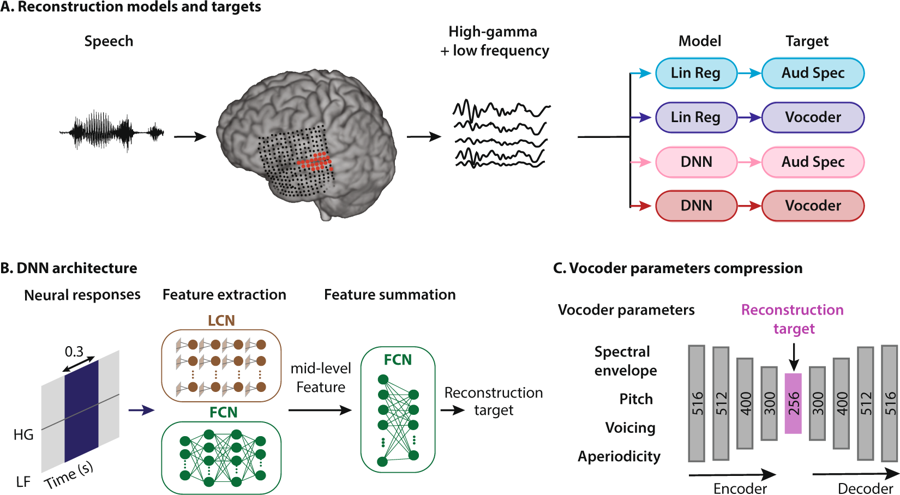
 Schema der Methode der Sprachrekonstruktion. Eine Person hört auf Wörter, wodurch Neuronen ihres auditorischen Kortex aktiviert werden. Die Daten werden auf vier Arten interpretiert: Durch Kombinieren von zwei Arten von Regressionsmodellen und zwei Arten von Sprachdarstellungen gelangen sie in das neuronale Netzwerksystem, um Merkmale zu extrahieren, die anschließend zum Konfigurieren von Vocoder-Parametern verwendet werden
Schema der Methode der Sprachrekonstruktion. Eine Person hört auf Wörter, wodurch Neuronen ihres auditorischen Kortex aktiviert werden. Die Daten werden auf vier Arten interpretiert: Durch Kombinieren von zwei Arten von Regressionsmodellen und zwei Arten von Sprachdarstellungen gelangen sie in das neuronale Netzwerksystem, um Merkmale zu extrahieren, die anschließend zum Konfigurieren von Vocoder-Parametern verwendet werdenNeuroingenieure an der Columbia University (USA) waren die ersten auf der Welt,
die ein System geschaffen haben , das menschliche Gedanken in verständliche, unterscheidbare Sprache übersetzt. Hier ist die
Tonaufzeichnung von Wörtern (mp3), die durch Gehirnaktivität synthetisiert werden.
Durch Beobachtung der Aktivität im auditorischen Kortex stellt das System die Wörter, die eine Person hört, mit beispielloser Klarheit wieder her. Natürlich ist dies nicht die Bewertung von Gedanken im wahrsten Sinne des Wortes, aber ein wichtiger Schritt in diese Richtung wurde unternommen. In der Tat treten ähnliche Muster der Gehirnaktivität in der Großhirnrinde auf, wenn sich eine Person vorstellt, Sprache zu hören, oder wenn sie geistig Worte spricht.
Dieser wissenschaftliche Durchbruch mithilfe künstlicher Intelligenz bringt uns der Schaffung effektiver neuronaler Schnittstellen näher, die den Computer direkt mit dem Gehirn verbinden. Es hilft auch Menschen, die nicht sprechen können und denen, die sich von einem Schlaganfall erholen oder aus einem anderen Grund, die vorübergehend oder ständig nicht in der Lage sind, Worte zu sprechen, um zu kommunizieren.
Jahrzehntelange Forschungen haben gezeigt, dass beim Sprechen oder sogar beim Sprechen von Wörtern Kontrollmuster der Aktivität im Gehirn auftreten. Darüber hinaus entsteht ein eindeutiges (und erkennbares) Signalmuster, wenn wir jemandem zuhören oder uns vorstellen, dass wir zuhören. Experten haben lange versucht, diese Muster aufzuzeichnen und zu entschlüsseln, um die Gedanken einer Person vom Schädel zu „befreien“ - und sie automatisch in mündliche Form zu übersetzen.
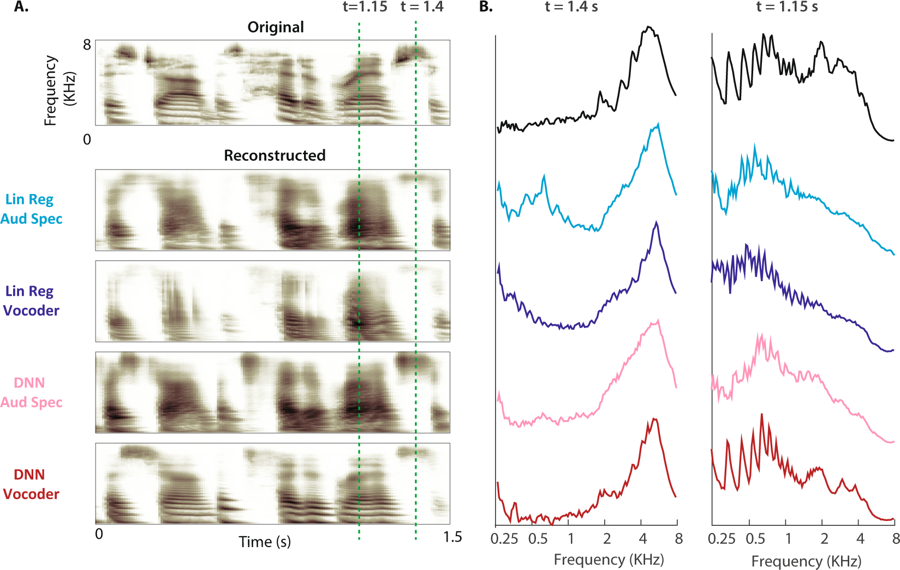 (A) Das ursprüngliche Spektrogramm einer Sprachprobe ist oben gezeigt. Die rekonstruierten Hörspektrogramme der vier Modelle sind unten gezeigt. (B) Die Größenleistung der Frequenzbänder während stimmloser (t = 1,4 s) und stimmhafter Sprache (t = 1,15 s: Die Lücke ist für das ursprüngliche Spektrogramm und vier Rekonstruktionen durch gestrichelte Linien dargestellt).
(A) Das ursprüngliche Spektrogramm einer Sprachprobe ist oben gezeigt. Die rekonstruierten Hörspektrogramme der vier Modelle sind unten gezeigt. (B) Die Größenleistung der Frequenzbänder während stimmloser (t = 1,4 s) und stimmhafter Sprache (t = 1,15 s: Die Lücke ist für das ursprüngliche Spektrogramm und vier Rekonstruktionen durch gestrichelte Linien dargestellt)."Dies ist dieselbe Technologie, mit der Amazon Echo und Apple Siri unsere Fragen mündlich beantworten",
erklärt Dr. Nima Mesgarani, Hauptautorin des Papiers. Um dem Vocoder die Interpretation der Gehirnaktivität beizubringen, fanden Experten fünf Patienten mit Epilepsie, die sich bereits einer Gehirnoperation unterzogen hatten. Sie wurden gebeten, Sätze von verschiedenen Personen anzuhören, während Elektroden die Gehirnaktivität maßen, die von vier Modellen verarbeitet wurde. Diese neuronalen Muster lehrten Vocoder. Die Forscher baten dann dieselben Patienten, zuzuhören, wie die Sprecher Zahlen von 0 bis 9 aussprechen, und dabei Gehirnsignale aufzuzeichnen, die durch den Vocoder geleitet werden könnten. Der vom Vocoder als Reaktion auf diese Signale erzeugte Ton wird von mehreren neuronalen Netzen analysiert und gelöscht.
Als Ergebnis der Verarbeitung am Ausgang des neuronalen Netzwerks wurde eine Roboterstimme empfangen, die eine Folge von Zahlen aussprach. Um die Erkennungsgenauigkeit zu testen, wurde den Menschen die Möglichkeit gegeben, Geräusche zu hören, die durch ihre eigene Gehirnaktivität synthetisiert wurden: „Wir haben festgestellt, dass Menschen in 75% der Fälle Geräusche verstehen und wiederholen können, was viel höher ist und alle vorherigen Versuche übertrifft“, sagte Dr. Mesgarani.
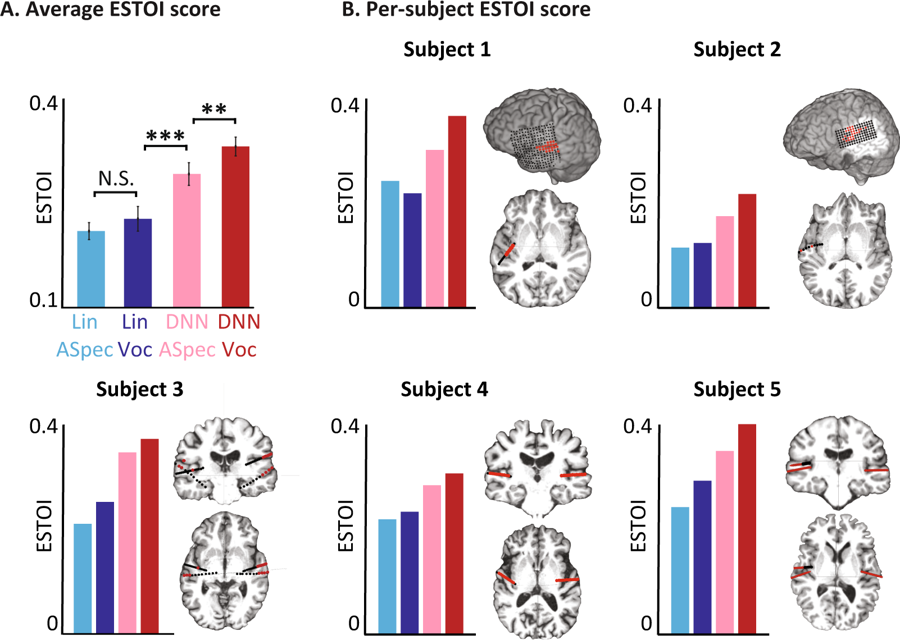 Objektive Bewertungen für verschiedene Modelle. (A) Durchschnittlicher ESTOI-Wert für alle Probanden für die vier Modelle. B) Die Abdeckung und Position der Elektroden und der ESTOI-Score für jede der fünf Personen. Jeder hat einen höheren ESTOI-Wert für den DNN-Vocoder als andere Modelle.
Objektive Bewertungen für verschiedene Modelle. (A) Durchschnittlicher ESTOI-Wert für alle Probanden für die vier Modelle. B) Die Abdeckung und Position der Elektroden und der ESTOI-Score für jede der fünf Personen. Jeder hat einen höheren ESTOI-Wert für den DNN-Vocoder als andere Modelle.Jetzt planen Wissenschaftler, das Experiment mit komplexeren Wörtern und Sätzen zu wiederholen. Darüber hinaus werden dieselben Tests für Gehirnsignale durchgeführt, wenn sich eine Person vorstellt, was sie sagt. Letztendlich hoffen sie, dass das System Teil des Implantats wird, das die Gedanken des Trägers direkt in Worte übersetzt.
Der wissenschaftliche Artikel wurde am 29. Januar 2019 öffentlich in der Zeitschrift
Scientific Reports (doi: 10.1038 / s41598-018-37359-z) veröffentlicht.
Der Programmcode zur Durchführung einer phonemischen Analyse, zur Berechnung hochfrequenter Amplituden und zur Rekonstruktion eines Hörspektrogramms
steht der Öffentlichkeit zur Verfügung .