Hallo! Mein Name ist Ivan Smurov und ich leite die NLP-Forschungsgruppe bei ABBYY. Lesen Sie hier, was unsere Gruppe tut. Ich habe kürzlich einen Vortrag über die Verarbeitung natürlicher Sprache (NLP) an der
School of Deep Learning gehalten - dies ist eine Gruppe an der PhysTech School für Angewandte Mathematik und Informatik am MIPT für ältere Studenten, die sich für Programmierung und Mathematik interessieren. Vielleicht sind die Thesen meines Vortrags für jemanden nützlich, also werde ich sie mit Habr teilen.
Da nicht alles auf einmal erfasst werden kann, werden wir den Artikel in zwei Teile teilen. Heute werde ich darüber sprechen, wie neuronale Netze (oder Deep Learning) in NLP verwendet werden. Im zweiten Teil des Artikels konzentrieren wir uns auf eine der häufigsten NLP-Aufgaben - das Extrahieren benannter Entitäten (Named-Entity-Erkennung, NER) und die detaillierte Analyse der Architektur ihrer Lösungen.
Was ist NLP?
Dies ist eine breite Palette von Aufgaben zum Verarbeiten von Texten in einer natürlichen Sprache (d. H. Der Sprache, die Menschen sprechen und schreiben). Es gibt eine Reihe klassischer NLP-Aufgaben, deren Lösung von praktischem Nutzen ist.
- Die erste und historisch wichtigste Aufgabe ist die maschinelle Übersetzung. Es wurde sehr lange praktiziert und es gibt enorme Fortschritte. Die Aufgabe, eine vollautomatische Übersetzung von hoher Qualität (FAHQMT) zu erhalten, bleibt jedoch ungelöst. In gewisser Weise ist dies die NLP-Engine, eine der größten Aufgaben, die Sie ausführen können.

- Die zweite Aufgabe ist die Klassifizierung von Texten. Es wird eine Reihe von Texten angegeben, deren Aufgabe es ist, diese Texte in Kategorien einzuteilen. Welches? Dies ist eine Frage an das Korps.
Die erste und eine der praktischsten Möglichkeiten, sie aus praktischer Sicht anzuwenden, ist die Einteilung von Buchstaben in Spam und Boor (nicht Spam).
Eine weitere klassische Option ist die Klassifizierung von Nachrichten in mehrere Klassen in Kategorien (Rubrik) - Außenpolitik, Sport, Big Top usw. Oder Sie erhalten beispielsweise Briefe und möchten Bestellungen aus dem Online-Shop von Flugtickets und Hotelreservierungen trennen.
Die dritte klassische Anwendung des Textklassifizierungsproblems ist die sentimentale Analyse. Zum Beispiel die Einstufung von Bewertungen als positiv, negativ und neutral.
Da es so viele mögliche Kategorien gibt, in die Sie Texte unterteilen können, ist die Textklassifizierung eine der beliebtesten praktischen Aufgaben von NLP. - Die dritte Aufgabe besteht darin, benannte Entitäten, NER, abzurufen. Wir wählen in den Textabschnitten aus, die einer vorgewählten Gruppe von Entitäten entsprechen. Beispielsweise müssen Sie alle Standorte, Personen und Organisationen im Text finden. Im Text „Ostap Bender - Direktor des Büros„ Hörner und Hufe ““ sollten Sie verstehen, dass Ostap Bender eine Person und „Hörner und Hufe“ eine Organisation ist. Warum diese Aufgabe in der Praxis benötigt wird und wie sie gelöst werden kann, werden wir im zweiten Teil unseres Artikels besprechen.
 Die vierte Aufgabe ist mit der dritten verbunden - die Aufgabe, Fakten und Beziehungen zu extrahieren (Beziehungsextraktion). Zum Beispiel gibt es eine Arbeitseinstellung (Beruf). Aus dem Text „Ostap Bender - Direktor des Büros„ Hörner und Hufe ““ geht hervor, dass unser Held mit den beruflichen Beziehungen zu „Hörner und Hufe“ verbunden ist. Das Gleiche kann auf viele andere Arten gesagt werden: "Das Büro von Ostap Bender wird vom Büro" Horns and Hooves "geleitet, oder" Ostap Bender ist vom einfachen Sohn von Leutnant Schmidt zum Leiter des Büros "Horns and Hooves" gewechselt. " Diese Sätze unterscheiden sich nicht nur im Prädikat, sondern auch in der Struktur.
Die vierte Aufgabe ist mit der dritten verbunden - die Aufgabe, Fakten und Beziehungen zu extrahieren (Beziehungsextraktion). Zum Beispiel gibt es eine Arbeitseinstellung (Beruf). Aus dem Text „Ostap Bender - Direktor des Büros„ Hörner und Hufe ““ geht hervor, dass unser Held mit den beruflichen Beziehungen zu „Hörner und Hufe“ verbunden ist. Das Gleiche kann auf viele andere Arten gesagt werden: "Das Büro von Ostap Bender wird vom Büro" Horns and Hooves "geleitet, oder" Ostap Bender ist vom einfachen Sohn von Leutnant Schmidt zum Leiter des Büros "Horns and Hooves" gewechselt. " Diese Sätze unterscheiden sich nicht nur im Prädikat, sondern auch in der Struktur.
Beispiele für andere Beziehungen, die häufig hervorgehoben werden, sind Kauf und Verkauf, Eigentum, die Tatsache der Geburt mit Attributen wie Datum, Ort usw. (Geburt) und einige andere.
Die Aufgabe scheint keine offensichtliche praktische Anwendung zu haben, wird jedoch bei der Strukturierung unstrukturierter Informationen verwendet. Darüber hinaus ist es in Frage-Antwort- und Dialogsystemen, in Suchmaschinen wichtig - immer dann, wenn Sie eine Frage analysieren und verstehen müssen, auf welchen Typ sie sich bezieht und welche Einschränkungen die Antwort enthält.

- Die nächsten beiden Aufgaben sind wahrscheinlich der größte Hype. Dies sind Frage-Antwort- und Dialogsysteme (Chat-Bots). Amazon Alexa, Alice sind klassische Beispiele für Konversationssysteme. Damit sie ordnungsgemäß funktionieren, müssen viele NLP-Aufgaben gelöst werden. Mithilfe der Textklassifizierung können Sie beispielsweise feststellen, ob wir in eines der zielorientierten Chatbot-Szenarien fallen. Angenommen, "die Frage der Wechselkurse". Das Extrahieren von Beziehungen ist erforderlich, um Platzhalter für die Skriptvorlage zu identifizieren, und die Aufgabe, einen Dialog über allgemeine Themen („Sprecher“) zu führen, hilft uns in einer Situation, in der wir in keines der Szenarien geraten sind.
Frage-Antwort-Systeme sind ebenfalls verständlich und nützlich. Wenn Sie einem Auto eine Frage stellen, sucht das Auto in einer Datenbank oder einem Textkörper nach einer Antwort darauf. Beispiele für solche Systeme sind IBM Watson oder Wolfram Alpha. - Ein weiteres Beispiel für das klassische NLP-Problem ist die Sammarisierung. Die Erklärung des Problems ist einfach: Das Eingabesystem akzeptiert großen Text, und die Ausgabe ist ein kleinerer Text, der irgendwie den Inhalt eines großen Textes widerspiegelt. Beispielsweise muss eine Maschine eine Nacherzählung eines Textes, seines Namens oder einer Anmerkung generieren.

- Eine weitere beliebte Aufgabe ist das Argumentation Mining, die Suche nach Rechtfertigung im Text. Sie erhalten eine Tatsache und einen Text, Sie müssen eine Rechtfertigung für diese Tatsache im Text finden.
Dies ist keineswegs die gesamte Liste der NLP-Aufgaben. Es gibt Dutzende von ihnen. Im Großen und Ganzen kann alles, was mit Text in einer natürlichen Sprache getan werden kann, den Aufgaben von NLP zugeordnet werden. Nur die aufgeführten Themen sind nach Gehör und sie haben die offensichtlichsten praktischen Anwendungen.
Warum ist es schwierig, NLP-Aufgaben zu lösen?
Der Wortlaut der Aufgaben ist nicht sehr kompliziert, aber die Aufgaben selbst sind überhaupt nicht einfach, weil wir mit der natürlichen Sprache arbeiten. Die Phänomene Polysemie (polysemische Wörter haben eine gemeinsame Anfangsbedeutung) und Homonymie (Wörter mit unterschiedlichen Bedeutungen werden gleich ausgesprochen und geschrieben) sind charakteristisch für jede natürliche Sprache. Und wenn ein russischer Muttersprachler gut versteht, dass
warmer Empfang wenig mit
Kampftechnik einerseits und
warmem Bier andererseits zu tun hat, muss das automatische System dies lange lernen. Warum es besser ist, "
Leertaste drücken, um fortzufahren " in langweiliges "
Drücken Sie die Leertaste, um fortzufahren " zu übersetzen
, als "Die
Leertaste wird weiterhin funktionieren ".
- Polysemie: Stopp (Prozess oder Gebäude), Tisch (Organisation oder Objekt), Specht (Vogel oder Person).
- Homonymie: Schlüssel, Bogen, Schloss, Herd.

- Ein weiteres klassisches Beispiel für Sprachkomplexität ist das Pronomen anaphora. Nehmen wir zum Beispiel den Text " Hausmeister zwei Stunden Schnee, er war unzufrieden ." Das Pronomen "er" kann sich sowohl auf den Hausmeister als auch auf den Schnee beziehen. Im Zusammenhang verstehen wir leicht, dass er ein Hausmeister ist, kein Schnee. Aber zu erreichen, dass der Computer dies auch leicht verstand, ist nicht einfach. Das Problem des Pronomen Anaphora ist immer noch nicht sehr gut gelöst, und es werden weiterhin aktive Versuche unternommen, die Qualität der Entscheidungen zu verbessern.
- Eine weitere zusätzliche Komplexität ist die Ellipse. Zum Beispiel: " Petja aß einen grünen Apfel und Mascha aß einen roten ." Wir verstehen, dass Mascha einen roten Apfel gegessen hat. Es ist jedoch nicht einfach, die Maschine dazu zu bringen, dies zu verstehen. Jetzt wird die Aufgabe der Wiederherstellung der Ellipse in winzigen Fällen (mehrere hundert Sätze) gelöst, und bei ihnen ist die Qualität der vollständigen Wiederherstellung offen gesagt schwach (in der Größenordnung von 0,5). Es ist klar, dass für praktische Anwendungen eine solche Qualität nicht gut ist.
Übrigens werden dieses Jahr auf der
Dialogkonferenz Tracks sowohl zu Anaphoren als auch zu Lücken (eine Art Ellipse) für die russische Sprache gehalten. Für beide Aufgaben wurden Fälle mit einem Volumen zusammengestellt, das um ein Vielfaches größer ist als das Volumen der derzeit vorhandenen Gebäude (außerdem ist das Volumen des Falles für Lücken um eine Größenordnung größer als das Volumen der Fälle, nicht nur für Russisch, sondern im Allgemeinen für alle Sprachen). Wenn Sie an Wettbewerben in diesen Gebäuden teilnehmen möchten,
klicken Sie hier (mit Registrierung, jedoch ohne SMS) .
Wie NLP-Aufgaben gelöst werden
Im Gegensatz zur Bildverarbeitung finden Sie auf NLP immer noch Artikel, die Lösungen beschreiben, die klassische Algorithmen wie
SVM oder
Xgboost verwenden , keine neuronalen Netze, und die Ergebnisse zeigen, die den Lösungen auf dem
neuesten Stand der Technik nicht zu unterlegen sind.
Vor einigen Jahren begannen neuronale Netze jedoch, klassische Modelle zu besiegen. Es ist wichtig anzumerken, dass für die meisten Aufgaben die auf klassischen Methoden basierenden Lösungen in der Regel einzigartig waren und nicht mit der Lösung anderer Probleme sowohl in der Architektur als auch in der Art und Weise, wie die Erfassung und Verarbeitung von Attributen erfolgt, vergleichbar waren.
Neuronale Netzwerkarchitekturen sind jedoch viel allgemeiner. Die Architektur des Netzwerks selbst ist höchstwahrscheinlich ebenfalls unterschiedlich, aber viel kleiner, es besteht eine Tendenz zur vollständigen Universalisierung. Mit welchen Funktionen und wie genau wir arbeiten, ist es jedoch für die meisten NLP-Aufgaben bereits fast gleich. Nur die letzten Schichten neuronaler Netze unterscheiden sich. Wir können also davon ausgehen, dass eine einzelne NLP-Pipeline gebildet wurde. Über die Anordnung werden wir Ihnen jetzt mehr erzählen.
Pipeline nlp
Diese Art der Arbeit mit Zeichen ist für alle Aufgaben mehr oder weniger gleich.
Wenn es um Sprache geht, ist die Grundeinheit, mit der wir arbeiten, das Wort. Oder formeller ein "Token". Wir verwenden diesen Begriff, weil nicht sehr klar ist, was 2128506 ist - ist das ein Wort oder nicht? Die Antwort ist nicht offensichtlich. Das Token wird normalerweise durch Leerzeichen oder Satzzeichen von anderen Token getrennt. Und wie Sie anhand der oben beschriebenen Schwierigkeiten verstehen können, ist der Kontext jedes Tokens sehr wichtig. Es gibt verschiedene Ansätze, aber in 95% der Fälle ist der Kontext, der bei der Arbeit des Modells berücksichtigt wird, ein Vorschlag, der das erste Token enthält.
Viele Aufgaben werden in der Regel auf Vorschlagsebene gelöst. Zum Beispiel maschinelle Übersetzung. Meistens übersetzen wir einfach einen Satz und verwenden überhaupt keinen breiteren Kontext. Es gibt Aufgaben, bei denen dies nicht der Fall ist, beispielsweise Dialogsysteme. Es ist wichtig, sich daran zu erinnern, worüber das System zuvor gefragt wurde, damit es Fragen beantworten kann. Das Angebot ist jedoch auch die Haupteinheit, mit der wir arbeiten.
Daher sind die ersten beiden Schritte der Pipeline, die ausgeführt werden, um fast jede Aufgabe zu lösen, Segmentierung (Teilen von Text in Sätze) und Tokenisierung (Teilen von Sätzen in Token, dh einzelne Wörter). Dies geschieht mit einfachen Algorithmen.
Als nächstes müssen Sie die Eigenschaften jedes Tokens berechnen. Dies geschieht in der Regel in zwei Schritten. Die erste besteht darin, kontextunabhängige Tokenattribute zu berechnen. Dies ist eine Reihe von Zeichen, die in keiner Weise von anderen Worten abhängen, die unser Zeichen umgeben. Gemeinsame kontextunabhängige Attribute sind:
- Einbettungen
- symbolische Zeichen
- zusätzliche Funktionen, die für eine bestimmte Aufgabe oder Sprache spezifisch sind
Wir werden im Folgenden ausführlicher über Einbettungen und symbolische Zeichen sprechen (über symbolische Zeichen - nicht heute, sondern im zweiten Teil unseres Artikels), aber lassen Sie uns zunächst mögliche Beispiele für zusätzliche Zeichen geben.
Eine der am häufigsten verwendeten Funktionen ist der Teil der Sprache oder das POS-Tag (Teil der Sprache). Solche Funktionen können wichtig sein, um viele Probleme zu lösen, z. B. Parsing-Aufgaben. Für Sprachen mit komplexer Morphologie wie die russische Sprache sind auch morphologische Zeichen wichtig: In welchem Fall ist das Substantiv, welche Art von Adjektiv. Daraus können wir unterschiedliche Schlussfolgerungen über die Struktur des Vorschlags ziehen. Außerdem wird Morphologie für die Lemmatisierung (Reduktion von Wörtern auf Anfangsformen) benötigt, mit deren Hilfe wir die Dimension des Attributraums reduzieren können, und daher wird die morphologische Analyse für die meisten NLP-Probleme aktiv verwendet.
Wenn wir ein Problem lösen, bei dem die Interaktion zwischen verschiedenen Objekten wichtig ist (z. B. bei der Beziehungsextraktionsaufgabe oder beim Erstellen eines Frage-Antwort-Systems), müssen wir viel über die Struktur des Vorschlags wissen. Dies erfordert eine Analyse. In der Schule hat jeder einen Satz für ein Thema, ein Prädikat, eine Addition usw. analysiert. Die syntaktische Analyse ist etwas in diesem Sinne, aber komplizierter.
Ein weiteres Beispiel für eine zusätzliche Funktion ist die Position des Tokens im Text. Wir können a priori wissen, dass eine Entität häufiger am Anfang des Textes zu finden ist oder umgekehrt am Ende.
Alles zusammen - Einbettungen, symbolische und zusätzliche Zeichen - bilden einen Vektor von Token-Zeichen, der nicht vom Kontext abhängt.
Kontextsensitive Funktionen
Kontextsensitive Token-Zeichen sind eine Reihe von Zeichen, die nicht nur Informationen über das Token selbst, sondern auch über seine Nachbarn enthalten. Es gibt verschiedene Möglichkeiten, diese Symptome zu berechnen. Bei klassischen Algorithmen gingen die Leute oft einfach am „Fenster“ vorbei: Sie nahmen mehrere (zum Beispiel drei) Token zum Original und mehrere Token danach und berechneten dann alle Zeichen in einem solchen Fenster. Dieser Ansatz ist unzuverlässig, da wichtige Informationen für die Analyse möglicherweise in einem größeren Abstand als das Fenster liegen und wir möglicherweise etwas übersehen.
Daher werden jetzt alle kontextsensitiven Funktionen auf Vorschlagsebene auf standardmäßige Weise berechnet: unter Verwendung von in zwei Richtungen wiederkehrenden neuronalen Netzen LSTM oder GRU. Um kontextsensitive Tokenattribute aus kontextunabhängigen, kontextunabhängigen Attributen aller Angebotstoken zu erhalten, werden diese an das bidirektionale RNN (ein- oder mehrschichtig) gesendet. Die Ausgabe des bidirektionalen RNN zum i-ten Zeitpunkt ist ein kontextsensitives Zeichen des i-ten Tokens, das Informationen zu beiden vorherigen Token (da diese Informationen im i-ten Wert des direkten RNN enthalten sind) und zum nachfolgenden Token enthält Diese Informationen sind im entsprechenden Wert des inversen RNN enthalten.
Außerdem machen wir für jede einzelne Aufgabe etwas anderes, aber die ersten Schichten - bis hin zur bidirektionalen RNN - können für fast jede Aufgabe verwendet werden.
Diese Methode zum Abrufen von Features wird als NLP-Pipeline bezeichnet.
Es ist erwähnenswert, dass Forscher in den letzten 2 Jahren aktiv versucht haben, die NLP-Pipeline zu verbessern - sowohl in Bezug auf die Geschwindigkeit (z. B. Transformator - eine auf Selbstaufmerksamkeit basierende Architektur, die kein RNN enthält und daher schneller lernen und anwenden kann) als auch mit Sicht der verwendeten Zeichen (jetzt verwenden sie aktiv Zeichen, die auf vorab trainierten Sprachmodellen basieren, beispielsweise
ELMo , oder sie verwenden die ersten Schichten des vorab trainierten Sprachmodells und trainieren sie in dem für die Aufgabe verfügbaren Fall -
ULMFit ,
BERT ).
Einbettungen in Wortform
Schauen wir uns die Einbettung genauer an. Grob gesagt ist das Einbetten eine prägnante Darstellung des Kontextes eines Wortes. Warum ist es wichtig, den Kontext eines Wortes zu kennen? Weil wir an eine Verteilungshypothese glauben - dass Wörter mit ähnlicher Bedeutung in ähnlichen Kontexten verwendet werden.
Versuchen wir nun, die Einbettung genau zu definieren. Das Einbetten ist eine Abbildung von einem diskreten Vektor kategorialer Merkmale in einen kontinuierlichen Vektor mit einer vorbestimmten Dimension.
Ein kanonisches Beispiel für das Einbetten ist das Einbetten von Wörtern (Einbetten in Wortform).
Was wirkt normalerweise als diskreter Merkmalsvektor? Ein boolescher Vektor, der allen möglichen Werten einer bestimmten Kategorie entspricht (z. B. alle möglichen Wortarten oder alle möglichen Wörter aus einem begrenzten Wörterbuch).
Bei Einbettungen in Wortform ist diese Kategorie normalerweise der Index des Wortes im Wörterbuch. Angenommen, es gibt ein Wörterbuch mit einer Größe von 100.000. Dementsprechend hat jedes Wort einen diskreten Merkmalsvektor - einen Booleschen Vektor der Dimension 100.000, wobei an einer Stelle (der Index des Wortes in unserem Wörterbuch) eins ist und der Rest Nullen sind.
Warum möchten wir unsere diskreten Merkmalsvektoren auf kontinuierliche gegebene Dimensionen abbilden? Weil Vektoren mit einer Dimension von 100.000 nicht sehr bequem für Berechnungen zu verwenden sind, sind Vektoren von ganzen Zahlen mit den Dimensionen 100, 200 oder beispielsweise 300 viel bequemer.
Grundsätzlich dürfen wir nicht versuchen, einer solchen Zuordnung zusätzliche Einschränkungen aufzuerlegen. Da wir jedoch eine solche Zuordnung erstellen, sollten wir sicherstellen, dass die Vektoren ähnlich aussagekräftiger Wörter auch in gewissem Sinne nahe beieinander liegen. Dies erfolgt unter Verwendung eines einfachen neuronalen Feed-Forward-Netzwerks.
Einbettungstraining
Wie werden Einbettungen trainiert? Wir versuchen, das Problem der Wiederherstellung eines Wortes nach Kontext zu lösen (oder umgekehrt, einen Kontext nach Wort wiederherzustellen). Im einfachsten Fall erhalten wir den Index im Wörterbuch des vorherigen Wortes (den Booleschen Vektor der Wörterbuchdimension) als Eingabe und versuchen, den Index im Wörterbuch unseres Wortes zu bestimmen. Dies geschieht mithilfe eines Rasters mit einer äußerst einfachen Architektur: zwei vollständig verbundenen Schichten. Zuerst kommt eine vollständig verbundene Schicht vom Booleschen Vektor der Dimension des Wörterbuchs zur verborgenen Schicht der Dimension der Einbettung (d. H. Nur Multiplizieren des Booleschen Vektors mit der Matrix der gewünschten Dimension). Und umgekehrt, eine vollständig verbundene Ebene mit Softmax aus einer verborgenen Dimensionsebene, die in einen Wörterbuch-Dimensionsvektor eingebettet ist. Dank der Softmax-Aktivierungsfunktion erhalten wir die Wahrscheinlichkeitsverteilung unseres Wortes und können die wahrscheinlichste Option auswählen.
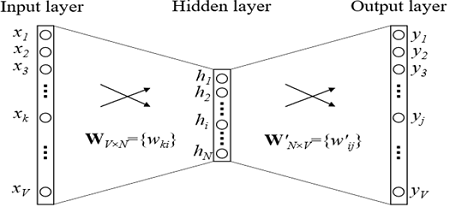
In den in der Praxis verwendeten Modellen ist die Architektur komplexer, aber nicht viel. Der Hauptunterschied besteht darin, dass wir nicht einen Vektor aus dem Kontext verwenden, um unser Wort zu definieren, sondern mehrere (zum Beispiel alles in einem Fenster der Größe 3). Eine etwas populärere Option ist, wenn wir versuchen, nicht ein Wort nach Kontext, sondern einen Kontext nach Wort vorherzusagen. Dieser Ansatz wird Skip-Gramm genannt.
Lassen Sie uns ein Beispiel für die Anwendung einer Aufgabe geben, die während des Trainings von Einbettungen gelöst wird (in der CBOW-Variante Wortvorhersagen nach Kontext). Angenommen, ein Token-Kontext besteht aus zwei vorherigen Wörtern. “ ”, , , “”.
, ( ), , .
, , , (, , ). — .
, , . , , , .
, — ELMo, ULMFit, BERT. , ( , , , ).
?
, 2 .
- -, , , - 100 . – : , , .
- -, . -. . . , , . , , . . , , .
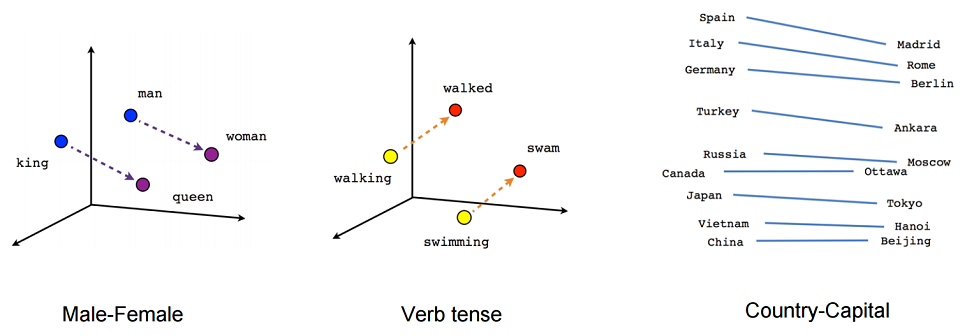
, .
, , , , , . , , , , .
NER. , , . , , , , .