Wir sprechen weiterhin über gemeinsame Forschungsprojekte zwischen unseren Studenten und JetBrains Research. In diesem Artikel werden wir über Verstärkungs-Deep-Learning-Algorithmen sprechen, die zur Simulation des menschlichen Motorapparats verwendet werden.
Es ist eine ziemlich schwierige Aufgabe, alle möglichen menschlichen Bewegungen zu simulieren und alle Verhaltensszenarien zu beschreiben. Wenn wir verstehen lernen, wie sich eine Person bewegt, und ihre Bewegungen „im Bild und in der Ähnlichkeit“ reproduzieren können, wird dies die Einführung von Robotern in vielen Bereichen erheblich erleichtern. Nur damit die Roboter lernen, die Bewegungen selbst zu wiederholen und zu analysieren, wird maschinelles Lernen angewendet.

Über mich
Mein Name ist Alexandra Malysheva, ich habe einen Bachelor-Abschluss in Angewandter Mathematik und Informatik an der St. Petersburg Academic University und seit Herbst dieses Jahres bin ich eine Doktorandin im ersten Jahr an der St. Petersburg HSE in Programmierung und Datenanalyse. Darüber hinaus arbeite ich im Labor für Agentensysteme und verstärktes Lernen, JetBrains Research, und leite Kurse - Vorlesungen und Praktiken - im Bachelor-Programm der HSE in St. Petersburg.
Im Moment arbeite ich an mehreren Projekten im Bereich Deep Learning mit Verstärkung (wir haben im vorherigen Artikel darüber gesprochen). Und heute möchte ich mein erstes Projekt zeigen, das reibungslos aus meiner Diplomarbeit hervorgegangen ist.
Aufgabenbeschreibung

Um den menschlichen Motorapparat zu simulieren, werden spezielle Umgebungen geschaffen, die versuchen, die physische Welt so genau wie möglich zu simulieren, um ein bestimmtes Problem zu lösen. Der
NIPS 2017- Wettbewerb konzentrierte sich beispielsweise auf die Entwicklung eines humanoiden Roboters, der das Gehen von Menschen simuliert.
Um dieses Problem zu lösen, werden normalerweise Methoden des tiefen Lernens mit Verstärkung verwendet, die zu einer guten, aber nicht optimalen Strategie führen. Außerdem ist die Trainingszeit in den meisten Fällen zu lang.
Wie im
vorherigen Artikel richtig erwähnt, besteht das Hauptproblem beim Übergang von fiktiven / einfachen Aufgaben zu realen / praktischen Aufgaben darin, dass Belohnungen bei solchen Problemen normalerweise sehr selten sind. Zum Beispiel können wir den Durchgang einer langen Strecke nur dann bewerten, wenn der Agent die Ziellinie erreicht hat. Dazu muss er eine komplexe und korrekte Abfolge von Aktionen ausführen, was nicht immer der Fall ist. Dieses Problem kann gelöst werden, indem dem Agenten zu Beginn Beispiele für das „Spielen“ gegeben werden - die sogenannten Expertendemonstrationen.
Ich habe diesen Ansatz verwendet, um dieses Problem zu lösen. Es stellte sich heraus, dass sich die Qualität des Trainings erheblich verbessert. Wir können Videos verwenden, die die Bewegungen einer Person beim Laufen zeigen. Insbesondere können Sie versuchen, die Koordinaten der Bewegung bestimmter Körperteile (z. B. Füße) aus einem Video auf YouTube zu verwenden.
Die Umwelt
Bei Lernaufgaben zur Verstärkung wird die Interaktion des Agenten und der Umgebung berücksichtigt. Eine der modernen Umgebungen zur Modellierung des menschlichen Motorapparats ist die OpenSim-Simulationsumgebung unter Verwendung der Simbody-Physik-Engine.
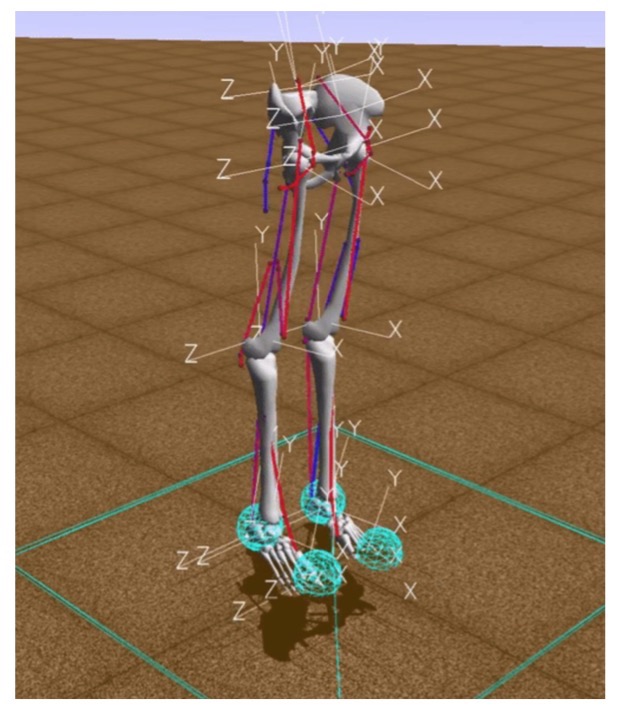
In dieser Umgebung ist „Umgebung“ eine dreidimensionale Welt mit Hindernissen, „Agent“ ist ein humanoider Roboter mit sechs Gelenken (Knöchel, Knie und Hüften auf zwei Beinen) und Muskeln, die das Verhalten menschlicher Muskeln simulieren, und „Agentenaktion“ reale Werte von 0 bis 1, die die Spannung der vorhandenen Muskeln angeben.
Die Belohnung wird berechnet als die Änderung der Position des Beckens entlang der x-Achse abzüglich der Strafe für die Verwendung von Bändern. Auf der einen Seite müssen Sie also in einer bestimmten Zeit so weit wie möglich gehen und auf der anderen Seite Ihre Muskeln so wenig wie möglich arbeiten lassen. Die Trainingsepisode endet, wenn entweder 1000 Iterationen erreicht werden oder die Beckenhöhe unter 0,65 Metern liegt, was bedeutet, dass das Modell der Person fällt.
Basisimplementierung
Das Hauptziel des Verstärkungstrainings besteht darin, dem Roboter beizubringen, sich schnell und effizient in der Umgebung zu bewegen.
Um die Hypothese zu testen, ob das Lernen in Demonstrationen hilfreich ist, musste ein grundlegender Algorithmus implementiert werden, der wie viele vorhandene Beispiele lernen würde, schnell, aber suboptimal zu laufen.
Dazu haben wir einige Tricks angewendet:
- Zunächst musste die OpenSim-Umgebung angepasst werden, um Verstärkungslernalgorithmen effektiv einsetzen zu können. Insbesondere haben wir in der Beschreibung der Umgebung zweidimensionale Koordinaten der Positionen der Körperteile relativ zum Becken hinzugefügt.
- Die Anzahl der Beispiele für das Überqueren der Distanz aufgrund der Symmetrie des Mediums wurde erhöht. In der Ausgangsposition ist das Mittel absolut symmetrisch zur linken und rechten Körperseite. Daher können Sie nach einer Entfernung zwei Beispiele gleichzeitig hinzufügen: das aufgetretene und den Spiegel, der relativ zur linken oder rechten Seite des Körpers des Agenten symmetrisch ist.
- Um die Geschwindigkeit des Algorithmus zu erhöhen, wurden Frames übersprungen: Der Algorithmus zur Auswahl der nächsten Agentenaktion wurde nur jede dritte Iteration gestartet, in anderen Fällen wurde die zuletzt ausgewählte Aktion wiederholt. Somit wurde die Anzahl der Iterationen des Starts des Agentenaktionsauswahlalgorithmus von 1000 auf 333 reduziert, was die Anzahl der erforderlichen Berechnungen reduzierte.
- Frühere Änderungen haben das Lernen deutlich beschleunigt, aber der Lernprozess war immer noch langsam. Daher wurde zusätzlich eine Beschleunigungsmethode implementiert, die mit einer Verringerung der Genauigkeit der Berechnungen verbunden ist: Die Art der im Agentenzustandsvektor verwendeten Werte wurde von double auf float geändert.

Diese Grafik zeigt die Verbesserung nach jeder der oben beschriebenen Optimierungen. Sie zeigt die Belohnung, die für eine Ära ab dem Zeitpunkt des Trainings erhalten wurde.
Was hat YouTube damit zu tun?
Nach der Entwicklung des Basismodells haben wir die Belohnungsgenerierung basierend auf der potenziellen Funktion hinzugefügt. Eine mögliche Funktion wird eingeführt, um dem Roboter nützliche Informationen über die Welt um uns herum zu geben: Wir sagen, dass einige Körperpositionen, die der laufende Charakter im Video einnahm, „profitabler“ sind (dh er erhält eine größere Belohnung für sie) als andere.
Wir haben die Funktion auf der Grundlage von Videodaten erstellt, die aus YouTube-Videos stammen und den Ablauf realer Personen und menschlicher Charaktere von Cartoons und Computerspielen darstellen. Die gesamte potentielle Funktion wurde als die Summe der potentiellen Funktionen für jeden Körperteil definiert: das Becken, zwei Knie und zwei Füße. Nach dem potenziellbasierten Ansatz zur Bildung der Vergütung erhält der Agent bei jeder Iteration des Algorithmus eine zusätzliche Vergütung, die einer Änderung der Potenziale des vorherigen und aktuellen Zustands entspricht. Die möglichen Funktionen einzelner Körperteile wurden unter Verwendung der inversen Abstände zwischen der entsprechenden Koordinate des Körperteils in den videogenerierten Daten und dem humanoiden Roboter konstruiert.
Wir haben drei Datenquellen untersucht:
 Becker Alan. Animierende Laufzyklen - 2010
Becker Alan. Animierende Laufzyklen - 2010 ProcrastinatorPro. QWOP Speedrun - 2010
ProcrastinatorPro. QWOP Speedrun - 2010 ShvetsovLeonid.HumanSpeedrun - 2015
ShvetsovLeonid.HumanSpeedrun - 2015... und drei verschiedene Distanzfunktionen:
Hier ist dx (dy) die absolute Differenz zwischen der x (y) -Koordinate der entsprechenden Körperteile aus den Videodaten und der x (y) -Koordinate des Agenten.
Das Folgende sind die Ergebnisse, die durch Vergleichen verschiedener Datenquellen für eine mögliche Funktion basierend auf PF2 erhalten wurden:

Ergebnisse
Vergleich der Produktivität zwischen dem Basisniveau und dem Ansatz zur Bildung der Vergütung:

Es stellte sich heraus, dass die Bildung von Vergütungen das Lernen erheblich beschleunigt und in 12 Stunden Training die doppelte Geschwindigkeit erreicht. Das Endergebnis nach 24 Stunden zeigt immer noch einen signifikanten Vorteil des Ansatzes unter Verwendung der Methode potenzieller Funktionen.
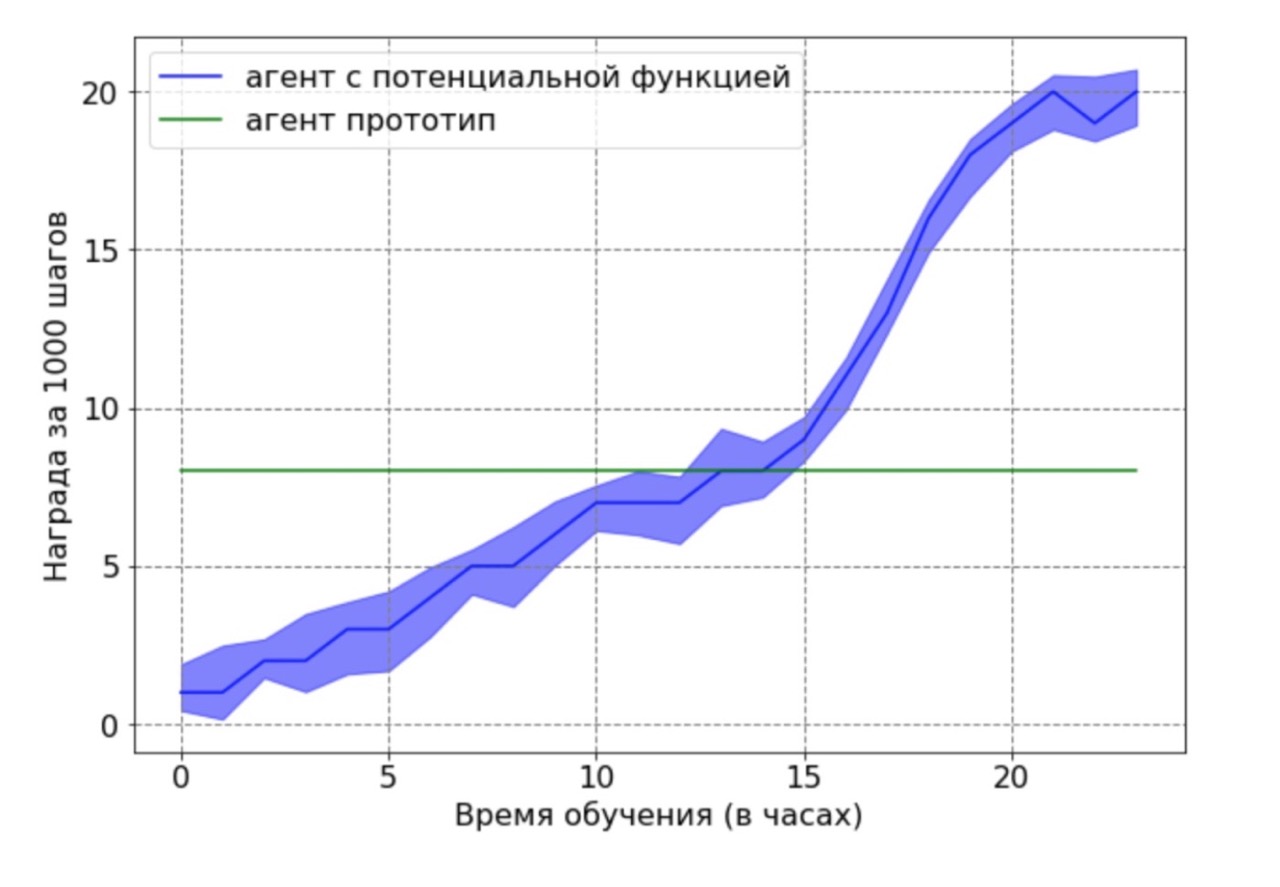
Unabhängig davon möchte ich das folgende wichtige Ergebnis festhalten: Wir konnten theoretisch nachweisen, dass eine Vergütung auf der Grundlage einer potenziellen Funktion eine optimale Politik nicht verschlechtert. Um diesen Vorteil in diesem Zusammenhang zu demonstrieren, haben wir einen suboptimalen Agenten verwendet, der vom Basisagenten nach 12 Stunden Training generiert wurde. Der resultierende Prototyp-Agent wurde als Datenquelle für eine mögliche Funktion verwendet. Offensichtlich funktioniert das mit diesem Ansatz erhaltene Mittel nicht optimal, und die Positionen der Füße und Knie befinden sich in den meisten Fällen nicht in optimalen Positionen. Dann wurde der durch den DDPG-Algorithmus unter Verwendung der Potentialfunktion trainierte Agent auf die erhaltenen Daten trainiert. Als nächstes wurde ein Vergleich der Lernergebnisse eines Agenten mit einer möglichen Funktion mit einem Prototyp-Agenten durchgeführt. Der Agententrainingsplan zeigt, dass der RL-Agent die suboptimale Leistung der Datenquelle überwinden kann.
Erste Schritte in der Wissenschaft
Ich habe das Abschlussprojekt ziemlich früh beendet. Ich möchte darauf hinweisen, dass wir einen sehr verantwortungsvollen Ansatz zum Schutz eines Diploms verfolgen. Seit September kennen die Studierenden das Thema, die Bewertungskriterien, was und wann zu tun ist. Wenn alles so klar ist, dass es sehr bequem ist zu arbeiten, gibt es kein Gefühl "Ich habe ein ganzes Jahr vor mir, ich kann nächste Woche / Monat / sechs Monate damit beginnen". Wenn Sie effizient arbeiten, können Sie die endgültigen Ergebnisse der Arbeit bis zum neuen Jahr erhalten und die verbleibende Zeit damit verbringen, das Modell zu erstellen, statistisch signifikante Ergebnisse zu sammeln und den Text des Diploms zu schreiben. Genau das ist mir passiert.
Zwei Monate vor der Verteidigung des Diploms hatte ich bereits den Text der Arbeit fertig, und mein wissenschaftlicher Berater, Aleksey Aleksandrovich Shpilman, schlug vor, einen Artikel über den
Workshop über adaptive und lernende Mittel (ALA) bei ICML-AAMAS zu schreiben. Ich musste nur meine These übersetzen und neu verpacken. Als Ergebnis haben wir einen Artikel zur Konferenz geschickt und ... er wurde angenommen! Dies war meine erste Veröffentlichung und ich war äußerst glücklich, als ich einen Brief mit dem Wort "Akzeptiert" in meiner Mail sah. Leider habe ich gleichzeitig in Südkorea trainiert und konnte nicht persönlich an der Konferenz teilnehmen.
Neben der
Veröffentlichung und Anerkennung der geleisteten Arbeit brachte mir die erste Konferenz ein weiteres angenehmes Ergebnis. Alexey Alexandrovich begann mich anzulocken, eine Rezension über die Arbeit anderer Leute zu schreiben. Dies scheint mir sehr nützlich zu sein, um Erfahrungen bei der Bewertung neuer Ideen zu sammeln: Auf diese Weise können Sie lernen, vorhandene Arbeiten zu analysieren und die Idee auf Originalität und Relevanz zu überprüfen.
Einen Artikel über den Workshop zu schreiben ist gut, aber auf der Hauptstrecke ist es besser
Nach Korea bekam ich ein Praktikum bei JetBrains Research und arbeitete weiter an dem Projekt. Zu diesem Zeitpunkt haben wir drei verschiedene Formeln auf eine mögliche Funktion getestet und einen Vergleich durchgeführt. Wir wollten unbedingt die Ergebnisse unserer Arbeit teilen und haben uns daher entschlossen, einen vollständigen Artikel auf der
ICARCV- Hauptkonferenz in Singapur zu schreiben.
Einen Artikel in einem Workshop zu schreiben ist gut, aber auf einer Hauptstrecke ist es besser. Und natürlich war ich sehr froh, als ich herausfand, dass der Artikel angenommen wurde! Darüber hinaus haben unsere Kollegen und Sponsoren von JetBrains zugestimmt, meine Reise zur Konferenz zu bezahlen. Ein großer Bonus war die Gelegenheit, Singapur kennenzulernen.
Als die Tickets bereits gekauft waren, das Hotel gebucht war und ich nur ein Visum bekommen konnte, erhielt ich einen Brief per Post:

Ich erhielt kein Visum, obwohl ich Dokumente hatte, die meine Rede auf der Konferenz bestätigten! Es stellt sich heraus, dass die Botschaft von Singapur keine Bewerbungen von unverheirateten und arbeitslosen Mädchen unter 35 Jahren akzeptiert. Und selbst wenn das Mädchen arbeitet, aber nicht verheiratet ist, ist die Chance, eine Ablehnung zu erhalten, immer noch sehr groß.
Glücklicherweise habe ich erfahren, dass Bürger der Russischen Föderation, die auf der Durchreise sind, bis zu 96 Stunden in Singapur bleiben können. Infolgedessen flog ich über Singapur nach Malaysia, wo ich insgesamt fast acht Tage verbrachte. Die Konferenz selbst dauerte sechs Tage. Aufgrund von Einschränkungen nahm ich an den ersten vier teil, dann musste ich gehen, um zum Schließen zurückzukehren. Nach der Konferenz beschloss ich, mich wie ein Tourist zu fühlen und ging zwei Tage lang durch die Stadt und besuchte Museen.
Ich habe im Voraus eine Rede bei ICARCV in St. Petersburg vorbereitet. Probte es in einem Workshop zum Verstärkungstraining ein. Daher war das Sprechen auf der Konferenz aufregend, aber nicht beängstigend. Die Präsentation selbst dauerte 15 Minuten, aber danach gab es einen Abschnitt mit Fragen, die mir sehr nützlich erschienen.
Mir wurden einige interessante Fragen gestellt, die zu neuen Ideen führten. Zum Beispiel darüber, wie wir die Daten markiert haben. In unserer Arbeit haben wir die Daten manuell markiert und es wurde uns angeboten, eine Bibliothek zu verwenden, die automatisch versteht, wo sich Teile des menschlichen Körpers befinden. Jetzt haben wir gerade damit begonnen, diese Idee umzusetzen. Sie können die ganze Arbeit
hier lesen.
Bei ICARCV habe ich gerne mit Wissenschaftlern kommuniziert und viele neue Ideen gelernt. Die Anzahl der interessanten Artikel, die ich in diesen wenigen Tagen getroffen habe, war höher als in den letzten vier Jahren. Jetzt gibt es einen „Hype“ für maschinelles Lernen in der Welt, und jeden Tag erscheinen Dutzende neuer Artikel im Internet, unter denen es sehr schwierig ist, etwas Wertvolles zu finden. Aus diesem Grund lohnt es sich meines Erachtens, Konferenzen zu besuchen: Gemeinschaften zu finden, die neue interessante Themen diskutieren, neue Ideen kennenlernen und ihre eigenen teilen. Und Freunde finden!