Hallo! Mein Name ist Ivan Davydov, ich beschäftige mich mit Leistungsforschung in Yandex.Money.
Stellen Sie sich vor, Sie haben leistungsstarke Server, auf denen jeweils eine Reihe von Anwendungen gehostet werden. Wenn es nicht sehr viele davon gibt, stören sie sich nicht gegenseitig in der Arbeit - sie sind bequem und gemütlich. Sobald Sie zu Microservices kommen und einen Teil der "schweren" Funktionalität in separaten Anwendungen ausschalten.
Hier können Sie sich mitreißen lassen, und es wird zu viele Microservices geben, wodurch es schwierig wird, sie zu verwalten und ihre Fehlertoleranz sicherzustellen. Infolgedessen werden ein Dutzend Anwendungen, die um gemeinsam genutzte Ressourcen kämpfen, auf jedem Server "gebündelt". Es wird sich als "große Familie" herausstellen, aber in einer großen Familie klicken Sie nicht mit Ihrem Schnabel!
Einmal haben wir uns auch damit konfrontiert. Meine Geschichte handelt von schweren und schlaflosen Nächten, in denen ich nachts unter einer Lampe saß und auf den Stoß schoss. Alles begann mit der Tatsache, dass wir Netzwerkprobleme auf den Kampfservern bemerkten.
Sie haben die Leistung stark beeinflusst und erhebliche Drawdowns erzielt. Gleichzeitig stellte sich heraus, dass bei einem regulären Benutzerstrom dieselben Fehler auftreten, jedoch in viel geringerem Umfang.
Das Problem lag in der Auslastung der TCP-Sockets um mehr als 100%. Dies geschieht, wenn alle Sockets auf den Servern ständig geöffnet und geschlossen werden. Aus diesem Grund treten Netzwerkprobleme bei der Interaktion zwischen Anwendungen auf und es treten verschiedene Arten von Fehlern auf - der Remote-Host ist nicht verfügbar, die HTTP / HTTPS-Verbindung (Zeitlimit für Verbindung / Lesen, SSL-Peer wurde falsch heruntergefahren) und andere sind unterbrochen.
Selbst wenn Sie keinen eigenen elektronischen Zahlungsdienst haben, ist es nicht sehr schwierig, das Ausmaß der Schmerzen bei einem nächsten Verkauf einzuschätzen. Der Datenverkehr nimmt um ein Vielfaches zu, und Leistungseinbußen können zu erheblichen Verlusten führen. Wir sind also zu zwei Schlussfolgerungen gekommen: Wir müssen bewerten, wie die aktuellen Kapazitäten genutzt werden, und die Anwendungen voneinander isolieren.
Um Anwendungen zu isolieren, haben wir uns für die Containerisierung entschieden. Zu diesem Zweck haben wir einen Hypervisor verwendet, der viele separate Container mit Anwendungen enthält. Auf diese Weise können Sie die Ressourcen des Prozessors, des Speichers, der Eingabe- / Ausgabegeräte, der Netzwerke sowie der Prozessbäume, Benutzer, Dateisysteme usw. isolieren.
Bei diesem Ansatz verfügt jede Anwendung über eine eigene Umgebung, die Flexibilität, Isolation und Zuverlässigkeit bietet und die Gesamtsystemleistung verbessert. Dies ist eine schöne und elegante Lösung, aber vorher müssen Sie eine Reihe von Fragen beantworten:
- Welche Leistungsspanne hat eine Anwendungsinstanz derzeit?
- Wie ist die Anwendung skaliert und gibt es in der aktuellen Konfiguration Ressourcenredundanz?
- Ist es möglich, die Leistung einer Instanz zu verbessern und was ist der Engpass?
Mit solchen Fragen kamen Kollegen zu uns - ein Team von Leistungsforschern.
Was machen wir
Wir tun alles, um die Leistung unseres Service sicherzustellen, und erforschen und verbessern ihn zunächst für die Geschäftsprozesse unserer Produktion. Jeder Geschäftsprozess, ob es sich um die Bezahlung von Waren in einem Geschäft mit einer Brieftasche oder die Überweisung von Geld zwischen Benutzern handelt, stellt für uns im Wesentlichen eine Kette von Anforderungen im System dar.
Wir führen Experimente durch und erstellen Berichte, um die Systemleistung bei hoher Intensität eingehender Anforderungen zu bewerten. Die Berichte enthalten Leistungsmetriken und eine detaillierte Beschreibung der erkannten Probleme und Engpässe. Mit Hilfe dieser Informationen verbessern und optimieren wir unser System.
Die Bewertung des Potenzials jeder Anwendung wird durch die Tatsache erschwert, dass mehrere Microservices, die die Leistung aller beteiligten Instanzen nutzen, an der Organisation der Abfolge von Geschäftsprozessanforderungen beteiligt sind.
Metaphorisch gesehen kennen wir die Macht unserer Armee, aber nicht das Potenzial jedes einzelnen Kämpfers. Daher ist es neben der laufenden Forschung erforderlich, die im Rahmen des Kapazitätsmanagementprozesses verwendeten Ressourcen zu bewerten. Dieser Prozess wird als Kapazitätsmanagement bezeichnet.
Unsere Forschung hilft, einen Mangel an Ressourcen zu identifizieren und zu verhindern, Eiseneinkäufe vorherzusagen und genaue Daten über die aktuellen und potenziellen Fähigkeiten des Systems zu erhalten. Im Rahmen dieses Prozesses wird die tatsächliche Anwendungsleistung (sowohl Median als auch Maximum) überwacht und Daten zum aktuellen Bestand bereitgestellt.
Das Wesentliche beim Kapazitätsmanagement ist es, ein Gleichgewicht zwischen verbrauchten Ressourcen und Produktivität zu finden.
Vorteile:
- Es ist jederzeit bekannt, was mit der Leistung jeder Anwendung geschieht.
- Geringeres Risiko beim Hinzufügen neuer Microservices.
- Geringere Kosten für den Kauf neuer Geräte.
- Die bereits vorhandenen Kapazitäten werden intelligenter genutzt.
Wie das Kapazitätsmanagement funktioniert
Kommen wir mit vielen Anwendungen auf unsere Situation zurück. Wir haben eine Studie durchgeführt, deren Zweck es war, zu bewerten, wie Kapazitäten auf Produktionsservern verwendet werden.
Kurz gesagt, der Aktionsplan lautet wie folgt:
- Definieren Sie die Benutzerintensität für bestimmte Anwendungen.
- Erstellen Sie ein Aufnahmeprofil.
- Bewerten Sie die Leistung jeder Anwendungsinstanz.
- Skalierbarkeit der Rate.
- Erstellen Sie Berichte und Schlussfolgerungen zur Mindestanzahl von Instanzen für jede Anwendung in einer Kampfumgebung.
Und jetzt im Detail.
Die Werkzeuge
Wir verwenden Heka und Zabbix, um benutzerdefinierte Intensitätsmetriken zu erfassen. Grafana wird verwendet, um gesammelte Metriken zu visualisieren.
Zabbix wird zur Überwachung von Serverressourcen benötigt, z. B .: CPU, Speicher, Netzwerkverbindungen, Datenbank und andere. Heka liefert Daten zur Anzahl und zum Zeitpunkt der Ausführung eingehender / ausgehender Anforderungen, zur Erfassung von Metriken in internen Anwendungswarteschlangen und zu einer endlosen Menge anderer Daten. Grafana ist ein flexibles Visualisierungstool, das von verschiedenen Yandex.Money-Teams verwendet wird. Wir sind keine Ausnahme.
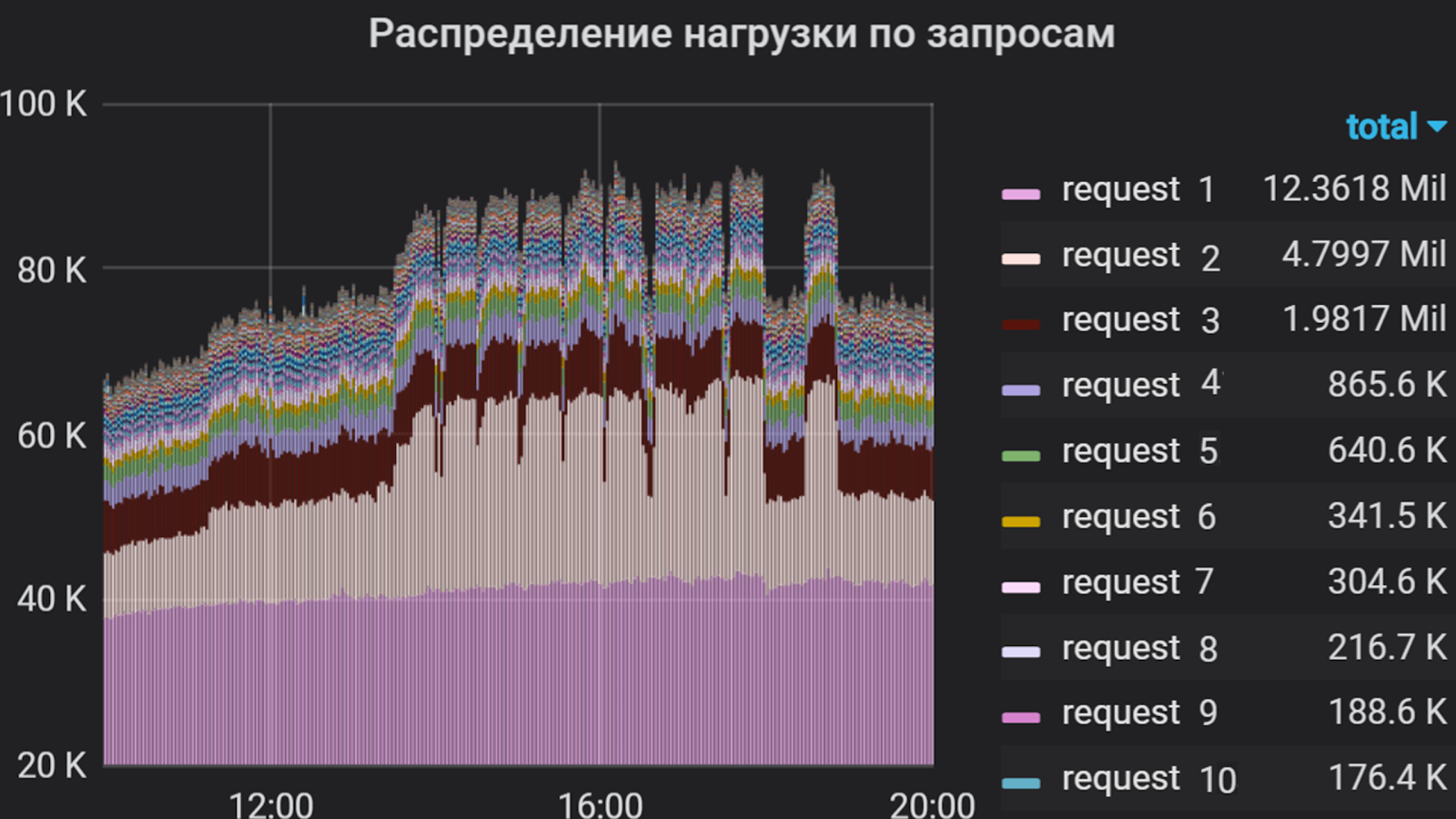
Grafana kann zum Beispiel solche Dinge zeigen
Apache JMeter wird als Verkehrsgenerator verwendet. Mit seiner Hilfe wird ein Aufnahmeszenario erstellt, das die Implementierung von Anforderungen, die Überwachung der Gültigkeit der Antwort, die flexible Steuerung des Feed-Streams und vieles mehr umfasst. Dieses Tool hat sowohl Vor- als auch Nachteile, aber um genau zu sein: „Warum dieses spezielle Produkt?“ Ich werde nicht.
Zusätzlich zu JMeter wird das Yandex-Tank- Framework verwendet - ein Tool zum Stresstest und zur Analyse der Leistung von Webdiensten und -anwendungen. Sie können Ihre Module anschließen, um die gewünschten Funktionen zu erhalten und die Ergebnisse in der Konsole oder in Form von Diagrammen anzuzeigen. Die Ergebnisse unseres Feuers werden im Lunapark (analog zu https://overload.yandex.net ) angezeigt, wo wir sie in Echtzeit bis zu zweiten Spitzen detailliert beobachten können, um die notwendige und ausreichende Diskretion zu gewährleisten und dadurch schneller auf Bursts zu reagieren. aus dem Schießen entstehen. In Graphan kann man auch die Diskretion anpassen, aber diese Lösung ist in Bezug auf physische und logische Ressourcen teurer. Und manchmal laden wir sogar Rohdaten hoch und visualisieren sie über das GUI Jmeter. Aber nur - shhh!
Apropos Erniedrigung. Fast alle Abstürze, die in der Anwendung unter einem großen Verkehrsfluss auftreten, werden mit Kibana schnell analysiert. Dies ist jedoch auch kein Allheilmittel. Einige Netzwerkprobleme können nur durch Entfernen und Analysieren des Datenverkehrs analysiert werden.
Mit Grafana haben wir die Benutzerintensität in der Anwendung mehrere Monate lang analysiert. Wir haben beschlossen, die Gesamtprozessorzeit für die Ausführung von Anforderungen als Maßeinheit zu verwenden, d. H. Die Anzahl der Anforderungen und die Zeit ihrer Ausführung wurden berücksichtigt. Deshalb haben wir eine Liste der „schwersten“ Anfragen zusammengestellt, die den größten Teil des Flusses zur Anwendung ausmachen. Diese Liste bildete die Grundlage für das Schießprofil.

Benutzerintensität pro Anwendung für mehrere Monate
Schieß- und Sichtprofil
Wir nennen das Auslösen eines Skriptstarts als Teil eines Experiments. Das Profil besteht aus zwei Teilen.
Der erste Teil ist das Schreiben eines Abfrageskripts. Während der Implementierung ist es erforderlich, die Benutzerintensität für jede eingehende Anwendungsanforderung zu analysieren und ein prozentuales Verhältnis zwischen ihnen zu erstellen, um die am häufigsten aufgerufenen und lang laufenden zu identifizieren. Der zweite Teil ist die Auswahl der Strömungswachstumsparameter: mit welcher Intensität und wie lange zu laden.
Zur besseren Übersichtlichkeit lässt sich die Methode zum Erstellen eines Profils am besten anhand eines Beispiels demonstrieren.
Grafana erstellt ein Diagramm, das die Benutzerintensität und den Anteil jeder Anforderung am Gesamtfluss widerspiegelt. Basierend auf dieser Verteilung und Antwortzeit für jede Anforderung werden Gruppen in JMeter erstellt, von denen jede ein unabhängiger Verkehrsgenerator ist. Das Szenario basiert nur auf den „schwierigsten“ Anforderungen, da es schwierig ist, alles zu implementieren (in einigen Anwendungen gibt es mehr als hundert), und dies ist aufgrund ihrer relativ geringen Intensität nicht immer erforderlich.

Prozentsatz der Abfragen
Diese Studie untersucht die Benutzerintensität in einem konstanten Fluss, und periodisch auftretende „Bursts“ werden am häufigsten privat betrachtet.
In unserem Beispiel werden zwei Gruppen betrachtet. Die erste Gruppe enthielt "Anfrage 1" und "Anfrage 2" im Verhältnis 1 zu 2. Ebenso enthielt die zweite Gruppe die Anfragen 3 und 4. Die verbleibenden Anforderungen für die Komponente sind viel weniger intensiv, sodass wir sie nicht in das Skript aufnehmen.

Gruppieren von Abfragen in Jmeter
Basierend auf der mittleren Antwortzeit für jede Gruppe wird die Leistung durch die Formel geschätzt:
x = 1000 / t, wobei t die mittlere Zeit ist, ms
Wir erhalten das Berechnungsergebnis und schätzen die ungefähre Intensität mit zunehmender Anzahl von Threads:
TPS = x * p, wobei p die Anzahl der Threads ist, TPS die Transaktion pro Sekunde ist und x das Ergebnis der vorherigen Berechnung ist.
Wenn die Anfrage in 500 ms verarbeitet wird, haben wir mit einem Stream 2 Tps und mit 100 Threads idealerweise 200 Tps. Basierend auf den erhaltenen Ergebnissen können anfängliche Wachstumsparameter ausgewählt werden. Nach der ersten Iteration der Forschung werden diese Parameter normalerweise angepasst.
Wenn das Aufnahmeszenario fertig ist, starten wir die Aufnahme - eine Minute lang in einem Stream. Dies geschieht, um die Funktionsfähigkeit des Skripts mit einem konstanten Fluss zu überprüfen, die Antwortzeit auf Anforderungen in jeder Gruppe zu bewerten und ein prozentuales Verhältnis der Anforderungen zu erhalten.
Bei der Ausführung dieses Profils haben wir festgestellt, dass bei gleicher Intensität der Prozentsatz der Anforderungen erhalten bleibt, da die durchschnittliche Antwortzeit in der zweiten Gruppe länger ist als in der ersten. Daher stellen wir für beide Gruppen die gleiche Durchflussrate ein. In anderen Fällen wäre es notwendig, die Parameter für jede Gruppe separat experimentell auszuwählen.
In diesem Beispiel wurde die Intensität schrittweise angewendet, dh eine bestimmte Anzahl von Flüssen wurde über ein bestimmtes Intervall hinzugefügt.

Optionen für das Intensitätswachstum
Die Intensitätswachstumsparameter waren wie folgt:
- Die Zielanzahl der Fäden beträgt 100 (während der Sichtung bestimmt).
- Wachstum für 1000 Sekunden (~ 16 Minuten).
- 100 Schritte.
Daher fügen wir alle 10 Sekunden einen Stream hinzu. Das Intervall zwischen dem Hinzufügen von Threads und der Anzahl der hinzugefügten Threads hängt vom Verhalten des Systems in einem bestimmten Schritt ab. Oft wird die Intensität mit einem gleichmäßigen Wachstum geliefert, so dass Sie den Status des Systems in jeder Phase verfolgen können.
Feuern
Normalerweise wird das Brennen nachts von Remote-Servern aus gestartet. Zu diesem Zeitpunkt ist der Benutzerverkehr minimal - dies bedeutet, dass das Aufnehmen die Benutzer kaum beeinträchtigt und der Fehler in den Ergebnissen geringer ist.
Entsprechend den Ergebnissen des ersten Brennens in einem Fall passen wir die Anzahl der Fäden und die Wachstumszeit an, analysieren das Verhalten des Gesamtsystems und stellen Abweichungen in der Arbeit fest. Nach allen Anpassungen beginnt das wiederholte Auslösen einer Instanz. In dieser Phase ermitteln wir die maximale Leistung und überwachen die Verwendung der Hardwareressourcen des Servers mit der Anwendung und allem, was dahinter steckt.
Nach den Ergebnissen der Aufnahme betrug die Leistung einer Instanz unserer Anwendung etwa 1000 Tps. Gleichzeitig wurde eine Verlängerung der Antwortzeit für alle Anforderungen aufgezeichnet, ohne die Produktivität zu erhöhen, dh wir erreichten eine Sättigung, aber keine Verschlechterung.
Im nächsten Schritt vergleichen wir die Ergebnisse aus anderen Fällen. Dies ist wichtig, da die Hardware unterschiedlich sein kann, was bedeutet, dass verschiedene Instanzen sehr unterschiedliche Indikatoren liefern können. So war es auch bei uns - einige der Server erwiesen sich aufgrund ihrer Generierung und Eigenschaften als um eine Größenordnung produktiver. Daher haben wir eine Gruppe von Servern mit den besten Ergebnissen identifiziert und deren Skalierbarkeit untersucht.
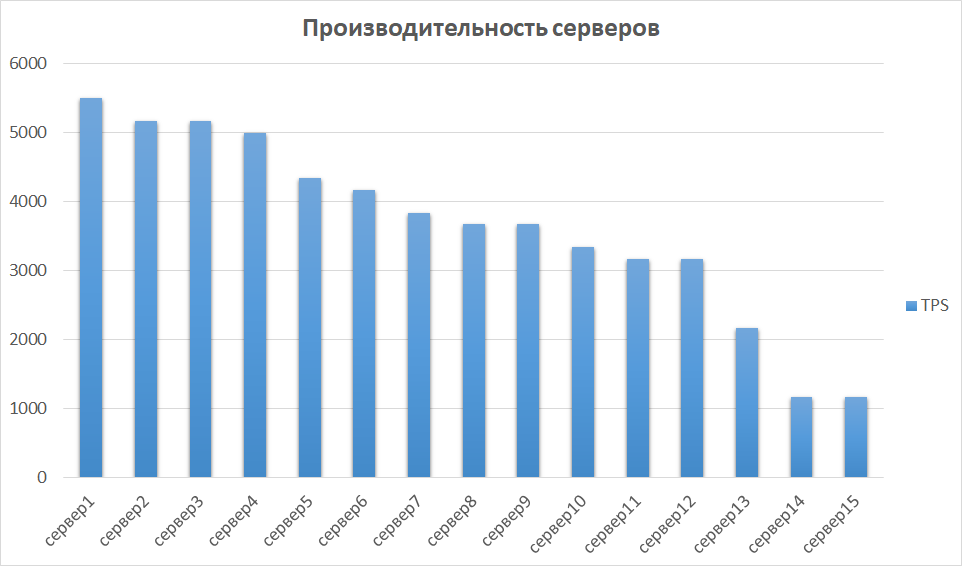
Vergleich der Serverleistung
Skalierbarkeit und Engpass
Der nächste Schritt besteht darin, die Leistung in den Instanzen 2, 3 und 4 zu untersuchen. Theoretisch sollte die Leistung mit zunehmender Anzahl von Instanzen linear wachsen. In der Praxis ist dies normalerweise nicht der Fall.
In unserem Beispiel stellte sich heraus, dass dies eine nahezu perfekte Option war.

Der Grund für das gesättigte Produktivitätswachstum war die Erschöpfung der Konnektorpools vor dem anschließenden Backend. Dies wird durch die Steuerung der Größe der Pools auf der ausgehenden und eingehenden Seite gelöst und führt zu einer Steigerung der Anwendungsleistung.
In anderen Studien sind wir auf interessantere Dinge gestoßen. Experimente haben gezeigt, dass mit der Leistung die Auslastung von CPU- und Datenbankverbindungen schnell zunimmt. In unserem Fall geschah dies, weil wir in der Konfiguration mit einer Instanz auf unsere eigenen Einstellungen für Anwendungspools gestoßen sind und bei zwei Instanzen diese Anzahl verdoppelt haben, wodurch der ausgehende Stream verdoppelt wurde. Die Datenbank war für ein solches Volume nicht bereit. Aus diesem Grund verstopften die Pools in der Datenbank, der Prozentsatz der verbrauchten CPU erreichte eine kritische Marke von 99%, und die Verarbeitungszeit für Abfragen nahm zu, und ein Teil des Datenverkehrs fiel insgesamt ab. Und solche Ergebnisse haben wir bereits in zwei Fällen erzielt!
Um uns endlich von unseren Ängsten zu überzeugen, haben wir in drei Fällen geschossen. Die Ergebnisse waren ungefähr die gleichen wie in den ersten beiden, außer dass sie schnell zu einer Störung kamen.
Es gibt ein weiteres Beispiel für „Stecker“, das meiner Meinung nach am schmerzhaftesten ist - dies ist schlecht geschriebener Code. Sie können alles Mögliche tun, angefangen bei Datenbankabfragen, die in wenigen Minuten ausgeführt werden, bis hin zu Code, der den Speicher eines Java-Computers falsch zuordnet.
Zusammenfassung
Infolgedessen hat die in unserer Beispielanwendung untersuchte Anwendungsspanne eine Leistungsspanne von mehr als dem Fünffachen.
Um die Produktivität zu steigern, muss in den Anwendungseinstellungen eine ausreichende Anzahl von Prozessorpools berechnet werden. Zwei Instanzen für eine bestimmte Anwendung sind ausreichend, und die Verwendung aller 15 verfügbaren Instanzen ist redundant.
Nach der Studie wurden die folgenden Ergebnisse erhalten:
- Die Benutzerintensität für 1 Monat wurde bestimmt und überwacht.
- Die Leistungsspanne einer Instanz der Anwendung wurde ermittelt.
- Die Ergebnisse werden über Fehler erhalten, die unter einem großen Strom auftreten.
- Es wurden Engpässe für weitere Arbeiten zur Steigerung der Produktivität festgestellt.
- Die Mindestanzahl von Instanzen für den korrekten Betrieb der Anwendung wurde ermittelt. Infolgedessen wurde der übermäßige Einsatz von Kapazitäten aufgedeckt.
Die Ergebnisse der Studie bildeten die Grundlage des Projekts für den Transfer von Komponenten in Behälter, das wir in den folgenden Artikeln diskutieren werden. Jetzt können wir mit Sicherheit sagen, wie viele Container und mit welchen Eigenschaften sie benötigt werden, wie ihre Kapazitäten rational genutzt werden können und woran gearbeitet werden sollte, um eine ordnungsgemäße Leistung sicherzustellen.
Besuchen Sie unseren gemütlichen Telegramm-Chatroom, in dem Sie jederzeit um Rat fragen, Kollegen helfen und einfach über Produktivitätsforschung sprechen können.
Das ist alles für heute. Stellen Sie Fragen in den Kommentaren und abonnieren Sie den Yandex.Money-Blog - bald werden wir über Phishing sprechen und wie Sie es vermeiden können.