Am 4. Januar, um 7:15 Uhr, lösche ich meine Augen aus dem Schlaf und finde ein Bündel einer Nachricht in der Telegrammgruppe vom Zabbix-Server, dass die CPU-Auslastung auf einem der Virtualisierungsserver gestiegen ist:
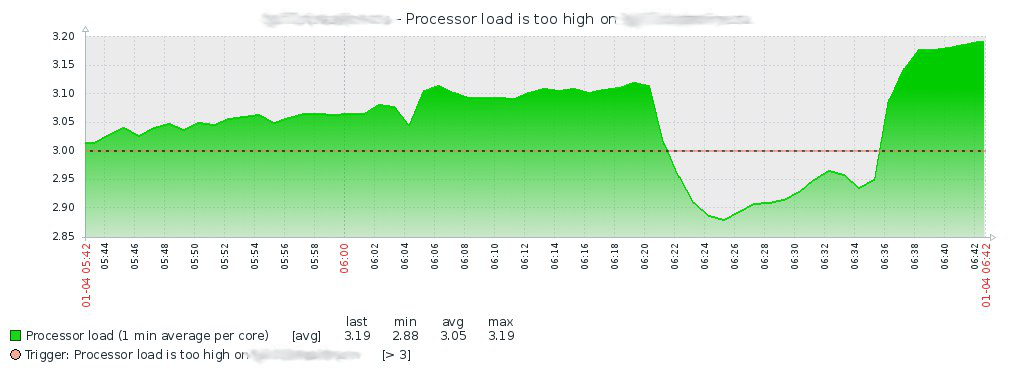
Nachdem ich mir die Geschichte in Zabbix angesehen habe, klettere ich auf den Server und schaue in dmesg, wo ich Folgendes finde:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
Ich klettere in den Speicher, in dem sich der QLogic FC-Adapter befindet. Ich sehe, dass am 1. Januar um 19:54 Uhr eines der Laufwerke im Speicher außer Betrieb genommen wurde, das Ersatzlaufwerk abgeholt wurde und das Resilvering am 2. Januar um 9:11 Uhr endete:

Ich dachte: Vielleicht kam etwas aus dem Repository oder dem FC-Switch, was dazu führte, dass der Treiber über den QLogic-Adapter wütend wurde.
Erstellte eine Aufgabe im Tracker, startete den Server neu, alles funktionierte auf den ersten Blick wieder wie es sollte.
In diesem Zusammenhang verschob er weitere Maßnahmen bis zum Ende der Neujahrsferien.
Mit Beginn der Arbeitswoche am 9. Januar begann er, die Ursache des Versagens zu klären.
Seit der Nachricht:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.
nicht zu informativ, stieg in die Treiberquelle.
Dem Treibercode nach zu urteilen, wird eine Nachricht ausgegeben, wenn der Treiber aufgrund eines Fehlers auf der PCI entladen wird (linux / drivers / scsi / qla2xxx / qla_os.c (Kernel v4.15)):
qla2x00_disable_board_on_pci_error(struct work_struct *work) { struct qla_hw_data *ha = container_of(work, struct qla_hw_data, board_disable); struct pci_dev *pdev = ha->pdev; scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev); /* * if UNLOAD flag is already set, then continue unload, * where it was set first. */ if (test_bit(UNLOADING, &base_vha->dpc_flags)) return; ql_log(ql_log_warn, base_vha, 0x015b, "Disabling adapter.\n");
Ich fing an weiter zu graben, stieg in BMC ein und schaute in das Ereignisprotokoll:
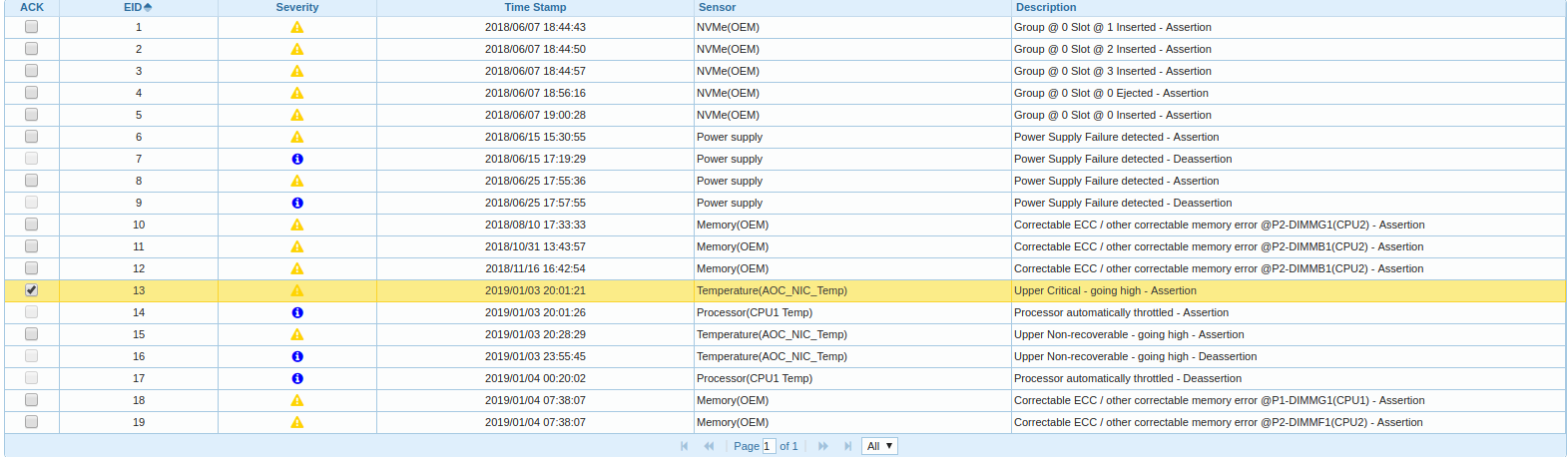
Es stellt sich heraus, dass sich einer der beiden CPU-Knoten in der Plattform erwärmt und drosselt, und die Zeit der Meldung zum Entladen des Treibers des FC-Adapters korreliert mit der Startzeit der Drosselung.
Hier ist anzumerken, dass die Serverplattform, die wir hier haben, https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm mit zwei EPYC 7601 für jeden Knoten ist:
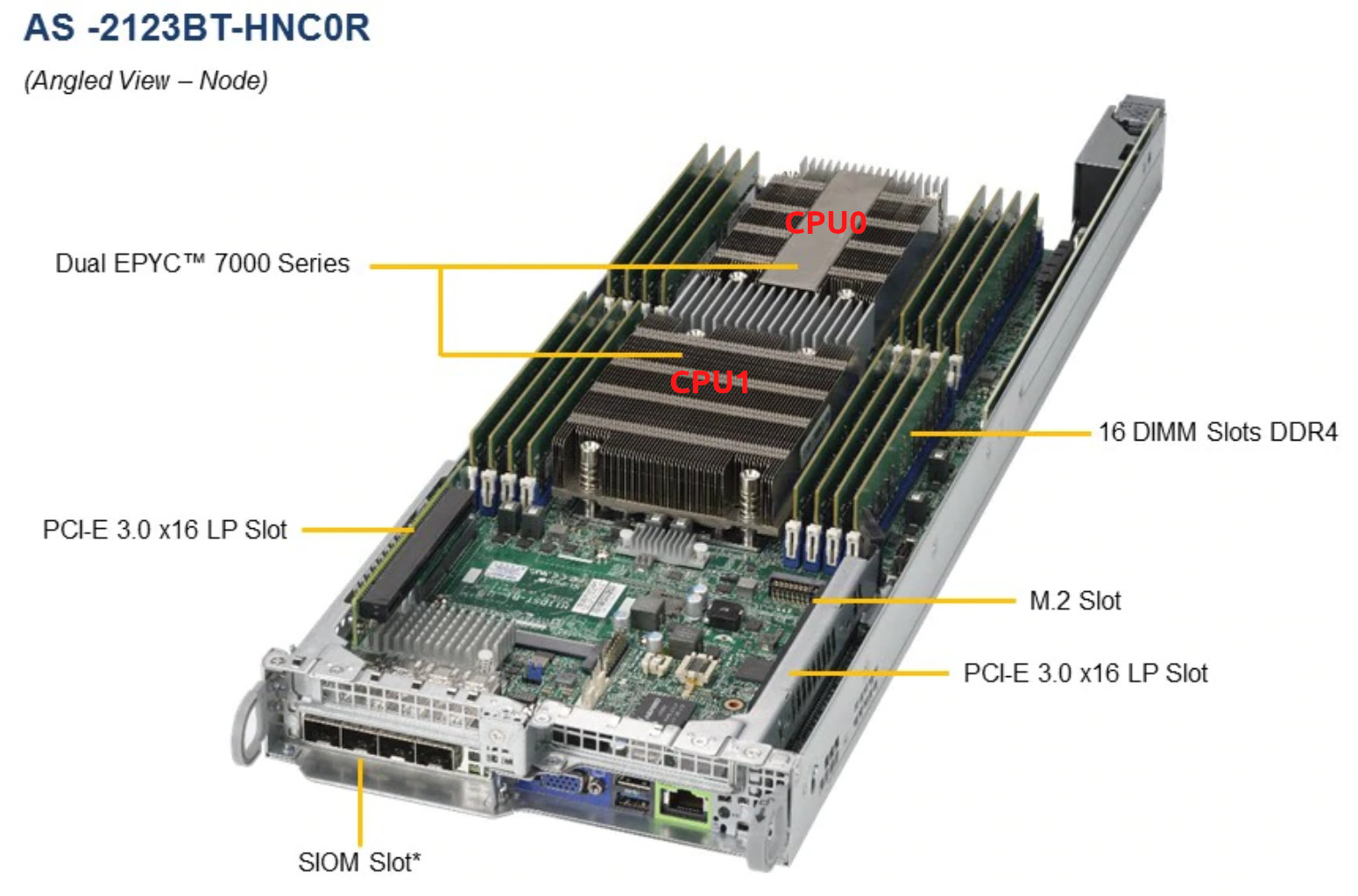
Ich habe es in das Rechenzentrum verschoben, den Knoten vom Server entfernt, die Wärmeleitpaste geändert, sie zurückgeklebt, aber sie heizt sich immer noch auf.
Wir haben festgestellt, dass der Luftstrom in einem Teil des Servers nicht so stark ist wie im anderen. Nachdem alle Knoten leicht mit Stress belastet wurden, wurde deutlich, dass die Knotenprozessoren auf der rechten Seite der Plattform nicht richtig durchbrennen und die Temperatur der zweiten CPU in zwei Knoten sehr schnell kritisch wird.
Nach dem Versuch, die Blasparameter in BMC zu ändern, stellte sich heraus, dass sie keine Auswirkung hatten:
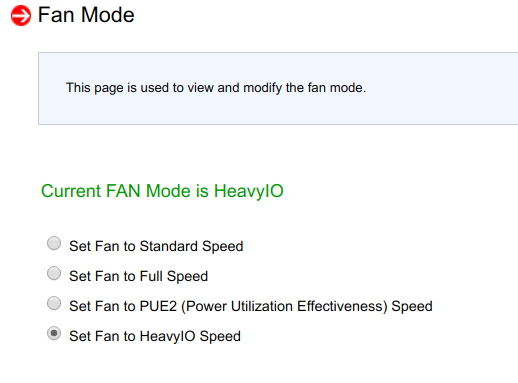
Ein Neustart von BMC hatte ebenfalls keine Auswirkungen.
Nachdem ich mir die Sensorwerte angesehen hatte, sah ich, dass auf einem von 53 Sensoren nur 4 erkannt wurden und auf dem anderen nur 6:
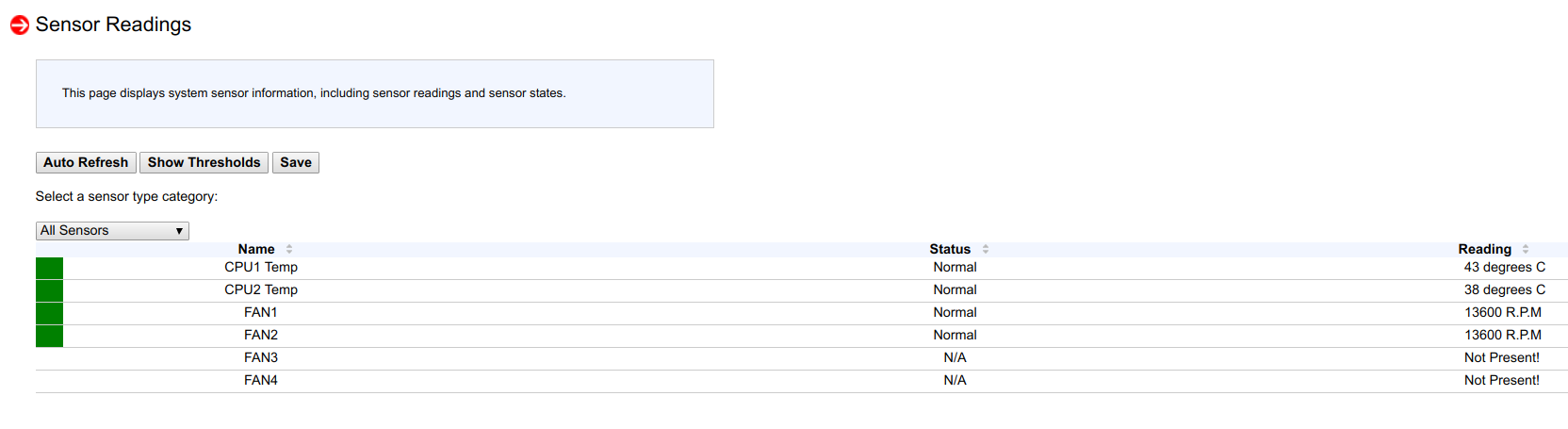
Und dann erinnerte ich mich, dass ich beim Flashen einer neuen BIOS-Version und eines neuen BMC in Knoten vor ein oder zwei Monaten auf zwei Knoten die BMC-Konfiguration nicht auf die werkseitigen Parameter zurückgesetzt habe (um einen bestimmten Fall der Optimierung zu überprüfen).
Nach dem Zurücksetzen des BMC auf die werkseitigen Parameter wurden alle 53 Sensoren erneut erkannt, die Steuerung der Lüftergeschwindigkeit funktionierte erneut und die Prozessoren hörten auf zu erwärmen.
Die Tatsache, dass die Ursache für das Entladen des QLogic-Treibers die Überhitzung des Prozessors ist, ist nicht genau, aber ich habe keine anderen engen Korrelationen gefunden.
Schlussfolgerungen:
- Auch nach der BMC-Firmware lohnt es sich, die Werkseinstellungen zurückzusetzen, auch wenn auf den ersten Blick alles einwandfrei funktioniert.
- Natürlich müssen die Temperatur- und Kernelfehlermeldungen überwacht werden, und dies ist in den Plänen natürlich, aber nicht auf einmal.