
Noch einmal, als ich mit dem Auto durch meine Heimatstadt fuhr und eine andere Grube umrundete, dachte ich: Gab es überall in unserem Land so „gute“ Straßen und ich entschied, dass wir die Situation objektiv anhand der Straßenqualität in unserem Land bewerten sollten.
Aufgabenformalisierung
In Russland sind die Anforderungen an die Straßenqualität in GOST R 50597-2017 „Straßen und Wege. Anforderungen an den Betriebszustand, die unter den Bedingungen der Gewährleistung der Verkehrssicherheit akzeptabel sind. Kontrollmethoden. " In diesem Dokument werden die Anforderungen für die Abdeckung der Fahrbahn, der Straßenränder, der Trennstreifen, der Bürgersteige, der Fußgängerwege usw. definiert und die Arten von Schäden festgelegt.
Da die Ermittlung aller Parameter der Straßen sehr umfangreich ist, habe ich mich entschlossen, sie einzugrenzen und mich nur auf das Problem der Ermittlung von Fehlern in der Fahrbahnabdeckung zu konzentrieren. In GOST R 50597-2017 werden folgende Mängel in der Fahrbahnbeschichtung unterschieden:
- Schlaglöcher
- bricht
- Drawdowns
- verschiebt sich
- Kämme
- verfolgen
- schwitzender Binder
Ich habe mich entschlossen, diese Mängel zu beheben.
Datenerfassung
Wo kann ich Fotos bekommen, die ausreichend große Abschnitte der Fahrbahn und sogar in Bezug auf die Geolokalisierung darstellen? Die Antwort kam in Strasssteinen - Panoramen auf den Karten von Yandex (oder Google), aber nach einigem Suchen fand ich mehrere weitere alternative Optionen:
- Ausgabe von Suchmaschinen für Bilder für relevante Anfragen;
- Fotos auf Websites für den Empfang von Beschwerden (Rosyama, Angry Citizen, Tugend usw.)
- Opendatascience veranlasste ein Projekt, Straßenfehler mit einem markierten Datensatz zu erkennen - github.com/sekilab/RoadDamageDetector
Leider hat eine Analyse dieser Optionen ergeben, dass sie für mich nicht sehr geeignet sind: Die Ausgabe von Suchmaschinen ist sehr laut (viele Fotos sind keine Straßen, verschiedene Renderings usw.), Fotos von Websites, auf denen Beschwerden eingehen, enthalten nur Fotos mit großen Verstößen gegen die Asphaltoberfläche Es gibt einige Fotos mit kleinen Verstößen gegen die Abdeckung und ohne Verstöße auf diesen Websites. Der Datensatz aus dem RoadDamageDetector-Projekt wird in Japan gesammelt und enthält keine Beispiele mit großen Verstößen gegen die Abdeckung sowie Straßen ohne Abdeckung.
Da alternative Optionen nicht geeignet sind, verwenden wir Yandex-Panoramen (ich habe die Google-Panoramaoption ausgeschlossen, da der Dienst in weniger Städten in Russland angeboten und weniger häufig aktualisiert wird). Er beschloss, Daten in Städten mit mehr als 100.000 Einwohnern sowie in Bundeszentren zu sammeln. Ich habe eine Liste mit Städtenamen erstellt - es gab 176, später stellte sich heraus, dass nur 149 von ihnen Panoramen haben. Ich werde mich nicht mit den Funktionen des Parsens von Kacheln befassen. Ich werde sagen, dass ich am Ende 149 Ordner (einen für jede Stadt) erhalten habe, in denen sich insgesamt 1,7 Millionen Fotos befanden. Für Novokuznetsk sah der Ordner beispielsweise folgendermaßen aus:

Durch die Anzahl der heruntergeladenen Fotos wurden die Städte wie folgt verteilt:
TabelleStadt
| Anzahl der Fotos, Stk
|
|---|
Moskau
| 86048
|
Sankt Petersburg
| 41376
|
Saransk
| 18880
|
Podolsk
| 18560
|
Krasnogorsk
| 18208
|
Lyubertsie
| 17760
|
Kaliningrad
| 16928
|
Kolomna
| 16832
|
Mytishchi
| 16192
|
Wladiwostok
| 16096
|
Balashikha
| 15968
|
Petrosawodsk
| 15968
|
Jekaterinburg
| 15808
|
Veliky Novgorod
| 15744
|
Naberezhnye Chelny
| 15680
|
Krasnodar
| 15520
|
Nizhny Novgorod
| 15488
|
Khimki
| 15296
|
Tula
| 15296
|
Nowosibirsk
| 15264
|
Tver
| 15200
|
Miass
| 15104
|
Ivanovo
| 15072
|
Vologda
| 15008
|
Schukowski
| 14976
|
Kostroma
| 14912
|
Samara
| 14880
|
Korolev
| 14784
|
Kaluga
| 14720
|
Cherepovets
| 14720
|
Sewastopol
| 14688
|
Pushkino
| 14528
|
Jaroslawl
| 14464
|
Uljanowsk
| 14400
|
Rostow am Don
| 14368
|
Domodedovo
| 14304
|
Kamensk-Uralsky
| 14208
|
Pskov
| 14144
|
Yoshkar-Ola
| 14080
|
Kertsch
| 14080
|
Murmansk
| 13920
|
Togliatti
| 13920
|
Wladimir
| 13792
|
Adler
| 13792
|
Syktyvkar
| 13728
|
Dolgoprudny
| 13696
|
Khanty-Mansiysk
| 13664
|
Kasan
| 13600
|
Engels
| 13440
|
Archangelsk
| 13280
|
Brjansk
| 13216
|
Omsk
| 13120
|
Syzran
| 13088
|
Krasnojarsk
| 13056
|
Shchelkovo
| 12928
|
Penza
| 12864
|
Tscheljabinsk
| 12768
|
Cheboksary
| 12768
|
Nischni Tagil
| 12672
|
Stavropol
| 12672
|
Ramenskoye
| 12640
|
Irkutsk
| 12608
|
Angarsk
| 12608
|
Tjumen
| 12512
|
Odintsovo
| 12512
|
Ufa
| 12512
|
Magadan
| 12512
|
Perm
| 12448
|
Kirov
| 12256
|
Nischnekamsk
| 12224
|
Makhachkala
| 12096
|
Nischnewartowsk
| 11936
|
Kursk
| 11904
|
Sotschi
| 11872
|
Tambow
| 11840
|
Pjatigorsk
| 11808
|
Wolgodonsk
| 11712
|
Rjasan
| 11680
|
Saratow
| 11616
|
Dzerzhinsk
| 11456
|
Orenburg
| 11456
|
Hügel
| 11424
|
Wolgograd
| 11264
|
Ischewsk
| 11168
|
Chrysostomus
| 11136
|
Lipetsk
| 11072
|
Kislowodsk
| 11072
|
Surgut
| 11040
|
Magnitogorsk
| 10912
|
Smolensk
| 10784
|
Chabarowsk
| 10752
|
Kopeysk
| 10688
|
Maykop
| 10656
|
Petropawlowsk-Kamtschatski
| 10624
|
Taganrog
| 10560
|
Barnaul
| 10528
|
Sergiev Posad
| 10368
|
Elista
| 10304
|
Sterlitamak
| 9920
|
Simferopol
| 9824
|
Tomsk
| 9760
|
Orekhovo-Zuevo
| 9728
|
Astrachan
| 9664
|
Evpatoria
| 9568
|
Noginsk
| 9344
|
Chita
| 9216
|
Belgorod
| 9120
|
Biysk
| 8928
|
Rybinsk
| 8896
|
Sewerodwinsk
| 8832
|
Woronesch
| 8768
|
Blagoveshchensk
| 8672
|
Novorossiysk
| 8608
|
Ulan-Ude
| 8576
|
Serpukhov
| 8320
|
Komsomolsk-on-Amur
| 8192
|
Abakan
| 8128
|
Norilsk
| 8096
|
Juschno-Sachalininsk
| 8032
|
Obninsk
| 7904
|
Essentuki
| 7712
|
Bataysk
| 7648
|
Wolzhsky
| 7584
|
Novocherkassk
| 7488
|
Berdsk
| 7456
|
Arzamas
| 7424
|
Pervouralsk
| 7392
|
Kemerowo
| 7104
|
Elektrostal
| 6720
|
Derbent
| 6592
|
Jakutsk
| 6528
|
Murom
| 6240
|
Nefteyugansk
| 5792
|
Reutov
| 5696
|
Birobidschan
| 5440
|
Novokuybyshevsk
| 5248
|
Salekhard
| 5184
|
Nowokusnezk
| 5152
|
Novy Urengoy
| 4736
|
Noyabrsk
| 4416
|
Novocheboksarsk
| 4352
|
Yelets
| 3968
|
Kaspiysk
| 3936
|
Stary Oskol
| 3840
|
Artyom
| 3744
|
Zheleznogorsk
| 3584
|
Salavat
| 3584
|
Prokopyevsk
| 2816
|
Gorno-Altaysk
| 2464
|
Vorbereiten eines Datensatzes für das Training
Und so wird der Datensatz zusammengestellt. Wie können Sie nun anhand eines Fotos des Straßenabschnitts und der umgebenden Objekte die Qualität des darauf abgebildeten Asphalts herausfinden? Ich beschloss, ein Stück des Fotos mit einer Größe von 350 * 244 Pixel in der Mitte des Originalfotos direkt unterhalb der Mitte auszuschneiden. Reduzieren Sie dann das geschnittene Stück horizontal auf eine Größe von 244 Pixel. Das resultierende Bild (244 * 244 groß) ist die Eingabe für den Faltungscodierer:

Um besser zu verstehen, mit welchen Daten ich zu tun habe, wurden die ersten 2000 Bilder, die ich selbst markiert habe, und die restlichen Bilder von Yandex.Tolki-Mitarbeitern markiert. Vor ihnen habe ich im folgenden Wortlaut eine Frage gestellt.
Geben Sie an, welche Straßenoberfläche Sie auf dem Foto sehen:
- Boden / Schutt
- Pflastersteine, Fliesen, Pflaster
- Schienen, Eisenbahnschienen
- Wasser, große Pfützen
- Asphalt
- Es gibt keine Straße auf dem Foto / Fremdkörper / Die Abdeckung ist aufgrund von Autos nicht sichtbar
Wenn der Darsteller „Asphalt“ wählte, erschien ein Menü, in dem die Qualität bewertet werden konnte:
- Hervorragende Abdeckung
- Leichte Einzelrisse / flache Schlaglöcher
- Große Risse / Gitterrisse / einzelne kleine Schlaglöcher
- Große Schlaglöcher / tiefe Schlaglöcher / zerstörte Beschichtung
Wie Testläufe der Aufgaben zeigten, unterscheiden sich die Darsteller von Y. Toloki nicht in der Integrität der Arbeit - sie klicken versehentlich mit der Maus auf die Felder und betrachten die Aufgabe als erledigt. Ich musste Kontrollfragen hinzufügen (in der Aufgabe gab es 46 Fotos, von denen 12 Kontrollfragen waren) und eine verzögerte Annahme ermöglichen. Als Kontrollfragen habe ich die Bilder verwendet, die ich selbst markiert habe. Ich habe die verzögerte Annahme automatisiert. Mit Y. Toloka können Sie die Arbeitsergebnisse in eine CSV-Datei hochladen und die Ergebnisse der Überprüfung der Antworten laden. Die Überprüfung der Antworten funktionierte wie folgt: Wenn die Aufgabe mehr als 5% falsche Antworten auf Kontrollfragen enthält, gilt sie als unerfüllt. Wenn der Auftragnehmer eine Antwort angibt, die logisch nahe an der Wahrheit liegt, wird seine Antwort als richtig angesehen.
Als Ergebnis erhielt ich ungefähr 30.000 getaggte Fotos, die ich für das Training in drei Klassen verteilte:
- "Gut" - Fotos mit den Bezeichnungen "Asphalt: Ausgezeichnete Beschichtung" und "Asphalt: Kleinere Einzelrisse"
- "Mitte" - Fotos mit den Bezeichnungen "Pflastersteine, Fliesen, Pflaster", "Schienen, Eisenbahnschienen" und "Asphalt: Große Risse / Gitterrisse / einzelne kleine Schlaglöcher"
- "Groß" - Fotos mit den Bezeichnungen "Boden / Schotter", "Wasser, große Pfützen" und "Asphalt: Eine große Anzahl von Schlaglöchern / tiefen Schlaglöchern / zerstörten Gehwegen"
- Fotos mit dem Tag „Es gibt keine Straße auf dem Foto / Fremdkörper / Abdeckung ist aufgrund von Autos nicht sichtbar“ gab es nur sehr wenige (22 Stück). Und ich habe sie von weiteren Arbeiten ausgeschlossen
Entwicklung und Schulung von Klassifikatoren
Also, die Daten werden gesammelt und beschriftet, fahren wir mit der Entwicklung des Klassifikators fort. Normalerweise wird für die Aufgaben der Bildklassifizierung, insbesondere beim Training mit kleinen Datensätzen, ein vorgefertigter Faltungscodierer verwendet, an dessen Ausgabe ein neuer Klassifizierer angeschlossen wird. Ich entschied mich für einen einfachen Klassifikator ohne versteckte Ebene, eine Eingabeebene der Größe 128 und eine Ausgabeebene der Größe 3. Ich entschied mich, sofort mehrere vorgefertigte Optionen zu verwenden, die in ImageNet als Encoder trainiert wurden:
- Xception
- Resnet
- Inception
- Vgg16
- Densenet121
- Mobilenet
Hier ist die Funktion, die das Keras-Modell mit dem angegebenen Encoder erstellt:
def createModel(typeModel): conv_base = None if(typeModel == "nasnet"): conv_base = keras.applications.nasnet.NASNetMobile(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "xception"): conv_base = keras.applications.xception.Xception(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "resnet"): conv_base = keras.applications.resnet50.ResNet50(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "inception"): conv_base = keras.applications.inception_v3.InceptionV3(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "densenet121"): conv_base = keras.applications.densenet.DenseNet121(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "mobilenet"): conv_base = keras.applications.mobilenet_v2.MobileNetV2(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "vgg16"): conv_base = keras.applications.vgg16.VGG16(include_top=False, input_shape=(224,224,3), weights='imagenet') conv_base.trainable = False model = Sequential() model.add(conv_base) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.0002))) model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Für das Training habe ich einen Generator mit Augmentation verwendet (da mir die Möglichkeiten der in Keras integrierten Augmentation unzureichend erschienen, habe ich die
Augmentor- Bibliothek verwendet):
- Pisten
- Zufällige Verzerrung
- Dreht sich
- Farbtausch
- Schichten
- Ändern Sie Kontrast und Helligkeit
- Zufälliges Rauschen hinzufügen
- Ernte
Nach der Vergrößerung sahen die Fotos folgendermaßen aus:

Generatorcode:
def get_datagen(): train_dir='~/data/train_img' test_dir='~/data/test_img' testDataGen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=16, class_mode='categorical') p = Augmentor.Pipeline(train_dir) p.skew(probability=0.9) p.random_distortion(probability=0.9,grid_width=3,grid_height=3,magnitude=8) p.rotate(probability=0.9, max_left_rotation=5, max_right_rotation=5) p.random_color(probability=0.7, min_factor=0.8, max_factor=1) p.flip_left_right(probability=0.7) p.random_brightness(probability=0.7, min_factor=0.8, max_factor=1.2) p.random_contrast(probability=0.5, min_factor=0.9, max_factor=1) p.random_erasing(probability=1,rectangle_area=0.2) p.crop_by_size(probability=1, width=244, height=244, centre=True) train_generator = keras_generator(p,batch_size=16) test_generator = testDataGen.flow_from_directory( test_dir, target_size=img_size, batch_size=32, class_mode='categorical') return (train_generator, test_generator)
Der Code zeigt, dass die Erweiterung nicht für Testdaten verwendet wird.
Wenn Sie einen abgestimmten Generator haben, können Sie mit dem Training des Modells beginnen. Wir führen es in zwei Schritten durch: Trainieren Sie zuerst nur unseren Klassifikator, dann das gesamte Modell.
def evalModelstep1(typeModel): K.clear_session() gc.collect() model=createModel(typeModel) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=4, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, ) return model def evalModelstep2(model): early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3) model.layers[0].trainable=True model.trainable=True model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=25, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, callbacks=[early_stopping_callback] ) return model def full_fit(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] for model_name in model_names: print("#########################################") print("#########################################") print("#########################################") print(model_name) print("#########################################") print("#########################################") print("#########################################") model = evalModelstep1(model_name) model = evalModelstep2(model) model.save("~/data/models/model_new_"+str(model_name)+".h5")
Rufen Sie full_fit () auf und warten Sie. Wir warten lange.
Als Ergebnis werden wir sechs trainierte Modelle haben. Wir werden die Genauigkeit dieser Modelle anhand eines separaten Teils der gekennzeichneten Daten überprüfen. Ich habe Folgendes erhalten:
Modellname
| Genauigkeit%
|
Xception
| 87.3
|
Resnet
| 90,8
|
Inception
| 90.2
|
Vgg16
| 89.2
|
Densenet121
| 90.6
|
Mobilenet
| 86,5
|
Im Allgemeinen nicht viel, aber mit einer so kleinen Trainingsstichprobe kann man nicht mehr erwarten. Um die Genauigkeit leicht zu erhöhen, habe ich die Ausgaben der Modelle durch Mittelwertbildung kombiniert:
def create_meta_model(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] model_input = Input(shape=(244,244,3)) submodels=[] i=0; for model_name in model_names: filename= "~/data/models/model_new_"+str(model_name)+".h5" submodel = keras.models.load_model(filename) submodel.name = model_name+"_"+str(i) i+=1 submodels.append(submodel(model_input)) out=average(submodels) model = Model(inputs = model_input,outputs=out) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Die resultierende Genauigkeit betrug 91,3%. Aufgrund dieses Ergebnisses habe ich beschlossen, aufzuhören.
Klassifikator verwenden
Endlich ist der Klassifikator fertig und kann in Aktion gesetzt werden! Ich bereite die Eingabedaten vor und starte den Klassifikator - etwas mehr als einen Tag und 1,7 Millionen Fotos wurden verarbeitet. Jetzt ist der lustige Teil das Ergebnis. Bringen Sie sofort die ersten und letzten zehn Städte in die relative Anzahl der Straßen mit guter Abdeckung:

Vollständige Tabelle (anklickbares Bild) Und hier ist die Straßenqualitätsbewertung nach Bundesfächern:
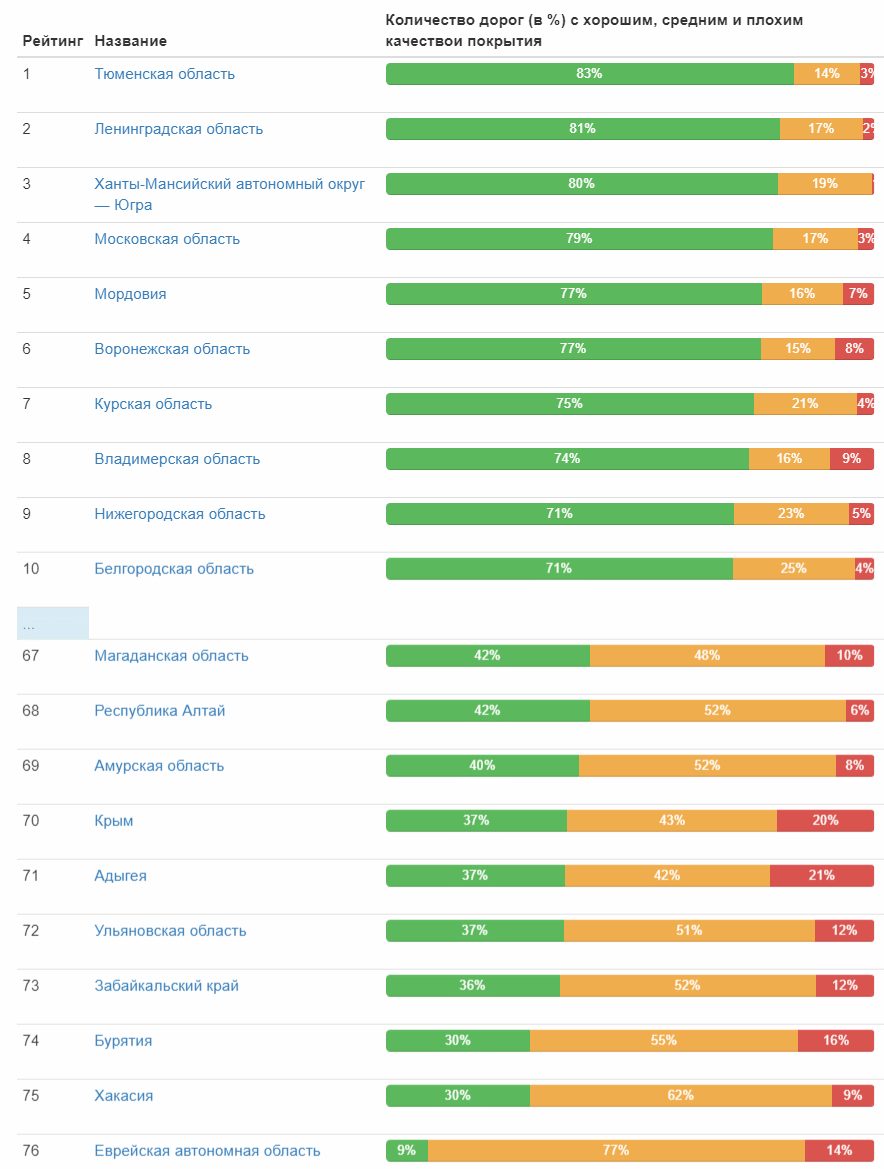
Bewertung nach Bundesbezirken:
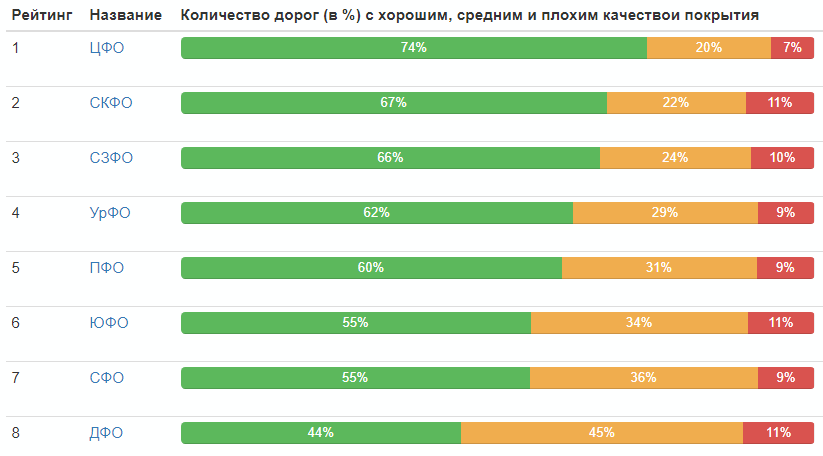
Verteilung der Straßenqualität in Russland insgesamt:

Nun, das ist alles, jeder kann selbst Schlussfolgerungen ziehen.
Schließlich werde ich die besten Fotos in jeder Kategorie geben (die den Maximalwert in ihrer Klasse erhalten haben):
PS In den Kommentaren wurde zu Recht auf das Fehlen von Statistiken über die Jahre des Eingangs der Fotos hingewiesen. Ich korrigiere und gebe eine Tabelle:
Jahr
| Anzahl der Fotos, Stk
|
| 2008 | 37 |
| 2009 | 13 |
| 2010 | 157030 |
| 2011 | 60724 |
| 2012 | 42387 |
| 2013 | 12148
|
| 2014 | 141021
|
| 2015 | 46143
|
| 2016 | 410385
|
| 2017 | 324279
|
| 2018 | 581961
|