Russische Version
Stellen Sie sich vor, Sie entwickeln eine Software- und Hardware-Appliance. Die Appliance besteht aus benutzerdefinierten Betriebssystemverteilern, gehobenen Servern und viel Geschäftslogik. Daher muss echte Hardware verwendet werden. Wenn Sie eine defekte Appliance freigeben, sind Ihre Benutzer nicht zufrieden. Wie mache ich stabile Releases?
Ich möchte meine Geschichte erzählen, wie wir damit umgegangen sind.
Proof of Concept
Wenn Sie kein Ziel kennen, wird es wirklich schwierig sein, die Aufgabe zu meistern. Die erste Bereitstellungsvariante sah aus wie Bash :
make dist for i in abc ; do scp ./result.tar.gz $i:~/ ssh $i "tar -zxvf result.tar.gz" ssh $i "make -C ~/resutl install" done
Das Skript wurde vereinfacht, um die Hauptidee zu zeigen: Es gab kein CI / CD. Unser Fluss war:
- Aufbauend auf Entwickler-Host.
- Wird zum Testen der Umgebung für eine Demo bereitgestellt.
Zum gegenwärtigen Zeitpunkt war das Wissen, wie es bereitgestellt wurde, alle bekannten Kludges in den Köpfen der Entwickler schmutzige Magie. Aufgrund des Teamwachstums war dies ein echtes Problem für uns.
Mach es einfach
Wir hatten TeamCity für unsere Projekte verwendet und Gitlab war nicht beliebt, deshalb haben wir uns für TeamCity entschieden. Wir haben manuell eine VM erstellt. Wir haben Tests innerhalb der VM durchgeführt.
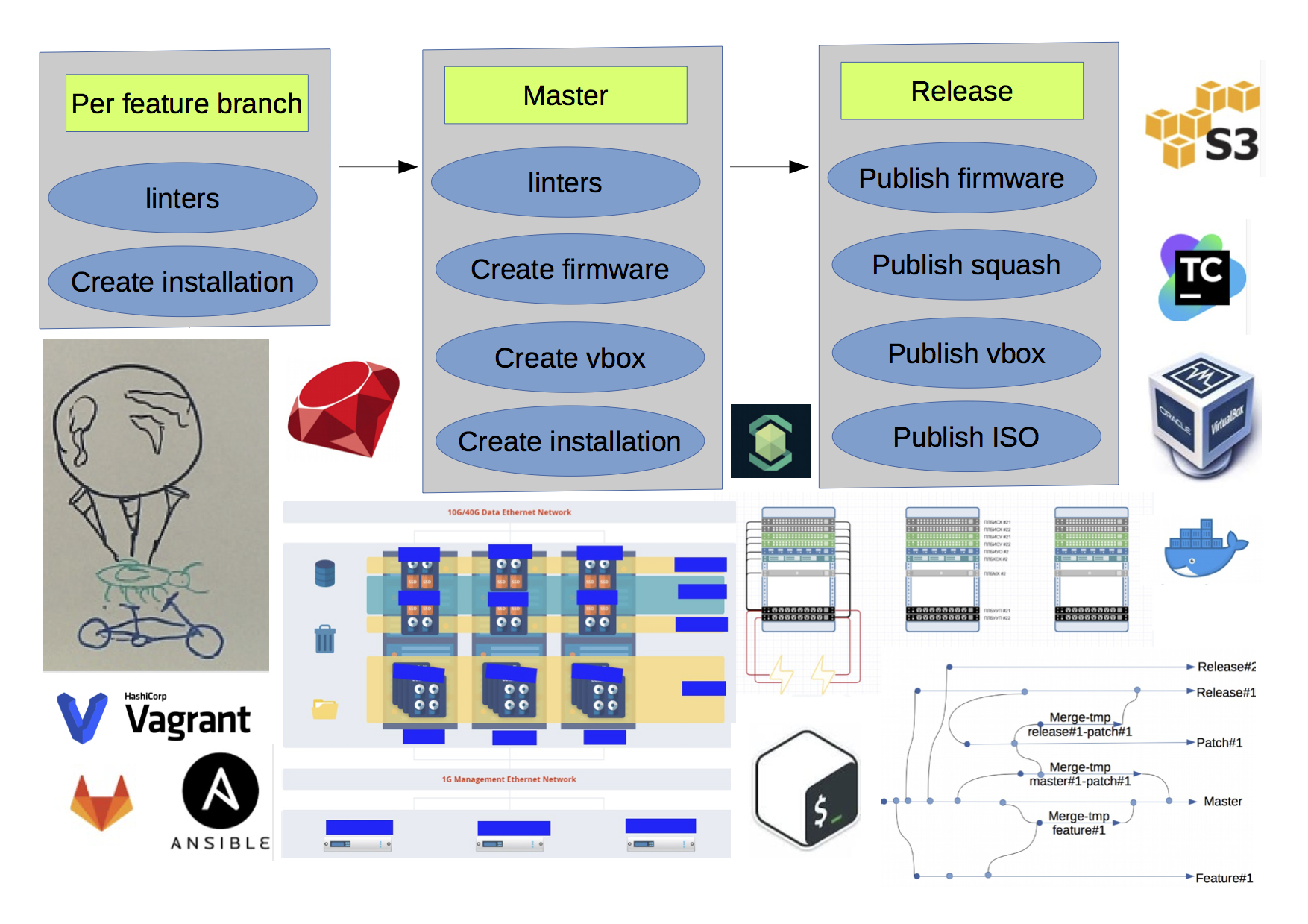
Es gab einige Schritte im Build-Flow:
- Installieren Sie einige Dienstprogramme in einer manuell vorbereiteten Umgebung.
- Überprüfen Sie, ob es funktioniert.
- Wenn es in Ordnung ist, veröffentlichen Sie RPMs.
- Aktualisieren Sie das Staging auf die neue Version.
make install && ./libs/run_all_tests.sh make dist make srpm rpmbuild -ba SPECS/xxx-base.spec make publish
Wir haben ein vorübergehendes Ergebnis erhalten:
- In der Hauptniederlassung befand sich etwas Lauffähiges.
- Es hat irgendwo funktioniert.
- Wir konnten einige gelegentliche Probleme feststellen.
Fühlst du den Geruch?
- Es gab eine Abhängigkeitshölle mit RPMs.
- Jeder hatte seine eigene Entwicklungsumgebung für Haustiere.
- Die Tests wurden in einer unbekannten Umgebung ausgeführt.
- Es gab drei völlig unbegrenzte Einheiten: Betriebssystemerstellung, Bereitstellung von Installationen und Tests.
Reduzieren Sie schmutzige Magie
Wir haben die Abläufe und Prozesse geändert:
- Wir hatten ein RPM-Metapaket erstellt und die Abhängigkeitshölle entfernt.
- Wir haben eine Entwicklungs-VM-Vorlage über vagrant erstellt.
- Wir haben Bash-Skripte in ansible verschoben.
- Einerseits haben wir ein Integrationstest-Framework erstellt, andererseits haben wir serverspec verwendet .
Als Ergebnis für die aktuelle Phase erhielten wir:
- Alle unsere Entwicklungsumgebungen waren identisch.
- App-Code und Bereitstellungslogik wurden mit jedem Over synchronisiert.
- Wir haben den Onboarding-Prozess für neue Entwickler beschleunigt.
Einerseits war ein Build sehr langsam (ca. 30-60 Minuten), andererseits war er gut genug und konnte die überwiegende Mehrheit der Probleme vor der manuellen Qualitätssicherung erfolgreich lösen. Wir hatten jedoch neue Probleme, dh wir haben den Kernel aktualisiert oder ein Paket zurückgesetzt.
Verbessere es
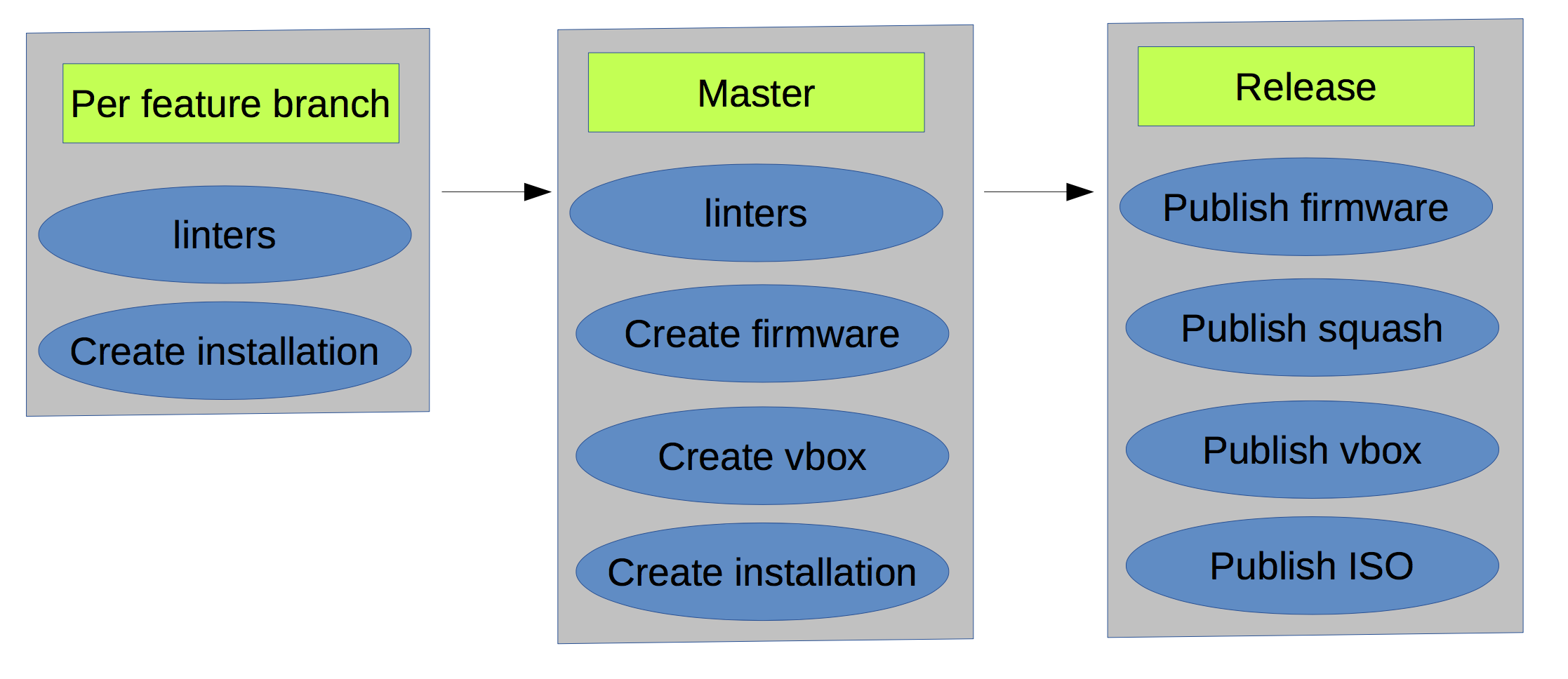
Wir haben viele verschiedene Probleme gelöst:
- Integrationstests arbeiteten immer langsamer, da die Dev-VM-Vorlage älter als die tatsächlichen RPMs war. Wir haben die Vorlage manuell neu erstellt und dann beschlossen, sie zu automatisieren:
- Erstellen Sie automatisch ein VMDK.
- Hängen Sie das VMDK an eine VM an.
- Packe die VM und lade sie auf s3 hoch.
- Im Falle einer Zusammenführung war es nicht möglich, den Build-Status zu erhalten. Daher sind wir zu gitlab gewechselt.
- Früher haben wir jede Woche eine manuelle Version erstellt, die wir automatisiert haben.
- Auto-Inkrement-Version.
- Generieren Sie Versionshinweise basierend auf geschlossenen Problemen.
- Änderungsprotokoll aktualisieren.
- Erstellen Sie Zusammenführungsanforderungen.
- Erstellen Sie einen neuen Meilenstein.
- Wir haben einige Schritte in Docker verschoben (Flusen, einige Tests ausführen, Nachrichten senden, Dokumente erstellen usw.).
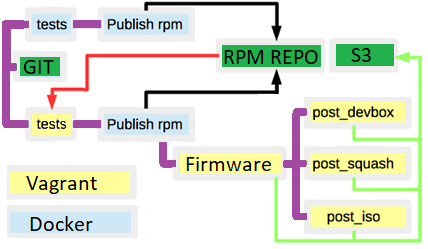
Infolgedessen sah das Schema zum gegenwärtigen Zeitpunkt wie folgt aus:

- Es gab viele RPM / DEB-Repos für Pakete.
- Es gab s3 als Artefaktlager.
- Wenn Sie einen Build zweimal für denselben Zweig ausführen, erhalten Sie ein anderes Ergebnis, da die Abhängigkeiten des Metapakets nicht fest codiert wurden.
- Es gab nicht offensichtliche Grenzen (rote Linien) zwischen den Gebäuden.
Wir konnten jedoch jede Woche eine Veröffentlichung produzieren und die Entwicklungsgeschwindigkeit verbessern.
Fazit
Das Ergebnis war nicht ideal, aber eine Reise von tausend Li beginnt mit einem einzigen Schritt ©.
PS es ist Crosspost