
DeepMind, eine Tochtergesellschaft von Alphabet, einem Forschungsunternehmen auf dem Gebiet der künstlichen Intelligenz, hat einen neuen Meilenstein in dieser großartigen Suche angekündigt:
Zum ersten Mal besiegte AI die Person in der Strategie von Starcraft II . Im Dezember 2018 verbreitete ein Faltungsnetzwerk namens
AlphaStar die Profispieler
TLO (Dario Wünsch, Deutschland) und
MaNa (Grzegorz Kominz, Polen) und erzielte zehn Siege. Das Unternehmen hat diese Veranstaltung gestern in einer
Live-Übertragung auf YouTube und Twitch angekündigt.
In beiden Fällen spielten sowohl Personen als auch das Programm als Protoss. TLO ist zwar nicht auf dieses Rennen spezialisiert, aber MaNa leistete ernsthaften Widerstand und gewann dann sogar ein Spiel.
In der beliebten Echtzeitstrategie repräsentieren die Spieler eines von drei Rennen, die um Ressourcen konkurrieren, Strukturen aufbauen und auf der großen Karte kämpfen. Es ist wichtig zu beachten, dass die Geschwindigkeit des Programms und seine Sichtbarkeit auf dem Schlachtfeld begrenzt waren, damit AlphaStar keinen unfairen Vorteil gegenüber Menschen erlangte (Korrektur: Anscheinend war die Sichtbarkeit nur im letzten Spiel begrenzt). Laut Statistik führte das Programm sogar weniger Aktionen pro Minute durch als Personen: durchschnittlich 277 für AlphaStar, 390 für MaNa, 678 für TLO.
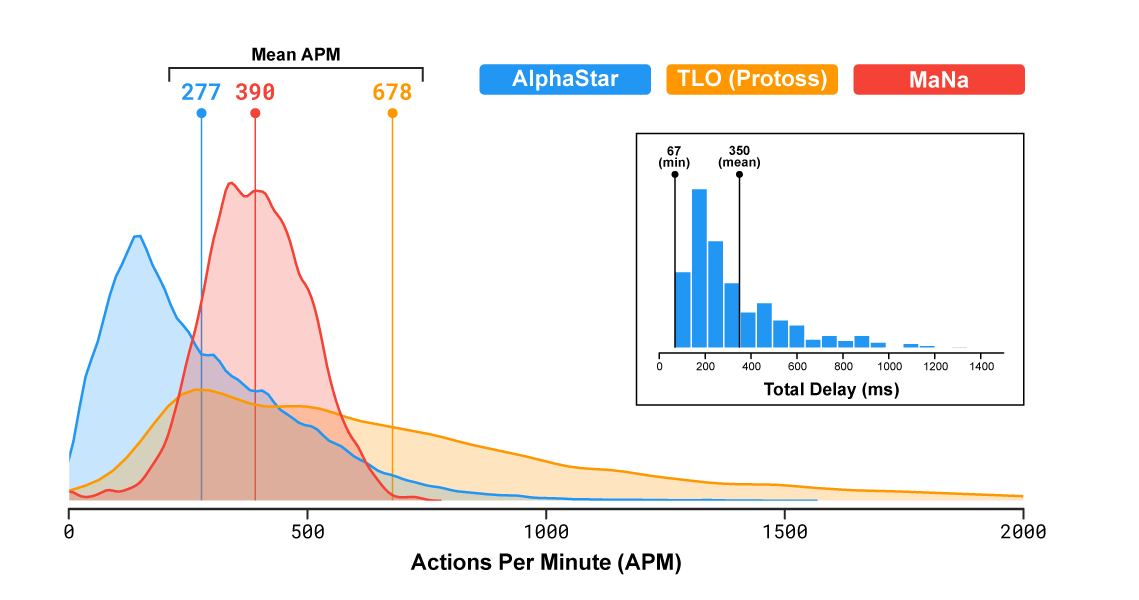
Das
Video zeigt die Sicht des Spiels aus Sicht des KI-Agenten im zweiten Spiel gegen MaNa. Die Ansicht von der menschlichen Seite wird ebenfalls gezeigt, war jedoch für das Programm nicht verfügbar.
AlphaStar wurde darauf trainiert, in einer Umgebung namens AlphaStar League für Protoss zu spielen. Zuerst verbrachte das neuronale Netzwerk drei Tage damit, Aufzeichnungen von Spielen zu betrachten und dann mit sich selbst zu spielen, wobei eine Technik verwendet wurde, die als Verstärkungstraining bekannt ist und die Fähigkeiten verfeinert.
Im Dezember organisierten sie erstmals eine Spielsitzung gegen TLO, in der fünf verschiedene Versionen von AlphaStar getestet wurden. Bei dieser Gelegenheit
beschwerte sich TLO
, dass er sich nicht an das Spiel des Gegners anpassen könne. Das Programm gewann mit 5: 0.
Nach der Optimierung der Einstellungen des neuronalen Netzwerks wurde eine Woche später ein Match gegen MaNa organisiert. Das Programm gewann erneut fünf Spiele, aber MaNa rächte sich im letzten Spiel gegen die neueste Version des Algorithmus live, sodass er auf etwas stolz sein kann.
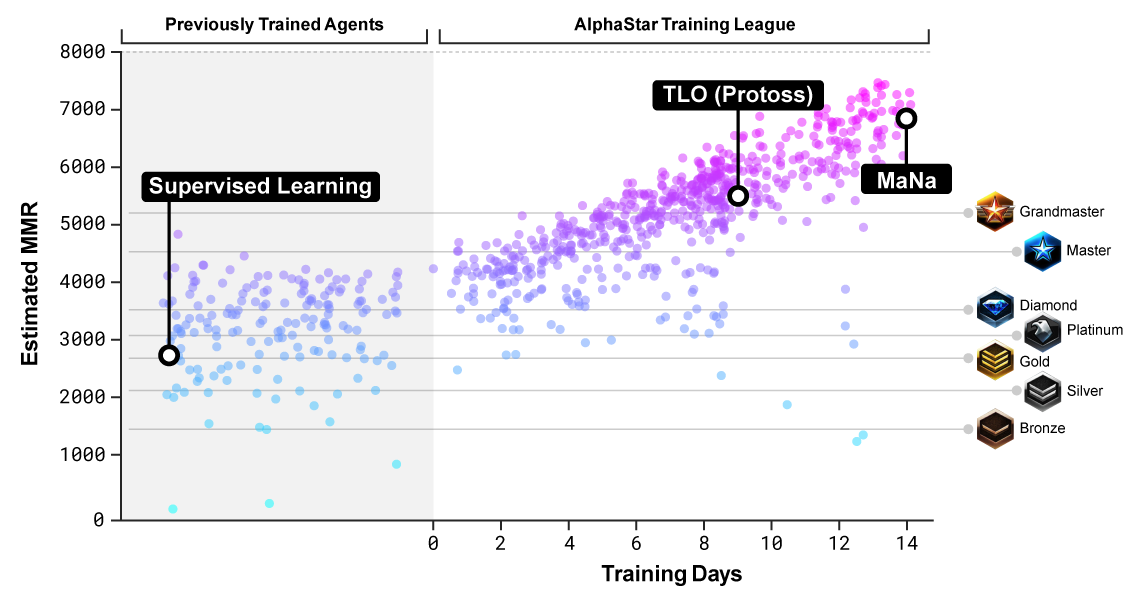 Bewertung der Ebene der Gegner, auf denen das neuronale Netzwerk trainiert wurde
Bewertung der Ebene der Gegner, auf denen das neuronale Netzwerk trainiert wurdeUm die Prinzipien der strategischen Planung zu verstehen, musste AlphaStar spezielles Denken beherrschen. Die für dieses Spiel entwickelten Methoden können möglicherweise in vielen praktischen Situationen nützlich sein, wenn eine komplexe Strategie erforderlich ist: zum Beispiel Handels- oder Militärplanung.
Starcraft II ist nicht nur ein extrem herausforderndes Spiel. Dies ist auch ein Spiel mit unvollständigen Informationen, bei dem die Spieler die Aktionen ihres Gegners nicht immer sehen können. Es fehlt auch eine optimale Strategie. Und es braucht Zeit, bis die Ergebnisse der Aktionen des Spielers klar werden: Dies erschwert auch das Lernen. Das DeepMind-Team verwendete eine sehr spezialisierte neuronale Netzwerkarchitektur, um diese Probleme zu lösen.
Eingeschränktes Lernen in Spielen
DeepMind ist als Softwareentwickler bekannt, der die weltbesten Go- und Schachprofis besiegt. Zuvor entwickelte das Unternehmen mehrere Algorithmen, die das Spielen einfacher Atari-Spiele lernten. Videospiele sind eine großartige Möglichkeit, Fortschritte in der künstlichen Intelligenz zu messen und Computer mit Menschen zu vergleichen. Dies ist jedoch ein sehr enger Testbereich. Wie frühere Programme führt AlphaStar nur eine Aufgabe aus, wenn auch unglaublich gut.
Wir können sagen, dass eine schwache KI mit engen Zielen die Fähigkeiten der strategischen Planung und Taktik von Kampfhandlungen beherrscht. Theoretisch können diese Fähigkeiten in der realen Welt nützlich sein. In der Praxis ist dies jedoch nicht unbedingt der Fall.
Einige Experten glauben, dass solche hochspezialisierten KI-Anwendungen nichts mit starker KI zu tun haben: „Programme, die gelernt haben, ein bestimmtes Videospiel oder Brettspiel auf„ übermenschlicher “Ebene meisterhaft zu spielen,
gehen bei geringsten Änderungen der Bedingungen (Änderung des Hintergrunds auf dem Bildschirm oder Änderung der Position)
vollständig verloren virtuelle „Plattform“ für den „Ball“) zu schlagen, - sagt Professor für Informatik an der Portland State University, Melanie Mitchell in dem Artikel
„Künstliche Intelligenz lief in eine Barriere ponima gen " . - Dies sind nur einige Beispiele, die die Unzuverlässigkeit der besten KI-Programme belegen, wenn sich die Situation geringfügig von der unterscheidet, in der sie trainiert wurden. Fehler in diesen Systemen reichen von lächerlich und harmlos bis zu potenziell katastrophal. “
Der Professor glaubt, dass das KI-Kommerzialisierungsrennen einen enormen Druck auf die Forscher ausübt, Systeme zu entwickeln, die bei engen Aufgaben „einigermaßen gut“ funktionieren. Letztendlich erfordert die Entwicklung einer zuverlässigen KI jedoch ein tieferes Studium unserer eigenen Fähigkeiten und ein neues Verständnis der kognitiven Mechanismen, die wir selbst verwenden:
Unser eigenes Verständnis der Situationen, mit denen wir konfrontiert sind, basiert auf umfassenden, intuitiven „Common-Sense-Konzepten“ über die Funktionsweise der Welt und die Ziele, Motive und das wahrscheinliche Verhalten anderer Lebewesen, insbesondere anderer Menschen. Darüber hinaus basiert unser Verständnis der Welt auf unseren grundlegenden Fähigkeiten, das, was wir wissen, zu verallgemeinern, abstrakte Konzepte zu bilden und Analogien zu ziehen - kurz gesagt, unsere Konzepte flexibel an neue Situationen anzupassen. Seit Jahrzehnten experimentieren Forscher damit, KI intuitiven gesunden Menschenverstand und nachhaltige menschliche Fähigkeiten zur Verallgemeinerung beizubringen, aber in dieser sehr schwierigen Angelegenheit wurden nur geringe Fortschritte erzielt.
Das neuronale AlphaStar-Netzwerk kann bisher nur für Protoss spielen. Die Entwickler kündigten Pläne an, sie in Zukunft für andere Rennen zu trainieren.