Prometheus 2.6.0 optimierte das Laden von WAL, was den Startvorgang beschleunigt.
Das inoffizielle Ziel der Entwicklung von Prometheus 2.x TSDB besteht darin, den Start so zu beschleunigen, dass er nicht länger als eine Minute dauert. In den letzten Monaten wurde berichtet, dass der Prozess etwas länger dauert. Wenn Prometheus aus irgendeinem Grund neu gestartet wird, ist dies bereits ein Problem. Fast die ganze Zeit wird die WAL (Pre-Recording Recording) geladen, die Samples der letzten Stunden enthält, die noch nicht zu einem Block komprimiert wurden. Ende Oktober gelang es mir endlich, es herauszufinden; Das Ergebnis ist PR # 440 , wodurch die CPU-Zeit um das 6,5-fache und die Berechnungszeit um das 4-fache reduziert wird. Mal sehen, wie ich diese Verbesserungen vorgenommen habe.

Zunächst ist ein Testaufbau erforderlich. Ich habe ein kleines Go-Programm erstellt, das TSDB mit WAL mit einer Milliarde Stichproben generiert, die über 10.000 Zeitreihen verteilt sind. Dann habe ich diese TSDB geöffnet und mir angesehen, wie lange es gedauert hat, das Zeitdienstprogramm (nicht die integrierte Struktur, da es keine Speicherstatistik enthält) zu verwenden, und auch ein CPU-Profil mit dem Paket runtime / pprof erstellt :
f, err := os.Create("cpu.prof") if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile()
Das CPU-Profil ermöglicht es uns nicht, die für uns interessante Berechnungszeit direkt zu bestimmen, es besteht jedoch eine signifikante Korrelation. Auf meinem Desktop-Computer (i7-3770-Prozessor mit 16 GB RAM und Solid-State-Laufwerken) dauerte der Download daher etwa 4 Minuten und auf dem Höhepunkt etwas weniger als 6 GB RAM:
1727.50user 16.61system 4:01.12elapsed 723%CPU (0avgtext+0avgdata 5962812maxresident)k 23625165inputs+95outputs (196major+2042817minor)pagefaults 0swaps
Dies ist kein Buzz. Laden Sie das Profil mit dem go tool pprof cpu.prof und sehen Sie, wie lange der Vorgang go tool pprof cpu.prof , wenn Sie den Befehl top .

Hier ist flat die Zeit, die für eine bestimmte Funktion aufgewendet wird, und cum ist die Zeit, die für diese Funktion und alle von ihr aufgerufenen Funktionen aufgewendet wird. Es kann auch nützlich sein, diese Daten in einem Diagramm anzuzeigen, um sich ein Bild von der Frage zu machen. Ich bevorzuge es, den web dafür zu verwenden, aber es gibt andere Optionen, einschließlich SVG-, PNG- und PDF-Dateien.
Es ist ersichtlich, dass etwa ein Drittel unserer CPU für das Hinzufügen von Samples zur internen Datenbank, etwa zwei Drittel für die WAL-Verarbeitung im Allgemeinen und ein Viertel für die Bereinigung des Speichers ( runtime.scanobject ) runtime.scanobject . Schauen wir uns den Code für den ersten dieser Prozesse mit list memSeries.*append :
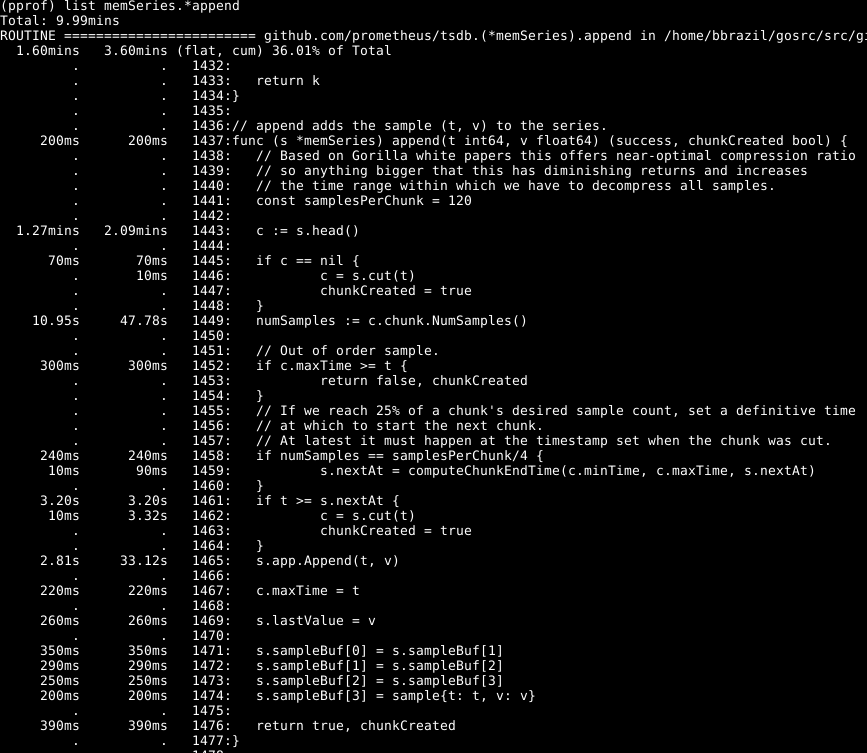
Folgendes ist hier auffällig: Mehr als die Hälfte der Zeit wird für das Abrufen des Hauptdatenstücks für die Serie in Zeile 1443 aufgewendet. Außerdem wird nicht wenig Zeit für das Festlegen der Anzahl der Stichproben in diesem Datenelement in Zeile 1449 aufgewendet. Die Zeit, die zum Abschließen der Zeile 1465 benötigt wird - erwartet, da dies der Kern der Aktion dieser Funktion ist. Dementsprechend erwartete ich, dass die Operation die meiste Zeit dauern würde.
Schauen Sie sich das Element memSeries.head : Es berechnet ein Datenelement, das jedes Mal zurückgegeben wird. Das Datenfragment ändert sich erst nach jeweils 120 Hinzufügungen, sodass wir das aktuelle Kopffragment in der Datenstruktur der Serie speichern können. Dies beansprucht einen Teil des Arbeitsspeichers (auf den ich später zurückkommen werde ), spart jedoch eine erhebliche Menge an CPU. Und insgesamt beschleunigt es auch Prometheus.
Dann schauen Head.processWALSamples uns Head.processWALSamples :
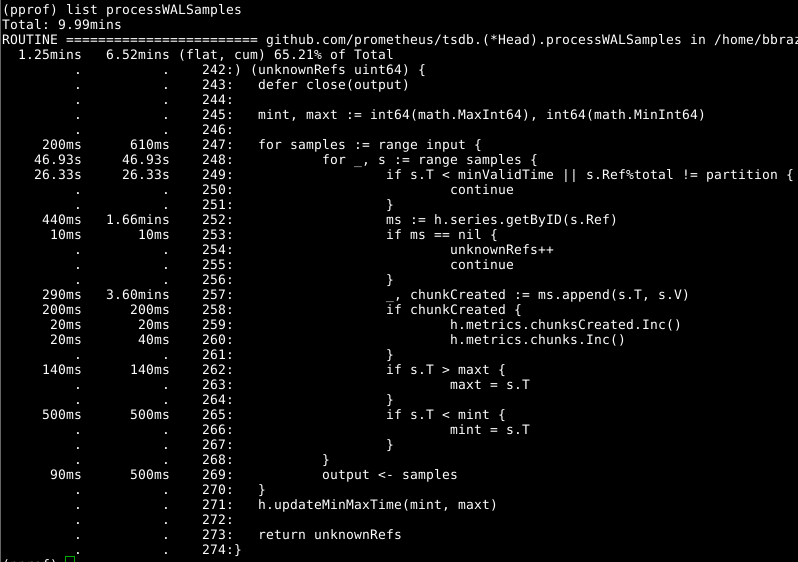
Dieses Add-On wurde bereits oben optimiert. Schauen Sie sich also den nächsten offensichtlichen Schuldigen an, getByID in Zeile 252:
(Code)
Es scheint, dass es eine Art Blockierungskonflikt gibt und Zeit für eine zweistufige Kartensuche verschwendet wird. Der Cache für jeden Bezeichner reduziert diesen Indikator erheblich.
Es lohnt sich Head.processWALSamples zweiten Blick auf Head.processWALSamples zu Head.processWALSamples , und Sie sind überrascht, wie viel Zeit in Zeile 249 verbracht wurde. Head.processWALSamples wir noch einmal auf die Frage zurück, wie das Laden von WAL funktioniert: Head.processWALSamples- Head.processWALSamples wird für jede verfügbare CPU zusätzlich zu einer anderen zum Lesen und Head.processWALSamples erstellt Dekodieren von WAL von der Festplatte. Zeilen werden nach diesen Goroutinen segmentiert, sodass Parallelität von Vorteil sein kann. Die Implementierungsmethode lautet wie folgt: Alle Proben werden an das erste Gorutin gesendet, das die benötigten Elemente verarbeitet. Dann sendet sie alle Proben an das zweite Gorutin, das die benötigten Elemente verarbeitet, und so weiter, bis das letzte Gorutin, Head.processWALSamples alle Daten an das Kontrollgorutin zurücksendet.
In der Zwischenzeit werden Add-Ons auf die Kernel verteilt - was genau das ist, was Sie benötigen - und in jedem Gorutin werden viele doppelte Aufgaben ausgeführt, die alle Samples verarbeiten und das Modul berechnen müssen. Je mehr Kerne vorhanden sind, desto mehr Arbeit wird dupliziert. Ich habe Änderungen vorgenommen, um die Daten im Controller-Gourutin zu segmentieren, sodass jedes Gorutin von Head.processWALSamples nur noch die benötigten Samples erhält . Auf meinem Computer - 8 mit Gorutin - wurde die Berechnungszeit etwas gespart, aber das CPU-Volumen war anständig. Bei Computern mit einer großen Anzahl von Kernen sollten die Vorteile erheblich sein.
Und wieder kehren wir zur Frage zurück: Zeit, die Erinnerung zu löschen. Wir können dies (normalerweise) nicht durch CPU-Profile bestimmen. Achten Sie stattdessen auf die dynamischen Speicherprofile, um die hervorstechenden Elemente zu finden. Dies erfordert eine Code-Erweiterung am Ende des Programms:
runtime.GC() hf, err := os.Create("heap.prof") if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(hf)
Die formale Speicherbereinigung ist mit einigen Informationen im dynamischen Speicher verbunden, deren Erfassung und Bereinigung nur während der Speicherbereinigung durchgeführt wird.
Wir verwenden wieder dasselbe Tool, geben jedoch die Bezeichnung -alloc_space , da wir an allen Speicherzuweisungsoperationen interessiert sind und nicht nur an Operationen, die zu einem bestimmten Zeitpunkt Speicher verwenden. Führen go tool pprof -alloc_space heap.prof daher das go tool pprof -alloc_space heap.prof . Wenn Sie sich den oberen Verteiler ansehen, ist der Schuldige offensichtlich:
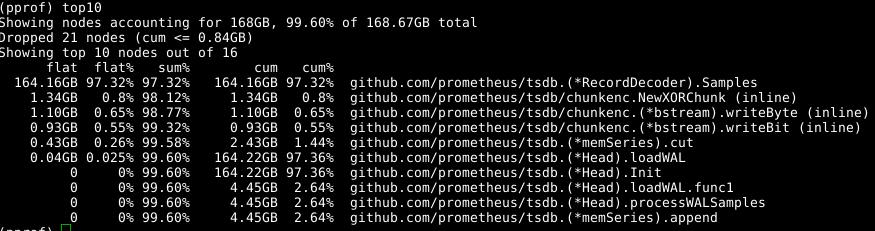
Schauen Sie sich den Code an:
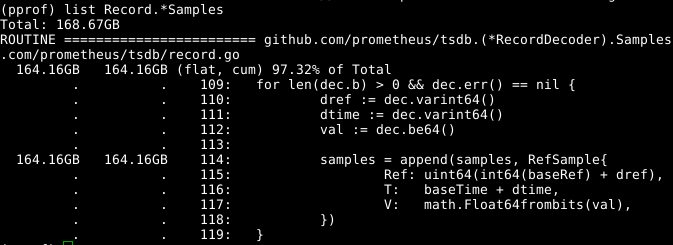
Das erweiterbare samples Array scheint ein Problem zu sein. Wenn wir das Array gleichzeitig mit dem Aufruf von RecordDecoder.Samples wiederverwenden könnten, würde dies eine erhebliche Menge an Speicherplatz sparen. Es stellt sich heraus, dass der Code auf diese Weise erstellt wurde, aber ein kleiner Codierungsfehler führte dazu, dass er nicht funktionierte. Wenn Sie das Problem beheben , wird der Speicher in 8 Sekunden anstelle von 151 Sekunden von der CPU gelöscht.
Die Gesamtergebnisse sind greifbar:
269.18user 10.69system 1:05.58elapsed 426%CPU (0avgtext+0avgdata 3529556maxresident)k 23174929inputs+70outputs (815major+1083172minor)pagefaults 0swap
Wir haben nicht nur die Berechnungszeit um das 4-fache und die CPU-Zeit um das 6,5-fache reduziert, sondern auch die Menge des belegten Speichers um mehr als 2 GB.
Es sieht so aus, als wäre alles einfach, aber der Trick ist folgender: Ich habe anständig in der Codebasis gestöbert und alles wie im Nachhinein analysiert. Als ich den Code studierte, kam ich mehrmals in eine Sackgasse, zum Beispiel beim Löschen eines NumSamples Aufrufs, beim Lesen und Dekodieren in separaten Threads sowie auf verschiedene Arten, um processWALSamples zu segmentieren. Ich bin mir fast sicher, dass durch die Regulierung der Anzahl der Gorutine mehr erreicht werden kann, aber dafür müssen Tests auf Maschinen durchgeführt werden, die leistungsstärker sind als meine, damit mehr Kerne vorhanden sind. Ich habe mein Ziel erreicht: Die Produktivität wurde gesteigert, und ich erkannte, dass es besser ist, die Programmregistrierung nicht zu groß zu machen, und beschloss daher, dort anzuhalten.