
Maschinelles Lernen wird in vielen Bereichen unseres Lebens aktiv eingesetzt. Algorithmen helfen dabei, Verkehrszeichen zu erkennen, Spam zu filtern, die Gesichter unserer Freunde auf Facebook zu erkennen und sogar an Börsen zu handeln. Der Algorithmus trifft wichtige Entscheidungen, daher müssen Sie sicher sein, dass er nicht getäuscht werden kann.
In diesem Artikel, der der erste einer Reihe ist, werden wir Ihnen das Problem der Sicherheit von Algorithmen für maschinelles Lernen vorstellen. Dies erfordert kein hohes Maß an Wissen über maschinelles Lernen vom Leser, es reicht aus, eine allgemeine Vorstellung von diesem Bereich zu haben.
Zunächst geben wir die Begriffe an, die im Thema Sicherheit von Algorithmen für maschinelles Lernen verwendet werden:
Ein gegnerisches Beispiel ist ein Vektor, der eine Eingabe an einen Algorithmus weiterleitet, bei dem der Algorithmus eine falsche Ausgabe erzeugt.
Adversarial Attack - Ein Aktionsalgorithmus, dessen Zweck es ist, ein Adversarial-Beispiel zu erhalten.
Um das Problem der konträren Beispiele zu verstehen, erinnern wir uns an eine der Aufgaben des maschinellen Lernens - das Lernen mit einem Lehrer in der Benotung. In diesem Problem haben wir "Objekt-Beschriftungs" -Paare, und wir müssen lernen, den Wert für neue Objekte vorherzusagen.
Wenn wir dieses Problem aus geometrischer Sicht betrachten, ist es notwendig, den Raum so zu teilen, dass die „richtige“ Klasse für das neue Objekt vorhergesagt wird. Wenn wir einen allgemeinen Datensatz hätten (zum Beispiel für einen Satz handgeschriebener Ziffern MNIST, um alle Arten von Bildern aller Ziffern zu haben), könnte diese Hyperebene idealerweise ausgeführt werden, vorausgesetzt, die Klassen sind trennbar. Da die allgemeine Bevölkerung jedoch meistens nicht existiert, verwenden wir zur Lösung dieses Problems Algorithmen für maschinelles Lernen, um die „ideale“ Hyperebene unter Verwendung der uns vorliegenden Daten so genau wie möglich zu approximieren.
Jede Abweichung der Hyperebene von der idealen führt zu einer bestimmten „Lücke“, in die Objekte falsch klassifiziert werden. Deshalb erscheinen Beispiele wie der als Gibbon klassifizierte Panda. Die Aufgabe des Angreifers besteht darin, den Vektor der Objektparameter so zu ändern, dass er in diese „Lücke“ fällt.
Beispiele für gegnerische Angriffe
Es gibt ein neuronales Netzwerk, das das Gesicht auf einem Foto erkennt. Sie hat die Aufgabe erfolgreich gemeistert (Bild links). Nachdem Sie diesem Foto ein wenig Rauschen hinzugefügt haben (Bild rechts), erkennt der Algorithmus des erhaltenen gegnerischen Beispiels (Bild in der Mitte) das Gesicht im Bild nicht mehr.

Dieses Beispiel, das im Artikel „ Widersprüchliche Angriffe auf Gesichtsdetektoren mithilfe der auf neuronalen Netzen basierenden eingeschränkten Optimierung “ demonstriert wird, ist interessant, da viele reale Gesichtserkennungssysteme neuronale Netzwerkansätze zur Erkennung von Gesichtern verwenden. Eine Person wird den Unterschied beim Betrachten beider Bilder nicht bemerken.
Das folgende Beispiel stammt aus der Automobilindustrie, nämlich die Verkehrszeichenerkennung. Dieses Beispiel ist insofern interessant, als das gegnerische Beispiel kein Objekt sein muss, das den Objekten, auf denen das Netzwerk trainiert wurde, zumindest etwas nahe kommt. In Rogue Signs: Täuschung der Verkehrszeichenerkennung mit böswilligen Anzeigen und Logos wurde beispielsweise gezeigt, dass das gegnerische Beispiel des KFC-Zeichens vom ursprünglichen neuronalen Netzwerk mit einer Wahrscheinlichkeit von 100% als STOP-Zeichen „erkannt“ wird.
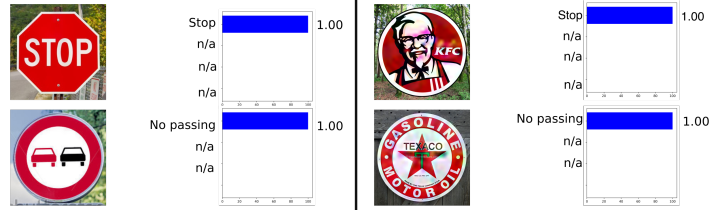
Viele könnten die Verwendung von gegnerischen Beispielen in der realen Welt bezweifeln, da die vorherigen Beispiele auf einem Computer getestet wurden, während es im realen Leben kaum möglich ist, ein solches Objekt zu erhalten. Aber das ist nicht so. Die Synthese robuster gegnerischer Beispiele hat gezeigt, dass ein auf einem Computer erstelltes gegnerisches Beispiel erfolgreich auf einem 3D-Drucker gedruckt werden kann und der Algorithmus dieselben Fehler wie bei einer Computersimulation macht.

Hier sehen Sie eine Schildkröte, die auf einem 3D-Drucker gedruckt wurde und in keinem Winkel als Schildkröte erkannt wurde.
Das folgende Beispiel zeigt, was getan werden kann, wenn wir über das übliche Verständnis von gegnerischen Angriffen hinausgehen. Programmieren Sie das Quellnetzwerk neu, um seine eigene Nutzlast zu verwenden. Mit anderen Worten, wir lernen, das neuronale Netzwerk eines anderen zu verwenden, um das vom Angreifer aufgeworfene Problem zu lösen. Zum Beispiel hat die Adversrial Reprogramming of Neural Network gezeigt, wie ein auf ImageNet trainiertes Netzwerk die Anzahl der Quadrate in einem Bild perfekt berechnet und die Zahlen aus dem MNIST-Satz erkannt hat.
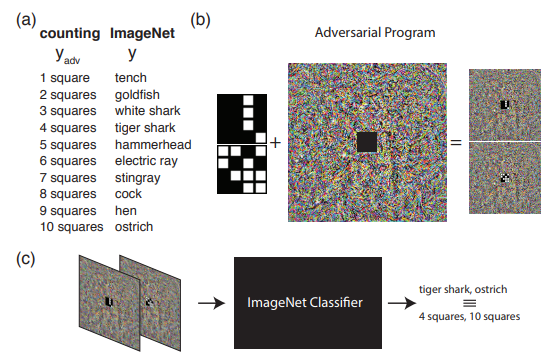
Das Bild zeigt den Algorithmus für die Arbeit mit der kontradiktorischen Neuprogrammierung, der empfohlen wird, um ihn im Originalartikel besser kennenzulernen.
In diesem Artikel möchte ich speziell darauf eingehen, wie kontradiktorische Beispiele generiert werden, und im zweiten Artikel werden wir uns mit Methoden zum Schutz und Testen von Algorithmen für maschinelles Lernen befassen.
Angriffsklassifikation
Alle Angriffe können in zwei Klassen unterteilt werden: WhiteBox (WB) und BlackBox (BB) . Im Fall von WB kennen wir alle Informationen über das trainierte Modell des Algorithmus, während wir im Fall von BB nur Zugriff auf die Eingabe und Ausgabe des Modells haben. Tatsächlich ist die GrayBox-Option immer noch möglich, wenn wir die Informationen über das trainierte Modell nicht kennen, aber Informationen über die Art des Algorithmus und seine Hyperparameter vorliegen. Dieser Typ fällt jedoch in einer separaten Klasse nicht auf, da zusätzliche Informationen nicht ausreichen, um zu WB zu gelangen. Dies bedeutet, dass dies nur ein zusätzlicher Satz von Informationen für die Durchführung eines BB-Angriffs ist.
Als nächstes lohnt es sich, Angriffe auf gezielte und nicht zielgerichtete Angriffe zu klassifizieren. Gezielte Angriffe bedeuten, dass der Angriff in eine bestimmte Richtung ausgeführt wird. Im MNIST-Datensatz trainieren wir beispielsweise das neuronale Netzwerk und nehmen Bild 0 aus dem Testsatz. Ein trainiertes neuronales Netzwerk erzeugt in diesem Objekt eine Wahrscheinlichkeit der Klasse 0 von 1,00. Wenn das gegnerische Beispiel nach Anwendung des gegnerischen Angriffs als Klasse 1 erkannt werden soll, verwenden wir den gezielten Angriff. Andernfalls ist ein solcher Angriff nicht zielgerichtet, wenn es für uns nicht besonders wichtig ist, für welche Klasse das neuronale Netzwerk das Bild empfängt (Hauptsache, es ist nicht mehr Klasse 0).
Außerdem werden Angriffe in eine Metrik unterteilt, nach der 2 Objekte als ähnlich betrachtet werden - Normen. Norm - die Anzahl der geänderten Parameter. Euklidischer Abstand zwischen zwei Vektoren. maximale elementweise Differenz zwischen zwei Vektoren.
Python-Bibliotheken
Mit Python-Datenbibliotheken können Sie mit gegnerischen Beispielen arbeiten. Dies sind FoolBox, CleverHans und ART-IBM.
| Foolbox | Cleverhans | ART-IBM |
|---|
| Unterstützte Frameworks | TensorFlow, Keras, Theano, PyTorch, Lasagne, MXNet | TensorFlow, Keras | TensorFlow, Keras, versprechen MXNet, PyTorch |
Schauen wir uns nun die Angriffe etwas genauer an und beginnen wir mit WhiteBox-Angriffen.
L-BFGS-Angriff
Die Anweisung der L-BFGS-Methode kann wie folgt geschrieben werden.
Daraus folgt, dass wir die Verlustfunktion in Richtung der Zielklasse mit der Einschränkung minimieren wollen, dass die eingeführten Änderungen minimal waren. Gleichzeitig wurde vorgeschlagen, ein solches Problem im Originalartikel mit der L-BFGS-Methode zu lösen, daher der Name dieses Angriffs.
Originalartikel - Faszinierende Eigenschaften neuronaler Netze
Dieser Angriff wird in 2 von 3 zuvor stimmhaften Bibliotheken präsentiert - FoolBox und CleverHans.
Die Anwendung dieses Angriffs auf FoolBox erfordert in Python drei Codezeilen:
from foolbox.attacks import LBFGSAttack attack = LBFGSAttack(fmodel) adversarial = attack(image, label)
Die Verwendung von L-BFGS hilft Ihnen dabei, die besten gegnerischen Beispiele basierend auf Ihren Einschränkungen zu finden. Erstens kann die Suche nach einem solchen Beispiel lange dauern, und zweitens ist es durchaus möglich, dass die Methode einfach nicht konvergiert.
FGSM-Angriff
Die nächste Entwicklungsstufe war die FGSM (Fast Sign Gradient Method), die mit folgender Formel dargestellt werden kann:
Diese Methode arbeitet viel schneller als L-BFGS. Hier nehmen wir einfach die Vorzeichen aus der Gradientenfunktion der ursprünglichen Verlustfunktion und multiplizieren das Vorzeichen mit einigen , zum Originalbild hinzufügen.

Hier ist ein Beispiel, wie diese Methode funktioniert. Eine Lärmkarte mit gleich 0,007, und es stellt sich heraus, dass das Foto des Pandas jetzt mit einer Wahrscheinlichkeit von 99,3% als Gibbon erkannt wird
Diese Methode ist einfach zu implementieren, aber gleichzeitig ist das Ergebnis dieser Methode sehr verrauscht.
Originalartikel - Erklären und Nutzen widersprüchlicher Beispiele
Sie finden die Implementierung dieser Methode in Bibliotheken, und die Verwendung von Foolbox wird auch nicht viel Zeit in Anspruch nehmen.
from foolbox.attacks import FGSM attack = FGSM(fmodel) adversarial = attack(image, label)
Deepfool-Angriff
DeepFool ist eine nicht zielgerichtete Methode. Der Hauptunterschied zu den vorherigen Methoden besteht darin, dass versucht wird, eine minimale Rauschkarte zu erstellen, die den Algorithmus täuscht. Mit dieser Methode können Sie nicht aus einer Klasse eine bestimmte Klasse machen, sondern aus einer anderen, die dem Originalbild am nächsten kommt.

Ein Beispiel zeigt das Originalbild in der unteren Zeile - der FGSM-Methode - und in der Mitte nur einen DeepFool-Angriff. Es ist ersichtlich, dass die Rauschkarte viel kleiner ist als bei FGSM.
Originalartikel - DeepFool: Eine einfache und genaue Methode, um tiefe neuronale Netze zu täuschen
Ein solcher Angriff kann mit jeder der aufgelisteten Bibliotheken ausgeführt werden, und die Implementierung auf ART-IBM erfordert nur drei Codezeilen:
from art.attacks import DeepFool attack = DeepFool(model) img_adv = attack.generate(img)
Jacobian Saliency Map Angriff
Bei der JSMA-Methode wird eine direkte Ableitung berücksichtigt, auf deren Grundlage eine Gradientenkarte erstellt wird. Auf der Karte entspricht jeder Parameter des Objekts tatsächlich dem Beitrag dieses Parameters zur Änderung des Endergebnisses des Algorithmus. Auf diese Weise können Sie mit der Methode so wenige Parameter wie möglich im angegriffenen Objekt ändern. Und dementsprechend funktioniert es weiter normal.
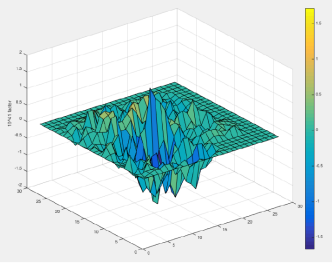
Originalartikel - Die Grenzen des tiefen Lernens in kontroversen Umgebungen
Dieser Angriff kann mit CleverHans oder ART-IBM ausgeführt werden. Und bei CleverHans sieht es so aus:
from cleverhans.attacks import SaliencyMapMethod jsma = SaliencyMapMethod(model, sees=sees) jsma_params = { 'theta' : 1., 'gamma' : 0.1, 'clip_min' : 0., 'clip_max' : 1., 'y_target' : None} adv_x = jsma.generate_np(img, **jsma_params)
Ein Pixel-Angriff
Die logische Frage ist, wie viele Pixel mindestens geändert werden müssen, um einen Angriff auf den Algorithmus auszuführen. Wie viele bereits anhand des Angriffsnamens erraten haben, reicht 1 Pixel aus.

Beispielsweise wird das Bild eines Pferdes mit nur einem Pixel geändert zu einem Frosch mit einer Wahrscheinlichkeit von 99,9%
Originalartikel - Ein-Pixel-Angriff zum Täuschen tiefer neuronaler Netze
Dieser Angriff wird nur in FoolBox unterstützt und wie folgt implementiert:
from foolbox.attacks import SinglePixelAttack attack = SinglePixelAttack(fmodel) adversarial = attack(image,max_pixel=1)
Hier lohnt es sich zu reservieren und zu sagen, dass die Implementierung des Algorithmus in Foolbox im Vergleich zum Originalartikel zwar ein gemeinsames Ziel hat (die spezifische Anzahl von Pixeln im Bild zu ändern), sich jedoch in der Methode zum Erhalten des Bildes unterscheidet.
Methoden basierend auf der Verallgemeinerung des BlackBox-Modells
Die meisten Methoden erfordern ein Verständnis der Struktur der Architektur des Modells und die Kenntnis der genauen Werte seiner Parameter. In der Praxis ist dies jedoch selten möglich. Und deshalb erscheint eine separate Angriffsrichtung - BlacBox / GrayBox-Angriffe. Für solche Angriffe reicht es aus, Zugriff auf die Ein- und Ausgabe des Modells zu haben.
Eine der Methoden zum Implementieren eines Angriffs auf das BlackBox-Modell besteht darin, dieses Modell auf das Student-Modell (im Ersatzbild) zu verallgemeinern.
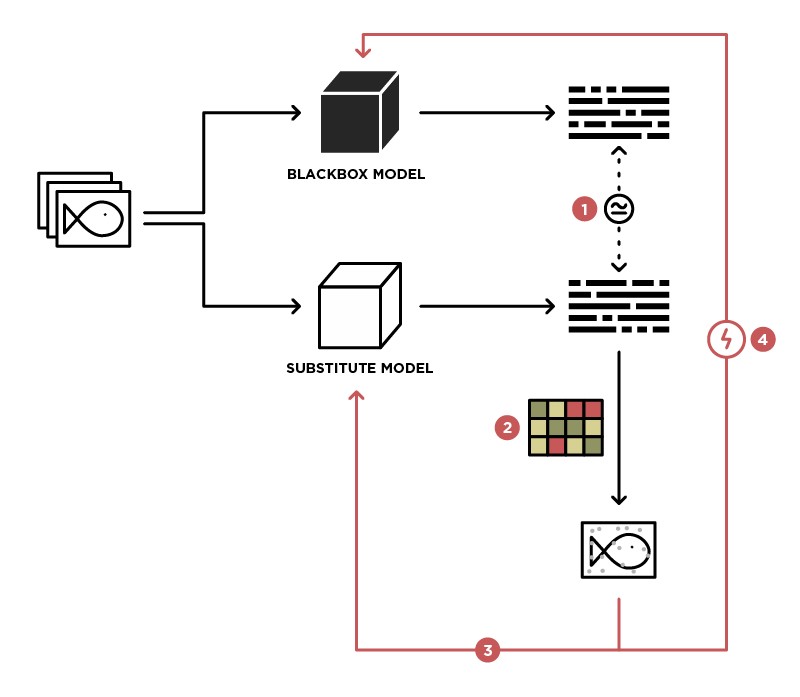
Mit dem Zugriff zum Senden von Daten an das BlackBox-Modell (Lehrer) und dem Zugriff auf die Ausgabe dieses Modells können wir einen Datensatz erstellen, auf dem unser eigenes Modell (Schüler) trainiert werden kann, wodurch das Lehrermodell verallgemeinert wird. Danach können Sie den WhiteBox-Angriff auf das Student-Modell anwenden. Mit hoher Wahrscheinlichkeit wird dieser Angriff auch auf das Teacher-Modell ausgeführt. Die Wahrscheinlichkeit eines solchen Angriffs ist umso höher, je mehr Wissen wir über das Lehrermodell haben. Wir wissen beispielsweise, dass das Lehrermodell Bilder verarbeitet. Am häufigsten werden vorab trainierte Architekturen (ResNet, Inception) mit ImageNet-Gewichten für die Bildverarbeitung verwendet. Basierend auf einem Studentenmodell mit derselben Architektur wird die Wahrscheinlichkeit eines erfolgreichen Angriffs maximiert.
Originalartikel - Praktische Black-Box-Angriffe gegen maschinelles Lernen
Diese Methode wird in keiner der Bibliotheken vorgestellt und erfordert eine unabhängige Implementierung des Student-Modells. Angriffe darauf können mit den oben beschriebenen Methoden ausgeführt werden.
GAN-basierte Methoden
Die nächste Stufe in der Entwicklung von BlackBox-Angriffen waren Angriffe, die auf der Einbettung des BlackBox-Modells in die Architektur des generativ-kontradiktorischen Netzwerks (GAN) basieren, einem Netzwerk, das die Generierung neuer Objekte ermöglicht, die anschließend auf das Black-Box-Modell übertragen werden.
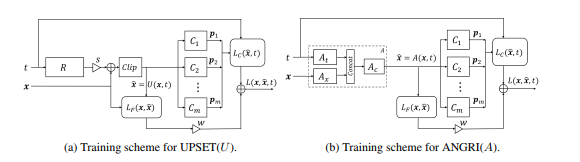
Diese Methode ermöglichte die Erzeugung von kontroversen Beispielen für nahezu jede Architektur. Es erfordert auch Zugang zum Ein- und Ausgang des angegriffenen Modells.
Weitere Informationen zu dieser Methode finden Sie im Originalartikel - UPSET und ANGRI: Breaking High Performance Image Classifiers
Wie Sie vielleicht vermutet haben, sind diese Methoden in keiner der Bibliotheken vertreten.
Fazit
Tatsächlich gibt es eine große Anzahl von Angriffen. Dieser Artikel behandelt nur einige von ihnen. Wir hoffen, dass dieses Material Ihnen geholfen hat, die Grundkonzepte von gegnerischen Beispielen und deren Generierungsalgorithmen zu verstehen. Für eine detailliertere Überprüfung empfehlen wir Ihnen, die Originalartikel und -materialien aus der Referenzliste zu lesen.
Wir sehen uns im nächsten Artikel, der sich auf Methoden zum Schutz und Testen von Algorithmen für maschinelles Lernen konzentriert.
Referenzliste
- Bedrohung durch kontroverse Angriffe auf Deep Learning in Computer Vision: Eine Umfrage - ein großartiger Überblick über Angriffsmethoden auf Deep Learning-Algorithmen in Computer Vision
- Angriff auf maschinelles Lernen mit kontroversen Beispielen - ein OpenAI-Blog, der sich kontroversen Beispielen widmet
- Awesome Adversarial Machine Learning - Github mit Links zu vielen nützlichen Materialien zu kontroversen Themen
- Präsentation zum kontradiktorischen maschinellen Lernen - Präsentation der MoscowPythonConf2018-Konferenz zum kontradiktorischen maschinellen Lernen