
Soziale Netzwerke sind heute eines der beliebtesten Internetprodukte und eine der wichtigsten Datenquellen für die Analyse. Innerhalb der sozialen Netzwerke selbst wird die schwierigste und interessanteste Aufgabe im Bereich der Datenwissenschaft als die Bildung eines Newsfeeds angesehen. Um den steigenden Anforderungen des Benutzers an die Qualität und Relevanz des Inhalts gerecht zu werden, muss er lernen, wie Informationen aus vielen Quellen gesammelt, die Prognose der Reaktion des Benutzers berechnet und das Gleichgewicht zwischen Dutzenden konkurrierender Metriken im A / B-Test hergestellt werden. Große Datenmengen, hohe Arbeitslasten und hohe Anforderungen an die Reaktionsgeschwindigkeit machen die Aufgabe noch interessanter.
Es scheint, dass die Aufgaben des Rankings heute bereits hin und her untersucht wurden, aber wenn Sie genau hinschauen, ist es nicht so einfach. Der Inhalt des Feeds ist sehr heterogen - dies ist ein Foto von Freunden und Memos, viralen Videos, langen Lesungen und wissenschaftlichem Pop. Um alles zusammenzustellen, benötigen Sie Kenntnisse aus verschiedenen Bereichen: Computer Vision, Arbeiten mit Texten, Empfehlungssystemen und ohne Zweifel moderne hochgeladene Speicher- und Datenverarbeitungstools. Es ist heutzutage äußerst schwierig, eine Person mit allen Fähigkeiten zu finden. Das Sortieren des Bandes ist also wirklich eine Teamaufgabe.
Odnoklassniki begann bereits 2012 mit verschiedenen Ribbon-Ranking-Algorithmen zu experimentieren, und 2014 schloss sich auch maschinelles Lernen diesem Prozess an. Möglich wurde dies vor allem durch die Fortschritte auf dem Gebiet der Technologien für die Arbeit mit Datenströmen. Gerade als wir
anfingen , Objektanzeigen und ihre Attribute in
Kafka zu sammeln und Protokolle mit
Samza zu aggregieren, konnten wir einen Datensatz für Trainingsmodelle erstellen und
die am häufigsten verwendeten Funktionen
berechnen : Click Through Rate-Objekte und Prognosen des Empfehlungssystems "basierend auf" der
Arbeit von Kollegen von LinkedIn .

Es wurde schnell klar, dass das Arbeitstier der logistischen Regression das Band nicht alleine herausnehmen kann, da der Benutzer sehr unterschiedlich reagieren kann: Klasse, Kommentar, Klicken, Verstecken usw., und der Inhalt kann sehr unterschiedlich sein - Foto ein Freund, ein Gruppenbeitrag oder ein von einem Freund eingeschriebener Vidosik. Jede Reaktion für jede Art von Inhalt hat ihre eigene Spezifität und ihren eigenen Geschäftswert. Als Ergebnis kamen wir zum Konzept einer „
Matrix logistischer Regressionen “: Für jede Art von Inhalt und jede Reaktion wird ein separates Modell erstellt, und dann werden ihre Prognosen mit einer Gewichtsmatrix multipliziert, die von Händen basierend auf den aktuellen Geschäftsprioritäten gebildet wird.
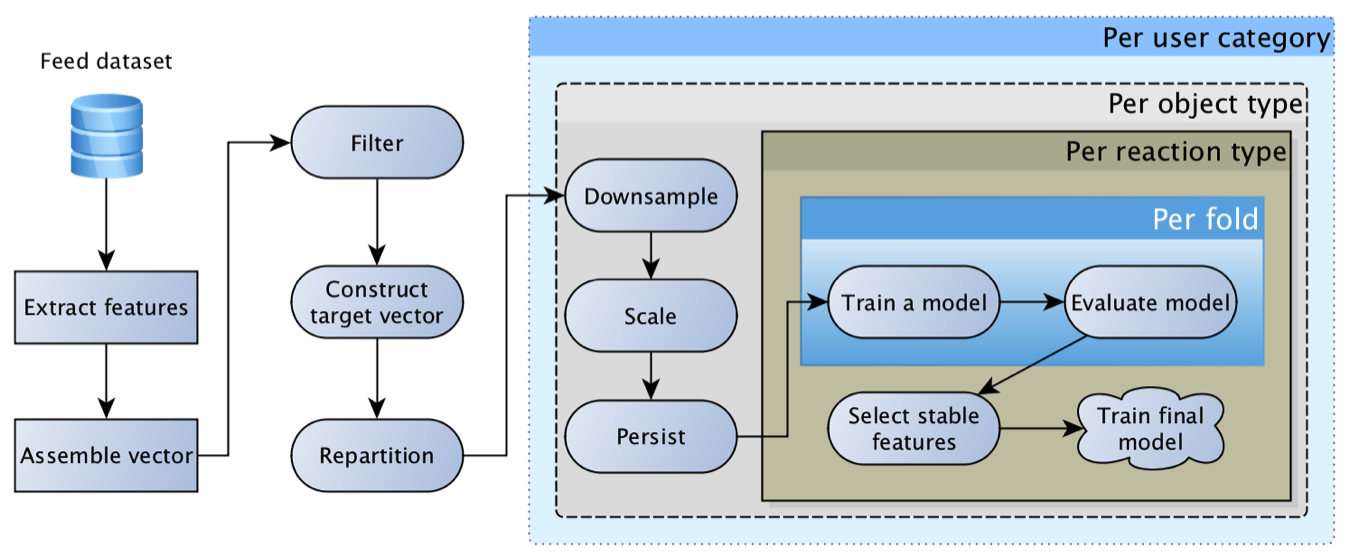
Dieses Modell war äußerst lebensfähig und war lange Zeit das wichtigste. Im Laufe der Zeit wurden immer interessantere Funktionen erworben: für Objekte, für Benutzer, für Autoren, für die Beziehung des Benutzers zum Autor, für diejenigen, die mit dem Objekt interagierten usw. Infolgedessen endeten die ersten Versuche, die Regression durch ein neuronales Netzwerk zu ersetzen, mit einem traurigen "Merkmal, das wir haben, sind zu beschissen, das Netz gibt keinen Schub".
Gleichzeitig haben technische und nicht algorithmische Verbesserungen unter dem Gesichtspunkt der Benutzeraktivität häufig den spürbarsten Schub gebracht: Mehr Kandidaten für das Ranking gewinnen, die Fakten der Show genauer verfolgen, die Antwortgeschwindigkeit des Algorithmus optimieren und den Browserverlauf vertiefen. Solche Verbesserungen führten häufig zu Einheiten und manchmal sogar zu einer Steigerung der Aktivität um zehn Prozent, während die Aktualisierung des Modells und das Hinzufügen eines Features häufig zu einer Steigerung um Zehntel Prozent führte.

Eine separate Schwierigkeit bei den Experimenten zur Aktualisierung des Modells bestand darin, ein inhaltliches Gleichgewicht herzustellen - die Verteilung der Prognosen des „neuen“ Modells konnte sich häufig erheblich von der des Vorgängers unterscheiden, was zu einer Umverteilung von Verkehr und Feedback führte. Infolgedessen ist es schwierig, die Qualität des neuen Modells zu beurteilen, da Sie zuerst die Ausgewogenheit des Inhalts kalibrieren müssen (wiederholen Sie den Vorgang zum Festlegen der Matrixgewichte für geschäftliche Zwecke). Nachdem wir die
Erfahrungen von Kollegen von Facebook untersucht hatten , stellten wir fest, dass das Modell
kalibriert werden muss , und zusätzlich zur logistischen Regression wurde eine isotonische Regression hinzugefügt :).
Bei der Erstellung neuer Inhaltsattribute kam es häufig zu Frustrationen: Ein einfaches Modell mit grundlegenden Techniken der Zusammenarbeit kann 80% oder sogar 90% des Ergebnisses liefern, während ein modisches neuronales Netzwerk, das eine Woche lang auf superteueren GPUs trainiert wurde, Katzen und Autos perfekt erkennt, aber eine Steigerung erzielt Metriken nur in der dritten Ziffer. Ein ähnlicher Effekt ist häufig bei der Implementierung thematischer Modelle, fastText und anderer Einbettungen zu beobachten. Wir haben es geschafft, die Frustration zu überwinden, indem wir die Validierung aus dem richtigen Blickwinkel betrachtet haben: Die Leistung kollaborativer Algorithmen verbessert sich erheblich, wenn sich Informationen über das Objekt ansammeln, während bei „frischen“ Objekten die Inhaltsattribute einen spürbaren Schub geben.
Aber natürlich sollten eines Tages die Ergebnisse der logistischen Regression verbessert werden, und Fortschritte wurden durch die Anwendung des kürzlich veröffentlichten
XGBoost-Spark erzielt. Die Integration
war nicht einfach , aber am Ende wurde das Modell schließlich modisch und jugendlich, und die Metriken wuchsen um Prozent.
Sicherlich kann viel mehr Wissen aus den Daten extrahiert und das Ranking des Bandes auf eine neue Höhe gebracht werden - und heute hat jeder die Möglichkeit, sich beim
SNA Hackathon 2019- Wettbewerb an dieser nicht trivialen Aufgabe zu versuchen. Der Wettbewerb findet in zwei Phasen statt: Laden Sie vom 7. Februar bis 15. März die Lösung für eine von drei Aufgaben herunter. Nach dem 15. März werden die Zwischenergebnisse zusammengefasst, und 15 Personen aus der Rangliste für jede Aufgabe erhalten Einladungen zur zweiten Phase, die vom 30. März bis 1. April im Moskauer Büro der Mail.ru Group stattfindet. Darüber hinaus erhält die Einladung zur zweiten Stufe Ende Februar drei Personen, die an der Spitze des Ratings stehen.
Warum gibt es drei Aufgaben? Im Rahmen der Online-Phase bieten wir drei Datensätze an, von denen jeder nur einen der Aspekte darstellt: Bild, Text oder Informationen zu einer Vielzahl von Attributen für die Zusammenarbeit. Und erst in der zweiten Phase, wenn Experten auf verschiedenen Gebieten zusammenkommen, wird der allgemeine Datensatz angezeigt, sodass Sie Punkte für die Synergie verschiedener Methoden finden können.
Interessiert an einer Aufgabe? Mach mit bei
SNA Hackathon :)