Hallo Habr!
Im Dezember gewann unser Kollege von Advanced Analytics, Leonid Sherstyuk, den ersten Platz in der Kompetenz für maschinelles Lernen und Big Data bei der 2. DigitalSkills-Branchenmeisterschaft. Dies ist ein „digitaler“ Zweig bekannter professioneller Wettbewerbe, die von WorldSkills Russia organisiert werden. Insgesamt nahmen mehr als 200 Personen an der Meisterschaft teil und kämpften um die Führung in 25 digitalen Kompetenzen - Unternehmensschutz gegen Bedrohungen der inneren Sicherheit, Internet-Marketing, Entwicklung von Computerspielen und Multimedia-Anwendungen, Quantentechnologien, Internet der Dinge, Industriedesign usw.

Als Beispiel für maschinelles Lernen wurde die Aufgabe vorgeschlagen, Defekte in Pipelines von Kernkraftwerken, Öl- und Gaspipelines mithilfe eines halbautomatischen Ultraschallprüfungssystems zu überwachen und zu erkennen.
Leonid wird erzählen, was beim Wettbewerb war und wie er es geschafft hat, unter dem Schnitt zu gewinnen.
WorldSkills ist eine internationale Organisation, die weltweit Wettbewerbe für berufliche Fähigkeiten organisiert. Traditionell nahmen Vertreter von Industrieunternehmen und Studenten einschlägiger Universitäten an diesen Wettbewerben teil und zeigten ihre Fähigkeiten in Arbeitsspezialitäten. Seit kurzem treten digitale Nominierungen beim Wettbewerb auf, bei dem junge Spezialisten in den Bereichen Robotik, Anwendungsentwicklung, Informationssicherheit und in anderen Berufen, die Sie nicht einmal als Arbeitnehmer bezeichnen können, gegeneinander antreten. Bei einer dieser Nominierungen - beim maschinellen Lernen und beim Arbeiten mit Big Data - nahm ich in Kasan am DigitalSkills-Wettbewerb teil, der unter der Schirmherrschaft von WS stattfand.
Da die Kompetenz für den Wettbewerb neu ist, konnte ich mir nur schwer vorstellen, was mich erwartet. Für alle Fälle wiederholte ich alles, was ich über die Arbeit mit Datenbanken und verteiltem Computing, Metriken und Trainingsalgorithmen, statistischen Kriterien und Vorverarbeitungsmethoden weiß. Da ich mit den ungefähren Bewertungskriterien vertraut war, verstand ich nicht, wie es möglich sein würde, eine vollwertige Arbeit mit Hadoop zusammenzubringen und in 6 kurzen Sitzungen einen Chat-Bot zu erstellen.
Der gesamte Wettbewerb dauert 3 Tage und umfasst 6 Sitzungen. Jede Sitzung dauert 3 Stunden mit einer Pause, für die Sie mehrere Aufgaben ausführen müssen, die in einem sinnvollen Zusammenhang zueinander stehen. Auf den ersten Blick mag es scheinen, dass Zeit genug ist, aber in Wirklichkeit dauerte es ein rasantes Tempo, um alles zu schaffen, was gedacht war.
Beim Wettbewerb wurde erwartet, dass nicht mit Big Data gearbeitet werden kann, und der gesamte Aufgabenpool wurde auf die Analyse eines begrenzten Datensatzes reduziert.
Tatsächlich wurden wir gebeten, den Weg eines der Organisatoren zu wiederholen, zu dem Kunden mit ihrem Problem und ihren Daten kamen und von dem sie innerhalb weniger Wochen ein kommerzielles Angebot erwarteten.
Wir haben mit den Daten des PUZK (halbautomatisches Ultraschallkontrollsystem) gearbeitet. Das System dient zur Überprüfung der Verbindungen in der Rohrleitung auf Risse und Defekte. Die Installation selbst verläuft entlang einer am Rohr montierten Schiene und führt bei jedem Schritt 16 Messungen durch. Unter idealen Bedingungen und ohne Defekte sollten einige Sensoren das maximale Signal liefern, andere - Null; In Wirklichkeit waren die Daten sehr verrauscht, und die Beantwortung der Frage, ob an einem bestimmten Ort ein Defekt vorliegt, wurde zu einer nicht trivialen Aufgabe.
 Installation des Luftverteidigungssystems
Installation des LuftverteidigungssystemsDer erste Tag war dem Kennenlernen, Bereinigen und Erstellen beschreibender Statistiken gewidmet. Wir erhielten nur minimale Hintergrundinformationen über die Installation und die am Gerät montierten Sensortypen. Zusätzlich zur Datenvorverarbeitung mussten wir feststellen, zu welchem Typ die Sensoren gehören und wie sie sich auf dem Gerät befinden.
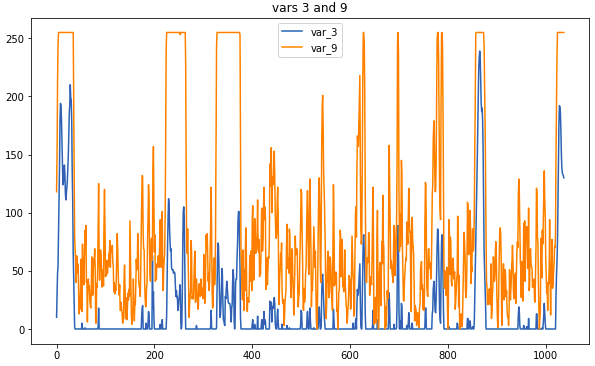 Beispieldaten: So sehen verwandte Sensoren aus
Beispieldaten: So sehen verwandte Sensoren ausDie Hauptvorverarbeitungsoperation besteht darin, Messungen durch einen gleitenden Durchschnitt zu ersetzen. Wenn das Fenster zu groß war, bestand die Gefahr, dass zu viele Informationen verloren gingen, aber Korrelationen, die zur Bestimmung des Typs beitragen, waren visueller. Einige Verbindungen waren ohne Vorverarbeitung erkennbar. Es blieb jedoch keine Zeit, die Rohdaten sorgfältig zu untersuchen, weshalb die Verwendung von Korrelogrammen unabdingbar ist.
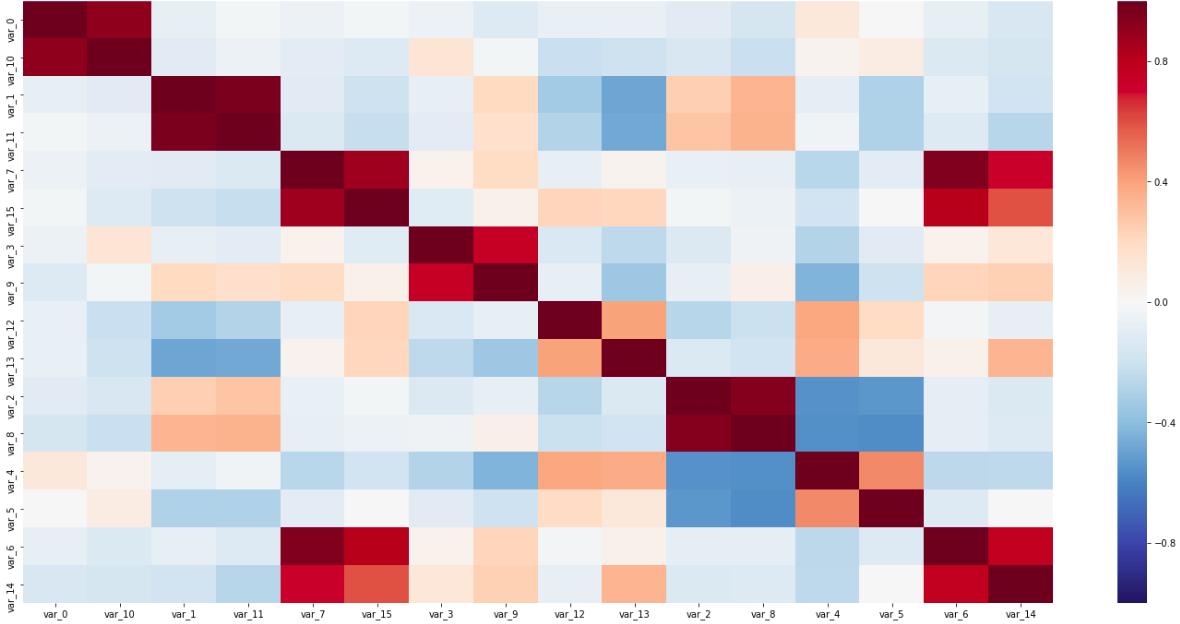 Korrelationsmatrix
KorrelationsmatrixAuf dieser Matrix sind beide Sensorpaare entlang der Diagonale, die eng miteinander verbunden sind, und umgekehrt korrelierende Variablen sichtbar; All dies half bei der Bestimmung der Sensortypen.
Der letzte obligatorische Punkt war, die Sensoren auf eine Koordinate zu reduzieren. Da das Messgerät deutlich mehr als einen Messschritt umfasste und die Sensoren über das gesamte Gerät verteilt waren, war dies ein obligatorischer Schritt vor der weiteren Verwendung von Daten für das Training.
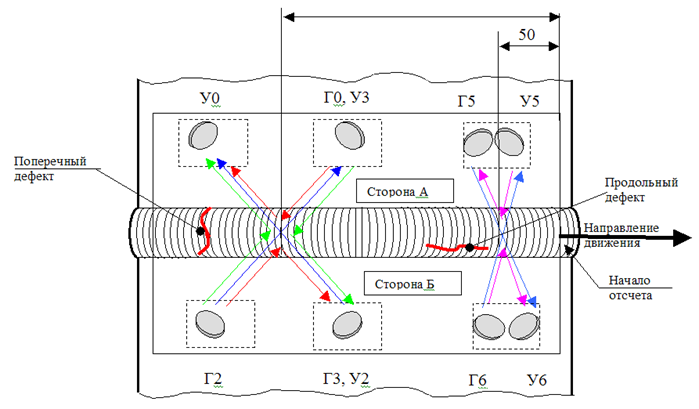
\.
Anordnung der Sensoren an der AnlageDas Diagramm der Installation von Sensoren am Gerät zeigt, dass wir die Abstände zwischen den drei Gruppen von Sensoren ermitteln müssen. Der einfachste und schnellste Weg besteht darin, festzustellen, auf welchem Segment des Geräts sich jeder Sensor befinden soll, und dann nach der maximalen Korrelation zu suchen, wobei ein Teil der Messungen schrittweise verschoben wird.
Diese Phase wurde durch die Tatsache erschwert, dass meine Annahmen über den Sensortyp nicht garantiert waren. Daher musste ich alle Korrelationen, Typen und Schemata betrachten und diese zu einem einzigen konsistenten System verknüpfen.
Für den zweiten Tag mussten wir die Daten für das Training vorbereiten und Clustering nach Punkten durchführen und dann einen Klassifikator erstellen.
Während der Aufbereitung der Daten entfernte ich zu korrelative Messwerte und fügte als synthetisches Merkmal den gleitenden Durchschnitt, die Ableitung und den Z-Score hinzu. Zweifellos könnte die Synthese neuer Variablen ziemlich weit verbreitet sein, aber die Zeit hat ihre Grenzen auferlegt.
Clustering kann dazu beitragen, fehlerhafte Punkte von allen anderen zu trennen. Ich habe 3 Methoden ausprobiert: k-means, Birch und DBScan, aber leider hat keine von ihnen ein gutes Ergebnis geliefert.
Für den Vorhersagealgorithmus wurde uns völlige Freiheit gegeben; Es wurde nur das Format angegeben, das am Ausgang abgerufen werden soll. Der Algorithmus sollte eine Tabelle (oder auf sie reduzierbare Daten) bereitstellen, in der eine Zeile einem Riss und den Spalten ihre Eigenschaften (wie Länge, Breite, Typ und Seite) entspricht. Es schien mir die einfachste Option zu sein, bei der wir für jeden Punkt der Testprobe eine Vorhersage treffen und dann die benachbarten zu einem Riss kombinieren. Als Ergebnis habe ich 3 Klassifikatoren erstellt, die die folgenden Fragen beantworteten: Auf welcher Seite der Naht befindet sich der Defekt, wie tief geht er und zu welchem Typ gehört er (in Längsrichtung oder in Querrichtung).
Hier ist die Tiefe auffällig, die durch Regression vorhergesagt werden sollte; In der markierten Stichprobe fand ich jedoch nur 5 eindeutige Tiefen, sodass ich diese Vereinfachung für akzeptabel hielt.
 Bewertungsmetriken für Algorithmen
Bewertungsmetriken für AlgorithmenVon allen Algorithmen (ich habe es geschafft, logistische Regression, entscheidenden Baum und Gradienten-Boosting zu versuchen) war Boosting wie erwartet am besten. Die Metriken sind zweifellos sehr angenehm, aber es ist ziemlich schwierig, die Funktionsweise der Algorithmen ohne Ergebnisse in einem neuen Testsatz zu bewerten. Die Organisatoren kehrten nie mit bestimmten Messwerten zurück und beschränkten sich auf einen allgemeinen Kommentar, dass niemand den Test durchgeführt hatte, sowie auf eine verspätete Stichprobe.
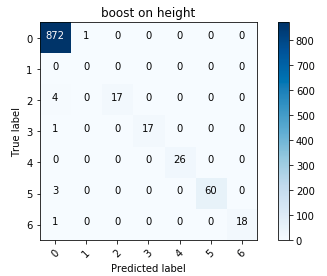 Fehlermatrix zum Boosten
Fehlermatrix zum BoostenIm Allgemeinen war ich mit den Ergebnissen zufrieden; Insbesondere die Reduzierung der Höhe auf eine kategoriale Variable hat sich ausgezahlt.
Am letzten Tag mussten wir die geschulten Algorithmen in einem Produkt zusammenfassen, das ein potenzieller Kunde verwenden konnte, und eine Präsentation unserer unternehmensfähigen Lösung vorbereiten.
Hier half mir der Perfektionismus beim Schreiben von relativ sauberem Code, der auch in einer begrenzten Zeit nicht verschwand. Aus den vorgefertigten Codeteilen entwickelte sich der Prototyp schnell, und ich hatte Zeit, die Fehler zu debuggen. Im Gegensatz zu den vorherigen Phasen spielte hier die Leistung der Lösung eine wichtigere Rolle als die Erfüllung formaler Kriterien.
 Fertiges Produkt - CLI-Dienstprogramm
Fertiges Produkt - CLI-DienstprogrammGegen Ende der Sitzung erhielt ich ein CLI-Dienstprogramm, das einen Quellordner als Eingabe akzeptiert und Tabellen mit den Ergebnissen der Vorhersage in einer für den Technologen geeigneten Form zurückgibt.
In der letzten Phase hatte ich die Gelegenheit, über meine Erfolge zu sprechen und zu sehen, wozu andere Teilnehmer kamen. Selbst unter strengen Kriterien waren unsere Entscheidungen völlig anders - jemand hat erfolgreich geclustert, andere haben gekonnt lineare Methoden angewendet. Während der Präsentationen betonten die Teilnehmer ihre Stärken - einige beschäftigten sich mit dem Verkauf des Produkts, andere vertieften sich tiefer in technische Details; Es gab schöne Grafiken und adaptive Lösungsoberflächen.
 Der Hauptvorteil meiner Lösung passt auf eine Folie
Der Hauptvorteil meiner Lösung passt auf eine FolieWas ist mit dem Wettbewerb im Allgemeinen?
Wettbewerbe dieser Art sind eine großartige Gelegenheit, um herauszufinden, wie schnell Sie Aufgaben ausführen können, die für Ihr Fachgebiet typisch sind. Die Kriterien wurden so zusammengestellt, dass nicht derjenige, der die besten Ergebnisse erzielt hat (wie zum Beispiel bei Kaggle), die meisten Punkte erhält, sondern der die für die tägliche Arbeit in der Branche typischen Vorgänge am schnellsten ausführen kann. Meiner Meinung nach kann die Teilnahme und der Sieg an solchen Wettbewerben einem potenziellen Arbeitgeber nicht weniger als Erfahrung in der Branche bei Hackathons und Kaggle verraten.
Lenonid Sherstyuk,
Datenanalyst, Advanced Analytics, SIBUR