
Anfang 2018 wurde ein Artikel veröffentlicht. Deep Reinforcement Learning funktioniert noch nicht ("Lernen mit Verstärkung funktioniert noch nicht."). Die Hauptbeschwerde war, dass moderne Lernalgorithmen mit Verstärkung ungefähr die gleiche Zeit benötigen, um ein Problem zu lösen wie eine reguläre Zufallssuche.
Hat sich seitdem etwas geändert? Nein.
Verstärktes Lernen wird als einer der drei Hauptpfade zum Aufbau einer starken KI angesehen. Die Schwierigkeiten in diesem Bereich des maschinellen Lernens und die Methoden, mit denen Wissenschaftler versuchen, mit diesen Schwierigkeiten umzugehen, lassen jedoch darauf schließen, dass dieser Ansatz selbst möglicherweise grundlegende Probleme aufweist.
Warten Sie, was bedeutet einer von drei? Was sind die anderen beiden?
Angesichts des Erfolgs neuronaler Netze in den letzten Jahren und der Analyse, wie sie mit kognitiven Fähigkeiten auf hoher Ebene arbeiten, die früher nur für Menschen und höhere Tiere als charakteristisch angesehen wurden, gibt es heute in der wissenschaftlichen Gemeinschaft die Meinung, dass es drei Hauptansätze zur Schaffung einer starken KI gibt die Basis neuronaler Netze, die als mehr oder weniger realistisch angesehen werden können:
1. Textverarbeitung
Die Welt hat eine große Anzahl von Büchern und Texten im Internet gesammelt, einschließlich Lehrbüchern und Nachschlagewerken. Der Text ist bequem und schnell für die Verarbeitung auf einem Computer. Theoretisch sollte diese Reihe von Texten ausreichen, um eine starke Konversations-KI zu trainieren.
Es wird impliziert, dass sich in diesen Textfeldern die gesamte Struktur der Welt widerspiegelt (zumindest wird sie in Lehrbüchern und Nachschlagewerken beschrieben). Dies ist jedoch überhaupt keine Tatsache. Texte als Form der Darstellung von Informationen sind stark von der realen dreidimensionalen Welt und dem Zeitverlauf, in dem wir leben, getrennt.
Gute Beispiele für KI, die auf Textarrays trainiert wurden, sind Chat-Bots und automatische Übersetzer. Um den Text zu übersetzen, müssen Sie die Bedeutung der Phrase verstehen und sie in neuen Wörtern (in einer anderen Sprache) nacherzählen. Es gibt ein weit verbreitetes Missverständnis, dass Grammatik- und Syntaxregeln, einschließlich einer Beschreibung aller möglichen Ausnahmen, eine bestimmte Sprache vollständig beschreiben. Es ist nicht so. Sprache ist nur ein Hilfsmittel im Leben, sie ändert sich leicht und passt sich neuen Situationen an.
Das Problem bei der Textverarbeitung (auch durch Expertensysteme, sogar neuronale Netze) besteht darin, dass es keine Regeln gibt, welche Phrasen in welchen Situationen angewendet werden sollten. Bitte beachten Sie - nicht die Regeln für die Erstellung der Phrasen selbst (was Grammatik und Syntax bewirken), sondern welche Phrasen in welchen Situationen. In der gleichen Situation sprechen Menschen Phrasen in verschiedenen Sprachen aus, die im Allgemeinen in Bezug auf die Struktur der Sprache nicht miteinander verwandt sind. Vergleichen Sie Sätze mit äußerster Überraschung: "Oh Gott!" und "o heilige Scheiße!". Nun, und wie kann man eine Korrespondenz zwischen ihnen herstellen, wenn man das Sprachmodell kennt? Auf keinen Fall. Es ist historisch zufällig passiert. Sie müssen die Situation kennen und wissen, was sie normalerweise in einer bestimmten Sprache sprechen. Aus diesem Grund sind automatische Übersetzer so unvollkommen.
Ob dieses Wissen nur von einer Reihe von Texten unterschieden werden kann, ist unbekannt. Wenn automatische Übersetzer jedoch perfekt übersetzen, ohne dumme und lächerliche Fehler zu machen, ist dies ein Beweis dafür, dass die Erstellung einer starken KI nur auf der Grundlage von Text möglich ist.
2. Bilderkennung
Schau dir dieses Bild an

Wenn wir uns dieses Foto ansehen, verstehen wir, dass nachts geschossen wurde. Den Fahnen nach zu urteilen, weht der Wind von rechts nach links. Und nach dem Rechtsverkehr zu urteilen, ist der Fall in England oder Australien nicht der Fall. Keine dieser Informationen wird explizit in den Pixeln des Bildes angegeben, dies ist externes Wissen. Auf dem Foto gibt es nur Zeichen, anhand derer wir das Wissen aus anderen Quellen nutzen können.
Wissen Sie noch etwas, das dieses Bild betrachtet?Darüber und über die Rede ... Und finden Sie sich endlich ein Mädchen
Daher wird angenommen, dass ein neuronales Netzwerk, das Objekte in einem Bild erkennt, eine interne Vorstellung davon hat, wie die reale Welt funktioniert. Und diese Ansicht, die sich aus den Fotografien ergibt, wird sicherlich unserer realen und realen Welt entsprechen. Im Gegensatz zu Textfeldern, bei denen dies nicht garantiert ist.
Der Wert neuronaler Netze, die auf einem ImageNet-Array von Fotos (und jetzt OpenImages V4 , COCO , KITTI , BDD100K und anderen) trainiert wurden , ist keineswegs die Tatsache, dass eine Katze auf einem Foto erkannt wird. Und das ist in der vorletzten Ebene gespeichert. Hier befinden sich eine Reihe von Funktionen auf hoher Ebene, die unsere Welt beschreiben. Ein Vektor mit 1024 Zahlen reicht aus, um eine Beschreibung von 1000 verschiedenen Kategorien von Objekten mit einer Genauigkeit von 80% zu erhalten (und in 95% der Fälle liegt die richtige Antwort in den 5 nächstgelegenen Optionen). Denken Sie nur darüber nach.
Aus diesem Grund werden diese Funktionen aus der vorletzten Ebene bei völlig unterschiedlichen Aufgaben in der Bildverarbeitung so erfolgreich eingesetzt. Durch Transferlernen und Feinabstimmung. Aus diesem Vektor in 1024 Zahlen können Sie beispielsweise eine Tiefenkarte aus dem Bild erhalten
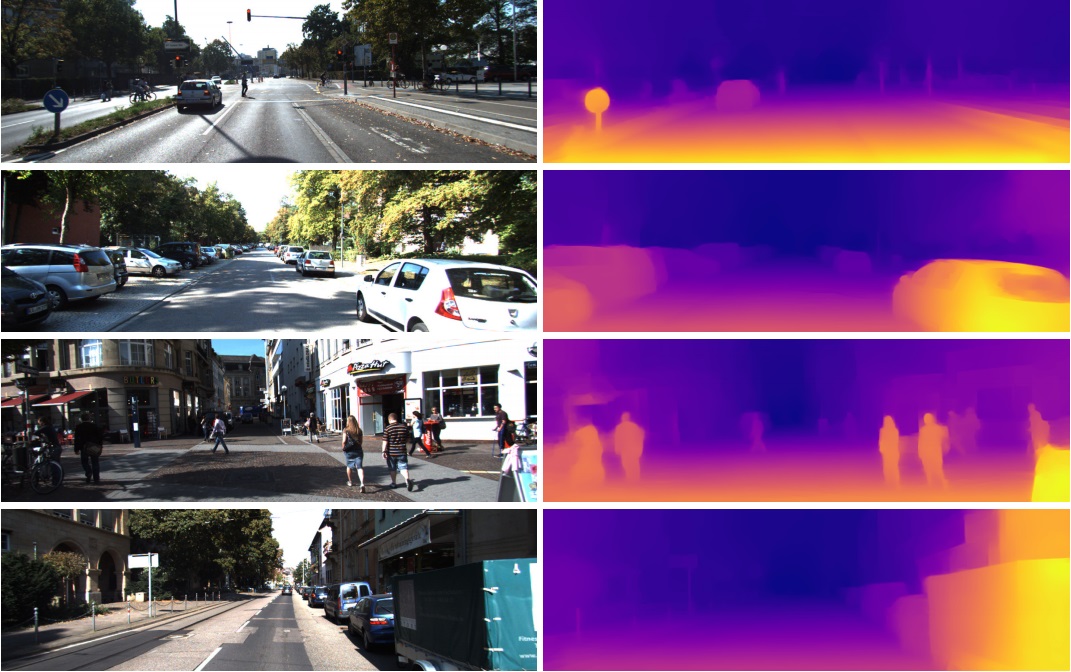
(Ein Beispiel aus der Arbeit, in der ein praktisch unverändertes vorab trainiertes Densenet-169-Netzwerk verwendet wird)
Oder bestimmen Sie die Pose einer Person. Es gibt viele Anwendungen.
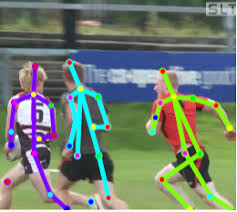
Infolgedessen kann die Bilderkennung möglicherweise verwendet werden, um eine starke KI zu erzeugen, da sie das Modell unserer realen Welt wirklich widerspiegelt. Ein Schritt von der Fotografie zum Video und zum Video ist unser Leben, da wir ungefähr 99% der Informationen visuell erhalten.
Auf dem Foto ist jedoch völlig unverständlich, wie das neuronale Netzwerk zum Denken und Ziehen von Schlussfolgerungen motiviert werden kann. Sie kann trainiert werden, um Fragen wie "Wie viele Stifte liegen auf dem Tisch?" Zu beantworten. (Diese Aufgabenklasse heißt Visual Question Answering, ein Beispiel für einen solchen Datensatz: https://visualqa.org ). Oder geben Sie eine Textbeschreibung darüber, was auf dem Foto passiert. Dies ist die Taskklasse für Bildunterschriften .

Aber ist das Intelligenz? Nachdem sie diesen Ansatz entwickelt haben, können neuronale Netze in naher Zukunft Videofragen beantworten wie "Zwei Spatzen saßen auf den Drähten, einer von ihnen flog weg, wie viele Spatzen waren noch übrig?". Dies ist echte Mathematik, in etwas komplizierteren Fällen, für Tiere unzugänglich und auf der Ebene der menschlichen Schulbildung. Vor allem, wenn außer Spatzen neben ihnen Titten sitzen, die aber nicht berücksichtigt werden müssen, da es sich nur um Spatzen handelte. Ja, es wird definitiv Intelligenz sein.
3. Reinforcement Learning
Die Idee ist sehr einfach: Aktionen zu fördern, die zur Belohnung führen, und zu vermeiden, dass sie zum Scheitern führen. Dies ist eine universelle Art des Lernens und kann natürlich definitiv zur Schaffung einer starken KI führen. Daher gab es in den letzten Jahren so viel Interesse an Reinforcement Learning.
Mischen, aber nicht schüttelnNatürlich ist es am besten, eine starke KI zu schaffen, indem Sie alle drei Ansätze kombinieren. In Bildern und mit Verstärkungstraining können Sie KI auf Tierniveau erhalten. Und theoretisch können Sie den Bildern Textnamen von Objekten hinzufügen (ein Witz natürlich - die KI dazu zwingen, Videos anzusehen, in denen Menschen interagieren und sprechen, wie beim Unterrichten eines Babys), und eine Umschulung in einem Textfeld vornehmen, um Wissen zu erlangen (ein Analogon unserer Schule und Universität) KI auf menschlicher Ebene. Kann reden.
Verstärktes Lernen hat ein großes Plus. Im Simulator können Sie ein vereinfachtes Modell der Welt erstellen. Für eine menschliche Figur reichen also nur 17 Freiheitsgrade aus, anstatt 700 bei einer lebenden Person (ungefähre Anzahl von Muskeln). Daher können Sie im Simulator das Problem in einer sehr kleinen Dimension lösen.
Mit Blick auf die Zukunft können moderne Reinforcement Learning-Algorithmen das Modell einer Person selbst bei 17 Freiheitsgraden nicht willkürlich steuern. Das heißt, sie können das Optimierungsproblem nicht lösen, bei dem 44 Zahlen am Eingang und 17 am Eingang vorhanden sind. Dies ist nur in sehr einfachen Fällen möglich, wobei die Anfangsbedingungen und Hyperparameter genau eingestellt werden. Und selbst in diesem Fall benötigen Sie mehrere Tage Berechnungen auf einer leistungsstarken GPU, um beispielsweise ein humanoides Modell mit 17 Freiheitsgraden zum Laufen zu unterrichten und von einer stehenden Position aus zu starten (was viel einfacher ist). Und etwas kompliziertere Fälle, zum Beispiel das Lernen, aus einer willkürlichen Pose aufzustehen, lernen möglicherweise überhaupt nicht. Dies ist ein Fehler.
Darüber hinaus arbeiten alle Reinforcement Learning-Algorithmen mit bedrückend kleinen neuronalen Netzen, können jedoch keine großen lernen. Große Faltungsnetzwerke werden nur verwendet, um die Dimension des Bildes auf mehrere Merkmale zu reduzieren, die den Lernalgorithmen mit Verstärkung zugeführt werden. Der gleiche laufende Humanoid wird von einem Feed Forward-Netzwerk mit zwei oder drei Schichten von 128 Neuronen gesteuert. Wirklich? Und versuchen wir auf dieser Grundlage, eine starke KI aufzubauen?
Um zu verstehen, warum dies geschieht und was beim Lernen von Verstärkung falsch ist, müssen Sie sich zunächst mit den grundlegenden Architekturen des modernen Lernens von Verstärkung vertraut machen.
Die physische Struktur des Gehirns und des Nervensystems wird durch die Evolution auf den spezifischen Tiertyp und seine Lebensbedingungen abgestimmt. Im Laufe der Evolution entwickelte eine Fliege ein solches Nervensystem und eine solche Arbeit von Neurotransmittern in den Ganglien (ein Analogon des Gehirns bei Insekten), um einer Fliegenklatsche schnell auszuweichen. Nun, nicht von einer Fliegenklatsche, sondern von Vögeln, die seit 400 Millionen Jahren gefischt haben (nur ein Scherz, die Vögel selbst erschienen vor 150 Millionen Jahren, höchstwahrscheinlich von Fröschen vor 360 Millionen Jahren). Ein Nashorn hat genug Nervensystem und Gehirn, um sich langsam dem Ziel zuzuwenden und zu rennen. Und dort, wie sie sagen, hat das Nashorn schlechtes Sehvermögen, aber das ist nicht sein Problem.
Zusätzlich zur Evolution arbeitet jedes einzelne Individuum von der Geburt an und während des gesamten Lebens genau den üblichen Lernmechanismus mit Verstärkung. Bei Säugetieren und auch bei Insekten erledigt das Dopaminsystem diese Arbeit. Ihre Arbeit ist voller Geheimnisse und Nuancen, aber alles läuft darauf hinaus, dass das Dopaminsystem im Falle einer Auszeichnung durch Gedächtnismechanismen die Verbindungen zwischen Neuronen, die unmittelbar zuvor aktiv waren, irgendwie repariert. So entsteht assoziatives Gedächtnis.
Was aufgrund seiner Assoziativität dann bei der Entscheidungsfindung verwendet wird. Einfach ausgedrückt, wenn die aktuelle Situation (aktuelle aktive Neuronen in dieser Situation) durch assoziatives Gedächtnis Lustneuronen aktiviert, wählt die Person die Aktionen aus, die sie in einer ähnlichen Situation ausgeführt hat und an die sie sich erinnert. "Wählt Aktionen" ist eine schlechte Definition. Es gibt keine Wahl. Einfach aktivierte Lustgedächtnisneuronen, die vom Dopaminsystem für eine bestimmte Situation fixiert werden, aktivieren automatisch Motoneuronen, was zu einer Muskelkontraktion führt. Dies ist der Fall, wenn sofortige Maßnahmen erforderlich sind.
Künstliches Lernen mit Verstärkung als Wissensgebiet ist es notwendig, beide Probleme zu lösen:
1. Wählen Sie die Architektur des neuronalen Netzwerks (was die Evolution bereits für uns getan hat)
Die gute Nachricht ist, dass höhere kognitive Funktionen im Neokortex bei Säugetieren (und im Striatum bei Korviden ) in einer annähernd einheitlichen Struktur ausgeführt werden. Anscheinend braucht dies keine streng vorgeschriebene "Architektur".
Die Vielfalt der Hirnregionen ist wahrscheinlich auf rein historische Gründe zurückzuführen. Als sie sich weiterentwickelten, wuchsen neue Teile des Gehirns zusätzlich zu den grundlegenden Teilen, die von den ersten Tieren übrig geblieben waren. Nach dem Prinzip funktioniert es - nicht anfassen. Andererseits reagieren bei verschiedenen Menschen dieselben Teile des Gehirns auf dieselben Situationen. Dies kann sowohl durch die Assoziativität (Merkmale und "Großmutterneuronen", die sich an diesen Stellen während des Lernprozesses auf natürliche Weise gebildet haben) als auch durch die Physiologie erklärt werden. Dass in Genen kodierte Signalwege genau zu diesen Bereichen führen. Es gibt keinen Konsens, aber Sie können zum Beispiel diesen kürzlich erschienenen Artikel lesen: "Biologische und künstliche Intelligenz . "
2. Lernen Sie, wie Sie neuronale Netze nach den Prinzipien des Lernens mit Verstärkung trainieren
Dies ist, was modernes Reinforcement Learning hauptsächlich tut. Und was sind die Erfolge? Nicht sehr.
Naiver Ansatz
Es scheint sehr einfach zu sein, ein neuronales Netzwerk mit Verstärkung zu trainieren: Wir führen zufällige Aktionen aus, und wenn wir eine Belohnung erhalten, betrachten wir die ergriffenen Aktionen als „Referenz“. Wir setzen sie als Standardbezeichnungen auf die Ausgabe des neuronalen Netzwerks und trainieren das neuronale Netzwerk durch die Methode der Rückausbreitung des Fehlers, so dass es genau eine solche Ausgabe erzeugt. Nun, das häufigste neuronale Netzwerktraining. Und wenn die Aktionen zu einem Fehler geführt haben, ignorieren Sie entweder diesen Fall oder unterdrücken Sie diese Aktionen (wir legen einige andere als Ausgabe fest, z. B. jede andere zufällige Aktion). Im Allgemeinen wiederholt diese Idee das Dopaminsystem.
Wenn Sie jedoch versuchen, ein neuronales Netzwerk auf diese Weise zu trainieren, egal wie komplex die Architektur ist, rekursiv, faltungsorientiert oder gewöhnliche direkte Verteilung, dann ... wird es nicht funktionieren!
Warum? Unbekannt
Es wird angenommen, dass das Nutzsignal so klein ist, dass es vor dem Hintergrund von Rauschen verloren geht. Daher lernt das Netzwerk nicht die Standardmethode zur Rückübertragung des Fehlers. Eine Belohnung kommt sehr selten vor, vielleicht einmal in Hunderten oder sogar Tausenden von Schritten. Und selbst LSTM merkt sich maximal 100-500 Punkte in der Geschichte und dann nur bei sehr einfachen Aufgaben. Bei komplexeren Fällen ist es jedoch bereits gut, wenn es 10 bis 20 Punkte in der Geschichte gibt.
Die Wurzel des Problems liegt jedoch gerade in sehr seltenen Belohnungen (zumindest bei Aufgaben von praktischem Wert). Im Moment wissen wir nicht, wie man neuronale Netze trainiert, die sich an Einzelfälle erinnern würden. Was das Gehirn mit Brillanz bewältigt. Sie können sich an etwas erinnern, das nur einmal im Leben passiert ist. Übrigens basiert der größte Teil der Ausbildung und Arbeit des Intellekts auf solchen Fällen.
Dies ist so etwas wie ein schreckliches Ungleichgewicht von Klassen aus dem Bereich der Bilderkennung. Es gibt einfach keine Möglichkeiten, damit umzugehen. Das Beste, was sie bisher finden konnten, ist einfach, dem Netzwerkeingang zusammen mit neuen Situationen erfolgreiche Situationen aus der Vergangenheit zu übermitteln, die in einem künstlichen Spezialpuffer gespeichert sind. Das heißt, ständig nicht nur neue Fälle zu lehren, sondern auch erfolgreiche alte. Natürlich kann ein solcher Puffer nicht unendlich erhöht werden, und es ist unklar, was genau darin gespeichert werden soll. Es wird immer noch versucht, die Pfade innerhalb des neuronalen Netzwerks, die während eines erfolgreichen Falls aktiv waren, vorübergehend zu reparieren, damit sie durch nachfolgendes Training nicht überschrieben werden. Eine ziemlich enge Analogie zu dem, was meiner Meinung nach im Gehirn passiert, obwohl sie auch in dieser Richtung noch nicht viel Erfolg haben. Da die neuen trainierten Aufgaben in ihrer Berechnung die Ergebnisse der Neuronen verwenden, die die eingefrorenen Pfade verlassen, stört das Signal nur die neuen eingefrorenen und die alten Aufgaben funktionieren nicht mehr. Es gibt noch einen anderen merkwürdigen Ansatz: Das Netzwerk mit neuen Beispielen / Aufgaben nur in orthogonaler Richtung zu früheren Aufgaben zu trainieren ( https://arxiv.org/abs/1810.01256 ). Dies überschreibt nicht die bisherigen Erfahrungen, schränkt jedoch die Netzwerkkapazität drastisch ein.
In Meta-Learning wird eine separate Klasse von Algorithmen entwickelt, die zur Bewältigung dieser Katastrophe entwickelt wurden (und gleichzeitig Hoffnung auf eine starke KI geben). Dies sind Versuche, einem neuronalen Netzwerk mehrere Aufgaben gleichzeitig beizubringen. Nicht in dem Sinne, dass es unterschiedliche Bilder in einer Aufgabe erkennt, nämlich unterschiedliche Aufgaben in unterschiedlichen Bereichen (jede mit ihrer eigenen Verteilungs- und Lösungslandschaft). Sagen Sie, erkennen Sie Bilder und fahren Sie gleichzeitig Fahrrad. Bisher ist der Erfolg auch nicht sehr gut, da es normalerweise darauf ankommt, ein neuronales Netzwerk mit allgemeinen universellen Gewichten im Voraus vorzubereiten und es dann in nur wenigen Schritten des Gradientenabfalls schnell an eine bestimmte Aufgabe anzupassen. Beispiele für Meta-Learning-Algorithmen sind MAML und Reptile .
Im Allgemeinen beendet nur dieses Problem (die Unfähigkeit, aus einzelnen erfolgreichen Beispielen zu lernen) das moderne Training mit Verstärkung. Die ganze Kraft neuronaler Netze vor dieser traurigen Tatsache ist bisher machtlos.
Diese Tatsache, dass der einfachste und offensichtlichste Weg nicht funktioniert, zwang die Forscher, zum klassischen tischbasierten Reinforcement Learning zurückzukehren. Was als Wissenschaft in der Antike auftauchte, als neuronale Netze noch nicht einmal im Projekt waren. Aber anstatt die Werte in Tabellen und Formeln manuell zu berechnen, verwenden wir jetzt einen so leistungsstarken Approximator wie neuronale Netze als Zielfunktionen! Dies ist die Essenz des modernen Reinforcement Learning. Und sein Hauptunterschied zum üblichen Training neuronaler Netze.
Q-Learning und DQN
Reinforcement Learning (noch vor den neuronalen Netzen) wurde als eine ziemlich einfache und originelle Idee geboren: Lassen Sie uns zufällige Aktionen ausführen, und dann berechnen wir für jede Zelle in der Tabelle und jede Bewegungsrichtung nach einer speziellen Formel (genannt Bellman-Gleichung, dieses Wort werden Sie in fast jeder Arbeit mit Verstärkungstraining zu treffen), wie gut diese Zelle und die gewählte Richtung sind. Je höher diese Zahl ist, desto wahrscheinlicher führt dieser Weg zum Sieg.
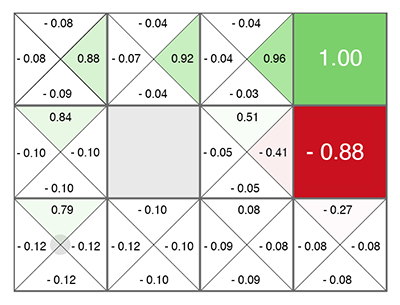
Egal in welcher Zelle Sie erscheinen, bewegen Sie sich entlang des wachsenden Grüns! (in Richtung der maximalen Anzahl an den Seiten der aktuellen Zelle).
Diese Zahl heißt Q (aus dem Wort Qualität - Qualität der Wahl natürlich), und die Methode ist Q-Learning. Deepmind ersetzte die Formel zur Berechnung dieser Zahl durch ein neuronales Netzwerk oder lehrte das neuronale Netzwerk mithilfe dieser Formel (plus ein paar weitere Tricks, die ausschließlich mit der Mathematik des Trainings neuronaler Netzwerke zusammenhängen) und erhielt die DQN- Methode. Dies ist, wer 2015 den Haufen von Atari-Spielen gewann und eine Revolution im Deep Reinforcement Learning einleitete.
Leider funktioniert diese Methode in ihrer Architektur nur mit diskreten diskreten Aktionen. Im DQN wird der aktuelle Zustand (die aktuelle Situation) dem Eingang des neuronalen Netzwerks zugeführt, und am Ausgang sagt das neuronale Netzwerk die Zahl Q voraus. Und da der Ausgang des Netzwerks alle möglichen Aktionen auf einmal auflistet (jede mit ihrem eigenen vorhergesagten Q), stellt sich heraus, dass das neuronale Netzwerk im DQN die klassische Funktion Q implementiert (s, a) aus Q-Learning. Q state action ( Q(s,a) s a). argmax Q , .
Q, . , Q- (.. Q , ). . , (Exploration), , , . , .
, ? 5 Atari, continuous ? , -1..1 0.1, , Atari. . , . 10 . - , 10 . . DQN , 17 . , , .
DQN, , , continuous ( ): DDQN, DuDQN, BDQN, CDQN, NAF, Rainbow. , Direct Future Prediction (DFP) , DQN . Q , DFP , . . , . , , , .
, Reinforcement Learning.
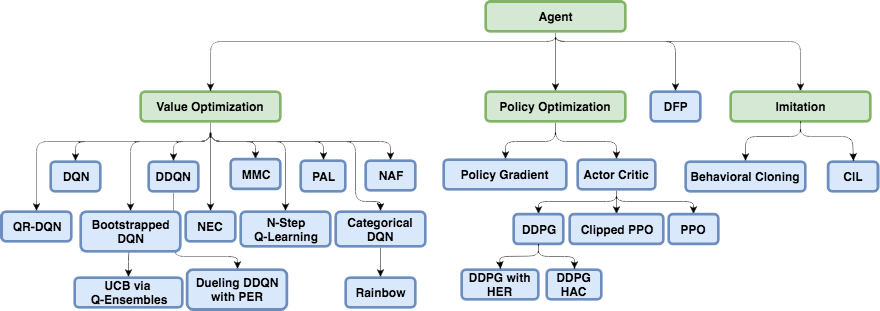
Policy Gradient
state, ( , ). , actions, . , R . ( ), ( ). . .
, R , , . ! . "" labels ( ), . , , R.
Policy Gradient. — , R, . — , , . , .
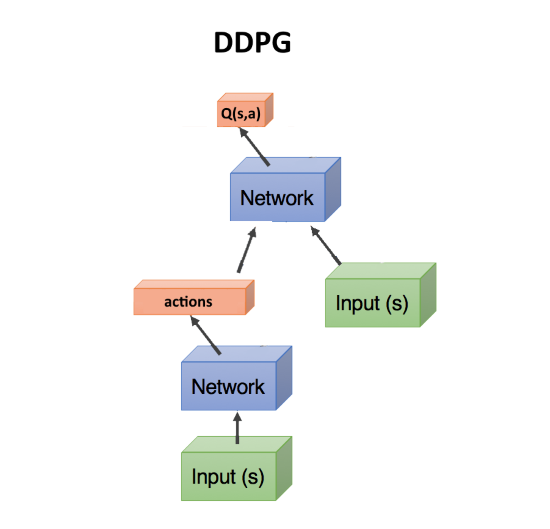
Actor-critic, DDPG
, — , . , Q- , DQN. state, action(s). state, action, , Q : Q(s,a).
, Q(s,a), ( critic, ), , ( , actor), R. , . actor-critic. Policy Gradient, , . .
DDPG. actions, continuous . DDPG continuous DQN .
Advantage Actor Critic (A3C/A2C)
critic Q(s,a) — , actor, DDPG. , .
, . , , , . , , , ( , ).
Q(s,a), Advantage: A(s,a) = Q(s,a) — V(s). A(s,a) Q(s,a) , — , V(s). A(s,a) > 0, , . A(s,a) < 0, , , .. .
V(s) state , ( s, a). — state, V(s). , state, V(s).
, Q(s,a) r, , A = r — V(s).
, V(s) ( ), — actor critic, ! state, head: actions, V(s). c , .. state. , .
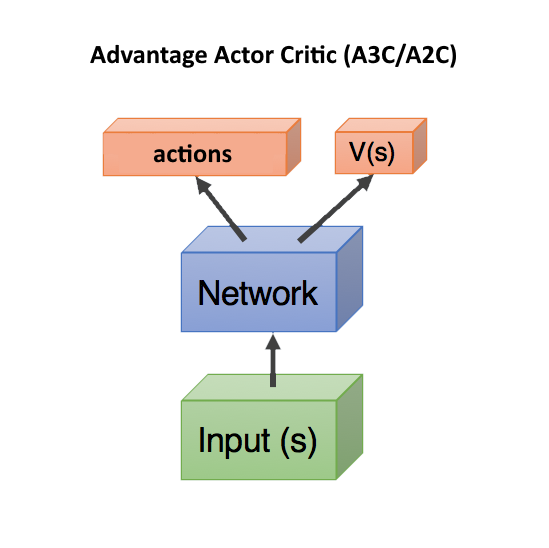
V(s) . V(s), action ( ), . Dueling Q-Network (DuDQN), Q(s,a) Q(s,a) = V(s) + A(a), .
Asynchronous Advantage Actor Critic (A3C) , , actor. batch . , actor. , , . , A2C — A3C, actor ( ). A2C , , .
TRPO, PPO, SAC
, .
, . Reinforcement Learning , , , — , . .
— TRPO PPO, state-of-the-art, Actor-Critic. PPO RL. , OpenAI Five Dota 2.
, TRPO PPO — , . , A3C/A2C , . , policy , . - gradient clipping , . , ( , ), , , - .
In letzter Zeit hat der SAC-Algorithmus (Soft-Actor-Critic) an Popularität gewonnen. Es unterscheidet sich nicht sehr von PPO, nur ein Ziel wurde hinzugefügt, wenn gelernt wurde, die Entropie in der Politik zu erhöhen. Machen Sie das Verhalten von Agenten zufälliger. Nein, nicht so. Dass der Agent in eher zufälligen Situationen handeln konnte. Dies erhöht automatisch die Zuverlässigkeit der Richtlinie, sobald der Agent für zufällige Situationen bereit ist. Darüber hinaus erfordert der SAC etwas weniger Trainingsbeispiele als PPO und reagiert weniger empfindlich auf Hyperparametereinstellungen, was ebenfalls von Vorteil ist. Selbst mit SAC benötigen Sie jedoch ungefähr 20 Millionen Frames und ungefähr einen Berechnungstag auf einer GPU, um einen Humanoiden für das Laufen mit 17 Freiheitsgraden ausgehend von einer stehenden Position zu trainieren. Schwierigere Anfangsbedingungen, um beispielsweise einem Humanoiden beizubringen, sich aus einer willkürlichen Pose zu erheben, werden möglicherweise überhaupt nicht gelehrt.
Insgesamt die allgemeine Empfehlung im modernen Reinforcement Learning: Verwenden Sie SAC, PPO, DDPG, DQN (in dieser Reihenfolge absteigend).
Modellbasiert
Es gibt einen anderen interessanten Ansatz, der indirekt mit dem verstärkten Lernen zusammenhängt. Dies dient dazu, ein Modell der Umgebung zu erstellen und damit vorherzusagen, was passieren wird, wenn wir Maßnahmen ergreifen.
Ihr Nachteil ist, dass sie in keiner Weise sagt, welche Maßnahmen ergriffen werden sollten. Nur über ihr Ergebnis. Ein solches neuronales Netzwerk ist jedoch einfach zu trainieren - trainieren Sie einfach alle Statistiken. Es stellt sich so etwas wie ein Weltsimulator heraus, der auf einem neuronalen Netzwerk basiert.
Danach generieren wir eine große Anzahl von zufälligen Aktionen, und jede wird durch diesen Simulator (über ein neuronales Netzwerk) gesteuert. Und wir schauen, welches die maximale Belohnung bringt. Es gibt eine kleine Optimierung - um nicht nur zufällige Aktionen zu generieren, sondern nach dem Normalgesetz von der aktuellen Flugbahn abzuweichen. Und tatsächlich, wenn wir unsere Hand heben, müssen wir sie mit hoher Wahrscheinlichkeit weiter heben. Daher müssen Sie zunächst die minimalen Abweichungen von der aktuellen Flugbahn überprüfen.
Der Trick dabei ist, dass selbst ein primitiver physikalischer Simulator wie MuJoCo oder pyBullet etwa 200 FPS erzeugt. Wenn Sie ein neuronales Netzwerk so trainieren, dass es mindestens einige Schritte vorwärts vorhersagt, können Sie in einfachen Umgebungen problemlos Stapel von 2000-5000 Vorhersagen gleichzeitig abrufen. Abhängig von der Leistung der GPU können Sie aufgrund der Parallelisierung in der GPU und der Rechengeschwindigkeit im neuronalen Netzwerk eine Prognose für Zehntausende von zufälligen Aktionen pro Sekunde erhalten. Das neuronale Netzwerk fungiert hier einfach als sehr schneller Simulator der Realität.
Da das neuronale Netzwerk die reale Welt vorhersagen kann (dies ist im Allgemeinen ein modellbasierter Ansatz), kann das Training sozusagen vollständig in der Vorstellungskraft durchgeführt werden. Dieses Konzept im Reinforcement Learning wird als Traumwelten oder Weltmodelle bezeichnet. Dies funktioniert gut, eine gute Beschreibung finden Sie hier: https://worldmodels.imtqy.com . Darüber hinaus hat es ein natürliches Gegenstück - gewöhnliche Träume. Und mehrfaches Scrollen der letzten oder geplanten Ereignisse im Kopf.
Nachahmung lernen
Aufgrund der Ohnmacht, dass die Reinforcement Learning-Algorithmen nicht für große Dimensionen und komplexe Aufgaben geeignet sind, haben sich die Menschen vorgenommen, die Handlungen von Experten zumindest in Form von Personen zu wiederholen. Hier wurden gute Ergebnisse erzielt (unerreichbar durch konventionelles Reinforcement Learning). Es stellte sich heraus, dass OpenAI das Spiel Montezumas Rache bestanden hat . Der Trick erwies sich als einfach - den Agenten sofort am Ende des Spiels (am Ende der von der Person angezeigten Flugbahn) zu platzieren. Dort lernt der Agent mithilfe von PPO dank der Nähe der endgültigen Belohnung schnell, auf der Flugbahn zu gehen. Danach setzen wir ihn ein wenig zurück, wo er schnell lernt, den Ort zu erreichen, den er bereits studiert hat. Wenn der Agent den "Respawn" -Punkt entlang der Flugbahn schrittweise bis zum Beginn des Spiels verschiebt, lernt er, die Flugbahn des Experten während des Spiels zu bestehen / zu simulieren.
Ein weiteres beeindruckendes Ergebnis ist die Wiederholung von Bewegungen für Personen, die mit Motion Capture: DeepMimic aufgenommen wurden . Das Rezept ähnelt der OpenAI-Methode: Jede Episode beginnt nicht am Anfang des Pfades, sondern an einem zufälligen Punkt entlang des Pfades. Dann untersucht PPO erfolgreich die Umgebung dieses Punktes.
Ich muss sagen, dass der sensationelle Go-Explore- Algorithmus von Uber, der Montezumas Revenge mit Rekordpunkten bestanden hat, überhaupt kein Reinforcement Learning-Algorithmus ist. Dies ist eine reguläre zufällige Suche, die jedoch mit einer zufällig besuchten Zellzelle beginnt (einer groben Zelle, in die mehrere Zustände fallen). Und nur wenn die Flugbahn bis zum Ende des Spiels durch eine solche zufällige Suche gefunden wird, wird das neuronale Netzwerk mithilfe von Imitation Learning trainiert. In ähnlicher Weise wie OpenAI, d.h. beginnend am Ende der Flugbahn.
Neugier (Neugier)
Ein sehr wichtiges Konzept beim Reinforcement Learning ist die Neugier. In der Natur ist es ein Motor für die Umweltforschung.
Das Problem ist, dass Sie als Maß für die Neugier keinen einfachen Netzwerkvorhersagefehler verwenden können, was als nächstes passieren wird. Andernfalls hängt ein solches Netzwerk mit schwankendem Laub vor dem ersten Baum. Oder vor einem Fernseher mit zufälliger Kanalumschaltung. Da das Ergebnis aufgrund der Komplexität nicht vorhersehbar ist und der Fehler immer groß ist. Dies ist jedoch genau der Grund, warum wir (Menschen) gerne Laub, Wasser und Feuer betrachten. Und wie andere Leute arbeiten =). Aber wir haben Schutzmechanismen, um nicht für immer zu hängen.
Einer dieser Mechanismen wurde als inverses Modell in der neugierigen Erforschung von erfunden
Selbstüberwachte Vorhersage . Kurz gesagt, ein Agent (neuronales Netzwerk) versucht nicht nur vorherzusagen, welche Aktionen in einer bestimmten Situation am besten ausgeführt werden, sondern auch vorherzusagen, was nach den ergriffenen Aktionen mit der Welt geschehen wird. Und er verwendet diese Vorhersage der Welt für den nächsten Schritt, damit er und der aktuelle Schritt seine früher ergriffenen Maßnahmen vorhersagen können (ja, es ist schwierig, Sie können es nicht ohne ein Pint herausfinden).
Dies führt zu einem merkwürdigen Effekt: Der Agent wird nur neugierig auf das, was er mit seinen Handlungen beeinflussen kann. Er kann die schwingenden Äste eines Baumes nicht beeinflussen, so dass sie für ihn uninteressant werden. Aber er kann durch das Viertel laufen, also ist er neugierig darauf, die Welt zu erkunden.
Wenn der Agent jedoch eine TV-Fernbedienung hat, die zufällige Kanäle umschaltet, kann er dies beeinflussen! Und er wird neugierig sein, ad infinitum auf die Kanäle zu klicken (da er nicht vorhersagen kann, was der nächste Kanal sein wird, weil er zufällig ist). Ein Versuch, dieses Problem zu umgehen, wurde von Google in der Arbeit von Episodic Curiosity through Reachability unternommen.
Das vielleicht beste Ergebnis auf dem neuesten Stand der Technik ist jedoch die Neugierde. OpenAI besitzt derzeit die Idee der Random Network Distillation (RND) . Das Wesentliche ist, dass ein zweites, vollständig zufällig initialisiertes Netzwerk benötigt wird und der aktuelle Status ihm zugeführt wird. Und unser hauptsächlich funktionierendes neuronales Netzwerk versucht, die Ausgabe dieses neuronalen Netzwerks zu erraten. Das zweite Netzwerk ist nicht trainiert, es bleibt während der Initialisierung immer fest.
Was ist der Punkt? Der Punkt ist, dass, wenn ein Staat bereits von unserem Arbeitsnetzwerk besucht und untersucht wurde, er die Ausgabe dieses zweiten Netzwerks mehr oder weniger erfolgreich vorhersagen kann. Und wenn dies ein neuer Zustand ist, in dem wir noch nie waren, kann unser neuronales Netzwerk die Ausgabe dieses RND-Netzwerks nicht vorhersagen. Dieser Fehler bei der Vorhersage der Ausgabe dieses zufällig initialisierten Netzwerks wird als Indikator für die Neugier verwendet (er bietet hohe Belohnungen, wenn wir seine Ausgabe in dieser Situation nicht vorhersagen können).
Warum dies funktioniert, ist nicht ganz klar. Sie schreiben jedoch, dass dies das Problem beseitigt, wenn das Vorhersageziel stochastisch ist und wenn nicht genügend Daten vorhanden sind, um eine Vorhersage darüber zu treffen, was als nächstes passieren wird (was bei gewöhnlichen Neugieralgorithmen einen großen Vorhersagefehler ergibt). Auf die eine oder andere Weise, aber RND zeigte wirklich hervorragende Forschungsergebnisse, die auf Neugierde in Spielen beruhten. Und bewältigt das Problem des Zufallsfernsehens.
Mit RND hat die Neugier in OpenAI zum ersten Mal ehrlich (und nicht durch eine vorläufige Zufallssuche wie in Uber) die erste Stufe von Montezumas Rache überschritten. Nicht jedes Mal und unzuverlässig, aber von Zeit zu Zeit stellt sich heraus.

Was ist das Ergebnis?
Wie Sie sehen, hat das Reinforcement Learning in nur wenigen Jahren einen langen Weg zurückgelegt. Nicht nur einige erfolgreiche Lösungen, wie in Faltungsnetzwerken, in denen Resudal- und Skip-Verbindungen es ermöglichten, Netzwerke mit einer Tiefe von Hunderten von Schichten zu trainieren, anstatt ein Dutzend Schichten mit Relu-Aktivierungsfunktion allein, die das Problem des Verschwindens von Gradienten in Sigmoid und Tanh überwanden. Beim Lernen mit Verstärkung wurden Fortschritte bei den Konzepten und beim Verständnis der Gründe erzielt, warum diese oder jene naive Version der Implementierung nicht funktioniert hat. Das Schlüsselwort "hat nicht funktioniert."
Aus technischer Sicht beruht jedoch immer noch alles auf den Vorhersagen aller gleichen Q-, V- oder A-Werte. Es gibt keine Zeitabhängigkeiten auf verschiedenen Ebenen, wie im Gehirn (Hierarchisches Reinforcement Learning zählt nicht, die Hierarchie ist darin zu primitiv im Vergleich zur Assoziativität im lebenden Gehirn). Keine Versuche, eine Netzwerkarchitektur zu entwickeln, die speziell auf das verstärkte Lernen zugeschnitten ist, wie dies bei LSTM und anderen wiederkehrenden Netzwerken für Zeitsequenzen der Fall war. Verstärkung Das Lernen stampft entweder auf der Stelle, freut sich über kleine Erfolge oder bewegt sich in eine völlig falsche Richtung.
Ich würde gerne glauben, dass es in der Architektur neuronaler Netze einen Durchbruch in der Architektur neuronaler Netze geben wird, ähnlich wie in Faltungsnetzen. Und wir werden sehen, wie das Lernen zur Stärkung wirklich funktioniert. Lernen an isolierten Beispielen mit assoziativem Gedächtnis und Arbeiten auf verschiedenen Zeitskalen.