Unbemannte Autos können nicht ohne Verständnis auskommen, was sich in der Nähe befindet und wo genau. Im Dezember letzten Jahres hielt der Entwickler Victor Otliga
vitonka einen Vortrag über die Erkennung von 3D-Objekten am
Data-Christmas-Baum . Victor arbeitet in Richtung unbemannter Fahrzeuge Yandex, in der Gruppe, die die Verkehrssituation behandelt (und unterrichtet auch am ShAD). Er erklärte, wie wir das Problem der Erkennung anderer Verkehrsteilnehmer in einer dreidimensionalen Punktwolke lösen, wie sich dieses Problem von der Erkennung von Objekten in einem Bild unterscheidet und wie wir von der gemeinsamen Nutzung verschiedener Sensortypen profitieren können.
- Hallo allerseits! Mein Name ist Victor Otliga, ich arbeite im Yandex-Büro in Minsk und entwickle unbemannte Fahrzeuge. Heute werde ich über eine ziemlich wichtige Aufgabe für Drohnen sprechen - die Erkennung von 3D-Objekten um uns herum.

Um zu fahren, muss man verstehen, was sich in der Nähe befindet. Ich werde Ihnen kurz sagen, welche Sensoren und Sensoren in unbemannten Fahrzeugen verwendet werden und welche wir verwenden. Ich werde Ihnen sagen, was die Aufgabe der Erkennung von 3D-Objekten ist und wie Sie die Qualität der Erkennung messen können. Dann werde ich Ihnen sagen, woran diese Qualität gemessen werden kann. Und dann werde ich einen kurzen Überblick über gute moderne Algorithmen geben, einschließlich derer, auf denen unsere Lösungen basieren. Und am Ende - kleine Ergebnisse, ein Vergleich dieser Algorithmen, einschließlich unserer.

So sieht unser funktionierender Prototyp eines unbemannten Autos jetzt aus. Ein solches Taxi kann von jedem ohne Fahrer in der russischen Stadt Innopolis sowie in Skolkovo gemietet werden. Und wenn Sie genau hinschauen, befindet sich oben ein großer Würfel. Was ist da drin?

In einem einfachen Satz von Sensoren. Es gibt eine GNSS- und GSM-Antenne, um festzustellen, wo sich das Auto befindet, und um mit der Außenwelt zu kommunizieren. Wo ohne so einen klassischen Sensor wie eine Kamera. Aber heute werden wir uns für Lidars interessieren.


Lidar erzeugt ungefähr eine solche Punktwolke um sich herum, die drei Koordinaten hat. Und du musst mit ihnen arbeiten. Ich werde Ihnen sagen, wie Sie mithilfe eines Kamerabilds und einer Lidarwolke Objekte erkennen können.
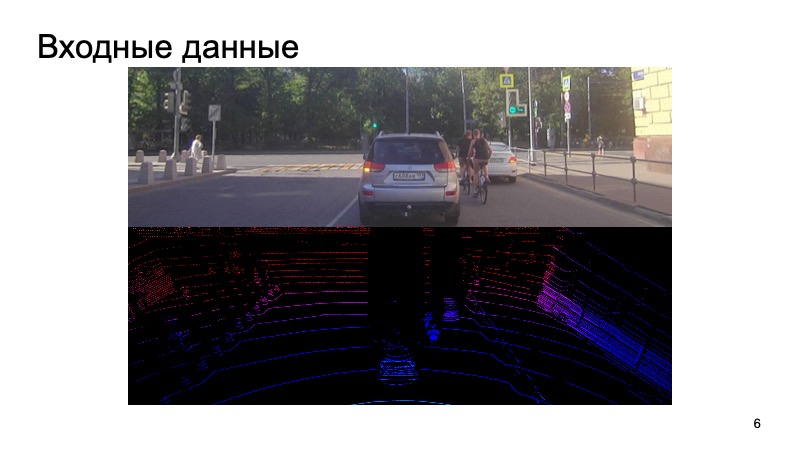
Was ist die Herausforderung? Das Bild von der Kamera wird in den Eingang eingegeben, die Kamera wird mit dem Lidar synchronisiert. Es wäre seltsam, das Bild von der Kamera vor einer Sekunde zu verwenden, die Lidarwolke aus einem ganz anderen Moment zu nehmen und zu versuchen, Objekte darauf zu erkennen.

Wir synchronisieren irgendwie Kameras und Lidars, dies ist eine separate schwierige Aufgabe, aber wir bewältigen sie erfolgreich. Solche Daten werden in die Eingabe eingegeben, und am Ende möchten wir Kästchen erhalten, Begrenzungskästchen, die das Objekt einschränken: Fußgänger, Radfahrer, Autos und andere Verkehrsteilnehmer und nicht nur.
Die Aufgabe wurde gestellt. Wie werden wir es bewerten?

Das Problem der 2D-Erkennung von Objekten in einem Bild wurde umfassend untersucht.
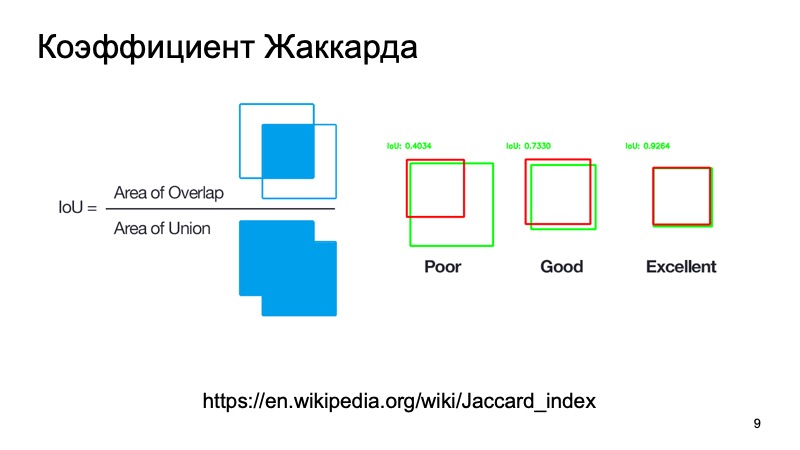
Sie können Standardmetriken oder deren Analoga verwenden. Es gibt einen Jacquard-Koeffizienten oder Schnittpunkt über der Vereinigung, einen wunderbaren Koeffizienten, der zeigt, wie gut wir ein Objekt erkannt haben. Wir können eine Box nehmen, in der sich, wie wir annehmen, das Objekt befindet, und eine Box, in der es sich tatsächlich befindet. Zählen Sie diese Metrik. Es gibt Standardschwellen - sagen wir, für Autos nehmen sie oft eine Schwelle von 0,7. Wenn dieser Wert größer als 0,7 ist, glauben wir, dass wir das Objekt erfolgreich erkannt haben und dass das Objekt dort ist. Wir sind großartig, wir können noch weiter gehen.
Um ein Objekt zu erkennen und zu verstehen, dass es sich irgendwo befindet, möchten wir außerdem das Vertrauen haben, dass wir das Objekt dort wirklich sehen, und es auch messen. Sie können einfach messen und die durchschnittliche Genauigkeit berücksichtigen. Sie können die Präzisionsrückrufkurve und den Bereich darunter nehmen und sagen: Je größer sie ist, desto besser.
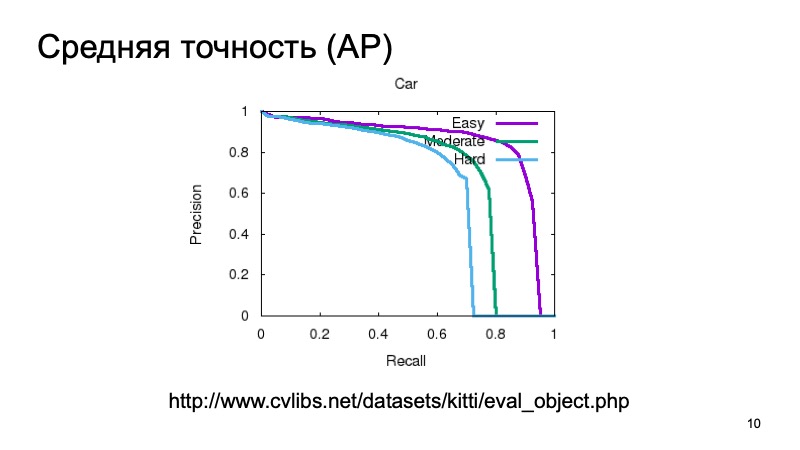
Um die Qualität der 3D-Erkennung zu messen, nehmen sie normalerweise einen Datensatz und teilen ihn in mehrere Teile auf, da Objekte nahe oder weiter entfernt sein können und teilweise durch etwas anderes verdeckt werden können. Daher ist die Validierungsstichprobe häufig in drei Teile unterteilt. Objekte, die leicht zu erkennen, von mittlerer Komplexität und komplex, entfernt oder stark verdeckt sind. Und sie messen getrennt in drei Teilen. Und in den Ergebnissen des Vergleichs werden wir auch eine solche Partition nehmen.
Sie können die Qualität wie in 3D messen, ein Analogon der Schnittmenge über der Vereinigung, jedoch nicht das Verhältnis der Flächen, sondern beispielsweise die Volumina. Aber einem unbemannten Auto ist es in der Regel egal, was in der Z-Koordinate vor sich geht. Wir können eine Vogelperspektive von oben betrachten und eine Art Metrik verwenden, als ob wir alles in 2D betrachten würden. Der Mensch wird mehr oder weniger in 2D navigiert, und ein unbemanntes Fahrzeug ist dasselbe. Wie hoch die Box ist, ist nicht sehr wichtig.

Was ist zu messen?

Wahrscheinlich hat jeder, der zumindest irgendwie vor der Aufgabe stand, die Lidarwolke in 3D zu erkennen, von einem Datensatz wie KITTI gehört.

In einigen Städten in Deutschland wurde ein Datensatz aufgezeichnet, ein mit Sensoren ausgestattetes Auto ging, es hatte GPS-Sensoren, Kameras und Lidars. Dann wurden ungefähr 8000 Szenen markiert und in zwei Teile geteilt. Ein Teil ist das Training, an dem jeder trainieren kann, und der zweite Teil ist die Validierung, um die Ergebnisse zu messen. Die KITTI-Validierungsprobe gilt als Qualitätsmaß. Erstens gibt es auf der KITTI-Datensatzseite eine Rangliste. Dort können Sie Ihre Entscheidung und Ihre Ergebnisse im Validierungsdatensatz senden und mit den Entscheidungen anderer Marktteilnehmer oder Forscher vergleichen. Aber auch dieser Datensatz ist öffentlich verfügbar. Sie können ihn herunterladen, niemandem mitteilen, Ihren eigenen überprüfen, mit Mitbewerbern vergleichen, aber nicht öffentlich hochladen.

Externe Datensätze sind gut, Sie müssen Ihre Zeit und Ressourcen nicht dafür aufwenden, aber in der Regel kann ein Auto, das nach Deutschland gereist ist, mit völlig anderen Sensoren ausgestattet werden. Und es ist immer gut, einen eigenen internen Datensatz zu haben. Darüber hinaus ist es schwieriger, ein externes Dataset auf Kosten anderer zu erweitern, aber es ist einfacher, Ihr eigenes zu verwalten. Deshalb nutzen wir den wunderbaren Yandex.Tolok-Service.

Wir haben unser spezielles Aufgabensystem fertiggestellt. Für den Benutzer, der beim Markup helfen und eine Belohnung dafür erhalten möchte, geben wir ein Bild von der Kamera aus, geben eine Lidarwolke aus, die Sie drehen, vergrößern, verkleinern können, und bitten ihn, Kästchen zu platzieren, die unsere Begrenzungsrahmen begrenzen, damit ein Auto oder ein Fußgänger in sie eindringt oder etwas anderes. Daher sammeln wir interne Proben für den persönlichen Gebrauch.
Angenommen, wir haben entschieden, welche Aufgabe wir lösen und wie wir davon ausgehen, dass wir es gut oder schlecht gemacht haben. Wir haben die Daten irgendwohin gebracht.
Was sind die Algorithmen? Beginnen wir mit 2D. Die Aufgabe der 2D-Erkennung ist sehr bekannt und untersucht.
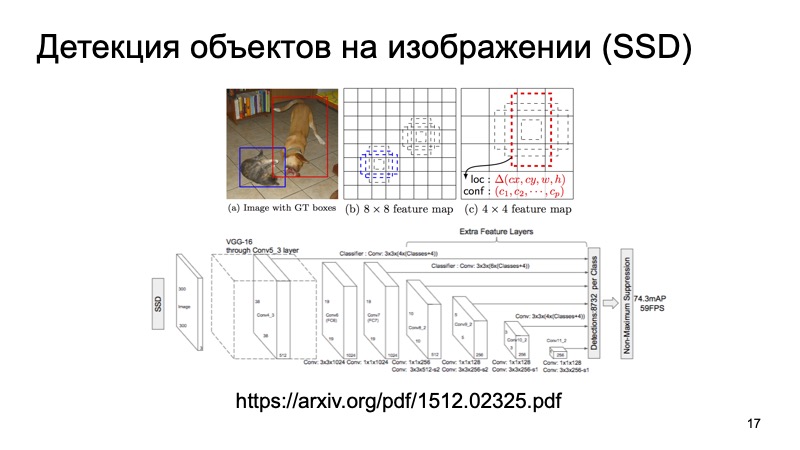
Sicherlich kennen viele Menschen den SSD-Algorithmus, der zu den modernsten Methoden zur Erkennung von 2D-Objekten gehört, und im Prinzip können wir davon ausgehen, dass das Problem der Erkennung von Objekten im Bild in gewisser Weise recht gut gelöst ist. Wenn überhaupt, können wir diese Ergebnisse als zusätzliche Informationen verwenden.
Unsere Lidarwolke hat jedoch ihre eigenen Eigenschaften, die sie stark vom Bild unterscheiden. Erstens ist es sehr spärlich. Wenn das Bild eine dichte Struktur hat, die Pixel nah sind, alles dicht ist, dann ist die Wolke sehr dünn, es gibt nicht so viele Punkte und es hat keine reguläre Struktur. Rein physisch gibt es dort viel mehr Punkte als in der Ferne, und je weiter Sie gehen, desto weniger Punkte gibt es, desto weniger Genauigkeit gibt es, desto schwieriger ist es, etwas zu bestimmen.
Nun, die Punkte aus der Wolke kommen im Prinzip in einer unverständlichen Reihenfolge. Niemand garantiert, dass ein Punkt immer früher als der andere ist. Sie kommen in relativ zufälliger Reihenfolge. Sie können sich irgendwie darauf einigen, sie zu sortieren oder im Voraus neu zu ordnen und erst dann Modelle an die Eingabe zu senden. Dies ist jedoch recht unpraktisch. Sie müssen Zeit aufwenden, um sie zu ändern, und so weiter.
Wir möchten ein System entwickeln, das für unsere Probleme unveränderlich ist und all diese Probleme löst. Glücklicherweise hat CVPR im vergangenen Jahr ein solches System vorgestellt. Es gab eine solche Architektur - PointNet. Wie arbeitet sie?

Am Eingang kommt eine Wolke von n Punkten mit jeweils drei Koordinaten an. Dann wird jeder Punkt irgendwie durch eine spezielle kleine Transformation standardisiert. Weiterhin wird es durch ein vollständig verbundenes Netzwerk gefahren, um diese Punkte mit Zeichen anzureichern. Dann findet wieder die Transformation statt und am Ende wird sie zusätzlich angereichert. Irgendwann werden n Punkte erhalten, aber jeder hat ungefähr 1024 Merkmale, sie sind irgendwie standardisiert. Bisher haben wir das Problem der Invarianz von Verschiebungen, Wendungen usw. noch nicht gelöst. Hier wird vorgeschlagen, Max-Pooling durchzuführen, das Maximum unter den Punkten auf jedem Kanal zu nehmen und einen Vektor mit 1024 Zeichen zu erhalten, der ein Deskriptor unserer Cloud ist und Informationen über die gesamte Cloud enthält. Und dann können Sie mit diesem Deskriptor viele verschiedene Dinge tun.
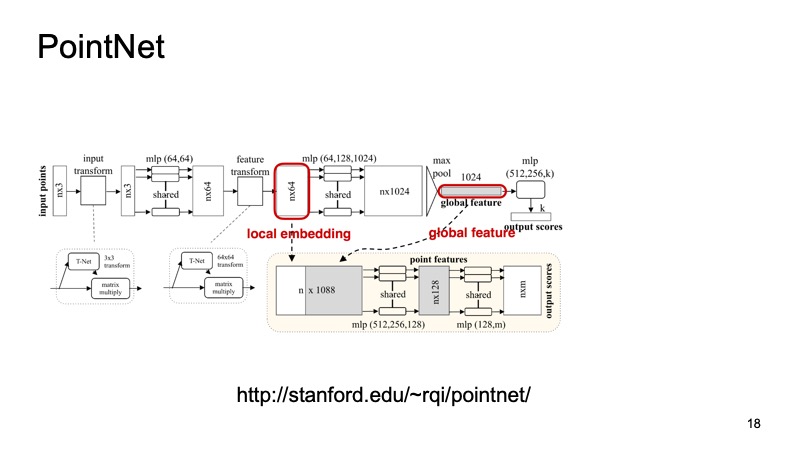
Sie können es beispielsweise auf die Deskriptoren einzelner Punkte kleben und das Segmentierungsproblem lösen, damit jeder Punkt bestimmt, zu welchem Objekt er gehört. Es ist nur eine Straße oder eine Person oder ein Auto. Und hier sind die Ergebnisse aus dem Artikel.

Möglicherweise stellen Sie fest, dass dieser Algorithmus sehr gute Arbeit leistet. Insbesondere gefällt mir die kleine Tabelle, in der einige Daten über die Arbeitsplatte weggeworfen wurden, sehr gut, und er hat trotzdem festgestellt, wo sich die Beine befinden und wo sich die Arbeitsplatte befindet. Insbesondere dieser Algorithmus kann als Baustein zum Aufbau weiterer Systeme verwendet werden.
Ein Ansatz, der dies verwendet, ist der Frustum PointNets-Ansatz oder der Ansatz der abgeschnittenen Pyramide. Die Idee ist ungefähr so: Lassen Sie uns Objekte in 2D erkennen, wir sind gut darin.
Wenn wir dann wissen, wie die Kamera funktioniert, können wir abschätzen, in welchem Bereich das für uns interessante Objekt, die Maschine, liegen kann. Schneiden Sie zum Projizieren nur diesen Bereich aus und lösen Sie bereits darauf das Problem, ein interessantes Objekt zu finden, beispielsweise eine Maschine. Dies ist viel einfacher als die Suche nach einer beliebigen Anzahl von Autos in der Cloud. Die Suche nach einem Auto genau in derselben Cloud scheint viel klarer und effizienter zu sein.
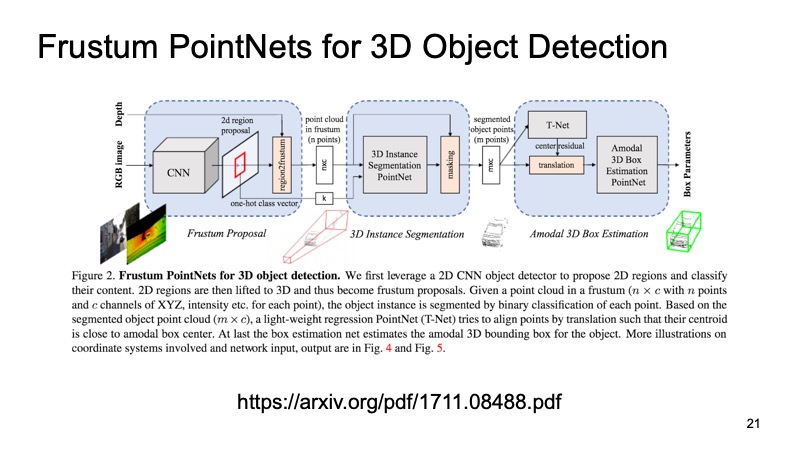
Die Architektur sieht ungefähr so aus. Zuerst wählen wir irgendwie die Regionen aus, die uns interessieren, in jeder Region, die wir segmentieren, und dann lösen wir das Problem, einen Begrenzungsrahmen zu finden, der das für uns interessante Objekt begrenzt.

Der Ansatz hat sich bewährt. Auf den Bildern sieht man, dass es ganz gut funktioniert, aber auch Nachteile hat. Der Ansatz ist zweistufig, daher kann er langsam sein. Wir müssen zuerst Netzwerke anwenden und 2D-Objekte erkennen, dann das Problem der Segmentierung und Zuordnung des Begrenzungsrahmens auf einem Teil der Wolke ausschneiden und dann lösen, damit es etwas langsam arbeiten kann.
Ein anderer Ansatz. Warum verwandeln wir unsere Wolke nicht in eine Art Struktur, die wie ein Bild aussieht? Die Idee ist folgende: Schauen wir es uns von oben an und probieren Sie unsere Lidarwolke. Wir bekommen Raumwürfel.
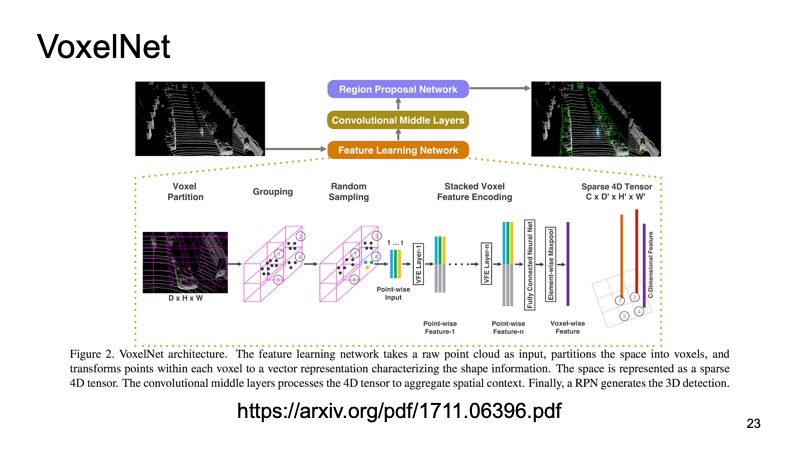
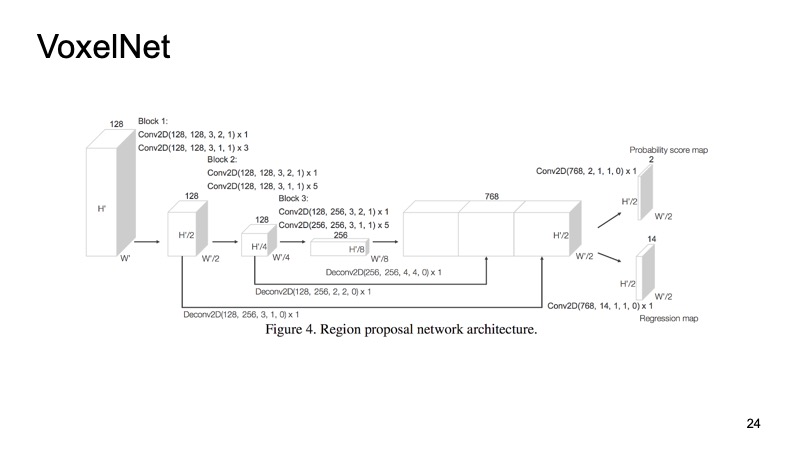
In jedem Würfel haben wir einige Punkte. Wir können einige Features auf ihnen zählen, aber wir können PointNet verwenden, das für jedes Stück Platz eine Art Deskriptor zählt. Wir werden ein Voxel bekommen, jedes Voxel hat eine charakteristische Beschreibung und es wird mehr oder weniger wie eine dichte Struktur aussehen, wie ein Bild. Wir können bereits verschiedene Architekturen erstellen, zum Beispiel eine SSD-ähnliche Architektur zum Erkennen von Objekten.
Letzterer Ansatz war einer der ersten Ansätze zum Kombinieren von Daten von mehreren Sensoren. Es wäre eine Sünde, nur Lidar-Daten zu verwenden, wenn wir auch Kameradaten haben. Einer dieser Ansätze wird als Multi-View 3D-Objekterkennungsnetzwerk bezeichnet. Seine Idee ist folgende: Drei Kanäle mit Eingabedaten in die Eingabe eines großen Netzwerks einspeisen.
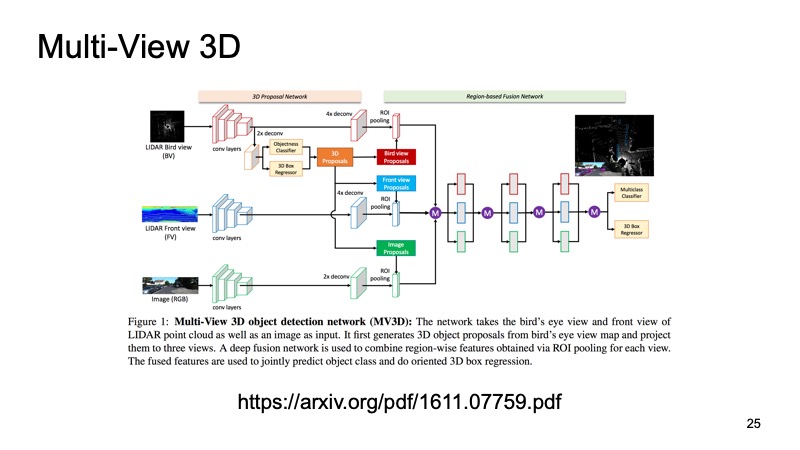
Dies ist ein Bild von der Kamera und in zwei Versionen eine Lidarwolke: von oben mit einer Vogelperspektive und einer Art Vorderansicht, was wir vor uns sehen. Wir übermitteln dies dem Eingang des Neurons, und es konfiguriert alles in sich selbst und gibt uns das Endergebnis - das Objekt.
Ich möchte diese Modelle vergleichen. Im KITTI-Datensatz wird auf Validierungslaufwerken die Qualität als Prozentsatz der durchschnittlichen Genauigkeit bewertet.
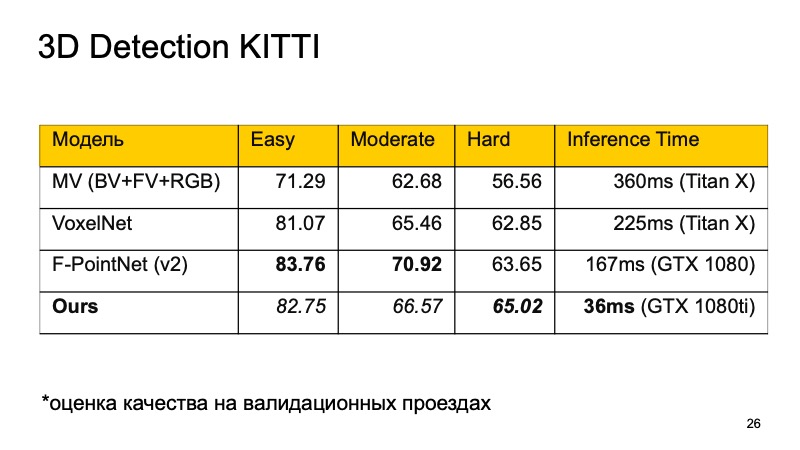
Sie werden vielleicht feststellen, dass F-PointNet recht gut und schnell genug funktioniert und alle anderen in verschiedenen Bereichen schlägt - zumindest laut den Autoren.
Unser Ansatz basiert auf mehr oder weniger allen Ideen, die ich aufgelistet habe. Wenn Sie vergleichen, erhalten Sie ungefähr das folgende Bild. Wenn wir nicht den ersten Platz einnehmen, dann zumindest den zweiten. Darüber hinaus brechen wir bei den Objekten, die schwer zu erkennen sind, in die Führer aus. Und vor allem ist unser Ansatz schnell genug. Dies bedeutet, dass es für Echtzeitsysteme bereits recht gut geeignet ist, und es ist besonders wichtig, dass ein unbemanntes Fahrzeug überwacht, was auf der Straße passiert, und alle diese Objekte hervorhebt.

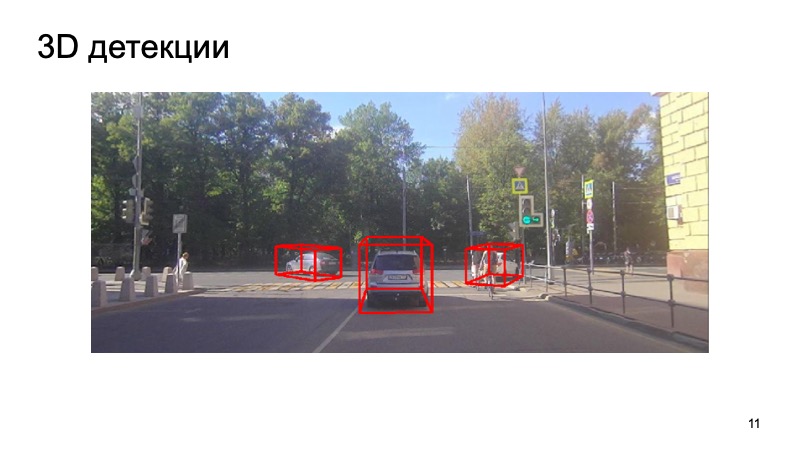
Fazit - ein Beispiel für unseren Detektor:
Es ist ersichtlich, dass die Situation kompliziert ist: Einige der Objekte sind geschlossen, andere für die Kamera nicht sichtbar. Fußgänger, Radfahrer. Aber der Detektor kommt gut genug zurecht. Vielen Dank!