Einführung
In einem früheren Artikel (
„Teil 2: Verwenden der PSoC-UDB-Blöcke von Cypress zur Reduzierung der Anzahl von Interrupts in einem 3D-Drucker“ ) habe ich eine sehr interessante Tatsache festgestellt: Wenn ein Computer in UDB Daten zu schnell aus dem FIFO entfernte, konnte er feststellen, dass es neue gibt Es gibt keine Daten im FIFO, danach geht es in einen falschen Zustand
Leerlauf . Das hat mich natürlich interessiert. Ich habe die geöffneten Ergebnisse einer Gruppe von Bekannten gezeigt. Eine Person antwortete, dass dies alles ganz offensichtlich sei, und nannte sogar die Gründe. Der Rest war nicht weniger überrascht als ich zu Beginn der Forschung. Einige Experten werden hier also nichts Neues finden, aber es wäre schön, diese Informationen der Öffentlichkeit zugänglich zu machen, damit alle Programmierer für Mikrocontroller dies berücksichtigen.
Nicht, dass es sich um eine Art Deckung handelte. Es stellte sich heraus, dass dies alles gut dokumentiert ist, aber das Problem ist, dass nicht in der Hauptsache, sondern in zusätzlichen Dokumenten. Und ich persönlich war in glücklicher Unwissenheit und glaubte, dass DMA ein sehr flinkes Subsystem ist, das die Effizienz von Programmen dramatisch steigern kann, da es eine systematische Datenübertragung gibt, ohne das Registerinkrement abzulenken und den Zyklus auf dieselben Befehle zu organisieren. Was die Verbesserung der Effizienz betrifft - alles ist wahr, aber aufgrund etwas anderer Dinge.
Aber das Wichtigste zuerst.
Experimente mit Cypress PSoC
Machen wir eine einfache Maschine. Es wird bedingt zwei Zustände haben: den Ruhezustand und den Zustand, in den es fällt, wenn mindestens ein Datenbyte im FIFO vorhanden ist. Wenn er in diesen Zustand eintritt, nimmt er einfach diese Daten und versagt dann erneut in einem Ruhezustand. Das Wort "bedingt" habe ich nicht versehentlich zitiert. Wir haben zwei FIFOs, daher werde ich zwei solche Zustände festlegen, einen für jeden FIFO, um sicherzustellen, dass sie sich im Verhalten vollständig identifizieren. Das Übergangsdiagramm für die Maschine sah folgendermaßen aus:
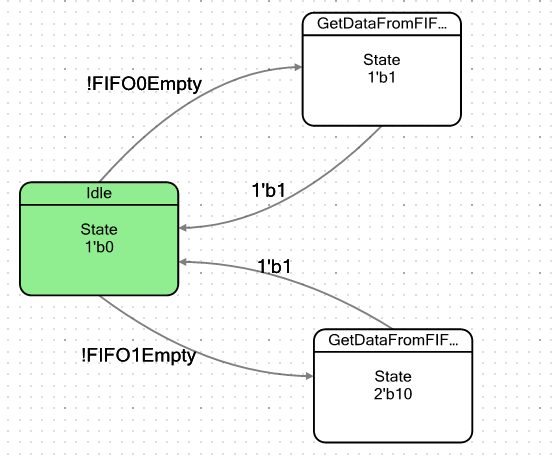
Die Flags zum Verlassen des Ruhezustands sind wie folgt definiert:
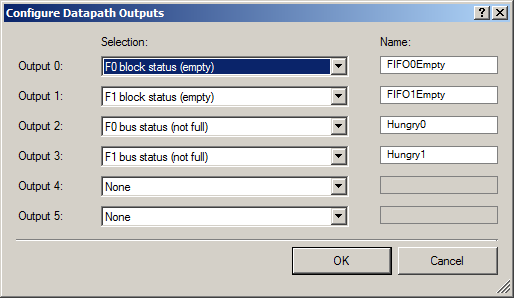
Vergessen Sie nicht, die Bits der Statusnummer an die Datenpfadeingänge zu senden:

Nach außen geben wir zwei Gruppen von Signalen aus: ein Signalpaar, für das der FIFO freien Speicherplatz hat (damit DMA mit dem Hochladen von Daten beginnen kann), und ein paar Signale, für die der FIFO leer ist (um diese Tatsache auf einem Oszilloskop anzuzeigen).

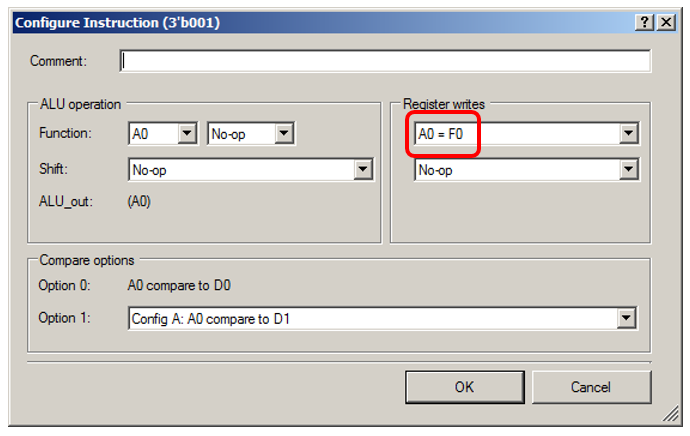
ALU nimmt einfach fiktiv Daten vom FIFO entgegen:

Lassen Sie mich Ihnen die Details für den Status "0001" zeigen:
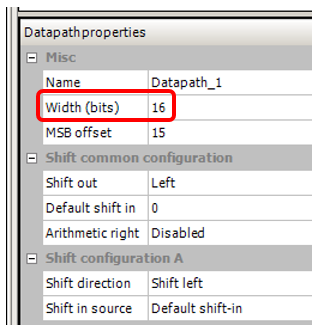
Ich habe auch die Busbreite, die sich in dem Projekt befand, bei dem ich diesen Effekt bemerkt habe, auf 16 Bit eingestellt:
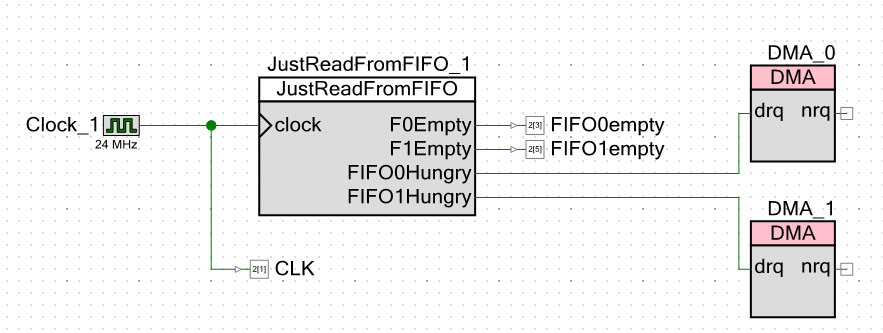
Wir gehen zum Schema des Projekts selbst über. Äußerlich gebe ich nicht nur Signale aus, dass der FIFO leer ist, sondern auch Taktimpulse. Dadurch kann ich auf Cursormessungen auf einem Oszilloskop verzichten. Ich kann einfach mit dem Finger Maßnahmen ergreifen.
Anscheinend habe ich 24 Megahertz Taktrate gemacht. Die Prozessorkernfrequenz ist genau gleich. Je niedriger die Frequenz, desto weniger Interferenzen treten bei einem chinesischen Oszilloskop auf (offiziell hat es ein Band von 250 MHz, dann aber chinesisches Megahertz), und alle Messungen werden in Bezug auf Taktimpulse durchgeführt. Unabhängig von der Frequenz funktioniert das System in Bezug auf diese weiterhin. Ich hätte einen Megahertz eingestellt, aber die Entwicklungsumgebung verbot mir, einen Prozessorkernfrequenzwert von weniger als 24 MHz einzugeben.
Nun das Testmaterial. Um in FIFO0 zu schreiben, habe ich folgende Funktion ausgeführt:
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
Das Wort ROM im Funktionsnamen ist darauf zurückzuführen, dass das zu sendende Array im ROM-Bereich gespeichert ist und der Cortex M3 über eine Harvard-Architektur verfügt. Die Zugriffsgeschwindigkeit auf den RAM-Bus und den ROM-Bus kann variieren. Ich wollte dies überprüfen, daher habe ich eine ähnliche Funktion zum Senden eines Arrays aus dem RAM (das
Step- Array enthält keinen
statischen Const- Modifikator in seinem Hauptteil). Nun, es gibt das gleiche Funktionspaar zum Senden an FIFO1, das Empfängerregister ist dort unterschiedlich: nicht F0, sondern F1. Ansonsten sind alle Funktionen identisch. Da ich keinen großen Unterschied in den Ergebnissen festgestellt habe, werde ich die Ergebnisse des Aufrufs genau der obigen Funktion berücksichtigen. Ein gelber Strahl - Taktimpulse, blauer Ausgang
FIFO0empty .

Überprüfen Sie zunächst die Plausibilität, warum der FIFO über zwei Taktzyklen gefüllt ist. Sehen wir uns diese Seite genauer an:
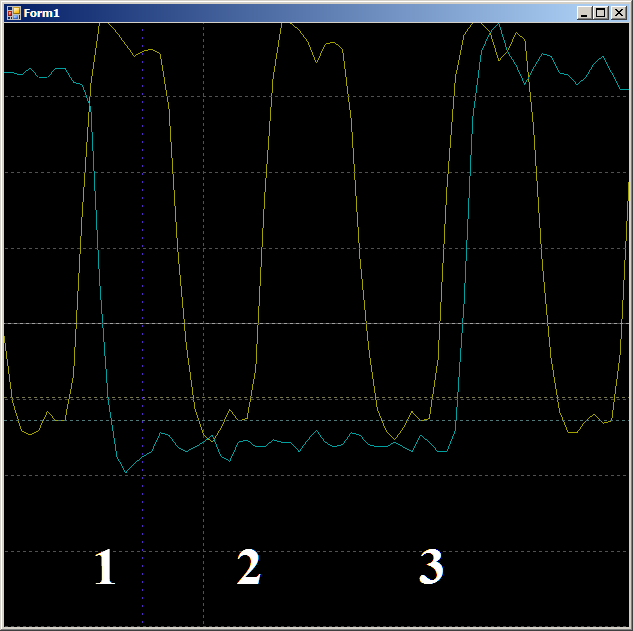
An Kante 1 fallen die Daten in den FIFO, das
FIFO0-Leerzeichen fällt ab. An Kante 2 wechselt der Automat in den
Status GetDataFromFifo1 . An Kante 3 werden in diesem Zustand Daten vom FIFO in das ALU-Register kopiert, FIFO wird geleert, das Flag
FIFO0empty wird erneut
ausgelöst . Das heißt, die Wellenform verhält sich plausibel, Sie können sich auf den Taktzyklus verlassen. Wir bekommen 9 Stück.
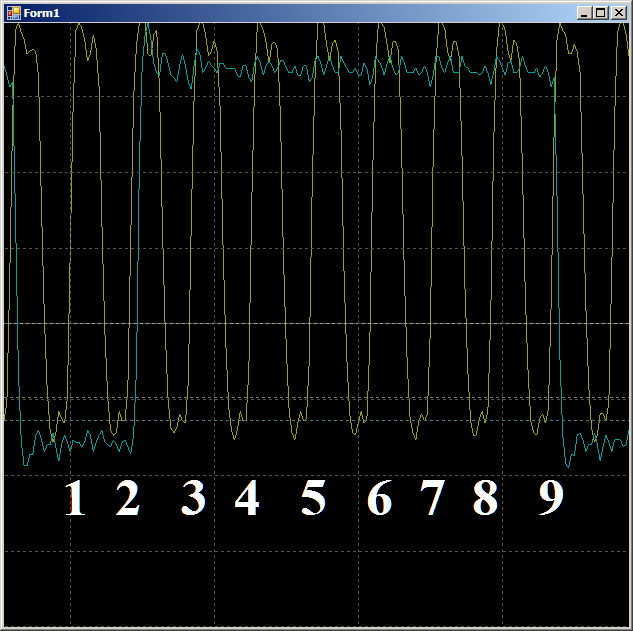 Insgesamt dauert es im inspizierten Bereich 9 Taktzyklen, um ein Datenwort mit DMA aus dem RAM in die UDB zu kopieren.
Insgesamt dauert es im inspizierten Bereich 9 Taktzyklen, um ein Datenwort mit DMA aus dem RAM in die UDB zu kopieren.Und jetzt das Gleiche, aber mit Hilfe des Prozessorkerns. Erstens ein idealer Code, der im wirklichen Leben kaum erreichbar ist:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0;
Was wird zum Assembler-Code?
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] bn 8e <main+0xa> .word 0x40006898
Keine Pausen, keine zusätzlichen Zyklen. Zwei Taktpaare hintereinander ...
Lassen Sie uns den Code etwas realer gestalten (mit dem Aufwand, den Zyklus zu organisieren, Daten abzurufen und Zeiger zu erhöhen):
void SoftWriteTo0FromROM() { // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } }
Assembler-Code erhalten:
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa>
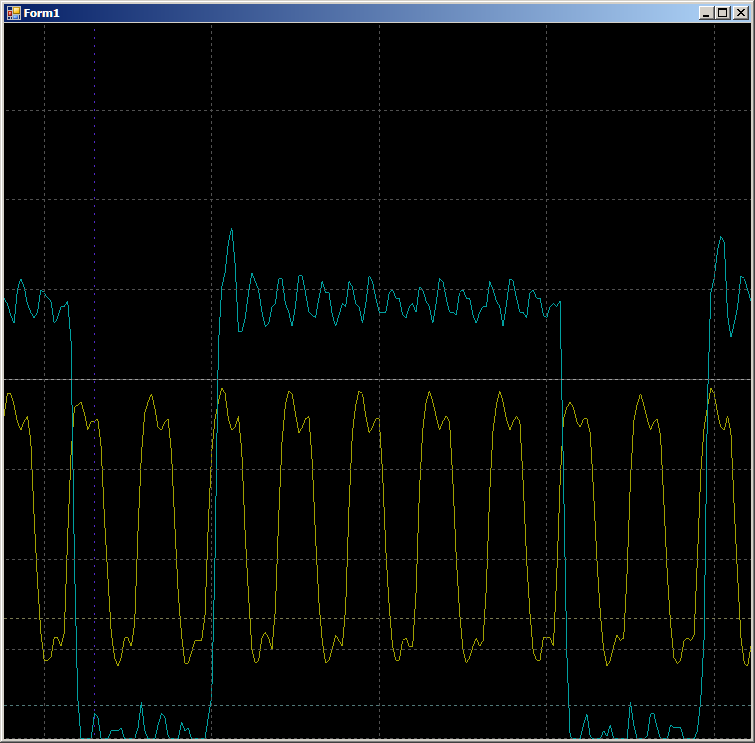
Auf dem Oszillogramm sehen wir nur 7 Zyklen pro Zyklus gegenüber neun im Fall von DMA:
Ein bisschen über Mythos
Um ehrlich zu sein, war es für mich ursprünglich ein Schock. Ich bin es irgendwie gewohnt zu glauben, dass der DMA-Mechanismus es Ihnen ermöglicht, Daten schnell und effizient zu übertragen. 1/9 der Busfrequenz ist nicht so schnell. Aber es stellte sich heraus, dass niemand es versteckte. Das TRM-Dokument für PSoC 5LP enthält sogar eine Reihe theoretischer Überlegungen, und das Dokument „AN84810 - Erweiterte DMA-Themen für PSoC 3 und PSoC 5LP“ beschreibt ausführlich den Zugriff auf DMA. Latenz ist schuld. Der Austauschzyklus mit dem Bus dauert eine bestimmte Anzahl von Ticks. Tatsächlich spielen diese Maßnahmen beim Auftreten einer Verzögerung eine entscheidende Rolle. Im Allgemeinen versteckt niemand etwas, aber Sie müssen dies wissen.
Wenn das berühmte GPIF, das in FX2LP (einer anderen von Cypress hergestellten Architektur) verwendet wird, nichts einschränkt, ist das Tempolimit auf Latenzen zurückzuführen, die beim Zugriff auf den Bus auftreten.DMA-Prüfung auf STM32
Ich war so beeindruckt, dass ich mich entschied, ein Experiment mit STM32 durchzuführen. Ein STM32F103 mit dem gleichen Cortex M3-Prozessorkern wurde als experimentelles Kaninchen genommen. Es gibt keine UDB, aus der Dienstsignale abgeleitet werden könnten, aber es ist durchaus möglich, DMA zu überprüfen. Was ist ein GPIO? Dies ist ein Satz von Registern in einem gemeinsamen Adressraum. Das ist in Ordnung. Wir konfigurieren DMA im Kopiermodus „Speicher-Speicher“, indem wir den realen Speicher (ROM oder RAM) als Quelle und das GPIO-Datenregister ohne das Adressinkrement als Empfänger angeben. Wir werden abwechselnd entweder 0 oder 1 dorthin senden und das Ergebnis mit einem Oszilloskop fixieren. Zu Beginn habe ich Port B gewählt, es war einfacher, eine Verbindung über das Steckbrett herzustellen.

Ich habe es wirklich genossen, Maßnahmen mit einem Finger zu zählen, nicht mit Cursorn. Ist es möglich, dasselbe auf diesem Controller zu tun? Ganz! Nehmen Sie die Referenztaktfrequenz für das Oszilloskop vom MCO-Zweig, der an den PA8-Anschluss des STM32F10C8T6 angeschlossen ist. Die Auswahl der Quellen für diesen billigen Kristall ist nicht großartig (der gleiche STM32F103, aber beeindruckender, er bietet viel mehr Optionen). Wir werden das SYSCLK-Signal an diesen Ausgang senden. Da die Frequenz auf dem MCO nicht höher als 50 MHz sein kann, reduzieren wir die Taktrate des Gesamtsystems auf 48 MHz. Wir werden die Frequenz von Quarz 8 MHz nicht mit 9, sondern mit 6 multiplizieren (da 6 * 8 = 48):

Gleicher Text: void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); }
Wir werden das MCO mit der
mcucpp- Bibliothek von Konstantin Chizhov programmieren (von nun an werde ich alle Anrufe an die Ausrüstung über diese wunderbare Bibliothek durchführen):
// MCO Mcucpp::Clock::McoBitField::Set (0x4); // MCO Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest);
Nun stellen wir die Ausgabe des Datenarrays im GPIOB ein:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // GPIOB dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // , DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } }
Die resultierende Wellenform ist der auf dem PSoC sehr ähnlich.

In der Mitte befindet sich ein großer blauer Buckel. Dies ist der DMA-Initialisierungsprozess. Die blauen Impulse links wurden rein per Software auf PB1 empfangen. Dehnen Sie sie weiter:

2 Maßnahmen pro Puls. Der Betrieb des Systems ist wie erwartet. Aber jetzt schauen wir uns den größeren Bereich an, der auf der Hauptwellenform mit einem dunkelblauen Hintergrund markiert ist. Zu diesem Zeitpunkt wird der DMA-Block bereits ausgeführt.
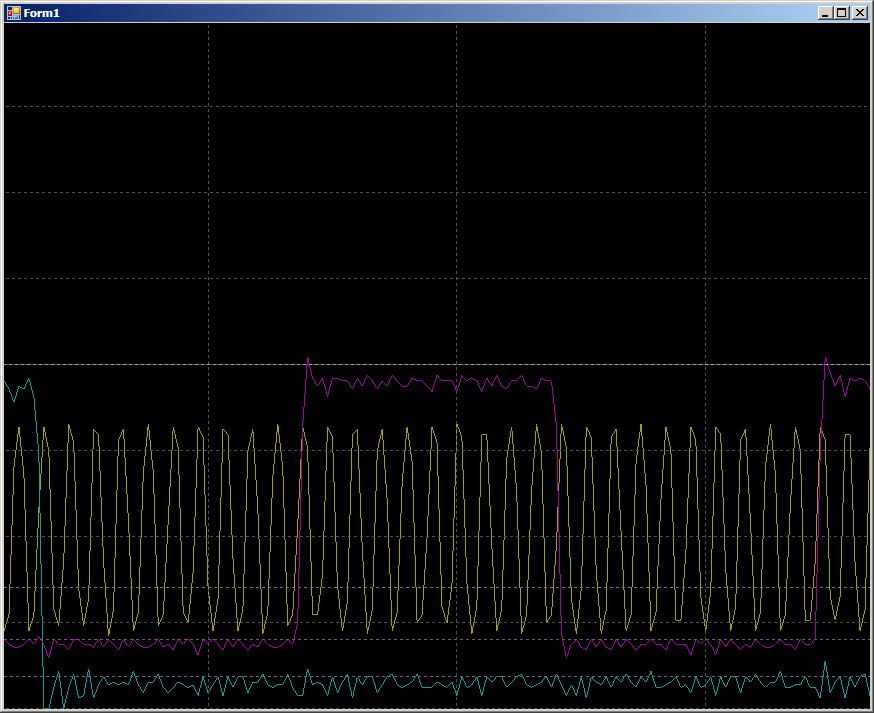
10 Zyklen pro GPIO-Leitungswechsel. Tatsächlich geht die Arbeit mit RAM, und das Programm wird in einem konstanten Zyklus wiederholt. Es gibt keine RAM-Aufrufe vom Prozessorkern. Der Bus steht der DMA-Einheit vollständig zur Verfügung, jedoch 10 Zyklen. Tatsächlich unterscheiden sich die Ergebnisse jedoch nicht wesentlich von denen auf der PSoC. Suchen Sie daher einfach nach Anwendungshinweisen zu DMA auf STM32. Es gab mehrere von ihnen. Es gibt AN2548 auf F0 / F1, es gibt AN3117 auf L0 / L1 / L3, es gibt AN4031 auf F2 / F4 / F77. Vielleicht gibt es noch mehr ...
Trotzdem sehen wir bei ihnen, dass auch hier die Latenz schuld ist. Darüber hinaus ist der Batch-Zugriff des F103 auf den Bus mit DMA nicht möglich. Sie sind für F4 möglich, jedoch nicht mehr als für vier Wörter. Andererseits tritt das Latenzproblem auf.
Versuchen wir, die gleichen Aktionen auszuführen, jedoch mithilfe eines Programmdatensatzes. Oben haben wir gesehen, dass die direkte Aufzeichnung an Ports sofort erfolgt. Aber es gab ziemlich eine perfekte Aufzeichnung. Zeilen:
// dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set();
vorbehaltlich solcher Optimierungseinstellungen (Sie müssen die Optimierung für die Zeit angeben):

wurde in den folgenden Assembler-Code umgewandelt:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00]
Beim realen Kopieren wird die Quelle, der Empfänger aufgerufen, die Schleifenvariable geändert, verzweigt ... Im Allgemeinen viel Overhead (der, wie angenommen wird, nur den DMA eliminiert). Wie schnell werden sich die Änderungen im Hafen ändern? Also schreiben wir:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Dieser C ++ - Code wird zu einem solchen Assemblycode:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8
Und wir bekommen:
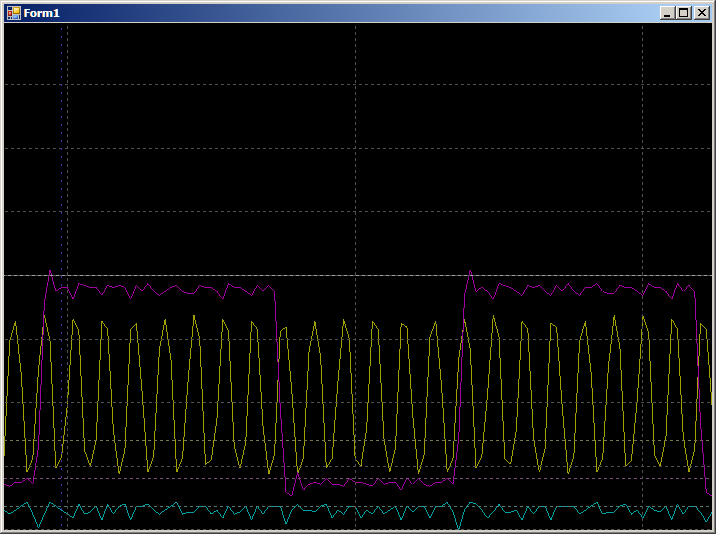
8 Takte in der oberen Hälfte und 6 in der unteren Hälfte (ich habe überprüft, das Ergebnis wird für alle Halbperioden wiederholt). Der Unterschied ergab sich, weil der Optimierer 2 Kopien pro Iteration erstellt hat. Daher werden dem Zweigbetrieb 2 Takte in einer der Halbperioden hinzugefügt.
Grob gesagt werden beim Kopieren von Software 14 Takte für das Kopieren von zwei Wörtern gegen 20 Takte auf demselben ausgegeben, jedoch von DMA. Das Ergebnis ist ziemlich dokumentiert, aber für diejenigen, die die erweiterte Literatur noch nicht gelesen haben, sehr unerwartet.Gut. Aber was passiert, wenn Sie Daten gleichzeitig in zwei DMA-Streams schreiben? Wie viel Geschwindigkeit wird fallen? Schließen Sie den blauen Strahl an PA0 an und schreiben Sie das Programm wie folgt neu:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Lassen Sie uns zunächst die Art der Impulse untersuchen:
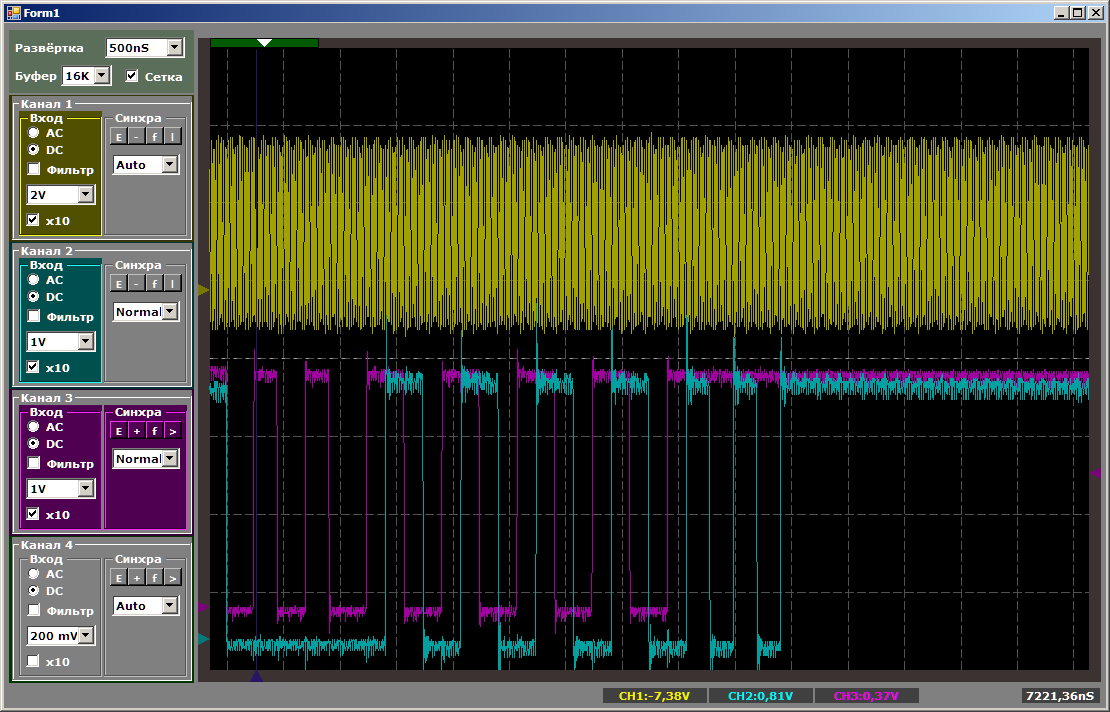
Während der zweite Kanal eingestellt wird, ist die Kopiergeschwindigkeit für den ersten höher. Wenn Sie dann paarweise kopieren, sinkt die Geschwindigkeit. Wenn der erste Kanal fertig ist, beginnt der zweite schneller zu arbeiten. Alles ist logisch, es bleibt nur herauszufinden, um wie viel die Geschwindigkeit sinkt.
Während es nur einen Kanal gibt, dauert die Aufnahme 10 bis 12 Takte (Ziffern schweben).

Während der Zusammenarbeit erhalten wir 16 Zyklen pro Datensatz in jedem Port:
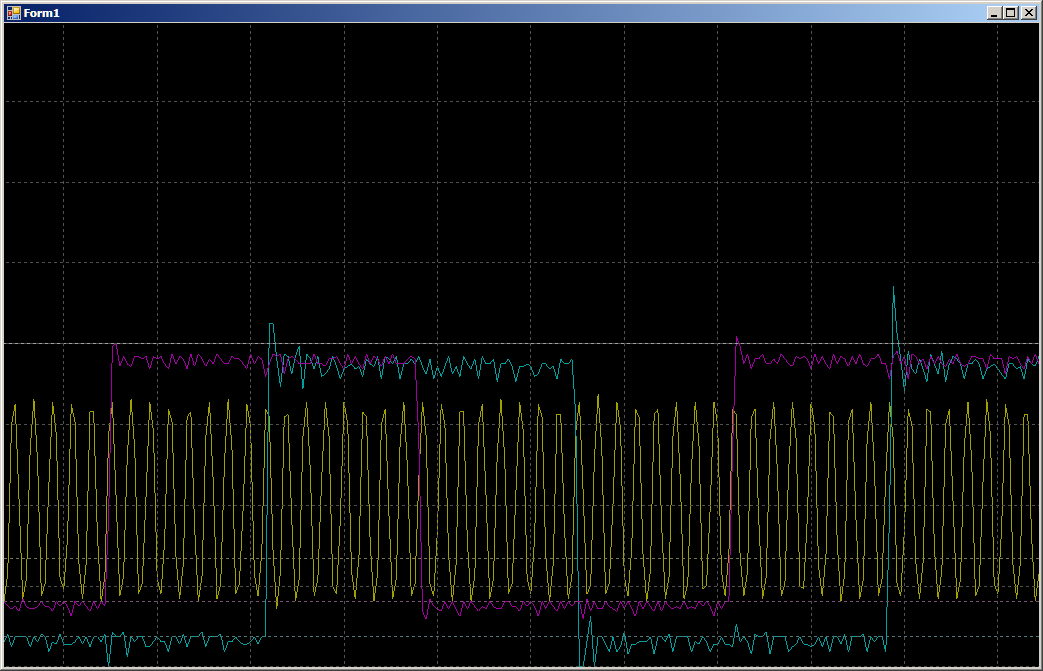
Das heißt, die Geschwindigkeit wird nicht halbiert. Aber was ist, wenn Sie anfangen, in drei Threads gleichzeitig zu schreiben? Wir fügen Arbeit mit PC15 hinzu, da PC0 nicht ausgegeben wird (deshalb werden nicht 0, 1, 0, 1 ..., sondern 0x0000,0x8001, 0x0000, 0x8001 ... im Array ausgegeben).
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2);
Hier ist das Ergebnis so unerwartet, dass ich den Strahl ausschalte, der die Taktfrequenz anzeigt. Wir haben keine Zeit für Messungen. Wir betrachten die Logik der Arbeit.

Bis der erste Kanal die Arbeit beendet hatte, begann der dritte nicht mit der Arbeit. Drei Kanäle gleichzeitig funktionieren nicht! Etwas zu diesem Thema kann aus AppNote zu DMA abgeleitet werden. Es heißt, dass F103 nur zwei Engines in einem Block hat (und wir kopieren mit einem Block von DMA, der zweite ist jetzt inaktiv und das Volumen des Artikels ist bereits so, dass ich es verwenden kann Ich werde nicht). Wir schreiben das Beispielprogramm so um, dass der dritte Kanal früher startet als alle anderen:

Gleicher Text: // , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Das Bild ändert sich wie folgt:

Der dritte Kanal wurde gestartet, er arbeitete sogar mit dem ersten zusammen, aber als der zweite ins Geschäft kam, wurde der dritte ersetzt, bis der erste Kanal fertiggestellt war.
Ein bisschen über Prioritäten
Tatsächlich bezieht sich das vorherige Bild auf die Prioritäten von DMA, es gibt einige. Wenn alle Arbeitskanäle die gleiche Priorität haben, kommen ihre Nummern ins Spiel. Innerhalb einer bestimmten Priorität hat derjenige, der eine kleinere Anzahl hat, die Priorität. Versuchen wir, auf dem dritten Kanal eine andere globale Priorität anzugeben und diese vor allen anderen zu erhöhen (auf dem Weg werden wir auch die Priorität des zweiten Kanals erhöhen):

Gleicher Text: channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Jetzt wird der erste, der früher am coolsten war, benachteiligt.
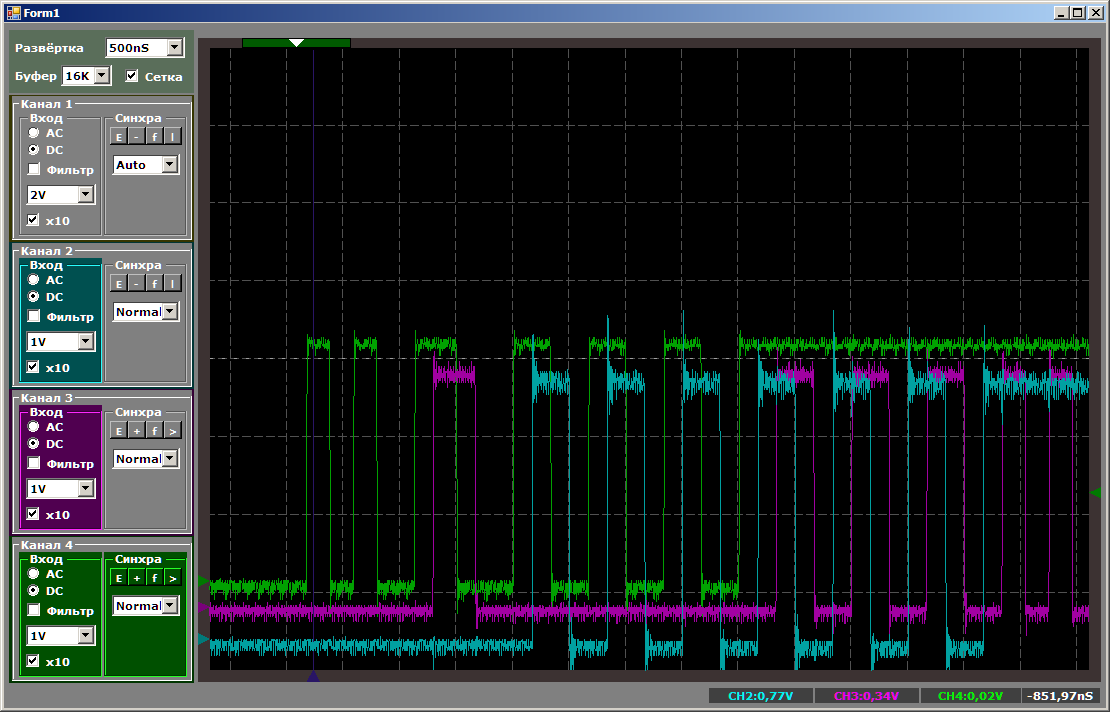
Insgesamt sehen wir, dass STM32F103 selbst bei Prioritäten nicht mehr als zwei Threads auf einem DMA-Block starten kann. Grundsätzlich kann der dritte Thread auf dem Prozessorkern ausgeführt werden. Auf diese Weise können wir die Leistung vergleichen.
// , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Zunächst das allgemeine Bild, das zeigt, dass alles parallel funktioniert und der Prozessorkern die höchste Kopiergeschwindigkeit aufweist:
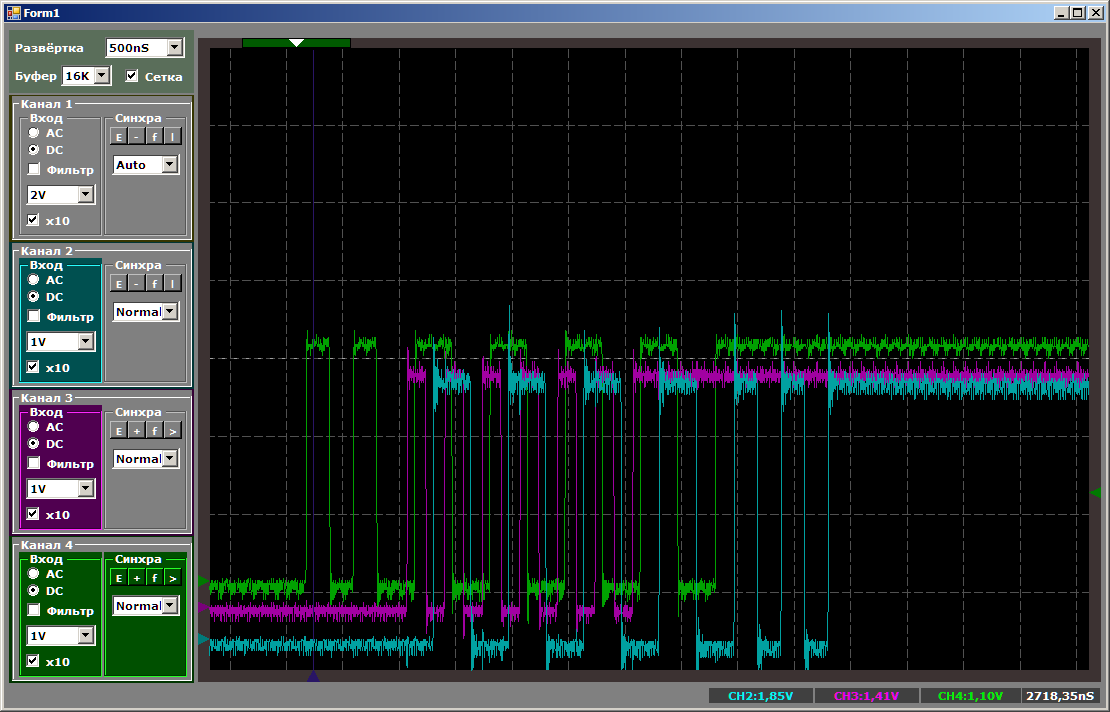
Und jetzt gebe ich jedem die Möglichkeit, die Maßnahmen zu einem Zeitpunkt zu zählen, an dem alle Kopierströme aktiv sind:
Der Prozessorkern priorisiert alle
Kommen wir nun zu der Tatsache zurück, dass während des Zweithread-Betriebs, während der zweite Kanal abgestimmt war, der erste Daten für eine andere Anzahl von Taktzyklen ausgegeben hat. Diese Tatsache ist auch in AppNote on DMA gut dokumentiert. Tatsache ist, dass während des Aufbaus des zweiten Kanals regelmäßig Anforderungen an den RAM gesendet wurden und der Prozessorkern beim Zugriff auf den RAM eine höhere Priorität hat als der DMA-Kern. Wenn der Prozessor einige Daten anforderte, nahm DMA Taktzyklen weg, empfing Daten mit einer Verzögerung und kopierte daher langsamer. Lassen Sie uns das letzte Experiment für heute machen. Lassen Sie uns die Arbeit realer gestalten. Nach dem Starten von DMA gehen wir nicht in einen leeren Zyklus (wenn definitiv kein Zugriff auf RAM besteht), sondern führen eine Kopieroperation von RAM zu RAM durch, aber diese Operation bezieht sich nicht auf die Operation von DMA-Kernen:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } }

An einigen Stellen erstreckte sich der Zyklus von 16 auf 17 Maßnahmen. Ich hatte Angst, dass es schlimmer werden würde.
Fangen Sie an, Schlussfolgerungen zu ziehen
Eigentlich wenden wir uns dem zu, was ich sagen wollte.
Ich werde von weitem anfangen. Vor einigen Jahren, als ich anfing, STM32 zu studieren, studierte ich die damals existierenden Versionen von MiddleWare für USB und fragte mich, warum die Entwickler die Datenübertragung über DMA entfernt hatten. Es war offensichtlich, dass zunächst eine solche Option in Sicht war, dann wurde sie in die Hinterhöfe verlegt, und am Ende gab es nur noch Grundlagen. Jetzt fange ich an zu vermuten, dass ich die Entwickler verstehe.
Im
ersten Artikel über UDB habe ich gesagt, dass UDB zwar mit parallelen Daten arbeiten kann, es jedoch unwahrscheinlich ist, dass es GPIF durch sich selbst ersetzen kann, da der PSoC-USB-Bus für FX2LP mit voller Geschwindigkeit im Vergleich zu hoher Geschwindigkeit läuft. Es stellt sich heraus, dass es einen schwerwiegenderen begrenzenden Faktor gibt. DMA hat einfach keine Zeit, Daten mit der gleichen Geschwindigkeit wie das GPIF zu liefern, selbst innerhalb des Controllers, ohne den USB-Bus zu berücksichtigen.
Wie Sie sehen können, gibt es keine einzelne Entitäts-DMA. Erstens macht jeder Hersteller seinen eigenen Weg. Nicht nur das, auch ein Hersteller für verschiedene Familien kann den Ansatz zum Aufbau von DMA variieren. Wenn Sie dieses Gerät ernsthaft laden möchten, sollten Sie sorgfältig prüfen, ob die Anforderungen erfüllt werden.
Wahrscheinlich ist es notwendig, den pessimistischen Fluss mit einer optimistischen Bemerkung zu verdünnen. Ich werde sie sogar hervorheben.
Mit DMA von Cortex M-Controllern können Sie die Systemleistung nach dem Prinzip der berühmten Javelins steigern: "Starten und vergessen". Ja, das Kopieren von Daten durch Software ist etwas schneller. Wenn Sie jedoch mehrere Threads kopieren müssen, kann kein Optimierer den Prozessor dazu bringen, alle Threads zu steuern, ohne dass der Aufwand für das Neuladen von Registern und das Drehen von Schleifen anfällt. Außerdem muss der Prozessor bei langsamen Ports noch auf die Verfügbarkeit warten, und DMA tut dies auf Hardwareebene.Aber auch hier sind verschiedene Nuancen möglich. Wenn der Port nur relativ langsam ist ... Angenommen, ein SPI arbeitet mit der höchstmöglichen Frequenz, dann gibt es theoretisch mögliche Situationen, in denen der DMA keine Zeit hat, Daten aus dem Puffer zu sammeln, und ein Überlauf auftritt. Oder umgekehrt - legen Sie die Daten in das Pufferregister. Wenn der Datenstrom einzeln ist, ist dies unwahrscheinlich, aber wenn es viele davon gibt, haben wir gesehen, welche erstaunlichen Überlagerungen auftreten können. Um dies zu bewältigen, sollten Sie Aufgaben nicht separat, sondern in Kombination entwickeln. Und Tester versuchen, solche Probleme zu provozieren (solch eine zerstörerische Arbeit für Tester).
Wieder versteckt niemand diese Daten. Aus irgendeinem Grund ist all dies normalerweise nicht im Hauptdokument enthalten, sondern in den Anwendungshinweisen. Meine Aufgabe war es daher, die Programmierer darauf aufmerksam zu machen, dass DMA kein Allheilmittel, sondern nur ein praktisches Werkzeug ist.
Aber natürlich nicht nur Programmierer, sondern auch Hardwareentwickler. Angenommen, in unserer Organisation wird ein großer Software- und Hardwarekomplex für das Remote-Debugging eingebetteter Systeme entwickelt. Die Idee ist, dass jemand ein Gerät entwickelt, aber die "Firmware" nebenbei bestellen möchte. Und aus irgendeinem Grund kann keine Ausrüstung zur Seite gestellt werden. Es kann sperrig sein, es kann teuer sein, es kann einzigartig sein und „es selbst brauchen“, verschiedene Gruppen können in verschiedenen Zeitzonen damit arbeiten, eine Art Mehrschichtarbeit bieten, es kann ständig in Erinnerung gerufen werden ... Im Allgemeinen können Sie Gründe finden Sehr viel, unsere Gruppe hat diese Aufgabe einfach für selbstverständlich gehalten.
Dementsprechend sollte der Debugging-Komplex in der Lage sein, so viele externe Geräte wie möglich zu simulieren, von der trivialen Simulation von Tastendrücken bis zu verschiedenen Protokollen SPI, I2C, CAN, 4-20 mA und anderen, anderen Dingen, damit Emulatoren durch sie unterschiedliche Verhaltensweisen externer Geräte wiederherstellen können Blöcke, die mit der zu entwickelnden Ausrüstung verbunden sind (ich persönlich habe einmal viele Simulatoren für das Boden-Debugging von Anbaugeräten für Hubschrauber erstellt, auf unserer
Website werden die entsprechenden Fälle mit dem Wort Cassel Aero gesucht ).
Und so in den technischen Anforderungen für die Entwicklung bestimmter Anforderungen. So viel SPI, so viel I2C, so viel GPIO. Sie müssen bei solchen und solchen extremen Frequenzen arbeiten. Alles scheint klar zu sein. Wir haben STM32F4 und ULPI für die Arbeit mit USB in den HS-Modus versetzt. Die Technologie ist bewährt. Aber hier kommt ein langes Wochenende mit den Novemberferien, die ich mit UDB herausgefunden habe. Als ich sah, dass etwas nicht stimmte, bekam ich abends die praktischen Ergebnisse, die am Anfang dieses Artikels angegeben sind. Und mir wurde klar, dass natürlich alles großartig ist, aber nicht für dieses Projekt. Wie bereits erwähnt, sollte, wenn sich die mögliche maximale Systemleistung der Obergrenze nähert, alles nicht separat, sondern in einem Komplex entworfen werden.
Aber hier kann eine integrierte Gestaltung von Aufgaben grundsätzlich nicht sein. , — . . , FTDI. -- , USB . . DMA. , , , , – , .
. DMA (, 10: 1 , , 1 , 10 ) .