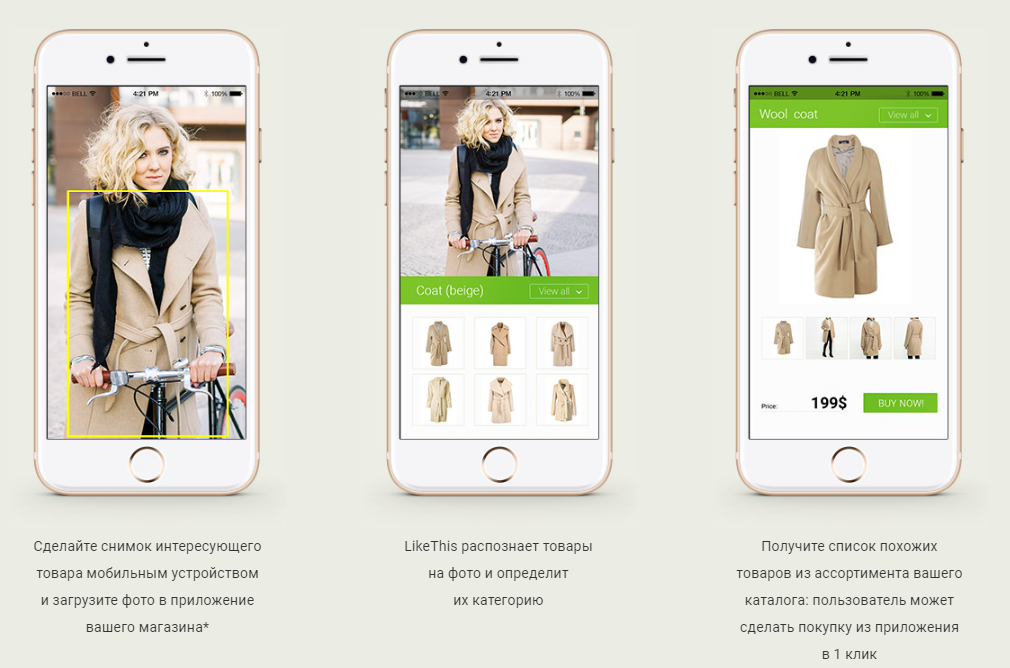
In diesem Artikel möchte ich darüber sprechen, wie wir aus Fotos ein Suchsystem für ähnliche Kleidung (genauer Kleidung, Schuhe und Taschen) erstellt haben. Das ist in geschäftlicher Hinsicht ein Empfehlungsdienst, der auf neuronalen Netzen basiert.
Wie bei den meisten modernen IT-Lösungen können wir die Entwicklung unseres Systems mit der Lego-Konstruktorbaugruppe vergleichen, wenn wir viele kleine Details und Anweisungen verwenden und daraus ein fertiges Modell erstellen. Hier ist eine solche Anweisung: Welche Details zu beachten sind und wie sie anzuwenden sind, damit Ihre GPU ähnliche Produkte aus einem Foto auswählen kann, finden Sie in diesem Artikel.
Aus welchen Teilen besteht unser System:
- Detektor und Klassifikator von Kleidung, Schuhen und Taschen auf Bildern;
- Crawler, Indexer oder Modul für die Arbeit mit elektronischen Katalogen von Geschäften;
- ähnliches Bildsuchmodul;
- JSON-API für die bequeme Interaktion mit jedem Gerät und Dienst;
- Weboberfläche oder mobile Anwendung, um die Ergebnisse anzuzeigen.
Am Ende des Artikels werden wir alle „Rechen“ beschreiben, auf die wir während der Entwicklung getreten sind, und Empfehlungen, wie wir sie neutralisieren können.
Erklärung des Problems und Erstellung des Rubrikators
Die Aufgabe und der Hauptanwendungsfall des Systems klingen recht einfach und klar:
- Der Benutzer legt dem Eingang (z. B. über eine mobile Anwendung) ein Foto vor, auf dem sich Kleidungsstücke und / oder Taschen und / oder Schuhe befinden.
- das System bestimmt (erkennt) alle diese Objekte;
- findet für jeden von ihnen die ähnlichsten (relevanten) Produkte in echten Online-Shops;
- bietet dem Benutzer Produkte die Möglichkeit, zum Kauf auf eine bestimmte Produktseite zuzugreifen.
Einfach ausgedrückt, das Ziel unseres Systems ist es, die berühmte Frage zu beantworten: "Und Sie haben nicht das gleiche, nur mit Perlmuttknöpfen?"
Bevor Sie in den Pool der Codierung, Markierung und des Trainings neuronaler Netze einsteigen, müssen Sie die Kategorien, die sich in Ihrem System befinden, dh die Kategorien, die das neuronale Netz erkennt, ganz klar bestimmen. Es ist wichtig zu verstehen, dass die Liste der Kategorien umso universeller ist, je breiter und detaillierter sie ist, da eine große Anzahl schmaler kleiner Kategorien wie Minikleid, Midikleid und Maxikleid immer mit einem Tastendruck zu einer Kategorie von Kleidungsstücken kombiniert werden kann ABER NICHT umgekehrt. Mit anderen Worten, der Rubrikator muss zu Beginn des Projekts gut durchdacht und kompiliert werden, damit die gleiche Arbeit nicht dreimal wiederholt wird. Wir haben den Rubrikator auf der Grundlage mehrerer großer Geschäfte wie Lamoda.ru und Amazon.com zusammengestellt und versucht, ihn einerseits so breit wie möglich und andererseits so vielseitig wie möglich zu gestalten, um die Zuordnung von Detektorkategorien zu verschiedenen Kategorien in Zukunft zu vereinfachen Online-Shops (Ich werde Ihnen im Abschnitt "Crawler und Indexer" mehr darüber erzählen, wie Sie diese Gruppe erstellen können.) Hier ist ein Beispiel dafür, was passiert ist.
 Beispielkategorien
BeispielkategorienIn unserem Katalog gibt es derzeit nur 205 Kategorien: Damenbekleidung, Herrenbekleidung, Damenschuhe, Herrenschuhe, Taschen, Kleidung für Neugeborene. Die Vollversion unseres Klassifikators finden Sie
unter dem Link .
Indexer oder Modul zum Arbeiten mit elektronischen Filialkatalogen
Um in Zukunft nach ähnlichen Produkten suchen zu können, müssen wir eine umfassende Basis für das schaffen, wonach wir suchen werden. Nach unserer Erfahrung hängt die Qualität der Suche nach ähnlichen Bildern direkt von der Größe der Suchbasis ab, die mindestens 100.000 Bilder und vorzugsweise 1 Million Bilder überschreiten sollte. Wenn Sie der Datenbank 1-2 kleine Online-Shops hinzufügen, erhalten Sie höchstwahrscheinlich keine beeindruckenden Ergebnisse, nur weil in 80% der Fälle nichts wirklich dem gewünschten Artikel in Ihrem Katalog ähnlich ist.
Um eine große Datenbank mit Bildern zu erstellen, die Sie zum Verarbeiten von Katalogen verschiedener Online-Shops benötigen, umfasst dieser Prozess Folgendes:
- Zuerst müssen Sie die XML-Feeds von Online-Shops finden. Sie können sie normalerweise entweder frei im Internet oder auf Anfrage im Store selbst oder in verschiedenen Aggregatoren wie Admitad finden.
- Der Feed wird von einem speziellen Programm verarbeitet (analysiert). Ein Crawler, der alle Bilder aus dem Feed herunterlädt, auf die Festplatte legt (genauer gesagt auf den Netzwerkspeicher, mit dem Ihr Server verbunden ist), schreibt alle Metainformationen zu den Waren in die Datenbank.
- Dann wird ein anderer Prozess gestartet - der Indexer, der binäre 128-dimensionale Merkmalsvektoren für jedes Bild berechnet. Sie können den Crawler und den Indexer in einem Modul oder Programm kombinieren, aber wir haben in der Vergangenheit festgestellt, dass dies unterschiedliche Prozesse waren. Dies war hauptsächlich auf die Tatsache zurückzuführen, dass wir zunächst Deskriptoren (Hashes) für jedes Bild berechnet haben, das auf einer großen Flotte von Maschinen verteilt ist, da dies ein sehr ressourcenintensiver Prozess war. Wenn Sie nur mit neuronalen Netzen arbeiten, reicht Ihnen der erste Computer mit einer GPU.
- Binärvektoren werden in die Datenbank geschrieben, alle Prozesse sind abgeschlossen und voila - Ihre Produktdatenbank ist bereit für die weitere Suche;
- Ein kleiner Trick bleibt jedoch bestehen: Da alle Geschäfte unterschiedliche Kataloge mit unterschiedlichen Kategorien enthalten, müssen Sie die Kategorien aller in Ihrer Datenbank enthaltenen Feeds mit den Kategorien des Detektors (genauer gesagt des Klassifikators) von Waren vergleichen. Wir nennen dies den Prozess der Zuordnung. Dies ist eine manuelle Routine, aber eine sehr nützliche Arbeit, bei der der Bediener beim manuellen Bearbeiten einer regulären XML-Datei die Kategorien von Feeds in der Datenbank mit den Kategorien des Detektors vergleicht. Hier ist das Ergebnis:
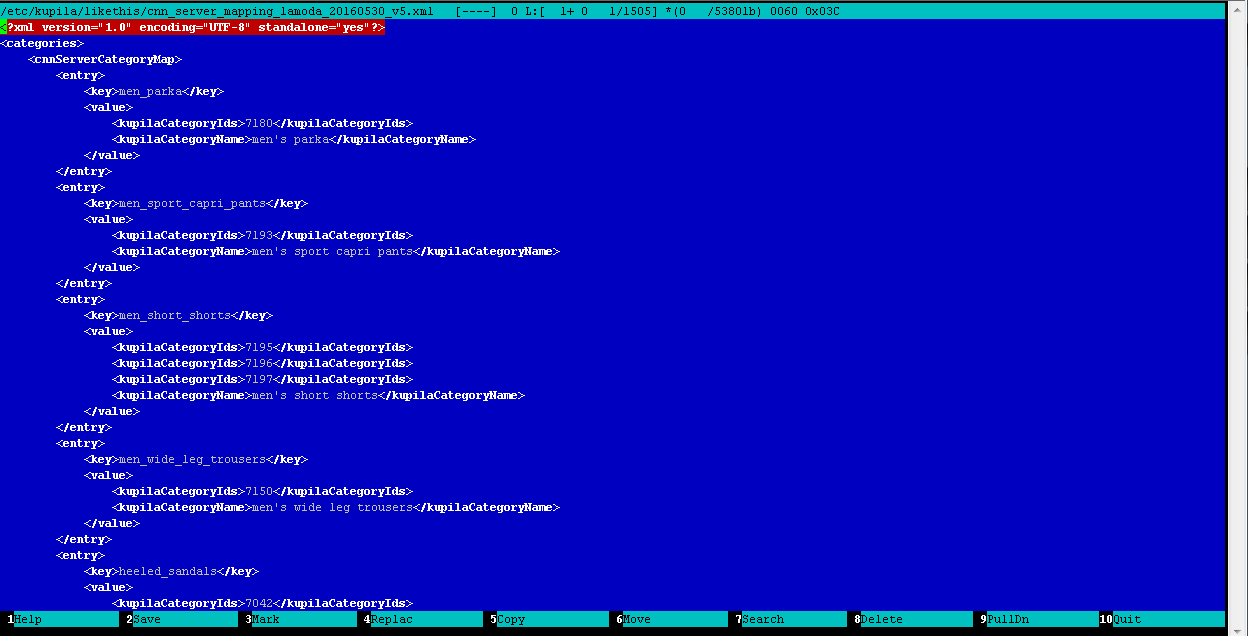 Beispiel für eine Kategoriezuordnungsdatei: Katalogklassifizierer
Beispiel für eine Kategoriezuordnungsdatei: KatalogklassifiziererErkennung und Klassifizierung
Um etwas zu finden, das dem ähnelt, was unser Auge auf dem Foto gefunden hat, müssen wir zuerst dieses „Etwas“ erkennen (dh das Objekt lokalisieren und auswählen). Wir haben einen langen Weg bei der Entwicklung eines Detektors zurückgelegt, angefangen beim Training von OpenCV-Kaskaden, die für diese Aufgabe überhaupt nicht
geeignet waren , bis hin zur modernen Technologie zur Erkennung und Klassifizierung von
R-FCN und dem Klassifikator basierend auf dem neuronalen
ResNet- Netzwerk.
Als Daten, die für Training und Test verwendet wurden (sogenannte Trainings- und Testmuster), haben wir alle Arten von Bildern aus dem Internet aufgenommen:
- Suche in Google / Yandex-Bildern;
- von Dritten markierte Datensätze;
- soziale Netzwerke;
- Modemagazinseiten;
- Internet-Shops mit Kleidung, Schuhen, Taschen.
Das Markup wurde mit einem Samopisny-Tool durchgeführt. Das Ergebnis des Markups waren Sätze von Bildern und * .seg-Dateien, in denen die Koordinaten von Objekten und Klassenbeschriftungen für sie gespeichert sind. Im Durchschnitt wurden 100 bis 200 Bilder für jede Kategorie beschriftet, die Gesamtzahl der Bilder in 205 Klassen betrug 65.000.
Nachdem die Schulungs- und Testmuster fertig sind, haben wir das Markup noch einmal überprüft und alle Bilder einem anderen Bediener übergeben. Dies ermöglichte es uns, eine große Anzahl von Fehlern herauszufiltern, die die Trainingsqualität des neuronalen Netzwerks, dh des Detektors und des Klassifikators, stark beeinflussen. Dann beginnen wir mit dem Training des neuronalen Netzwerks mit Standardwerkzeugen und "starten" den nächsten Schnappschuss des neuronalen Netzwerks "in der Hitze des Tages" in wenigen Tagen. Im Durchschnitt beträgt die Trainingszeit des Detektors und Klassifikators für das Datenvolumen von 65.000 Bildern auf einer Titan X-GPU etwa 3 Tage.
Ein vorgefertigtes neuronales Netzwerk muss irgendwie auf Qualität überprüft werden, dh um zu bewerten, ob und um wie viel die aktuelle Version des Netzwerks besser als die vorherige geworden ist. Wie wir es gemacht haben:
- Die Testprobe bestand aus 12.000 Bildern und war genauso angelegt wie das Training.
- Wir haben ein kleines Tool geschrieben, das die gesamte Testprobe durch den Detektor lief und eine Tabelle dieser Art zusammenstellte (die Vollversion der Tabelle finden Sie hier ).
- Diese Tabelle wird auf einer neuen Registerkarte zu Excel hinzugefügt und manuell oder mithilfe der integrierten Excel-Formeln mit der vorherigen Tabelle verglichen.
- Am Ausgang erhalten wir die allgemeinen Indikatoren des TPR / FPR-Detektors und Klassifikators im gesamten System in und für jede Kategorie separat.
 Beispiel einer Berichtstabelle zur Qualität des Detektors und Klassifikators
Beispiel einer Berichtstabelle zur Qualität des Detektors und KlassifikatorsSuchmodul für ähnliche Bilder
Nachdem wir auf dem Foto Kleidungsstücke entdeckt haben, starten wir die Suchmaschine für ähnliche Bilder. So funktioniert es:
- Für alle ausgeschnittenen Bildfragmente (erkannte Waren) werden 128-Bit-Binärmerkmalsvektoren des neuronalen Netzwerks in Form und Farbe berechnet (woher sie stammen, siehe unten).
- Die gleichen Vektoren, die zuvor in der Indizierungsphase für alle in der Datenbank gespeicherten Bilder von Waren berechnet wurden, sind bereits in den Computer-RAM geladen (da für die Suche nach ähnlichen Vektoren eine große Anzahl von Suchen und paarweisen Vergleichen erforderlich ist, haben wir die gesamte Datenbank sofort in den Speicher geladen, wodurch wir uns vergrößern konnten Die Suchgeschwindigkeit ist dutzende Male, während die Basis von etwa 100.000 Produkten in nicht mehr als 2-3 GB RAM passt.
- Suchkoeffizienten für diese Kategorie stammen von der Benutzeroberfläche oder von fest codierten Eigenschaften. Beispielsweise suchen wir in der Kategorie „Kleid“ mehr nach Farbe als nach Form (z. B. 8-zu-2-Farbformsuche) und in der Kategorie „Schuhe mit hohen Absätzen“ suchen wir 1-zu-1-Formfarbe, da hier sowohl Form als auch Farbe gleich wichtig sind;
- Ferner werden die Vektoren für die Ernte (Fragmente) aus dem Eingabebild paarweise mit dem Bild aus der Datenbank unter Berücksichtigung der Koeffizienten verglichen (der Hamming-Abstand zwischen den Vektoren wird verglichen).
- Infolgedessen wird für jedes Schnittproduktfragment ein Array ähnlicher Produkte aus der Datenbank gebildet, und jedem Produkt wird ein Gewicht zugewiesen (gemäß einer einfachen Formel unter Berücksichtigung der Normalisierung, so dass alle Gewichte im Bereich von 0 bis 1 liegen), um die Möglichkeit zur Ausgabe an die Schnittstelle sowie für weitere zu erhalten Sortieren;
- Über die Web-JSON-API wird in der Benutzeroberfläche eine Reihe ähnlicher Produkte angezeigt.
Neuronale Netze zur Bildung neuronaler Netzvektoren in Form und Farbe werden wie folgt trainiert.
- Um das neuronale Netzwerk in Form zu trainieren, nehmen wir alle markierten Bilder, schneiden die Fragmente gemäß dem Markup aus und verteilen sie entsprechend der Klasse in Ordnern: dh alle Pullover in einem Ordner, alle T-Shirts in einem anderen und alle hochhackigen Schuhe im dritten usw. d. Als nächstes trainieren wir einen gewöhnlichen Klassifikator basierend auf diesem Beispiel. Auf diese Weise „erklären“ wir dem neuronalen Netzwerk unser Verständnis der Form des Objekts.
- Um das neuronale Netzwerk in Farbe zu trainieren, nehmen wir alle markierten Bilder, schneiden die Fragmente gemäß dem Markup aus und verteilen sie entsprechend der Farbe in Ordnern: Das heißt, wir legen alle T-Shirts, Schuhe, Taschen usw. in den „grünen“ Ordner. grüne Farbe (daher sammeln sich alle Objekte mit grüner Farbe im Allgemeinen in einem Ordner an), im Ordner "gestrippt" legen wir alle Dinge in einen Streifen und im Ordner "rot-weiß" alle rot-weißen Dinge. Als nächstes trainieren wir einen separaten Klassifikator für diese Klassen, als ob wir dem neuronalen Netzwerk sein Verständnis der Farbe einer Sache „erklären“ würden.
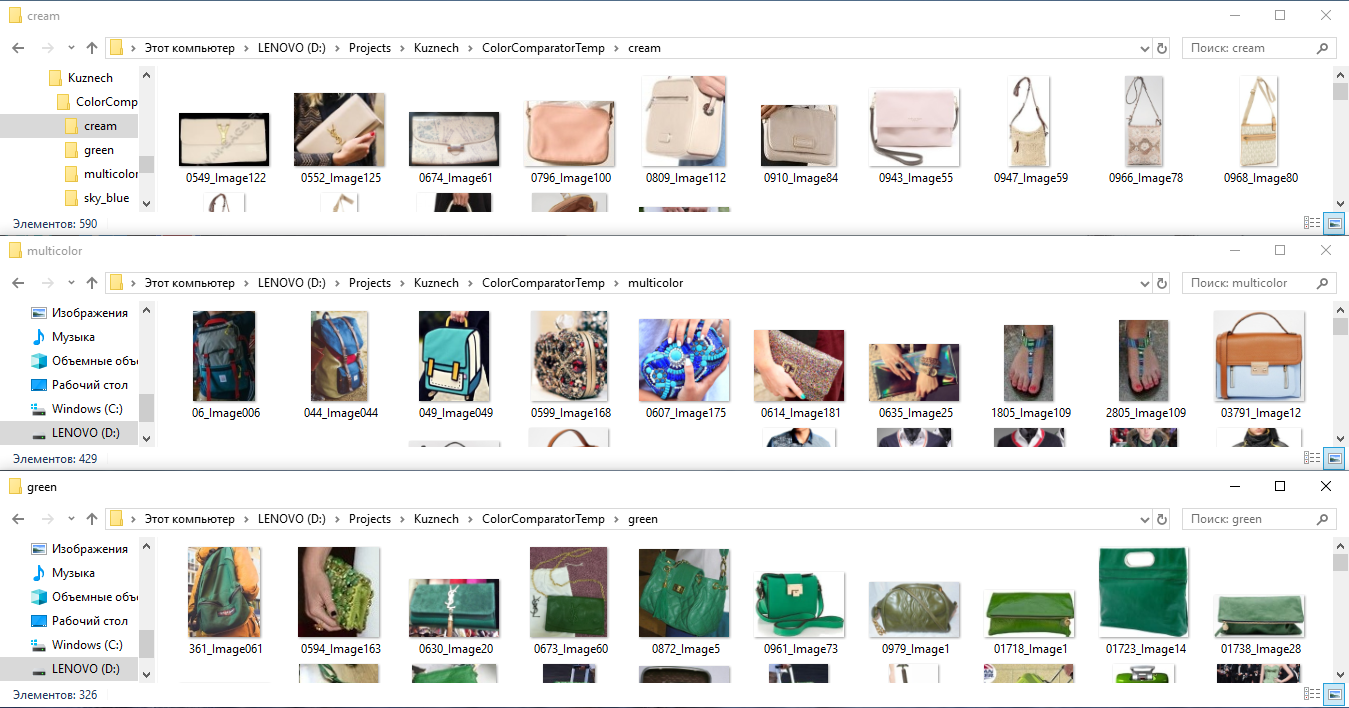 Ein Beispiel für das Markieren von Bildern nach Farbe, um neuronale Netzwerkvektoren von Zeichen nach Farbe zu erhalten.
Ein Beispiel für das Markieren von Bildern nach Farbe, um neuronale Netzwerkvektoren von Zeichen nach Farbe zu erhalten.Interessanterweise funktioniert eine solche Technologie auch auf komplexen Hintergründen gut, dh wenn Fragmente von Dingen nicht klar entlang der Kontur (Maske) ausgeschnitten werden, sondern entlang eines rechteckigen Rahmens, den der Marker definiert hat.
Die Suche nach ähnlichen basiert auf der Extraktion von binären Merkmalsvektoren aus dem neuronalen Netzwerk auf folgende Weise: Die Ausgabe der vorletzten Schicht wird genommen, komprimiert, normalisiert und binärisiert. In unserer Arbeit haben wir auf einen 128-Bit-Vektor komprimiert. Sie können dies beispielsweise etwas anders tun, wie in Yahoo-Artikel „
Deep Learning von binären Hash-Codes für das schnelle Abrufen von Bildern“ beschrieben. Die Essenz aller Algorithmen ist jedoch ungefähr gleich - Bilder, die dem Bild ähnlich sind, werden durchsucht, indem die Eigenschaften verglichen werden, die das neuronale Netzwerk innerhalb der Ebenen arbeitet.
Zunächst verwendeten wir als Technologie für die Suche nach ähnlichen Bildern Hashes oder Bilddeskriptoren, die auf bestimmten mathematischen Algorithmen basieren (genauer berechnet), z. B. dem Sobel-Operator (oder Kontur-Hash), dem SIFT-Algorithmus (oder einzelnen Punkten), dem Zeichnen eines Histogramms oder dem Vergleichen der Anzahl der Winkel in einem Bild . Diese Technologie hat funktioniert und zu mehr oder weniger vernünftigen Ergebnissen geführt, aber Hashes stehen in keinem Vergleich mit der Technologie zur Suche nach ähnlichen Bildern basierend auf Eigenschaften, die von einem neuronalen Netzwerk zugewiesen wurden. Wenn Sie versuchen, den Unterschied in zwei Worten zu erklären, ist der Hash-basierte Bildvergleichsalgorithmus ein „Taschenrechner“, der so konfiguriert ist, dass er Bilder mit einer Formel vergleicht und kontinuierlich funktioniert. Ein Vergleich unter Verwendung von Merkmalen aus einem neuronalen Netzwerk ist „künstliche Intelligenz“, die von einer Person trainiert wird, um ein bestimmtes Problem auf eine bestimmte Weise zu lösen. Sie können ein so grobes Beispiel geben: Wenn Sie nach Hash-Pullovern in schwarz-weißen Streifen suchen, werden Sie wahrscheinlich alle schwarz-weißen Dinge als ähnliche finden. Und wenn Sie über ein neuronales Netzwerk suchen, dann:
- an den ersten Stellen finden Sie alle Pullover mit schwarz-weißen Streifen,
- dann alle schwarz-weißen Pullover
- und dann alle gestreiften Pullover.
JSON-API für die bequeme Interaktion mit jedem Gerät und Dienst
Wir haben eine einfache und bequeme WEB-JSON-API für die Kommunikation unseres Systems mit allen Geräten und Systemen erstellt. Dies ist natürlich keine Innovation, sondern ein guter, starker Entwicklungsstandard.
Weboberfläche oder mobile Anwendung zum Anzeigen von Ergebnissen
Um die Ergebnisse visuell zu überprüfen und den Kunden das System zu demonstrieren, haben wir einfache Schnittstellen entwickelt:
Fehler, die im Projekt begangen wurden
- Zunächst ist es notwendig, die Aufgabe klarer zu definieren und basierend auf der Aufgabe Fotos für das Layout auszuwählen. Wenn Sie nach UGC-Fotos (User Generated Content) suchen müssen, ist dies ein Fall und ein Beispiel für das Layout. Wenn Sie eine Fotosuche aus Hochglanzmagazinen benötigen, ist dies ein anderer Fall. Wenn Sie eine Fotosuche benötigen, bei der sich ein großes Objekt auf einem weißen Hintergrund befindet, handelt es sich um eine separate Geschichte und ein völlig anderes Beispiel. Wir haben alles in einem Stapel gemischt, was sich auf die Qualität des Detektors und des Klassifikators auswirkte.
- Auf Fotos sollten Sie immer ALLE Objekte markieren, zumindest aufgrund der Tatsache, dass dies zumindest irgendwie zu Ihrer Aufgabe passt. Wenn Sie beispielsweise eine ähnliche Auswahl an Kleidungsstücken auswählen, müssen Sie sofort alle Accessoires (Perlen, Brillen, Armbänder usw.) und den Kopf markieren Hüte usw. Da wir jetzt über ein riesiges Trainingsset verfügen, müssen wir ALLE Fotos neu verteilen, um eine weitere Kategorie hinzuzufügen. Dies ist eine sehr umfangreiche Arbeit.
- Die Erkennung erfolgt höchstwahrscheinlich am besten mit einem Maskennetzwerk. Der Übergang zu Mask-CNN und einer modernen Detectron-basierten Lösung ist einer der Bereiche der Systementwicklung.
- Es wäre schön, sofort zu entscheiden, wie Sie die Qualität der Auswahl ähnlicher Bilder bestimmen möchten - es gibt zwei Methoden: "per Auge" und dies ist die einfachste und billigste Methode und die zweite - "wissenschaftliche" Methode, wenn Sie Daten von "Experten" (Personen,) sammeln. (Ich teste Ihren ähnlichen Suchalgorithmus) und basierend auf diesen Daten ein Testmuster und einen Katalog speziell für die Suche nach ähnlichen Bildern bilden. Diese Methode ist theoretisch gut und sieht ziemlich überzeugend aus (für Sie selbst und für Kunden), aber in der Praxis ist ihre Implementierung schwierig und ziemlich teuer.
Fazit und Weiterentwicklungspläne
Diese Technologie ist ziemlich fertig und einsatzbereit. Jetzt arbeitet sie bei einem unserer Kunden im Online-Shop als Empfehlungsservice. Außerdem haben wir kürzlich begonnen, ein ähnliches System in einer anderen Branche zu entwickeln (das heißt, wir arbeiten jetzt mit anderen Arten von Waren).
Aus sofortigen Plänen: die Übertragung des Netzwerks an Mask-CNN sowie das erneute Markieren und Markieren von Bildern, um die Qualität des Detektors und des Klassifikators zu verbessern.
Abschließend möchte ich sagen, dass nach unseren Gefühlen eine ähnliche Technologie und im Allgemeinen neuronale Netze bis zu 80% der komplexen und hochintellektuellen Aufgaben lösen können, die unser Gehirn täglich erfüllt. Die Frage ist nur, wer als erster eine solche Technologie implementiert und einen Menschen von der Routinearbeit entlastet, um ihm Raum für Kreativität und Entwicklung zu geben, was unserer Meinung nach der höchste Zweck des Menschen ist!
Referenzliste