Kurze Bekanntschaft mit Kubernetes für Entwickler am Beispiel der Bereitstellung einer einfachen Vorlagenwebsite, deren Einrichtung für die Überwachung, Durchführung geplanter Jobs und Integritätsprüfungen (alle Quellcodes sind beigefügt)
-
Installieren Sie Kubernetes-
Installieren Sie die Benutzeroberfläche-
Starten Sie Ihre Anwendung im Cluster-
Hinzufügen benutzerdefinierter Metriken zur Anwendung-
Erfassung von Metriken durch Prometheus-
Metriken in Grafana anzeigen-
Geplante Aufgaben-
Fehlertoleranz-
Schlussfolgerungen-
Notizen-
ReferenzenInstallieren Sie Kubernetes
Nicht für Linux-Benutzer geeignet, müssen Sie Minikube verwenden- Haben Sie einen Docker-Desktop?
- Darin müssen Sie Kubernetes Single-Node-Cluster finden und aktivieren
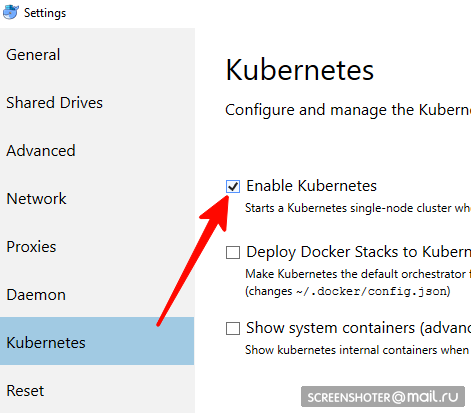
- Jetzt haben Sie api http: // localhost: 8001 / für die Arbeit mit kubernetis
- Die Kommunikation mit ihm erfolgt über ein praktisches Dienstprogramm kubectl
Überprüfen Sie die Version mit dem Befehl> kubectl version
Die neuesten relevanten Informationen finden Sie hier https://storage.googleapis.com/kubernetes-release/release/stable.txt
Sie können es unter dem entsprechenden Link https://storage.googleapis.com/kubernetes-release/release/v1.13.2/bin/windows/amd64/kubectl.exe herunterladen kubectl cluster-info dass der Cluster funktioniert> kubectl cluster-info
UI-Installation
- Die Schnittstelle wird im selben Cluster bereitgestellt
kubectl create -f https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended/kubernetes-dashboard.yaml
- Holen Sie sich ein Token, um auf die Schnittstelle zuzugreifen
kubectl describe secret
Und kopieren
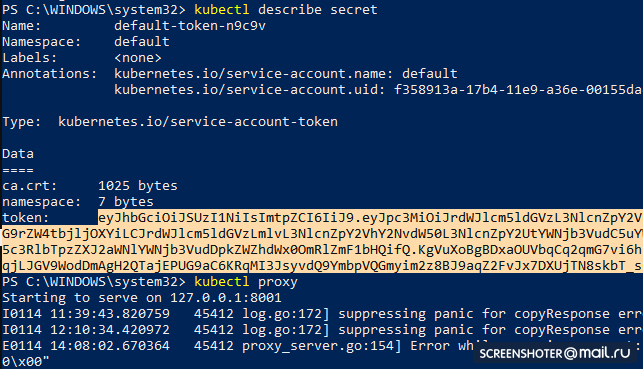
- Starten Sie nun den Proxy
kubectl proxy
- Und Sie können http: // localhost: 8001 / api / v1 / namespaces / kube-system / services / https: kubernetes-dashboard: / proxy / verwenden
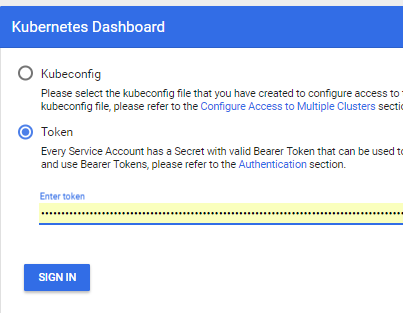
Ausführen Ihrer Anwendung in einem Cluster
- Ich habe über das Studio https://github.com/SanSYS/kuberfirst eine Standardanwendung für mvc netcoreapp2.1 erstellt
- Dockerfile:
FROM microsoft/dotnet:2.1-aspnetcore-runtime AS base WORKDIR /app EXPOSE 80 FROM microsoft/dotnet:2.1-sdk AS build WORKDIR /src COPY ./MetricsDemo.csproj . RUN ls RUN dotnet restore "MetricsDemo.csproj" COPY . . RUN dotnet build "MetricsDemo.csproj" -c Release -o /app FROM build AS publish RUN dotnet publish "MetricsDemo.csproj" -c Release -o /app FROM base AS final WORKDIR /app COPY --from=publish /app . ENTRYPOINT ["dotnet", "MetricsDemo.dll"]
- Sammelte dieses Ding mit dem Metricsdemo3-Tag
docker build -t metricsdemo3 .
- Aber! Coober zieht standardmäßig Bilder vom Hub, daher erhöhe ich das lokale Register
- Hinweis - Ich habe nicht versucht, in Kubernetis zu laufen
docker create -p 5000:5000 --restart always --name registry registry:2
- Und ich verschreibe es als autorisiert unsicher:
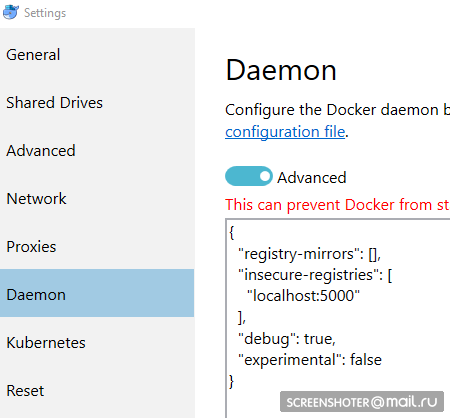
{ "registry-mirrors": [], "insecure-registries": [ "localhost:5000" ], "debug": true, "experimental": false }
- Bevor Sie in das Register drücken, noch ein paar Gesten
docker start registry docker tag metricsdemo3 localhost:5000/sansys/metricsdemo3 docker push localhost:5000/sansys/metricsdemo3
- Es wird ungefähr so aussehen:

Starten Sie über die Benutzeroberfläche
Wenn es startet, ist alles in Ordnung und Sie können den Betrieb aufnehmen
Erstellen Sie eine Bereitstellungsdatei
1-deploy-app.yaml kind: Deployment apiVersion: apps/v1 metadata: name: metricsdemo labels: app: web spec: replicas: 2
Kleine Beschreibung
- Art - Gibt an, welcher Entitätstyp in der yaml-Datei beschrieben wird
- apiVersion - Auf welche API wird das Objekt übertragen?
- Beschriftungen - im Wesentlichen nur Beschriftungen (Tasten links und Werte können Sie sich selbst ausdenken)
- Selektor - Ermöglicht das Verknüpfen von Diensten mit der Bereitstellung, z. B. über Labels
Weiter:
kubectl create -f .\1-deployment-app.yaml
Und Sie sollten Ihre Bereitstellung in der Schnittstelle
http: // localhost: 8001 / api / v1 / namespaces / kube-system / services / https: kubernetes-dashboard: / proxy / #! / Deployment? Namespace = default sehenIn diesem befindet sich ein Replikatsatz, der anzeigt, dass die Anwendung in zwei Instanzen (Pods) ausgeführt wird, und dass es einen verwandten Dienst mit einer Adresse von außen gibt, um eine synchronisierte Anwendung im Browser zu öffnen
Hinzufügen benutzerdefinierter Metriken zur Anwendung
Das Paket
https://www.app-metrics.io/ wurde zur Anwendung hinzugefügt
Ich werde vorerst nicht im Detail beschreiben, wie ich sie hinzufügen werde - ich registriere die Middleware zum Inkrementieren der Zähler von Aufrufen zu den API-Methoden
Hier ist die Middleware private static void AutoDiscoverRoutes(HttpContext context) { if (context.Request.Path.Value == "/favicon.ico") return; List<string> keys = new List<string>(); List<string> vals = new List<string>(); var routeData = context.GetRouteData(); if (routeData != null) { keys.AddRange(routeData.Values.Keys); vals.AddRange(routeData.Values.Values.Select(p => p.ToString())); } keys.Add("method"); vals.Add(context.Request.Method); keys.Add("response"); vals.Add(context.Response.StatusCode.ToString()); keys.Add("url"); vals.Add(context.Request.Path.Value); Program.Metrics.Measure.Counter.Increment(new CounterOptions { Name = "api",
Die gesammelten Metriken sind unter
http: // localhost: 9376 /metrics verfügbar

* IMetricRoot oder seine Abstraktion kann einfach in Diensten registriert und in der Anwendung verwendet werden (
services.AddMetrics (Program.Metrics); )
Metriksammlung durch Prometheus
Die grundlegendste Prometheus-Einstellung: Fügen Sie der Konfiguration (prometheus.yml) einen neuen Job hinzu und geben Sie ihm ein neues Ziel:
global: scrape_interval: 15s evaluation_interval: 15s rule_files:
Prometheus bietet jedoch native Unterstützung für das Sammeln von Metriken aus kubernetis
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_configIch möchte jeden Dienst einzeln filtern und nach Apptyp filtern: Geschäftslabel
Nachdem Sie sich mit dem Dock vertraut gemacht haben, gehen Sie wie folgt vor:
- job_name: business-metrics
In kubernetis gibt es einen speziellen Ort zum Speichern von Konfigurationsdateien -
ConfigMapIch speichere diese Konfiguration dort:
2-prometheus-configmap.yaml apiVersion: v1 kind: ConfigMap
Abfahrt nach Kubernetis
kubectl create -f .\2-prometheus-configmap.yaml
Jetzt müssen Sie prometheus mit dieser Konfigurationsdatei bereitstellen
kubectl create -f. \ 3-deploy-prometheus.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: prometheus namespace: default spec: replicas: 1 template: metadata: labels: app: prometheus-server spec: containers: - name: prometheus image: prom/prometheus args: - "--config.file=/etc/config/prometheus.yml" - "--web.enable-lifecycle" ports: - containerPort: 9090 volumeMounts: - name: prometheus-config-volume
Achtung - die Datei prometheus.yml ist nirgendwo angegeben
Alle Dateien, die in der Konfigurationszuordnung angegeben wurden, werden zu Dateien im Abschnitt prometheus-config-volume, der im Verzeichnis / etc / config / bereitgestellt wird
Außerdem verfügt der Container über Startargumente mit dem Pfad zur Konfiguration
--web.enable-lifecycle - sagt, dass Sie POST / - / reload aufrufen können, wodurch neue Konfigurationen angewendet werden (nützlich, wenn sich die Konfiguration "on the fly" ändert und Sie den Container nicht neu starten möchten).
Eigentlich bereitstellen
kubectl create -f .\3-deployment-prometheus.yaml
Befolgen Sie die kleinen Schritte und gehen Sie zur Adresse
http: // localhost: 9090 / Ziele . Dort sollten Sie die Endpunkte Ihres Dienstes sehen
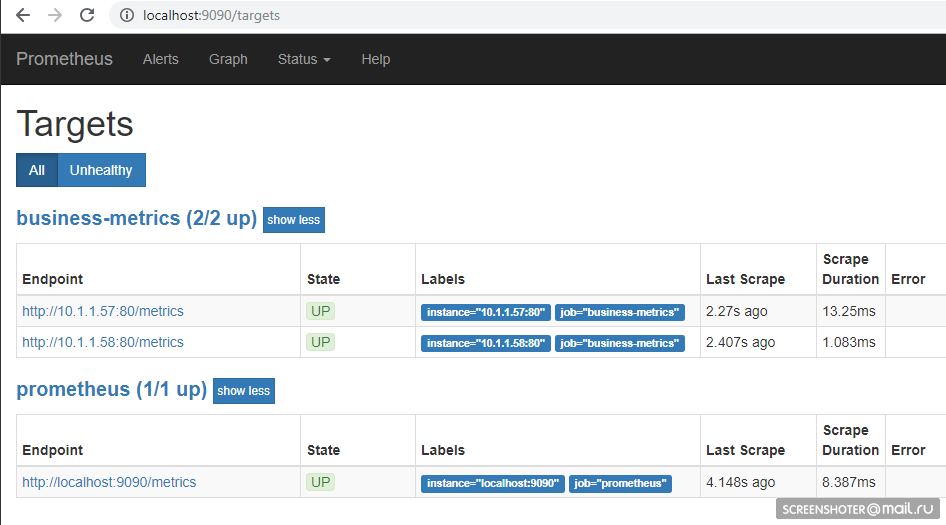
Und auf der Hauptseite können Sie Anfragen an den Prometheus schreiben
sum by (response, action, url, app) (delta(application_api[15s]))
Vorausgesetzt, jemand hat die Site besucht, wird es so ausfallen Abfragesprache -
https://prometheus.io/docs/prometheus/latest/querying/basics/Metriken in Grafana anzeigen
Wir hatten Glück - bis Version 5 konnten Dashboard-Konfigurationen nur über die HTTP-API übertragen werden, aber jetzt können Sie den gleichen Trick wie mit Prometeus ausführen
Grafana
kann beim Start standardmäßig
Datenquellenkonfigurationen und Dashboards
aufrufen/etc/grafana/provisioning/datasources/ - Quellkonfigurationen (Einstellungen für den Zugriff auf Prometeus, Postgres, Zabbiks, Gummiband usw.)/etc/grafana/provisioning/dashboards/ - /etc/grafana/provisioning/dashboards/ Zugriffseinstellungen/var/lib/grafana/dashboards/ - hier werde ich die Dashboards selbst in Form von JSON-Dateien speichern
Es stellte sich so heraus apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: grafana-provisioning-datasources namespace: default data: all.yml: | datasources: - name: 'Prometheus' type: 'prometheus' access: 'proxy' org_id: 1 url: 'http://prometheus:9090' is_default: true version: 1 editable: true --- apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: grafana-provisioning-dashboards namespace: default data: all.yml: | apiVersion: 1 providers: - name: 'default' orgId: 1 folder: '' type: file disableDeletion: false updateIntervalSeconds: 10
Bereitstellung selbst, nichts Neues apiVersion: extensions/v1beta1 kind: Deployment metadata: name: grafana namespace: default labels: app: grafana component: core spec: replicas: 1 template: metadata: labels: app: grafana component: core spec: containers: - image: grafana/grafana name: grafana imagePullPolicy: IfNotPresent resources: limits: cpu: 100m memory: 100Mi requests: cpu: 100m memory: 100Mi env: - name: GF_AUTH_BASIC_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin readinessProbe: httpGet: path: /login port: 3000
Erweitern
kubectl create -f .\4-grafana-configmap.yaml kubectl create -f .\5-deployment-grafana.yaml
Denken Sie daran, dass der Graphan nicht sofort steigt, sondern durch SQLite-Migrationen, die Sie
in den Protokollen sehen können, etwas gedämpft wird
Gehen Sie jetzt zu
http: // localhost: 3000 /Und klicken Sie auf das Dashboard
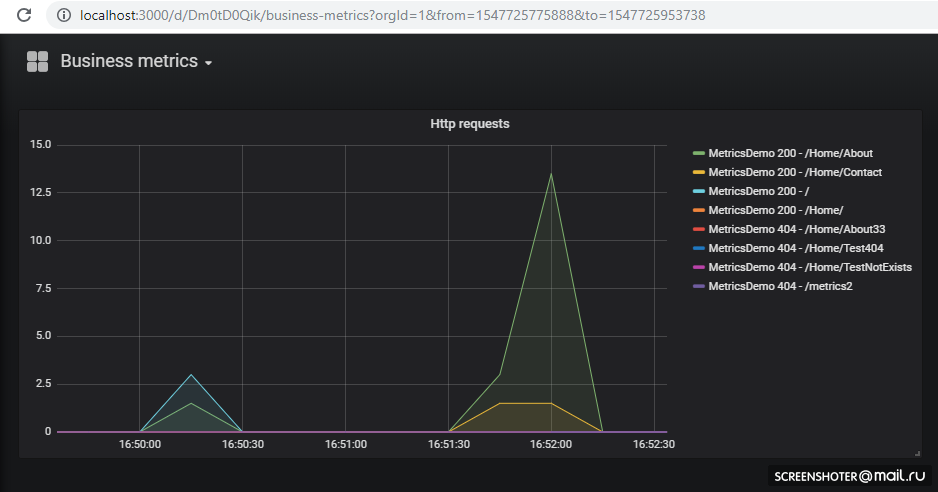
Wenn Sie eine neue Ansicht hinzufügen oder eine vorhandene ändern möchten - ändern Sie sie direkt in der Benutzeroberfläche und klicken Sie dann auf Speichern. Sie erhalten ein modales Fenster mit json, das Sie in die Konfigurationszuordnung einfügen müssen
Alles ist bereitgestellt und funktioniert hervorragend Geplante Aufgaben
Um Aufgaben an der Krone im Cuber auszuführen, gibt es das Konzept von CronJob
Mit CronJob können Sie einen Zeitplan für jede Aufgabe festlegen. Das einfachste Beispiel:
Der Zeitplanabschnitt legt die klassische Regel für die Krone fest
Der Trigger startet den Pod des Containers (Busybox), in dem ich die Metrikdemo-Service-API-Methode abrufe
Mit dem Befehl können Sie den Job verfolgen.
kubectl.exe get cronjob runapijob --watch
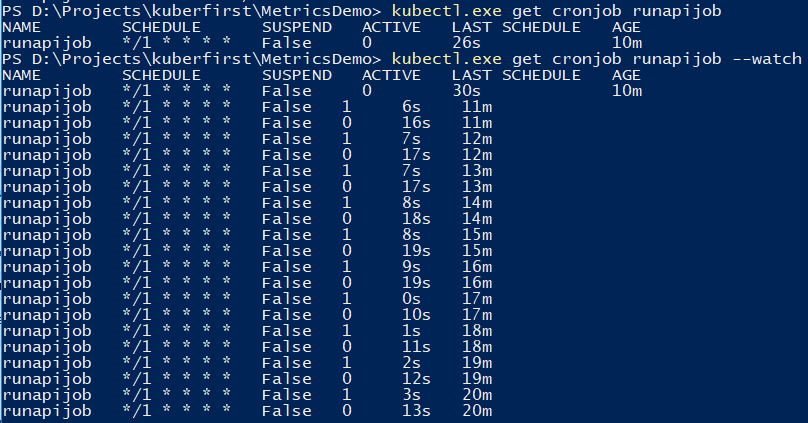
Der Hauptdienst, der aus dem Job ruckelt, wird in mehreren Fällen gestartet, da der Anruf an den Dienst mit einer ungefähr gleichmäßigen Verteilung an einen der Herde geht
Wie es in Prometheus aussieht Um den Job zu debuggen, können Sie ihn manuell auslösen Eine kleine Demo am Beispiel der Berechnung der Anzahl von π über den Unterschied bei den Starts von der Konsole aus
Fehlertoleranz
Wenn die Anwendung unerwartet beendet wird, startet der Cluster den Pod neu
Zum Beispiel habe ich eine Methode erstellt, mit der API gelöscht wird
[HttpGet("kill/me")] public async void Kill() { throw new Exception("Selfkill"); }
* Die Ausnahme, die in der API bei der asynchronen Void-Methode aufgetreten ist, wird als nicht behandelte Ausnahme betrachtet, die die Anwendung vollständig zum Absturz bringtIch appelliere an
http: // localhost: 9376 / api / job / kill / meDie Liste der Herde zeigt, dass einer der Herde des Dienstes neu gestartet wurde
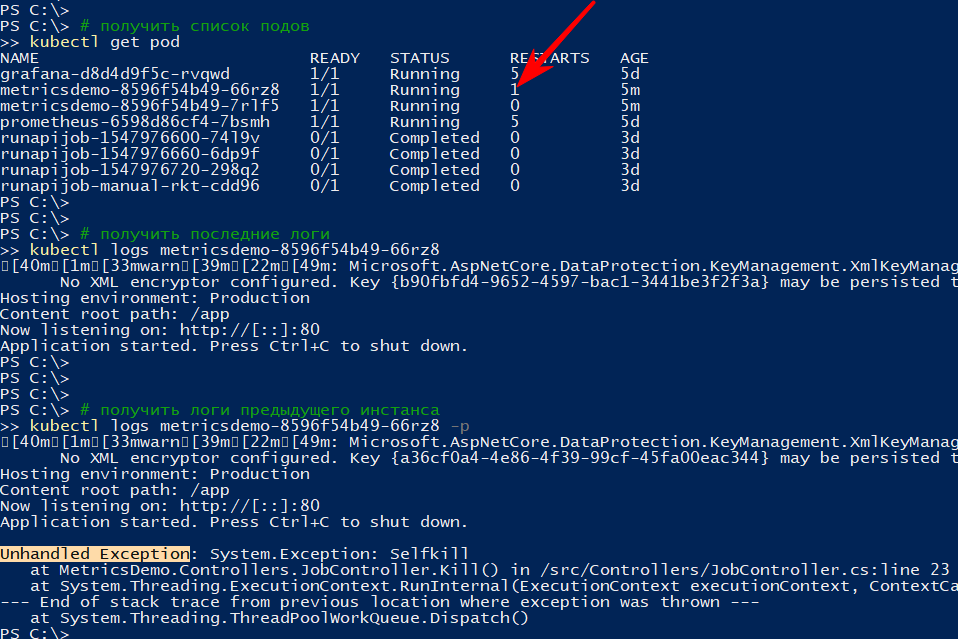
Der Befehl logs zeigt die aktuelle Ausgabe an und mit der Option -p werden die Protokolle der vorherigen Instanz angezeigt. Auf diese Weise können Sie den Grund für den Neustart herausfinden.
Ich denke mit einem einfachen Sturz ist alles klar: fiel - Rose
Die Anwendung kann jedoch bedingt live sein, d.h. nicht gefallen, aber nichts zu tun oder seinen Job zu machen, aber langsam
Gemäß der
Dokumentation gibt es mindestens zwei Arten von Überlebensprüfungen von Anwendungen in Pods
- Bereitschaft - Diese Art der Überprüfung wird verwendet, um zu verstehen, ob es möglich ist, den Verkehr auf diesem Pod zu starten. Wenn nicht, wird der Pod dereguliert, bis er wieder normal ist.
- Lebendigkeit - Überprüfen Sie den Antrag "auf Überlebensfähigkeit". Insbesondere wenn kein Zugriff auf eine wichtige Ressource besteht oder die Anwendung überhaupt nicht reagiert (z. B. Deadlock und daher Zeitüberschreitung), wird der Container neu gestartet. Alle http-Codes zwischen 200 und 400 gelten als erfolgreich, der Rest schlägt fehl
Ich werde den Neustart nach Zeitüberschreitung überprüfen. Dazu werde ich eine neue API-Methode hinzufügen, die nach einem bestimmten Befehl die Methode zur Überprüfung der Überlebensfähigkeit für 123 Sekunden verlangsamt
static bool deadlock; [HttpGet("alive/{cmd}")] public string Kill(string cmd) { if (cmd == "deadlock") { deadlock = true; return "Deadlocked"; } if (deadlock) Thread.Sleep(123 * 1000); return deadlock ? "Deadlocked!!!" : "Alive"; }
Ich füge der Datei 1-deploy-app.yaml im Container einige Abschnitte hinzu:
containers: - name: metricsdemo image: localhost:5000/sansys/metricsdemo3:6 ports: - containerPort: 80 readinessProbe:
Ich bin mir sicher, dass die App gestartet wurde und Ereignisse abonniert
kubectl get events --watch
Ich drücke auf das Menü Deadlock me (
http: // localhost: 9376 / api / job / living / deadlock )

Und innerhalb von fünf Sekunden beginne ich, das Problem und seine Lösung zu beobachten
1s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 1s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 0s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 0s Warning Unhealthy Pod Readiness probe failed: Get http://10.1.0.137:80/health: dial tcp 10.1.0.137:80: connect: connection refused 0s Normal Killing Pod Killing container with id docker://metricsdemo:Container failed liveness probe.. Container will be killed and recreated. 0s Normal Pulled Pod Container image "localhost:5000/sansys/metricsdemo3:6" already present on machine 0s Normal Created Pod Created container 0s Normal Started Pod Started container
Schlussfolgerungen
- Einerseits stellte sich heraus, dass die Eintrittsschwelle viel niedriger war als ich dachte, andererseits handelt es sich überhaupt nicht um einen echten Kubernetes-Cluster, sondern nur um einen Entwicklercomputer. Und die Grenzen für Ressourcen, Stateful Applications, A / B-Tests usw. wurden nicht berücksichtigt.
- Prometeus hat es zum ersten Mal versucht, aber das Lesen verschiedener Dokumente und Beispiele während der Überprüfung des Cuber hat deutlich gemacht, dass es sehr gut zum Sammeln von Metriken aus dem Cluster und den Anwendungen geeignet ist
- Es ist so gut, dass der Entwickler eine Funktion auf seinem Computer implementieren und zusätzlich zu den Informationen zur Bereitstellung die Bereitstellung des Zeitplans an den Graphan anhängen kann. Infolgedessen werden neue Metriken automatisch ohne zusätzliche Metriken erstellt. Die Bemühungen werden auf der Bühne und auf dem Produkt gezeigt. Bequem
Anmerkungen
- Anwendungen können sich unter dem
: kontaktieren : , was mit grafana → prometeus gemacht wurde. Für diejenigen, die mit Docker-Compose vertraut sind, gibt es nichts Neues kubectl create -f file.yml - Erstelle eine Entitätkubectl delete -f file.yml - löscht eine Entitätkubectl get pod - kubectl get pod sich eine Liste aller Herde (Service, Endpunkte ...)--namespace=kube-system - Filtern nach Namespace-n kube-system - ähnlich
kubectl -it exec grafana-d8d4d9f5c-cvnkh -- /bin/bash - Anhang an der Unterseitekubectl delete service grafana - lösche einen service, pod. Bereitstellung (--all - alle löschen)kubectl describe - beschreiben Sie die Entität (Sie können alles auf einmal tun)kubectl edit service metricsdemo - Bearbeiten Sie alle Yamls im Handumdrehen durch den Start des Notepadskubectl --help - große Hilfe)- Ein typisches Problem ist, dass es einen Pod gibt (betrachten Sie das laufende Image), etwas schief gelaufen ist und es keine Optionen gibt, außer es gibt keine Möglichkeit, darin zu debuggen (über tcpdump / nc usw.). - Yuzai kubectl-debug habr.com/de/company/flant/blog/436112
Referenzliste
- Was sind App-Metriken?
- Kubernetes
- Prometheus
- Vorbereitete Grafana-Konfiguration
- Um zu sehen, wie es den Leuten geht (aber es gibt bereits einige Dinge, die veraltet sind) - im Prinzip geht es auch um Protokollierung, Warnungen usw.
- Helm - Der Paketmanager für Kubernetes - dadurch war es einfacher, prometeus + grafana zu organisieren, aber manuell - es erscheint mehr Verständnis
- Würfel für Prometheus von Coober
- Kubernetes-Fehlergeschichten
- Kubernetes-HA. Stellen Sie den Kubernetes-Failovercluster mit 5 Assistenten bereit
 Quellcode und Marmeladen auf Github verfügbar
Quellcode und Marmeladen auf Github verfügbar