Bill Kennedy sagte in einem Vortrag über seinen wunderbaren
Ultimate Go-Programmierkurs :
Viele Entwickler versuchen, ihren Code zu optimieren. Sie nehmen eine Zeile und schreiben sie neu. Sie sagen, dass dies schneller wird. Müssen aufhören. Zu sagen, dass dieser oder jener Code schneller ist, ist erst möglich, nachdem er profiliert und Benchmarks erstellt wurden. Wahrsagerei ist nicht der richtige Ansatz, um Code zu schreiben.
Ich wollte schon lange anhand eines praktischen Beispiels zeigen, wie dies funktionieren kann. Und neulich wurde ich auf den folgenden Code aufmerksam gemacht, der nur als solches Beispiel verwendet werden könnte:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber) tempList := model.BuildsList{} for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchURLs = b.ReversePatchURLs b.ExtractedSize = b.RPatchExtractedSize tempList = append(tempList, b) }
Hier werden in allen Elementen des von der Datenbank zurückgegebenen
Build- Slice
PatchURLs durch
ReversePatchURLs ersetzt ,
ExtractedSize durch
RPatchExtractedSize und Reverse ausgeführt - die Reihenfolge der Elemente wird so geändert, dass das letzte Element das erste und das erste letzte wird.
Meiner Meinung nach ist der Quellcode etwas kompliziert zu lesen und kann optimiert werden. Dieser Code führt einen einfachen Algorithmus aus, der aus zwei logischen Teilen besteht: Ändern von Slice-Elementen und Sortieren. Es dauert jedoch einige Zeit, bis der Programmierer diese beiden Komponenten isoliert hat.
Trotz der Tatsache, dass beide Teile wichtig sind, wird der umgekehrte Code nicht so hervorgehoben, wie wir es gerne hätten. Es ist entlang von drei auseinandergerissenen Linien verteilt: Initialisieren eines neuen Slice, Iterieren eines vorhandenen Slice in umgekehrter Reihenfolge und Hinzufügen eines Elements am Ende eines neuen Slice. Trotzdem kann man die unbestrittenen Vorteile dieses Codes nicht ignorieren: Der Code funktioniert und wird getestet, und objektiv gesehen ist er völlig ausreichend. Die subjektive Wahrnehmung des Codes durch einen einzelnen Entwickler kann keine Entschuldigung für das Umschreiben sein. Leider oder zum Glück schreiben wir den Code nicht neu, nur weil er uns einfach nicht gefällt (oder, wie so oft, einfach weil er uns nicht gehört, siehe
Schwerwiegender Fehler ).
Was aber, wenn es uns gelingt, die Wahrnehmung des Codes nicht nur zu verbessern, sondern auch erheblich zu beschleunigen? Dies ist eine ganz andere Sache. Sie können verschiedene alternative Algorithmen anbieten, die die im Code eingebettete Funktionalität ausführen.
Erste Option: Durchlaufen aller Elemente in einer
Bereichsschleife ; Fügen Sie am Anfang des endgültigen Arrays ein Element hinzu, um das ursprüngliche Slice in jeder Iteration umzukehren. Wir könnten also die umständliche Variable
i loswerden, die
len- Funktion verwenden, es ist schwierig, die Iteration über die Elemente vom Ende zu erkennen und die Codemenge um zwei Zeilen (von sieben auf fünf Zeilen) zu reduzieren. Je kleiner der Code, desto weniger wahrscheinlich ist es, dass er dies zulässt ein Fehler.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*store.Build{build}, tempList...) }
Nachdem wir die Slice-Aufzählung am Ende entfernt haben, haben wir klar zwischen den Operationen zum Ändern von Elementen (3. Zeile) und der Umkehrung des ursprünglichen Arrays (4. Zeile) unterschieden.
Die Hauptidee der zweiten Option besteht darin, die Variation der Elemente und die Sortierung weiter zu explodieren. Zuerst sortieren wir die Elemente und ändern sie. Anschließend sortieren wir das Slice nach einer separaten Operation. Diese Methode erfordert eine zusätzliche Implementierung der Sortierschnittstelle für das Slice, erhöht jedoch die Lesbarkeit und trennt und isoliert die Umkehrung vollständig von sich ändernden Elementen, und die
Umkehrmethode zeigt dem Leser definitiv das gewünschte Ergebnis an.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(sort.IntSlice(keys)))
Die dritte Option ist fast eine Wiederholung der zweiten, aber
sort.Slice wird zum Sortieren verwendet, wodurch die Codemenge um eine Zeile erhöht wird, die zusätzliche Implementierung der Sortierschnittstelle jedoch vermieden wird.
for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id })
Auf den ersten Blick sind die interne Komplexität, die Anzahl der Iterationen, die angewendeten Funktionen, der Anfangscode und der erste Algorithmus nahe beieinander. Die zweite und dritte Option mögen schwieriger erscheinen, aber es ist unmöglich eindeutig zu sagen, welche der vier Optionen optimal ist.
Wir haben uns daher verboten, Entscheidungen auf der Grundlage von Annahmen zu treffen, die nicht durch Beweise gestützt werden. Es ist jedoch offensichtlich, dass das Interessanteste darin besteht, wie sich die Append-Funktion verhält, wenn am Ende und am Anfang des Slice ein Element hinzugefügt wird. Schließlich ist diese Funktion nicht so einfach, wie es scheint.
Das Anhängen funktioniert
wie folgt : Es fügt dem vorhandenen Slice entweder ein neues Element hinzu, wenn seine Kapazität größer als die Gesamtlänge ist, oder reserviert einen Speicherplatz für ein neues Slice, kopiert Daten aus dem ersten Slice, fügt Daten aus dem zweiten hinzu und gibt als Ergebnis ein neues zurück Scheibe.
Die interessanteste Nuance in der Arbeit dieser Funktion ist der Algorithmus, mit dem Speicher für ein neues Array reserviert wird. Da die teuerste Operation darin besteht, einen neuen Speicher zuzuweisen, haben die Go-Entwickler einen kleinen Trick gemacht, um die
Append- Operation billiger zu machen. Um den Speicher nicht jedes Mal neu zu reservieren, wenn ein Element hinzugefügt wird, wird zunächst die Speichermenge mit einem bestimmten Spielraum zugewiesen - dem Zweifachen des Originals, aber nach einer bestimmten Anzahl von Elementen wird die Größe des neu reservierten Speicherabschnitts nicht mehr als zweimal, sondern um 25%.
Angesichts des neuen Verständnisses der
Append- Funktion
lautet die Antwort auf die Frage: "Was wird schneller: Fügen Sie ein Element am Ende eines vorhandenen Slice hinzu oder fügen Sie einem Slice aus einem Element ein vorhandenes Slice hinzu?" - schon transparenter. Es kann davon ausgegangen werden, dass im zweiten Fall im Vergleich zum ersten mehr Speicherzuweisungen vorhanden sind, was sich direkt auf die Arbeitsgeschwindigkeit auswirkt.
So näherten wir uns reibungslos den Benchmarks. Mithilfe von Benchmarks können Sie die Auslastung des Algorithmus für die wichtigsten Ressourcen wie Laufzeit und RAM bewerten.
Schreiben wir einen Benchmark für die Bewertung aller vier unserer Algorithmen. Gleichzeitig werden wir bewerten, durch welches Wachstum die Sortierung abgelehnt werden kann (um zu verstehen, wie viel Zeit für das Sortieren aufgewendet wird). Benchmark-Code:
package services import ( "testing" "sort" ) type Build struct { Id int ExtractedSize int64 PatchUrls string ReversePatchUrls string RPatchExtractedSize int64 } type Builds []*Build func (a Builds) Len() int { return len(a) } func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id } func prepare() Builds { var builds Builds for i := 0; i < 100000; i++ { builds = append(builds, &Build{Id: i}) } return builds } func BenchmarkF1(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize tempList = append(tempList, b) } } } func BenchmarkF2(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*Build{build}, tempList...) } } } func BenchmarkF3(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(builds)) } } func BenchmarkF4(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) } } func BenchmarkF5(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } } }
Starten Sie den Benchmark mit dem Befehl
go test -bench =. -benchmem .
Die Berechnungsergebnisse für die Slices 10, 100, 1000, 10 000 und 100 000 Elemente sind in der folgenden Grafik dargestellt, wobei F1 der anfängliche Algorithmus ist, F2 die Hinzufügung des Elements zum Anfang des Arrays ist, F3 die Verwendung von
sort.Reverse to sort, F4 die Verwendung von
sort.Slice , F5 - Ablehnung der Sortierung.
Betriebszeit Anzahl der Speicherzuordnungen
Anzahl der Speicherzuordnungen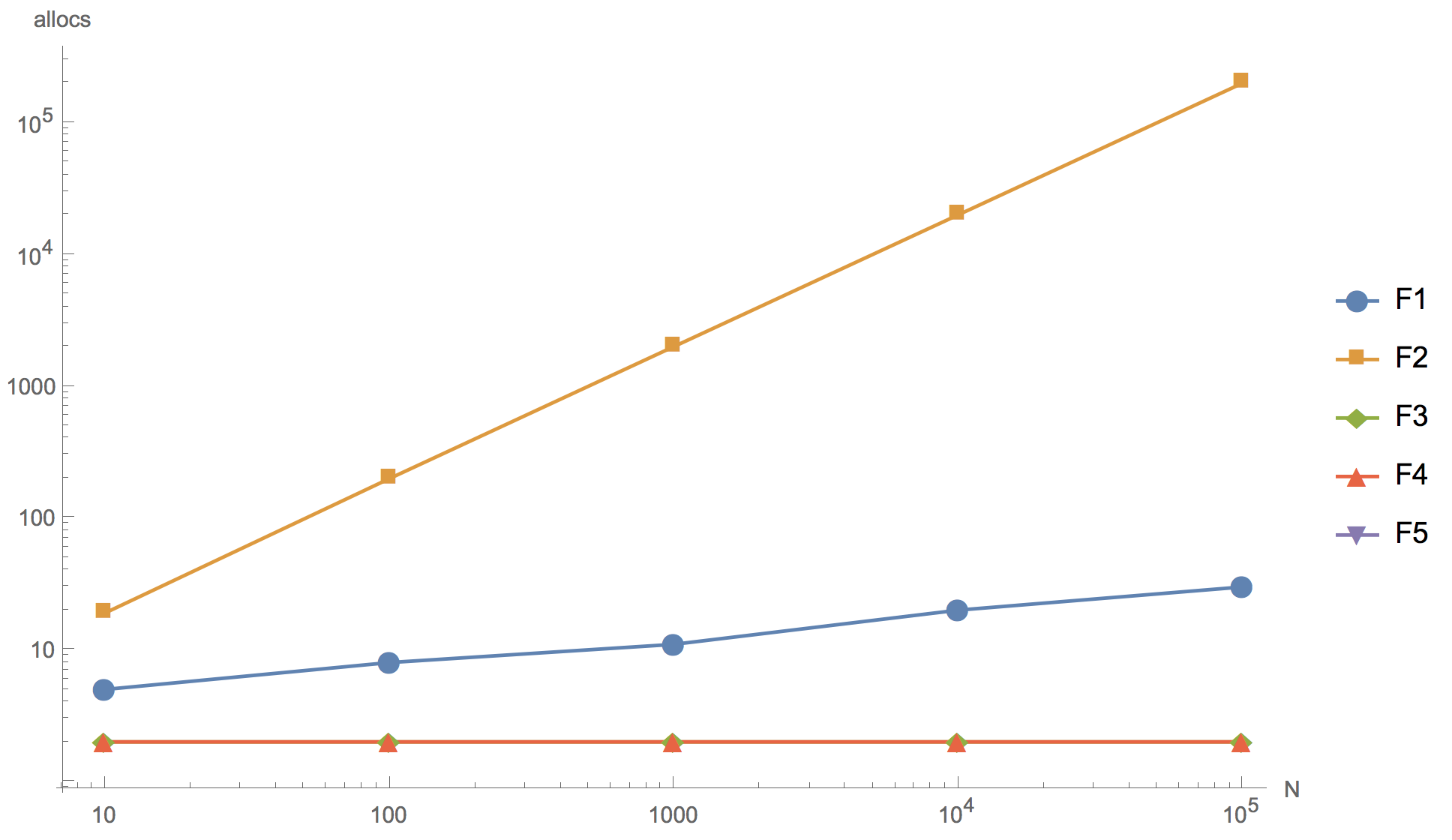
Wie Sie in der Grafik sehen können, können Sie das Array vergrößern, aber das Endergebnis ist im Prinzip bereits auf einem Slice von 10 Elementen unterscheidbar.
Keiner der vorgeschlagenen alternativen Algorithmen (F2, F3, F4) konnte die Geschwindigkeit des ursprünglichen Algorithmus (F1) überschreiten. Trotz der Tatsache, dass alle außer F2 weniger Speicherzuordnungen haben als das Original. Der erste Algorithmus (F2) mit dem Hinzufügen eines Elements am Anfang des Slice erwies sich als der unwirksamste: Wie erwartet weist er zu viele Speicherzuordnungen auf, so dass es absolut unmöglich ist, ihn in der Produktentwicklung zu verwenden. Ein Algorithmus, der die eingebaute umgekehrte Sortierfunktion (F3) verwendet, ist erheblich langsamer als der ursprüngliche. Und nur
sort.Slice- Sortieralgorithmus ist in der Geschwindigkeit mit dem ursprünglichen Algorithmus vergleichbar, aber etwas unterlegen.
Sie können auch feststellen, dass die Ablehnung der Sortierung (F5) eine erhebliche Beschleunigung bewirkt. Wenn Sie den Code wirklich neu schreiben möchten, können Sie in diese Richtung gehen, z. B. das anfängliche
Build- Slice aus der Datenbank erhöhen und in der Anforderung die Sortierung nach ID DESC anstelle von ASC verwenden. Gleichzeitig sind wir jedoch gezwungen, die Grenzen des betrachteten Codeabschnitts zu überschreiten, was das Risiko birgt, dass mehrere Änderungen vorgenommen werden.
Schlussfolgerungen
Benchmarks schreiben.
Es macht wenig Sinn, sich Gedanken darüber zu machen, ob ein bestimmter Code schneller sein wird. Informationen aus dem Internet, Urteile von Kollegen und anderen Personen, egal wie maßgeblich sie auch sein mögen, können als Hilfsargumente dienen, aber die Rolle des Hauptrichters bei der Entscheidung, ob es sich um einen neuen Algorithmus handelt oder nicht, sollte bei den Benchmarks bleiben.
Go ist nur auf den ersten Blick eine recht einfache Sprache. Hier gilt die umfassende 80⁄20-Regel. Diese 20% repräsentieren die Feinheiten der internen Struktur der Sprache, deren Kenntnis den Anfänger vom erfahrenen Entwickler unterscheidet. Das Schreiben von Benchmarks zur Lösung Ihrer Fragen ist eine der billigsten und effektivsten Methoden, um sowohl eine Antwort als auch ein tieferes Verständnis der internen Struktur und der Prinzipien der Go-Sprache zu erhalten.