Spiele werden seit Jahrzehnten als eine der wichtigsten Methoden zum Testen und Bewerten des Erfolgs künstlicher Intelligenzsysteme eingesetzt. Mit zunehmenden Möglichkeiten suchten die Forscher nach Spielen mit immer größerer Komplexität, die die verschiedenen Elemente des Denkens widerspiegeln, die zur Lösung wissenschaftlicher oder angewandter Probleme der realen Welt erforderlich sind. In den letzten Jahren wurde StarCraft als eine der vielseitigsten und komplexesten Echtzeitstrategien und als eine der beliebtesten in der E-Sportszene der Geschichte angesehen. Jetzt ist StarCraft auch die größte Herausforderung für die KI-Forschung.
AlphaStar ist das erste künstliche Intelligenzsystem, das die besten Profispieler besiegen kann. In einer Reihe von Spielen, die am 19. Dezember stattfanden, gewann AlphaStar einen Erdrutschsieg gegen Grzegorz Komincz (
MaNa ) vom Team
Liquid , einem der
stärksten Spieler der Welt , mit einem Ergebnis von 5: 0. Zuvor wurde auch ein erfolgreiches Demonstrationsspiel gegen seinen Teamkollegen Dario Wünsch (
TLO ) ausgetragen. Die Spiele wurden nach allen professionellen Regeln auf einer speziellen
Turnierkarte und ohne Einschränkungen ausgetragen.
Trotz bedeutender Erfolge in Spielen wie
Atari ,
Mario ,
Quake III Arena und
Dota 2 kämpften KI-Techniker erfolglos gegen die Komplexität von StarCraft. Die besten
Ergebnisse wurden erzielt, indem die Grundelemente des Systems manuell erstellt wurden, indem den Spielregeln verschiedene Einschränkungen auferlegt wurden, indem dem System übermenschliche Fähigkeiten verliehen wurden oder indem auf vereinfachten Karten gespielt wurde. Aber selbst diese Nuancen machten es unmöglich, dem Niveau der Profispieler näher zu kommen. Im Gegensatz dazu spielt AlphaStar ein vollwertiges Spiel mit tiefen neuronalen Netzen, die auf der Grundlage von Rohdaten des Spiels trainiert werden, wobei Methoden zum
Lehren mit einem Lehrer und zum
Lernen mit Verstärkung verwendet werden .
Hauptherausforderung
StarCraft II ist ein fiktives Fantasy-Universum mit einem reichhaltigen, mehrstufigen Gameplay. Zusammen mit der Originalausgabe ist dies das größte und erfolgreichste Spiel aller Zeiten, das seit mehr als 20 Jahren in Turnieren ausgetragen wird.

Es gibt viele Möglichkeiten zu spielen, aber die häufigste im E-Sport sind Eins-zu-Eins-Turniere, die aus 5 Spielen bestehen. Zu Beginn muss der Spieler eine von drei Rassen auswählen - Zergs, Protoss oder Terrans, von denen jede ihre eigenen Eigenschaften und Fähigkeiten hat. Daher spezialisieren sich professionelle Spieler meist auf ein Rennen. Jeder Spieler beginnt mit mehreren Arbeitseinheiten, die Ressourcen für den Bau von Gebäuden, andere Einheiten oder die Entwicklung von Technologie extrahieren. Dies ermöglicht es dem Spieler, andere Ressourcen zu ergreifen, ausgefeiltere Basen aufzubauen und neue Fähigkeiten zu entwickeln, um den Gegner zu überlisten. Um zu gewinnen, muss der Spieler das Bild der Gesamtwirtschaft, das als "Makro" bezeichnet wird, und die Kontrolle einzelner Einheiten auf niedriger Ebene, das als "Mikro" bezeichnet wird, sehr fein ausbalancieren.
Die Notwendigkeit, kurzfristige und langfristige Ziele in Einklang zu bringen und sich an unvorhergesehene Situationen anzupassen, stellt Systeme vor große Herausforderungen, die sich tatsächlich oft als völlig unflexibel herausstellen. Die Lösung dieses Problems erfordert einen Durchbruch in mehreren Bereichen der KI:
Spieltheorie : StarCraft ist ein Spiel, bei dem es wie in „Stein, Schere, Papier“ keine einzige Gewinnstrategie gibt. Daher muss die KI im Lernprozess ständig den Horizont ihres strategischen Wissens erforschen und erweitern.
Unvollständige Informationen : Im Gegensatz zu Schach oder Go, wo die Spieler alles sehen, was passiert, sind in StarCraft wichtige Informationen oft verborgen und müssen aktiv durch Intelligenz extrahiert werden.
Langfristige Planung : Wie bei realen Aufgaben sind Ursache-Wirkungs-Beziehungen möglicherweise nicht augenblicklich. Ein Spiel kann auch eine Stunde oder länger dauern, daher können Aktionen, die zu Beginn eines Spiels ausgeführt werden, auf lange Sicht absolut keine Bedeutung haben.
Echtzeit : Im Gegensatz zu herkömmlichen Brettspielen, bei denen sich die Teilnehmer abwechseln, führen die Spieler in StarCraft im Laufe der Zeit kontinuierlich Aktionen aus.
Riesiger Aktionsraum : Hunderte verschiedener Einheiten und Gebäude müssen gleichzeitig in Echtzeit überwacht werden, was einen wirklich riesigen kombinatorischen Raum an Möglichkeiten bietet. Darüber hinaus sind viele Aktionen hierarchisch und können sich auf dem Weg ändern und ergänzen. Unsere Parametrisierung des Spiels ergibt durchschnittlich 10 bis 26 Aktionen pro Zeiteinheit.
Angesichts dieser Herausforderungen ist StarCraft für KI-Forscher zu einer großen Herausforderung geworden. Die laufenden StarCraft- und StarCraft II-Wettbewerbe haben ihre Wurzeln in der Einführung der
BroodWar-API im Jahr 2009. Darunter befinden sich der
AIIDE StarCraft AI-Wettbewerb , der
CIG StarCraft-Wettbewerb , das
Student StarCraft AI-Turnier und die
Starcraft II AI Ladder .
Hinweis : 2017 veröffentlichte PatientZero auf Habré eine hervorragende Übersetzung von „ Die Geschichte der KI-Wettbewerbe in Starcraft “.Um die Community bei der weiteren Erforschung dieser Probleme zu unterstützen, haben wir in
Zusammenarbeit mit Blizzard in den Jahren 2016 und 2017 das
PySC2-Toolkit veröffentlicht , das die größte Anzahl anonymisierter Wiederholungen enthält, die jemals veröffentlicht wurden. Basierend auf dieser Arbeit haben wir unsere technischen und algorithmischen Errungenschaften kombiniert, um den AlphaStar zu erstellen.
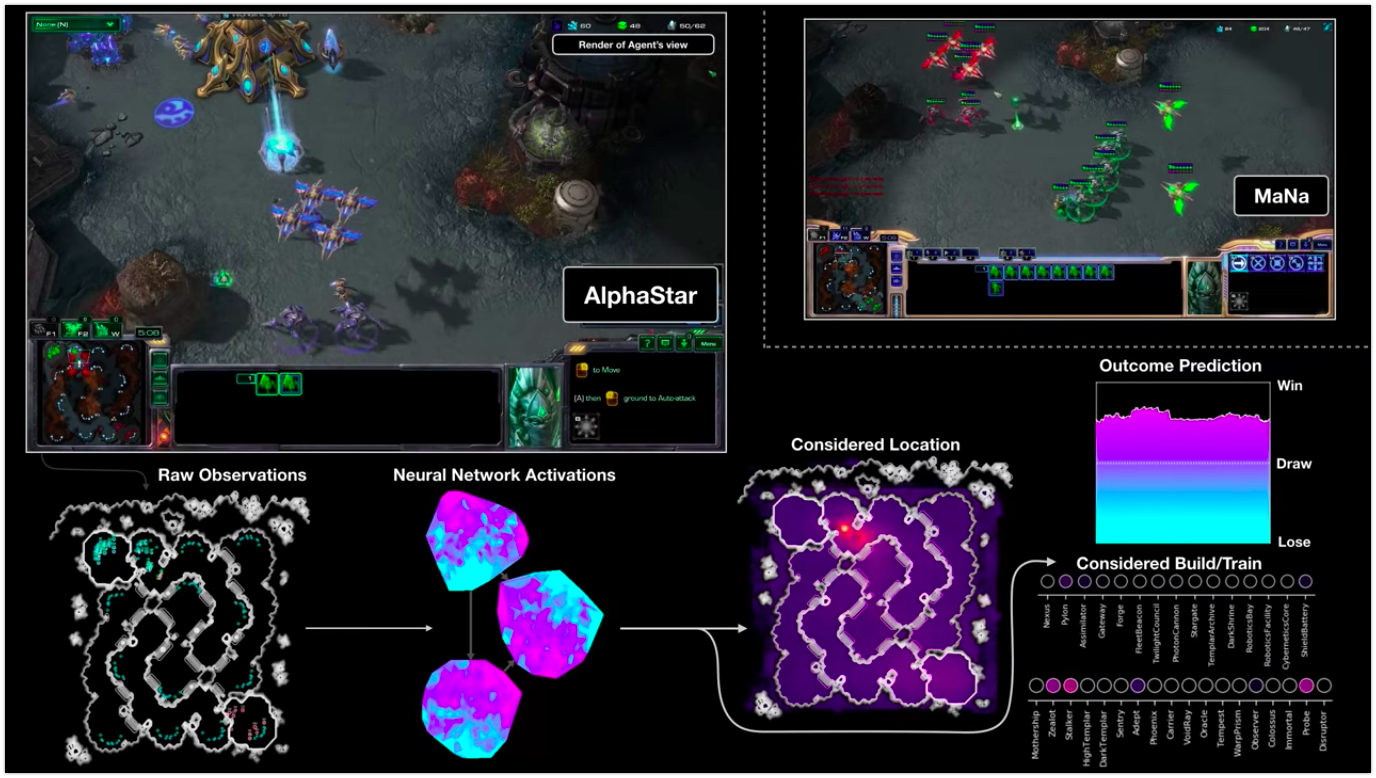
 Die Visualisierung von AlphaStar während des Kampfes gegen MaNa demonstriert das Spiel im Auftrag des Agenten - die anfänglich beobachteten Daten, die Aktivität des neuronalen Netzwerks, einige der vorgeschlagenen Aktionen und die erforderlichen Koordinaten sowie das geschätzte Ergebnis des Spiels. Die Ansicht des MaNa-Players wird ebenfalls angezeigt, ist jedoch für den Agenten natürlich nicht zugänglich.
Die Visualisierung von AlphaStar während des Kampfes gegen MaNa demonstriert das Spiel im Auftrag des Agenten - die anfänglich beobachteten Daten, die Aktivität des neuronalen Netzwerks, einige der vorgeschlagenen Aktionen und die erforderlichen Koordinaten sowie das geschätzte Ergebnis des Spiels. Die Ansicht des MaNa-Players wird ebenfalls angezeigt, ist jedoch für den Agenten natürlich nicht zugänglich.Wie ist das Training?
Das AlphaStar-Verhalten wird
durch ein tief lernendes
neuronales Netzwerk erzeugt , das Rohdaten über die Schnittstelle (eine Liste der Einheiten und ihrer Eigenschaften) empfängt und eine Folge von Anweisungen gibt, die Aktionen im Spiel sind. Insbesondere verwendet die Architektur des neuronalen Netzwerks den Ansatz des "
Transformator- Torsos für die Einheiten, kombiniert mit einem
tiefen LSTM-Kern , einem
automatisch regressiven Richtlinienkopf mit einem
Zeigernetzwerk und einer
zentralisierten Wertebasislinie "
(für die Genauigkeit der Begriffe, die ohne Übersetzung verbleiben) . Wir glauben, dass diese Modelle weiter dazu beitragen werden, andere wichtige maschinelle Lernaufgaben zu bewältigen, einschließlich der Langzeitsequenzmodellierung und großer Ausgaberäume wie Übersetzung, Sprachmodellierung und visuelle Darstellungen.
AlphaStar verwendet auch den neuen Multi-Agent-Lernalgorithmus. Dieses neuronale Netzwerk wurde ursprünglich mit einer lehrerbasierten Lernmethode trainiert, die auf anonymisierten Wiederholungen basiert, die über Blizzard
verfügbar sind. Dadurch konnte AlphaStar die grundlegenden Mikro- und Makrostrategien von Spielern in Turnieren untersuchen und simulieren. Dieser Agent besiegte die eingebaute KI-Stufe „Elite“, die in 95% der Testspiele der Stufe eines Spielers in der Goldliga entspricht.
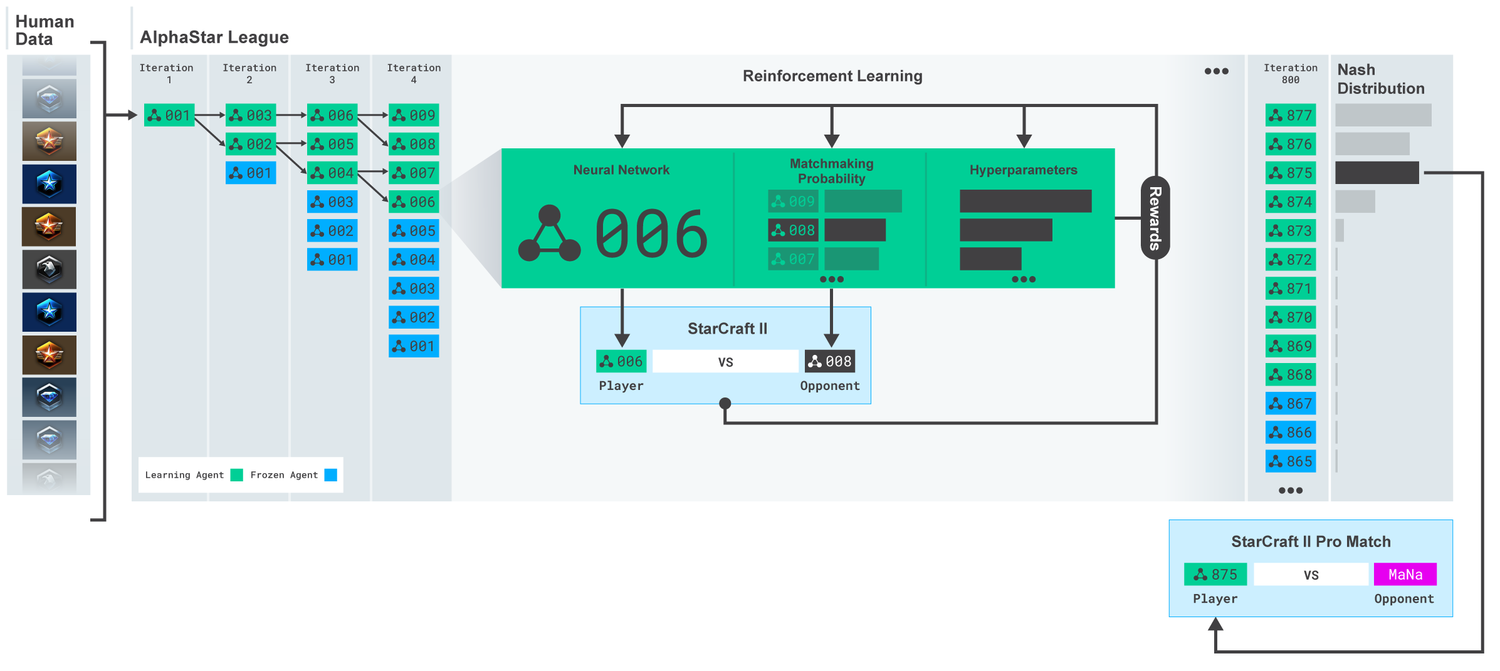 Liga AlphaStar. Die Agenten wurden zunächst auf der Grundlage von Wiederholungen menschlicher Übereinstimmungen und dann auf der Grundlage von Wettbewerbsspielen untereinander geschult. Bei jeder Iteration verzweigen sich neue Gegner und die ursprünglichen frieren ein. Die Wahrscheinlichkeit, andere Gegner und Hyperparameter zu treffen, bestimmt die Lernziele für jeden Agenten, was die Komplexität erhöht und die Vielfalt bewahrt. Die Agentenparameter werden mit einem Verstärkungstraining aktualisiert, das auf dem Ergebnis des Spiels gegen Gegner basiert. Der endgültige Agent wird (ohne Ersatz) basierend auf der Nash-Verteilung ausgewählt.
Liga AlphaStar. Die Agenten wurden zunächst auf der Grundlage von Wiederholungen menschlicher Übereinstimmungen und dann auf der Grundlage von Wettbewerbsspielen untereinander geschult. Bei jeder Iteration verzweigen sich neue Gegner und die ursprünglichen frieren ein. Die Wahrscheinlichkeit, andere Gegner und Hyperparameter zu treffen, bestimmt die Lernziele für jeden Agenten, was die Komplexität erhöht und die Vielfalt bewahrt. Die Agentenparameter werden mit einem Verstärkungstraining aktualisiert, das auf dem Ergebnis des Spiels gegen Gegner basiert. Der endgültige Agent wird (ohne Ersatz) basierend auf der Nash-Verteilung ausgewählt.Diese Ergebnisse werden dann verwendet, um einen Lernprozess zur Verstärkung mehrerer Agenten zu initiieren. Zu diesem Zweck wurde eine Liga geschaffen, in der gegnerische Agenten gegeneinander spielen, genau wie Menschen durch das Spielen von Turnieren Erfahrung sammeln. Durch die Verdoppelung der derzeitigen Agenten wurden neue Rivalen in die Liga aufgenommen. Diese neue Form des Trainings, bei der einige Ideen aus der Methode des verstärkenden Lernens mit Elementen genetischer (
bevölkerungsbasierter ) Algorithmen übernommen wurden, ermöglicht es Ihnen, einen kontinuierlichen Prozess zur Erkundung des riesigen strategischen Spielraums von StarCraft zu erstellen und sicherzustellen, dass Agenten den leistungsstärksten Strategien standhalten können, nicht die alten vergessen.
 Score MMR (Match Making Rating) - ein ungefährer Indikator für die Fähigkeiten des Spielers. Für Rivalen in der AlphaStar-Liga während des Trainings im Vergleich zu Blizzards Online-Ligen.
Score MMR (Match Making Rating) - ein ungefährer Indikator für die Fähigkeiten des Spielers. Für Rivalen in der AlphaStar-Liga während des Trainings im Vergleich zu Blizzards Online-Ligen.Als sich die Liga entwickelte und neue Agenten geschaffen wurden, tauchten Gegenstrategien auf, die die vorherigen besiegen konnten. Während einige Agenten nur die Strategien verbesserten, auf die sie zuvor gestoßen waren, erstellten andere Agenten völlig neue, einschließlich neuer ungewöhnlicher Bauaufträge, Einheitenzusammensetzung und Makromanagement. Zum Beispiel blühten die „Käse“ schon früh - schneller Ansturm mit Hilfe von
Photonenkanonen oder
dunklen Templern . Aber als der Lernprozess voranschritt, wurden diese riskanten Strategien verworfen und machten anderen Platz. Zum Beispiel die Produktion einer überschüssigen Anzahl von Arbeitern, um einen zusätzlichen Zufluss von Ressourcen zu erhalten, oder die Spende von zwei
Orakeln , um die feindlichen Arbeiter anzugreifen und seine Wirtschaft zu untergraben. Dieser Prozess ähnelt dem, wie reguläre Spieler in den vielen Jahren seit der Veröffentlichung von StarCraft neue Strategien entdeckten und alte populäre Ansätze besiegten.
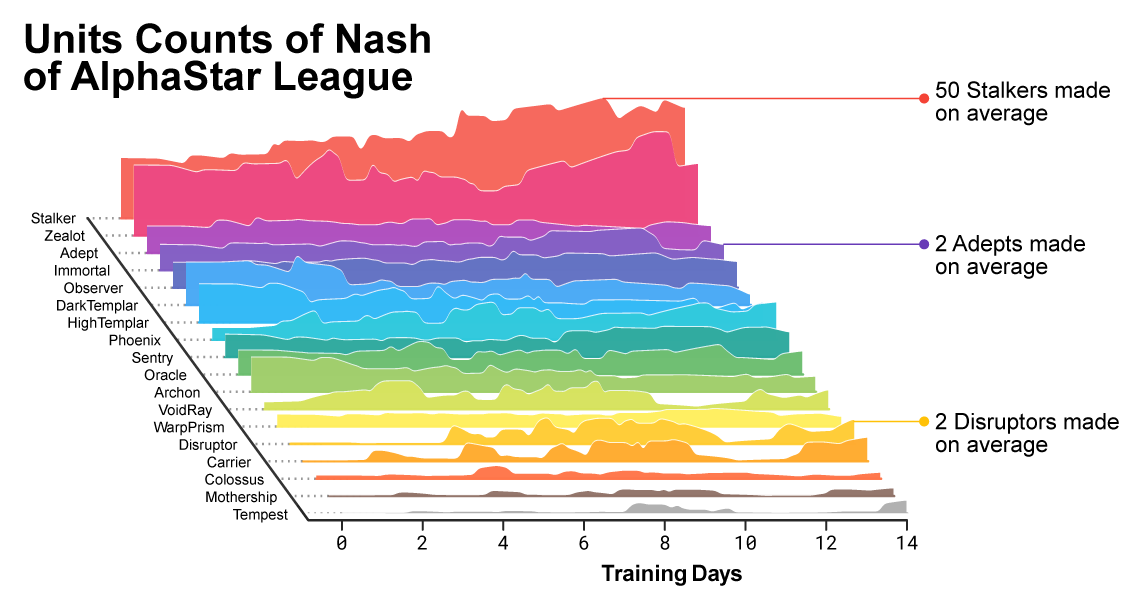 Im Verlauf des Trainings fiel auf, wie sich die Zusammensetzung der von den Agenten verwendeten Einheiten änderte.
Im Verlauf des Trainings fiel auf, wie sich die Zusammensetzung der von den Agenten verwendeten Einheiten änderte.Um die Vielfalt zu gewährleisten, wurde jeder Agent mit seinem eigenen Lernziel ausgestattet. Zum Beispiel, welche Gegner dieser Agent besiegen sollte oder welche andere intrinsische Motivation das Spiel des Agenten bestimmt. Ein bestimmter Agent kann das Ziel haben, einen bestimmten Gegner und den anderen eine ganze Auswahl von Gegnern zu besiegen, aber nur bestimmte Einheiten. Diese Ziele haben sich im Laufe des Lernprozesses geändert.
 Interaktive Visualisierung (interaktive Funktionen sind im Originalartikel verfügbar), die Rivalen mit der AlphaStar League zeigt. Der Agent, der gegen TLO und MaNa gespielt hat, ist separat gekennzeichnet.
Interaktive Visualisierung (interaktive Funktionen sind im Originalartikel verfügbar), die Rivalen mit der AlphaStar League zeigt. Der Agent, der gegen TLO und MaNa gespielt hat, ist separat gekennzeichnet.Die Koeffizienten (Gewichte) des neuronalen Netzwerks jedes Agenten wurden unter Verwendung eines Verstärkungstrainings basierend auf Spielen mit Gegnern aktualisiert, um ihre spezifischen Lernziele zu optimieren. Die Regel für die Aktualisierung des Gewichts ist ein neuer effektiver Lernalgorithmus „Lernalgorithmus für die Verstärkung von
Akteuren und
Kritikern außerhalb der Politik mit
Erfahrungswiedergabe ,
selbstnachahmendem Lernen und
Destillation von Richtlinien “
(für die Genauigkeit der Begriffe, die ohne Übersetzung bleiben) .
 Das Bild zeigt, wie ein Agent (schwarzer Punkt), der als Ergebnis für das Spiel gegen MaNa ausgewählt wurde, seine Strategie im Vergleich zu Gegnern (farbige Punkte) im Trainingsprozess entwickelt hat. Jeder Punkt repräsentiert einen Gegner in der Liga. Die Position des Punktes zeigt die Strategie und die Größe - die Häufigkeit, mit der er als Gegner für den MaNa-Agenten im Lernprozess ausgewählt wird.
Das Bild zeigt, wie ein Agent (schwarzer Punkt), der als Ergebnis für das Spiel gegen MaNa ausgewählt wurde, seine Strategie im Vergleich zu Gegnern (farbige Punkte) im Trainingsprozess entwickelt hat. Jeder Punkt repräsentiert einen Gegner in der Liga. Die Position des Punktes zeigt die Strategie und die Größe - die Häufigkeit, mit der er als Gegner für den MaNa-Agenten im Lernprozess ausgewählt wird.Um AlphaStar zu trainieren, haben wir ein skalierbares verteiltes System basierend auf
Google TPU 3 erstellt, das den Prozess des parallelen Trainings einer ganzen Population von Agenten mit Tausenden von laufenden Kopien von StarCraft II ermöglicht. Die AlphaStar League dauerte 14 Tage und verwendete 16 TPUs für jeden Agenten. Während des Trainings hatte jeder Agent bis zu 200 Jahre Erfahrung mit StarCraft in Echtzeit. Die endgültige Version von AlphaStar Agent enthält alle
Vertriebskomponenten von League
Nash . Mit anderen Worten, die effektivste Mischung von Strategien, die während der Spiele entdeckt wurden. Diese Konfiguration kann auf einer Standard-Desktop-GPU ausgeführt werden. Eine vollständige technische Beschreibung wird zur Veröffentlichung in einer von Experten begutachteten wissenschaftlichen Zeitschrift vorbereitet.
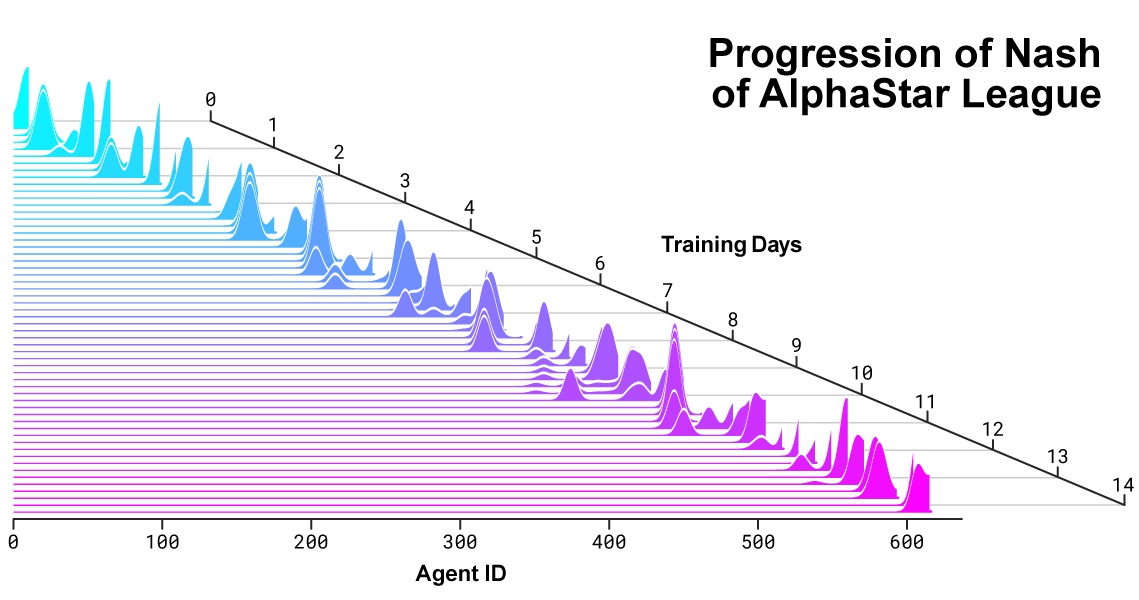 Nash-Verteilung zwischen Rivalen während der Entwicklung der Liga und der Schaffung neuer Gegner. Die Nash-Distribution, die die am wenigsten ausnutzbare Gruppe komplementärer Wettbewerber darstellt, schätzt neue Spieler und zeigt damit kontinuierliche Fortschritte gegenüber allen früheren Wettbewerbern.
Nash-Verteilung zwischen Rivalen während der Entwicklung der Liga und der Schaffung neuer Gegner. Die Nash-Distribution, die die am wenigsten ausnutzbare Gruppe komplementärer Wettbewerber darstellt, schätzt neue Spieler und zeigt damit kontinuierliche Fortschritte gegenüber allen früheren Wettbewerbern.Wie AlphaStar sich verhält und das Spiel sieht
Professionelle Spieler wie TLO oder MaNa können Hunderte von Aktionen pro Minute (
APM ) ausführen. Dies ist jedoch viel weniger als bei den meisten
vorhandenen Bots , die jede Einheit unabhängig voneinander steuern und Tausende, wenn nicht Zehntausende von Aktionen generieren.
In unseren Spielen gegen TLO und MaNa hat AlphaStar den APM auf einem Durchschnitt von 280 gehalten, was viel weniger ist als der von Profispielern, obwohl seine Aktionen möglicherweise genauer sind. Ein derart niedriger APM ist insbesondere auf die Tatsache zurückzuführen, dass AlphaStar auf der Grundlage von Wiederholungen gewöhnlicher Spieler zu studieren begann und versuchte, die Art des menschlichen Spielens nachzuahmen. Darüber hinaus reagiert AlphaStar mit einer Verzögerung zwischen Beobachtung und Aktion von durchschnittlich etwa 350 ms.
 Verteilung von APM AlphaStar in Spielen gegen MaNa und TLO und die Gesamtverzögerung zwischen Beobachtung und Aktion.
Verteilung von APM AlphaStar in Spielen gegen MaNa und TLO und die Gesamtverzögerung zwischen Beobachtung und Aktion.Während der Spiele gegen TLO und MaNa interagierte AlphaStar über die Rohschnittstelle mit der StarCraft-Spiel-Engine, dh er konnte die Attribute seiner und sichtbaren feindlichen Einheiten direkt auf der Karte sehen, ohne die Kamera bewegen zu müssen - spielen Sie effektiv mit einer reduzierten Sicht auf das gesamte Gebiet . Im Gegensatz dazu müssen lebende Menschen die „Aufmerksamkeitsökonomie“ klar steuern, um ständig zu entscheiden, wo die Kamera fokussiert werden soll. Eine Analyse von AlphaStar-Spielen zeigt jedoch, dass der Fokus implizit gesteuert wird. Im Durchschnitt wechselt ein Agent wie MaNa und TLO etwa 30 Mal pro Minute seinen Aufmerksamkeitskontext.
Zusätzlich haben wir die zweite Version von AlphaStar entwickelt. Als menschliche Spieler wählt diese Version von AlphaStar klar, wann und wo die Kamera bewegt werden soll. In dieser Ausführungsform ist seine Wahrnehmung auf Informationen auf dem Bildschirm beschränkt, und Aktionen sind auch nur auf dem sichtbaren Bereich des Bildschirms zulässig.
 AlphaStar-Leistung bei Verwendung der Basisschnittstelle und der Kameraschnittstelle. Die Grafik zeigt, dass der neue Agent, der mit der Kamera arbeitet, über die Basisschnittstelle schnell eine vergleichbare Leistung für den Agenten erzielt.
AlphaStar-Leistung bei Verwendung der Basisschnittstelle und der Kameraschnittstelle. Die Grafik zeigt, dass der neue Agent, der mit der Kamera arbeitet, über die Basisschnittstelle schnell eine vergleichbare Leistung für den Agenten erzielt.Wir haben zwei neue Agenten geschult, einen über die Basisschnittstelle und einen, der lernen sollte, wie man die Kamera steuert, und gegen die AlphaStar-Liga spielt. Jeder Agent wurde zu Beginn mit einem Lehrer trainiert, der auf menschlichen Übereinstimmungen basierte, gefolgt von einem Training mit der oben beschriebenen Verstärkung. Die AlphaStar-Version, die die Kameraschnittstelle verwendet, erzielte fast die gleichen Ergebnisse wie die Version mit der Basisschnittstelle und überschritt die 7000-MMR-Marke in unserer internen Rangliste. In einem Demonstrationsspiel besiegte MaNa den AlphaStar-Prototyp mit einer Kamera. Wir haben diese Version nur 7 Tage trainiert. Wir hoffen, dass wir in naher Zukunft eine voll ausgebildete Version mit einer Kamera evaluieren können.
Diese Ergebnisse zeigen, dass der Erfolg von AlphaStar bei Spielen gegen MaNa und TLO in erster Linie auf ein gutes Makro- und Mikromanagement zurückzuführen ist und nicht nur auf eine hohe Klickrate, eine schnelle Reaktion oder den Zugriff auf Informationen auf der Basisoberfläche.
Ergebnisse des Spiels AlphaStar gegen professionelle Spieler
Mit StarCraft können Spieler zwischen drei Rennen wählen - Terraner, Zerg oder Protoss. Wir haben beschlossen, dass AlphaStar sich derzeit auf ein bestimmtes Rennen, das Protoss, spezialisieren wird, um die Trainingszeit und die Abweichungen bei der Bewertung der Ergebnisse unserer heimischen Liga zu reduzieren. Es sollte jedoch beachtet werden, dass ein ähnlicher Lernprozess auf jede Rasse angewendet werden kann. Unsere Agenten wurden geschult, um StarCraft II Version 4.6.2 im Protoss versus Protoss-Modus auf der CatalystLE-Karte zu spielen. Um die Leistung von AlphaStar zu bewerten, haben wir unsere Agenten zunächst in Spielen gegen TLO getestet - einen professionellen Spieler für Zerg und einen Spieler für Protoss Level „GrandMaster“. AlphaStar gewann Matches mit einer Punktzahl von 5: 0 unter Verwendung einer Vielzahl von Einheiten und Bauaufträgen. "Ich war überrascht, wie stark der Agent war", sagte er. „AlphaStar verfolgt bekannte Strategien und stellt sie auf den Kopf. Der Agent zeigte Strategien, an die ich noch nie gedacht hatte. Und das zeigt, dass es immer noch Spielmöglichkeiten geben kann, die noch nicht vollständig verstanden sind. “
Nach einer zusätzlichen Trainingswoche spielten wir gegen MaNa, einen der mächtigsten StarCraft II-Spieler der Welt und einen der 10 besten Protoss-Spieler. AlphaStar gewann diesmal mit 5: 0 und zeigte starke Fähigkeiten im Bereich Mikromanagement und Makrostrategie. "Ich war erstaunt zu sehen, dass AlphaStar in jedem Spiel die fortschrittlichsten Ansätze und unterschiedlichen Strategien verwendet und einen sehr menschlichen Spielstil zeigt, den ich nie erwartet hätte", sagte er. „Mir wurde klar, wie stark mein Spielstil von der Verwendung von Fehlern abhängt, die auf menschlichen Reaktionen beruhen. Und das bringt das Spiel auf ein ganz neues Level. Wir alle erwarten begeistert, was als nächstes passiert. "
AlphaStar und andere schwierige Probleme
Trotz der Tatsache, dass StarCraft nur ein Spiel ist, denken wir, dass die Techniken, die AlphaStar zugrunde liegen, bei der Lösung anderer Probleme hilfreich sein können, auch wenn es sehr schwierig ist. Beispielsweise kann diese Art der neuronalen Netzwerkarchitektur sehr lange Sequenzen wahrscheinlicher Aktionen in Spielen simulieren, die oft bis zu einer Stunde dauern und Zehntausende von Aktionen enthalten, die auf unvollständigen Informationen basieren. Jeder Frame in StarCraft wird als ein Eingabeschritt verwendet. In diesem Fall sagt das neuronale Netzwerk bei jedem dieser Schritte die erwartete Abfolge von Aktionen für das gesamte verbleibende Spiel voraus. Die grundlegende Aufgabe, komplexe Vorhersagen für sehr lange Datensequenzen zu erstellen, liegt in vielen realen Aufgaben wie Wettervorhersage, Klimamodellierung, Sprachverständnis usw. Wir freuen uns sehr, das enorme Potenzial zu erkennen.Dies kann in diesen Bereichen angewendet werden, basierend auf den Erfahrungen, die wir im AlphaStar-Projekt gesammelt haben.Wir glauben auch, dass einige unserer Lehrmethoden nützlich sein können, um die Sicherheit und Zuverlässigkeit der KI zu untersuchen. Eines der schwierigsten Probleme auf dem Gebiet der KI ist die Anzahl der Optionen, bei denen das System möglicherweise falsch ist. Und professionelle Spieler haben in der Vergangenheit schnell Wege gefunden, die KI zu umgehen, indem sie ihre Fehler auf die ursprüngliche Weise nutzten. Der innovative AlphaStar-Ansatz, der auf dem Training in der Liga basiert, findet solche Ansätze und macht den Gesamtprozess zuverlässiger und vor solchen Fehlern geschützt. Wir freuen uns, dass das Potenzial dieses Ansatzes dazu beitragen kann, die Sicherheit und Zuverlässigkeit von KI-Systemen im Allgemeinen zu verbessern. Besonders in kritischen Bereichen wie Energie, wo es äußerst wichtig ist, in schwierigen Situationen richtig zu reagieren.Das Erreichen eines so hohen Spielniveaus in StarCraft ist ein großer Durchbruch in einem der herausforderndsten Videospiele, die jemals entwickelt wurden. Wir glauben, dass diese Erfolge zusammen mit den Erfolgen in anderen Projekten, ob AlphaZero oder AlphaFold , einen Fortschritt bei der Umsetzung unserer Mission darstellen, intelligente Systeme zu schaffen, die uns eines Tages helfen werden, Lösungen für die komplexesten und grundlegendsten wissenschaftlichen Probleme zu finden.
11 Wiederholungen aller SpieleVideo des Demonstrationsspiels gegen MaNaVideo mit Visualisierung von AlphaStar des vollständigen zweiten Spiels gegen MaNa