Latenzzahlen, die jeder Programmierer kennen sollte - eine Tabelle mit "Verzögerungen, die jeder Programmierer kennen sollte". Es enthält die durchschnittlichen Zeitwerte für die Durchführung grundlegender Computeroperationen im Jahr 2012. Es gibt mehrere alternative Ansichten für diese Tabelle, und hier ist eine davon.
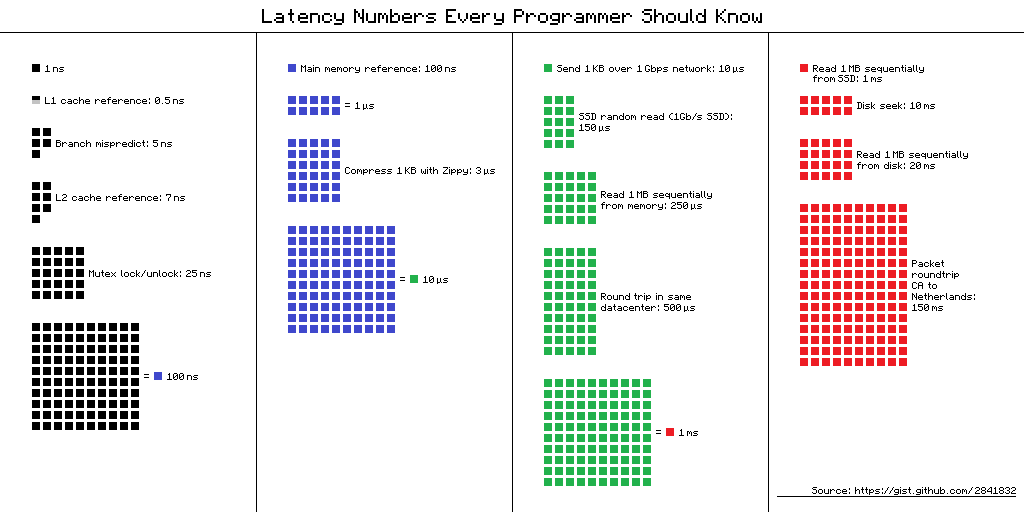 Link zur Schemaquelle
Link zur SchemaquelleAber was ist der Nutzen dieser Informationen für mobile Entwickler im Jahr 2019? Es scheint, dass nein, aber
Dmitry Kurkin (
SClown ) vom Yandex.Navigator-Team dachte: "Wie würde der Tisch für ein modernes iPhone aussehen?" Was dabei herauskam, in einer überarbeiteten Textversion von
Dmitrys Bericht über
AppsConf .
Wofür ist das?
Warum sollten Programmierer diese Nummern kennen? Und sind sie für mobile Entwickler relevant? Es gibt zwei Hauptaufgaben, die mit Hilfe dieser Zahlen gelöst werden können.
Die Zeitskala eines Computers verstehen
Nehmen Sie eine einfache Situation - ein Telefongespräch. Wir können leicht erkennen, wann dieser Prozess schnell und wann er lang ist: Ein paar Sekunden sind sehr schnell, ein paar Minuten sind ein durchschnittliches Gespräch und eine Stunde oder mehr ist sehr lang. Beim Laden von Seiten ist es ähnlich: In weniger als einer Sekunde - schnell, in wenigen Sekunden - erträglich und eine Minute ist eine Katastrophe. Der Benutzer wartet möglicherweise nicht auf den Download.
Aber was ist mit Operationen wie dem Hinzufügen einer Nummer zu einem Array - der sehr „schnellen Einfügung“, über die die Leute manchmal gerne in Interviews sprechen? Wie viel kostet ein Smartphone? Nanosekunden, Mikrosekunden oder Millisekunden? Ich habe nur wenige Leute getroffen, die sagen könnten, dass 1 Millisekunde eine lange Zeit ist, aber in unserem Fall ist es so.
Das Verhältnis der Geschwindigkeit verschiedener Computerkomponenten
Die Ausführungszeit von Vorgängen auf verschiedenen Geräten kann zehn- oder hundertfach variieren. Beispielsweise unterscheidet sich die Zugriffszeit auf den Hauptspeicher 100-mal vom Zugriff auf den L1-Cache. Dies ist ein großer Unterschied, aber nicht unendlich. Wenn wir dafür eine spezifische Bedeutung haben, können wir bei der Optimierung unserer Anwendungen bewerten, ob es einen Zeitgewinn gibt oder nicht.

"Latenzzahlen" im wirklichen Leben
Als ich diese Zahlen sah, interessierte mich der Unterschied zwischen Cache- und Speicherzugriff. Wenn ich meine Daten sorgfältig in 64 KByte lege, was nicht so klein ist, funktioniert mein Code 100-mal schneller - es ist schnell, alles wird fliegen!

Ich wollte sofort alles überprüfen, es meinen Kollegen zeigen und wo immer möglich anwenden. Ich habe mich entschieden, mit dem Standard-Tool von Apple zu beginnen - XCTest mit MeasureBlock. Der Test war wie folgt organisiert: Er ordnete ein Array zu, füllte es mit Zahlen, deren XOR'il und wiederholte den Algorithmus sicher zehnmal. Danach habe ich mir angesehen, wie viel Zeit ein Element benötigt.
| Puffergröße | Gesamtzeit | Zeit für eine Operation |
| 50 kb | 1,5 ms | 30 ns |
| 500 kb | 12 ms | 24 ns |
| 5000 kb | 85 ms | 17 ns |
Die Größe des Puffers erhöhte sich um das 100-fache, und die Zeit für die Operation erhöhte sich nicht nur nicht um das 100-fache, sondern verringerte sich fast um das 2-fache.
Meine Herren, Offiziere, sie haben uns betrogen ?!Nach einem solchen Ergebnis schlichen sich große Zweifel in mir ein, dass diese Zahlen im wirklichen Leben gesehen werden können. Bei einer regulären Anwendung ist es möglicherweise nicht möglich, diesen Unterschied zu erkennen. Oder vielleicht ist auf der mobilen Plattform alles anders.
Ich suchte nach einer Möglichkeit, den Leistungsunterschied zwischen Caches und Hauptspeicher zu erkennen. Während der Suche stieß ich auf einen Artikel, in dem sich der Autor beschwerte, dass auf seinem Mac und iPhone ein Benchmark ausgeführt wurde und diese Verzögerungen nicht angezeigt wurden. Ich nahm dieses Werkzeug und bekam das Ergebnis - genau wie in einer Apotheke. Die Speicherzugriffszeit nahm ziemlich deutlich zu, wenn die Puffergröße die Größe des entsprechenden Caches überschritt.
 LMbench
LMbench hat mir geholfen, diese Ergebnisse zu
erzielen . Dies ist ein von Larry McVoy, einem der Entwickler des Linux-Kernels, erstellter Benchmark, mit dem Sie die Speicherzugriffszeit, die Kosten für das Wechseln von Threads und Dateisystemoperationen und sogar die Zeit messen können, die die Hauptprozessoroperationen benötigen: Addition, Subtraktion usw. Gemäß diesem Benchmark Texas Instruments präsentierte
interessante Messdaten für seine Prozessoren. LMBench ist in C geschrieben, daher war es nicht schwierig, es unter iOS auszuführen.
Speicherkosten
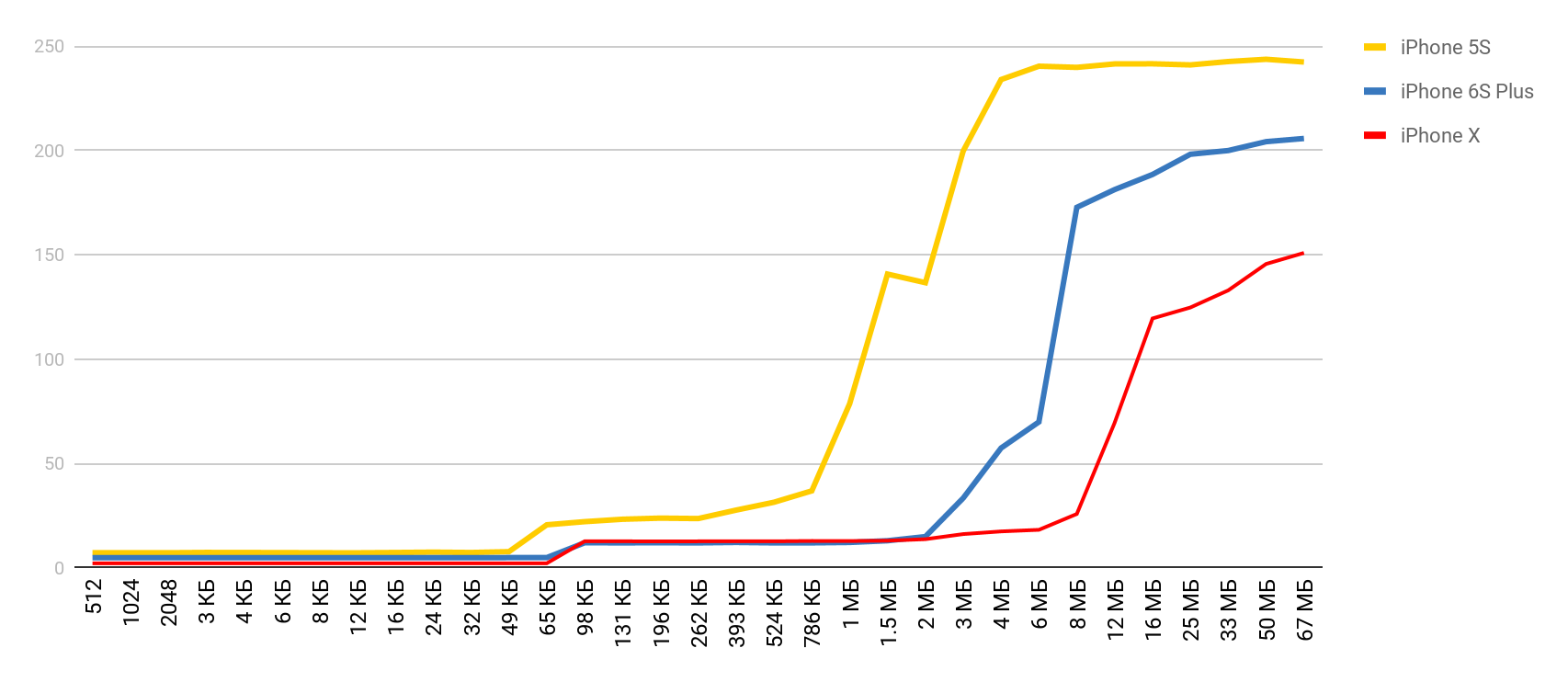
Mit einem so wunderbaren Werkzeug ausgestattet, entschied ich mich für ähnliche Messungen, jedoch für ein tatsächliches Mobilgerät - für das iPhone. Die Hauptmessungen wurden mit dem 5S durchgeführt, und dann erhielt ich die Ergebnisse, als andere Geräte in meine Hände fielen. Wenn das Gerät nicht angegeben ist, ist es daher 5S.
Speicherzugriff
Für diesen Test wird ein spezielles Array verwendet, das mit Elementen gefüllt ist, die aufeinander verweisen. Jedes der Elemente ist ein Zeiger auf ein anderes Element. Das Array wird nicht vom Index durchlaufen, sondern von Übergängen von einem Knoten zum anderen. Diese Elemente sind über das Array verteilt, sodass sie beim Zugriff auf ein neues Element so oft wie möglich nicht im Cache, sondern aus dem RAM entladen wurden. Diese Anordnung stört die Caches so weit wie möglich.
Sie haben das vorläufige Ergebnis bereits gesehen. Im Fall des L1-Cache sind es weniger als 10 Nanosekunden, im Fall von L2 sind es einige zehn Nanosekunden, und im Fall des Hauptspeichers steigt die Zeit auf Hunderte von Nanosekunden.
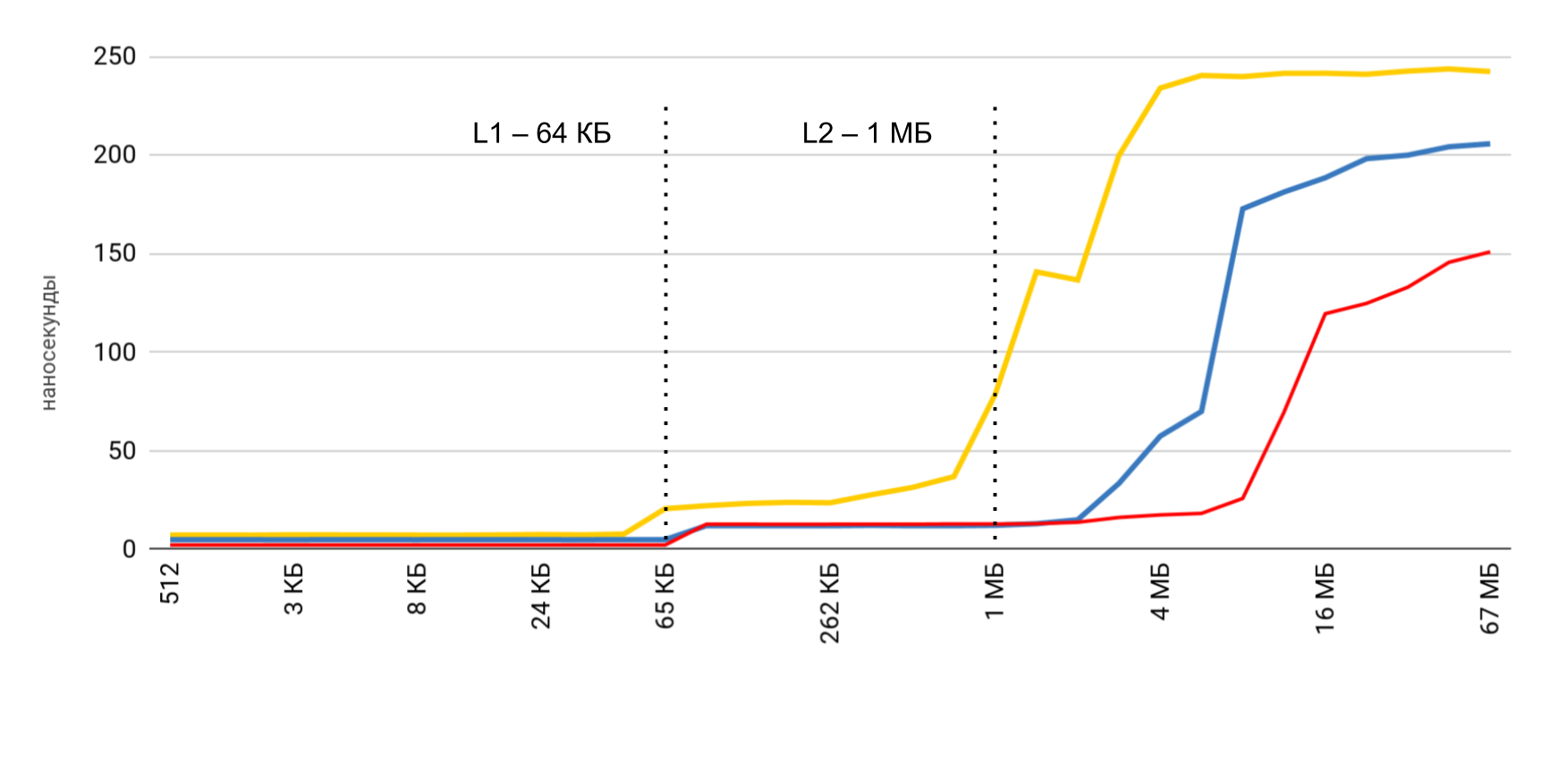
Lese- und Schreibgeschwindigkeit
Drei Hauptoperationen werden gemessen:
- Lesen ( p [i] + ) - Wir lesen die Elemente und addieren sie zum Gesamtbetrag.
- record ( p [i] = 1 ) - in jedes Element wird eine konstante Zahl geschrieben;
- Lesen und Schreiben ( p [i] = p [i] * 2 ) - Wir nehmen das Element heraus, ändern es und schreiben den neuen Wert zurück.
Bei der Arbeit mit dem Puffer werden zwei Ansätze verwendet: Im ersten Fall wird nur jedes vierte Element verwendet, und im zweiten Fall werden alle Elemente nacheinander verwendet.
Die höchste Geschwindigkeit wird mit einer kleinen Puffergröße erzielt, und dann gibt es klare Schritte entsprechend der Größe der L1- und L2-Caches. Das Interessanteste ist, dass beim sequentiellen Lesen von Daten keine Geschwindigkeitsreduzierung auftritt. Bei Pässen sind jedoch klare Schritte sichtbar.
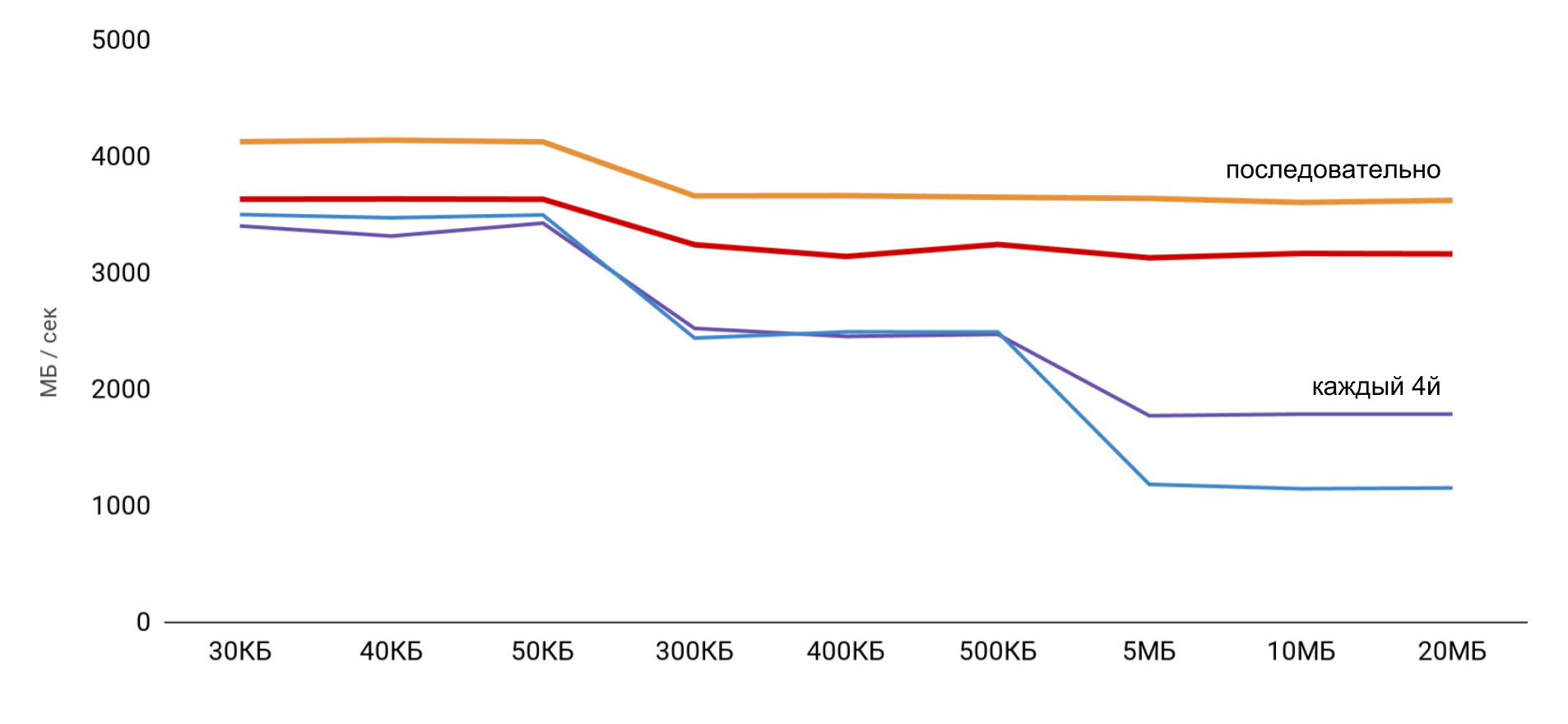
Während des sequentiellen Lesens gelingt es dem Betriebssystem, die erforderlichen Daten in den Cache zu laden, sodass ich für jede Puffergröße nicht auf den Speicher zugreifen muss - alle erforderlichen Daten werden aus dem Cache abgerufen. Dies erklärt, warum ich den Zeitunterschied in meinem Basistest nicht gesehen habe.
Die Ergebnisse von Messungen von Lese- und Schreibvorgängen zeigten, dass es bei einer normalen Anwendung ziemlich schwierig ist, die geschätzte Beschleunigung von 100 zu erhalten. Einerseits speichert das System selbst Daten recht gut zwischen, und selbst bei großen Arrays ist es sehr wahrscheinlich, dass wir Daten im Cache finden. Andererseits kann das Arbeiten mit verschiedenen Variablen leicht den Zugriff auf den Speicher und den Verlust von Hunderten von gewonnenen Nanosekunden erfordern.
| L1 | L2 | Speicher |
| Latenzzahlen | 1 ns | 7 ns | 100 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns |
| iPhone X. | 2 ns | 12 ns | 146 ns |
Threading-Kosten
Als nächstes wollte ich ähnliche Daten für die Arbeit mit Threads erhalten,
um die Kosten für die Verwendung von Multithreading zu
verstehen : Wie viel kostet es, einen Thread zu erstellen und von einem Thread zu einem anderen zu wechseln? Für uns sind dies häufige Operationen, und ich möchte den Verlust verstehen.
Instrumente. Systemablaufverfolgung
System Trace hilft sehr dabei, die Arbeit von Threads in der Anwendung zu verfolgen. Dieses Tool wurde auf der
WWDC 2016 ausführlich beschrieben. Das Tool hilft beim Erkennen von Übergängen nach Stream-Bedingungen und zeigt Daten zu Streams in drei Hauptkategorien an: Systemaufrufe, Arbeiten mit Speicher und Stream-Bedingungen.
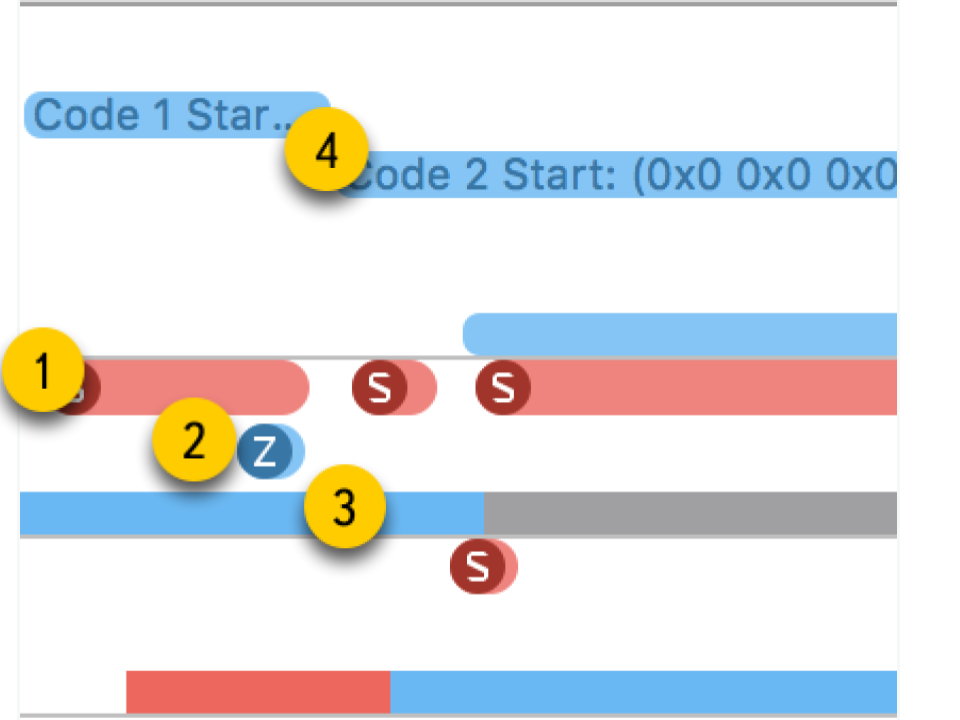
- Systemaufrufe Sie werden in Form von roten "Würstchen" präsentiert. Wenn Sie darauf zeigen, sehen Sie den Namen der Systemmethode und die Dauer der Ausführung. In Anwendungsanwendungen tritt ein solcher Systemaufruf häufig nicht direkt auf: Wir verwenden etwas, das wiederum bereits die Systemmethode aufruft. Sie sollten sich nicht darauf verlassen, dass hier die Methoden aus Ihrem Code sichtbar sind.
- Speicheroperationen . Sie werden in Form von blauen "Würstchen" präsentiert. Dies umfasst Vorgänge wie Speicherzuweisung, Freigeben, Nullstellen usw.
- Der Zustand des Streams . Blaue Farbe - Ein Thread wird ausgeführt, ein Prozessor führt Code aus diesem Thread aus. Grau - Der Thread ist aus irgendeinem Grund blockiert und kann die Ausführung nicht fortsetzen. Rot - Der Thread ist betriebsbereit, aber derzeit gibt es keinen freien Kernel, um seinen Code auszuführen. Orange Farbe - Der Fluss wird für Arbeiten mit höherer Priorität unterbrochen.
- Punkte von Interesse . Dies sind spezielle Beschriftungen, die durch Aufrufen von
kdebug_signpost nach Code angeordnet werden kdebug_signpost . Beschriftungen können einzeln (eine bestimmte Stelle im Code) oder als Bereich (um die gesamte Prozedur hervorzuheben) sein. Mit solchen Beschriftungen ist es viel einfacher, Mikrosekunden und Systemaufrufe mit Ihrer Anwendung zu korrelieren.
Kosten für die Stream-Erstellung
Der erste Test ist die
Ausführung einer Aufgabe in einem neuen Thread . Wir erstellen einen Thread mit einer bestimmten Prozedur und warten, bis er seine Arbeit abgeschlossen hat. Wenn wir die Gesamtzeit mit der Zeit für die Prozedur selbst vergleichen, erhalten wir den Gesamtverlust, um die Prozedur in einem neuen Thread zu starten.
In System Trace können Sie deutlich sehen, wie wirklich alles passiert:
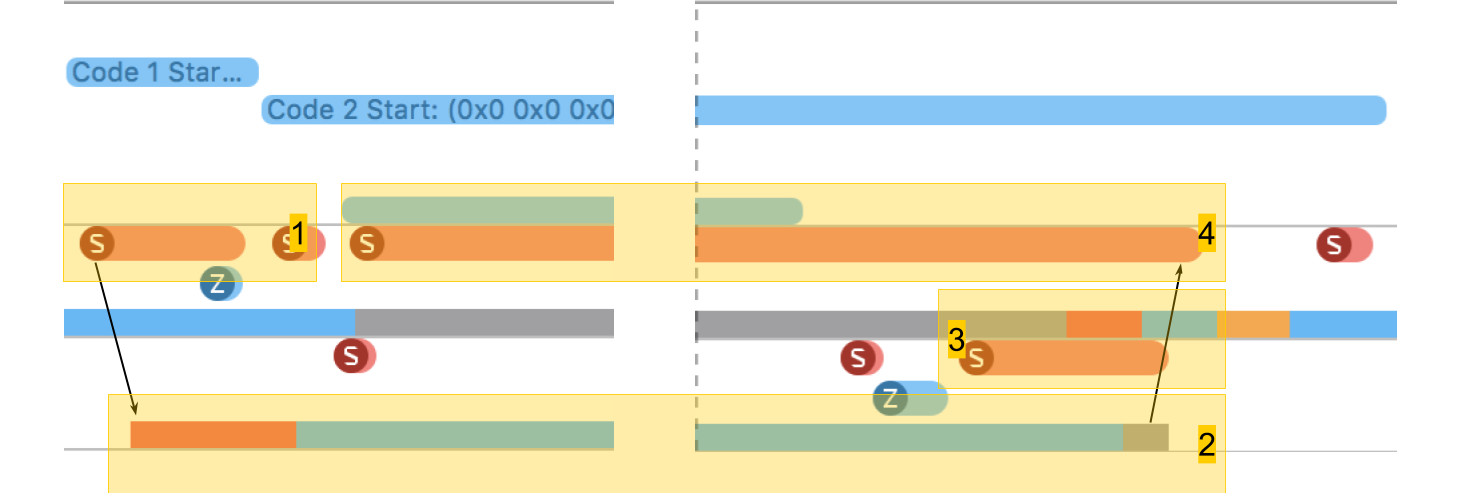
- Stream erstellen.
- Der neue Thread, in dem unsere Prozedur ausgeführt wird. Die rote Zone am Anfang besagt, dass der Thread erstellt wurde, aber für einige Zeit nicht ausgeführt werden konnte, da es keinen freien Kern gab.
- Die Fertigstellung des Streams. Interessanterweise ist das Thread-Vervollständigungsverfahren selbst noch größer als seine Erstellung. Obwohl es scheint, dass das Löschen immer schneller ist.
- Warten auf den Abschluss des Verfahrens, das im ursprünglichen Schema enthalten war, und es endet nach dem Ende des Streams - für eine Weile erkennt die Methode dies und meldet danach. Diese Zeit ist etwas länger als die Fertigstellung des Streams.
Das Erstellen eines Streams erfordert daher erhebliche Kosten: iPhone 5S - 230 Mikrosekunden, 6S - 50 Mikrosekunden.
Die Fertigstellung des Streams dauert fast zweimal länger als die Erstellung , die Verknüpfung dauert ebenfalls spürbar. Bei der Arbeit mit dem Speicher haben wir Hunderte von Nanosekunden erhalten, was 100-mal weniger als zehn Mikrosekunden entspricht.
| Overhead | erstellen | Ende | beitreten |
| iPhone 5s | 230 μs | 40 μs | 70 μs | 30 μs |
| iPhone 6s Plus | 50 μs | 12 μs | 20 μs | 7 μs |
Semaphor-Schaltzeit
Der nächste Test sind
Messungen an der Arbeit des Semaphors . Wir haben 2 vorgefertigte Threads, und für jeden von ihnen gibt es ein Semaphor. Streams signalisieren abwechselnd das Semaphor des Nachbarn und warten auf ihr eigenes. Streams geben sich gegenseitig Signale, spielen Ping-Pong und beleben sich gegenseitig. Diese doppelte Iteration ergibt eine doppelte Semaphorschaltzeit.
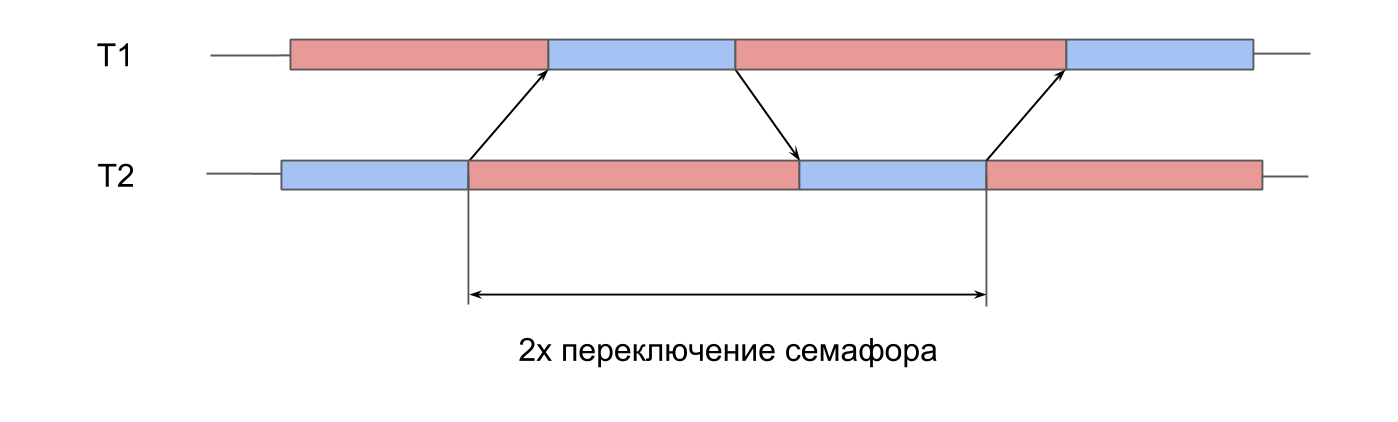
In System Trace sieht alles ähnlich aus:
- Für das Semaphor des zweiten Stroms wird ein Signal gegeben. Es ist ersichtlich, dass dieser Vorgang sehr kurz ist.
- Der zweite Thread wird entsperrt, das Warten auf sein Semaphor endet.
- Für das Semaphor des ersten Stroms wird ein Signal gegeben.
- Der erste Thread wird entsperrt, das Warten auf sein Semaphor endet.
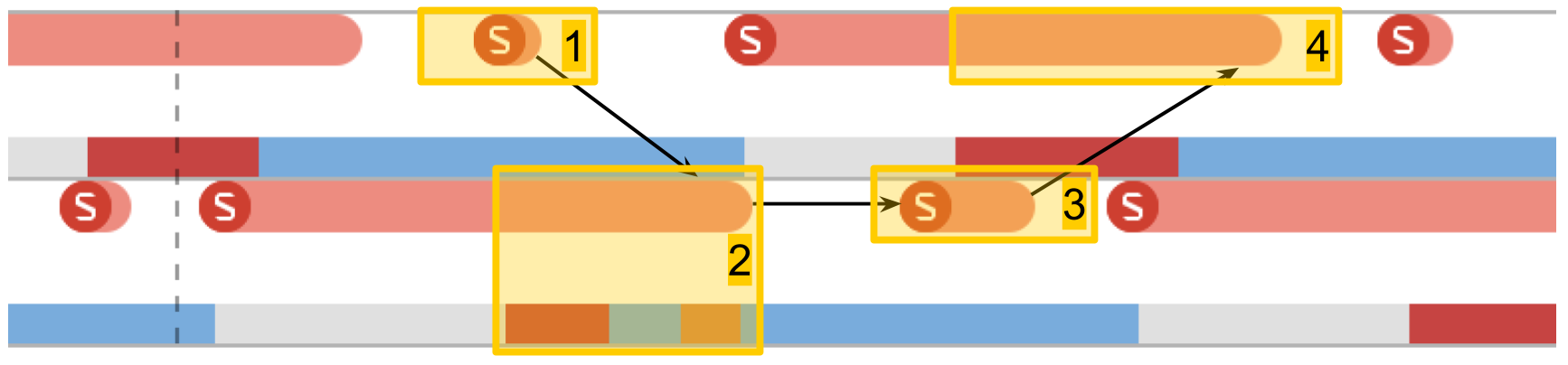
Die Schaltzeit betrug innerhalb von 10 Mikrosekunden. Der Unterschied zum 50-fachen Erstellen eines Threads ist genau der Grund, warum Thread-Pools erstellt werden, und nicht für jede Prozedur ein neuer Thread.
Verluste beim Umschalten des System-Thread-Kontexts
In den beiden vorherigen Tests wurde die Übertragung der Kontrolle zwischen den Threads vollständig kontrolliert - wir haben klar verstanden, wo und wo der Übergang stattfinden sollte. Es kommt jedoch häufig vor, dass das System selbst von einem Thread zu einem anderen wechselt. Wenn mehr Aufgaben parallel ausgeführt werden als die Kerne im Gerät, muss das Betriebssystem in der Lage sein, sich selbst zu wechseln, um allen Prozessoren Zeit zu geben.
In diesem Test wollte ich den Verlust beim Starten zu vieler Threads messen. Dazu wird ein Pool von 16 Threads erstellt, von denen jeder auf ein Semaphor wartet und sobald es ein Signal empfängt, eine bestimmte Prozedur ausführt und das Semaphor zurücksigniert. Der Haupt-Thread startet den gesamten Pool mit 16 Signalen und wartet danach 16 Signale als Antwort.
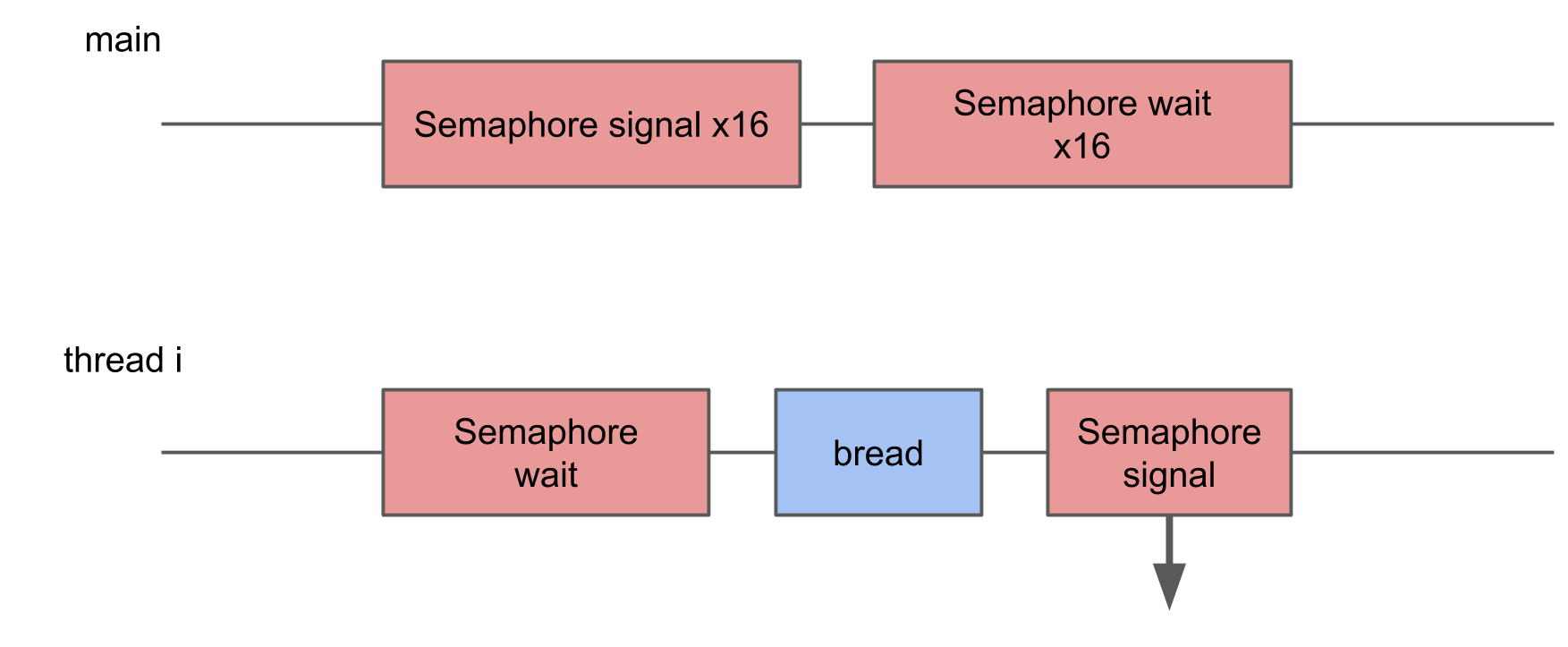
In System Trace können Sie sehen, dass die Blöcke zufällig verteilt sind, einige von ihnen sind viel länger als die anderen. Wenn mehrfaches Umschalten zu einer Verlängerung der Ausführungszeit der Operation führt, sollte sich die durchschnittliche Ausführungszeit infolgedessen erhöhen.
Mit zunehmender Anzahl von Threads erhöht sich jedoch die durchschnittliche Betriebszeit nicht.Theoretisch sollte die durchschnittliche Zeit so lange eingehalten werden, wie die Last der Verarbeitungsleistung entspricht. Das heißt, die Anzahl der Aufgaben entspricht der Anzahl der Kerne.
Wenn Sie viele Aufgaben parallel ausführen, führt das Betriebssystem beim Wechsel von einer Aufgabe zur anderen zu zusätzlichen Verzögerungen. Dies sollte sich im Ergebnis widerspiegeln.
In der Praxis funktioniert nicht nur unsere Anwendung auf dem Gerät, sondern es gibt immer noch viele parallele und Systemprozesse. Selbst der einzige Thread in unserer Anwendung wird vom Umschalten betroffen sein, was zu Unterbrechungen und Verzögerungen führt. Daher gibt es in allen Situationen Verzögerungen, und es gibt keinen Unterschied, ob Aufgaben in Reihe erstellt oder parallel ausgeführt werden sollen.

Unten finden Sie unsere Tabelle mit den Latenznummern mit Daten zu Flows und Semaphoren.
| L1 | L2 | Speicher | Semaphor |
| Latenzzahlen | 1 ns | 7 ns | 100 ns | 25 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs |
| iPhone X. | 2 ns | 12 ns | 146 ns | 3,2 μs |
Dateikosten
Wir haben bereits Speicher und Threads - der Vollständigkeit halber benötigen wir nur Dateisystemoperationen.
Datei lesen
Der erste Test ist die
Lesegeschwindigkeit - wie viel kostet das Lesen einer Datei? Der Test besteht aus zwei Teilen. Im ersten Schritt
messen wir
die Lesegeschwindigkeit unter Berücksichtigung des Öffnens, Lesens und Schließens der Datei. Im zweiten Fall
gehen wir
davon aus, dass die Datei ständig geöffnet ist : Wir positionieren uns irgendwo und lesen so viel, wie wir wollen.
Die Ergebnisse werden unter zwei Gesichtspunkten korrekt angezeigt.
Wenn die Datei klein ist , bleibt nur wenig Zeit, um Daten aus der Datei zu lesen. Bis zu einem Kilobyte sind 5,3 Mikrosekunden - egal: 1 Byte, 2 oder 1 KB - für alle 5,3 μs. Daher können Sie nur bei großen Dateien von Geschwindigkeit sprechen, wenn die festgelegte Zeit bereits vernachlässigt werden kann. Der Vorgang zum Öffnen und Schließen der Datei dauert für jede Dateigröße ungefähr dieselbe Zeit - im Fall von 5S etwa 50 Mikrosekunden.
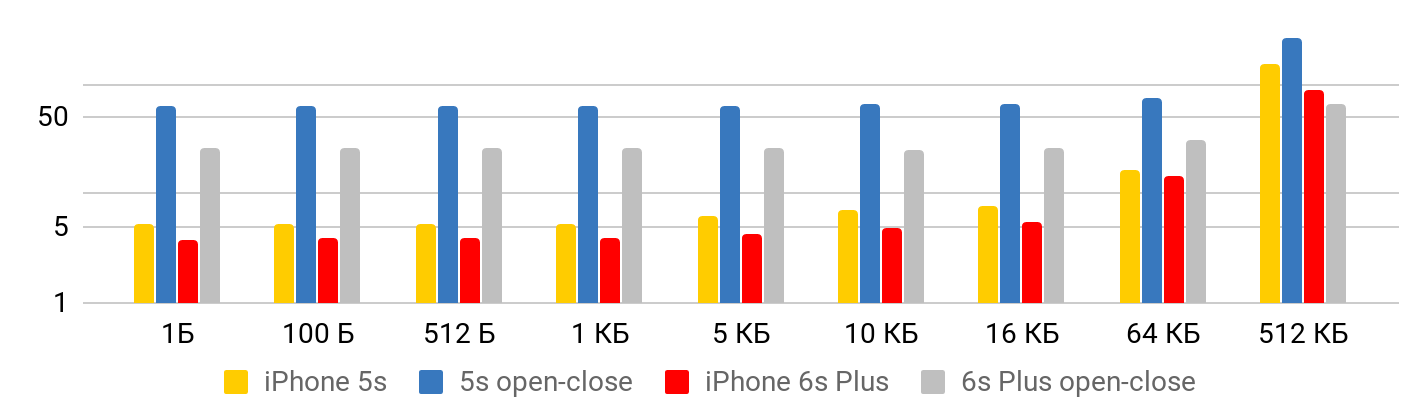
Für die Lesegeschwindigkeit werden solche Graphen erhalten.
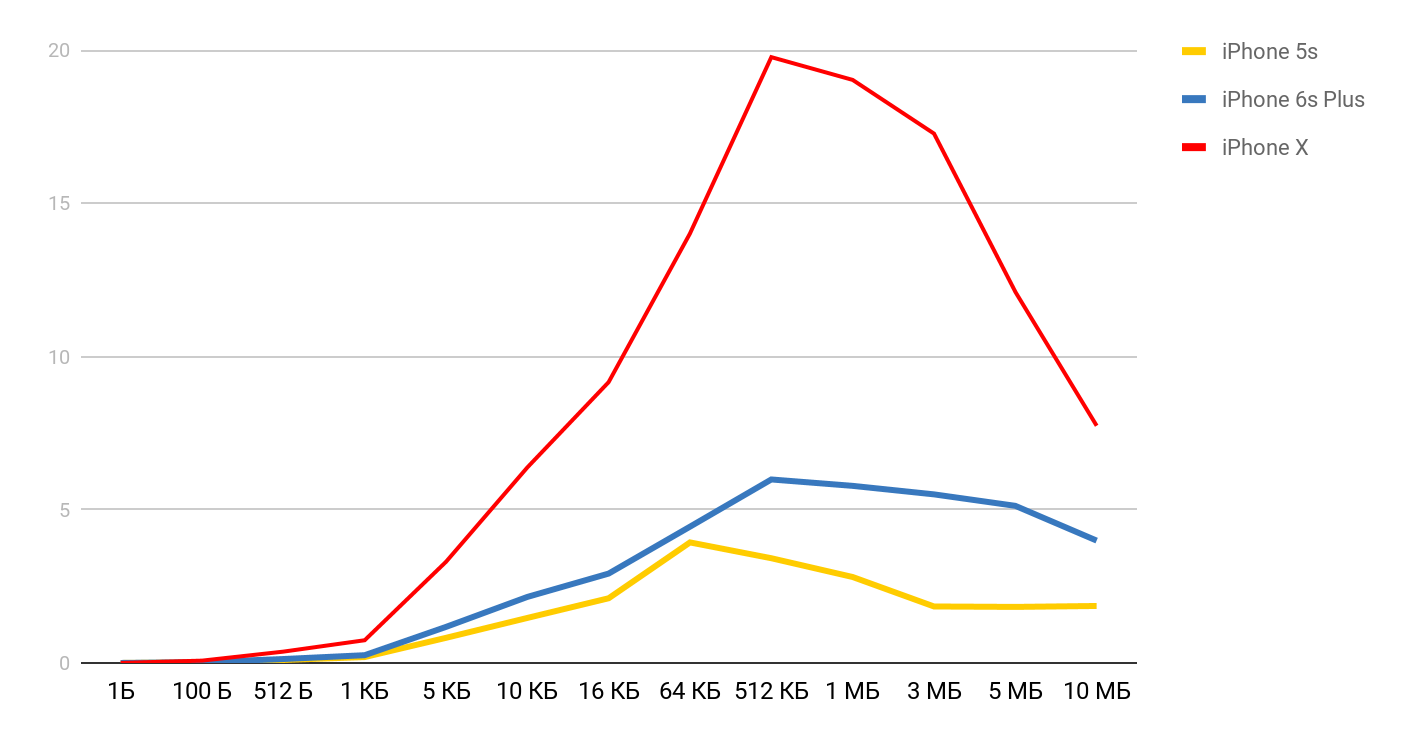
Für das iPhone X und eine Datei mit 1 MB kann die Geschwindigkeit 20 MB / s erreichen. Interessanterweise ist das Lesen einer 1-MB-Datei effizienter. Bei großen Dateien scheinen die Cache-Größen betroffen zu sein. Deshalb sinkt die Geschwindigkeit weiter und gleicht sich im Bereich von 10 Mb aus.
Dateien erstellen und löschen
Der Test besteht aus dem Schritt des
Erstellens einer Datei und des Schreibens von Daten sowie des
Löschens der erstellten Dateien. Das Ergebnis ist schrittweise: Bei kleinen Größen ist die Zeit stabil - etwa 7 μs - und wächst weiter. Die Skala ist logarithmisch.
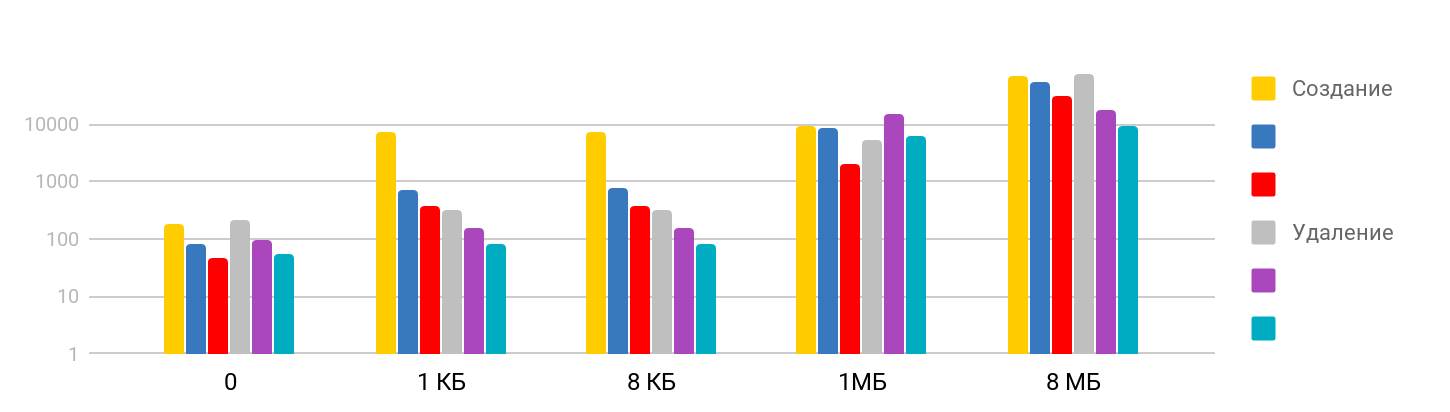
Ich war überrascht, dass die Zeit, die zum Löschen einer großen Datei benötigt wird, der Zeit entspricht, die zum Erstellen benötigt wird, da ich davon ausgegangen bin, dass das Löschen ein schneller Vorgang ist. Es stellt sich heraus, dass für das iPhone das rechtzeitige Löschen mit dem Erstellen einer Datei vergleichbar ist. Die Übersichtstabelle sieht folgendermaßen aus.
| L1 | L2 | Speicher | Semaphor | Festplatte |
| Latenzzahlen | 1 ns | 7 ns | 100 ns | 25 ns | 150 μs |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs | 5 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs | 4 μs |
| iPhone X. | 2 ns | 12 ns | 146 ns | 3,2 μs | 1,3 μs |
Fazit
Basierend auf diesen Messungen haben wir jetzt eine Vorstellung davon, wie viel Zeit die grundlegenden iOS-Vorgänge benötigen: Der Zugriff auf den Speicher dauert Nanosekunden, das Arbeiten mit Dateien dauert Mikrosekunden, das Erstellen eines Streams dauert mehrere zehn Sekunden und das Umschalten dauert nur wenige Mikrosekunden.
Um einen physisch wahrnehmbaren Hang in der Anwendung zu erhalten, muss die Ausführungszeit der Prozedur 15 Millisekunden überschreiten (die Zeit, die zum Aktualisieren des Bildschirms mit 60 fps benötigt wird). Dies ist fast tausendmal größer als die meisten Messungen im Artikel. In einem solchen Maßstab ist eine Millisekunde ziemlich viel, und eine Sekunde ist bereits "für immer".
Tests haben gezeigt, dass die direkte Verwendung dieses Verhältnisses trotz des großen Zeitunterschieds beim Zugriff auf Speicher und Caches ziemlich schwierig ist. Bevor Sie alle Ihre Daten unter L1 zusammenstellen, müssen Sie sicherstellen, dass in Ihrem Fall wirklich ein Ergebnis erzielt wird.
Gemäß den Tests von Operationen mit Threads konnten wir sicherstellen, dass das Erstellen und Zerstören von Threads viel Zeit in Anspruch nimmt, aber das Ausführen einer großen Anzahl paralleler Operationen keine zusätzlichen Kosten verursacht.
Abschließend möchte ich Sie an die wichtigste Regel bei der Arbeit an der Leistung erinnern -
erst Messungen und erst dann Optimierung !
Profilsprecher Dmitry Kurkin auf
GitHub .
Die Konvertierung und Umwandlung von AppsConf 2018-Berichten in Artikel erfolgt parallel zur Vorbereitung der brandneuen Konferenz 2019. Die Liste der akzeptierten Berichte enthält bisher nur 7 Themen. Diese Liste wird jedoch ständig erweitert, sodass vom 22. bis 23. April eine coole Konferenz für Entwickler von Mobilgeräten stattfindet.
Folgen Sie Veröffentlichungen, abonnieren Sie den Youtube-Kanal und den Newsletter und diese Zeit vergeht schnell.