Ich wurde aufgefordert, diesen Artikel durch eine große Menge von Materialien zur statischen Analyse zu schreiben, die mir immer häufiger auffallen. Erstens ist dies der
PVS-Studio-Blog , der sich mithilfe von Fehlerprüfungen, die sein Tool in Open-Source-Projekten gefunden hat, aktiv auf Habré bewirbt. Vor kurzem hat PVS-Studio die
Unterstützung für Java implementiert, und natürlich konnten sich die Entwickler von IntelliJ IDEA, dessen integrierter Analysator heute wahrscheinlich der fortschrittlichste für Java ist,
nicht fernhalten .
Wenn Sie solche Bewertungen lesen, haben Sie das Gefühl, dass es sich um ein magisches Elixier handelt: Klicken Sie auf die Schaltfläche, und hier ist es - eine Liste von Fehlern vor Ihren Augen. Es scheint, dass mit der Verbesserung der Analysegeräte immer mehr Fehler automatisch gefunden werden und die von diesen Robotern gescannten Produkte ohne unser Zutun immer besser werden.
Aber es gibt keine magischen Elixiere. Ich möchte über etwas sprechen, das in Beiträgen wie „Dies sind die Dinge, die unser Roboter finden kann“ normalerweise nicht erwähnt wird: Was Analysatoren nicht können, welche Rolle und welchen Stellenwert sie im Softwarebereitstellungsprozess wirklich haben und wie sie korrekt implementiert werden.
 Ratsche (Quelle: Wikipedia ).
Ratsche (Quelle: Wikipedia ).Was statische Analysatoren niemals können
Was ist aus praktischer Sicht die Quellcode-Analyse? Wir senden einige Quellen an die Eingabe und erhalten bei der Ausgabe in kurzer Zeit (viel kürzer als der Testlauf) einige Informationen über unser System. Die grundlegende und mathematisch unüberwindbare Einschränkung besteht darin, dass wir auf diese Weise nur eine ziemlich enge Klasse von Informationen erhalten können.
Das bekannteste Beispiel für ein Problem, das mit Hilfe der statischen Analyse nicht gelöst werden kann, ist
das Problem des Herunterfahrens : Dies ist ein Theorem, das beweist, dass es unmöglich ist, einen allgemeinen Algorithmus zu entwickeln, der anhand des Quellcodes eines Programms bestimmt, ob es sich in einer endlichen Zeit wiederholt oder endet. Eine Erweiterung dieses Theorems ist
das Theorem von Rice, das besagt, dass für jede nicht triviale Eigenschaft berechenbarer Funktionen die Bestimmung, ob ein beliebiges Programm eine Funktion mit dieser Eigenschaft berechnet, ein algorithmisch unlösbares Problem ist. Zum Beispiel ist es unmöglich, einen Analysator zu schreiben, der durch irgendeinen Quellcode bestimmt, ob das zu analysierende Programm eine Implementierung eines Algorithmus ist, der beispielsweise das Quadrieren einer ganzen Zahl berechnet.
Somit weist die Funktionalität von statischen Analysatoren unüberwindbare Einschränkungen auf. In allen Fällen kann der statische Analysator niemals beispielsweise das Auftreten einer „Nullzeigerausnahme“ in nullbaren Sprachen erkennen oder in allen Fällen das Auftreten eines „nicht gefundenen Attributs“ in dynamisch typisierten Sprachen bestimmen. Der fortschrittlichste statische Analysator kann lediglich bestimmte Fälle hervorheben, deren Anzahl unter allen möglichen Problemen mit Ihrem Quellcode ohne Übertreibung ein Tropfen auf den heißen Stein ist.
Statische Analyse ist keine Fehlersuche
Die Schlussfolgerung folgt aus dem Vorstehenden: Die statische Analyse ist kein Mittel, um die Anzahl der Fehler in einem Programm zu verringern. Ich wage zu behaupten: Wenn es zum ersten Mal auf Ihr Projekt angewendet wird, findet es "belegte" Stellen im Code, aber höchstwahrscheinlich werden keine Fehler gefunden, die die Qualität Ihres Programms beeinträchtigen.
Die Beispiele für Fehler, die von Analysatoren automatisch gefunden werden, sind beeindruckend, aber wir sollten nicht vergessen, dass diese Beispiele durch Scannen eines großen Satzes großer Codebasen gefunden wurden. Nach dem gleichen Prinzip finden Cracker mit der Fähigkeit, einige einfache Passwörter für eine große Anzahl von Konten aufzulisten, letztendlich diejenigen Konten, die ein einfaches Passwort haben.
Bedeutet dies, dass keine statische Analyse angewendet werden muss? Natürlich nicht! Und genau aus dem gleichen Grund, aus dem es sich lohnt, jedes neue Passwort zu überprüfen, um zur Stoppliste der "einfachen" Passwörter zu gelangen.
Statische Analyse ist mehr als Fehlersuche
Tatsächlich sind die durch die Analyse praktisch gelösten Aufgaben viel umfassender. In der Tat ist eine statische Analyse im Allgemeinen eine Überprüfung der Quellen, die vor ihrem Start durchgeführt wird. Hier sind einige Dinge, die Sie tun können:
- Überprüfung des Codierungsstils im weiteren Sinne des Wortes. Dies umfasst das Überprüfen der Formatierung und das Suchen nach leeren / zusätzlichen Klammern, das Festlegen von Schwellenwerten für Metriken wie die Anzahl der Zeilen / die zyklomatische Komplexität der Methode usw. - all dies macht das Lesen und Verwalten des Codes möglicherweise schwierig. In Java ist ein solches Tool Checkstyle, in Python - flake8. Programme dieser Klasse werden normalerweise als Linters bezeichnet.
- Es kann nicht nur ausführbarer Code analysiert werden. Ressourcendateien wie JSON, YAML, XML, .properties können (und sollten!) Automatisch auf ihre Gültigkeit überprüft werden. Schließlich ist es besser herauszufinden, dass aufgrund einiger ungepaarter Anführungszeichen die JSON-Struktur in der frühen Phase der automatischen Pull-Request-Prüfung verletzt wird, als wenn Tests ausgeführt werden oder zur Laufzeit? Relevante Tools stehen zur Verfügung: zum Beispiel YAMLlint , JSONLint .
- Das Kompilieren (oder Parsen für dynamische Programmiersprachen) ist auch eine Form der statischen Analyse. In der Regel können Compiler Warnungen ausgeben, die auf Probleme mit der Qualität des Quellcodes hinweisen, und sollten nicht ignoriert werden.
- Manchmal ist die Kompilierung nicht nur die Kompilierung von ausführbarem Code. Wenn Sie beispielsweise über eine Dokumentation im AsciiDoctor- Format verfügen, gibt der AsciiDoctor-Handler ( Maven-Plugin ) zum Zeitpunkt der Konvertierung in HTML / PDF möglicherweise Warnungen aus, z. B. vor fehlerhaften internen Links. Dies ist ein guter Grund, die Pull-Anforderung mit Änderungen an der Dokumentation nicht zu akzeptieren.
- Die Rechtschreibprüfung ist auch eine Form der statischen Analyse. Das Dienstprogramm aspell kann die Rechtschreibung nicht nur in der Dokumentation, sondern auch in den Quellcodes von Programmen (Kommentare und Literale) in verschiedenen Programmiersprachen, einschließlich C / C ++, Java und Python, überprüfen. Ein Rechtschreibfehler in der Benutzeroberfläche oder Dokumentation ist ebenfalls ein Fehler!
- Konfigurationstests (für das, was es ist - siehe diesen und diesen Bericht), obwohl sie in einer Laufzeitumgebung für Komponententests wie pytest ausgeführt werden, sind in der Tat auch eine Art statische Analyse, da sie während ihrer Ausführung keine Quellcodes ausführen .
Wie Sie sehen können, spielt die Suche nach Fehlern in dieser Liste die am wenigsten wichtige Rolle, und alles andere ist mithilfe kostenloser Open Source-Tools verfügbar.
Welche dieser Arten der statischen Analyse sollte in Ihrem Projekt verwendet werden? Natürlich alles, je mehr - desto besser! Die Hauptsache ist, es richtig zu implementieren, worauf weiter eingegangen wird.
Lieferpipeline als mehrstufiger Filter und statische Analyse als erste Kaskade
Die klassische Metapher für die kontinuierliche Integration ist die Pipeline, durch die Änderungen fließen - von der Änderung des Quellcodes bis zur Lieferung an die Produktion. Die Standardsequenz der Schritte in dieser Pipeline lautet wie folgt:
- statische Analyse
- Zusammenstellung
- Unit-Tests
- Integrationstests
- UI-Tests
- manuelle Überprüfung
In der N-ten Stufe des Förderers abgelehnte Änderungen werden nicht in die Stufe N + 1 übertragen.
Warum so und nicht anders? Im Testteil der Pipeline erkennen Tester die bekannte Testpyramide.
 Testpyramide. Quelle: Artikel von Martin Fowler.
Testpyramide. Quelle: Artikel von Martin Fowler.Am Ende dieser Pyramide befinden sich Tests, die einfacher zu schreiben sind, schneller ausgeführt werden können und nicht zu Fehlalarmen neigen. Daher sollte es mehr geben, sie sollten mehr Code abdecken und zuerst ausgeführt werden. An der Spitze der Pyramide ist alles umgekehrt, daher sollte die Anzahl der Integrations- und UI-Tests auf das erforderliche Minimum reduziert werden. Die Person in dieser Kette ist die teuerste, langsamste und unzuverlässigste Ressource. Sie steht also ganz am Ende und erledigt die Arbeit nur, wenn bei den vorherigen Schritten keine Mängel festgestellt wurden. Nach den gleichen Grundsätzen wird ein Förderer jedoch aus Teilen gebaut, die nicht in direktem Zusammenhang mit der Prüfung stehen!
Ich möchte eine Analogie in Form eines mehrstufigen Wasserfiltersystems anbieten. Schmutziges Wasser (Änderungen mit Defekten) wird dem Eingang zugeführt, am Ausgang müssen wir sauberes Wasser bekommen, in dem alle unerwünschten Verschmutzungen beseitigt werden.
 Mehrstufiger Filter. Quelle: Wikimedia Commons
Mehrstufiger Filter. Quelle: Wikimedia CommonsWie Sie wissen, sind Reinigungsfilter so konzipiert, dass jede nachfolgende Kaskade einen immer geringeren Anteil an Verunreinigungen herausfiltern kann. Gleichzeitig haben gröbere Kaskaden einen höheren Durchsatz und geringere Kosten. In unserer Analogie bedeutet dies, dass Gates mit Eingangsqualität schneller sind, weniger Aufwand beim Starten erfordern und selbst unprätentiöser in ihrer Arbeit sind - und in dieser Reihenfolge werden sie erstellt. Die Rolle der statischen Analyse, die, wie wir jetzt verstehen, nur die gröbsten Mängel beseitigen kann, ist die Rolle des "Schmutzfänger" -Gitters am Anfang der Filterkaskade.
Eine statische Analyse allein verbessert die Qualität des Endprodukts nicht, so wie ein Schlammsammler kein Trinkwasser herstellt. Im Allgemeinen in Verbindung mit anderen Elementen des Förderers ist seine Bedeutung jedoch offensichtlich. Obwohl im mehrstufigen Filter die Ausgangsstufen möglicherweise in der Lage sind, alles gleich wie die Eingangsstufen abzufangen, ist klar, welche Konsequenzen der Versuch, mit feinen Stufen ohne Eingangsstufen zu arbeiten, dazu führen wird.
Ziel des „Schmutzsammlers“ ist es, nachfolgende Kaskaden von der Erfassung sehr grober Defekte zu entlasten. Zum Beispiel sollte zumindest die Person, die die Codeüberprüfung durchführt, nicht durch falsch formatierten Code und Verstöße gegen etablierte Codierungsstandards (wie zusätzliche Klammern oder zu tief verschachtelte Zweige) abgelenkt werden. Fehler wie NPE sollten durch Komponententests abgefangen werden. Wenn der Analysator uns jedoch bereits vor dem Test mitteilt, dass der Fehler unvermeidlich auftreten sollte, beschleunigt dies die Korrektur erheblich.
Ich glaube, es ist jetzt klar, warum die statische Analyse die Produktqualität bei sporadischer Anwendung nicht verbessert und kontinuierlich verwendet werden sollte, um Änderungen mit groben Fehlern herauszufiltern. Die Frage ist, ob die Verwendung eines statischen Analysegeräts die Qualität Ihres Produkts verbessert. Dies entspricht in etwa der Frage: "Verbessern sich die Trinkqualitäten von Wasser aus einem verschmutzten Reservoir, wenn es durch ein Sieb geleitet wird?"
Implementierung in ein Legacy-Projekt
Eine wichtige praktische Frage: Wie lässt sich die statische Analyse als „Qualitätsgatter“ in den Prozess der kontinuierlichen Integration integrieren? Bei automatischen Tests ist alles offensichtlich: Es gibt eine Reihe von Tests, deren Sturz ein ausreichender Grund zu der Annahme ist, dass die Baugruppe das Qualitätstor nicht bestanden hat. Der Versuch, das Gate basierend auf den Ergebnissen der statischen Analyse auf dieselbe Weise einzustellen, schlägt fehl: Der Legacy-Code enthält zu viele Analysewarnungen. Sie möchten diese nicht vollständig ignorieren, aber es ist unmöglich, die Lieferung des Produkts zu stoppen, nur weil es Warnungen für den Analysator enthält.
Bei der erstmaligen Anwendung generiert der Analysator bei jedem Projekt eine Vielzahl von Warnungen, von denen die meisten nicht mit der ordnungsgemäßen Funktion des Produkts zusammenhängen. Es ist unmöglich, alle diese Bemerkungen auf einmal zu korrigieren, und viele sind nicht notwendig. Am Ende wissen wir, dass unser Produkt als Ganzes funktioniert, und bevor die statische Analyse eingeführt wird!
Infolgedessen beschränken sich viele auf die episodische Verwendung der statischen Analyse oder verwenden sie nur im Informationsmodus, wenn der Analysatorbericht einfach während der Montage ausgegeben wird. Dies ist gleichbedeutend mit dem Fehlen jeglicher Analyse, denn wenn wir bereits viele Warnungen haben, bleibt das Auftreten einer anderen (willkürlich schwerwiegenden) Warnung beim Ändern des Codes unbemerkt.
Die folgenden Methoden zur Verwaltung von Qualitätsgattern sind bekannt:
- Festlegen eines Grenzwerts für die Gesamtzahl der Warnungen oder die Anzahl der Warnungen geteilt durch die Anzahl der Codezeilen. Dies funktioniert schlecht, da ein solches Tor Änderungen mit neuen Defekten frei überspringt, bis deren Grenze überschritten wird.
- Zu einem bestimmten Zeitpunkt wurden alle alten Warnungen im Code als ignoriert behoben und die Erstellung verweigert, wenn neue Warnungen auftreten. Diese Funktionalität wird von PVS-Studio und einigen Online-Ressourcen bereitgestellt, z. B. Codacy. Ich habe nicht zufällig in PVS-Studio gearbeitet, da meine Erfahrung mit Codacy das Hauptproblem darin besteht, dass die Bestimmung, was "alt" und was "neu" ist, ein ziemlich komplizierter und nicht immer funktionierender Algorithmus ist, insbesondere wenn Dateien werden stark geändert oder umbenannt. In meinem Gedächtnis konnte Codacy neue Warnungen in der Pull-Anforderung überspringen und gleichzeitig keine Pull-Anforderung überspringen, da Warnungen nicht mit Änderungen im Code dieser PR zusammenhängen.
- Meiner Meinung nach ist die effektivste Lösung im Buch Continuous Delivery "Ratschen" ("Ratschen") beschrieben. Die Hauptidee ist, dass die Eigenschaft jeder Version die Anzahl der Warnungen bei der statischen Analyse ist und nur die Änderungen zulässig sind, die die Gesamtzahl der Warnungen nicht erhöhen.
Ratsche
Es funktioniert so:
- In der Anfangsphase wird die Anzahl der Warnungen im Code, die von den Analysatoren gefunden wurden, in den Metadaten zur Freigabe aufgezeichnet. Daher wird beim Erstellen des Hauptzweigs nicht nur "Release 7.0.2", sondern auch "Release 7.0.2, das 100500 Checkstyle-Warnungen enthält" in Ihren Repository-Manager geschrieben. Wenn Sie einen erweiterten Repository-Manager (z. B. Artifactory) verwenden, ist das Speichern solcher Metadaten zu Ihrer Version einfach.
- Jetzt vergleicht jede Pull-Anforderung während der Montage die Anzahl der empfangenen Warnungen mit der Anzahl in der aktuellen Version. Wenn PR zu einer Erhöhung dieser Anzahl führt, passiert der Code das Qualitätsgatter für die statische Analyse nicht. Wenn die Anzahl der Warnungen abnimmt oder sich nicht ändert, wird sie bestanden.
- Bei der nächsten Version wird die gezählte Anzahl von Warnungen in die Release-Metadaten neu geschrieben.
So nach und nach, aber stetig (wie bei Ratschen) wird die Anzahl der Warnungen gegen Null tendieren. Natürlich kann das System getäuscht werden, indem eine neue Warnung eingeführt, aber die einer anderen korrigiert wird. Dies ist normal, da es über große Entfernungen zu einem Ergebnis führt: Warnungen werden in der Regel nicht einzeln, sondern sofort von einer Gruppe eines bestimmten Typs korrigiert, und alle leicht zu beseitigenden Warnungen werden schnell beseitigt.
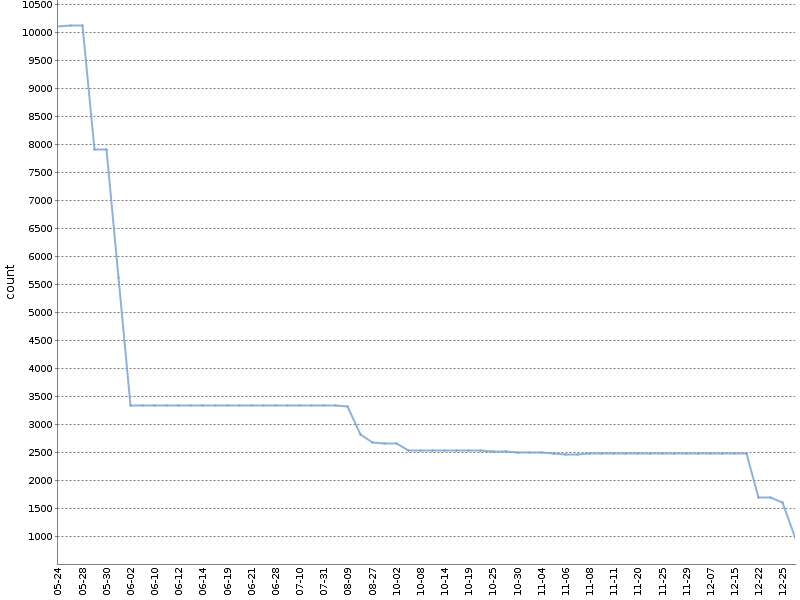
Diese Grafik zeigt die Gesamtzahl der Checkstyle-Warnungen für ein halbes Jahr, in dem eine solche Ratsche an
einem unserer OpenSource-Projekte gearbeitet hat . Die Anzahl der Warnungen hat sich um eine Größenordnung verringert, und dies geschah natürlich parallel zur Entwicklung des Produkts!
Ich verwende eine modifizierte Version dieser Methode, bei der Warnungen, die nach Projektmodulen und Analysetools aufgeschlüsselt sind, separat gezählt werden. Die generierte YAML-Datei mit Assembly-Metadaten sieht folgendermaßen aus:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
In jedem fortschrittlichen CI-System kann „Ratsche“ für alle statischen Analysetools implementiert werden, ohne auf Plugins und Tools von Drittanbietern angewiesen zu sein. Jeder der Analysatoren erstellt seinen Bericht in einem einfachen Text- oder XML-Format, das leicht zu analysieren ist. Es bleibt nur die notwendige Logik im CI-Skript zu registrieren. Wie dies in unseren Open-Source-Projekten auf Basis von Jenkins und Artifactory umgesetzt wird, erfahren Sie
hier oder
hier . Beide Beispiele hängen von der
Ratchetlib- Bibliothek ab: Die
countWarnings() -Methode zählt
countWarnings() die XML-Tags in den von Checkstyle und Spotbugs generierten Dateien, und
compareWarningMaps() implementiert dasselbe Ratchet und gibt einen Fehler aus, wenn die Anzahl der Warnungen in einer der Kategorien zunimmt.
Eine interessante Implementierung der Ratsche ist möglich, um die Schreibweise von Kommentaren, Textliteralen und Dokumentationen mit Aspell zu analysieren. Wie Sie wissen, sind bei der Rechtschreibprüfung nicht alle Wörter, die dem Standardwörterbuch unbekannt sind, falsch. Sie können dem Benutzerwörterbuch hinzugefügt werden. Wenn Sie ein benutzerdefiniertes Wörterbuch zum Teil des Quellcodes eines Projekts machen, kann das Rechtschreibqualitäts-Gate wie folgt formuliert werden: Beim Ausführen von aspell mit einem Standard- und einem benutzerdefinierten Wörterbuch
sollten keine Rechtschreibfehler gefunden werden.
Über die Wichtigkeit der Korrektur der Analysatorversion
Abschließend sollte Folgendes beachtet werden: Unabhängig davon, wie Sie die Analyse in Ihre Lieferpipeline integrieren, muss die Analysatorversion festgelegt werden. Wenn Sie zulassen, dass der Analysator spontan aktualisiert wird, können beim Zusammenstellen der nächsten Pull-Anforderung neue Fehler auftreten, die nicht mit der Änderung des Codes zusammenhängen, sondern damit zusammenhängen, dass der neue Analysator einfach mehr Fehler finden kann - und dies unterbricht den Prozess des Empfangs von Pull-Anforderungen . Das Upgrade des Analysators muss eine bewusste Aktion sein. Das genaue Festlegen der Version jeder Komponente der Baugruppe ist jedoch im Allgemeinen eine notwendige Anforderung und ein Thema für eine separate Konversation.
Schlussfolgerungen
- Bei der statischen Analyse werden keine Fehler gefunden und die Qualität Ihres Produkts durch eine einzelne Anwendung nicht verbessert. Ein positiver Effekt auf die Qualität wird nur durch die ständige Verwendung im Lieferprozess erzielt.
- Die Suche nach Fehlern ist überhaupt nicht die Hauptaufgabe der Analyse, die überwiegende Mehrheit der nützlichen Funktionen ist in OpenSource-Tools verfügbar.
- Implementieren Sie Qualitätsgatter basierend auf den Ergebnissen der statischen Analyse in der ersten Phase der Lieferpipeline, indem Sie Ratsche für den Legacy-Code verwenden.
Referenzen
- Kontinuierliche Lieferung
- A. Kudryavtsev: Analyse von Programmen: Wie kann man verstehen, dass Sie ein guter Programmierer sind? Bericht über verschiedene Methoden der Codeanalyse (nicht nur statisch!)