Eintrag
In diesem Artikel werde ich über den bekannten Huffman-Algorithmus sowie dessen Anwendung bei der Datenkomprimierung sprechen.
Als Ergebnis werden wir einen einfachen Archivierer schreiben. Es gab bereits einen
Artikel über Habré , jedoch ohne praktische Umsetzung. Das theoretische Material des aktuellen Beitrags stammt aus dem Schulunterricht in Informatik und aus Robert Lafores Buch „Datenstrukturen und Algorithmen in Java“. Also ist alles unter dem Schnitt!
Ein kleiner Gedanke
In einer Nur-Text-Datei wird ein Zeichen mit 8 Bit (ASCII-Codierung) oder 16 Bit (Unicode-Codierung) codiert. Weiter werden wir die ASCII-Codierung betrachten. Nehmen Sie zum Beispiel die Zeile s1 = "SUSIE SAGT, ES IST EINFACH \ n". Insgesamt enthält die Zeile natürlich 22 Zeichen, einschließlich Leerzeichen und des Zeilenumbruchzeichens '\ n'. Eine Datei mit dieser Zeile wiegt 22 * 8 = 176 Bit. Es stellt sich sofort die Frage: Ist es sinnvoll, alle 8 Bits zum Codieren von 1 Zeichen zu verwenden? Wir verwenden nicht alle ASCII-Zeichen. Selbst wenn es verwendet wird, wäre es rationaler, wenn der häufigste Buchstabe - S - den kürzestmöglichen Code und der seltenste Buchstabe - T (oder U oder '\ n') - einen authentischeren Code angibt. Dies ist der Huffman-Algorithmus: Sie müssen die beste Codierungsoption finden, bei der die Datei ein minimales Gewicht hat. Es ist ganz normal, dass die Codelängen für verschiedene Zeichen unterschiedlich sind - dies ist die Grundlage des Algorithmus.
Codierung
Warum geben Sie dem Zeichen 'S' keinen Code, zum Beispiel 1 Bit lang: 0 oder 1. Lassen Sie es 1 sein. Dann geben wir das am zweithäufigsten angetroffene Zeichen - '' (Leerzeichen) - 0. Stellen Sie sich vor, Sie haben begonnen, Ihre Nachricht zu dekodieren - codierte Zeichenfolge s1 - und Sie sehen, dass der Code mit 1 beginnt. Was ist also zu tun: Ist es ein Zeichen S oder ein anderes Zeichen, zum Beispiel A? Daher ergibt sich eine wichtige Regel:
Kein Code sollte ein Präfix eines anderen seinDiese Regel ist der Schlüssel im Algorithmus. Daher beginnt die Erstellung des Codes mit der Häufigkeitstabelle, die die Häufigkeit (Anzahl der Vorkommen) jedes Zeichens angibt:
Die Zeichen mit den meisten Vorkommen sollten mit der kleinstmöglichen Anzahl von Bits codiert werden. Ich werde ein Beispiel für eine der möglichen Codetabellen geben:
Die verschlüsselte Nachricht sieht also folgendermaßen aus:
10 01111 10 110 1111 00 10 010 1110 10 00 110 0110 00 110 10 00 1111 010 10 1110 01110
Ich habe den Code jedes Zeichens durch ein Leerzeichen getrennt. Dies wird in einer komprimierten Datei nicht wirklich passieren!
Es stellt sich die Frage:
Wie kam diese Salaga auf einen Code ? Wie erstelle
ich eine Codetabelle? Dies wird unten diskutiert.
Einen Huffman-Baum bauen
Hier kommen binäre Suchbäume zur Rettung. Keine Sorge, hier sind die Methoden zum Suchen, Einfügen und Löschen nicht erforderlich. Hier ist die Baumstruktur in Java:
public class Node { private int frequence; private char letter; private Node leftChild; private Node rightChild; ... }
class BinaryTree { private Node root; public BinaryTree() { root = new Node(); } public BinaryTree(Node root) { this.root = root; } ... }
Dies ist kein vollständiger Code, der vollständige Code wird unten angegeben.
Hier ist der Baumbildungsalgorithmus selbst:
- Erstellen Sie für jedes Zeichen aus der Nachricht ein Knotenobjekt (Zeile s1). In unserem Fall gibt es 9 Knoten (Knotenobjekte). Jeder Knoten besteht aus zwei Datenfeldern: Symbol und Frequenz
- Erstellen Sie für jeden Knotenknoten ein Baumobjekt (BinaryTree). Der Knoten wird zur Wurzel des Baums.
- Fügen Sie diese Bäume in die Prioritätswarteschlange ein. Je niedriger die Frequenz, desto höher die Priorität. Daher wird beim Extrahieren der Dervo immer mit der niedrigsten Frequenz ausgewählt.
Als nächstes müssen Sie zyklisch Folgendes tun:
- Extrahieren Sie zwei Bäume aus der Prioritätswarteschlange und machen Sie sie zu Nachkommen des neuen Knotens (des neu erstellten Knotens ohne Buchstaben). Die Frequenz des neuen Knotens ist gleich der Summe der Frequenzen zweier Nachkommenbäume.
- Erstellen Sie für diesen Knoten einen Baum mit einer Wurzel in diesem Knoten. Fügen Sie diesen Baum wieder in die Prioritätswarteschlange ein. (Da der Baum eine neue Frequenz hat, wird er höchstwahrscheinlich an einen neuen Platz in der Warteschlange gelangen.)
- Fahren Sie mit den Schritten 1 und 2 fort, bis nur noch ein Baum in der Warteschlange vorhanden ist - der Huffman-Baum
Betrachten Sie diesen Algorithmus in Zeile s1:

Hier zeigt das Symbol "lf" (Zeilenvorschub) den Übergang zu einer neuen Zeile an, "sp" (Leerzeichen) ist ein Leerzeichen.
Was kommt als nächstes?
Wir haben einen Huffman-Baum. Na gut. Und was soll man damit machen?
Sie werden es nicht kostenlos nehmen. Und dann müssen Sie alle möglichen Wege von der Wurzel bis zu den Blättern des Baumes verfolgen. Lassen Sie uns vereinbaren, die Kante 0 zu bezeichnen, wenn sie zum linken Nachkommen führt, und 1, wenn sie zum rechten Nachkommen führt. Genau genommen ist in diesen Notationen der Symbolcode der Pfad von der Wurzel des Baums zu dem Blatt, das dasselbe Symbol enthält.
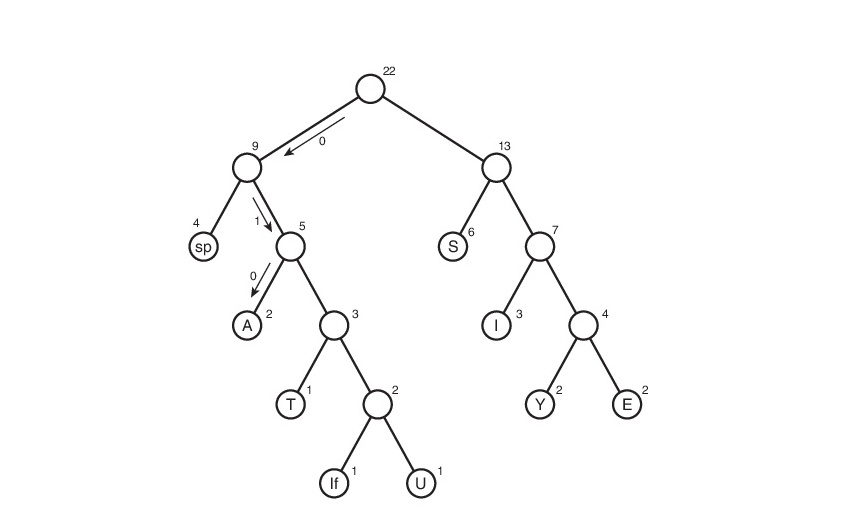
Somit stellte sich die Codetabelle heraus. Beachten Sie, dass wir, wenn wir diese Tabelle betrachten, auf das "Gewicht" jedes Zeichens schließen können - dies ist die Länge seines Codes. Dann wiegt die komprimierte Datei: 2 * 3 + 2 * 4 + 3 * 3 + 6 * 2 + 1 * 4 + 1 * 5 + 2 * 4 + 4 * 2 + 1 * 5 = 65 Bit. Anfangs wog es 176 Bit. Deshalb haben wir es um das 176/65 = 2,7-fache reduziert! Aber das ist Utopie. Es ist unwahrscheinlich, dass ein solcher Koeffizient erhalten wird. Warum? Dies wird etwas später besprochen.
Dekodierung
Nun, vielleicht ist das Einfachste, was noch übrig ist, das Dekodieren. Ich denke, viele von Ihnen haben vermutet, dass es unmöglich ist, einfach eine komprimierte Datei zu erstellen, ohne einen Hinweis darauf zu haben, wie sie codiert wurde - wir können sie nicht dekodieren! Ja, es war schwer für mich, dies zu realisieren, aber ich musste eine Textdatei table.txt mit einer Komprimierungstabelle erstellen:
01110 00 A010 E1111 I110 S10 T0110 U01111 Y1110
Notieren Sie die Tabelle in Form von "Zeichen" "Zeichencode". Warum ist 01110 ohne Zeichen? Tatsächlich ist es mit einem Symbol, nur den Java-Werkzeugen, die ich bei der Ausgabe in eine Datei verwendet habe, das Zeilenumbruchzeichen - '\ n' - wird in einen Zeilenumbruch konvertiert (egal wie dumm es klingt). Daher ist die leere Zeile oben das Zeichen für Code 01110. Bei Code 00 ist das Zeichen ein Leerzeichen am Zeilenanfang. Ich muss sofort sagen, dass
unsere Methode zur Speicherung dieser Tabelle die irrationalste sein kann. Aber es ist einfach zu verstehen und umzusetzen. Ich freue mich über Ihre Empfehlungen in den Kommentaren zur Optimierung.
Diese Tabelle zu haben ist sehr einfach zu dekodieren. Erinnern Sie sich daran, nach welcher Regel wir uns beim Erstellen der Codierung orientiert haben:
Kein Code sollte einem anderen vorangestellt werdenHier spielt es eine unterstützende Rolle. Wir lesen nacheinander Stück für Stück und sobald die empfangene Zeichenfolge d, die aus Lesebits besteht, mit der Codierung übereinstimmt, die dem Zeichen entspricht, wissen wir sofort, dass das Zeichen codiert wurde (und nur es!). Als nächstes schreiben wir ein Zeichen in die Decodierungszeile (die Zeile, die die decodierte Nachricht enthält), setzen die Zeile d auf Null und lesen dann die codierte Datei.
Implementierung
Es ist Zeit,
meinen Code zu
demütigen, indem ich einen Archivierer schreibe. Nennen wir es Compressor.
Beginnen wir von vorne. Zuerst schreiben wir die Node-Klasse:
public class Node { private int frequence;
Nun der Baum:
class BinaryTree { private Node root; public BinaryTree() { root = new Node(); } public BinaryTree(Node root) { this.root = root; } public int getFrequence() { return root.getFrequence(); } public Node getRoot() { return root; } }
Prioritätswarteschlange:
import java.util.ArrayList;
Die Klasse, die den Huffman-Baum erstellt:
public class HuffmanTree { private final byte ENCODING_TABLE_SIZE = 127;
Klasse, die enthält, welche codiert / decodiert:
public class HuffmanOperator { private final byte ENCODING_TABLE_SIZE = 127;
Klasse, die das Schreiben in eine Datei erleichtert:
import java.io.File; import java.io.PrintWriter; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.Closeable; public class FileOutputHelper implements Closeable { private File outputFile; private FileOutputStream fileOutputStream; public FileOutputHelper(File file) throws FileNotFoundException { outputFile = file; fileOutputStream = new FileOutputStream(outputFile); } public void writeByte(byte msg) throws IOException { fileOutputStream.write(msg); } public void writeBytes(byte[] msg) throws IOException { fileOutputStream.write(msg); } public void writeString(String msg) { try (PrintWriter pw = new PrintWriter(outputFile)) { pw.write(msg); } catch (FileNotFoundException e) { System.out.println(" , !"); } } @Override public void close() throws IOException { fileOutputStream.close(); } public void finalize() throws IOException { close(); } }
Klasse, die das Lesen aus einer Datei erleichtert:
import java.io.FileInputStream; import java.io.EOFException; import java.io.BufferedReader; import java.io.InputStreamReader; import java.io.Closeable; import java.io.File; import java.io.IOException; public class FileInputHelper implements Closeable { private FileInputStream fileInputStream; private BufferedReader fileBufferedReader; public FileInputHelper(File file) throws IOException { fileInputStream = new FileInputStream(file); fileBufferedReader = new BufferedReader(new InputStreamReader(fileInputStream)); } public byte readByte() throws IOException { int cur = fileInputStream.read(); if (cur == -1)
Nun, und die Hauptklasse:
import java.io.File; import java.nio.charset.MalformedInputException; import java.io.FileNotFoundException; import java.io.IOException; import java.nio.file.Files; import java.nio.file.NoSuchFileException; import java.nio.file.Paths; import java.util.List; import java.io.EOFException; public class Main { private static final byte ENCODING_TABLE_SIZE = 127; public static void main(String[] args) throws IOException { try {
Die Anweisungsdatei readme.txt können Sie selbst schreiben :-)
Fazit
Das ist wahrscheinlich alles, was ich sagen wollte. Wenn Sie etwas über
meine Inkompetenz bei Verbesserungen des Codes, des Algorithmus und jeglicher Optimierung im Allgemeinen zu sagen haben, können Sie gerne schreiben. Wenn ich etwas falsch verstanden habe, schreibe auch. Ich würde mich freuen, von Ihnen in den Kommentaren zu hören!
PS
Ja, ja, ich bin immer noch hier, weil ich den Koeffizienten nicht vergessen habe. Für die Zeichenfolge s1 wiegt die Codierungstabelle 48 Byte - viel mehr als die Originaldatei, und sie haben zusätzliche Nullen nicht vergessen (die Anzahl der hinzugefügten Nullen beträgt 7) => das Komprimierungsverhältnis ist kleiner als eins: 176 / (65 + 48 * 8 + 7) = 0,38. Wenn Sie dies auch bemerkt haben, dann sind Sie
einfach nicht gut im Gesicht . Ja, diese Implementierung ist für kleine Dateien äußerst ineffizient. Aber was passiert mit großen Dateien? Die Dateigrößen überschreiten die Größe der Codierungstabelle bei weitem. Hier funktioniert der Algorithmus wie er sollte! Zum Beispiel gibt
der Archivierer für den
Faust-Monolog einen realen (nicht idealisierten) Koeffizienten von 1,46 an - fast das Eineinhalbfache! Und ja, die Datei sollte auf Englisch sein.