
Guten Tag.
In der Praxis stoßen Sie häufig auf Aufgaben, die weit von komplexen ML-Algorithmen entfernt sind, aber gleichzeitig nicht weniger wichtig und dringend für das Unternehmen sind.
Reden wir über einen von ihnen.
Die Aufgabe besteht darin, die Daten einer Zieltabelle mit Aggregaten (Aggregatwerten) auf einer Tabelle mit detaillierterer Granularität zu verteilen (Sägen, Rasplitovat - der Jargon des Geschäfts ist unerschöpflich).
Zum Beispiel muss die Handelsabteilung den auf Markenebene vereinbarten Jahresplan aufschlüsseln - im Detail zu den Produkten, damit Vermarkter das jährliche Marketingbudget nach Ländern aufschlüsseln können, die Planungs- und Wirtschaftsabteilung die allgemeinen Geschäftskosten nach Finanzverantwortungszentren aufschlüsseln usw. usw.
Wenn Sie das Gefühl haben, dass solche Aufgaben bereits am Horizont vor Ihnen stehen oder bereits diejenigen behandeln, die unter solchen Aufgaben gelitten haben, dann bitte ich um eine Katze.
Betrachten Sie ein reales Beispiel:
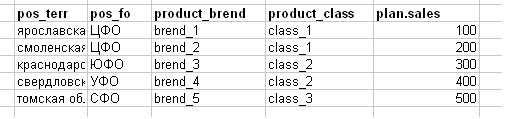
Sie senken den Verkaufsplan als Aufgabe wie im Bild unten (ich habe das Beispiel in der Realität absichtlich vereinfacht - ein Excel-Banner mit 100 bis 200 MB).
Überschriftenerklärung:
- pos_terr-Gebiet (Region) der Steckdose
- pos_fo - der Bundesbezirk des Outlets (zum Beispiel der Central Federal District-Central Federal District)
- product_brend - Produktmarke
- product_class - Produktklasse
- plan.sales ist ein Verkaufsplan für alles.
Und sie bitten zum Beispiel, ihren Mega-Tisch zu brechen (im Rahmen unseres Kinderbeispiels ist es natürlich bescheidener) - zum Vertriebskanal. Auf die Frage - nach welcher Logik zu trennen, bekomme ich die Antwort: "Aber nehmen Sie die Statistik der tatsächlichen Verkäufe für das 4. Quartal dieses und jenes Jahres, erhalten Sie die tatsächlichen Anteile der Kanäle in% für jede Zeile des Plans und dividieren Sie durch diese Teile der Planzeile."
In der Tat ist dies die häufigste Antwort bei solchen Aufgaben ...
Bisher scheint alles einfach genug zu sein.
Ich verstehe diese Tatsache (siehe Bild unten):
- pos_channell - Vertriebskanal (Zielattribut für den Plan)
- fact.sales - tatsächlicher Verkauf von etwas.
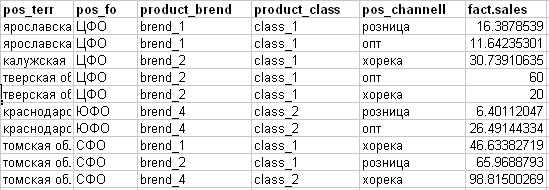
Basierend auf dem erhaltenen Ansatz zum "Sägen" am Beispiel der ersten Zeile des Plans werden wir ihn auf der Grundlage der folgenden Tatsache aufschlüsseln:

Wenn wir jedoch die Tatsache mit dem Plan für die gesamte Platte vergleichen, um zu verstehen, ob alle Linien des Plans in Anteilen angemessen „geschnitten“ werden können, erhalten wir das folgende Bild: (grün - alle Attribute der Planlinie stimmten mit der Tatsache überein, dass gelbe Zellen nicht übereinstimmten).
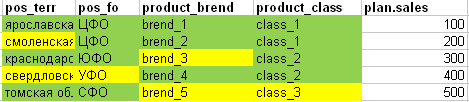
- In der ersten Zeile des Plans befinden sich alle Felder vollständig in der Tatsache.
- In der 2. Zeile des Plans wurde das entsprechende Gebiet tatsächlich nicht gefunden
- Die 3. Zeile des Plans reicht aufgrund der Marke nicht aus
- Die 4. Zeile des Plans reicht in Bezug auf das Territorium und den Bundesbezirk nicht aus
- In der 5. Zeile des Plans fehlen tatsächlich die Marke und die Klasse.
Wie Panikovsky sagte: "Sah die Shura, sah - sie sind Gold ..."

Ich gehe zum Geschäftskunden und kläre am Beispiel der 2. Zeile, welchen Ansatz er für solche Situationen sieht.
Ich bekomme die Antwort: „In Fällen, in denen es nicht möglich ist, den Anteil der Kanäle für Marke Nr. 2 in der Region Smolensk zu berechnen (unter Berücksichtigung der Tatsache, dass wir die Region Smolensk im zentralen Bundesbezirk-zentralen Bundesbezirk haben) - dann brechen Sie diese Linie entsprechend der Struktur der Kanäle im gesamten zentralen Bundesbezirk!“
Das heißt, für {Region Smolensk + Marke_2} aggregieren wir die Tatsache auf der Ebene des Bundesdistrikts und teilen die Region Smolensk wie folgt auf:

Ich gehe zurück und verdaue, was ich gehört habe, und versuche, es auf eine universellere Heuristik zu verallgemeinern:
Wenn auf der aktuellen Detailebene der Faktentabelle keine Daten vorhanden sind, aggregieren wir vor der Berechnung der Anteile für das Zielfeld (Vertriebskanal) die Faktentabelle bis zum obigen Hierarchieattribut.
Das heißt, wenn nicht für das Gebiet, dann aggregieren wir die Tatsache auf eine höhere Hierarchieebene - Anteile für denselben zentralen Bundesdistrikt wie im Plan. Wenn nicht für die Marke, dann gibt es in der obigen Hierarchie eine Produktklasse - dementsprechend zählen wir die Anteile für dieselbe Klasse und so weiter.
Das heißt, Wir kombinieren den Plan und die Tatsache auf den Kopplungsfeldern, für die wir die Anteile an der Tatsache berücksichtigen, und reduzieren bei jeder Iteration gemäß dem verbleibenden nicht verteilten Plan sukzessive die Zusammensetzung der Kopplungsfelder.
Hier zeichnet sich bereits ein bestimmtes Datenverteilungsmuster ab:
- Wir verteilen den Plan tatsächlich auf der Grundlage der vollständigen Übereinstimmung der entsprechenden Felder
- Wir erhalten einen kaputten Plan (wir akkumulieren ihn im Zwischenergebnis) und einen ungebrochenen Plan (nicht alle Zeilen stimmen überein).
- Wir nehmen einen ungebrochenen Plan und teilen ihn tatsächlich auf eine höhere Hierarchieebene auf (d. H. Wir geben ein bestimmtes Kopplungsfeld dieser beiden Tabellen auf und aggregieren die Tatsache ohne dieses Feld, um die Anteile zu berechnen).
- Wir erhalten einen fehlerhaften Plan (wir fügen ihn dem Zwischenergebnis hinzu) und einen ungebrochenen Plan (nicht alle Zeilen stimmen überein).
- Und wir wiederholen die gleichen Schritte, bis es keinen „ungelösten“ Plan mehr gibt.
Im Allgemeinen verpflichtet uns niemand, Hitch-Felder nur innerhalb der Hierarchie konsequent zu entfernen. Zum Beispiel haben wir die Marke und das Gebiet bereits aus den Hitch-Feldern entfernt und den verbleibenden Plan verteilt nach: product_class (Hierarchie über der Marke) + Fed.krug (Hierarchie über dem Gebiet). Und immer noch ein nicht zugewiesenes Gleichgewicht des Plans.
Ferner können wir aus den Kopplungsfeldern entweder die Produktklasse oder den Bundesbezirk als entfernen Sie sind nicht mehr in die Hierarchie des anderen eingebettet.
Wenn man bedenkt, dass solche Tabellen Dutzende und Reihen von Feldern enthalten - bis zu einer Million, die solche Manipulationen mit den Händen ausführen -, ist die Aufgabe nicht die angenehmste.
Und da mir solche Aufgaben am Ende eines jeden Jahres regelmäßig einfallen (Genehmigung der Budgets für das nächste Jahr im Verwaltungsrat), mussten Sie diesen Prozess in eine Art flexible universelle Vorlage übersetzen.
Und da ich die meiste Zeit mit Daten über R arbeite, ist die Implementierung entsprechend gleich.
Zuerst müssen wir eine universelle magische Funktion schreiben, die eine Basistabelle (Basetab) mit Daten für eine Aufschlüsselung (in unserem Beispiel einen Plan) und eine Tabelle zur Berechnung von Anteilen (Sharetab) verwendet, auf deren Grundlage wir die Daten "sehen" (in unserem Beispiel) Tatsache). Die Funktion muss jedoch auch verstehen, was mit diesen Objekten zu tun ist, damit die Funktion auch den Vektor der Namen der Kopplungsfelder (merge.vrs) akzeptiert - d. H. Diese Felder, die in beiden Tabellen identisch benannt sind und es uns ermöglichen, eine Tabelle mit den anderen Feldern zu verbinden, in denen sie funktioniert (d. h. Rechtsverknüpfung). Außerdem sollte die Funktion verstehen, welche Spalte der Basistabelle in die Verteilung aufgenommen werden soll (basetab.value) und basierend auf welchem Feld die Anteile gezählt werden sollen (sharetab.value). Nun, und vor allem - was für das resultierende Feld (sharetab.targetvars) zu beachten ist, in unserem Fall möchten wir den Plan über den Vertriebskanal anhand der Tatsache detaillieren.
Übrigens ist diese Variable sharetab.targetvars in meinem Plural nicht zufällig - es kann sich nicht um ein Feld, sondern um einen Vektor von Feldnamen handeln, wenn Sie der Basistabelle nicht ein Feld aus der Freigabetabelle hinzufügen müssen, sondern mehrere gleichzeitig (z. B. können Sie den Plan aufgrund der Tatsache nicht aufteilen nur über den Vertriebskanal, aber auch über den Namen der in der Marke enthaltenen Produkte).
Ja, und noch eine Bedingung :) Meine Funktion sollte so lokalistisch und lesbar wie möglich sein, ohne mehrstöckiges Gebäude auf 2 Bildschirmen (ich mag große Funktionen wirklich nicht).
In der letzten Bedingung passte das beliebte dplyr-Paket so bequem wie möglich, und da die Pipeline-Betreiber die Textnamen der Felder verstehen müssen, die in die Funktion abgesenkt wurden, war die
Standart-Bewertung nicht ohne.
Hier ist dieses Baby (ohne interne Kommentare):
fn_distr <- function(sharetab, sharetab.value, sharetab.targetvars, basetab, basetab.value, merge.vrs,level.txt=NA) { # sharetab - = # sharetab.value - - # sharetab.targetvars - - # basetab - = # basetab.value - # merge.vrs - 2- # level.txt - . ( merge.vrs) require(dplyr) sharetab.value <- as.name(sharetab.value) basetab.value <- as.name(basetab.value) if(is.na(level.txt )){level.txt <- paste0(merge.vrs,collapse = ",")} result <- sharetab %>% group_by(.dots = c(merge.vrs, sharetab.targetvars)) %>% summarise(sharetab.sum = sum(!!sharetab.value)) %>% ungroup %>% group_by(.dots = merge.vrs) %>% mutate(sharetab.share = sharetab.sum / sum(sharetab.sum)) %>% ungroup %>% right_join(y = basetab, by = merge.vrs) %>% mutate(distributed.result = !!basetab.value * sharetab.share, level = level.txt) %>% select(-sharetab.sum,-sharetab.share) return(result) }
Bei der Ausgabe sollte die Funktion data.frame der Vereinigung zweier Tabellen mit den Zeilen des Plans + fact zurückgeben, in denen der Plan in der aktuellen Version der Kopplungsfelder aufgeteilt werden konnte, und mit den ursprünglichen Zeilen des Plans (und der leeren Tatsache) in den Zeilen, in denen der Plan in der aktuellen Iteration nicht aufgeteilt werden konnte.
Das heißt, das Ergebnis, das von der Funktion nach der ersten Iteration zurückgegeben wird (wobei die erste Zeile des Plans für die Region Jaroslawl unterbrochen wird), sieht folgendermaßen aus:
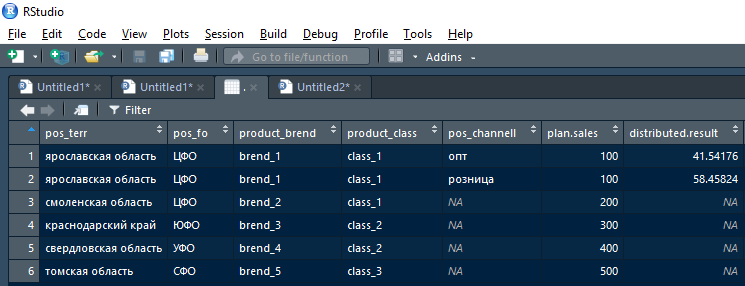
Ferner kann dieses Ergebnis durch nicht leeres verteiltes Ergebnis in das kumulative Ergebnis und durch leeres (NA) verteiltes Ergebnis übernommen werden - an die nächste typische Iteration senden, jedoch nach Freigaben auf einer höheren Hierarchieebene unterteilt.
Der ganze Reiz und die Bequemlichkeit besteht darin, dass die Arbeit in derselben Art von Blöcken und einer universellen Funktion ausgeführt wird. Bei jedem Schritt (Iteration) muss lediglich der Vektor merge.vrs korrigiert und beobachtet werden, wie die Magie all diese mühsame Arbeit für Sie erledigt:

Ja, ich habe fast eine kleine Nuance vergessen: Wenn etwas schief geht und wir am Ende einen kaputten Plan erhalten, der insgesamt nicht dem Plan vor dem Zusammenbruch entspricht, wird es schwierig sein zu verfolgen, bei welcher Iteration alles schief gelaufen ist.
Daher liefern wir jeder Iteration eine Prüfsumme:
(_)-(___ )-(___.)=0
Versuchen wir nun, unser Beispiel durch die Verteilungsvorlage zu führen und zu sehen, was wir an der Ausgabe erhalten.
Holen Sie sich zuerst die Quelldaten:
library(dplyr) plan <- data_frame(pos_terr = c(" ", " ", " ", " ", " "), pos_fo = c("", "", "", "", ""), product_brend = c("brend_1", "brend_2", "brend_3", "brend_4", "brend_5"), product_class = c("class_1", "class_1", "class_2", "class_2", "class_3"), plan.sales = c(100, 200, 300, 400, 500)) fact <- data_frame(pos_terr = c(" ", " ", " ", " ", " "," ", " ", " ", " ", " "), pos_fo = c("", "","","", "", "", "", "", "", ""), product_brend = c("brend_1", "brend_1", "brend_2", "brend_2","brend_2", "brend_4", "brend_4", "brend_1", "brend_2", "brend_4"), product_class = c("class_1", "class_1", "class_1","class_1","class_1", "class_2", "class_2", "class_1", "class_1", "class_2"), pos_channell = c("", "", "","", "", "", "", "", "", ""), fact.sales = c(16.38, 11.64, 30.73,60, 20, 6.40, 26.49, 46.63, 65.96, 98.81)) </soure> ( ) . <source> plan.remain <- plan result.total <- data_frame()
1. Wir vertreiben nach Terr, FD (Bundesdistrikt), Marke, Klasse merge.fields <- c("pos_terr","pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) # - plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) # = cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 2. Wir vertreiben nach Pho, Marke, Klasse (das heißt, wir verlassen das Gebiet tatsächlich)
2. Wir vertreiben nach Pho, Marke, Klasse (das heißt, wir verlassen das Gebiet tatsächlich)Der einzige Unterschied zum ersten Block besteht darin, dass sie merge.fields leicht verkürzen, indem sie pos_terr darin entfernen
merge.fields <- c("pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
3. Verteilen Sie nach Pho, Klasse merge.fields <- c("pos_fo", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
4. Nach Klasse verteilen merge.fields <- c( "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 5. Verteilen Sie durch FD
5. Verteilen Sie durch FD merge.fields <- c( "pos_fo") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
Wie Sie sehen können, gibt es keinen "nicht gesägten" Plan mehr und die Arithmetik des verteilten Plans entspricht der ursprünglichen.

Und hier ist das Ergebnis mit Vertriebskanälen (in der rechten Spalte zeigt die Funktion an, für welche Felder die Kopplung / Aggregation bestimmt war, damit wir später verstehen können, woher diese Verteilung stammt):

Das ist alles Der Artikel war nicht sehr klein, aber es gibt mehr erklärenden Text als den Code selbst.
Ich hoffe, dieser flexible Ansatz spart nicht nur mir Zeit und Nerven :-)
Vielen Dank für Ihre Aufmerksamkeit.