Dies ist ein neuer Artikel aus einer
Diskussion von Aufgaben aus Interviews in Google . Als ich dort arbeitete, bot ich Kandidaten solche Aufgaben an. Dann gab es ein Leck und sie wurden verboten. Aber die Münze hat eine Kehrseite: Jetzt kann ich die Lösung frei erklären.
Tolle Neuigkeiten für den Anfang: Ich habe Google verlassen! Ich freue mich, Ihnen mitteilen zu können, dass ich jetzt als technischer Manager von Reddit in New York arbeite! Diese Artikelserie wird jedoch weiterhin fortgesetzt.
Haftungsausschluss: Obwohl das Befragen von Kandidaten eine meiner beruflichen Aufgaben ist, teile ich in diesem Blog persönliche Beobachtungen, Geschichten und persönliche Meinungen. Bitte betrachten Sie dies nicht als offizielle Erklärung von Google, Alphabet, Reddit, einer anderen Person oder Organisation.Frage
Nach den
letzten beiden Artikeln über die Fortschritte des Pferdes beim Wählen einer Telefonnummer erhielt ich Kritik, dass dies kein realistisches Problem ist. Egal wie nützlich es ist, die Denkfähigkeiten des Kandidaten zu studieren, ich muss zugeben: Die Aufgabe ist wirklich ein wenig unrealistisch. Obwohl ich einige Gedanken über den Zusammenhang zwischen Interviewfragen und Realität habe, werde ich sie mir vorerst überlassen. Seien Sie sicher, ich lese überall Kommentare und habe etwas zu beantworten, aber nicht jetzt.
Aber als die Aufgabe, das Pferd zu übergeben, vor einigen Jahren verboten wurde, nahm ich mir Kritik zu Herzen und versuchte, sie durch eine Frage zu ersetzen, die für den Umfang von Google etwas relevanter ist. Und was kann für Google relevanter sein als die Mechanik von Suchanfragen? Also habe ich diese Frage gefunden und lange benutzt, bevor sie auch öffentlich wurde und verboten wurde. Nach wie vor werde ich die Frage formulieren, in ihre Erklärung eintauchen und dann erzählen, wie ich sie in Interviews verwendet habe und warum sie mir gefällt.
Die Frage ist also.
Stellen Sie sich vor, Sie verwalten eine beliebte Suchmaschine und sehen zwei Anfragen in den Protokollen: "Obamas Zustimmungsrate" und "Obamas Beliebtheitsgrad" (wenn ich mich richtig erinnere, sind dies echte Beispiele aus der Fragenbasis, obwohl sie jetzt etwas veraltet sind ...) . Wir sehen unterschiedliche Abfragen, aber alle sind sich einig: Benutzer suchen im Wesentlichen nach denselben Informationen. Daher sollten Abfragen beim Zählen der Anzahl der Abfragen, Anzeigen von Ergebnissen usw. als gleichwertig angesehen werden.
Wie stellen Sie fest, ob zwei Abfragen synonym sind?Lassen Sie uns die Aufgabe formalisieren. Angenommen, es gibt zwei Sätze von Zeichenfolgenpaaren: Synonympaare und Abfragepaare.
Im Folgenden finden Sie eine Beispieleingabe zur Veranschaulichung:
SYNONYMS = [ ('rate', 'ratings'), ('approval', 'popularity'), ] QUERIES = [ ('obama approval rate', 'obama popularity ratings'), ('obama approval rates', 'obama popularity ratings'), ('obama approval rate', 'popularity ratings obama') ]
Es ist notwendig, eine Liste logischer Werte zu erstellen: Sind die Abfragen in jedem Paar synonym.
Alle neuen Fragen ...
Auf den ersten Blick ist dies eine einfache Aufgabe. Aber je länger Sie denken, desto schwieriger wird es. Kann ein Wort mehrere Synonyme haben? Ist die Wortreihenfolge wichtig? Sind synonym Beziehungen transitiv, dh wenn A gleichbedeutend mit B ist und B gleichbedeutend mit C ist, ist A ein Synonym für C? Können Synonyme ein paar Wörter umfassen, wie ist "USA" ein Synonym für die Ausdrücke "Vereinigte Staaten von Amerika" oder "Vereinigte Staaten"?
Eine solche Mehrdeutigkeit ermöglicht es sofort, sich einem guten Kandidaten zu beweisen. Das erste, was er tut, ist, solche Unklarheiten zu suchen und zu lösen. Jeder tut dies auf unterschiedliche Weise: Einige nähern sich dem Board und versuchen, bestimmte Fälle manuell zu lösen, während andere die Frage betrachten und sofort die Lücken erkennen. In jedem Fall ist es entscheidend, diese Probleme frühzeitig zu erkennen.
Die Phase des "Verständnisses des Problems" ist von großer Bedeutung. Ich nenne Software Engineering gerne eine fraktale Disziplin. Wie Fraktale zeigt die Approximation zusätzliche Komplexität. Sie denken, Sie verstehen das Problem und schauen es sich dann genauer an - und Sie sehen, dass Sie einige Feinheiten oder Details der Implementierung übersehen haben, die verbessert werden können. Oder eine andere Herangehensweise an das Problem.
 Mandelbrot gesetztDas Kaliber eines Ingenieurs hängt weitgehend davon ab, wie tief er das Problem verstehen kann.
Mandelbrot gesetztDas Kaliber eines Ingenieurs hängt weitgehend davon ab, wie tief er das Problem verstehen kann. Die Umwandlung einer vagen Erklärung des Problems in einen detaillierten Satz von Anforderungen ist der erste Schritt in diesem Prozess. Durch gezieltes Understatement können Sie bewerten, wie gut der Kandidat für neue Situationen geeignet ist.
Wir lassen triviale Fragen wie „Sind Großbuchstaben wichtig?“ Abgesehen, die den Hauptalgorithmus nicht beeinflussen. Ich gebe immer die einfachste Antwort auf diese Fragen (in diesem Fall „Angenommen, alle Buchstaben sind bereits vorverarbeitet und werden in Kleinbuchstaben umgewandelt“).Teil 1. (nicht ganz) ein einfacher Fall
Wenn Kandidaten Fragen stellen, beginne ich immer mit dem einfachsten Fall: Ein Wort kann mehrere Synonyme haben, die Reihenfolge der Wörter ist wichtig, Synonyme sind nicht transitiv. Dies gibt der Suchmaschine eine recht eingeschränkte Funktionalität, verfügt jedoch über genügend Feinheiten für ein interessantes Interview.
Eine allgemeine Übersicht lautet wie folgt: Teilen Sie die Abfrage in Wörter auf (z. B. durch Leerzeichen) und vergleichen Sie die entsprechenden Paare, um nach identischen Wörtern und Synonymen zu suchen. Optisch sieht es so aus:
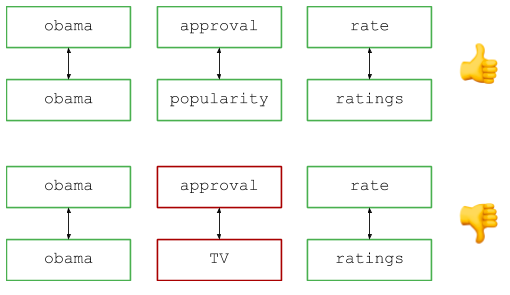
Im Code:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif words_are_synonyms(w1, w2): continue result = False break output.append(result) return output
Einfach, oder? Algorithmisch ist es ziemlich einfach. Keine dynamische Programmierung, Rekursion, komplexe Strukturen usw. Einfache Manipulation der Standardbibliothek und eines Algorithmus, der in linearer Zeit arbeitet, oder?
Aber es gibt mehr Nuancen, als es auf den ersten Blick scheint. Die schwierigste Komponente ist natürlich der Vergleich von Synonymen. Obwohl die Komponente leicht zu verstehen und zu beschreiben ist, gibt es viele Möglichkeiten, einen Fehler zu machen. Ich erzähle Ihnen von den häufigsten Fehlern.
Aus Gründen der Klarheit: Keine Fehler disqualifizieren einen Kandidaten. Wenn das so ist, weise ich nur auf einen Fehler in der Implementierung hin, der behoben wird, und wir fahren fort. Ein Interview ist jedoch in erster Linie ein Kampf gegen die Zeit. Sie werden Fehler machen, bemerken und korrigieren, aber es braucht Zeit, die für einen anderen aufgewendet werden kann, um beispielsweise eine optimalere Lösung zu finden. Fast jeder macht Fehler, das ist normal, aber Kandidaten, die sie kleiner machen, zeigen bessere Ergebnisse, einfach weil sie weniger Zeit damit verbringen, sie zu korrigieren.
Deshalb mag ich dieses Problem. Wenn der Schritt eines Ritters einen Einblick in das Verständnis des Algorithmus und dann (ich hoffe) eine einfache Implementierung erfordert, dann ist die Lösung viele Schritte in die richtige Richtung. Jeder Schritt stellt ein winziges Hindernis dar, durch das der Kandidat entweder anmutig springen oder stolpern und sich erheben kann. Dank Erfahrung und Intuition vermeiden gute Kandidaten diese kleinen Fallstricke - und erhalten eine detailliertere und korrektere Lösung, während schwächere Zeit und Energie für Fehler aufwenden und normalerweise beim falschen Code bleiben.
Bei jedem Interview sah ich eine andere Kombination aus Erfolg und Misserfolg. Dies sind die häufigsten Fehler.
Zufällige Leistungskiller
Erstens haben einige Kandidaten die Synonymerkennung implementiert, indem sie einfach die Liste der Synonyme durchlaufen haben:
... elif (w1, w2) in synonym_words: continue ...
Auf den ersten Blick erscheint dies vernünftig. Bei näherer Betrachtung ist die Idee jedoch sehr, sehr schlecht. Für diejenigen unter Ihnen, die Python nicht kennen, ist das Schlüsselwort in syntaktischer Zucker für die Methode includes und funktioniert auf allen Standard-Python-Containern. Dies ist ein Problem, da
synonym_words eine Liste ist, die das Schlüsselwort in mithilfe der linearen Suche implementiert. Python-Benutzer reagieren besonders empfindlich auf diesen Fehler, da die Sprache Typen verbirgt. C ++ - und Java-Benutzer haben jedoch manchmal ähnliche Fehler gemacht.
Im Laufe meiner Karriere habe ich nur einige Male mit linearem Suchcode geschrieben und jeweils auf einer Liste von nicht mehr als zwei Dutzend Elementen. Und selbst in diesem Fall schrieb er einen langen Kommentar, in dem er erklärte, warum er sich für einen scheinbar suboptimalen Ansatz entschieden hatte. Ich vermute, dass einige Kandidaten es einfach verwendet haben, weil sie nicht wussten, wie das Schlüsselwort in in Listen in der Python-Standardbibliothek funktioniert. Dies ist ein einfacher Fehler, nicht tödlich, aber eine schlechte Kenntnis Ihrer Lieblingssprache ist nicht sehr gut.
In der Praxis wird dieser Fehler leicht vermieden. Vergessen Sie niemals Ihre Objekttypen, auch wenn Sie eine untypisierte Sprache wie Python verwenden! Denken Sie zweitens daran, dass eine lineare Suche beginnt, wenn Sie das Schlüsselwort
in in der Liste verwenden. Wenn es keine Garantie gibt, dass diese Liste immer sehr klein bleibt, wird die Leistung beeinträchtigt.
Damit der Kandidat zur Besinnung kommt, reicht es normalerweise aus, ihn daran zu erinnern, dass die Eingabestruktur eine Liste ist. Es ist sehr wichtig zu beobachten, wie der Kandidat auf die Aufforderung reagiert. Die besten Kandidaten versuchen sofort, die Synonyme irgendwie vorzuverarbeiten, was ein guter Anfang ist. Dieser Ansatz ist jedoch nicht ohne Fallstricke ...
Verwenden Sie die richtige Datenstruktur
Aus dem obigen Code wird sofort klar, dass es zur Implementierung dieses Algorithmus in linearer Zeit notwendig ist, Synonyme schnell zu finden. Und wenn wir über schnelle Suchen sprechen, ist es immer eine Karte oder eine Reihe von Hashes.
Es ist mir egal, ob der Kandidat eine Karte oder eine Reihe von Hashes auswählt. Das Wichtigste ist, dass er es dort ablegt (verwenden Sie übrigens niemals Diktat / Hashmap beim Übergang zu
True oder
False ). Die meisten Kandidaten wählen eine Art Diktat / Hashmap. Der häufigste Fehler ist die unbewusste Annahme, dass jedes Wort nicht mehr als ein Synonym hat:
... synonyms = {} for w1, w2 in synonym_words: synonyms[w1] = w2 ... elif synonyms[w1] == w2: continue
Ich bestrafe keine Kandidaten für diesen Fehler. Die Aufgabe ist speziell formuliert, um sich nicht auf die Tatsache zu konzentrieren, dass Wörter mehrere Synonyme haben können, und einige Kandidaten sind einfach nicht auf eine solche Situation gestoßen. Beheben Sie am schnellsten einen Fehler, wenn ich darauf zeige. Gute Kandidaten bemerken es früh und verbringen normalerweise nicht viel Zeit.
Ein etwas schwerwiegenderes Problem ist das mangelnde Bewusstsein, dass sich die Beziehung der Synonyme in beide Richtungen ausbreitet. Beachten Sie, dass dies im obigen Code berücksichtigt wird. Es gibt jedoch Implementierungen mit einem Fehler:
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) synonyms[w2].append(w1) ... elif w2 in synonyms.get(w1, tuple()): continue
Warum zwei Einfügungen und doppelt so viel Speicher verwenden?
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) ... elif (w2 in synonyms.get(w1, tuple()) or w1 in synonyms.get(w2, tuple())): continue
Fazit: Überlegen Sie
immer, wie Sie den Code optimieren können ! Rückblickend ist die Permutation der Suchfunktionen eine offensichtliche Optimierung, ansonsten können wir den Schluss ziehen, dass der Kandidat nicht über Optimierungsoptionen nachgedacht hat. Auch hier gebe ich gerne einen Hinweis, aber es ist besser, selbst zu raten.
Sortieren?
Einige intelligente Kandidaten möchten die Liste der Synonyme sortieren und dann die binäre Suche verwenden. Tatsächlich hat dieser Ansatz einen wichtigen Vorteil: Er benötigt keinen zusätzlichen Platz, außer für die Liste der Synonyme (vorausgesetzt, die Liste darf geändert werden).
Leider stört die Zeitkomplexität: Das Sortieren einer Liste von Synonymen erfordert
Nlog(N) und dann ein weiteres
log(N) , um nach jedem Synonympaar zu suchen, während die beschriebene Vorverarbeitungslösung in linearer und dann konstanter Zeit erfolgt. Darüber hinaus bin ich kategorisch dagegen, den Kandidaten zu zwingen, Sortierung und binäre Suche an der Tafel zu implementieren, weil: 1) die Sortieralgorithmen bekannt sind, daher kann der Kandidat sie meines Wissens ohne nachzudenken ausgeben; 2) Diese Algorithmen sind teuflisch schwer korrekt zu implementieren, und oft machen sogar die besten Kandidaten Fehler, die nichts über ihre Programmierkenntnisse aussagen.
Wann immer ein Kandidat eine solche Lösung vorschlug, war ich an der Ausführungszeit des Programms interessiert und fragte, ob es eine bessere Option gäbe. Zur Information: Wenn der Interviewer Sie fragt, ob es eine bessere Option gibt, lautet die Antwort fast immer Ja. Wenn ich Ihnen diese Frage jemals stelle, wird die Antwort sicherlich die folgende sein.
Endlich Lösung
Am Ende bietet der Kandidat etwas Richtiges und einigermaßen Optimales. Hier ist eine Implementierung in linearer Zeit und linearem Raum für gegebene Bedingungen:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].add(w2) output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif ((w1 in synonyms and w2 in synonyms[w1]) or (w2 in synonyms and w1 in synonyms[w2])): continue result = False break output.append(result) return output
Ein paar kurze Anmerkungen:
- Beachten Sie die Verwendung von
dict.get() . Sie können eine Überprüfung durchführen, um festzustellen, ob der Schlüssel im Diktat enthalten ist, und ihn dann abrufen. Dies ist jedoch ein komplizierter Ansatz, obwohl Sie auf diese Weise Ihr Wissen über die Standardbibliothek zeigen. - Ich persönlich bin kein Fan von Code mit häufigem
continue , und einige Styleguides verbieten oder empfehlen sie nicht . Ich selbst habe in der ersten Ausgabe dieses Codes die continue Anweisung vergessen, nachdem ich die Länge der Anfrage überprüft hatte. Dies ist kein schlechter Ansatz. Sie müssen nur wissen, dass er fehleranfällig ist.
Teil 2: Immer härter!
Gute Kandidaten haben nach der Lösung des Problems noch zehn bis fünfzehn Minuten Zeit. Glücklicherweise gibt es eine Reihe zusätzlicher Fragen, obwohl es unwahrscheinlich ist, dass wir in dieser Zeit viel Code schreiben werden. Dies ist jedoch nicht erforderlich. Ich möchte zwei Dinge über den Kandidaten wissen: Ist er in der Lage, Algorithmen zu entwickeln und kann er codieren? Das Problem mit dem Zug des Ritters beantwortet zuerst die Frage nach der Entwicklung des Algorithmus und überprüft dann die Codierung. Hier erhalten wir die Antworten in umgekehrter Reihenfolge.
Als der Kandidat den ersten Teil der Frage abgeschlossen hatte, hatte er das Problem bereits mit (überraschend nicht trivialer) Codierung gelöst. In dieser Phase kann ich zuversichtlich über seine Fähigkeit sprechen, rudimentäre Algorithmen zu entwickeln und Ideen in Code zu übersetzen, sowie über seine Bekanntschaft mit seiner Lieblingssprache und Standardbibliothek. Jetzt wird das Gespräch viel interessanter, weil die Programmieranforderungen gelockert werden können und wir uns mit den Algorithmen befassen werden.
Zu diesem Zweck kehren wir zu den Hauptpostulaten des ersten Teils zurück: Die Wortreihenfolge ist wichtig, Synonyme sind nicht transitiv und für jedes Wort können mehrere Synonyme vorhanden sein. Im Verlauf des Interviews ändere ich jede dieser Einschränkungen, und in dieser neuen Phase führen der Kandidat und ich eine rein algorithmische Diskussion. Hier werde ich Codebeispiele geben, um meinen Standpunkt zu veranschaulichen, aber in einem echten Interview sprechen wir nur über Algorithmen.
Bevor ich anfange, erkläre ich meine Position: Alle nachfolgenden Aktionen in dieser Phase des Interviews sind hauptsächlich „Bonuspunkte“. Mein persönlicher Ansatz ist es, Kandidaten zu identifizieren, die genau die erste Phase durchlaufen und für die Arbeit geeignet sind. Die zweite Stufe wird benötigt, um das Beste hervorzuheben. Die erste Bewertung ist bereits sehr stark und bedeutet, dass der Kandidat gut genug für das Unternehmen ist, und die zweite Bewertung besagt, dass der Kandidat ausgezeichnet ist und seine Einstellung ein großer Sieg für uns sein wird.
Transitivität: Naive Ansätze
Zunächst möchte ich die Transitivitätsbeschränkung entfernen. Wenn also die Paare A - B und B - C Synonyme sind, sind die Wörter A und C auch Synonyme. Intelligente Kandidaten werden schnell verstehen, wie sie ihre vorherige Lösung anpassen können, obwohl mit der weiteren Beseitigung anderer Einschränkungen die grundlegende Logik des Algorithmus nicht mehr funktioniert.
Wie kann man es jedoch anpassen? Ein üblicher Ansatz besteht darin, einen vollständigen Satz von Synonymen für jedes Wort basierend auf transitiven Beziehungen beizubehalten. Jedes Mal, wenn wir ein Wort in eine Reihe von Synonymen einfügen, fügen wir es auch den entsprechenden Mengen für alle Wörter in dieser Menge hinzu:
synonyms = defaultdict(set) for w1, w2 in synonym_words: for w in synonyms[w1]: synonyms[w].add(w2) synonyms[w1].add(w2) for w in synonyms[w2]: synonyms[w].add(w1) synonyms[w2].add(w1)
Bitte beachten Sie, dass wir uns beim Erstellen des Codes bereits mit dieser Lösung befasst haben.Diese Lösung funktioniert, ist aber alles andere als optimal. Um die Gründe zu verstehen, schätzen wir die räumliche Komplexität dieser Lösung. Jedes Synonym muss nicht nur zur Menge des Anfangsworts hinzugefügt werden, sondern auch zu der Menge aller seiner Synonyme. Wenn es ein Synonym gibt, wird ein Eintrag hinzugefügt. Wenn wir jedoch 50 Synonyme haben, müssen Sie 50 Einträge hinzufügen. In der Abbildung sieht es so aus:
Beachten Sie, dass wir von drei Schlüsseln und sechs Datensätzen zu vier Schlüsseln und zwölf Datensätzen gewechselt sind. Ein Wort mit 50 Synonymen erfordert 50 Schlüssel und fast 2500 Einträge. Der notwendige Raum für die Darstellung eines Wortes wächst quadratisch mit einer Zunahme der Synonyme, was ziemlich verschwenderisch ist.
Es gibt andere Lösungen, aber ich werde nicht zu tief gehen, um den Artikel nicht aufzublasen. Das interessanteste davon ist die Verwendung der Synonymdatenstruktur zum Erstellen eines gerichteten Graphen und anschließend eine Breitensuche, um den Pfad zwischen zwei Wörtern zu finden. Dies ist eine großartige Lösung, aber die Suche wird linear in der Größe der Synonyme für das Wort. Da wir diese Suche für jede Anforderung mehrmals durchführen, ist dieser Ansatz nicht optimal.
Transitivität: Verwenden von disjunkten Mengen
Es stellt sich heraus, dass die Suche nach Synonymen dank einer Datenstruktur, die als disjunkte Mengen bezeichnet wird, für eine (fast) konstante Zeit möglich ist. Diese Struktur bietet etwas andere Möglichkeiten als ein regulärer Datensatz.
Die übliche Set-Struktur (Hashset, TreeSet) ist ein Container, mit dem Sie schnell feststellen können, ob sich ein Objekt innerhalb oder außerhalb befindet. Disjunkte Mengen lösen ein völlig anderes Problem: Anstatt ein bestimmtes Element zu definieren, können Sie bestimmen,
ob zwei Elemente zu derselben Menge gehören . Darüber hinaus tut die Struktur dies für eine blendend schnelle Zeit
O(a(n)) , wobei
a(n) die inverse Ackerman-Funktion ist. Wenn Sie keine fortgeschrittenen Algorithmen studiert haben, kennen Sie diese Funktion möglicherweise nicht, die für alle vernünftigen Eingaben tatsächlich in konstanter Zeit ausgeführt wird.
Auf hoher Ebene funktioniert der Algorithmus wie folgt. Mengen werden durch Bäume mit Eltern für jedes Element dargestellt. Da jeder Baum eine Wurzel hat (ein Element, das sein eigenes übergeordnetes Element ist), können wir feststellen, ob zwei Elemente zu derselben Menge gehören, indem wir ihre Eltern zur Wurzel zurückverfolgen. Wenn zwei Elemente eine Wurzel haben, gehören sie zu einer Menge. Das Kombinieren von Mengen ist ebenfalls einfach: Finden Sie einfach die Wurzelelemente und machen Sie eines davon zur Wurzel des anderen.
So weit so gut, aber bisher wurde keine blendende Geschwindigkeit gesehen. Das Genie dieser Struktur liegt in einem Verfahren, das als
Komprimierung bezeichnet wird . Angenommen, Sie haben den folgenden Baum:
Stellen Sie sich vor, Sie möchten wissen, ob
schnell und
voreilig Synonyme sind. Gehen Sie alle Eltern durch - und finden Sie die gleiche
schnelle Wurzel. Nehmen wir nun an, wir führen eine ähnliche Prüfung für die Wörter
schnell und
schnell durch . Wieder gehen wir bis zur Wurzel und von
schnell gehen wir den gleichen Weg. Kann Doppelarbeit vermieden werden?
Es stellt sich heraus, dass Sie können. In gewisser Weise ist jedes Element in diesem Baum dazu bestimmt, zu
schnell zu kommen. Anstatt jedes Mal den gesamten Baum zu durchlaufen, sollten Sie das übergeordnete Element für alle
schnellen Nachkommen ändern, um den Weg zur Wurzel zu verkürzen. Dieser Prozess wird als Komprimierung bezeichnet und ist in disjunkten Sätzen in die Stammsuchoperation eingebettet. Zum Beispiel wird
die Struktur nach der ersten Operation, bei der
schnell und
hastig verglichen wird, verstehen, dass es sich um Synonyme handelt, und den Baum wie folgt komprimieren:
Für alle Wörter zwischen schnell und schnell wurde der Elternteil aktualisiert, dasselbe geschah mit hastigJetzt werden alle nachfolgenden Aufrufe in konstanter Zeit ausgeführt, da jeder Knoten in diesem Baum auf
schnell zeigt . Es ist nicht sehr einfach, die zeitliche Komplexität von Operationen zu bewerten: Tatsächlich ist sie nicht konstant, da sie von der Tiefe der Bäume abhängt, sondern nahezu konstant, da die Struktur schnell optimiert wird. Der Einfachheit halber nehmen wir an, dass die Zeit konstant ist.
Mit diesem Konzept implementieren wir nicht verwandte Mengen für unser Problem:
class DisjointSet(object): def __init__(self): self.parents = {} def get_root(self, w): words_traversed = [] while self.parents[w] != w: words_traversed.append(w) w = self.parents[w] for word in words_traversed: self.parents[word] = w return w def add_synonyms(self, w1, w2): if w1 not in self.parents: self.parents[w1] = w1 if w2 not in self.parents: self.parents[w2] = w2 w1_root = self.get_root(w1) w2_root = self.get_root(w2) if w1_root < w2_root: w1_root, w2_root = w2_root, w1_root self.parents[w2_root] = w1_root def are_synonymous(self, w1, w2): return self.get_root(w1) == self.get_root(w2)
Mit dieser Struktur können Sie Synonyme vorverarbeiten und das Problem in linearer Zeit lösen.Bewertung und Notizen
Zu diesem Zeitpunkt haben wir die Grenze dessen erreicht, was ein Kandidat in 40 bis 45 Minuten eines Interviews zeigen kann. Allen Kandidaten, die mit dem Einführungsteil fertig wurden und erhebliche Fortschritte bei der Beschreibung (nicht Implementierung) nicht verwandter Gruppen erzielt haben, habe ich die Bewertung „Sehr empfehlenswert für die Beschäftigung“ zugewiesen und ihnen gestattet, Fragen zu stellen. Ich habe noch nie einen Kandidaten gesehen, der so weit gegangen ist und noch viel Zeit hat.Grundsätzlich gibt es immer noch Varianten des Transitivitätsproblems: Entfernen Sie beispielsweise die Einschränkung der Wortreihenfolge oder mehrerer Synonyme für ein Wort. Jede Entscheidung wird schwierig und erfreulich sein, aber ich werde sie für später belassen.Der Vorteil dieser Aufgabe besteht darin, dass die Kandidaten Fehler machen können. Die tägliche Softwareentwicklung besteht aus endlosen Zyklen der Analyse, Ausführung und Verfeinerung. Dieses Problem ermöglicht es den Kandidaten, ihre Fähigkeiten in jeder Phase unter Beweis zu stellen. Berücksichtigen Sie die Fähigkeiten, die erforderlich sind, um die maximale Punktzahl für dieses Problem zu erzielen:- Analysieren Sie die Aussage des Problems und stellen Sie fest, wo es nicht klar formuliert ist. Entwickeln Sie eine eindeutige Formulierung. Fahren Sie fort, während Sie sich lösen und neue Fragen auftauchen. Führen Sie diese Vorgänge für maximale Effizienz so früh wie möglich aus. Je weiter die Arbeit fortgeschritten ist, desto länger dauert die Behebung des Fehlers.
- , . , .
- . , , .
- , . ,
continue , , .
- , : , , , . , , , .
- . — , . — .
Keine dieser Fähigkeiten kann aus Lehrbüchern gelernt werden (mit der möglichen Ausnahme von Datenstrukturen und Algorithmen). Der einzige Weg, diese zu erwerben, ist eine regelmäßige und umfassende Praxis, die gut mit den Bedürfnissen des Arbeitgebers übereinstimmt: erfahrene Kandidaten, die in der Lage sind, ihr Wissen effektiv anzuwenden. In den Interviews ging es darum, solche Leute zu finden, und die Aufgabe aus diesem Artikel hat mir lange Zeit gut geholfen.Zukunftspläne
Wie Sie verstehen können, wurde die Aufgabe schließlich der Öffentlichkeit bekannt . Seitdem habe ich mehrere andere Fragen verwendet, abhängig von den Fragen der vorherigen Interviewer und meiner Stimmung (eine Frage zu stellen ist immer langweilig). Ich benutze immer noch einige Fragen, also werde ich sie geheim halten, aber einige sind es nicht! Sie finden sie in den folgenden Artikeln.In naher Zukunft plane ich zwei Artikel. Zunächst werde ich, wie oben versprochen, die Lösung der beiden verbleibenden Probleme für diese Aufgabe erläutern. Ich habe sie nie bei Interviews gefragt, aber sie sind an sich interessant. Darüber hinaus werde ich meine Gedanken und meine persönliche Meinung zum Verfahren zur Suche nach Mitarbeitern in der IT mitteilen, was für mich jetzt besonders interessant ist, da ich Ingenieure für mein Team in Reddit suche.Wenn Sie mehr über die Veröffentlichung neuer Artikel erfahren möchten, folgen Sie mir wie immer auf Twitter oder auf Medium . Wenn Ihnen dieser Artikel gefallen hat, vergessen Sie nicht, dafür zu stimmen oder einen Kommentar zu hinterlassen.Danke fürs Lesen!PS: Sie können den Code aller Artikel in untersuchen Repository GitHub oder mit ihnen live spielen dank meiner guten Freunde von repl.it .