In früheren Artikeln haben sie bereits darüber geschrieben, wie unsere Texterkennungstechnologie funktioniert:
Bis 2018 wurde die Erkennung japanischer und chinesischer Schriftzeichen auf die gleiche Weise angeordnet: hauptsächlich unter Verwendung von Raster- und Feature-Klassifikatoren. Aber mit dem Erkennen von Hieroglyphen gibt es Schwierigkeiten:
- Eine große Anzahl von Klassen, die unterschieden werden müssen.
- Komplexerer Gerätecharakter als Ganzes.

Es ist ebenso schwierig, eindeutig zu sagen, wie viele Zeichen das chinesische Alphabet schriftlich hat, wie es genau ist, wie viele Wörter auf Russisch zu zählen. In der chinesischen Schrift werden jedoch meistens ~ 10.000 Zeichen verwendet. Mit ihnen haben wir die Anzahl der zur Anerkennung verwendeten Klassen begrenzt.
Beide oben beschriebenen Probleme führen auch dazu, dass Sie eine große Anzahl von Zeichen verwenden müssen, um eine hohe Qualität zu erzielen, und diese Zeichen selbst werden auf den Bildern von Zeichen länger berechnet.
Damit diese Probleme nicht zu einer starken Verlangsamung des gesamten Erkennungssystems führten, musste ich viele Heuristiken verwenden, die in erster Linie darauf abzielten, eine erhebliche Anzahl von Hieroglyphen schnell abzuschneiden, wie dieses Bild definitiv nicht aussieht. Es hat bis zum Ende immer noch nicht geholfen, aber wir wollten unsere Technologie auf ein ganz neues Niveau bringen.
Wir haben begonnen, die Anwendbarkeit von Faltungs-Neuronalen Netzen zu untersuchen, um sowohl die Qualität als auch die Erkennungsgeschwindigkeit von Hieroglyphen zu verbessern. Ich wollte die gesamte Einheit für die Erkennung eines einzelnen Zeichens für diese Sprachen mithilfe neuronaler Netze ersetzen. In diesem Artikel werden wir beschreiben, wie es uns letztendlich gelungen ist.
Ein einfacher Ansatz: Ein Faltungsnetzwerk, um alle Hieroglyphen zu erkennen
Im Allgemeinen ist die Verwendung von Faltungsnetzwerken zur Zeichenerkennung überhaupt keine neue Idee.
Historisch gesehen wurden sie bereits 1998 genau für diese Aufgabe eingesetzt. Das waren zwar keine gedruckten Zeichen, sondern handgeschriebene englische Buchstaben und Zahlen.
In über 20 Jahren hat die Technologie im Bereich des tiefen Lernens natürlich Fortschritte gemacht. Einschließlich fortschrittlicherer Architekturen und neuer Lernansätze.
Die im obigen Diagramm (LeNet) dargestellte Architektur eignet sich heute sehr gut für einfache Aufgaben wie die Erkennung von gedrucktem Text. "Einfach" nenne ich es im Vergleich zu anderen Aufgaben der Bildverarbeitung wie der Suche und Erkennung von Gesichtern.
Es scheint, dass die Lösung nirgends einfacher ist. Wir nehmen ein neuronales Netzwerk, eine Stichprobe markierter Hieroglyphen, und trainieren es für das Klassifizierungsproblem. Leider stellte sich heraus, dass nicht alles so einfach ist. Alle möglichen Änderungen von LeNet für die Klassifizierung von 10.000 Hieroglyphen lieferten keine ausreichende Qualität (zumindest vergleichbar mit dem bereits vorhandenen Erkennungssystem).
Um die erforderliche Qualität zu erreichen, mussten wir tiefere und komplexere Architekturen berücksichtigen: WideResNet, SqueezeNet usw. Mit ihrer Hilfe war es möglich, das erforderliche Qualitätsniveau zu erreichen, aber sie gaben einen starken Geschwindigkeitsabfall - 3-5 mal im Vergleich zum Basisalgorithmus auf der CPU.
Jemand könnte fragen: "Was bringt es, die Geschwindigkeit des Netzwerks auf der CPU zu messen, wenn es auf dem Grafikprozessor (GPU) viel schneller arbeitet?" An dieser Stelle sei darauf hingewiesen, dass die Geschwindigkeit des Algorithmus auf der CPU in erster Linie für uns wichtig ist. Wir entwickeln Technologien für die große Produktpalette von ABBYY. In den meisten Szenarien erfolgt die Erkennung auf der Clientseite, und wir können nicht wissen, dass eine GPU vorhanden ist.
Am Ende kamen wir also zu folgendem Problem: Ein neuronales Netzwerk zum Erkennen aller Zeichen in Abhängigkeit von der Wahl der Architektur funktioniert entweder zu schlecht oder zu langsam.
Zwei-Ebenen-Hieroglyphenerkennungsmodell für neuronale Netze
Ich musste nach einem anderen Weg suchen. Gleichzeitig wollte ich neuronale Netze nicht aufgeben. Es schien, dass das größte Problem eine große Anzahl von Klassen war, weshalb es notwendig war, Netzwerke komplexer Architektur aufzubauen. Aus diesem Grund haben wir beschlossen, kein Netzwerk für eine große Anzahl von Klassen, dh für das gesamte Alphabet, zu trainieren, sondern viele Netzwerke für eine kleine Anzahl von Klassen (Teilmengen des Alphabets) zu trainieren.
Im Allgemeinen wurde das ideale System wie folgt dargestellt: Das Alphabet ist in Gruppen ähnlicher Zeichen unterteilt. Das Netzwerk der ersten Ebene klassifiziert, zu welcher Zeichengruppe ein bestimmtes Bild gehört. Für jede Gruppe wird wiederum ein Netzwerk der zweiten Ebene trainiert, das die endgültige Klassifizierung innerhalb jeder Gruppe erstellt.
Klickbares Bild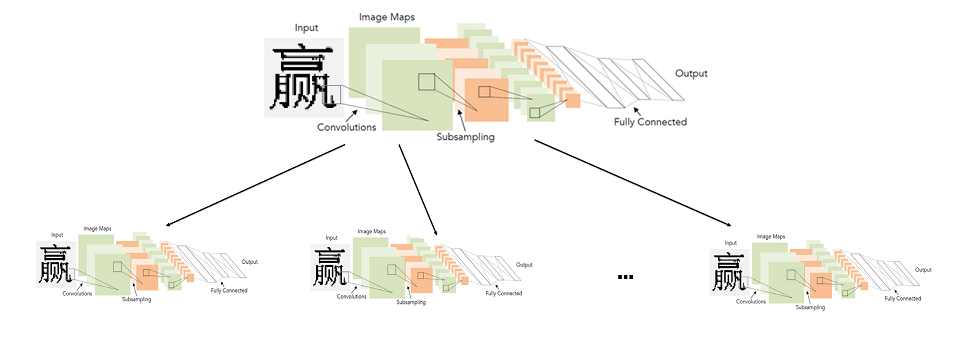
Daher nehmen wir die endgültige Klassifizierung vor, indem wir zwei Netzwerke starten: Das erste bestimmt, welches Netzwerk der zweiten Ebene gestartet werden soll, und das zweite führt bereits die endgültige Klassifizierung durch.
Tatsächlich ist der grundlegende Punkt hier, wie die Zeichen in Gruppen unterteilt werden, damit das Netzwerk der ersten Ebene genau und schnell erstellt werden kann.
Erstellen eines Klassifikators der ersten Ebene
Um zu verstehen, welche Netzwerksymbole leichter zu unterscheiden und welche schwieriger sind, ist es am einfachsten zu untersuchen, welche Zeichen für bestimmte Symbole hervorstechen. Zu diesem Zweck haben wir ein Klassifikator-Netzwerk verwendet, das darauf trainiert ist, alle Zeichen des Alphabets mit guter Qualität zu unterscheiden, und die Aktivierungsstatistik der vorletzten Schicht dieses Netzwerks untersucht. Wir haben begonnen, die endgültigen Feature-Darstellungen zu untersuchen, die das Netzwerk für alle Zeichen erhält.
Gleichzeitig wussten wir, dass das Bild dort ungefähr so aussehen sollte:
Dies ist ein einfaches Beispiel für den Fall der Klassifizierung einer Auswahl handgeschriebener Ziffern (MNIST) in 10 Klassen. Auf der vorletzten verborgenen Ebene, die vor der Klassifizierung liegt, befinden sich nur 2 Neuronen, wodurch die Aktivierungsstatistik einfach in der Ebene angezeigt werden kann. Jeder Punkt in der Grafik entspricht einem Beispiel aus der Testprobe. Die Farbe eines Punktes entspricht einer bestimmten Klasse.
In unserem Fall war die Dimension des Merkmalsraums im Beispiel größer als 128. Wir haben eine Gruppe von Bildern aus einer Testprobe ausgeführt und für jedes Bild einen Merkmalsvektor erhalten. Danach wurden sie normalisiert (geteilt durch die Länge). Aus dem obigen Bild ist ersichtlich, warum sich dies lohnt. Wir haben die normalisierten Vektoren nach der KMeans-Methode geclustert. Wir haben eine Aufschlüsselung der Stichprobe in Gruppen ähnlicher (aus Sicht des Netzwerks) Bilder erhalten.
Am Ende mussten wir jedoch eine Partition des Alphabets in Gruppen und nicht eine Partition des Testbeispiels erstellen. Die erste der zweiten ist jedoch nicht schwer zu erhalten: Es reicht aus, jede Klassenbezeichnung dem Cluster zuzuweisen, der die meisten Bilder dieser Klasse enthält. In den meisten Situationen landet die gesamte Klasse natürlich sogar in einem Cluster.
Nun, das ist alles, wir haben eine Aufteilung des gesamten Alphabets in Gruppen ähnlicher Zeichen. Dann bleibt es, eine einfache Architektur zu wählen und den Klassifikator zu trainieren, um zwischen diesen Gruppen zu unterscheiden.
Hier ist ein Beispiel für zufällige 6 Gruppen, die durch Aufteilen des gesamten Quellalphabets in 500 Cluster erhalten werden:
Konstruktion von Klassifikatoren der zweiten Ebene
Als nächstes müssen Sie entscheiden, welche Zielzeichensätze die Klassifikatoren der zweiten Ebene lernen sollen. Die Antwort scheint offensichtlich zu sein - dies sollten Gruppen von Zeichen sein, die im vorherigen Schritt erhalten wurden. Dies wird funktionieren, aber nicht immer mit guter Qualität.
Tatsache ist, dass der Klassifikator der ersten Ebene in jedem Fall Fehler macht und diese teilweise durch die Konstruktion von Mengen der zweiten Ebene wie folgt ausgeglichen werden können:
- Wir korrigieren eine bestimmte separate Stichprobe von Symbolbildern (die weder an Schulungen noch an Tests teilnehmen).
- Wir führen dieses Beispiel durch einen trainierten Klassifikator der ersten Ebene und markieren jedes Bild mit der Bezeichnung dieses Klassifikators (Gruppenbezeichnung).
- Für jedes Symbol betrachten wir alle möglichen Gruppen, zu denen der Klassifikator der ersten Ebene zu den Bildern dieses Symbols gehört.
- Fügen Sie dieses Symbol allen Gruppen hinzu, bis der erforderliche Abdeckungsgrad T_acc erreicht ist.
- Wir betrachten die letzten Gruppen von Symbolen als Zielmengen der zweiten Ebene, auf denen Klassifikatoren trainiert werden.
Zum Beispiel wurden die Bilder des Symbols "A" vom Klassifikator der ersten Ebene 980 Mal der 5. Gruppe, 19 Mal der 2. Gruppe und 1 Mal der 6. Gruppe zugewiesen. Insgesamt haben wir 1000 Bilder dieses Symbols.
Dann können wir das Symbol „A“ zur 5. Gruppe hinzufügen und eine 98% ige Abdeckung dieses Symbols erhalten. Wir können es der 5. und 2. Gruppe zuordnen und erhalten eine Abdeckung von 99,9%. Und wir können es sofort Gruppen (5, 2, 6) zuordnen und eine 100% ige Abdeckung erhalten.
Im Wesentlichen stellt T_acc ein Gleichgewicht zwischen Geschwindigkeit und Qualität her. Je höher es ist, desto höher ist die endgültige Qualität der Klassifizierung, aber desto größer sind die Zielmengen der zweiten Ebene und desto schwieriger ist die Klassifizierung auf der zweiten Ebene.
Die Praxis zeigt, dass selbst bei T_acc = 1 die Zunahme der Größe von Sätzen infolge des oben beschriebenen Nachfüllvorgangs nicht so signifikant ist - im Durchschnitt etwa zweimal. Dies hängt natürlich direkt von der Qualität des trainierten Klassifikators der ersten Stufe ab.
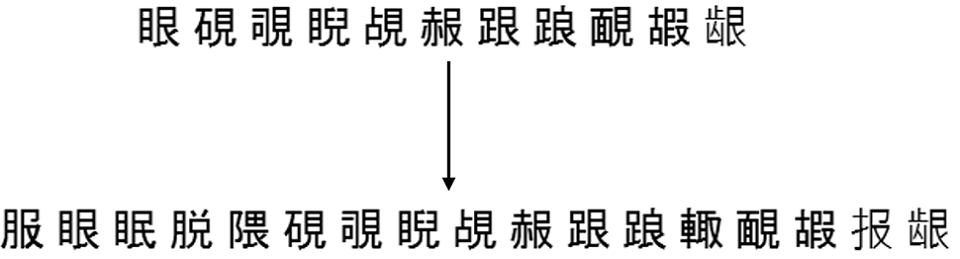
Hier ist ein Beispiel dafür, wie diese Vervollständigung für einen der Sätze aus derselben Partition in 500 Gruppen funktioniert, was höher war:
Ergebnisse der Modelleinbettung
Geschulte zweistufige Modelle haben endlich schneller und besser funktioniert als bisher verwendete Klassifikatoren. Tatsächlich war es nicht so einfach, mit demselben linearen Teilungsgraphen (GLD) „Freunde zu finden“. Dazu musste ich dem Modell separat beibringen, Zeichen von a priori Müll- und Zeilensegmentierungsfehlern zu unterscheiden (um in diesen Situationen ein geringes Vertrauen zurückzugeben).
Das Endergebnis der Einbettung in den folgenden Algorithmus zur vollständigen Dokumentenerkennung (erhalten bei der Sammlung chinesischer und japanischer Dokumente) ist die Geschwindigkeit, die für den vollständigen Algorithmus angegeben wird:
Wir haben die Qualität verbessert und sowohl im normalen als auch im schnellen Modus beschleunigt, während wir die gesamte Zeichenerkennung auf neuronale Netze übertragen haben.
Ein bisschen über End-to-End-Erkennung
Heutzutage verwenden die meisten öffentlich bekannten OCR-Systeme (der gleiche Tesseract von Google) die End-to-End-Architektur neuronaler Netze, um Zeichenfolgen oder deren Fragmente in ihrer Gesamtheit zu erkennen. Aber hier haben wir neuronale Netze genau als Ersatz für ein einzelnes Zeichenerkennungsmodul verwendet. Das ist kein Zufall.
Tatsache ist, dass die Segmentierung einer Zeichenfolge in Zeichen in gedrucktem Chinesisch und Japanisch aufgrund des
monospaced Drucks kein großes Problem darstellt. In dieser Hinsicht verbessert die Verwendung der End-to-End-Erkennung für diese Sprachen die Qualität nicht wesentlich, ist jedoch viel langsamer (zumindest auf der CPU). Im Allgemeinen ist nicht klar, wie der vorgeschlagene zweistufige Ansatz im End-to-End-Kontext verwendet werden soll.
Im Gegenteil, es gibt Sprachen, bei denen die lineare Unterteilung in Zeichen ein Schlüsselproblem darstellt. Explizite Beispiele sind Arabisch, Hindi. Für Arabisch zum Beispiel werden End-to-End-Lösungen bereits aktiv bei uns untersucht. Aber das ist eine ganz andere Geschichte.
Alexey Zhuravlev, Leiter der OCR New Technologies Group