Ich möchte meine Geschichte über die Anwendung von Migrationsmonolithen in Microservices teilen. Bitte denken Sie daran, dass es von 2012 bis 2014 war. Es ist eine Transkription meiner Präsentation auf der dotnetconf (RU) . Ich werde eine Geschichte über die Veränderung jedes Teils der Infrastruktur erzählen.
Projektbeschreibung

Die Hauptprojektidee bestand darin, Artikel aus dem Internet zu crawlen, zu analysieren, Benutzer-Feeds zu speichern und zu erstellen. Einerseits musste unsere Infrastruktur zuverlässig sein, andererseits hatten wir ein begrenztes Budget. Infolgedessen waren wir uns einig, dass:
- Eine Verschlechterung der Systemleistung ist zulässig.
- Einige Teile unserer Infrastruktur sind möglicherweise 30 Minuten lang außer Betrieb.
- Im Katastrophenfall kann die Ausfallzeit einige Tage betragen.
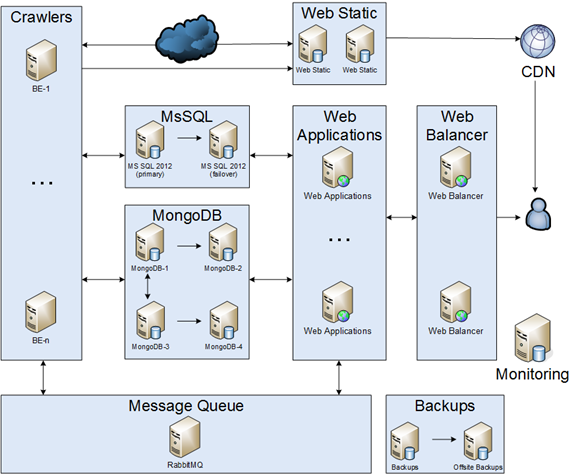
Crawler
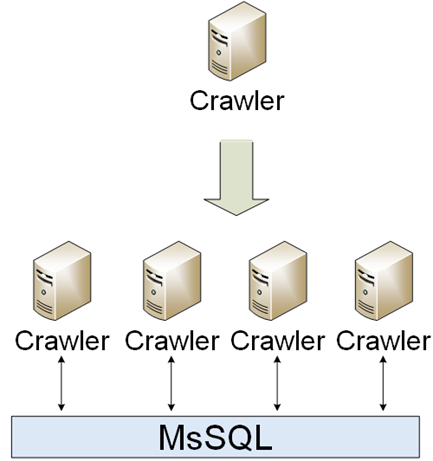
Es war ein einfacher Teil der Infrastruktur. Crawler sollten herunterladen, analysieren und speichern. Die erste Implementierung war ein einzelner Crawler, jedoch veränderte sich die Welt und es erschienen viele verschiedene Crawler. Crawler kommunizierten über MsSQL miteinander.
Ausfallzeiten waren für Crawler kein Problem, daher war es wirklich einfach, sie zu skalieren:
- Bereitstellung automatisieren.
- Fügen Sie Geschäftsmetriken hinzu.
- Fehler sammeln.
Msql
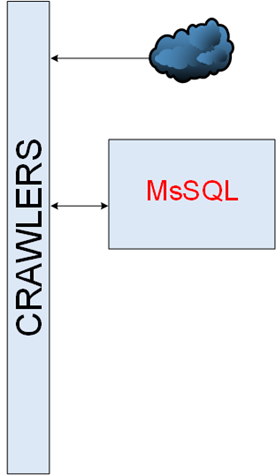
Unsere Datenbank war ungefähr 1 TB groß.
MsSQL-Cluster
Es gab verschiedene Möglichkeiten, einen Cluster zu erstellen:
- SQL-Spiegelung.
- Windows-Failovercluster - dies war kein Fall, da kein San / Nas vorhanden war.
- AlwaysOn - es war völlig neu für uns und es gab kein Fachwissen darin, also war es kein Fall für uns.
Aus diesem Grund haben wir uns für den 1. entschieden. Ich möchte darauf hinweisen, dass wir wegen des asynchronen Modus keinen Zeugen verwendet haben. Deshalb haben wir Skripte für Auto Switch Master -> Slave & Manual Slave -> Master erstellt.
MsSQL-Leistung

Die Uhr tickte, eine Leistung verschlechterte sich, wir suchten nach Engpässen. Manchmal war es nicht einfach, dh wir optimierten SQL-Abfragen nach Festplatte io, als wir feststellten, dass die Leistung aufgrund fehlenden Arbeitsspeichers gering war. Es reichte jedoch nicht aus, als vorübergehende Lösung haben wir von HDD auf SSD migriert. Einerseits wurde die Leistung dramatisch gesteigert, andererseits war es keine langfristige Lösung.
Nachrichtenwarteschlange
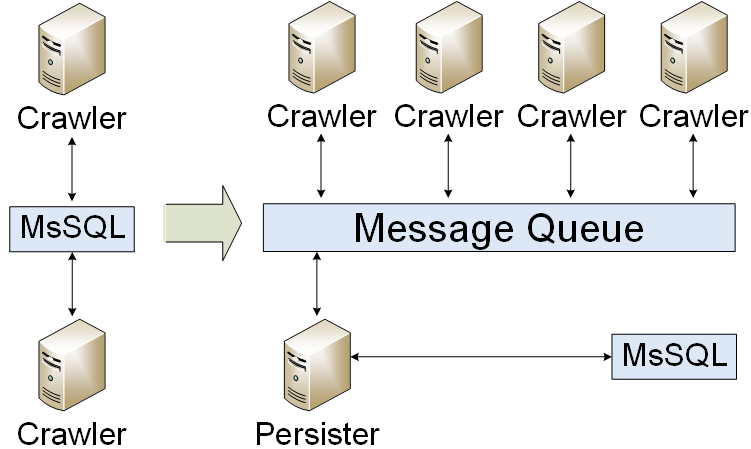
Unsere Anwendung wurde in eine Nachrichtenwarteschlange migriert. Wir haben nur Ergebnisse in die Datenbank geschrieben. Infolgedessen haben wir die Datenbanklast reduziert. Wir hatten jedoch ein Problem: Wie organisiert man einen Nachrichtenwarteschlangencluster? Zuerst haben wir einen kalten Standby erstellt.
WEB

Ein Webpart bestand aus zwei Teilen: statischem Inhalt und benutzerdynamischem Inhalt.
WEB statisch

Der statische WEB-Teil der Infrastruktur war ungefähr 2 TB groß und musste:
- Bilder speichern.
- Bilder konvertieren.
- Crawlen Sie das Ursprungsbild und beschneiden Sie es bei Bedarf.

Es gab zwei Hauptprobleme: Synchronisieren von Dateien und Erstellen eines Webclusters. Es gab verschiedene Möglichkeiten, Dateien zu synchronisieren: Kaufen Sie einen Speicher, verwenden Sie DFS und speichern Sie Dateien auf jedem Server. Es war eine schwierige Entscheidung, aber wir haben uns für den 3. Weg entschieden. Für den Webcluster haben wir uns für NLB & CDN entschieden.
WEB Balancer

Es ist keine wirklich gute Idee, einen einzelnen Server für ein Hochlastprojekt zu verwenden. Sie müssen den Datenverkehr irgendwie ausgleichen. In unserem Fall gab es 4 Möglichkeiten:
- Hardware Balancer - es war zu teuer für uns.
- IIS & ARR - es war zu kompliziert, um es zu unterstützen.
- Nginx - es war gut genug, aber wir hatten einige Probleme mit Gesundheitschecks.
- Haproxy - es war eine Lösung mit dem geringsten Overhead.
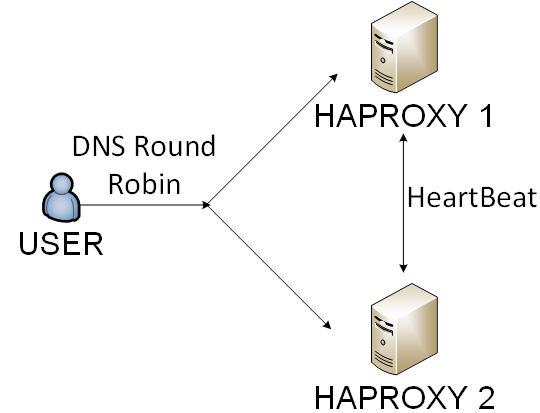
Wir haben den 4. Weg gewählt. Wir haben Haproxy per DNS-Round-Robin und Benutzer per Cookie ausgeglichen.
Mongodb

Einige Monate später stellten wir fest, dass die SQL-Leistung wieder nicht gut genug war. Nach langen Gesprächen entschieden wir uns jedoch für Verfügbarkeit und Partitionstoleranz aus dem CAP-Theorem . Als Ergebnis haben wir einen MongoDB-Cluster (Sharding & Replica) implementiert. Es gab eine interessante Erfahrung: wie man ein MongoDB-Backup erstellt, wie man ein Upgrade durchführt und viele MongoDB-Fehler.
Backups & Überwachung
Wir haben die 3-2-1-Regel implementiert:
- Mindestens 3 Kopien.
- Mindestens 2 verschiedene Speichertypen.
- Mindestens 1 Kopie muss irgendwo außerhalb aufbewahrt werden.
Außerdem haben wir einen Disaster Recovery-Plan erstellt und getestet. Informationen zur Überwachung finden Sie hier .
Anwendungsaktualisierungen
Wie Sie sehen, war die Infrastruktur nicht so einfach. Wir mussten es irgendwie aktualisieren. Ein gelegentliches Update sah aus wie:
- Bereite dich vor.
- Ran Migration.
- Webanwendungen aktualisieren.
- Aktualisieren Sie Backend-Anwendungen.
Alle logischen Schritte waren für Staging- / Preprod- / Productions-Umgebungen identisch, unterschieden sich jedoch im Detail geringfügig. Also haben wir PowerShell-Skripte mit OOP-Magie erstellt. Es war ein kontinuierlicher Prozess zur Verbesserung unserer CI / CD-Infrastruktur.
Fazit
| 2012 | 2014 |
|---|
| Server | 3 | 60 |
| RAM GB | 72 | 800 |
| SSD GB | 200 | 10.000 |
| MsSQL gb | 150 | 700 |
| MongoDB GB | 0 | 700 |
| Artikel pro Tag | 10.000 | 150.000 |
Es war eine erstaunliche Geschichte über den Umzug von 3 Desktop-PCs in eine zuverlässige Infrastruktur. Sei geduldig und mache Pläne.
PS