In meinem vorherigen Projekt standen wir vor der Aufgabe, eine
umgekehrte Geokodierung für viele Paare geografischer Koordinaten durchzuführen. Die umgekehrte Geokodierung ist eine Prozedur, bei der ein Breiten- und Längengradpaar mit der Adresse oder dem Namen eines Objekts auf der Karte abgeglichen wird, zu dem der angegebene Punkt oder die angegebenen Koordinaten gehören oder in dessen Nähe er sich befindet. Das heißt, wir nehmen die Koordinaten, sagen diese: @ 55.7602485,37.6170409, und wir erhalten das Ergebnis entweder "Russland, der zentrale Bundesbezirk, Moskau, Theaterplatz, so und so Haus" oder zum Beispiel "Das Bolschoi-Theater".
Wenn sich die Adresse oder der Name am Eingang befindet und die Koordinaten am Ausgang liegen, handelt es sich bei dieser Operation um eine
direkte Geokodierung . Wir hoffen, dass wir später darüber sprechen können.
Als Eingabe hatten wir ungefähr 100.000 oder 200.000 Punkte an der Eingabe, die im Hadoop-Cluster als Hive-Tabelle lagen. Dies soll den Umfang der Aufgabe verdeutlichen.
Spark wurde schließlich als Verarbeitungswerkzeug ausgewählt, obwohl wir dabei sowohl MapReduce als auch Apache Crunch ausprobiert haben. Aber dies ist eine separate Geschichte, die vielleicht ihren Beitrag verdient.
Einfache Lösung mit erschwinglichen Mitteln
Zunächst haben wir versucht, uns sozusagen dem Problem zu nähern. Als Tool gab es einen ArcGIS-Server, der einen REST-Service für die umgekehrte Geokodierung bereitstellte. Die Verwendung ist recht einfach. Dazu führen wir eine http GET-Anfrage mit der folgenden URL durch:
http://-url/GeocodeServer/reverseGeocode?<>
Von den vielen Parametern reicht es aus, location = x, y zu setzen (die Hauptsache ist nicht zu verwechseln, welcher von ihnen der Breitengrad und welcher der Längengrad ist;). Und jetzt haben wir bereits JSON mit den Ergebnissen: Land, Region, Stadt, Straße, Hausnummer. Beispiel aus der Dokumentation:
{ "address": { "Match_addr": "Beeman's Redlands Pharmacy", "LongLabel": "Beeman's Redlands Pharmacy, 255 Terracina Blvd, Redlands, CA, 92373, USA", "ShortLabel": "Beeman's Redlands Pharmacy", "Addr_type": "POI", "Type": "Pharmacy", "PlaceName": "Beeman's Redlands Pharmacy", "AddNum": "255", "Address": "255 Terracina Blvd", "Block": "", "Sector": "", "Neighborhood": "South Redlands", "District": "", "City": "Redlands", "MetroArea": "Inland Empire", "Subregion": "San Bernardino County", "Region": "California", "Territory": "", "Postal": "92373", "PostalExt": "", "CountryCode": "USA" }, "location": { "x": -117.20558993392585, "y": 34.037880040538894, "spatialReference": { "wkid": 4326, "latestWkid": 4326 } } }
Sie können zusätzlich angeben, welche Arten von Antworten wir möchten - Postanschriften oder POI (Punkt von Interesse, um Antworten wie „Bolschoi-Theater“ zu erhalten) oder ob wir beispielsweise Straßenkreuzungen benötigen. Sie können auch den Radius angeben, innerhalb dessen ein benanntes Objekt vom angegebenen Punkt aus durchsucht wird.
Um die Qualität der Antwort schnell zu überprüfen, können Sie den Abstand zwischen dem Startpunkt in den Anforderungsparametern und dem empfangenen Punkt - Ort in der Serviceantwort schätzen.
Es scheint, dass jetzt alles gut wird. Aber da war es. Unsere ArcGIS-Instanz war ziemlich langsam, dem Server wurden 4 Kerne und etwa 8 Gigabyte RAM zugewiesen. Infolgedessen konnte die Aufgabe im Cluster unsere 200.000 Punkte sehr schnell lesen, beruhte jedoch auf der REST- und ArcGIS-Leistung. Die Geokodierung aller Punkte dauerte Stunden. Gleichzeitig haben wir in Hadoop nur 8 Kerne und ein wenig Speicher zugewiesen. Da das Laden des ArcGIS-Servers jedoch viele Stunden lang nahezu 100% betrug, haben uns die zusätzlichen Ressourcen im Cluster nichts gebracht.
ArcGIS kann keine Batch-Reverse-Geokodierungsvorgänge ausführen, daher wird die Anforderung für jeden Punkt einmal ausgeführt. Übrigens, wenn der Dienst nicht antwortet, fallen wir durch Zeitüberschreitung oder mit einem Fehler ab, und was damit zu tun ist, ist ein Problem mit einer nicht offensichtlichen Antwort. Versuchen Sie es vielleicht noch einmal oder schließen Sie den gesamten Vorgang ab und wiederholen Sie ihn für die Rohpunkte.
In der zweiten Näherung führen wir den Cache ein
Zunächst stellten wir fest, dass viele Punkte in unserem Satz sich wiederholende Koordinaten haben. Der Grund ist einfach: Offensichtlich ist die GPS-Genauigkeit nicht gut genug, damit sich die Koordinaten der zwei Meter voneinander entfernten Punkte am Ausgang unterscheiden, oder die Koordinaten, die nicht vom GPS, sondern von einer anderen Basis erhalten wurden, wurden einfach in die Quellendatenbank eingegeben. Im Allgemeinen spielt es keine Rolle, warum dies so ist. Hauptsache, dies ist eine sehr typische Situation. Mit dem vom Service empfangenen Ergebnis-Cache können Sie jedes Koordinatenpaar nur einmal geocodieren. Und wir können uns den Speicher für den Cache durchaus leisten.
Tatsächlich wurde die erste Änderung des Algorithmus trivial gemacht - alle von REST erhaltenen Ergebnisse wurden dem Cache hinzugefügt, und für alle Punkte wurde zuerst nach den darin enthaltenen Koordinaten gesucht. Wir haben nicht einmal damit begonnen, einen gemeinsamen Cache für alle Spark-Prozesse zu erstellen - auf jedem Knoten des Clusters hatte er einen eigenen.
Auf so einfache Weise konnten wir eine Beschleunigung von bis zu etwa dem Zehnfachen erzielen, was ungefähr der Anzahl der Koordinatenwiederholungen im ursprünglichen Satz entspricht. Es war schon akzeptabel, aber immer noch sehr langsam.
Nun, unser Kunde sagte uns zu diesem Zeitpunkt, wenn wir die Adressen nicht schneller herausfinden können, können wir dann zumindest eine Stadt schnell identifizieren? Und wir haben aufgenommen ...
Vereinfachte Lösung zur Implementierung der Geomerty-API
Was müssen wir eine Stadt definieren? Wir hatten die Geometrie der Regionen Russlands, die administrativ-territoriale Aufteilung, ungefähr auf die Bezirke der Stadt abgestimmt.
Sie können diese Daten zum Beispiel
hier nehmen . Was ist da Dies ist eine Datenbank der Verwaltungsgrenzen der Russischen Föderation für Ebenen von 2 (Land) bis 9 (Stadtbezirke). Das Format ist entweder Geojson oder CSV (während die Geometrie selbst im wkt-Format vorliegt). Insgesamt umfasst die Datenbank etwa 20.000 Datensätze.
Eine neue vereinfachte Lösung des Problems sah folgendermaßen aus:
- Hochladen von ADT-Daten in Hive.
- Für jeden Punkt mit Koordinaten suchen wir in der Tabelle der territorialen Aufteilung nach Polygonen, in die dieser Punkt eintritt.
- Sortieren Sie die gefundenen Polygone nach Ebene.
Als Ergebnis erhalten wir so etwas wie: Russland, den zentralen Bundesbezirk, Moskau, so und so einen Verwaltungsbezirk, ein Gebiet von so und so, dh eine Liste von Gebieten, zu denen unser Punkt gehört.
ADT wird geladen
Um CSV einfacher herunterzuladen, verwenden wir
Kite . Dieses Tool kann sehr gut ein Schema für Hive erstellen, das auf den Spaltenüberschriften in CSV basiert. Tatsächlich besteht der Import aus drei Befehlen (von denen einer für jede Ebenendatei wiederholt wird):
kite-tools csv-schema admin_level_2.csv --class al --delimiter \; >adminLevel.avrs kite-tools create dataset:hive:/default/levelswkt -s adminLevel.avrs kite-tools csv-import admin_level_2.csv dataset:hive:/default/levelswkt --delimiter \; ... kite-tools csv-import admin_level_10.csv dataset:hive:/default/levelswkt --delimiter \;
Was haben wir hier gemacht? Das erste Team hat uns ein Avro-Schema für csv erstellt, für das wir einige Parameter des Schemas (in diesem Fall Klasse) und ein Feldtrennzeichen für CSV angegeben haben. Als nächstes lohnt es sich, das erhaltene Diagramm mit Ihren Augen zu betrachten, und es ist möglich, einige Korrekturen vorzunehmen, da Kite nicht alle Zeilen unserer Datei, sondern nur einige Beispiele betrachtet, sodass manchmal falsche Annahmen über den Datentyp getroffen werden können (ich habe drei Zahlen gesehen - das habe ich entschieden numerische Spalte, und dann ging die Zeile).
Nun, basierend auf dem Schema erstellen wir einen Datensatz (dies ist der allgemeine Begriff Kite, der Tabellen in Hive verallgemeinert, Tabellen in HBase und etwas anderes). In diesem Fall ist die Datenbank standardmäßig (für Hive ist sie mit dem Schema identisch), und levelwkt ist der Name unserer Tabelle.
Nun, die neuesten Befehle laden CSV-Dateien in unseren Datensatz hoch. Nachdem der Download erfolgreich abgeschlossen wurde, können Sie die Anforderung bereits abschließen:
select * from levelswkt;
irgendwo in der Farbe.
Arbeite mit Geometrie
Für die Arbeit mit Geometrie in Java haben wir die Esri
Java Geometry API (ArcGIS-Entwickler) ausgewählt. Grundsätzlich war es möglich, andere Frameworks zu verwenden, es gibt eine Auswahl an Open Source, zum Beispiel die weithin bekannte
JTS Topology Suite oder
Geotools .
Die erste Aufgabe ermöglicht es uns, mit einem anderen Framework derselben Esri-Firma fertig zu werden, das als
Spatial Framework für Hadoop bezeichnet wird und auf dem ersten basiert. Tatsächlich benötigen wir das sogenannte SerDe, das Serialisierungs-Deserialisierungs-Modul für Hive, mit dem wir eine Reihe von Geojson-Dateien als Tabelle in Hive darstellen können, deren Spalten aus Geojson-Attributen stammen. Und die Geometrie selbst wird zu einer weiteren Spalte (mit Binärdaten). Als Ergebnis haben wir eine Tabelle, deren eine Spalte die Geometrie einer bestimmten Region ist, und der Rest sind ihre Attribute (Name, Ebene in der ADT usw.). Diese Tabelle steht der Spark-Anwendung zur Verfügung.
Wenn wir die Datenbank im CSV-Format laden, haben wir eine Spalte, in der die Geometrien in Textform im
WKT- Format vorliegen. In diesem Fall kann Spark zur Laufzeit mithilfe der Geometrie-API ein Geometrieobjekt erstellen.
Wir haben uns aus einem einfachen Grund für das CSV-Format (und WKT) entschieden - wie jeder weiß, belegt Russland auf der Karte das Gebiet mit den Koordinaten von Tschukotka jenseits des 180-Meridians. Das Geojson-Format hat eine Einschränkung: Alle darin enthaltenen Polygone müssen auf 180 Grad begrenzt sein, und diejenigen, die den 180-Meridian kreuzen, müssen in zwei Teile geschnitten werden. Als Ergebnis erhalten wir beim Importieren von Geometrie in die Geometrie-API ein Objekt, für das die Geometrie-API den Begrenzungsrahmen (umschließendes Rechteck) für den russischen Rand falsch definiert. Es stellt sich heraus, dass die Antwort -180.180 in der Länge ist. Was natürlich nicht stimmt - in Wirklichkeit nimmt Russland etwa 20 bis -170 Grad ein. Dies ist ein Geometrie-API-Problem, das heute möglicherweise bereits behoben ist, aber dann mussten wir es umgehen.
WKT hat kein solches Problem. Sie fragen sich vielleicht, warum wir eine Bounding Box brauchen? Dann werde ich erzählen;)
Es bleibt das sogenannte PIP-Problem zu lösen, Punkt in Poligon. Die Java-Geometrie-API kann dies erneut tun. Für uns ist es einfach, eine Geometrie vom Typ Point, ein zweites Polygon (Multipoligon) für die Region und eine Methode.
Infolgedessen sah die zweite Lösung und auch auf der Stirn folgendermaßen aus: Die Spark-Anwendung lädt das ADT einschließlich der Geometrie. Daraus wird so etwas wie Kartenname-> Geometrie erstellt (eigentlich etwas komplizierter, da die ADTs ineinander verschachtelt sind und wir nur in den unteren Ebenen suchen müssen, die in der bereits gefundenen oberen Ebene enthalten sind. Infolgedessen gibt es eine Art Geometriebaum, der entsprechend der Quelle müssen noch Daten erstellt werden). Und dann erstellen wir einen Spark-Datensatz mit unseren Punkten und wenden für jeden Punkt unsere eigene UDF an, die den Eintrag des Punkts in alle Geometrien (im Baum) überprüft.
Das Schreiben einer neuen Version dauert ungefähr einen Arbeitstag, da das Spatial Framework für Hadoop-Bundle gute Beispiele für die direkte Lösung der PIP-Aufgabe enthielt (allerdings mit mehreren anderen Mitteln).
Wir fangen an und ... oh, Entsetzen, etwas wurde nicht schneller. Schau nochmal zu. Es ist Zeit, über Optimierung nachzudenken.
Optimierte Lösung, QuadTree
Der Grund für die Bremsen liegt auf der Hand - etwa die Geometrie Russlands, d.h. Außengrenzen, das sind Megabyte Geojson, ein kräftiges Polygon und keines. Wenn wir uns daran erinnern, wie das PIP-Problem gelöst ist, besteht eine der bekannten Methoden darin, einen Strahl von einem Punkt, etwa irgendwo oben, bis ins Unendliche zu erzeugen und zu bestimmen, an wie vielen Punkten er das Polygon schneidet. Wenn die Anzahl der Punkte gerade ist, befindet sich der Punkt außerhalb des Polygons, wenn er ungerade ist, befindet er sich innerhalb.
Hier ist eine Beschreibung
aus dem Wiki .

Es ist klar, dass für ein großes Polygon die Lösung des Schnittpunktproblems so oft kompliziert ist, wie es gerade Linien in unserem Polygon gibt. Daher ist es wünschenswert, die Polygone, in die der Punkt offensichtlich nicht eintreten kann, irgendwie zu verwerfen. Und als zusätzlichen Lebenshack ist es möglich, den Scheck für die Einreise in die Grenzen Russlands fallen zu lassen (wenn wir wissen, dass alle Koordinaten offensichtlich darin enthalten sind).
Dafür ist
ein Quadrantenbaum für uns geeignet. Glücklicherweise befindet sich die Implementierung alle in derselben Geometrie-API (und vielen weiteren).

Die baumbasierte Lösung sieht ungefähr so aus:
- Laden der ATD-Geometrie
- Für jede Geometrie definieren wir ein umschließendes Rechteck
- Wir setzen es in QuadTree, wir bekommen den Index als Antwort
- Der Index wird gespeichert
Als nächstes bei der Verarbeitung von Punkten:
- Wir fragen QuadTree, welche der ihm bekannten Geometrien einen Punkt enthalten kann
- Holen Sie sich die Indizes der Geometrien
- Nur für sie überprüfen wir das Auftreten durch Lösen des PIP-Problems
Die Entwicklung dauert weitere vier Stunden. Wir fangen wieder an und sehen, dass die Aufgabe irgendwie sehr schnell erledigt wurde. Wir prüfen - alles ist in Ordnung, die Lösung ist eingegangen. Und das alles in ein paar Minuten. QuadTree beschleunigt uns um mehrere Größenordnungen.
Zusammenfassung
Also, was haben wir am Ende? Wir haben einen umgekehrten Geokodierungsmechanismus, der auf einem Hadoop-Cluster effektiv parallelisiert und unser anfängliches Problem mit 200.000 Punkten in etwa einer Minute löst. Das heißt, Wir können diese Lösung leicht auf Millionen von Punkten anwenden.
Was sind die Einschränkungen dieser Lösung? Erstens die offensichtliche - sie basiert auf den uns zur Verfügung stehenden ADT-Daten, die a) möglicherweise nicht relevant sind, b) nur auf Russland beschränkt sind.
Und zweitens - wir können das Problem der umgekehrten Geokodierung für andere Objekte als geschlossene Polygone nicht lösen. Und das heißt - auch für die Straße.
Entwicklung
Was kann man damit machen?
Um die aktuellen ADT-Geometrien zu erhalten, ist es am einfachsten, sie von OpenStreetMap abzurufen. Natürlich müssen sie ein wenig arbeiten, aber das ist eine völlig lösbare Aufgabe. Bei Interesse werde ich über die Aufgabe sprechen, OpenStreetMap-Daten ein anderes Mal in einen Hadoop-Cluster zu laden.
Was kann man für Straßen und Häuser tun? Im Prinzip befinden sich die Straßen im selben OSM. Dies sind aber keine geschlossenen Strukturen, sondern Linien. Um festzustellen, dass der Punkt "nahe" an einer bestimmten Straße liegt, müssen Sie ein Polygon für die Straße aus Punkten erstellen, die gleich weit davon entfernt sind, und prüfen, ob er in diese Straße gelangt. Als Ergebnis stellt sich eine Art Wurst heraus ... es sieht ungefähr so aus:
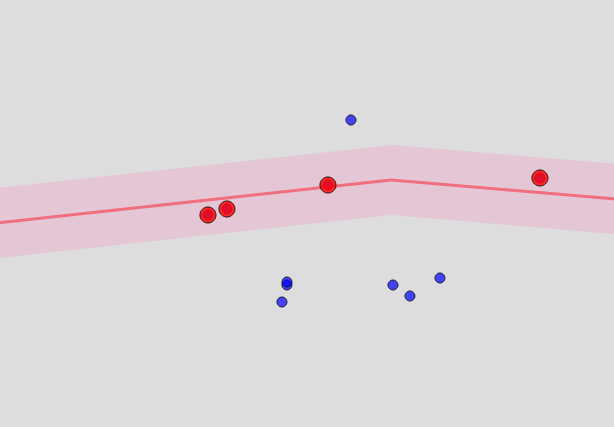
Wie nah ist der Punkt? Dies ist ein Parameter und entspricht in etwa dem Radius, in dem ArcGIS nach Objekten sucht, den ich ganz am Anfang erwähnt habe.
So finden wir Straßen, deren Entfernung von einem Punkt weniger als eine bestimmte Grenze beträgt (z. B. 100 Meter). Und je kleiner diese Grenze ist, desto schneller arbeitet der Algorithmus, aber desto wahrscheinlicher ist es, dass Sie keine einzige Übereinstimmung finden.
Das offensichtliche Problem ist, dass es unmöglich ist, diese sogenannten Puffer im Voraus zu berechnen - ihre Größe ist ein Parameter des Dienstes. Sie müssen im laufenden Betrieb gebaut werden, nachdem wir das gewünschte Gebiet der Stadt identifiziert und aus der OSM-Basis die Straßen ausgewählt haben, die durch dieses Gebiet führen. Die Straßen können jedoch im Voraus ausgewählt werden.
Die Häuser, die sich in dem gefundenen Bereich befinden, bewegen sich auch nirgendwo hin, so dass ihre Liste im Voraus erstellt werden kann - aber das Betreten muss noch im Handumdrehen in Betracht gezogen werden.
Das heißt, Sie müssen zuerst einen Index der Form „Stadtteil“ erstellen -> eine Liste von Häusern mit Links zu Geometrien und eine ähnliche Liste für die Liste der Straßen.
Und sobald wir das Gebiet identifiziert haben, erhalten wir die Liste der Häuser und Straßen, bauen entlang der Straßen der Grenze und lösen nur für sie das PIP-Problem (wahrscheinlich unter Verwendung der gleichen Optimierungen wie für die Grenzen der Regionen). Der Quadrantenbaum für Häuser kann in diesem Fall natürlich auch im Voraus gebaut und irgendwo gespeichert werden.
Unser Hauptziel ist es, den Rechenaufwand zu minimieren und gleichzeitig alles zu maximieren und im Voraus zu erhalten, was berechnet und gespeichert werden kann. In diesem Fall besteht der Prozess aus einer langsamen Phase der Indexerstellung und einer zweiten Phase der Berechnung, die in der Nähe der Online-Version bereits schnell erfolgt.