Hallo Habr! Mein Name ist Sergey Lezhnin, ich bin ein leitender Architekt in Sbertekh. Eine der Richtungen meiner Arbeit ist das Unified Frontal System. Dieses System verfügt über einen Konfigurationsparameter-Verwaltungsdienst. Es wird von vielen Benutzern, Diensten und Anwendungen verwendet, was eine hohe Leistung erfordert. In diesem Beitrag werde ich erläutern, wie sich dieser Dienst von der ersten, einfachsten bis zur aktuellen Version entwickelt hat und warum wir schließlich die gesamte Architektur um 180 Grad bereitgestellt haben.

Hier haben wir begonnen - dies ist die erste Implementierung des Parameterverwaltungsdienstes:
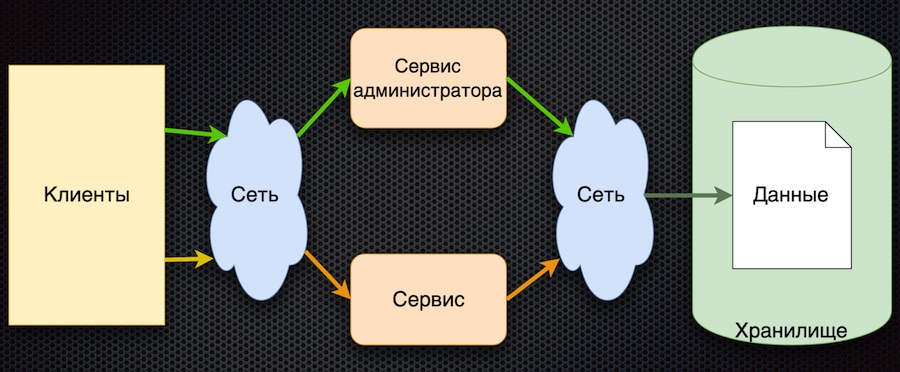
Der Client fordert vom Dienst Konfigurationsparameter an. Der Dienst übersetzt die Anforderung in die Datenbank, empfängt eine Antwort und gibt sie an den Client zurück. Gleichzeitig können Administratoren Parameter über ihren separaten Dienst verwalten: neue Werte hinzufügen, aktuelle ändern.
Dieser Ansatz hat einen Vorteil - Einfachheit. Es gibt mehr Nachteile, obwohl sie alle miteinander verbunden sind:
- häufiger Zugriff auf Speicher über das Netzwerk,
- hoher Wettbewerb um den Zugriff auf die Datenbank (wir haben sie auf einem Knoten),
- schlechte Leistung.
Um die Lasttests zu bestehen, musste diese Architektur die Last nicht mehr bereitstellen als die, die durch direkten Zugriff auf die Datenbank erfolgt. Infolgedessen wurde der Lasttest dieser Schaltung nicht bestanden.
Die zweite Phase: Wir haben beschlossen, die Daten auf der Serviceseite zwischenzuspeichern.

Hier werden die Daten bei der Anforderung zunächst in den gemeinsam genutzten Cache geladen und bei den nächsten Anforderungen aus dem Cache zurückgegeben. Der Dienstadministrator verwaltet die Daten nicht nur, sondern markiert sie auch im Cache, damit sie bei Änderungen aktualisiert werden.
Deshalb haben wir die Anzahl der Zugriffe auf das Repository reduziert. Gleichzeitig stellte sich die Datensynchronisation als einfach heraus, da der Administratordienst Zugriff auf den Cache im Speicher hat und das Zurücksetzen steuert. Wenn andererseits ein Netzwerkfehler auftritt, kann der Client keine Daten empfangen. Im Allgemeinen ist die Logik zum Abrufen von Daten kompliziert: Wenn sich keine Daten im Cache befinden, müssen Sie sie aus der Datenbank abrufen, in den Cache stellen und erst dann zurückgeben. Notwendigkeit, sich weiterzuentwickeln.
Die dritte Entwicklungsstufe ist das clientseitige Zwischenspeichern von Daten:
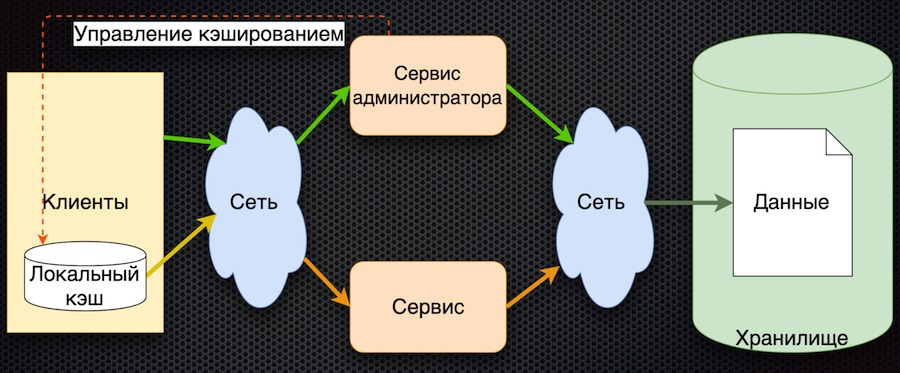
Der Client verfügt über eine Shell für den Zugriff auf den Dienst (das „Client-Modul“), die den lokalen Datencache verbirgt. Befinden sich die angeforderten Daten beim Anfordern nicht im Cache, wird der Dienst aufgerufen. Der Dienst fordert Parameter aus der Datenbank an und gibt sie zurück. Im Vergleich zum vorherigen Schema ist die Caching-Verwaltung hier kompliziert. Um die Parameter zurückzusetzen, muss der Service Kunden benachrichtigen, dass sich diese Parameter geändert haben.
In dieser Architektur reduzieren wir die Anzahl der Aufrufe des Dienstes und der Datenbank. Wenn der Parameter bereits angefordert wurde, kehrt er zum Client zurück, ohne auf das Netzwerk zuzugreifen, selbst wenn der Dienst oder die Datenbank nicht verfügbar ist. Andererseits ist das große Minus, dass die Logik des Datenaustauschs mit dem Client kompliziert ist. Sie müssen ihn zusätzlich über einen Dienst benachrichtigen - beispielsweise über eine Nachrichtenwarteschlange. Der Client muss das Thema abonnieren, er erhält Benachrichtigungen über die Änderung von Parametern und in seinem Cache muss der Client diese zurücksetzen, um neue Werte zu erhalten. Ziemlich kompliziertes Schema.
Schließlich kommen wir im Moment zur letzten Etappe. Dabei haben uns die im Reactive Manifesto formulierten Grundprinzipien geholfen.
- Reaktionsschnell: Das System reagiert so schnell wie möglich.
- Ausfallsicher: Das System reagiert auch im Fehlerfall weiter.
- Elastisch: Das System verwendet Ressourcen entsprechend der Last.
- Nachrichtengesteuert: Bietet Asynchronität und kostenloses Messaging zwischen Systemkomponenten.
Das diesem Ansatz entsprechende Schema erwies sich als recht einfach:
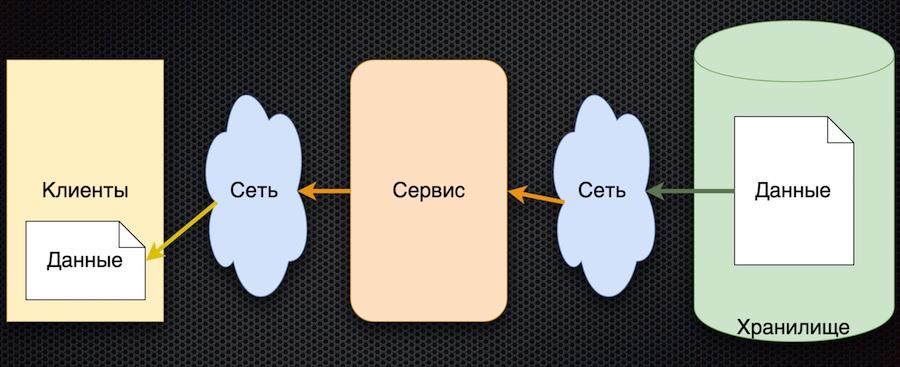
Das allgemeine Prinzip lautet: Der Client abonniert den Konfigurationsparameter, und wenn sich seine Werte ändern, benachrichtigt der Server den Client darüber. Das obige Schema ist leicht vereinfacht: Es spiegelt nicht wider, dass ein Client, wenn er sich anmeldet, initialisieren und den Anfangswert erhalten muss. Aber dann ist da noch die Hauptsache: Die Pfeile haben die Richtung geändert. Früher hat ein Client oder Cache aktiv einen Dienst für Datenänderungen angefordert, jetzt sendet der Dienst selbst Ereignisse zu Datenänderungen und diese werden vom Client aktualisiert.
Diese Architektur hat mehrere wichtige Vorteile. Die Anzahl der Anrufe an den Dienst und den Speicher wird reduziert, da der Client dies nicht aktiv anfordert. Tatsächlich tritt der Aufruf für jeden gewünschten Parameter nur einmal auf, wenn er abonniert wird. Dann erhält der Client bereits einfach einen Änderungsstrom. Die Datenverfügbarkeit steigt, da der Client immer einen Wert hat - er wird zwischengespeichert. Im Allgemeinen ist dieses Schema zum Austausch von Parametern recht einfach.
Der einzige Nachteil dieser Architektur ist die Unsicherheit bei der Dateninitialisierung. Bis zur ersten Aktualisierung durch Abonnement bleibt der Parameterwert undefiniert. Dies kann jedoch behoben werden, indem die Standardparameterwerte des Clients festgelegt werden, die beim ersten Update durch die tatsächlichen Werte ersetzt werden.
Technologieauswahl
Nachdem wir das Programm genehmigt hatten, begannen wir mit der Suche nach Produkten für seine Implementierung.
Wählen Sie zwischen
Vertx.io ,
Akka.io und
Spring Boot .

Die Tabelle fasst die Merkmale zusammen, die uns interessieren. Vertx und Akka haben Schauspieler, und Sping Boot hat eine Microservice-Bibliothek, die im Wesentlichen den Schauspielern nahe steht. Ähnliches gilt für die Reaktivität: Spring Boot verfügt über eine eigene WebFlux-Bibliothek, die dieselben Funktionen implementiert. Wir haben die Helligkeit ungefähr innerhalb der Tabelle geschätzt. In Bezug auf Sprachen wird Vertx von den drei Optionen als polyglott angesehen: Es unterstützt Java, Scala, Kotlin und JavaScript. Akka hat Scala und Java; Kotlin kann wahrscheinlich auch verwendet werden, aber es gibt keine direkte Unterstützung. Der Frühling hat Java, Kotlin und Groovy.
Infolgedessen gewann Vertx. Übrigens haben sie auf der JUG-Konferenz viel über ihn gesprochen, und tatsächlich nutzen es viele Unternehmen. Hier ist ein Screenshot von der Entwicklerseite:

Auf Vertx.io lautet das Implementierungsschema unserer Lösung wie folgt:

Wir haben uns entschieden, die Parameter nicht in der Datenbank, sondern im Git-Repository zu speichern. Wir können diese relativ langsame Datenquelle sehr gut nutzen, da der Client keine Parameter aktiv anfordert und die Anzahl der Treffer reduziert wird.
Ein Reader (Verticle) liest Daten aus dem Git-Repository in den Speicher der Anwendung, um den Benutzerzugriff auf die Daten zu beschleunigen. Dies ist beispielsweise beim Abonnieren von Parametern wichtig. Darüber hinaus verarbeitet der Leser Aktualisierungen - liest die Daten erneut und markiert sie, ersetzt die alten Daten durch neue.
Event Bus ist ein Vertx-Dienst, der Ereignisse zwischen Vertikalen sowie über Bridges sendet. Einschließlich durch die Websocket-Brücke, die in diesem Fall verwendet wird. Wenn Parameteränderungsereignisse eintreffen, sendet der Ereignisbus sie an den Client.
Schließlich wird hier auf der Clientseite ein einfacher Webclient implementiert, der Ereignisse (Parameteränderungen) abonniert und diese Änderungen auf den Seiten anzeigt.
Wie funktioniert es?
Wir zeigen, wie alles über eine Webanwendung funktioniert.
Wir starten die Anwendungsseite im Browser. Wir abonnieren wichtige Datenänderungen. Dann gehen wir zur Projektseite im lokalen GitLab, ändern die Daten im JSON-Format und speichern sie im Repository. Die Anwendung zeigt die entsprechende Änderung an, die wir benötigt haben.
Das ist alles. Sie finden den Quellcode der Demo in meinem
Git-Repository und stellen Fragen in den Kommentaren.