
Anmerkung des Übersetzers
Die meisten modernen Softwareprodukte sind nicht monolithisch, sondern bestehen aus vielen Teilen, die miteinander interagieren. In dieser Situation ist es erforderlich, dass die Kommunikation der interagierenden Teile des Systems in einer Sprache erfolgt (obwohl diese Teile selbst in verschiedenen Programmiersprachen geschrieben und auf verschiedenen Maschinen ausgeführt werden können). Um die Lösung dieses Problems zu vereinfachen, hilft gRPC - Open-Source-Framework von Google, das 2015 veröffentlicht wurde. Er löst sofort eine Reihe von Problemen und erlaubt:
- Verwenden Sie die Sprache Protokollpuffer, um die Interaktion von Diensten zu beschreiben.
- Generieren von Programmcode basierend auf dem beschriebenen Protokoll für 11 verschiedene Sprachen sowohl für den Client-Teil als auch für den Server-Teil;
- Autorisierung zwischen interagierenden Komponenten implementieren;
- Verwenden Sie sowohl synchrone als auch asynchrone Interaktion.
gRPC schien mir ein ziemlich interessantes Framework zu sein, und ich war daran interessiert, die tatsächlichen Erfahrungen von Dropbox beim Aufbau eines darauf basierenden Systems kennenzulernen. Der Artikel enthält viele Details zur Verwendung der Verschlüsselung, zum Aufbau eines zuverlässigen, beobachtbaren und produktiven Systems sowie zum Migrationsprozess von der alten RPC-Lösung zur neuen.
HaftungsausschlussDer Originalartikel enthält keine Beschreibung von gRPC, und einige Punkte scheinen Ihnen möglicherweise nicht klar zu sein. Wenn Sie mit gRPC oder anderen ähnlichen Frameworks (z. B. Apache Thrift) nicht vertraut sind, empfehle ich Ihnen, sich zunächst mit den Hauptideen vertraut zu machen (es reicht aus, zwei kleine Artikel von der offiziellen Website zu lesen:
„Was ist gRPC?“ Und
„gRPC-Konzepte“ ).
Vielen Dank an Aleksey Ivanov aka
SaveTheRbtz für das Schreiben des Originalartikels und die Hilfe bei der Übersetzung schwieriger Orte.
Dropbox verwaltet viele Dienste, die in verschiedenen Sprachen geschrieben sind und Millionen von Anfragen pro Sekunde bearbeiten. Im Zentrum unserer serviceorientierten Architektur steht Courier, ein gPC-basiertes RPC-Framework. Während der Entwicklung haben wir viel über die Erweiterbarkeit von gRPC, die Leistungsoptimierung und den Übergang vom vorherigen RPC-System gelernt.
Hinweis: Der Beitrag enthält Codefragmente für Python und Go. Wir verwenden auch Rust und Java.Straße nach gRPC
Courier ist nicht das erste Dropbox-RPC-Framework. Noch bevor wir begannen, das monolithische Python-System in separate Dienste aufzuteilen, brauchten wir eine zuverlässige Basis für den Datenaustausch zwischen Diensten - insbesondere, da die Auswahl eines Frameworks langfristige Konsequenzen hätte.
Zuvor experimentierte Dropbox mit verschiedenen RPC-Frameworks. Zunächst hatten wir ein individuelles Protokoll für die manuelle Serialisierung und Deserialisierung. Einige Dienste, wie die
Scribe-basierte Protokollierung , verwendeten
Apache Thrift . Gleichzeitig war unser Haupt-RPC-Framework ein HTTP / 1.1-Protokoll mit Nachrichten, die mit Protobuf serialisiert wurden.
Bei der Erstellung eines Frameworks haben wir aus mehreren Optionen ausgewählt. Wir könnten Swagger (jetzt als
OpenAPI bekannt ) in das alte RPC-Framework
einführen, einen neuen Standard einführen oder ein auf Thrift oder gRPC basierendes Framework erstellen. Das Hauptargument für gRPC war die Möglichkeit, bereits vorhandene Protobufs zu verwenden. Auch Multiplex-HTTP / 2 und bidirektionale Datenübertragung waren für unsere Aufgaben nützlich.
Hinweis: Wenn zu diesem Zeitpunkt fbthrift vorhanden wäre, würden wir uns Thrift-Lösungen wahrscheinlich genauer ansehen.Was Kurier zu gRPC bringt
Courier ist kein RPC-Protokoll. Es ist ein Mittel zur Integration von gRPC in eine vorhandene Infrastruktur. Das Framework sollte mit unseren Authentifizierungs-, Autorisierungs- und Serviceerkennungstools sowie mit der Erfassung, Protokollierung und Nachverfolgung von Statistiken kompatibel sein. Also haben wir Courier erstellt.
Obwohl wir in einigen Fällen Bandaid als gRPC-Proxy verwenden, kommunizieren die meisten unserer Dienste direkt miteinander, um die Auswirkungen von RPC auf die Latenz zu minimieren.Für uns war es wichtig, die Menge an Routinecode zu reduzieren, die geschrieben werden muss. Da Courier als allgemeiner Rahmen für die Entwicklung von Diensten dient, enthält es Funktionen, die jeder benötigt. Die meisten von ihnen sind standardmäßig aktiviert und können über Befehlszeilenargumente gesteuert werden. Einige werden mit einem Kontrollkästchen aktiviert.
Sicherheit: Dienstidentität und gegenseitige TLS-Authentifizierung
Courier implementiert unseren Standardmechanismus zur Identifizierung von Diensten. Jedem Server und Client wird ein individuelles TLS-Zertifikat zugewiesen, das von unserer eigenen Zertifizierungsstelle ausgestellt wird. Die zertifikatcodierte persönliche Kennung, die für die gegenseitige Authentifizierung verwendet wird - der Server überprüft den Client, der Client überprüft den Server.
In TLS, wo wir beide Seiten der Verbindung steuern, haben wir strenge Einschränkungen eingeführt. Alle internen RPCs erfordern eine
PFS- Verschlüsselung. Die erforderliche Version von TLS ist 1.2 und höher. Wir haben auch die Anzahl der symmetrischen und asymmetrischen Algorithmen begrenzt und
ECDHE-ECDSA-AES128-GCM-SHA256 bevorzugt.
Nach Durchlaufen der Identifizierung und Entschlüsselung der Anforderung prüft der Server, ob der Client über die erforderlichen Berechtigungen verfügt. Zugriffssteuerungslisten (ACLs) und Geschwindigkeitsbegrenzungen können sowohl für Dienste im Allgemeinen als auch für einzelne Methoden konfiguriert werden. Ihre Parameter können auch über unser Distributed File System (AFS) geändert werden. Dank dessen können Servicebesitzer die Last in Sekundenschnelle fallen lassen, ohne die Prozesse neu zu starten. Courier kümmert sich um das Abonnieren von Benachrichtigungen und das Aktualisieren der Konfiguration.
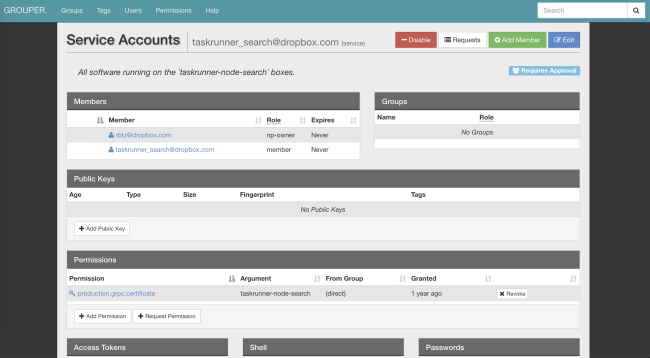
Der Identitätsdienst ist eine globale Kennung für ACLs, Geschwindigkeitsbegrenzungen, Statistiken usw. Außerdem ist er kryptografisch sicher.Hier ist ein Beispiel für die ACL-Konfiguration und die Geschwindigkeitsbegrenzung, die in unserem
optischen Mustererkennungsdienst verwendet werden :
limits: dropbox_engine_ocr: # All RPC methods. default: max_concurrency: 32 queue_timeout_ms: 1000 rate_acls: # OCR clients are unlimited. ocr: -1 # Nobody else gets to talk to us. authenticated: 0 unauthenticated: 0
 Wir erwägen die Möglichkeit, auf das SVID-Format (kryptografisch verifiziertes Dokument SPIFFE ) umzusteigen , um unser Framework mit vielen Open-Source-Projekten zu kombinieren.
Wir erwägen die Möglichkeit, auf das SVID-Format (kryptografisch verifiziertes Dokument SPIFFE ) umzusteigen , um unser Framework mit vielen Open-Source-Projekten zu kombinieren.Beobachtbarkeit: Statistik und Tracking
Mit nur einer Kennung können Sie problemlos Protokolle, Statistiken, Tracedateien und andere Daten zu Courier finden.
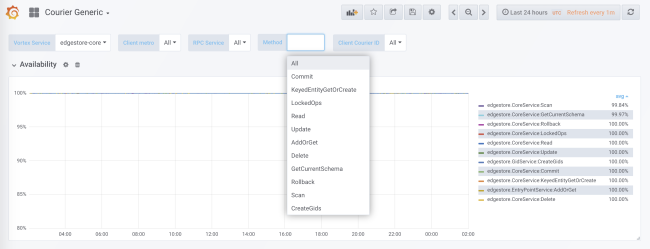
Während der Codegenerierung wird die Statistiksammlung für jeden Dienst und jede Methode sowohl auf der Clientseite als auch auf der Serverseite hinzugefügt. Serverseitige Statistiken werden durch die Client-ID unterteilt. In der Standardkonfiguration erhalten Sie detaillierte Daten zu Last, Fehlern und Verzögerungszeit für jeden Dienst mit Courier.
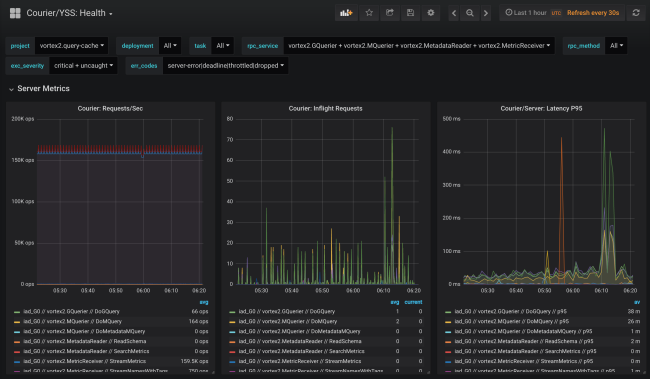
Die Kurierstatistik enthält Daten zur Verfügbarkeit und Latenz auf der Clientseite sowie zur Anzahl der Anforderungen und zur Warteschlangengröße auf der Serverseite. Es gibt andere nützliche Diagramme, insbesondere Histogramme der Antwortzeit für jede Methode und der Zeit der TLS-Handshakes für jeden Client.
Einer der Vorteile unserer Codegenerierung ist die Möglichkeit der statischen Initialisierung von Datenstrukturen wie Histogrammen und Trace-Diagrammen. Dies minimiert die Auswirkungen auf die Leistung.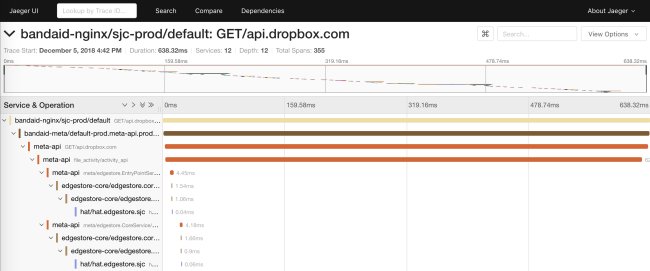
Das alte RPC-System hat nur
request_id über die API verteilt. Dies ermöglichte es, Daten aus den Protokollen verschiedener Dienste zu kombinieren. Bei Courier haben wir eine API eingeführt, die auf einer Teilmenge der
OpenTracing- Spezifikationen
basiert . Wir haben unsere eigenen Bibliotheken auf der Client-Seite geschrieben und auf der Server-Seite eine Lösung implementiert, die auf Cassandra und
Jaeger basiert.

Durch die Ablaufverfolgung können wir zur Laufzeit Abhängigkeitsdiagramme eines Dienstes erstellen. Auf diese Weise können Ingenieure alle transitiven Abhängigkeiten eines bestimmten Dienstes erkennen. Darüber hinaus ist die Funktion nützlich, um unerwünschte Abhängigkeiten nach der Bereitstellung zu verfolgen.
Zuverlässigkeit: Fristen und Unterbrechung
Courier bietet einen zentralen Ort, um gemeinsame Clientfunktionen (z. B. Zeitüberschreitungen) in verschiedenen Sprachen zu implementieren. Wir haben nach und nach verschiedene Funktionen hinzugefügt, die häufig auf den Ergebnissen einer „posthumen“ Analyse aufkommender Probleme basieren.
Fristen
Jede gRPC-Anfrage hat eine Frist , die das Client-Timeout angibt. Da Courier-Stubs bekannte Metadaten automatisch verteilen, wird die Anforderungsfrist sogar außerhalb der API übertragen. Innerhalb des Prozesses erhalten Fristen eine native Anzeige. In Go werden sie beispielsweise durch das Ergebnis von
context.Context aus der
WithDeadline- Methode dargestellt.
Tatsächlich konnten wir ganze Klassen von Zuverlässigkeitsproblemen beheben, indem wir die Ingenieure dazu zwangen, Fristen für die Definition der geeigneten Services festzulegen.
Dieser Ansatz geht sogar über RPC hinaus. Zum Beispiel serialisiert unser ORM MySQL einen RPC-Kontext zusammen mit einer Frist in einem SQL-Abfragekommentar. Unser SQL-Proxy kann Kommentare analysieren und Abfragen "töten", wenn die Frist abgelaufen ist. Als Bonus beim Debuggen von Datenbankaufrufen haben wir eine SQL-Abfrage, die an eine bestimmte RPC-Abfrage gebunden ist.
Trennen
Ein weiteres häufiges Problem, mit dem Clients des vorherigen RPC-Systems konfrontiert waren, war die Implementierung des Algorithmus für individuelle exponentielle Verzögerungen und Schwankungen bei wiederholter Anforderung.
Wir haben versucht, eine intelligente Lösung für das Problem der Trennung in Courier zu finden, beginnend mit der Implementierung des LIFO-Puffers (last in, first out) zwischen dem Dienst und dem Aufgabenpool.
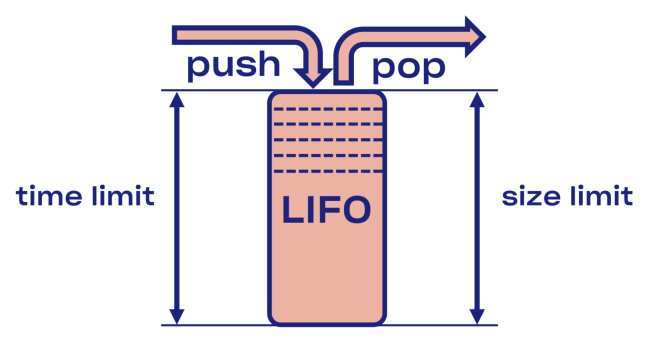
Im Falle einer Überlastung wird LIFO automatisch getrennt. Die Warteschlange, die wichtig ist, ist nicht nur durch die Größe, sondern auch
durch die Zeit begrenzt (die Anforderung kann nur eine bestimmte Zeit in der Warteschlange verbringen).
Minus LIFO - Änderung der Reihenfolge der Bearbeitung von Anfragen. Wenn Sie die ursprüngliche Bestellung beibehalten möchten, verwenden Sie CoDel . Auch dort besteht die Möglichkeit der Trennung, und die Reihenfolge der Verarbeitungsanforderungen bleibt gleich.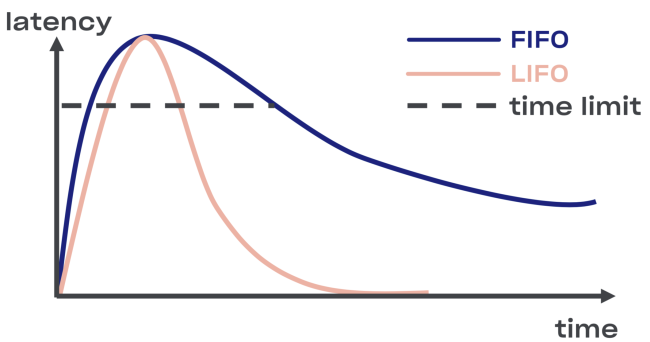
Selbstbeobachtung: Debuggen von Endpunkten
Obwohl Debugging-Endpunkte nicht direkt Teil von Courier sind, werden sie in Dropbox häufig verwendet und sind zu nützlich, um nicht erwähnt zu werden.
Aus Sicherheitsgründen können Sie sie an einem separaten Port oder an einem Unix-Socket öffnen (um den Zugriff mithilfe von Dateiberechtigungen zu steuern). Sie sollten auch die gegenseitige TLS-Authentifizierung in Betracht ziehen, mit der Entwickler ihre Zertifikate für den Zugriff auf Endpunkte bereitstellen müssen (hauptsächlich nicht nur schreibgeschützt).Ausführung
Die Möglichkeit, den Status eines Dienstes während seines Betriebs zu analysieren, ist für das Debuggen sehr nützlich. Auf
dynamische Speicher- und CPU-Profile kann beispielsweise über HTTP- oder gRPC-Endpunkte zugegriffen werden .
Wir planen, diese Möglichkeit bei der kanarischen Überprüfung zu nutzen, um die Suche nach dem Unterschied zwischen der alten und der neuen Version des Codes zu automatisieren.Endpunkte ermöglichen es, den Status eines Dienstes zur Laufzeit zu ändern. Insbesondere Golang-basierte Dienste können
GCPercent dynamisch konfigurieren.
Die Bibliothek
Der automatische Export bibliotheksspezifischer Daten als RPC-Endpunkt kann für Bibliotheksentwickler hilfreich sein. Beispielsweise kann die
Malloc- Bibliothek
interne Statistiken in einen Speicherauszug sichern . Ein weiteres Beispiel: Ein Debugging-Endpunkt kann den Grad der Dienstprotokollierung im laufenden Betrieb ändern.
Rpc
Natürlich ist die Fehlerbehebung in verschlüsselten und verschlüsselten Protokollen nicht einfach. Daher ist es eine gute Idee, so viele Tools wie möglich auf RPC-Ebene einzuführen. Ein Beispiel für eine solche introspektive API
ist die Channelz-Lösung .
Anwendungsebene
Es kann auch nützlich sein, Optionen auf Anwendungsebene zu lernen. Ein gutes Beispiel ist ein Endpunkt mit allgemeinen Informationen zur Anwendung (mit einem Hash von Quell- oder Assemblydateien, einer Befehlszeile usw.). Es kann von einem Orchestrierungssystem verwendet werden, um die Integrität bei der Bereitstellung eines Dienstes zu überprüfen.
Leistungsoptimierung
Durch die Erweiterung unseres gRPC-Frameworks auf den erforderlichen Maßstab haben wir einige Engpässe festgestellt, die für Dropbox spezifisch sind.
Ressourcenverbrauch von TLS-Handshakes
In Diensten, die aufgrund von TLS-Handshakes viele Beziehungen bedienen, kann die kombinierte CPU-Auslastung sehr schwerwiegend sein (insbesondere beim Neustart eines beliebten Dienstes).
Um die Leistung beim Signieren zu verbessern, haben wir die Schlüsselpaare RSA-2048 durch die ECDSA P-256 ersetzt. Hier sind Beispiele für ihre Leistung (Hinweis: Mit RSA ist die Signaturüberprüfung schneller).
RSA: ~/c0d3/boringssl bazel run -- //:bssl speed -filter 'RSA 2048' Did ... RSA 2048 signing operations in .............. (1527.9 ops/sec) Did ... RSA 2048 verify (same key) operations in .... (37066.4 ops/sec) Did ... RSA 2048 verify (fresh key) operations in ... (25887.6 ops/sec)
ECDSA: ~/c0d3/boringssl bazel run -- //:bssl speed -filter 'ECDSA P-256' Did ... ECDSA P-256 signing operations in ... (40410.9 ops/sec) Did ... ECDSA P-256 verify operations in .... (17037.5 ops/sec)
Da die Überprüfung mit RSA-2048 etwa dreimal schneller ist als mit ECDSA P-256, können Sie RSA für Root- und Endzertifikate auswählen, um die Betriebsgeschwindigkeit zu erhöhen. Unter dem Gesichtspunkt der Sicherheit ist jedoch nicht alles so einfach: Sie erstellen Ketten aus verschiedenen kryptografischen Grundelementen, und daher ist die Ebene der resultierenden Sicherheitsparameter am niedrigsten. Wenn Sie die Leistung verbessern möchten, empfehlen wir, keine Zertifikate der Version RSA-4096 (und höher) als Root- und Endzertifikate zu verwenden.
Wir haben auch festgestellt, dass die Auswahl einer TLS-Bibliothek (und von Kompilierungsflags) erhebliche Auswirkungen auf die Leistung und die Sicherheit hat. Vergleichen Sie beispielsweise den auf macOS X Mojave aufgebauten LibreSSL mit dem selbstgeschriebenen OpenSSL auf derselben Hardware.
LibreSSL 2.6.4: ~ openssl speed rsa2048 LibreSSL 2.6.4 ... sign verify sign/s verify/s rsa 2048 bits 0.032491s 0.001505s 30.8 664.3
OpenSSL 1.1.1a: ~ openssl speed rsa2048 OpenSSL 1.1.1a 20 Nov 2018 ... sign verify sign/s verify/s rsa 2048 bits 0.000992s 0.000029s 1208.0 34454.8
Der schnellste Weg, einen TLS-Handshake zu erstellen, besteht darin, ihn überhaupt nicht zu erstellen! Wir haben die Unterstützung für die Wiederaufnahme der Sitzung in gRPC-Core und gRPC-Python aufgenommen, wodurch die Belastung der CPU während der Bereitstellung verringert wird.
Die Verschlüsselung ist kostengünstig
Viele glauben fälschlicherweise, dass Verschlüsselung teuer ist. Selbst die einfachsten modernen Computer führen fast sofort eine symmetrische Verschlüsselung durch. Ein Standardprozessor kann Daten mit einer Geschwindigkeit von 40 Gbit / s pro Kern verschlüsseln und authentifizieren:
~/c0d3/boringssl bazel run -- //:bssl speed -filter 'AES' Did ... AES-128-GCM (8192 bytes) seal operations in ... 4534.4 MB/s
Trotzdem mussten wir gRPC für unsere Speicherblöcke konfigurieren, die mit einer Geschwindigkeit von 50 Gbit / s betrieben wurden. Wir haben festgestellt, dass es wichtig ist, die Anzahl der
Speichervorgänge zu minimieren, wenn die Verschlüsselungsgeschwindigkeit ungefähr der
Kopiergeschwindigkeit entspricht. Darüber hinaus haben wir einige Änderungen an gRPC selbst vorgenommen.
Durch authentifizierte und verschlüsselte Protokolle wurden viele unangenehme Probleme vermieden (z. B. Datenbeschädigung durch den Prozessor, DMA oder das Netzwerk). Auch wenn Sie gRPC nicht verwenden, empfehlen wir die Verwendung von TLS für interne Kontakte.Datenkanäle mit hoher Latenz (BDP)
Anmerkung des Übersetzers: Der ursprüngliche Untertitel verwendete den Begriff
Bandbreitenverzögerungsprodukt , für das keine etablierte Übersetzung ins Russische vorliegt.
Das Dropbox-Backbone-Netzwerk umfasst viele Rechenzentren . Manchmal müssen Knoten in verschiedenen Regionen über RPC kommunizieren, beispielsweise zur Replikation. Bei Verwendung von TCP ist der Systemkern für die Begrenzung der Datenmenge verantwortlich, die in einer bestimmten Verbindung übertragen wird (innerhalb von /
proc / sys / net / ipv4 / tcp_ {r, w} mem ), obwohl gRPC auf Basis von HTTP / 2 über ein eigenes Tool verfügt Flusskontrolle. Die Obergrenze von BDP
in grpc-go ist streng auf 16 MB begrenzt , was einen Engpass auslösen kann.
net.Server Golang oder grpc.Server
Zunächst haben wir in unserem Go-Code HTTP / 1.1 und gRPC mit einem einzigen
net.Server unterstützt . Die Lösung war im Hinblick auf die Pflege des Programmcodes sinnvoll, funktionierte jedoch überhaupt nicht einwandfrei. Durch die Verteilung von HTTP / 1.1 und gRPC auf Server und die Migration von gRPC auf grpc.Server wurden die Kurierbandbreite und die Speichernutzung erheblich verbessert.
Golang / Protobuf oder Gogo / Protobuf
Der Wechsel zu gRPC kann die Kosten für das Marshalling und das Unmarshaling erhöhen. Bei Go-Code konnten wir die CPU-Auslastung von Courier-Servern durch den Wechsel zu
gogo / protobuf erheblich reduzieren.
Wie immer war der Übergang zu Gogo / Protobuf mit einigen Bedenken verbunden , aber wenn Sie die Funktionalität angemessen einschränken, sollte es keine Probleme geben.Implementierungsdetails
In diesem Abschnitt werden wir tiefer in das Courier-Gerät eindringen, Protobuf-Schemata und Beispiele für Stubs aus verschiedenen Sprachen betrachten. Alle Beispiele stammen aus dem Testdienst, den wir beim Testen der Courier-Integration verwendet haben.
Servicebeschreibung
Schauen Sie sich einen Auszug aus der Testdienstdefinition an:
service Test { option (rpc_core.service_default_deadline_ms) = 1000; rpc UnaryUnary(TestRequest) returns (TestResponse) { option (rpc_core.method_default_deadline_ms) = 5000; } rpc UnaryStream(TestRequest) returns (stream TestResponse) { option (rpc_core.method_no_deadline) = true; } ... }
Wie oben angegeben, ist für alle Kuriermethoden eine Frist erforderlich. Mit der folgenden Option können Sie die Frist für den gesamten Service festlegen:
option (rpc_core.service_default_deadline_ms) = 1000;
Gleichzeitig kann jede Methode auf ihre eigene Frist eingestellt werden, wodurch die Frist für den gesamten Dienst (falls vorhanden) aufgehoben wird:
option (rpc_core.method_default_deadline_ms) = 5000;
In seltenen Fällen, in denen die Frist nicht sinnvoll ist (z. B. beim Verfolgen einer Ressource), kann der Entwickler sie deaktivieren:
option (rpc_core.method_no_deadline) = true;
Darüber hinaus sollte die Servicebeschreibung eine detaillierte API-Dokumentation enthalten, möglicherweise mit Verwendungsbeispielen.
Stub Generation
Um mehr Flexibilität zu bieten, generiert Courier seine eigenen Stubs, ohne sich auf die von gRPC bereitgestellte Interceptor-Funktionalität zu verlassen (mit Ausnahme von Java, in dem die Interceptor-API über ausreichende Leistung verfügt). Vergleichen wir unsere Stubs mit den Standard-Golang-Stubs.
So sehen die Standard-gRPC-Server-Stubs aus:
func _Test_UnaryUnary_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) { in := new(TestRequest) if err := dec(in); err != nil { return nil, err } if interceptor == nil { return srv.(TestServer).UnaryUnary(ctx, in) } info := &grpc.UnaryServerInfo{ Server: srv, FullMethod: "/test.Test/UnaryUnary", } handler := func(ctx context.Context, req interface{}) (interface{}, error) { return srv.(TestServer).UnaryUnary(ctx, req.(*TestRequest)) } return interceptor(ctx, in, info, handler) }
Die gesamte Verarbeitung erfolgt im Inneren: Dekodieren von Protobuf, Starten von Interceptors (siehe die
interceptor Variable im Code), Starten des UnaryUnary-Handlers.
Schauen Sie sich jetzt die Kurierstubs an:
func _Test_UnaryUnary_dbxHandler( srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) ( interface{}, error) { defer processor.PanicHandler() impl := srv.(*dbxTestServerImpl) metadata := impl.testUnaryUnaryMetadata ctx = metadata.SetupContext(ctx) clientId = client_info.ClientId(ctx) stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId) stats.TotalCount.Inc() req := &processor.UnaryUnaryRequest{ Srv: srv, Ctx: ctx, Dec: dec, Interceptor: interceptor, RpcStats: stats, Metadata: metadata, FullMethodPath: "/test.Test/UnaryUnary", Req: &test.TestRequest{}, Handler: impl._UnaryUnary_internalHandler, ClientId: clientId, EnqueueTime: time.Now(), } metadata.WorkPool.Process(req).Wait() return req.Resp, req.Err }
Hier gibt es ziemlich viel Code, also analysieren wir ihn.
Zunächst verschieben wir den Aufruf an den Panic Handler, der für die automatische Erfassung von Fehlern verantwortlich ist. Auf diese Weise können wir alle nicht erfassten Ausnahmen im zentralen Repository für die spätere Aggregation und Berichterstellung erfassen:
defer processor.PanicHandler()
Ein weiterer Grund, warum wir unseren eigenen Panik-Handler ausführen, besteht darin, sicherzustellen, dass die Anwendung abstürzt, wenn ein Fehler auftritt. Der Standard-Golang / Net-HTTP-Handler ignoriert in diesem Fall das Problem und bedient weiterhin neue Anforderungen (auch beschädigt und inkonsistent).
Dann geben wir den Kontext weiter und definieren die Werte basierend auf den Metadaten der eingehenden Anforderung neu:
ctx = metadata.SetupContext(ctx) clientId = client_info.ClientId(ctx)
Außerdem erstellen wir serverseitige Client-Statistiken für eine detailliertere Aggregation (und speichern sie zur Steigerung der Effizienz).
stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId)
Diese Zeile erstellt während der Ausführung Statistiken für jeden Client (dh eine TLS-Kennung). Wir haben auch Statistiken zu allen Methoden für jeden Service. Da der Stub-Generator während der Codegenerierung auf alle Methoden zugreifen kann, können wir sie vorher statisch erstellen, um eine Verlangsamung des Programms zu vermeiden.
Danach erstellen wir eine Anforderungsstruktur, übertragen sie in den Aufgabenpool und warten auf die Ausführung:
req := &processor.UnaryUnaryRequest{ Srv: srv, Ctx: ctx, Dec: dec, Interceptor: interceptor, RpcStats: stats, Metadata: metadata, ... } metadata.WorkPool.Process(req).Wait()
Bitte beachten Sie, dass wir zu diesem Zeitpunkt weder Protobuf dekodiert noch den Interceptor gestartet haben. Zuvor müssen der Zugriffspool, die Priorisierung und die Begrenzung der Anzahl der ausgeführten Anforderungen den Aufgabenpool durchlaufen.
Beachten Sie, dass die gRPC-Bibliothek die TAP-Schnittstelle unterstützt, mit der Sie Anforderungen mit einer enormen Geschwindigkeit abfangen können. Die Schnittstelle bietet die Infrastruktur für den Aufbau effektiver Geschwindigkeitsbegrenzer bei minimalem Ressourcenverbrauch.Spezifische Fehlercodes für verschiedene Anwendungen
Mit unserem Stub-Generator können Entwickler mithilfe spezieller Optionen auch anwendungsspezifische Fehlercodes zuweisen:
enum ErrorCode { option (rpc_core.rpc_error) = true; UNKNOWN = 0; NOT_FOUND = 1 [(rpc_core.grpc_code)="NOT_FOUND"]; ALREADY_EXISTS = 2 [(rpc_core.grpc_code)="ALREADY_EXISTS"]; ... STALE_READ = 7 [(rpc_core.grpc_code)="UNAVAILABLE"]; SHUTTING_DOWN = 8 [(rpc_core.grpc_code)="CANCELLED"]; }
Sowohl gRPC- als auch Anwendungsfehler breiten sich innerhalb des Dienstes aus, und an der API-Grenze werden alle Fehler durch UNBEKANNT ersetzt. Auf diese Weise können wir vermeiden, das Problem auf andere Dienste zu übertragen, was zu einer Änderung ihrer Semantik führen kann.
Python-Änderungen
Python-Stubs fügen allen Courier-Handlern einen expliziten Kontextparameter hinzu:
from dropbox.context import Context from dropbox.proto.test.service_pb2 import ( TestRequest, TestResponse, ) from typing_extensions import Protocol class TestCourierClient(Protocol): def UnaryUnary( self, ctx, # type: Context request, # type: TestRequest ):
Anfangs sah es seltsam aus, aber im Laufe der Zeit gewöhnten sich die Entwickler daran,
ctx genau wie früher
selbst zu explizieren.
Bitte beachten Sie, dass unsere Stubs vollständig für
mypy typisiert
sind , was bei größeren
Umgestaltungen ausgeglichen wird. Darüber hinaus wird die Integration mit einigen IDEs (z. B. PyCharm) vereinfacht.
Wir folgen weiterhin dem Trend zur statischen Typisierung und fügen den Protokollen selbst mypy-Anmerkungen hinzu:
class TestMessage(Message): field: int def __init__(self, field : Optional[int] = ..., ) -> None: ... @staticmethod def FromString(s: bytes) -> TestMessage: ...
Durch diese Anmerkungen werden viele häufig auftretende Fehler vermieden, z. B. das Zuweisen des Werts "
Keine" zu einem Feld vom Typ "
Zeichenfolge" .Dieser Code
ist hier verfügbar .
Migrationsprozess
Das Erstellen eines neuen RPC-Stacks ist keine leichte Aufgabe, steht jedoch nicht einmal neben dem Prozess eines vollständigen Übergangs, wenn Sie die Komplexität des Betriebs betrachten. Aus diesem Grund haben wir versucht, Entwicklern den Wechsel vom alten RPC zu Courier so einfach wie möglich zu gestalten. Da die Migration häufig mit Fehlern einhergeht, haben wir uns entschlossen, sie schrittweise umzusetzen.
Schritt 0: Frieren Sie den alten RPC ein
Zunächst haben wir den alten RPC eingefroren, um nicht auf ein sich bewegendes Ziel zu schießen. Es veranlasste die Benutzer auch, zu Courier zu wechseln, da alle neuen Funktionen wie die Ablaufverfolgung nur in Courier-Diensten verfügbar waren.
Schritt 1: Gemeinsame Schnittstelle für alte RPC und Courier
Wir haben zunächst eine gemeinsame Schnittstelle für den alten RPC und Courier definiert. Unsere Codegenerierung sollte sicherstellen, dass beide Versionen der Stubs dieser Schnittstelle entsprechen:
type TestServer interface { UnaryUnary( ctx context.Context, req *test.TestRequest) ( *test.TestResponse, error) ... }
Schritt 2: Migrieren Sie zur neuen Schnittstelle
Danach haben wir begonnen, jeden Dienst auf eine neue Schnittstelle umzustellen, während wir weiterhin den alten RPC verwendeten. Oft waren Codeänderungen ein großer Unterschied, der alle Methoden des Dienstes und seiner Clients betraf. Da diese Phase am problematischsten ist, wollten wir das Risiko vollständig beseitigen, indem wir jeweils nur eine Sache ändern.
Einfache Dienste mit einer geringen Anzahl von Methoden und dem Recht, Fehler zu machen, können gleichzeitig migriert werden, ohne unsere Warnungen zu beachten.Schritt 3: Migrieren Sie Kunden zum RPC Courier
Während des Migrationsprozesses haben wir begonnen, gleichzeitig alte und neue Server an verschiedenen Ports desselben Computers zu starten. Das Wechseln der clientseitigen RPC-Implementierung erfolgte durch Ändern einer Zeile:
class MyClient(object): def __init__(self): - self.client = LegacyRPCClient('myservice') + self.client = CourierRPCClient('myservice')
Bitte beachten Sie, dass Sie mit diesem Modell jeweils einen Client übertragen können, beginnend mit denen mit einem niedrigeren SLA-Level.
Schritt 4: Reinigung
, , RPC ( ). — .
Schlussfolgerungen
, Courier — RPC-, , Dropbox.
, Courier:
- — . .
- — , .
- , . Codegen.
- . , , . , : .
- RPC- — , . . .
Courier, gRPC , , , .
gRPC Python , C++ Python Rust . ALTS TLS- (, ).