Dies ist der erste Teil des Artikels, in dem ich darüber sprechen werde, wie wir den Prozess der Arbeit an einem großen Datenbankmigrationsprojekt aufgebaut haben: über sichere Experimente, Teamplanung und teamübergreifende Interaktion. In den folgenden Artikeln werde ich ausführlicher auf die technischen Probleme eingehen, die wir gelöst haben: Skalierung und Fehlertoleranz von PostgreSQL und Lasttests.
Die Hauptdatenbank in Miro (ex-RealtimeBoard) war lange Zeit Redis. Wir haben darin alle grundlegenden Informationen gespeichert: Daten über Benutzer, Konten, Boards usw. Alles hat schnell funktioniert, aber wir sind auf eine Reihe von Problemen gestoßen.
Probleme mit Redis- Abhängigkeit von der Netzwerklatenz. In unserer Cloud ist es ungefähr 20 Uhr Moskauer Zeit, aber wenn Sie sie erhöhen, beginnt die Anwendung sehr langsam zu arbeiten.
- Das Fehlen von Indizes, die wir auf der Ebene der Geschäftslogik benötigen. Ihre unabhängige Implementierung kann die Geschäftslogik komplizieren und zu Dateninkonsistenzen führen.
- Die Komplexität des Codes macht es auch schwierig, die Datenkonsistenz aufrechtzuerhalten.
- Ressourcenintensität von Abfragen mit Auswahl.
Diese Probleme verursachten zusammen mit einer Zunahme der Datenmenge auf den Servern die Datenbankmigration.
Erklärung des Problems
Die Entscheidung über die Migration wurde getroffen. Der nächste Schritt besteht darin, zu verstehen, welche Datenbank für unser Datenmodell geeignet ist.
Wir haben eine Studie durchgeführt, um die für uns optimale Datenbank auszuwählen, und uns für PostgreSQL entschieden. Unser Datenmodell passt gut zu einer relationalen Datenbank: PostgreSQL verfügt über integrierte Tools, um die Datenkonsistenz sicherzustellen. Es gibt einen JSONB-Typ und die Möglichkeit, bestimmte Felder in JSONB zu indizieren. Es passt zu uns.
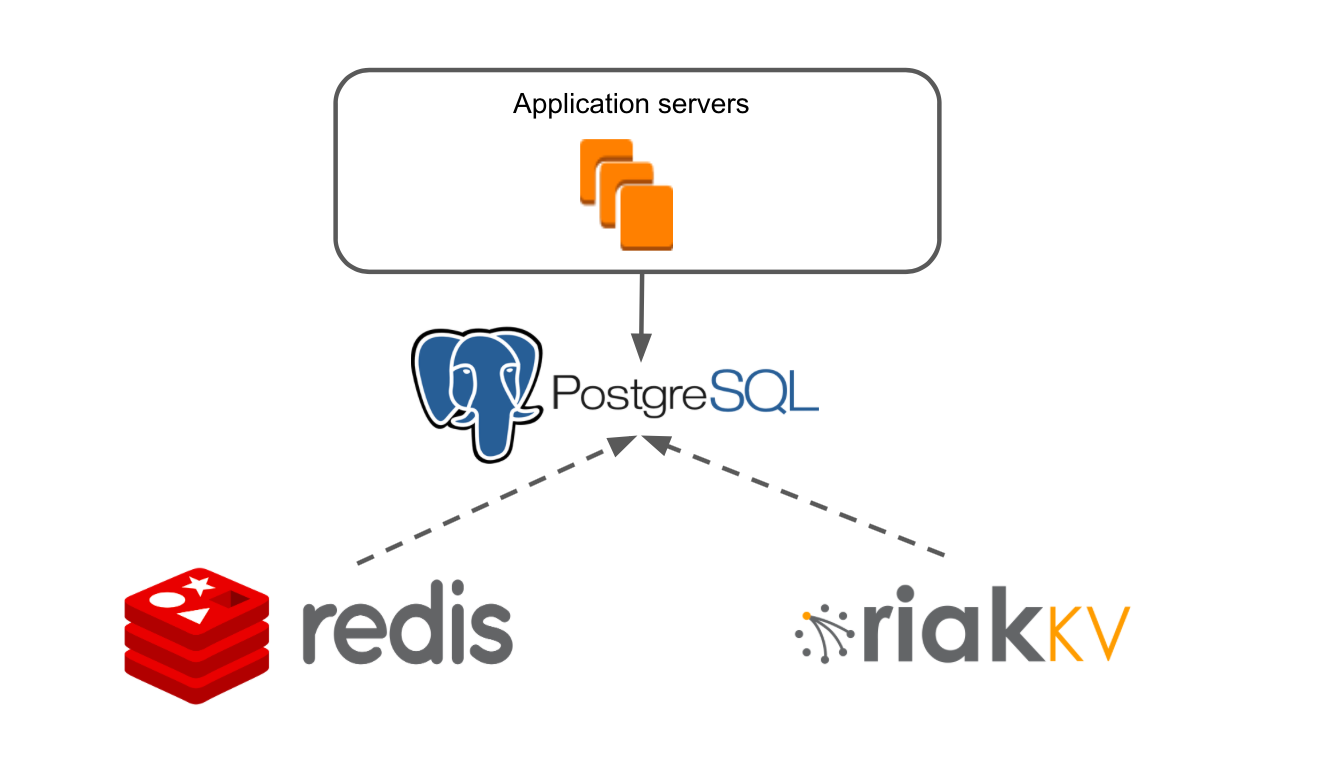
Die vereinfachte Architektur unserer Anwendung sah folgendermaßen aus: Es gibt Anwendungsserver, die über die Datenschicht auf Redis und RiakKV zugreifen.
Unser Anwendungsserver ist eine monolithische Java-Anwendung. Die Geschäftslogik ist in einem Framework geschrieben, das für NoSQL angepasst ist. Die Anwendung verfügt über ein eigenes Transaktionssystem, mit dem Sie mehrere Benutzer auf einem unserer Boards bereitstellen können.
Wir haben RiakKV verwendet, um Daten von Archivkarten zu speichern, die 7 Tage lang nicht geöffnet waren.
Fügen Sie diesem Schema PostgreSQL hinzu. Wir sorgen dafür, dass Anwendungsserver mit der neuen Datenbank funktionieren. Kopieren Sie Daten von Redis und RiakKV nach PostgreSQL. Das Problem ist gelöst!
Nichts kompliziertes, aber es gibt Nuancen:- Wir haben 2,2 Millionen registrierte Benutzer. Jeden Tag beschäftigt Miro 50.000 Benutzer, die Spitzenlast beträgt bis zu 14.000 gleichzeitig. Benutzer sollten aufgrund unserer Arbeit keine Fehler feststellen. Sie sollten den Moment des Umzugs auf eine neue Basis im Allgemeinen nicht bemerken.
- 1 TB Daten in der Datenbank oder 410 Millionen Objekte.
- Kontinuierliche Veröffentlichung neuer Funktionen durch andere Teams, deren Arbeit wir nicht stören sollten.
Optionen zur Lösung des Problems
Bei der Datenmigration standen zwei Optionen zur Auswahl:
- Beenden Sie die Entwicklung des Dienstes → Schreiben Sie den Code auf dem Server neu → Testen Sie die Funktionalität → Starten Sie eine neue Version.
- Führen Sie eine reibungslose Migration durch: Übertragen Sie Teile des Produkts schrittweise in eine neue Datenbank, wobei sowohl PostgreSQL als auch Redis unterstützt werden und die Entwicklung neuer Funktionen nicht unterbrochen wird.
Das Stoppen der Entwicklung eines Dienstes ist ein Zeitverlust, den wir für das Wachstum nutzen könnten, was einen Verlust von Benutzern und Marktanteilen bedeutet. Dies ist für uns von entscheidender Bedeutung, daher haben wir uns für die Option mit reibungsloser Migration entschieden. Trotz der Tatsache, dass dieser Prozess in seiner Komplexität mit dem Austausch von Rädern an einem Auto während der Fahrt verglichen werden kann.
Bei der Bewertung der Arbeit haben wir unser Produkt in Hauptblöcke unterteilt: Benutzer, Konten, Boards usw. Separat wurden Arbeiten zur Erstellung der PostgreSQL-Infrastruktur durchgeführt. Und sie setzen Risiken in die Bewertung ein, falls etwas schief geht (wie es passiert ist).
Sprints und Ziele
Der nächste Schritt besteht darin, ein Team von fünf Personen aufzubauen, damit sich alle mit der richtigen Geschwindigkeit zu einem gemeinsamen Ziel bewegen.
Wir haben zwei Punkte: den Beginn der Arbeit an der Aufgabe und das Endziel. Ideal, wenn wir uns direkt dem Ziel nähern. Aber es kommt oft vor, dass wir den geraden Weg gehen wollen, aber es stellt sich so heraus:
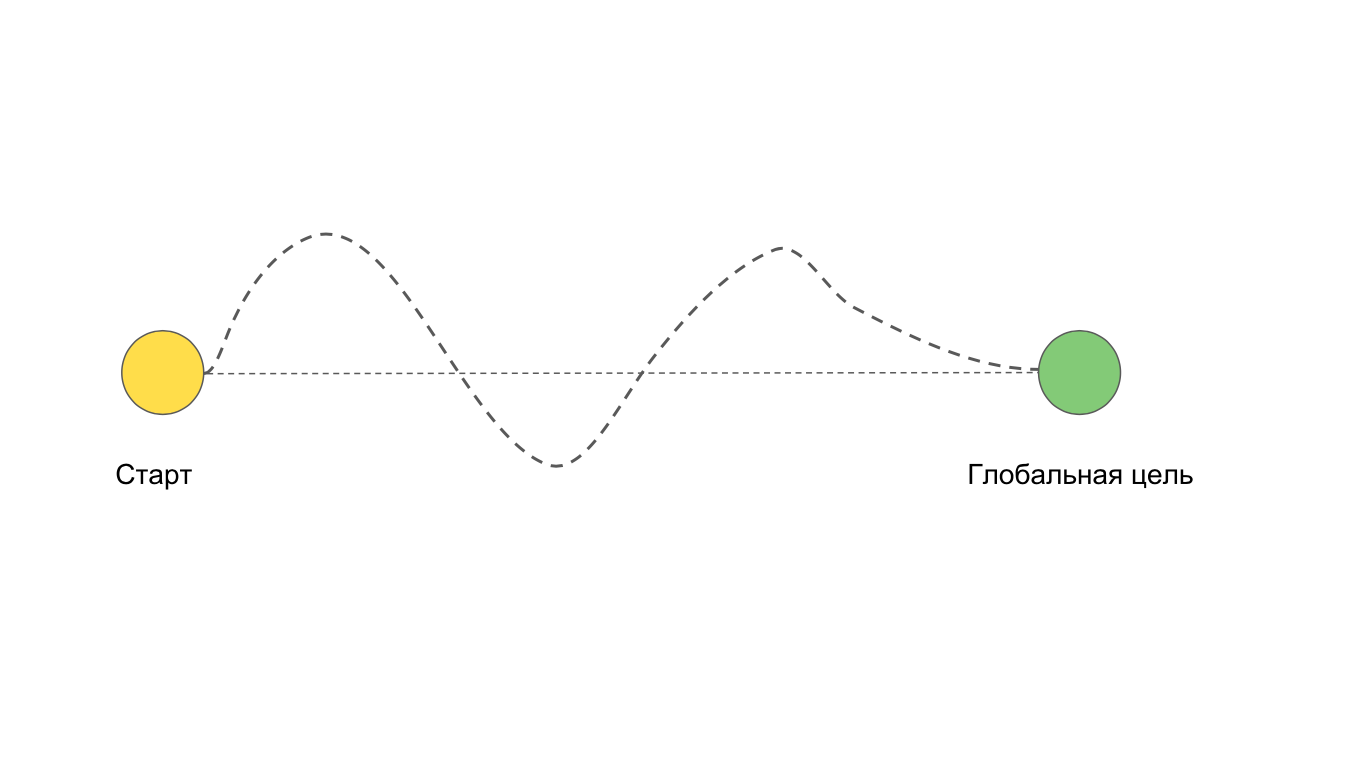
Zum Beispiel aufgrund von Schwierigkeiten und Problemen, die nicht im Voraus vorhergesehen werden konnten.
Es ist eine Situation möglich, in der wir das Ziel überhaupt nicht erreichen werden. Zum Beispiel, wenn wir uns intensiv mit dem Refactoring oder dem Umschreiben der gesamten Anwendung befassen.
Wir haben die Aufgabe in wöchentliche Sprints aufgeteilt, um die oben beschriebenen Schwierigkeiten zu minimieren. Wenn das Team plötzlich zur Seite geht, kann es mit minimalen Verlusten für das Projekt schnell zurückkehren, da kurze Iterationen es Ihnen nicht erlauben, zu weit "falsch" zu gehen.
Jede Iteration hat ihr eigenes Ziel, das das Team zum endgültigen großen Ergebnis führt.

Wenn während des Sprints eine neue Aufgabe erscheint, bewerten wir, ob ihre Implementierung uns dem Ziel näher bringt. Ja - nimm den nächsten Sprint oder ändere die Prioritäten im aktuellen, wenn nicht - nimm ihn nicht. Wenn Fehler auftreten, geben wir ihnen hohe Priorität und beheben sie schnell.
Es kommt vor, dass Entwickler innerhalb eines Sprints Aufgaben in einer genau definierten Reihenfolge ausführen müssen. Zum Beispiel übergibt der Entwickler die fertige Aufgabe dem QS-Ingenieur zur dringenden Prüfung. In der Planungsphase versuchen wir, für jedes Teammitglied ähnliche Beziehungen zwischen Aufgaben aufzubauen. Auf diese Weise kann das gesamte Team sehen, wer was wann tun wird, ohne die Abhängigkeit von anderen zu vergessen.
Das Team hat tägliche und wöchentliche Synchronisierungen. Jeden Morgen besprechen wir, wer, was und mit welcher Priorität heute vorgehen wird. Nach jedem Sprint synchronisieren wir uns, um sicherzustellen, dass sich alle in die richtige Richtung bewegen. Planen Sie unbedingt große oder komplexe Releases. Wir ernennen diensthabende Entwickler, die bei Bedarf während der Veröffentlichung anwesend sind und überwachen, ob alles in Ordnung ist.
Durch Planung und Synchronisierung innerhalb des Teams können alle Teilnehmer in alle Phasen des Projekts einbezogen werden. Pläne und Bewertungen kommen nicht von oben zu uns, wir machen sie selbst. Dies erhöht die Verantwortung und das Interesse des Teams an der Erledigung von Aufgaben.
Dies ist einer unserer Sprints. Wir tragen alles auf dem Miro-Brett:

Modi und sichere Experimente
Während der Migration mussten wir den stabilen Betrieb des Dienstes unter Kampfbedingungen gewährleisten. Dazu müssen Sie sicherstellen, dass alles getestet wird und nirgendwo Fehler auftreten. Um dieses Ziel zu erreichen, haben wir uns entschlossen, unsere reibungslose Migration noch reibungsloser zu gestalten.
Die Idee war, Produktblöcke schrittweise auf eine neue Datenbank umzustellen. Zu diesem Zweck haben wir eine Reihe von Modi entwickelt.
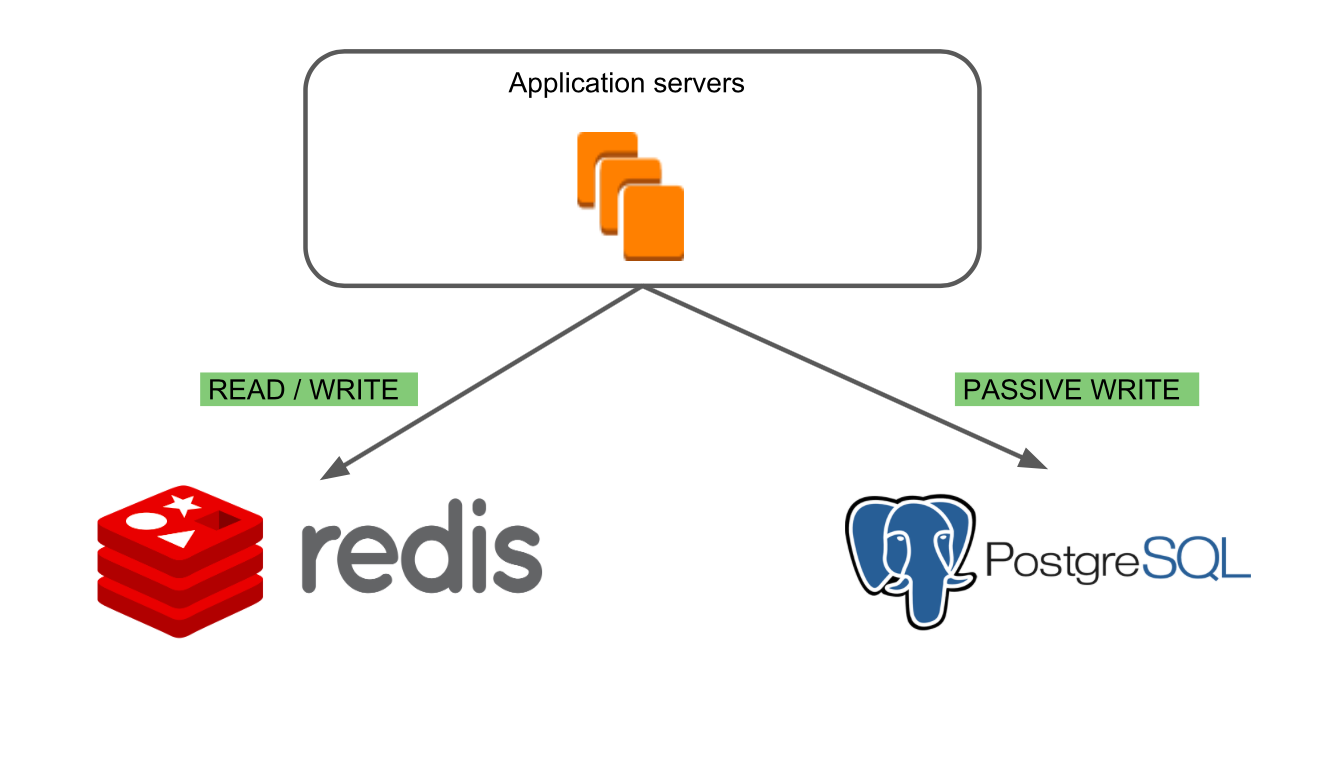
Im ersten "Redis Read / Write" -Modus funktioniert nur die alte Datenbank Redis.
 Im zweiten Modus „PostgreSQL Passive Write“ können
Im zweiten Modus „PostgreSQL Passive Write“ können wir sicherstellen, dass das Schreiben in die neue Datenbank korrekt und die Datenbanken konsistent sind.
 Im dritten Modus "PostgreSQL Lesen / Schreiben, Redis Passives Schreiben"
Im dritten Modus "PostgreSQL Lesen / Schreiben, Redis Passives Schreiben" können Sie die Richtigkeit des Lesens von Daten aus PostgreSQL überprüfen und sehen, wie sich die neue Datenbank unter Kampfbedingungen verhält. Gleichzeitig bleibt Redis die Hauptbasis, die es uns ermöglichte, bestimmte Fälle der Arbeit mit Boards zu finden, die zu Fehlern führen könnten.
 Im letzten "PostgreSQL-Lese- / Schreibmodus" wird
Im letzten "PostgreSQL-Lese- / Schreibmodus" wird nur die neue Datenbank ausgeführt.
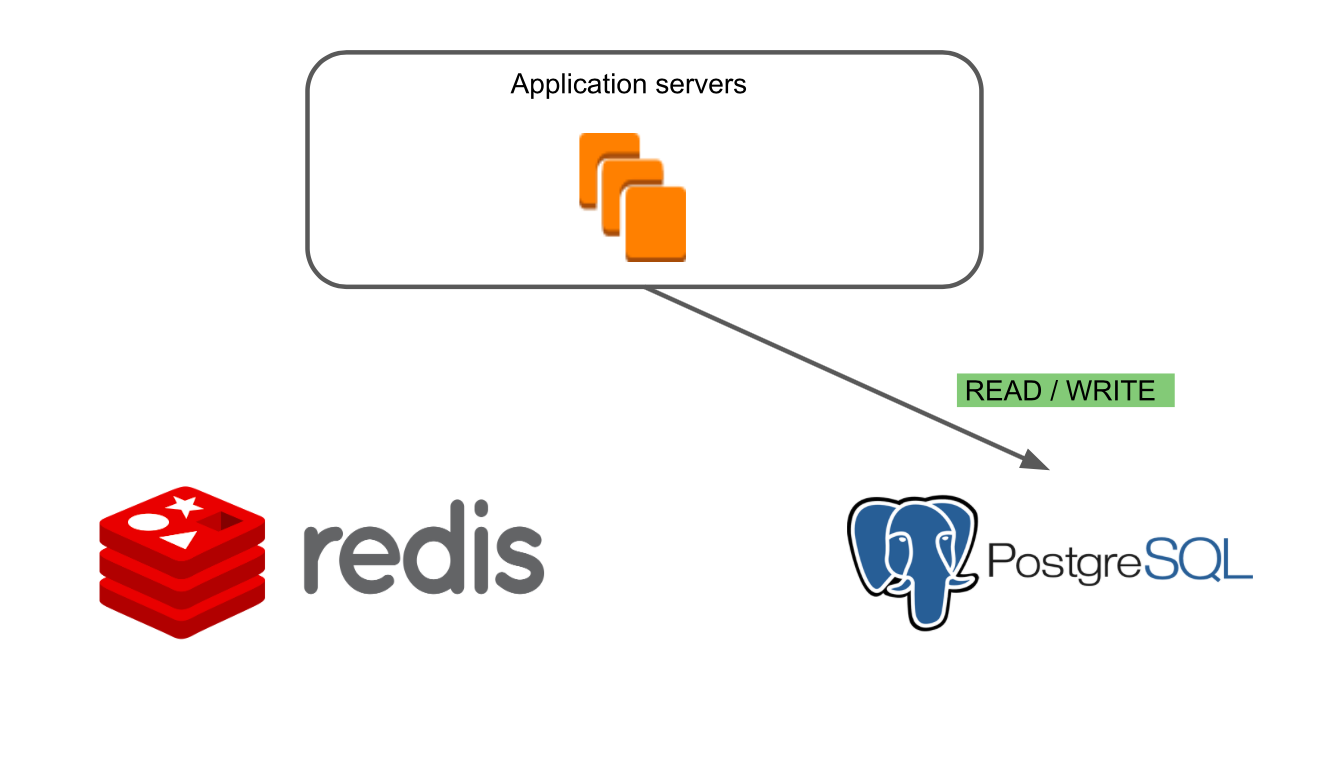
Migrationsarbeiten könnten sich auf die Hauptfunktionen des Produkts auswirken. Daher mussten wir zu 100% sicher sein, dass wir nichts kaputt machen und dass die neue Datenbank mindestens so langsam wie die alte arbeitet. Daher haben wir begonnen, sichere Experimente mit Schaltmodi durchzuführen.
Wir haben begonnen, den Modus auf unserem Unternehmenskonto zu wechseln, den wir täglich bei der Arbeit verwenden. Nachdem wir sichergestellt hatten, dass keine Fehler darin waren, haben wir bei einer kleinen Auswahl externer Benutzer den Modus gewechselt.
Der Zeitplan für den Start von Experimenten mit den Modi lautet wie folgt:
- Januar-Februar: Redis lesen / schreiben
- März-April: Passives Schreiben nach PostgreSQL
- Mai-Juni: PostgreSQL Lesen / Schreiben, Hauptdatenbank - Redis
- Juli-August: PostgreSQL lesen / schreiben
- September-Dezember: vollständige Migration.
Wenn Fehler auftraten, hatten wir die Möglichkeit, diese schnell zu beheben, da wir selbst Releases auf Servern erstellen konnten, auf denen die am Experiment beteiligten Benutzer arbeiteten. Wir waren nicht von der Hauptversion abhängig, daher haben wir Fehler schnell und jederzeit behoben.
Teamübergreifende Zusammenarbeit
Während der Migration haben wir uns häufig mit Teams getroffen, die neue Funktionen veröffentlicht haben. Wir haben eine einzige Codebasis, und im Rahmen ihrer Arbeit können Teams vorhandene Strukturen in einer neuen Datenbank ändern oder neue erstellen. In diesem Fall kann es zu Überschneidungen von Teams bei der Entwicklung und Rücknahme neuer Funktionen kommen. Beispielsweise versprach eines der Produktteams dem Marketingteam, bis zu einem bestimmten Datum eine neue Funktion zu veröffentlichen. Das Marketing-Team hat für diesen Zeitraum eine Werbekampagne geplant. Ein Verkaufsteam wartet auf eine Funktion und eine Kampagne, um mit neuen Kunden zu kommunizieren. Es stellt sich heraus, dass jeder voneinander abhängig ist und die Verzögerung der Fristen durch ein Team die Pläne des anderen stört.
Um solche Situationen zu vermeiden, haben wir zusammen mit anderen Teams eine einzige Roadmap für Lebensmittel erstellt, die mehrmals im Quartal und wöchentlich mit einigen Teams synchronisiert wurde.
Schlussfolgerungen
Was wir während dieses Projekts gelernt haben:
- Haben Sie keine Angst, komplexe Projekte anzunehmen. Nach der Zerlegung, Bewertung und Entwicklung von Arbeitsansätzen scheinen komplexe Projekte nicht mehr unmöglich zu sein.
- Nehmen Sie sich keine Zeit und Mühe für vorläufige Schätzungen, Zerlegung und Planung. Dies hilft, das Problem besser zu verstehen, bevor Sie mit der Arbeit beginnen, und das Volumen und die Komplexität der Arbeit zu verstehen.
- Legen Sie Risiken in schwierigen technischen und organisatorischen Projekten. Während der Arbeit werden Sie sicherlich auf ein Problem stoßen, das bei der Planung nicht berücksichtigt wurde.
- Migrieren Sie nicht, es sei denn, dies ist erforderlich.
In den folgenden Artikeln werde ich mehr über die technischen Probleme sprechen, die wir während der Migration gelöst haben.