausgabenamen, damit wir später darauf zugreifen können.
- Wir erhalten die Beschreibung der Ausgaben (dies ist eine Zuordnung vom Namen der Ausgabe zu einem Zeiger auf einen Datenblock). Wir erhalten einen Zeiger auf den Datenblock der ersten (einzelnen) Ausgabe.
- Wir erhalten seine Größe: 1 x 1 x maximale Anzahl von Erkennungen x Länge der Beschreibung der Erkennung (7). Über das Format der Beschreibung von Erkennungen - später.
- Stellen Sie das Ausgabeformat auf 32 Bit ein. Auch hier kümmert sich die Konvertierung von Float 16 Bit um InferenceEngine.
Nun der wichtigste Punkt: Wir laden das neuronale Netzwerk in das Plugin (dh in NCS). Anscheinend ist das Kompilieren im gewünschten Format im laufenden Betrieb. Wenn das Programm bei dieser Funktion abstürzt, ist das neuronale Netzwerk wahrscheinlich nicht für dieses Gerät geeignet.
net = plugin.LoadNetwork(netReader.getNetwork(), {});
Und schließlich - wir werden Versuchsschluss ziehen und die Eingabegrößen ermitteln (möglicherweise kann dies eleganter erfolgen). Zuerst öffnen wir eine Inferenzanforderung, dann erhalten wir daraus einen Link zum Eingabedatenblock, und wir fordern bereits die Größe von ihm an.
Versuchen wir, ein Bild in NCS hochzuladen. Auf die gleiche Weise erstellen wir eine Inferenzanforderung, erhalten daraus einen Zeiger auf einen Datenblock und von dort einen Zeiger auf das Array selbst. Als nächstes kopieren Sie einfach die Daten aus unserem Bild (hier sind sie bereits auf die gewünschte Größe reduziert). Es ist erwähnenswert, dass in
cv::Mat und
inputBlob Messungen in unterschiedlicher Reihenfolge gespeichert werden (in OpenCV ändert sich der Kanalindex schneller als alle, in OpenVINO ist er langsamer als alle), daher ist memcpy unverzichtbar. Dann beginnen wir mit der asynchronen Inferenz.
Warum asynchron? Dadurch wird die Ressourcenzuweisung optimiert. Während das NCS das neuronale Netzwerk berücksichtigt, können Sie den nächsten Frame verarbeiten - dies führt zu einer spürbaren Beschleunigung des Raspberry Pi.
cv::Mat data; ...
Wenn Sie mit neuronalen Netzen gut vertraut sind, haben Sie möglicherweise eine Frage, an welchem Punkt wir die Werte der Eingangspixel des neuronalen Netzes skalieren (zum Beispiel bringen wir sie in den Bereich
) Tatsache ist, dass diese Transformation in OpenVINO-Modellen bereits in der Beschreibung des neuronalen Netzwerks enthalten ist, und wenn wir unseren Detektor verwenden, werden wir etwas Ähnliches tun. Und da sowohl die Konvertierung in Float als auch die Skalierung von Eingaben von OpenVINO durchgeführt werden, müssen wir nur die Größe des Bildes ändern.
Jetzt (nach einigen nützlichen Arbeiten) werden wir die Inferenzanfrage vervollständigen. Das Programm wird blockiert, bis die Ausführungsergebnisse vorliegen. Wir bekommen einen Zeiger auf das Ergebnis.
float * output; ncsCode = request->Wait(IInferRequest::WaitMode::RESULT_READY); output = request->GetBlob(outputName)->buffer().as<float*>();
Jetzt ist es an der Zeit zu überlegen, in welchem Format das NCS das Ergebnis des Detektors zurückgibt. Es ist erwähnenswert, dass sich das Format geringfügig von dem bei Verwendung von NCSDK unterscheidet. Im Allgemeinen ist der Detektorausgang vierdimensional und hat eine Dimension (1 x 1 x maximale Anzahl von Erkennungen x 7). Wir können davon ausgehen, dass dies ein Array der Größe ist (
maxNumDetectedFaces x 7).
Der Parameter
maxNumDetectedFaces wird in der Beschreibung des neuronalen Netzwerks festgelegt und kann leicht geändert werden, z. B. in der .prototxt-Beschreibung des Netzwerks im Caffe-Format. Früher haben wir es von dem Objekt bekommen, das den Detektor darstellt. Dieser Parameter bezieht sich auf die Besonderheiten der Klasse der
SSD- Detektoren
(Single Shot Detector) , die alle unterstützten NCS-Detektoren umfasst. Eine SSD berücksichtigt immer die gleiche (und sehr große) Anzahl von Begrenzungsrahmen für jedes Bild. Nach dem Herausfiltern von Erkennungen mit niedriger Konfidenzbewertung und dem Entfernen überlappender Frames mithilfe der nicht maximalen Unterdrückung belassen sie normalerweise die 100-200 besten Werte. Genau dafür ist der Parameter verantwortlich.
Die sieben Werte in der Beschreibung einer Erkennung lauten wie folgt:
- die Bildnummer in dem Stapel, auf dem das Objekt erkannt wird (in unserem Fall sollte sie Null sein);
- Objektklasse (0 - Hintergrund, beginnend mit 1 - andere Klassen, nur Erkennungen mit einer positiven Klasse werden zurückgegeben);
- Vertrauen in das Vorhandensein von Erkennung (im Bereich );
- normalisierte x-Koordinate der oberen linken Ecke des Begrenzungsrahmens (im Bereich) );
- ähnlich - y-Koordinate;
- normalisierte Begrenzungsrahmenbreite (im Bereich );
- ebenfalls - Höhe;
Code zum Extrahieren von Begrenzungsrahmen aus der Detektorausgabe void get_detection_boxes(const float* predictions, int numPred, int w, int h, float thresh, std::vector<float>& probs, std::vector<cv::Rect>& boxes) { float score = 0; float cls = 0; float id = 0;
Wir lernen
numPred vom Detektor selbst und
w,h - Bildgrößen zur Visualisierung.
Nun dazu, wie das allgemeine Inferenzschema in Echtzeit aussieht. Zuerst initialisieren wir das neuronale Netzwerk und die Kamera, starten
cv::Mat für Rohbilder und eines für Bilder, die auf die gewünschte Größe reduziert sind. Wir füllen unsere Frames mit Nullen - dies erhöht die Sicherheit, dass das neuronale Netzwerk bei einem einzigen Start nichts findet. Dann starten wir den Inferenzzyklus:
- Wir laden den aktuellen Frame mithilfe einer asynchronen Anforderung in das neuronale Netzwerk - NCS hat bereits begonnen zu arbeiten, und zu diesem Zeitpunkt haben wir die Möglichkeit, nützliche Arbeit zum Hauptprozessor zu machen.
- Wir zeigen alle vorherigen Erkennungen im vorherigen Frame an und zeichnen einen Frame (falls erforderlich).
- Wir bekommen einen neuen Rahmen von der Kamera, komprimieren ihn auf die gewünschte Größe. Für Raspberry empfehle ich die Verwendung des einfachsten Größenänderungsalgorithmus - in OpenCV ist dies die Interpolation der nächsten Nachbarn. Dies hat keinen Einfluss auf die Qualität der Detektorleistung, kann jedoch die Geschwindigkeit erhöhen. Ich spiegele auch den Rahmen für eine einfache Visualisierung (optional).
- Jetzt ist es an der Zeit, das Ergebnis mit NCS zu erhalten, indem Sie die Inferenzanforderung abschließen. Das Programm wird blockiert, bis das Ergebnis eingeht.
- Wir verarbeiten neue Erkennungen, wählen Frames aus.
- Der Rest: Tastenanschläge trainieren, Frames zählen usw.
Wie man es kompiliert
In den InferenceEngine-Beispielen haben mir die umfangreichen CMake-Dateien nicht gefallen, und ich habe beschlossen, alles kompakt in mein Makefile umzuschreiben:
g++ $(RPI_ARCH) \ -I/usr/include -I. \ -I$(OPENVINO_PATH)/deployment_tools/inference_engine/include \ -I$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/include \ -L/usr/lib/x86_64-linux-gnu \ -L/usr/local/lib \ -L$(OPENVINO_PATH)/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64 \ -L$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/lib/raspbian_9/armv7l \ vino.cpp wrapper/vino_wrapper.cpp \ -o demo -std=c++11 \ `pkg-config opencv --cflags --libs` \ -ldl -linference_engine $(RPI_LIBS)
Dieses Team wird dank einiger Tricks sowohl an Ubuntu als auch an Raspbian arbeiten. Die Pfade für die Suche nach Headern und dynamischen Bibliotheken habe ich sowohl für Raspberry als auch für die Ubuntu-Maschine angegeben. Von den Bibliotheken müssen Sie neben OpenCV auch
libinference_engine und
libdl - eine Bibliothek zum dynamischen Verknüpfen anderer Bibliotheken, die zum Laden des Plugins benötigt wird. Gleichzeitig muss
libmyriadPlugin selbst nicht angegeben werden. Unter anderem verbinde ich für Raspberry auch die
Raspicam- Bibliothek für die Arbeit mit der Kamera (dies ist
$(RPI_LIBS) ). Ich musste auch den C ++ 11 Standard verwenden.
-march=armv7-a davon ist zu beachten, dass beim Kompilieren auf Raspberry das
-march=armv7-a benötigt wird (dies ist
$(RPI_ARCH) ). Wenn Sie es nicht angeben, wird das Programm kompiliert, stürzt jedoch mit einem stillen Segfault ab. Sie können auch Optimierungen mit
-O3 hinzufügen, um die Geschwindigkeit zu erhöhen.
Was sind die Detektoren
NCS unterstützt nur Caffe SSD-Detektoren aus der Box, obwohl ich es mit ein paar schmutzigen Tricks geschafft habe,
YOLO im Darknet-Format darauf auszuführen.
Single Shot Detector (SSD) ist eine beliebte Architektur unter leichten neuronalen Netzen. Mithilfe verschiedener Encoder (oder Backbone-Netze) können Sie das Verhältnis von Geschwindigkeit und Qualität sehr flexibel variieren.
Ich werde mit verschiedenen Gesichtsdetektoren experimentieren:
- Von hier übernommen wurde YOLO zuerst in das Caffe-Format und dann in das NCS-Format konvertiert (nur mit NCSDK). Bild 448 x 448.
- Mein Mobilenet + SSD-Detektor, über dessen Training ich in einer früheren Veröffentlichung gesprochen habe . Ich habe immer noch eine beschnittene Version dieses Detektors, der nur kleine Gesichter sieht und gleichzeitig etwas schneller ist. Ich werde die Vollversion meines Detektors sowohl auf NCSDK als auch auf OpenVINO überprüfen. Bild 300 x 300.
- Detektor Gesichtserkennung-adas-0001 von OpenVINO: MobileNet + SSD. Bild 384 x 672.
- OpenVINO Gesichtserkennungs-Retail-0004-Detektor: Leichtes SqueezeNet + SSD. Bild 300 x 300.
Für Detektoren von OpenVINO gibt es weder im Caffe-Format noch im NCSDK-Format Skalen, daher kann ich sie nur in OpenVINO starten.
Verwandeln Sie Ihren Detektor in das OpenVINO-Format
Ich habe zwei Dateien im Caffe-Format: .prototxt mit einer Beschreibung des Netzwerks und .caffemodel mit Gewichten. Ich muss zwei Dateien im OpenVINO-Format von ihnen erhalten: .xml und .bin mit einer Beschreibung bzw. Gewichtung. Verwenden Sie dazu das Skript mo.py von OpenVINO (auch bekannt als Model Optimizer):
mo.py \ --framework caffe \ --input_proto models/face/ssd-face.prototxt \ --input_model models/face/ssd-face.caffemodel \ --output_dir models/face \ --model_name ssd-vino-custom \ --mean_values [127.5,127.5,127.5] \ --scale_values [127.5,127.5,127.5] \ --data_type FP16
output_dir gibt das Verzeichnis an, in dem neue Dateien erstellt werden.
model_name ist der Name für neue Dateien ohne Erweiterung.
data_type (FP16/FP32) ist die Art des Guthabens im neuronalen Netzwerk (NCS unterstützt nur FP16). Die
mean_values, scale_values legen den Durchschnitt und die Skalierung für die Vorverarbeitung der Bilder fest, bevor sie in das neuronale Netzwerk gestartet werden. Die spezifische Konvertierung sieht folgendermaßen aus:
In diesem Fall werden die Werte aus dem Bereich konvertiert
in Reichweite
. Im Allgemeinen enthält dieses Skript viele Parameter, von denen einige für einzelne Frameworks spezifisch sind. Ich empfehle, dass Sie sich das Handbuch für das Skript ansehen.
Die OpenVINO-Distribution für Raspberry enthält keine vorgefertigten Modelle, sie sind jedoch recht einfach herunterzuladen.
Zum Beispiel so. wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.xml \ -O ./models/face/vino.xml; \ wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.bin \ -O ./models/face/vino.bin
Vergleich von Detektoren und Frameworks
Ich habe drei Vergleichsoptionen verwendet: 1) NCS + Virtual Machine mit Ubuntu 16.04, Core i7-Prozessor, USB 3.0-Anschluss; 2) NCS + Dieselbe Maschine, USB 3.0-Anschluss + USB 2.0-Kabel (der Austausch mit dem Gerät verzögert sich länger); 3) NCS + Raspberry Pi 2 Modell B, Raspbian Stretch, USB 2.0-Anschluss + USB 2.0-Kabel.
Ich habe meinen Detektor sowohl mit OpenVINO als auch mit NCSDK2 gestartet, Detektoren von OpenVINO nur mit ihrem nativen Framework, YOLO nur mit NCSDK2 (höchstwahrscheinlich kann er auch unter OpenVINO ausgeführt werden).
Die FPS-Tabelle für verschiedene Detektoren sieht folgendermaßen aus (die Zahlen sind ungefähr):
| Modell | USB 3.0 | USB 2.0 | Himbeer pi |
|---|
| Benutzerdefinierte SSD mit NCSDK2 | 10.8 | 9.3 | 7.2 |
| Benutzerdefinierte Langstrecken-SSD mit NCSDK2 | 11.8 | 10.0 | 7.3 |
| YOLO v2 mit NCSDK2 | 5.3 | 4.6 | 3.6 |
| Benutzerdefinierte SSD mit OpenVINO | 10.6 | 9.9 | 7.9 |
| OpenVINO Gesichtserkennung-Einzelhandel-0004 | 15.6 | 14.2 | 9.3 |
| OpenVINO Gesichtserkennung-adas-0001 | 5.8 | 5.5 | 3.9 |
Hinweis: Die Leistung wurde für das gesamte Demo-Programm gemessen, einschließlich der Verarbeitung und Visualisierung von Frames.YOLO war der langsamste und instabilste von allen. Es überspringt sehr oft die Erkennung und kann nicht mit beleuchteten Rahmen arbeiten.
Der von mir trainierte Detektor arbeitet doppelt so schnell, ist widerstandsfähiger gegen Bildverzerrungen und erkennt sogar kleine Gesichter. Manchmal wird jedoch die Erkennung übersprungen und manchmal werden falsche erkannt. Wenn Sie die letzten Schichten davon abschneiden, wird es etwas schneller, aber es werden keine großen Gesichter mehr angezeigt. Derselbe über OpenVINO gestartete Detektor wird bei Verwendung von USB 2.0 etwas schneller, die Qualität ändert sich optisch nicht.
Die OpenVINO-Detektoren sind natürlich sowohl YOLO als auch meinem Detektor weit überlegen. (Ich würde nicht einmal anfangen, meinen Detektor zu trainieren, wenn OpenVINO zu diesem Zeitpunkt in seiner aktuellen Form existieren würde). Das Retail-0004-Modell ist deutlich schneller und verfehlt gleichzeitig praktisch nicht das Gesicht, aber ich habe es geschafft, es ein wenig zu täuschen (obwohl das Vertrauen in diese Erkennungen gering ist):
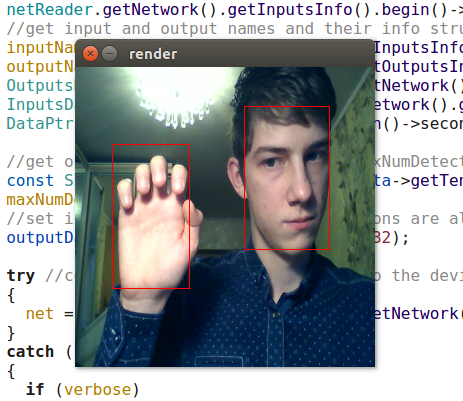 Wettbewerbsangriff der natürlichen Intelligenz auf künstliche
Wettbewerbsangriff der natürlichen Intelligenz auf künstlicheDer adas-0001-Detektor ist viel langsamer, funktioniert jedoch mit großen Bildern und sollte genauer sein. Ich habe den Unterschied nicht bemerkt, aber ich habe ziemlich einfache Frames überprüft.
Fazit
Im Allgemeinen ist es sehr schön, dass Sie auf einem Gerät mit geringem Stromverbrauch wie dem Raspberry Pi neuronale Netze verwenden können, und zwar fast in Echtzeit. OpenVINO bietet sehr umfangreiche Funktionen für die Inferenz neuronaler Netze auf vielen verschiedenen Geräten - viel breiter als im Artikel beschrieben. Ich denke, Neural Compute Stick und OpenVINO werden in meiner Roboterforschung sehr nützlich sein.