Die heutige R-Sprache ist eines der leistungsstärksten und multifunktionalsten Werkzeuge für die Arbeit mit Daten. Wie wir jedoch fast immer wissen, befindet sich in jedem Fass Honig eine Fliege in der Salbe. Tatsache ist, dass R standardmäßig Single-Threaded ist.
Dies wird Sie höchstwahrscheinlich nicht lange genug stören, und es ist unwahrscheinlich, dass Sie diese Frage stellen. Wenn Sie beispielsweise vor der Aufgabe stehen, Daten von einer großen Anzahl von Werbekonten über die API zu erfassen, z. B. Yandex.Direct, können Sie die Zeit für die Datenerfassung mithilfe von Multithreading mindestens zwei- bis dreimal erheblich verkürzen.

Das Thema Multithreading in R ist nicht neu und wurde hier , hier und hier wiederholt auf Habré angesprochen, aber die letzte Veröffentlichung stammt aus dem Jahr 2013, und wie man sagt, ist alles Neue gut vergessen, alt. Darüber hinaus wurde zuvor Multithreading für die Berechnung von Modellen und das Training neuronaler Netze erörtert, und wir werden über die Verwendung von Asynchronität für die Arbeit mit der API sprechen. Trotzdem möchte ich diese Gelegenheit nutzen, um den Autoren dieser Artikel zu danken, weil Sie haben mir sehr geholfen, diesen Artikel mit ihren Veröffentlichungen zu schreiben.
Inhalt
Der zweite Teil des Artikels, der sich mit moderneren Optionen zur Implementierung von Multithreading in R befasst, ist hier verfügbar.
Was ist Multithreading?
One-Threading (sequentielle Berechnungen) - Ein Berechnungsmodus, in dem alle Aktionen (Aufgaben) nacheinander ausgeführt werden. In diesem Fall entspricht die Gesamtdauer aller angegebenen Operationen der Summe der Dauer aller Operationen.
Multithreading (paralleles Rechnen) - ein Rechenmodus, in dem die angegebenen Aktionen (Aufgaben) parallel ausgeführt werden, d. H. Gleichzeitig entspricht die Gesamtausführungszeit aller Operationen nicht der Summe der Dauer aller Operationen.
Schauen wir uns zur Vereinfachung der Wahrnehmung die folgende Tabelle an:
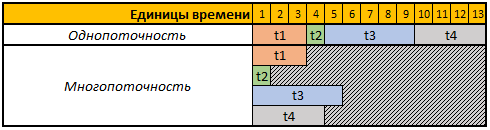
Die erste Zeile der angegebenen Tabelle enthält bedingte Zeiteinheiten. In diesem Fall spielt es für uns keine Rolle, Sekunden, Minuten oder andere Zeiträume.
In diesem Beispiel müssen 4 Operationen ausgeführt werden. Jede Operation hat in diesem Fall eine andere Berechnungsdauer. Im Single-Thread-Modus werden alle 4 Operationen nacheinander ausgeführt. Daher beträgt die Gesamtzeit für ihre Ausführung t1 + t2 + t3 + t4, 3 + 1 + 5 + 4 = 13.
Im Multithread-Modus werden alle 4 Aufgaben parallel ausgeführt, d. H. Um die nächste Aufgabe zu starten, müssen Sie nicht warten, bis die vorherige abgeschlossen ist. Wenn wir also unsere Aufgabe in 4 Threads starten, entspricht die Gesamtberechnungszeit der Berechnungszeit der größten Aufgabe. In unserem Fall ist es Aufgabe t3, deren Berechnungsdauer in unserem Beispiel 5 beträgt temporäre Einheiten und die Ausführungszeit aller 4 Operationen in diesem Fall entsprechen 5 temporären Einheiten.
Welche Pakete werden wir verwenden
Für Berechnungen im Multithread-Modus verwenden wir die doParallel foreach , doSNOW und doParallel .
Mit dem foreach Paket können Sie das foreach Konstrukt verwenden, das im Wesentlichen eine erweiterte for-Schleife ist.
Die doParallel doSNOW und doParallel sind im Wesentlichen Zwillingsbrüder, mit denen Sie virtuelle Cluster erstellen und für parallele Berechnungen verwenden können.
Am Ende des Artikels messen und vergleichen wir mithilfe des rbenchmark Pakets die Dauer der Datenerfassungsvorgänge über die Yandex.Direct-API mit allen unten beschriebenen Methoden.
Um mit der Yandex.Direct-API zu arbeiten, verwenden wir das ryandexdirect-Paket. In diesem Artikel wird es als Beispiel verwendet. Weitere Details zu seinen Funktionen und Funktionen finden Sie in der offiziellen Dokumentation .
Code zur Installation aller erforderlichen Pakete:
install.packages("foreach") install.packages("doSNOW") install.packages("doParallel") install.packages("rbenchmark") install.packages("ryandexdirect")
Herausforderung
Sie müssen einen Code schreiben, der eine Liste von Keywords von einer beliebigen Anzahl von Yandex.Direct-Werbekonten anfordert. Das Ergebnis muss in einem Datumsrahmen erfasst werden, in dem ein zusätzliches Feld mit dem Login des Werbekontos angezeigt wird, zu dem das Keyword gehört.
Darüber hinaus besteht unsere Aufgabe darin, einen Code zu schreiben, der diesen Vorgang so schnell wie möglich auf einer beliebigen Anzahl von Werbekonten ausführt.
Autorisierung in Yandex.Direct
Um mit der API der Yandex.Direct-Werbeplattform arbeiten zu können, muss zunächst für jedes Konto, von dem wir eine Liste mit Keywords anfordern möchten, eine Autorisierung durchgeführt werden.
Der gesamte in diesem Artikel angegebene Code spiegelt ein Beispiel für die Arbeit mit regulären Yandex.Direct-Werbekonten wider. Wenn Sie unter einem Agentenkonto arbeiten, müssen Sie das Argument AgencyAccount verwenden und die Anmeldung für das Agentenkonto an dieses Konto übergeben. Weitere Informationen zum Arbeiten mit Agentenkonten von Yandex.Direct mit dem Paket ryandexdirect finden Sie hier .
Für die Autorisierung muss die Funktion yadirAuth aus dem Paket yadirAuth ausgeführt werden. yadirAuth den yadirAuth Code zu wiederholen, ist für jedes Konto erforderlich, von dem Sie eine Liste der Schlüsselwörter und ihrer Parameter anfordern.
ryandexdirect::yadirAuth(Login = " ")
Der Autorisierungsprozess in Yandex.Direct über das Paket ryandexdirect absolut sicher, obwohl er über eine Website eines Drittanbieters geleitet wird. Ich habe bereits im Artikel "Wie sicher es ist, R-Pakete für die Arbeit mit der Advertising Systems API zu verwenden" ausführlich über die Sicherheit seiner Verwendung gesprochen.
Nach der Autorisierung wird unter jedem Konto in Ihrem Arbeitsverzeichnis eine Datei login.yadirAuth.RData erstellt, in der die Anmeldeinformationen für jedes Konto gespeichert werden. Der Dateiname beginnt mit der im Login- Argument angegebenen Anmeldung. Wenn Sie die Dateien nicht im aktuellen Arbeitsverzeichnis, sondern in einem anderen Ordner speichern müssen , verwenden Sie das TokenPath- Argument. In diesem Fall müssen Sie beim Anfordern von Schlüsselwörtern mithilfe der Funktion yadirGetKeyWords auch das TokenPath- Argument verwenden und den Pfad zu dem Ordner angeben, in dem Sie die Dateien gespeichert haben mit Anmeldeinformationen.
Sequentielle Lösung mit einem Thread und for-Schleife
Der einfachste Weg, Daten von mehreren Konten gleichzeitig zu erfassen, ist die Verwendung der for Schleife. Einfach, aber nicht die effektivste, weil Eines der Entwicklungsprinzipien in der R-Sprache besteht darin, die Verwendung von Schleifen im Code zu vermeiden.
Unten finden Sie einen Beispielcode zum Sammeln von Daten von 4 Konten mithilfe der for-Schleife. In diesem Beispiel können Sie Daten von einer beliebigen Anzahl von Werbekonten erfassen.
Code 1: Wir verarbeiten 4 Konten mit der üblichen for-Schleife library(ryandexdirect) # logins <- c("login_1", "login_2", "login_3", "login_4") # res1 <- data.frame() # for (login in logins) { temp <- yadirGetKeyWords(Login = login) temp$login <- login res1 <- rbind(res1, temp) }
Das Messen der Laufzeit mit der Funktion system.time ergab folgendes Ergebnis:
Arbeitszeit:
Benutzer: 178.83
System: 0,63
bestanden: 320,39
Das Sammeln von Schlüsselwörtern für 4 Konten dauerte 320 Sekunden. Aus den Informationsmeldungen, die yadirGetKeyWords Funktion yadirGetKeyWords während des Betriebs anzeigt, wird das größte Konto yadirGetKeyWords , von dem 5970 Schlüsselwörter empfangen wurden und 142 Sekunden verarbeitet wurden.
Multithreading-Lösung in R.
Ich habe bereits oben geschrieben, dass wir für Multithreading die doParallel doSNOW und doParallel .
Ich möchte darauf aufmerksam machen, dass fast jede API ihre eigenen Einschränkungen hat und die Yandex.Direct-API keine Ausnahme darstellt. In der Hilfe zur Arbeit mit der Yandex.Direct-API heißt es:
Es sind nicht mehr als fünf gleichzeitige API-Anforderungen für einen Benutzer zulässig.
Trotz der Tatsache, dass wir in diesem Fall ein Beispiel für die Erstellung von 4 Streams betrachten, können Sie bei der Arbeit mit Yandex.Direct 5 Streams erstellen, selbst wenn Sie alle Anforderungen unter demselben Benutzer senden. Es ist jedoch am rationalsten, 1 Thread pro 1 Kern Ihres Prozessors zu verwenden. Sie können die Anzahl der physischen Prozessorkerne mit dem Befehl parallel::detectCores(logical = FALSE) Die Anzahl der logischen Kerne kann mit parallel::detectCores(logical = TRUE) . Ein detaillierteres Verständnis darüber, was ein solcher physischer und logischer Kern bei Wikipedia möglich ist.
Zusätzlich zur Begrenzung der Anzahl der Anforderungen gibt es eine tägliche Begrenzung der Anzahl der Punkte für den Zugriff auf die Yandex.Direct-API. Diese kann für alle Konten unterschiedlich sein. Jede Anforderung verbraucht je nach ausgeführter Operation auch eine andere Anzahl von Punkten. Wenn Sie beispielsweise eine Liste mit Schlüsselwörtern abfragen, erhalten Sie 15 Punkte für eine abgeschlossene Abfrage und 3 Punkte für jeweils 2000 Wörter. Sie können herausfinden, wie Punkte im offiziellen Zertifikat abgeschrieben werden. Sie können auch Informationen über die Anzahl der erzielten und verfügbaren Punkte sowie deren tägliches Limit in Informationsnachrichten yadirGetKeyWords , die von der Funktion yadirGetKeyWords an die Konsole yadirGetKeyWords werden.
Number of API points spent when executing the request: 60 Available balance of daily limit API points: 993530 Daily limit of API points:996000
Lassen Sie uns der Reihe nach mit doSNOW und doParallel .
DoSNOW-Paket und Multithread-Funktionen
Wir schreiben dieselbe Operation für den Multi-Thread-Berechnungsmodus neu, erstellen in diesem Fall 4 Threads und verwenden anstelle der for Schleife das foreach Konstrukt.
Code 2: Paralleles Rechnen mit doSNOW library(foreach) library(doSNOW) # logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoSNOW(cl) res2 <- foreach(login = logins, # - .combine = 'rbind', # .packages = "ryandexdirect", # .inorder=F ) %dopar% {cbind(yadirGetKeyWords(Login = login), login) } stopCluster(cl)
In diesem Fall ergab die Messung der Laufzeit mit der Funktion system.time das folgende Ergebnis:
Arbeitszeit:
Benutzer: 0.17
System: 0,08
bestanden: 151,47
Das gleiche Ergebnis, d.h. Wir haben die Sammlung von Schlüsselwörtern von 4 Yandex.Direct-Konten in 151 Sekunden erhalten, d. h. 2 mal schneller. Außerdem habe ich gerade im letzten Beispiel geschrieben, wie lange es gedauert hat, eine Liste von Keywords aus dem größten Konto zu laden (142 Sekunden), d. H. In diesem Beispiel ist die Gesamtzeit fast identisch mit der Verarbeitungszeit des größten Kontos. Tatsache ist, dass wir mit Hilfe der foreach Funktion gleichzeitig den Prozess des Sammelns von Daten in 4 Threads gestartet haben, d. H. Gleichzeitig werden Daten von allen 4 Konten gesammelt. Die Gesamtzeit entspricht der Verarbeitungszeit des größten Kontos.
Ich werde Code 2 kurz makeCluster Funktion makeCluster für die Anzahl der Threads verantwortlich. In diesem Fall haben wir einen Cluster mit 4 Prozessorkernen erstellt. Wie ich bereits bei der Arbeit mit der Yandex.Direct-API geschrieben habe, können Sie unabhängig von der Anzahl der Konten 5 Threads erstellen Wenn Sie 5-15-100 oder mehr verarbeiten müssen, können Sie 5 Anforderungen gleichzeitig an die API senden.
Als nächstes startet die Funktion registerDoSNOW den erstellten Cluster.
Danach verwenden wir das foreach Konstrukt, wie ich bereits sagte, dieses Konstrukt ist eine verbesserte for-Schleife. Sie geben den Zähler als erstes Argument an. In dem Beispiel, das ich login genannt habe, wird bei jeder Iteration über die Elemente des Anmeldevektors iteriert. Wenn wir for ( login in logins) schreiben, erhalten wir dasselbe Ergebnis in der for Schleife.
Als Nächstes müssen Sie im Argument .combine die Funktion angeben, mit der Sie die bei jeder Iteration erzielten Ergebnisse kombinieren. Die häufigsten Optionen sind:
rbind - Verbinde die resultierenden Tabellen Zeile für Zeile untereinander.cbind - Verbinde die resultierenden Tabellen in Spalten."+" - fasst das bei jeder Iteration erhaltene Ergebnis zusammen.
Sie können auch jede andere Funktion verwenden, auch selbst geschrieben.
Mit dem Argument .inorder = F können Sie die Arbeit der Funktion etwas beschleunigen, wenn es Ihnen egal ist, in welcher Reihenfolge die Ergebnisse kombiniert werden sollen. In diesem Fall ist die Reihenfolge für uns nicht wichtig.
Als nächstes kommt der %dopar% -Operator, der die Schleife im parallelen Rechenmodus startet. Wenn Sie den %do% -Operator verwenden, werden die Iterationen nacheinander ausgeführt, ebenso wie bei Verwendung der üblichen for Schleife.
Die stopCluster Funktion stoppt den Cluster.
Multithreading, oder besser gesagt das foreach Konstrukt im Multithread-Modus, weist einige Funktionen auf. In diesem Fall starten wir jeden parallelen Prozess in einer neuen, sauberen R-Sitzung. Um die generischen Funktionen und Objekte darin zu verwenden, die außerhalb des foreach Konstrukts definiert wurden, müssen Sie sie daher mit dem Argument .export exportieren . Dieses Argument verwendet einen Textvektor, der die Namen der Objekte enthält, die Sie in foreach .
Außerdem werden in foreach im parallelen Modus die zuvor verbundenen Pakete standardmäßig nicht angezeigt, sodass sie auch mit dem Argument .packages in foreach übergeben werden müssen . Es ist auch erforderlich, Pakete zu übertragen, indem ihre Namen in einem .packages = c("ryandexdirect", "dplyr", "lubridate") , z. B. .packages = c("ryandexdirect", "dplyr", "lubridate") . Im obigen Codebeispiel 2 laden wir auf diese Weise das ryandexdirect- Paket bei jeder Iteration von foreach .
DoParallel-Paket
Wie ich oben geschrieben habe, sind die doParallel doSNOW und doParallel Zwillinge, daher haben sie dieselbe Syntax.
Code 5: Paralleles Rechnen mit doParallel library(foreach) library(doParallel) logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoParallel(cl) res3 <- data.frame() res3 <- foreach(login=logins, .combine= 'rbind', .inorder=F) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) stopCluster(cl)
Arbeitszeit:
Benutzer: 0,25
System: 0,01
bestanden: 173,28
Wie Sie in diesem Fall sehen können, unterscheidet sich die Ausführungszeit geringfügig vom vorherigen Beispiel für parallelen Computercode mit dem Paket doSNOW .
Geschwindigkeitstest zwischen den drei untersuchten Ansätzen
Führen Sie nun den Geschwindigkeitstest mit dem Paket rbenchmark .
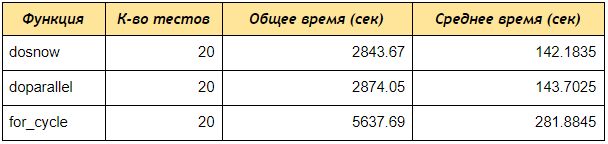
Wie Sie sehen können, haben die doParallel doSNOW und doParallel selbst bei einem Test mit 4 Konten Daten mit Schlüsselwörtern zweimal schneller empfangen als die sequentielle for-Schleife. Wenn Sie einen Cluster mit 5 Kernen erstellen und 50 oder 100 Konten verarbeiten, ist der Unterschied sogar noch größer.
Code 6: Skript zum Vergleichen der Geschwindigkeit von Multithreading und sequentiellem Computing # library(ryandexdirect) library(foreach) library(doParallel) library(doSNOW) library(rbenchmark) # for for_fun <- function(logins) { res1 <- data.frame() for (login in logins) { temp <- yadirGetKeyWords(Login = login) res1 <- rbind(res1, temp) } return(res1) } # foreach doSNOW dosnow_fun <- function(logins) { cl <- makeCluster(4) registerDoSNOW(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login } }) stopCluster(cl) return(res2) } # foreach doParallel dopar_fun <- function(logins) { cl <- makeCluster(4) registerDoParallel(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login) } }) stopCluster(cl) return(res2) } # within(benchmark(for_cycle = for_fun(logins = logins), dosnow = dosnow_fun(logins = logins), doparallel = dopar_fun(logins = logins), replications = c(20), columns=c('test', 'replications', 'elapsed'), order=c('elapsed', 'test')), { average = elapsed/replications })
Abschließend werde ich den obigen Code 5 erläutern, mit dem wir die Arbeitsgeschwindigkeit getestet haben.
Zunächst haben wir drei Funktionen erstellt:
for_fun - eine Funktion, die Schlüsselwörter von mehreren Konten anfordert und diese nacheinander in einem regulären Zyklus sortiert.
dosnow_fun - eine Funktion, die mithilfe des doSNOW Pakets eine Liste von Schlüsselwörtern im Multithread-Modus doSNOW .
dopar_fun - eine Funktion, die im Multithread-Modus mithilfe des doParallel Pakets eine Liste von Schlüsselwörtern doParallel .
Als nächstes führen wir innerhalb des Konstrukts inside die benchmark Funktion aus dem rbenchmark Paket aus, geben die Namen der Tests (for_cycle, dosnow, doparallel) und für jede Funktion die Funktionen an: for_fun(logins = logins) ; dosnow_fun(logins = logins) ; dopar_fun(logins = logins) .
Das Replikationsargument ist für die Anzahl der Tests verantwortlich, d.h. Wie oft werden wir jede Funktion ausführen?
Mit dem Spaltenargument können Sie angeben, welche Spalten Sie erhalten möchten. In unserem Fall bedeutet "Test", "Replikationen", "verstrichen", dass die Spalten zurückgegeben werden: Name des Tests, Anzahl der Tests, Gesamtausführungszeit aller Tests.
Sie können auch berechnete Spalten hinzufügen ( { average = elapsed/replications } ), d. H. Die Ausgabe ist eine durchschnittliche Spalte, die die Gesamtzeit durch die Anzahl der Tests dividiert. Daher berechnen wir die durchschnittliche Ausführungszeit jeder Funktion.
Die Bestellung ist für die Sortierung der Testergebnisse verantwortlich.
Fazit
In diesem Artikel wird im Prinzip eine ziemlich universelle Methode zur Beschleunigung der Arbeit mit der API beschrieben, aber jede API hat ihre Grenzen. Daher ist das obige Beispiel speziell in dieser Form bei so vielen Threads für die Arbeit mit der Yandex.Direct-API geeignet, um sie mit der API zu verwenden Bei anderen Diensten ist es zunächst erforderlich, die Dokumentation zu den Grenzwerten in der API für die Anzahl der gleichzeitig gesendeten Anforderungen zu lesen. Andernfalls wird möglicherweise der Fehler " Too Many Requests angezeigt.
Die Fortsetzung dieses Artikels finden Sie hier .