
Das Thema der Verbesserung der Leistung von Betriebssystemen und der Suche nach Engpässen gewinnt zunehmend an Popularität. In diesem Artikel werden wir anhand des Beispiels des Blockstapels unter Linux und eines Falls zur Fehlerbehebung bei einem Host über ein Tool zum Auffinden dieser Stellen sprechen.
Beispiel 1. Test
Nichts funktioniert
Das Testen in unserer Abteilung umfasst Kunststoffe auf der Produkthardware und später Tests der Anwendungssoftware. Zum Testen haben wir ein Intel Optane-Laufwerk erhalten. Wir haben bereits
in unserem Blog über das Testen von Optane-Laufwerken geschrieben.
Die Festplatte wurde auf einem Standardserver installiert, der für eine relativ lange Zeit unter einem der Cloud-Projekte erstellt wurde.
Während des Tests zeigte sich die Festplatte nicht optimal: Während des Tests mit einer Warteschlangentiefe von 1 Anforderung pro 1 Stream in Blöcken von 4 KByte ca. 70 KByte. Und das bedeutet, dass die Antwortzeit enorm ist: ungefähr 13 Mikrosekunden pro Anfrage!
Es ist seltsam, weil die
Spezifikation "Latenz - 10 µs lesen" verspricht und wir 30% mehr haben, der Unterschied ist ziemlich signifikant. Die Festplatte wurde auf eine andere Plattform umgestellt, eine „frischere“ Baugruppe, die in einem anderen Projekt verwendet wurde.
Warum funktioniert es?
Es ist lustig, aber das Laufwerk auf der neuen Plattform hat so funktioniert, wie es sollte. Leistung erhöht, Latenz verringert, CPU pro Regal, 1 Stream pro Anforderung, 4-KByte-Blöcke, ~ 106 KB bei ~ 9 Mikrosekunden pro Anforderung.
Und dann ist es Zeit,
die Einstellungen zu
vergleichen , um
Perfektion von breiten
Beinen zu bekommen. Immerhin fragen wir uns warum? Mit
perf können Sie:
- Nehmen Sie Hardware-Zählerablesungen vor: die Anzahl der Anweisungsaufrufe, Cache-Fehler, falsch vorhergesagten Verzweigungen usw. (PMU-Ereignisse)
- Entfernen Sie Informationen von statischen Handelspunkten, die Anzahl der Vorkommen
- Führen Sie eine dynamische Ablaufverfolgung durch
Zur Überprüfung verwendeten wir CPU-Sampling.
Unter dem Strich kann
perf den gesamten Stack-Trace eines laufenden Programms kompilieren. Das Ausführen von
perf führt natürlich zu einer Verzögerung des Betriebs des gesamten Systems. Aber wir haben das Flag
-F # , wobei
# die Abtastfrequenz ist, gemessen in Hz.
Es ist wichtig zu verstehen, dass je höher die Abtastfrequenz ist, desto wahrscheinlicher ist es, dass eine bestimmte Funktion aufgerufen wird, aber desto mehr Bremsen bringt der Profiler in das System. Je niedriger die Frequenz, desto größer ist die Wahrscheinlichkeit, dass wir keinen Teil des Stapels sehen.
Bei der Auswahl einer Frequenz müssen Sie sich vom gesunden Menschenverstand und einem Trick leiten lassen - versuchen Sie, keine gerade Frequenz einzustellen, um nicht in eine Situation zu geraten, in der Arbeiten, die mit einem Timer mit dieser Frequenz ausgeführt werden, in die Samples gelangen.
Ein weiterer Punkt, der zunächst irreführend ist: Die Software sollte mit dem Flag
-fno-omit-frame-pointer kompiliert werden, wenn dies natürlich möglich ist. Andernfalls werden in der Ablaufverfolgung anstelle von Funktionsnamen feste
unbekannte Werte angezeigt. Bei einigen Programmen werden Debugging-Symbole als separates Paket
geliefert , z. B.
someutil-dbg . Es wird empfohlen, dass Sie sie installieren, bevor Sie
perf ausführen .
Wir haben folgende Aktionen ausgeführt:
- Entnommen aus git: //git.kernel.dk/fio.git, Tag fio-3.9
- CPPFLAGS in Makefile wurde die Option -fno-omit-frame-pointer hinzugefügt
- Make -j8 gestartet
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
Die Option -g wird benötigt, um den Spurenstapel zu erfassen.
Sie können das Ergebnis mit dem folgenden Befehl anzeigen:
perf report -g fractal
Die
fraktale Option
-g wird benötigt, damit Prozentsätze, die die Anzahl der Abtastwerte mit dieser Funktion widerspiegeln und von
perf angezeigt werden, relativ zur aufrufenden Funktion sind, deren Anzahl von Aufrufen als 100% angenommen wird.
Gegen Ende des langen Fio-Call-Stacks auf der Plattform „Fresh Build“ werden wir sehen:
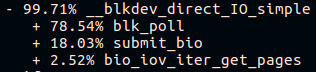
Und auf der "Old Build" -Plattform:

Großartig! Aber ich möchte schöne Flammengriffe.
Flamegramme bauen
Um schön zu sein, gibt es zwei Werkzeuge:
- Relativ statischer Flamegraph
- Flamescope , mit dem aus den gesammelten Proben ein bestimmter Zeitraum ausgewählt werden kann. Dies ist sehr nützlich, wenn der Suchcode die CPU mit kurzen Bursts lädt.
Diese Dienstprogramme akzeptieren
perf script> result als Eingabe.
Laden Sie das
Ergebnis herunter und senden Sie es per Pipes an
svg :
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
Öffnen Sie in einem Browser und genießen Sie ein anklickbares Bild.
Sie können eine andere Methode verwenden:
- Ergebnis zum Flamescope hinzufügen / example /
- Führen Sie python ./run.py aus
- Wir gehen über den Browser zum 5000-Port des lokalen Hosts
Was sehen wir am Ende?
Ein guter Fio verbringt viel Zeit mit
Umfragen :
Ein schlechtes Fio verbringt überall Zeit, aber nicht in Umfragen:
Auf den ersten Blick scheint das Polling auf dem alten Host nicht zu funktionieren, aber überall dort, wo der 4.15-Kernel von derselben Assembly ist, ist das Polling auf NVMe-Festplatten standardmäßig aktiviert. Überprüfen Sie, ob die Abfrage in
sysfs aktiviert ist:
Während der Tests werden
preadv2- Aufrufe mit dem Flag
RWF_HIPRI verwendet - eine notwendige Bedingung, damit die Abfrage funktioniert. Wenn Sie das Flammendiagramm (oder den vorherigen Screenshot aus der Ausgabe des
Perf-Berichts ) sorgfältig studieren, können Sie es finden, aber es dauert sehr wenig Zeit.
Das zweite, was sichtbar ist, ist der unterschiedliche Aufrufstapel für die Funktion submit_bio () und das Fehlen von io_schedule () -Aufrufen. Schauen wir uns den Unterschied in submit_bio () genauer an.
Langsame Plattform "alter Build":
Schnelle Plattform "frisch":
Es scheint, dass auf einer langsamen Plattform die Anforderung einen langen Weg zum Gerät geht und gleichzeitig in den
Kyber-Scheduler gelangt . Weitere
Informationen zu E / A-Schedulern finden Sie in
unserem Artikel .
Nach dem
Ausschalten von Kyber zeigte der gleiche Fio-Test eine durchschnittliche Latenz von etwa 10 Mikrosekunden, wie in der Spezifikation angegeben. Großartig!
Aber woher kommt der Unterschied in einer weiteren Mikrosekunde?
Und wenn etwas tiefer?
Wie bereits erwähnt, können Sie mit
perf Statistiken von Hardware-Zählern sammeln. Versuchen wir, die Anzahl der Cache-Fehler und Anweisungen pro Zyklus zu ermitteln:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10


Aus den Ergebnissen ist ersichtlich, dass eine schnelle Plattform mehr Anweisungen für den CPU-Zyklus ausführt und einen geringeren Prozentsatz an Cache-Fehlern während der Ausführung aufweist. Natürlich werden wir im Rahmen dieses Artikels nicht näher auf den Betrieb verschiedener Hardwareplattformen eingehen.
Beispiel 2. Lebensmittelgeschäft
Etwas läuft schief
Bei der Arbeit eines verteilten Speichersystems wurde eine Zunahme der Belastung der CPU auf einem der Hosts mit einer Zunahme des eingehenden Datenverkehrs beobachtet. Hosts sind Peers, Peers und haben identische Hardware und Software.
Schauen wir uns die CPU-Auslastung an:
~
Das Problem trat um 09:23:46 auf und wir sehen, dass der Prozess im Kernelraum ausschließlich für die gesamte Sekunde funktionierte. Schauen wir uns an, was im Inneren geschah.
Warum so langsam?
In diesem Fall haben wir Proben aus dem gesamten System entnommen:
perf record -a -g -- sleep 22 perf script > perf.results
Die Option
-a wird hier für
perf benötigt
, um Spuren von allen CPUs
zu entfernen.
Öffnen Sie
perf.results mit
flamescope , um den Moment erhöhter CPU-Auslastung zu verfolgen.
Vor uns liegt eine "Wärmekarte", deren beide Achsen (X und Y) die Zeit darstellen.
Auf der X-Achse ist der Raum in Sekunden und auf der Y-Achse in Segmente von 20 Millisekunden innerhalb von X Sekunden unterteilt. Die Zeit läuft von unten nach oben und von links nach rechts. Die hellsten Quadrate haben die größte Anzahl von Proben. Das heißt, die CPU arbeitete zu diesem Zeitpunkt am aktivsten.
Eigentlich interessiert uns der rote Fleck in der Mitte. Wählen Sie es mit der Maus aus, klicken Sie und sehen Sie, was es verbirgt:
Im Allgemeinen ist bereits
erkennbar , dass das Problem in der langsamen Operation
tcp_recvmsg und
skb_copy_datagram_iovec liegt .
Vergleichen Sie der Übersichtlichkeit halber Beispiele eines anderen Hosts, auf denen die gleiche Menge an eingehendem Datenverkehr keine Probleme verursacht:
Aufgrund der Tatsache, dass wir die gleiche Menge an eingehendem Verkehr haben, identische Plattformen, die lange Zeit ohne Unterbrechung gearbeitet haben, können wir davon ausgehen, dass die Probleme auf der Seite des Eisens aufgetreten sind. Die Funktion
skb_copy_datagram_iovec kopiert Daten aus der
Kernelstruktur in die Struktur im Benutzerbereich, um sie an die Anwendung weiterzuleiten. Es gibt wahrscheinlich Probleme mit dem Hostspeicher. Gleichzeitig gibt es keine Fehler in den Protokollen.
Wir starten die Plattform neu. Beim Laden des BIOS wird eine Meldung über eine defekte Speicherleiste angezeigt. Beim Austausch wird der Host gestartet und das Problem mit einer überlasteten CPU wird nicht mehr reproduziert.
Nachtrag
Systemleistung mit perf
Im Allgemeinen kann das Ausführen von
perf auf einem ausgelasteten System zu einer Verzögerung bei der Verarbeitung von Anforderungen führen. Die Größe dieser Verzögerungen hängt auch von der Auslastung des Servers ab.
Versuchen wir, diese Verzögerung zu finden:
~
Der Unterschied ist nicht sehr auffällig, nur etwa ~ 8 Nanosekunden.
Mal sehen, was passiert, wenn Sie die Last erhöhen:
~
Hier macht sich der Unterschied bereits bemerkbar. Es kann gesagt werden, dass das System um weniger als 1% langsamer wurde, aber ein Verlust von etwa 7 Kiops auf einem stark belasteten System kann zu Problemen führen.
Es ist klar, dass dieses Beispiel synthetisch ist, aber es ist sehr aufschlussreich.
Versuchen wir, einen weiteren synthetischen Test durchzuführen, der Primzahlen berechnet -
sysbench :
~
Hier sehen Sie, dass sich sogar die minimale Verarbeitungszeit um 270 Mikrosekunden erhöht hat.
Anstelle einer Schlussfolgerung
Perf ist ein sehr leistungsfähiges Tool zur Analyse der Systemleistung und zum Debuggen. Wie bei jedem anderen Tool müssen Sie jedoch die Kontrolle behalten und sich daran erinnern, dass jedes geladene System unter strenger Überwachung schlechter funktioniert.
Verwandte Links: