Hallo nochmal!
Kolleginnen und Kollegen, am letzten Tag im Januar starten wir den Kurs
„MS SQL Server Developer“ , in dessen Zusammenhang wir eine thematische offene Lektion hatten. Dabei haben wir darüber gesprochen, wie MS SQL Server eine SELECT-Abfrage ausführt, in welcher Reihenfolge und was analysiert wird, und auch ein wenig in das Lesen des Abfrageplans getaucht.
Dozentin -
Kristina Kucherova , Datenmodellarchitektin bei der Sberbank in Russland.
Ziele und Route des WebinarsZu Beginn des Webinars wurden folgende Ziele festgelegt:
- Sehen Sie, wie der Server die Anforderung ausführt und warum dies auf diese Weise geschieht.
- Lernen, einen Abfrageplan zu lesen.
Um sie zu erreichen, bereitete der Lehrer einen einfachen, aber effektiven Weg vor:
 Warum brauche ich einen Abfrageplan?
Warum brauche ich einen Abfrageplan?Der Abfrageplan ist ein sehr nützliches Tool, das leider viele Entwickler nicht verwenden. Auf den ersten Blick scheint es nicht notwendig zu sein, die Mechanik der Anfrage zu kennen. Wenn Sie jedoch verstehen, was in SQL Server geschieht, können Sie eine effizientere Abfrage schreiben. Und es wird zum Beispiel bei der Optimierung sehr hilfreich sein.
Wie sehen wir eine SELECT-Abfrage?Mal sehen, wie die SELECT-Abfrage aussieht:
SELECT [Feld1], [Feld2] ...
| Welche Felder wählen wir?
|
FROM [Tabelle]
| Woher?
|
WO [Bedingungen]
| Wo sind die Bedingungen?
|
GROUP BY [Feld1]
| Nach Feldern gruppieren
|
HABEN [Bedingungen]
| Solche und solche Bedingungen haben
|
BESTELLEN NACH [Feld1]
| Bestellung (sortieren)
|
Wie kann man verstehen, wohin Daten gehen sollen?Der Server versucht zunächst zu verstehen, wann eine Anfrage eingeht, wo die Daten abgerufen werden sollen. Der FROM-Befehl beantwortet diese Frage, da hier eine Liste von Tabellen (oder der Name einer Tabelle) angezeigt wird.
Stellen wir uns zur Klarheit vor, unser Server ist eine Art Butler, den wir im Urlaub abholen sollen. Dementsprechend beginnt der Butler zu überlegen, aber in welchem Schrank befinden sich die notwendigen Dinge (in welcher Tabelle müssen Sie die Daten aufnehmen)? Und damit unser Butler seine Aufgabe problemlos erledigen kann, verwenden wir FROM.
 Wie kann man verstehen, welche Daten zu nehmen sind?
Wie kann man verstehen, welche Daten zu nehmen sind?Nehmen wir an, der Butler hat den richtigen Schrank gefunden und geöffnet. Aber welche Dinge zu nehmen? Vielleicht fahren wir in ein Skigebiet? Oder vielleicht an einem heißen, sonnigen Strand? Damit unsere Sachen dem Wetter entsprechen, ist der Befehl WHERE für uns nützlich, der die Bedingungen definiert, dh das Filtern der Daten ermöglicht. Wenn es heiß ist, nehmen wir Schiefer, Hemden und Badebekleidung, wenn es kalt ist - Fäustlinge, gestrickte Socken, Pullover)).
Der nächste Schritt besteht darin, diese Daten an Gruppen anzuhängen, was bei GROUP BY der Fall ist (T-Shirts separat, Socken separat). Entsprechend den Gruppierungsergebnissen kann mit HAVING eine weitere Bedingung auferlegt werden (z. B. ungepaarte Dinge aussortieren). Am Ende fügen wir alles mit ORDER BY hinzu und erhalten den fertigen Koffer mit den Dingen am Ausgang oder vielmehr einen geordneten Datenblock.

Übrigens gibt es eine Nuance, aber sie besteht darin, dass es einen Unterschied gibt, welche Bedingungen in WO und welche in HAVING vorgeschrieben werden sollten. Aber das ist besser im Video zu sehen.
Wir fahren fort. Der Anforderungsausführungspfad wird
als Anforderungsplan im Cache gespeichert, dh unser Butler schreibt alles auf, weil er ein guter Butler ist - was ist, wenn Sie Ihre Bestellung nächstes Jahr wiederholen möchten? Und solche Pläne können im Prinzip viele sein.
Arten von Verbindungen im AbfrageplanEs gibt drei Verbindungen, auf die Sie bei der Abfrage stoßen können:
- Verschachtelte Schleife.
- Join zusammenführen.
- Hash beitreten.
Lassen Sie uns zusammenfassen, warum wir den Abfrageplan überhaupt lesen sollten, bevor wir uns näher mit den einzelnen Themen befassen. Dies ist tatsächlich sehr nützlich, da Sie lernen werden:
- welcher Index verwendet wird;
- in welcher Reihenfolge beitreten;
- was aus dem Puffer ausgewählt wird;
- Wie viel der Server für den Vorgang ausgibt?
- Was ist der Unterschied zwischen einem hypothetischen und einem realen Plan?
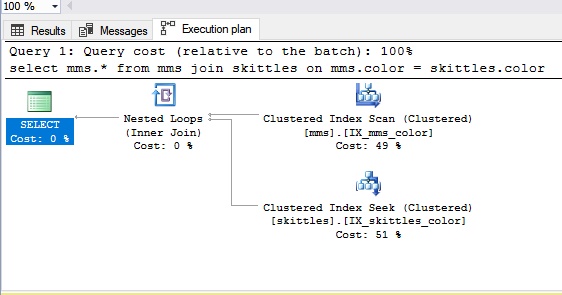
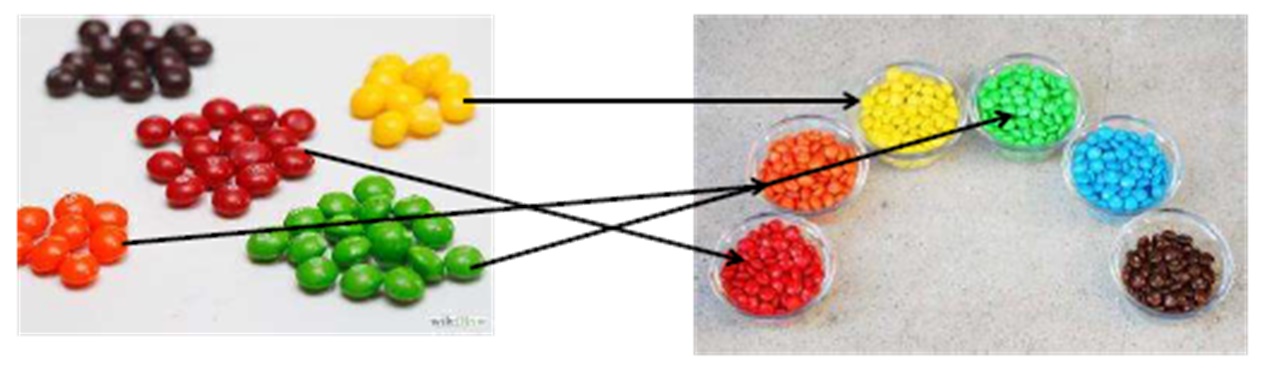
Verschachtelte SchleifeAngenommen, wir müssen Daten aus verschiedenen Tabellen zusammenführen. Lassen Sie uns diese Tabellen als ... eine kleine Menge Skittles-Pralinen und die vollständige Verpackung von M & M präsentieren.

Wenn wir einen Typ mit verschachtelter Schleife anschließen, nehmen wir die Kegelsüßigkeit und dann die blinde Süßigkeit aus dem Paket von M & M. Wenn wir nicht auf ein Bonbon der gleichen Farbe stoßen (dies ist unser Zustand), erhalten wir das nächste, dh es gibt eine übliche Büste. Daher können wir sagen, dass die Nested-Loop-Verbindung besser für kleine Datenmengen geeignet ist. Wenn es viele Daten gibt, ist Busting natürlich nicht die beste Option.

Mal sehen, wie es im SQL-Bereich aussieht:
 Join zusammenführen
Join zusammenführenEine Verbindung wird für große Datenmengen verwendet. Wenn Sie einen Merge-Join haben, haben beide Tabellen einen Index, über den sie verbunden werden können. Bei Süßigkeiten ist es so, als hätten wir sie im Voraus nach Farben geordnet.
Es sieht so aus:

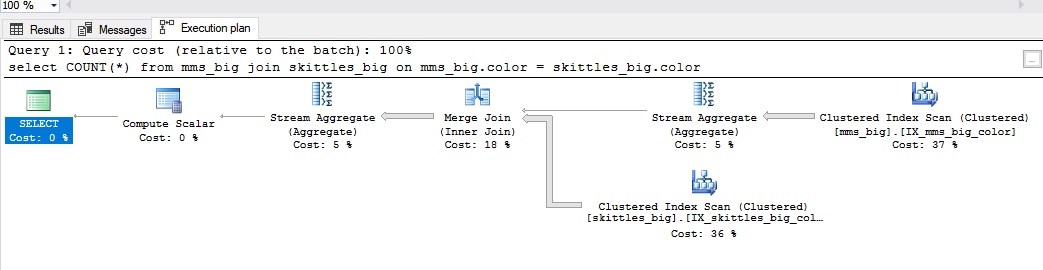
Merge Join ist in folgenden Fällen gut:
- große Datenmengen;
- die gleichen Verbindungsfelder des gleichen Typs;
- Die Verbindungsfelder haben Indizes.
Hash beitretenHash-Join wird für unsortierte große Datenmengen verwendet. Um in diesem Fall die Tabellen zu verbinden, müssen Sie etwas erstellen, das den Index nachahmt.
Beispiel für einen Hash-Join:
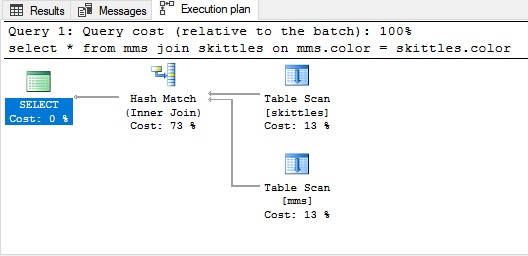
Aus Gründen der Klarheit erinnern wir uns an unsere Süßigkeiten:

Die Verwendung von Hash Join umfasst zwei Aktionsphasen:
- Erstellen - Eine Hash-Tabelle wird auf der kleinsten Tabelle erstellt. Für jeden Wert in Tabelle Nr. 1 wird ein Hash berücksichtigt. Der Wert wird in einer Hash-Tabelle gespeichert und der berechnete Hash wird als Schlüssel verwendet.
- Sonde. Für jede Zeile aus Tabelle Nr. 2 wird der Hashwert für die in join (operator =) angegebenen Felder berechnet. In der Hash-Tabelle wird nach einem Hash gesucht, Feldwerte werden überprüft.
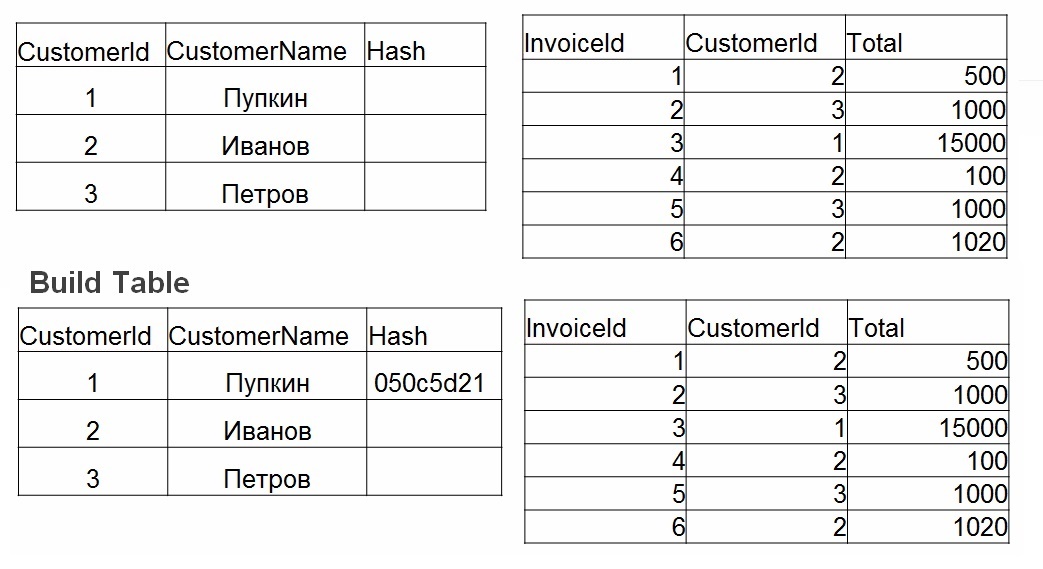
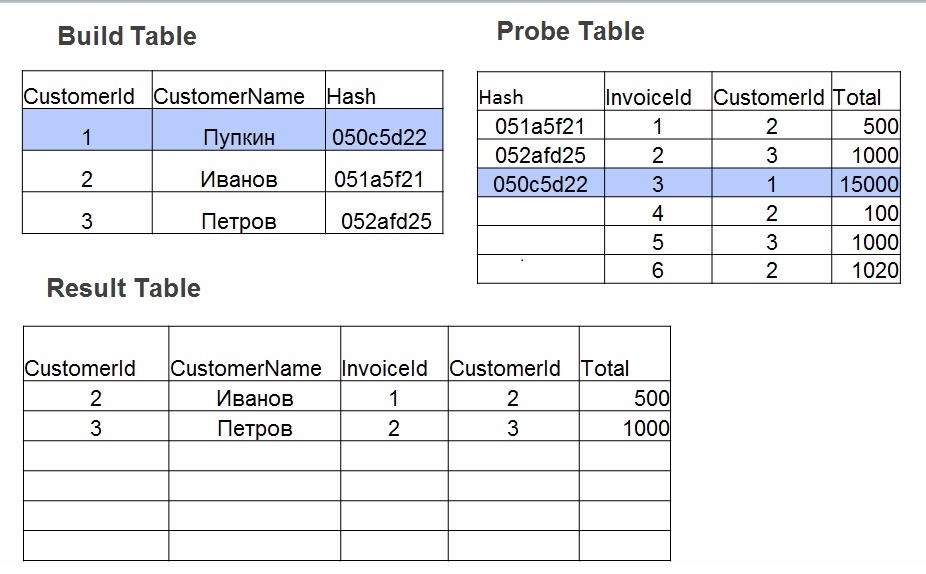
Wenn Hash-Join gut ist:
- großer Datensatz;
- keine Randindizes.
Ein wichtiger Punkt: Wenn nicht genügend Speicher vorhanden ist, wird die Aufnahme auf Tempdb - auf Festplatte übertragen.
Freunde, zusätzlich zu den oben genannten, enthielt die offene Lektion auch andere interessante Punkte, die am besten durch das Ansehen des Videos gesehen werden können. Wir empfehlen Ihnen, den
Tag der
offenen Tür des Kurses "MS SQL Server Developer" zu besuchen, an dem Sie dem Lehrer alle Ihre Fragen stellen können.
PS-Lehrerin
Kristina Kucherova dankt Jes Schultz Borland für ihre
Präsentation mit den PASS Summitt-Ausführungsplänen: Das Geheimnis für den Erfolg der Abfrageoptimierung, die bei der Vorbereitung der offenen Lektion verwendet wurden.