Beitrag erstellt von: Alexander Virilin xscrew - Autor, Leiter des Netzwerkinfrastrukturdienstes, Leonid Klyuyev - Herausgeber
Wir machen Sie weiterhin mit der internen Struktur von
Yandex.Cloud vertraut . Heute werden wir über Netzwerke sprechen - wir werden Ihnen erklären, wie die Netzwerkinfrastruktur funktioniert, warum sie das für Rechenzentren unpopuläre MPLS-Paradigma verwendet, welche anderen komplexen Entscheidungen wir beim Aufbau eines Cloud-Netzwerks treffen mussten, wie wir es verwalten und welche Art von Überwachung wir verwenden.
Das Netzwerk in der Cloud besteht aus drei Schichten. Die unterste Schicht ist die bereits erwähnte Infrastruktur. Dies ist ein physisches „eisernes“ Netzwerk innerhalb von Rechenzentren, zwischen Rechenzentren und an Orten, an denen Verbindungen zu externen Netzwerken bestehen. Ein virtuelles Netzwerk wird auf der Netzwerkinfrastruktur aufgebaut, und Netzwerkdienste werden auf dem virtuellen Netzwerk aufgebaut. Diese Struktur ist nicht monolithisch: Die Schichten überschneiden sich, das virtuelle Netzwerk und die Netzwerkdienste interagieren direkt mit der Netzwerkinfrastruktur. Da das virtuelle Netzwerk häufig als Overlay bezeichnet wird, wird es normalerweise als Unterlage der Netzwerkinfrastruktur bezeichnet.

Jetzt befindet sich die Cloud-Infrastruktur in der Zentralregion Russlands und umfasst drei Zugangszonen, dh drei geografisch verteilte unabhängige Rechenzentren. Unabhängig - unabhängig voneinander im Zusammenhang mit Netzen, technischen und elektrischen Systemen usw.
Über die Eigenschaften. Die geografische Lage der Rechenzentren ist so, dass die Umlaufzeit (RTT) der Umlaufzeit zwischen ihnen immer 6–7 ms beträgt. Die Gesamtkapazität der Kanäle hat bereits 10 Terabit überschritten und wächst ständig, da Yandex über ein eigenes Glasfasernetz zwischen den Zonen verfügt. Da wir keine Kommunikationskanäle leasen, können wir die Kapazität des Streifens zwischen den DCs schnell erhöhen: Jeder von ihnen verwendet Spektralmultiplexgeräte.
Hier ist die schematischste Darstellung der Zonen:
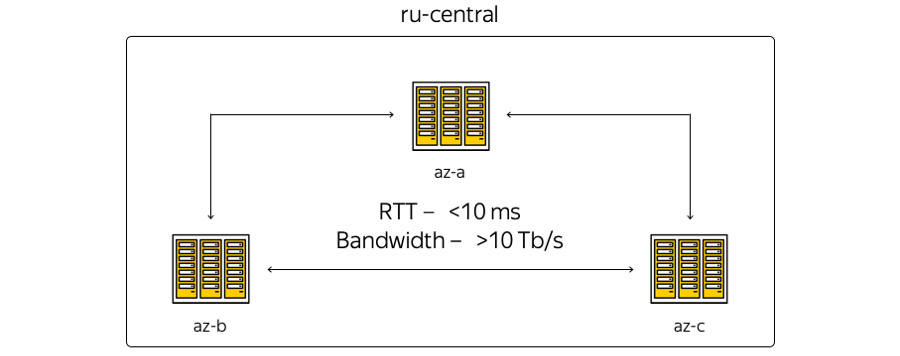
Die Realität sieht wiederum etwas anders aus:
Hier ist das aktuelle Yandex-Backbone-Netzwerk in der Region. Alle Yandex-Dienste arbeiten darüber hinaus, ein Teil des Netzwerks wird von der Cloud verwendet. (Dies ist ein Bild für den internen Gebrauch, daher werden Dienstinformationen absichtlich ausgeblendet. Dennoch ist es möglich, die Anzahl der Knoten und Verbindungen zu schätzen.) Die Entscheidung für die Verwendung des Backbone-Netzwerks war logisch: Wir konnten nichts erfinden, sondern die aktuelle Infrastruktur wiederverwenden - die über die Jahre der Entwicklung „gelitten“ hat.
Was ist der Unterschied zwischen dem ersten und dem zweiten Bild? Erstens sind Zugangszonen nicht direkt miteinander verbunden: Technische Standorte befinden sich zwischen ihnen. Die Sites enthalten keine Serverausrüstung - nur Netzwerkgeräte, um die Konnektivität sicherzustellen, werden auf ihnen platziert. Präsenzpunkte, an denen Yandex und Cloud mit der Außenwelt verbunden sind, sind mit technischen Standorten verbunden. Alle Präsenzpunkte arbeiten für die gesamte Region. Übrigens ist zu beachten, dass unter dem Gesichtspunkt des externen Zugriffs aus dem Internet alle Cloud-Zugriffszonen gleichwertig sind. Mit anderen Worten, sie bieten die gleiche Konnektivität - das heißt die gleiche Geschwindigkeit und den gleichen Durchsatz sowie gleich niedrige Latenzen.
Darüber hinaus gibt es Geräte an den Präsenzpunkten, zu denen Kunden - wenn lokale Ressourcen vorhanden sind und die lokale Infrastruktur mit Cloud-Einrichtungen erweitert werden soll - über einen garantierten Kanal eine Verbindung herstellen können. Dies kann mit Hilfe von Partnern oder auf eigene Faust erfolgen.
Das Kernnetz wird von der Cloud als MPLS-Transport verwendet.
MPLS
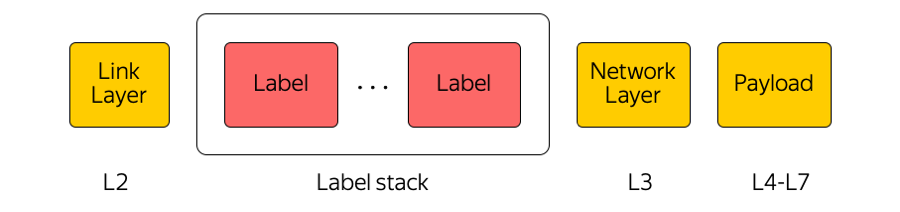
Multiprotokoll-Label-Switching ist eine in unserer Branche weit verbreitete Technologie. Wenn beispielsweise ein Paket zwischen Zugriffszonen oder zwischen einer Zugriffszone und dem Internet übertragen wird, achten Transitgeräte nur auf das oberste Etikett und „denken“ nicht darüber nach, was sich darunter befindet. Auf diese Weise können Sie mit MPLS die Cloud-Komplexität vor der Transportschicht verbergen. Im Allgemeinen lieben wir in der Cloud MPLS sehr. Wir haben es sogar zu einem Teil der unteren Ebene gemacht und es direkt in der Vermittlungsfabrik im Rechenzentrum verwendet:

(Tatsächlich gibt es viele parallele Verbindungen zwischen Blattschaltern und Stacheln.)
Warum MPLS?
Es stimmt, MPLS ist in Rechenzentrumsnetzwerken keineswegs häufig anzutreffen. Oft werden völlig unterschiedliche Technologien eingesetzt.
Wir verwenden MPLS aus mehreren Gründen. Zunächst fanden wir es zweckmäßig, die Technologien der Steuerebene und der Datenebene zu vereinheitlichen. Das heißt, anstelle einiger Protokolle im Rechenzentrumsnetzwerk andere Protokolle im Kernnetzwerk und die Verbindung dieser Protokolle - eine einzelne MPLS. So haben wir den technologischen Stack vereinheitlicht und die Komplexität des Netzwerks reduziert.
Zweitens verwenden wir in der Cloud verschiedene Netzwerkgeräte wie Cloud Gateway und Network Load Balancer. Sie müssen miteinander kommunizieren, Datenverkehr ins Internet senden und umgekehrt. Diese Netzwerk-Appliances können mit zunehmender Last horizontal skaliert werden. Da die Cloud nach dem Hyperkonvergenz-Modell erstellt wurde, können sie aus Sicht des Netzwerks im Rechenzentrum, dh in einem gemeinsamen Ressourcenpool, an absolut jedem Ort gestartet werden.
Somit können diese Appliances hinter jedem Port des Rack-Switches starten, an dem sich der Server befindet, und über MPLS mit dem Rest der Infrastruktur kommunizieren. Das einzige Problem beim Aufbau einer solchen Architektur war der Alarm.
Alarm
Der klassische MPLS-Protokollstapel ist recht komplex. Dies ist übrigens einer der Gründe für die Nichtverbreitung von MPLS in Rechenzentrumsnetzwerken.
Wir haben wiederum weder IGP (Interior Gateway Protocol) noch LDP (Label Distribution Protocol) oder andere Label Distribution-Protokolle verwendet. Es wird nur BGP-Label-Unicast (Border Gateway Protocol) verwendet. Jede Appliance, die beispielsweise als virtuelle Maschine ausgeführt wird, erstellt eine BGP-Sitzung vor dem Leaf-Switch für die Rackmontage.
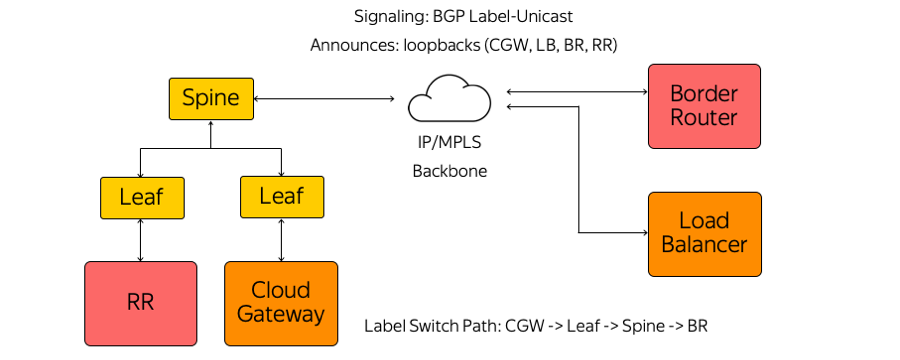
Eine BGP-Sitzung wird an einer bekannten Adresse erstellt. Es ist nicht erforderlich, den Switch automatisch so zu konfigurieren, dass jede Appliance ausgeführt wird. Alle Switches sind vorkonfiguriert und konsistent.
Innerhalb einer BGP-Sitzung sendet jede Appliance ihren eigenen Loopback und empfängt Loopbacks der übrigen Geräte, mit denen sie Datenverkehr austauschen muss. Beispiele für solche Geräte sind verschiedene Arten von Routenreflektoren, Grenzroutern und anderen Geräten. Infolgedessen werden auf den Geräten Informationen darüber angezeigt, wie Sie sich gegenseitig erreichen können. Vom Cloud-Gateway über den Leaf-Switch, den Spine-Switch und das Netzwerk bis zum Border-Router wird ein Label-Switch-Pfad erstellt. Switches sind L3-Switches, die sich wie ein Label Switch Router verhalten und nicht wissen, wie komplex sie sind.
MPLS auf allen Ebenen unseres Netzwerks hat es uns unter anderem ermöglicht, das Konzept von Eat your own dogfood anzuwenden.
Iss dein eigenes Hundefutter
Aus Netzwerksicht impliziert dieses Konzept, dass wir in derselben Infrastruktur leben, die wir dem Benutzer zur Verfügung stellen. Hier sind Diagramme von Racks in barrierefreien Bereichen:

Cloud-Host nimmt die Last vom Benutzer, enthält seine virtuellen Maschinen. Im wahrsten Sinne des Wortes kann ein benachbarter Host in einem Rack die Infrastrukturlast aus Sicht des Netzwerks tragen, einschließlich Routenreflektoren, Verwaltung, Überwachung von Servern usw.
Warum wurde das gemacht? Es bestand die Versuchung, Routenreflektoren und alle Infrastrukturelemente in einem separaten fehlertoleranten Segment zu betreiben. Wenn das Benutzersegment irgendwo im Rechenzentrum ausgefallen wäre, würden die Infrastrukturserver weiterhin die gesamte Netzwerkinfrastruktur verwalten. Dieser Ansatz erschien uns jedoch bösartig. Wenn wir unserer eigenen Infrastruktur nicht vertrauen, wie können wir sie dann unseren Kunden zur Verfügung stellen? Schließlich arbeiten absolut die gesamte Cloud, alle virtuellen Netzwerke, Benutzer- und Cloud-Dienste darüber.
Aus diesem Grund haben wir ein separates Segment aufgegeben. Unsere Infrastrukturelemente werden in derselben Netzwerktopologie und Netzwerkkonnektivität ausgeführt. Natürlich laufen sie in einer dreifachen Instanz - genau wie unsere Kunden ihre Dienste in der Cloud starten.
IP / MPLS-Fabrik
Hier ist ein Beispieldiagramm einer der Verfügbarkeitszonen:
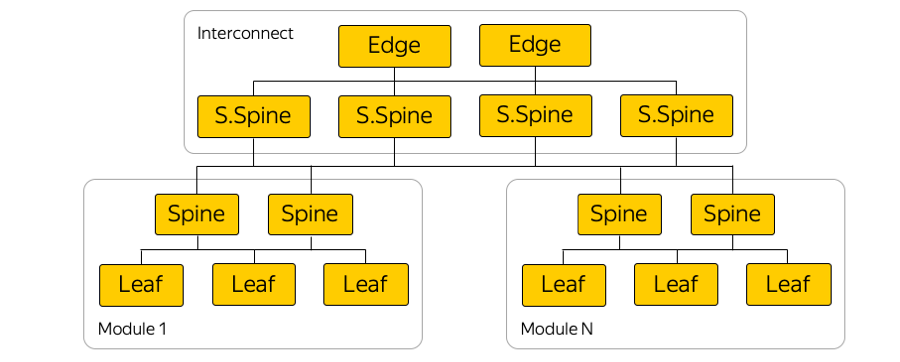
In jeder Verfügbarkeitszone gibt es ungefähr fünf Module und in jedem Modul ungefähr hundert Racks. Leaf-Rack-Switches, die innerhalb ihres Moduls über die Spine-Ebene verbunden sind, und die Konnektivität zwischen Modulen werden über die Netzwerkverbindung bereitgestellt. Dies ist die nächste Ebene, die die sogenannten Super-Spines- und Edge-Switches umfasst, die bereits die Zugriffszonen verbinden. Wir haben L2 absichtlich aufgegeben, wir sprechen nur über L3 IP / MPLS-Konnektivität. BGP wird zum Verteilen von Routing-Informationen verwendet.
Tatsächlich gibt es viel mehr parallele Verbindungen als auf dem Bild. Eine solch große Anzahl von ECMP-Verbindungen (Equal-Cost Multi-Path) stellt besondere Überwachungsanforderungen. Darüber hinaus gibt es auf den ersten Blick unerwartete Grenzen in der Ausrüstung - zum Beispiel die Anzahl der ECMP-Gruppen.
Serververbindung
Aufgrund der hohen Investitionen baut Yandex Services so auf, dass ein Ausfall eines Servers, Server-Racks, Moduls oder sogar eines gesamten Rechenzentrums niemals zu einem vollständigen Stopp des Service führt. Wenn wir irgendwelche Netzwerkprobleme haben - nehmen wir an, ein Rack-Mount-Switch ist defekt - sehen externe Benutzer dies nie.
Yandex.Cloud ist ein Sonderfall. Wir können dem Kunden nicht vorschreiben, wie er seine eigenen Services aufbauen soll, und wir haben uns entschlossen, diesen möglichen Single Point of Failure auszugleichen. Daher sind alle Server in der Cloud mit zwei Rack-Mount-Switches verbunden.
Wir verwenden auch keine Redundanzprotokolle auf L2-Ebene, sondern verwenden sofort nur L3 mit BGP - wiederum aus Gründen der Protokollvereinheitlichung. Diese Verbindung bietet jedem Dienst IPv4- und IPv6-Konnektivität: Einige Dienste funktionieren über IPv4, andere über IPv6.
Physisch ist jeder Server über zwei 25-Gigabit-Schnittstellen verbunden. Hier ist ein Foto aus dem Rechenzentrum:

Hier sehen Sie zwei Rack-Switches mit 100-Gigabit-Ports. Es sind unterschiedliche Breakout-Kabel sichtbar, die den 100-Gigabit-Port des Switch in 4 Ports mit 25 Gigabit pro Server unterteilen. Wir nennen diese Kabel "Hydra".
Infrastrukturmanagement
Die Cloud-Netzwerkinfrastruktur enthält keine proprietären Verwaltungslösungen: Alle Systeme sind entweder Open Source mit Anpassung für die Cloud oder vollständig selbst geschrieben.
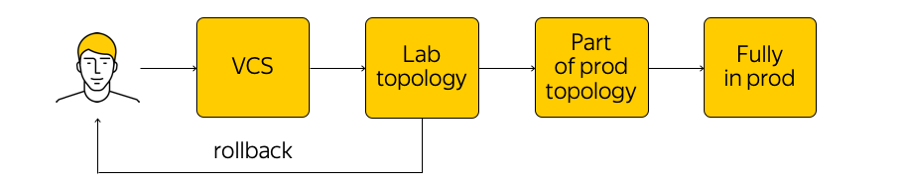
Wie wird diese Infrastruktur verwaltet? Es ist in der Cloud nicht so verboten, aber es wird dringend davon abgeraten, zu einem Netzwerkgerät zu gehen und Anpassungen vorzunehmen. Es gibt den aktuellen Status des Systems, und wir müssen die Änderungen anwenden: zu einem neuen Zielstatus kommen. Führen Sie ein Skript durch alle Drüsen, ändern Sie etwas in der Konfiguration - Sie sollten dies nicht tun. Stattdessen nehmen wir Änderungen an den Vorlagen vor, an einer einzigen Quelle des Wahrheitssystems, und übertragen unsere Änderungen auf das Versionskontrollsystem. Dies ist sehr praktisch, da Sie jederzeit einen Rollback durchführen, den Verlauf anzeigen, herausfinden können, wer für das Commit verantwortlich ist usw.
Wenn wir die Änderungen vorgenommen haben, werden Konfigurationen generiert und in der Labortesttopologie bereitgestellt. Aus Netzwerksicht ist dies eine kleine Cloud, die die gesamte vorhandene Produktion vollständig wiederholt. Wir werden sofort sehen, ob die gewünschten Änderungen etwas bewirken: erstens durch Überwachung und zweitens durch Feedback unserer internen Benutzer.
Wenn die Überwachung besagt, dass alles ruhig ist, fahren wir mit der Einführung fort - wenden die Änderung jedoch nur auf einen Teil der Topologie an (zwei oder mehr Zugänglichkeiten haben aus demselben Grund nicht das Recht, zu brechen). Darüber hinaus überwachen wir die Überwachung weiterhin genau. Dies ist ein ziemlich komplizierter Prozess, über den wir weiter unten sprechen werden.
Nachdem wir sichergestellt haben, dass alles in Ordnung ist, wenden wir die Änderung auf die gesamte Produktion an. Sie können jederzeit einen Rollback durchführen und zum vorherigen Status des Netzwerks zurückkehren, um das Problem schnell zu verfolgen und zu beheben.
Überwachung
Wir brauchen eine andere Überwachung. Eine der gefragtesten ist die Überwachung der End-to-End-Konnektivität. Jeder Server sollte jederzeit in der Lage sein, mit jedem anderen Server zu kommunizieren. Tatsache ist, dass wir, wenn irgendwo ein Problem auftritt, so früh wie möglich genau herausfinden möchten, wo (dh welche Server Probleme haben, aufeinander zuzugreifen). Die Gewährleistung einer durchgängigen Konnektivität ist unser Hauptanliegen.
Jeder Server listet eine Reihe aller Server auf, mit denen er zu einem bestimmten Zeitpunkt kommunizieren kann. Der Server nimmt eine zufällige Teilmenge dieser Menge und sendet ICMP-, TCP- und UDP-Pakete an alle ausgewählten Computer. Dadurch wird geprüft, ob im Netzwerk Verluste auftreten, ob sich die Verzögerung erhöht hat usw. Das gesamte Netzwerk wird innerhalb einer der Zugriffszonen und zwischen diesen "aufgerufen". Die Ergebnisse werden an ein zentrales System gesendet, das sie für uns visualisiert.
So sehen die Ergebnisse aus, wenn nicht alles sehr gut ist:
Hier können Sie sehen, zwischen welchen Netzwerksegmenten ein Problem besteht (in diesem Fall A und B) und wo alles in Ordnung ist (A und D). Hier können bestimmte Server, Rack-Switches, Module und gesamte Verfügbarkeitszonen angezeigt werden. Wenn eines der oben genannten Probleme das Problem verursacht, wird es in Echtzeit angezeigt.
Zusätzlich gibt es eine Ereignisüberwachung. Wir überwachen alle Verbindungen, Signalpegel auf Transceivern, BGP-Sitzungen usw. genau. Angenommen, drei BGP-Sitzungen werden aus einem Netzwerksegment erstellt, von denen eine nachts unterbrochen wurde. Wenn wir die Überwachung so einrichten, dass der Ausfall einer BGP-Sitzung für uns nicht kritisch ist und bis zum Morgen warten kann, werden die Netzwerktechniker durch die Überwachung nicht geweckt. Wenn jedoch die zweite der drei Sitzungen ausfällt, ruft ein Techniker automatisch an.
Zusätzlich zur End-to-End- und Ereignisüberwachung verwenden wir eine zentralisierte Sammlung von Protokollen, deren Echtzeitanalyse und nachfolgender Analyse. Sie können die Korrelationen sehen, Probleme identifizieren und herausfinden, was auf den Netzwerkgeräten passiert ist.
Das Überwachungsthema ist groß genug, es gibt einen großen Spielraum für Verbesserungen. Ich möchte das System zu mehr Automatisierung und wahrer Selbstheilung bringen.
Was weiter?
Wir haben viele Pläne. Es ist notwendig, Steuerungssysteme, Überwachung, IP / MPLS-Fabriken und vieles mehr zu verbessern.
Wir suchen auch aktiv nach White-Box-Schaltern. Dies ist ein fertiges "Eisen" -Gerät, ein Schalter, auf dem Sie Ihre Software rollen können. Erstens, wenn alles richtig gemacht wurde, ist es möglich, die Switches auf die gleiche Weise wie die Server zu „behandeln“, einen wirklich praktischen CI / CD-Prozess zu erstellen, Konfigurationen schrittweise einzuführen usw.
Zweitens ist es bei Problemen besser, eine Gruppe von Ingenieuren und Entwicklern zu behalten, die diese Probleme beheben, als lange auf eine Lösung durch den Anbieter zu warten.
Damit alles klappt, wird in zwei Richtungen gearbeitet:
- Wir haben die Komplexität der IP / MPLS-Fabrik erheblich reduziert. Einerseits ist die Ebene des virtuellen Netzwerks und der daraus resultierenden Automatisierungstools etwas komplizierter geworden. Andererseits ist das Unterlagennetzwerk selbst einfacher geworden. Mit anderen Worten, es gibt eine gewisse „Komplexität“, die nicht gespeichert werden kann. Es kann von einer Ebene zur anderen "geworfen" werden - beispielsweise zwischen Netzwerkebenen oder von der Netzwerkebene zur Anwendungsebene. Und Sie können diese Komplexität, die wir versuchen, richtig verteilen.
- Und natürlich stellen wir unsere Tools für die Verwaltung der gesamten Infrastruktur fertig.
Dies ist alles, was wir über unsere Netzwerkinfrastruktur sprechen wollten.
Hier ist ein Link zum Cloud Telegram-Kanal mit Neuigkeiten und Tipps.