Dieser Artikel wurde in Verbindung mit ananaskelly geschrieben .
Einführung
Hallo allerseits, Habr! In unserer Arbeit am Zentrum für Sprachtechnologie in St. Petersburg haben wir ein wenig Erfahrung in der Lösung der Probleme der Klassifizierung und Erkennung akustischer Ereignisse gesammelt und beschlossen, diese mit Ihnen zu teilen. Der Zweck dieses Artikels ist es, Ihnen einige Aufgaben vorzustellen und über den automatischen Soundverarbeitungswettbewerb DCASE 2018 zu sprechen. Wenn wir Ihnen von dem Wettbewerb erzählen, werden wir auf komplexe Formeln und Definitionen im Zusammenhang mit maschinellem Lernen verzichten, damit die allgemeine Bedeutung des Artikels von einem breiten Publikum verstanden wird.
Für diejenigen, die von der Versammlung des Klassifikators angezogen wurden, haben wir einen kleinen Python-Code vorbereitet. Über den Link auf dem Github finden Sie ein Notizbuch, in dem wir am Beispiel des zweiten Titels des DCASE-Wettbewerbs ein einfaches Faltungsnetzwerk auf Keras erstellen, um Audiodateien zu klassifizieren. Dort sprechen wir ein wenig über das Netzwerk und die für das Training verwendeten Funktionen sowie über die Verwendung einer einfachen Architektur, um ein Ergebnis nahe der Basislinie zu erzielen ( MAP @ 3 = 0,6).
Zusätzlich werden hier grundlegende Ansätze zur Lösung von Problemen (Baseline) beschrieben, die von den Organisatoren vorgeschlagen wurden. Auch in Zukunft wird es mehrere Artikel geben, in denen wir sowohl über unsere Erfahrungen bei der Teilnahme am Wettbewerb als auch über die von anderen Wettbewerbsteilnehmern vorgeschlagenen Lösungen ausführlicher und ausführlicher sprechen werden. Links zu diesen Artikeln werden nach und nach hier angezeigt.
Sicherlich haben viele Menschen absolut keine Ahnung von einer Art „DCASE“ . Lassen Sie uns also herausfinden, um welche Art von Obst es sich handelt und womit es gegessen wird. Der Wettbewerb „ DCASE “ findet jährlich statt. Jedes Jahr werden verschiedene Aufgaben zur Lösung von Problemen im Bereich der Klassifizierung von Audioaufnahmen und der Erkennung akustischer Ereignisse behandelt. Jeder kann am Wettbewerb teilnehmen, es ist kostenlos, dafür reicht es aus, sich einfach als Teilnehmer auf der Seite zu registrieren. Als Ergebnis des Wettbewerbs findet eine Konferenz zu denselben Themen statt, aber im Gegensatz zum Wettbewerb selbst ist die Teilnahme daran bereits bezahlt, und wir werden nicht mehr darüber sprechen. Belohnungen für die besten Entscheidungen werden normalerweise nicht herangezogen, aber es gibt Ausnahmen (zum Beispiel die 3. Aufgabe im Jahr 2018). In diesem Jahr schlugen die Organisatoren die folgenden 5 Aufgaben vor:
- Klassifizierung von akustischen Szenen (unterteilt in 3 Unteraufgaben)
A. Auf demselben Gerät aufgezeichnete Trainings- und Testdatensätze
B. Trainings- und Testdatensätze, die auf verschiedenen Geräten aufgezeichnet wurden
C. Die Schulung ist unter Verwendung von Daten gestattet, die nicht vom Veranstalter bereitgestellt wurden - Klassifizierung akustischer Ereignisse
- Vogelgesangserkennung
- Erkennung von akustischen Ereignissen im Haushalt anhand eines schwach beschrifteten Datensatzes
- Klassifizierung der Haushaltsaktivität im Raum nach Mehrkanalaufzeichnung
Informationen zur Erkennung und Klassifizierung
Wie wir sehen können, enthalten die Namen aller Aufgaben eines von zwei Wörtern: "Erkennung" oder "Klassifizierung". Lassen Sie uns klären, was der Unterschied zwischen diesen Konzepten ist, damit keine Verwirrung entsteht.
Stellen Sie sich vor, wir haben eine Audioaufnahme, auf der ein Hund in einem Moment bellt und eine Katze in einem anderen miaut, und es gibt einfach keine anderen Ereignisse dort. Wenn wir dann genau verstehen wollen, wann diese Ereignisse auftreten, müssen wir das Problem der Erkennung eines akustischen Ereignisses lösen. Das heißt, wir müssen die Start- und Endzeiten für jede Veranstaltung herausfinden. Nachdem wir das Erkennungsproblem gelöst haben, werden wir genau herausfinden, wann die Ereignisse auftreten, aber wir wissen nicht, von wem genau die gefundenen Geräusche erzeugt werden. Dann müssen wir das Klassifizierungsproblem lösen, dh bestimmen, was genau in dem angegebenen Zeitraum passiert ist.
Um die Beschreibung der Aufgaben des Wettbewerbs zu verstehen, reichen diese Beispiele völlig aus, was bedeutet, dass der einleitende Teil abgeschlossen ist und wir mit einer detaillierten Beschreibung der Aufgaben selbst fortfahren können.
Track 1. Klassifizierung von akustischen Szenen
Die erste Aufgabe besteht darin, die Umgebung (akustische Szene) zu bestimmen, in der das Audio aufgenommen wurde, z. B. "Metro Station", "Airport" oder "Pedestrian Street". Die Lösung dieses Problems kann bei der Beurteilung der Umgebung mit einem künstlichen Intelligenzsystem hilfreich sein, beispielsweise in Autos mit Autopilot.
In dieser Aufgabe wurden die von der Technischen Universität Tampere (Finnland) erstellten Datensätze TUT Urban Acoustic Scenes 2018 und TUT Urban Acoustic Scenes 2018 Mobile für das Training vorgestellt. Eine ausführliche Beschreibung der Erstellung des Datensatzes sowie der Basislösung finden Sie im Artikel .
Insgesamt wurden 10 akustische Szenen für den Wettbewerb präsentiert, die die Teilnehmer vorhersagen mussten.
Unteraufgabe A.
Wie bereits erwähnt, ist die Aufgabe in drei Unteraufgaben unterteilt, von denen sich jede in der Qualität der Audioaufnahmen unterscheidet. Beispielsweise wurden in Teilaufgabe A spezielle Mikrofone zur Aufzeichnung verwendet, die sich in den menschlichen Ohren befanden. So wurde die Stereoaufnahme der menschlichen Wahrnehmung von Schall näher gebracht. Die Teilnehmer hatten die Möglichkeit, diesen Ansatz für die Aufnahme zu verwenden, um die Erkennungsqualität der akustischen Szene zu verbessern.
Unteraufgabe B.
In Unteraufgabe B wurden auch andere Geräte (z. B. Mobiltelefone) zur Aufzeichnung verwendet. Die Daten aus Teilaufgabe A wurden in ein Monoformat konvertiert, die Abtastfrequenz wurde reduziert, es gibt keine Simulation der „Hörbarkeit“ von Schall durch eine Person im Datensatz für diese Aufgabe, aber es gibt mehr Daten für das Training.
Unteraufgabe C.
Der Datensatz für Unteraufgabe C ist der gleiche wie in Unteraufgabe A, aber zur Lösung dieses Problems dürfen alle externen Daten verwendet werden, die der Teilnehmer finden kann. Das Ziel der Lösung dieses Problems besteht darin, herauszufinden, ob es möglich ist, das in Teilaufgabe A erhaltene Ergebnis unter Verwendung von Daten von Drittanbietern zu verbessern.
Die Qualität der Entscheidungen auf dieser Strecke wurde anhand der Genauigkeitsmetrik bewertet.
Grundlage für diese Aufgabe ist ein zweischichtiges Faltungsnetzwerk, das aus den Logarithmen kleiner Spektrogramme der ursprünglichen Audiodaten lernt . Die vorgeschlagene Architektur verwendet die Standardtechniken BatchNormalization und Dropout. Der Code auf GitHub ist hier zu sehen.
Track 2. Klassifizierung von akustischen Ereignissen
In dieser Aufgabe wird vorgeschlagen, ein System zu erstellen, das akustische Ereignisse klassifiziert. Ein solches System kann eine Ergänzung zu Smart Homes sein, die Sicherheit an überfüllten Orten erhöhen oder Menschen mit Hörbehinderungen das Leben erleichtern.
Das Dataset für diese Aufgabe besteht aus Dateien, die aus dem Freesound-Dataset entnommen und mit Tags aus dem AudioSet von Google gekennzeichnet wurden . Ausführlicher wird der Prozess der Vorbereitung des Datensatzes in einem Artikel beschrieben , der von den Organisatoren des Wettbewerbs erstellt wurde.
Kehren wir zur eigentlichen Aufgabe zurück, die mehrere Funktionen hat.
Zunächst mussten die Teilnehmer ein Modell erstellen, mit dem Unterschiede zwischen akustischen Ereignissen sehr unterschiedlicher Art identifiziert werden können. Der Datensatz ist in Klasse 41 unterteilt und enthält verschiedene Musikinstrumente, Geräusche von Menschen, Tieren, Hausgeräusche und mehr.
Zweitens gibt es neben dem üblichen Markup von Daten auch zusätzliche Informationen zum manuellen Überprüfen des Etiketts. Das heißt, die Teilnehmer wissen, welche Dateien aus dem Datensatz von der Person auf Übereinstimmung mit dem Etikett überprüft wurden und welche nicht. Wie die Praxis gezeigt hat, haben Teilnehmer, die diese zusätzlichen Informationen irgendwie verwendet haben, Preise für die Lösung dieses Problems erhalten.
Darüber hinaus muss gesagt werden, dass die Dauer der Datensätze im Datensatz stark variiert: von 0,3 Sekunden bis 30 Sekunden. Bei diesem Problem variiert auch die Datenmenge pro Klasse, für die das Modell trainiert werden muss, stark. Dies wird am besten als Histogramm dargestellt, der Code für die Konstruktion, der von hier übernommen wird .
Wie Sie dem Histogramm entnehmen können, ist das manuelle Markup für die dargestellten Klassen ebenfalls unausgeglichen, was die Schwierigkeit erhöht, wenn Sie diese Informationen beim Trainieren von Modellen verwenden möchten.
Die Ergebnisse in dieser Spur wurden unter Verwendung der Durchschnittsgenauigkeitsmetrik (Mean Mean Precision, MAP @ 3) ausgewertet. Eine ziemlich einfache Demonstration der Berechnung dieser Metrik mit Beispielen und Code finden Sie hier .
Track 3. Erkennung von Vogelgesang
Der nächste Weg ist die Erkennung von Vogelgezwitscher. Ein ähnliches Problem tritt beispielsweise bei verschiedenen Systemen zur automatischen Überwachung von Wildtieren auf - dies ist der erste Schritt bei der Verarbeitung von Daten vor beispielsweise der Klassifizierung. Solche Systeme müssen häufig abgestimmt werden und sind gegenüber neuen akustischen Bedingungen instabil. Daher besteht das Ziel dieser Spur darin, die Kraft des maschinellen Lernens zur Lösung solcher Probleme zu nutzen.
Dieser Track ist eine erweiterte Version des Wettbewerbs „Bird Audio Detection Challenge“ , der 2017/2018 von der St. Mary's University of London organisiert wurde. Für Interessierte können Sie den Artikel der Autoren des Wettbewerbs lesen, der Details zur Datenbildung, zur Organisation des Wettbewerbs selbst und zur Analyse der getroffenen Entscheidungen enthält.
Zurück zur DCASE-Aufgabe. Die Organisatoren stellten sechs Datensätze zur Verfügung - drei für das Training, drei zum Testen - sie sind alle sehr unterschiedlich - aufgezeichnet unter verschiedenen akustischen Bedingungen mit verschiedenen Aufzeichnungsgeräten, vor dem Hintergrund gibt es verschiedene Geräusche. Die Hauptbotschaft lautet daher, dass das Modell nicht von der Umgebung abhängen oder sich an diese anpassen kann. Trotz der Tatsache, dass der Name „Erkennung“ bedeutet, besteht die Aufgabe nicht darin, die Grenzen des Ereignisses zu bestimmen, sondern in einer einfachen Klassifizierung - die endgültige Lösung ist eine Art binärer Klassifizierer, der einen kurzen Audioeintrag erhält und entscheidet, ob ein Vogel darauf singt oder nicht . Die AUC-Metrik wurde verwendet, um die Genauigkeit zu bewerten.
Meistens versuchten die Teilnehmer, durch verschiedene Datenerweiterungen eine Verallgemeinerung und Anpassung zu erreichen. Einer der Befehle beschreibt die Anwendung verschiedener Techniken - Ändern der Frequenzauflösung in den extrahierten Merkmalen, vorläufige Rauschreduzierung, eine Anpassungsmethode, die auf der Ausrichtung von Statistiken zweiter Ordnung für verschiedene Datensätze basiert. Solche Methoden sowie verschiedene Arten der Augmentation führen jedoch zu einer sehr geringen Steigerung gegenüber der Basislösung, wie viele Teilnehmer bemerken.
Als Basislösung bereiteten die Autoren eine Modifikation der erfolgreichsten Lösung aus dem ursprünglichen Wettbewerb „Bird Audio Detection Challenge“ vor. Der Code ist wie gewohnt auf dem Github verfügbar .
Track 4. Erkennung von akustischen Ereignissen im Haushalt anhand eines schwach beschrifteten Datensatzes.
In der vierten Spur ist das Erkennungsproblem bereits direkt gelöst. Den Teilnehmern wurde ein relativ kleiner Datensatz mit markierten Daten zur Verfügung gestellt - nur 1578 Audioaufnahmen von jeweils 10 Sekunden, die nur eine Klassenmarkierung aufweisen: Es ist bekannt, dass die Datei ein oder mehrere Ereignisse dieser Klassen enthält, es gibt jedoch kein temporäres Markup. Darüber hinaus wurden zwei große Datensätze mit nicht zugewiesenen Daten bereitgestellt - 14412 Dateien mit Zielereignissen derselben Klasse wie in den Trainings- und Testbeispielen sowie 39999 Dateien mit beliebigen Ereignissen, die nicht in den Zielen enthalten waren. Alle Daten sind eine Teilmenge des riesigen Audioset-Datensatzes, der von Google zusammengestellt wurde .
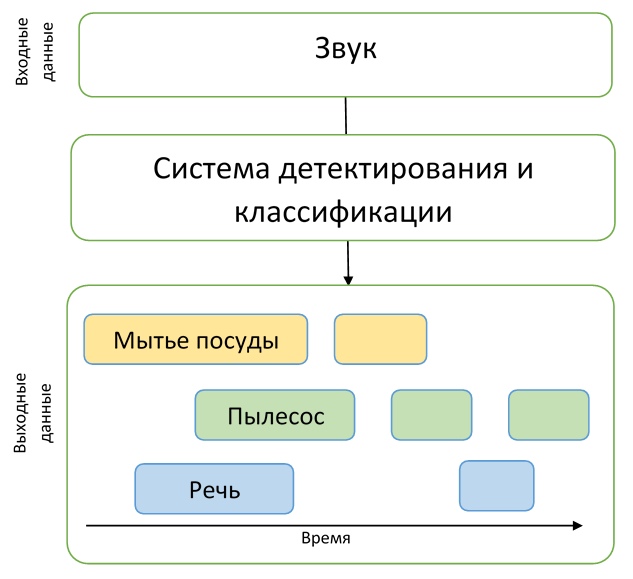
Daher mussten die Teilnehmer ein Modell erstellen, das aus schwach beschrifteten Daten lernen kann, um Zeitstempel für den Beginn und das Ende von Ereignissen zu finden (Ereignisse können sich überschneiden), und versuchen, es mit einer großen Menge nicht markierter zusätzlicher Daten zu verbessern. Darüber hinaus ist anzumerken, dass in dieser Spur eine ziemlich starre Metrik verwendet wurde - es war notwendig, die Zeitbezeichnungen von Ereignissen mit einer Genauigkeit von 200 ms vorherzusagen. Im Allgemeinen mussten die Teilnehmer eine ziemlich schwierige Aufgabe lösen, ein angemessenes Modell zu erstellen, während sie praktisch keine guten Daten für das Training hatten.
Die meisten Lösungen basierten auf Faltungs-Wiederholungsnetzwerken - eine ziemlich beliebte Architektur auf dem Gebiet der Erkennung akustischer Ereignisse in letzter Zeit (ein Beispiel kann hier gelesen werden ).
Die Grundlösung der Autoren, auch auf faltungsrekursiven Netzwerken, basiert auf zwei Modellen. Modelle haben fast die gleiche Architektur: drei Faltungsschichten und eine rekursive Schicht. Der einzige Unterschied sind die Ausgangsnetzwerke. Das erste Modell ist darauf trainiert, nicht zugewiesene Daten zu markieren, um den ursprünglichen Datensatz zu erweitern. Daher sind an der Ausgabe Klassen in der Ereignisdatei vorhanden. Die zweite dient zur direkten Lösung des Erkennungsproblems, dh am Ausgang erhalten wir eine temporäre Markierung für die Datei. Code für den Link .
Track 5. Klassifizierung der Haushaltsaktivität im Raum nach Mehrkanalaufzeichnung.
Der letzte Titel unterschied sich von den anderen vor allem dadurch, dass den Teilnehmern Mehrkanalaufnahmen angeboten wurden. Die Aufgabe selbst befand sich in der Klassifizierung: Es ist erforderlich, die Ereignisklasse vorherzusagen, die im Datensatz aufgetreten ist. Im Gegensatz zum vorherigen Titel ist die Aufgabe etwas einfacher - es ist bekannt, dass nur ein Ereignis im Datensatz enthalten ist.
Der Datensatz wird durch ungefähr 200 Stunden Aufzeichnungen auf einem linearen Mikrofonarray von 4 Mikrofonen dargestellt. Ereignisse sind alle Arten von alltäglichen Aktivitäten - Kochen, Geschirr spülen, soziale Aktivitäten (Telefonieren, Besuchen und persönliche Gespräche) usw. Auch die Klasse der Abwesenheit von Ereignissen wird hervorgehoben.
Die Autoren des Tracks betonen, dass die Bedingungen der Aufgabe relativ einfach sind, so dass sich die Teilnehmer direkt auf die Verwendung von räumlichen Informationen aus Mehrkanalaufzeichnungen konzentrieren. Die Teilnehmer hatten auch die Möglichkeit, zusätzliche Daten und vorgefertigte Modelle zu verwenden. Die Qualität wurde nach dem F1-Maß bewertet.
Als grundlegende Lösung schlugen die Autoren des Tracks ein einfaches Faltungsnetzwerk mit zwei Faltungsschichten vor. In ihrer Lösung wurden keine räumlichen Informationen verwendet - die Daten von vier Mikrofonen wurden für das unabhängige Training verwendet, und die Vorhersagen wurden während des Tests gemittelt. Beschreibung und Code finden Sie unter dem Link .
Fazit
In dem Artikel haben wir versucht, kurz über die Erkennung akustischer Ereignisse und über einen Wettbewerb wie DCASE zu sprechen. Vielleicht konnten sie jemanden für die Teilnahme im Jahr 2019 interessieren - der Wettbewerb beginnt im März.