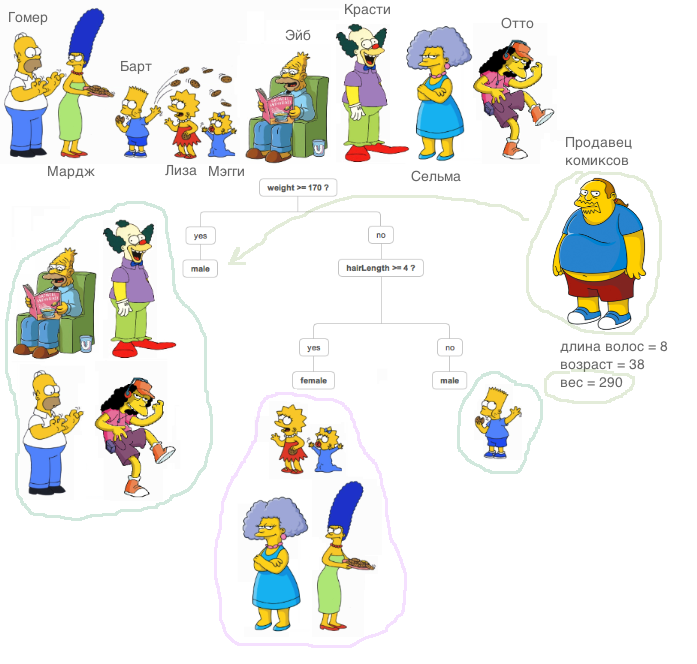
Hallo Habr!
Nach zahlreichen Suchen nach hochwertigen Anleitungen zu Entscheidungsbäumen und Ensemble-Algorithmen (Boosten, Entscheidungswald usw.) mit ihrer direkten Implementierung in Programmiersprachen und ohne etwas zu finden (wer es findet, schreibe in die Kommentare, vielleicht lerne ich etwas Neues), Ich beschloss, meine eigene Führung zu übernehmen, wie ich es gerne sehen würde. Die Aufgabe in Worten ist einfach, aber wie Sie wissen, steckt der Teufel im Detail, von dem es viele Algorithmen mit Bäumen gibt.
Da das Thema ziemlich umfangreich ist, wird es sehr schwierig sein, alles in einen Artikel zu packen. Daher wird es zwei Veröffentlichungen geben: Die erste ist Bäumen gewidmet, und der zweite Teil ist der Implementierung des Gradientenverstärkungsalgorithmus gewidmet. Das gesamte hier vorgestellte Material wurde basierend auf Open Source, meinem Code, dem Code von Kollegen und Freunden zusammengestellt und gestaltet. Ich warne Sie sofort, es wird viel Code geben.
Was müssen Sie also wissen und lernen können, wie Sie Ihre eigenen Ensemble-Algorithmen mit Entscheidungsbäumen von Grund auf neu schreiben? Da ein Ensemble von Algorithmen nichts anderes als eine Zusammensetzung von „schwachen Algorithmen“ ist, erfordert das Schreiben eines guten Ensembles gute „schwache Algorithmen“. Wir werden sie in diesem Artikel ausführlich analysieren. Wie der Name schon sagt, handelt es sich hierbei um wichtige Bäume. Wenn wir von einfach zu komplex wechseln, lernen wir, wie man sie schreibt. In diesem Fall wird der Schwerpunkt direkt auf die Implementierung gelegt, die gesamte Theorie wird in einem Minimum dargestellt, im Grunde werde ich Links zu Materialien für unabhängige Studien geben.
Um das Material zu lernen, müssen Sie verstehen, wie gut oder schlecht unser Algorithmus ist. Wir werden sehr einfach verstehen - wir werden einen bestimmten Datensatz reparieren und unsere Algorithmen mit den Algorithmen von Bäumen von Sklearn vergleichen (nun, was würde ohne diese Bibliothek passieren). Wir werden viel vergleichen: die Komplexität des Algorithmus, Metriken für Daten, Betriebszeit usw.
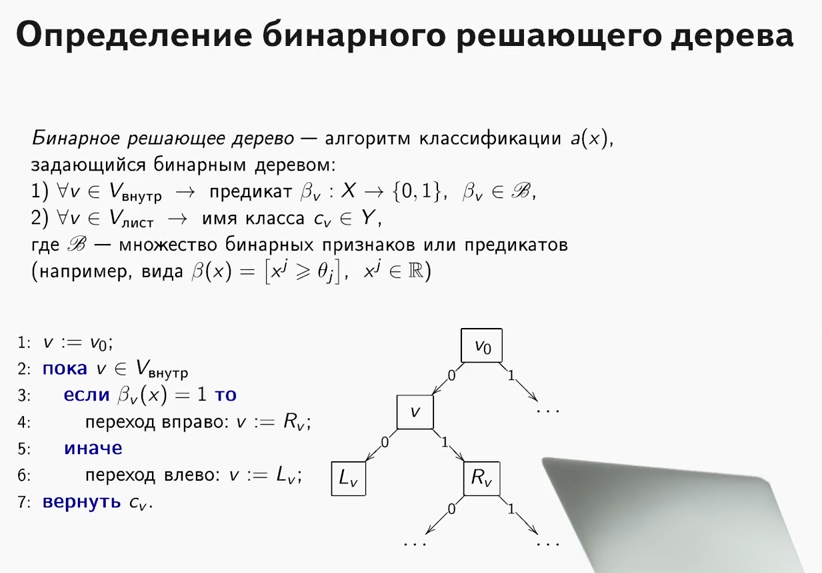
Was ist ein entscheidender Baum? Ein sehr gutes Material, das das Prinzip des Entscheidungsbaums erklärt, ist
im ODS-Kurs enthalten (übrigens ein cooler Kurs, den ich allen empfehlen kann, die mit ML vertraut sind).
Eine sehr wichtige Erklärung: In allen unten beschriebenen Fällen sind alle Vorzeichen real, wir führen keine speziellen Transformationen mit Daten außerhalb der Algorithmen durch (wir vergleichen Algorithmen, keine Datensätze).
Lassen Sie uns nun lernen, wie Sie das Problem der Regression mithilfe von Entscheidungsbäumen lösen. Wir werden die
MSE- Metrik als Entropie verwenden.
Wir implementieren eine sehr einfache
RegressionTree Klasse, die auf einem rekursiven Ansatz basiert. Absichtlich beginnen wir mit einer sehr ineffektiven, aber leicht verständlichen Implementierung dieser Klasse, damit wir sie in Zukunft verbessern können.
1. RegressionTree () -Klasse
class RegressionTree(): ''' RegressionTree . , . ''' def __init__(self, max_depth=3, n_epoch=10, min_size=8): ''' . ''' self.max_depth = max_depth
Ich werde hier kurz erklären, was jede Methode tut.
Die
fit lehrt, wie der Name schon sagt, das Modell. Ein Trainingsmuster wird auf die Eingabe angewendet und ein Baumtrainingsverfahren findet statt. Wenn wir die Zeichen
mse , suchen wir nach der besten Partition des Baums, um die Entropie zu reduzieren, in diesem Fall
mse . Es ist sehr einfach festzustellen, dass es möglich war, eine gute Aufteilung zu finden. Es reicht aus, zwei Bedingungen zu erfüllen. Wir möchten nicht, dass wenige Objekte in die Partition fallen (Schutz vor Umschulung), und der durchschnittliche Fehler für
mse sollte geringer sein als der Fehler, der jetzt im Baum vorhanden ist. Wir suchen nach dem gleichen Gewinn an
Informationsgewinn . Nachdem wir alle Zeichen und alle eindeutigen Werte auf diese Weise durchlaufen haben, werden wir alle Optionen durchgehen und die beste Partition auswählen. Und dann rufen wir die empfangenen Partitionen rekursiv auf, bis die Bedingungen zum Verlassen der Rekursion erfüllt sind.
Die
__predict Methode erstellt, wie der Name schon sagt, ein Prädikat. Nachdem ein Objekt als Eingabe empfangen wurde, durchläuft es die Knoten des resultierenden Baums. In jedem Knoten sind die Attributnummer und der Wert festgelegt. Je nachdem, welchen Wert die eingehende Methode des Objekts für dieses Attribut verwendet, gehen wir entweder zum rechten Nachkommen oder nach links. bis wir zu dem Blatt kommen, in dem es eine Antwort für dieses Objekt gibt.
Die
predict macht dasselbe wie die vorherige Methode, nur für eine Gruppe von Objekten.
Wir importieren den bekannten kalifornischen Heimdatensatz. Dies ist ein regulärer Datensatz mit Daten und einem Ziel zur Lösung des Regressionsproblems.
data = datasets.fetch_california_housing() X = np.array(data.data) y = np.array(data.target)
Beginnen wir mit dem Vergleich! Lassen Sie uns zunächst sehen, wie schnell der Algorithmus lernt. Wir setzen in Sklearn und uns den einzigen Parameter
max_depth , lassen Sie ihn gleich 2 sein.
%%time A = RegressionTree(2)
from sklearn.tree import DecisionTreeRegressor %%time model = DecisionTreeRegressor(max_depth=2)
Folgendes wird angezeigt:
- Für unseren Algorithmus - CPU-Zeiten: Benutzer 4 Minuten 47 Sekunden, System: 8,25 ms, Gesamt: 4 Minuten 47 Sekunden
Wandzeit: 4min 47s - Für Sklearn - CPU-Zeiten: Benutzer 53,5 ms, System: 0 ns, Gesamt: 53,5 ms
Wandzeit: 53,4 ms
Wie Sie sehen können, lernt der Algorithmus tausende Male langsamer. Was ist der Grund? Lass es uns richtig machen.
Erinnern Sie sich daran, wie das Verfahren zum Finden der besten Partition angeordnet ist. Wie Sie wissen, im allgemeinen Fall mit der Größe von Objekten
N und mit der Anzahl der Zeichen
d ist die Schwierigkeit, die beste Aufteilung zu finden
O(N∗logN∗d) .
Woher kommt diese Komplexität?
Um den Fehler effizient neu zu berechnen, müssen zunächst alle Spalten sortiert werden, um vor dem Übergeben des Features vom kleinsten zum größten zu wechseln. Wenn wir dies für jedes Merkmal tun, entsteht eine entsprechende Komplexität. Wie Sie sehen können, sortieren wir die Vorzeichen, aber das Problem liegt in der Neuberechnung des Fehlers - jedes Mal, wenn wir die Daten in die
mse Methode
mse , die für die Zeile funktioniert. Dies macht die Fehlerzählung so ineffizient! Immerhin steigt dann die Schwierigkeit, einen Split zu finden, auf
O(N2∗d) für große
N verlangsamt den Algorithmus enorm. Daher fahren wir reibungslos mit dem nächsten Punkt fort.
2. RegressionTree () -Klasse mit schneller Fehlerzählung
Was muss getan werden, um den Fehler schnell wiederzugeben? Nehmen Sie einen Stift und Papier und malen Sie, wie wir die Formeln ändern sollen.
Angenommen, irgendwann wird bereits ein Fehler berechnet
N Objekte. Es hat die folgende Formel:
sumni=1(yi− frac sumNi=1yiN)2 . Hier ist es notwendig, durch zu teilen
N aber jetzt lassen wir es weg. Wir wollen diesen Fehler schnell bekommen -
sumN−1i=1(yi− frac sumN−1i=1yiN−1)2 Das heißt, werfen Sie den Fehler, den das Element einführt
yi zu einem anderen Teil.
Da wir das Objekt werfen, muss der Fehler an zwei Stellen nachgezählt werden - auf der rechten Seite (ohne dieses Objekt) und auf der linken Seite (unter Berücksichtigung dieses Objekts). Aber ohne Verlust der Allgemeinheit werden wir nur eine Formel ableiten, da sie ähnlich sein werden.
Da wir mit
mse , hatten wir
mse Glück: Es ist ziemlich schwierig, eine schnelle Nachzählung eines Fehlers abzuleiten, aber wenn wir mit anderen Metriken arbeiten (z. B. dem Gini-Kriterium, wenn wir das Klassifizierungsproblem lösen), ist eine schnelle Nachzählung viel einfacher.
Nun, lasst uns anfangen, Formeln abzuleiten!
sumNi=1(yi− frac sumNi=1yiN)2= sumN−1i=1(yi− frac sumNi=1yiN)2+(yN− frac sumNi=1yiN)2
Wir werden das erste Mitglied schreiben:
sumN−1i=1(yi− frac sumNi=1yiN)2= sumN−1i=1(yi− frac sumN−1i=1yi+yNN)2= sumN−1i=1( fracNyi− sumN−1i=1yiN− fracyNN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN− fracyN−yiN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN)2−2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN+( fracyN−yiN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN−( fracyN−yiN)2)= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN−1)2∗( fracN−1N)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN−−( fracyN−yiN)2)
Ugh, nur noch ein bisschen übrig. Es bleibt nur der erforderliche Betrag auszudrücken.
sumNi=1(yi− frac sumNi=1yiN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN−1)2∗( fracN−1N)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN)( fracyN−yiN)−( fracyN−yiN)2)+(yN− sumNi=1 fracyiN)2
Und dann ist klar, wie der gewünschte Betrag ausgedrückt werden soll. Um den Fehler neu zu berechnen, müssen wir nur die Summe der Elemente rechts und links sowie das neue Element selbst speichern, das am Eingang angekommen ist. Jetzt wird der Fehler nachgezählt
O(1) .
Nun, lassen Sie uns dies in Code implementieren.
class RegressionTreeFastMse(): ''' RegressionTree . O(1). '''
Lassen Sie uns die Zeit messen, die jetzt für das Training aufgewendet wird, und mit dem Analogon von Sklearn vergleichen.
%%time A = RegressionTreeFastMse(4, min_size=5) A.fit(X,y) test_mytree = A.predict(X) test_mytree
%%time model = DecisionTreeRegressor(max_depth=4) model.fit(X,y) test_sklearn = model.predict(X)
- Für unseren Algorithmus erhalten wir - CPU-Zeiten: Benutzer 3,11 s, System: 2,7 ms, Gesamt: 3,11 s
Wandzeit: 3,11 s. - Für den Algorithmus von Sklearn - CPU-Zeiten: Benutzer 45,9 ms, System: 1,09 ms, Gesamt: 47 ms
Wandzeit: 45,7 ms.
Die Ergebnisse sind bereits angenehmer. Lassen Sie uns den Algorithmus weiter verbessern.
3. RegressionTree () -Klasse mit linearen Kombinationen von Merkmalen
In unserem Algorithmus werden die Beziehungen zwischen den Attributen in keiner Weise verwendet. Wir korrigieren ein Merkmal und betrachten nur orthogonale Raumpartitionen. Wie lerne ich, die linearen Beziehungen zwischen den Attributen zu verwenden? Das heißt, nach den besten Partitionen zu suchen, ist nicht so
afeat<x und
sumKi=1bi∗ai<x wo
K - Ist eine Zahl kleiner als die Dimension unseres Raumes?
Es gibt viele Möglichkeiten, ich werde zwei der aus meiner Sicht interessantesten hervorheben. Beide Ansätze sind im
Buch Friedman beschrieben (er hat diese Bäume erfunden).
Ich werde ein Bild geben, damit klar ist, was gemeint ist:

Zunächst können Sie versuchen, diese linearen Partitionen algorithmisch zu finden. Es ist klar, dass es unmöglich ist, alle linearen Kombinationen zu sortieren, da es unendlich viele Kombinationen gibt. Daher sollte ein solcher Algorithmus gierig sein, dh bei jeder Iteration das Ergebnis der vorherigen Iteration verbessern. Die Hauptidee dieses Algorithmus kann im Buch gelesen werden. Ich werde hier auch einen Link zum
Repository meines Freundes und Kollegen mit der Implementierung dieses Algorithmus hinterlassen.
Zweitens, wenn wir nicht weit von der Idee entfernt sind, die beste orthogonale Partition zu finden, wie ändern wir dann den Datensatz, sodass Informationen über die Beziehung von Merkmalen verwendet werden und die Suche auf orthogonalen Partitionen basiert? Das ist richtig, um die ursprünglichen Funktionen in neue umzuwandeln. Sie können beispielsweise die Summe einer Kombination von Features verwenden und bereits nach Partitionen suchen. Eine solche Methode passt schlechter in das algorithmische Konzept, erfüllt aber ihre Aufgabe - sie sucht nach orthogonalen Partitionen, die sich bereits in einer Art Verbindung von Attributen befinden.
Nun, lassen Sie es uns implementieren - wir werden als neue Features beispielsweise alle Arten von Kombinationen von Feature-Summen hinzufügen
i,j wo
I<j . Ich stelle fest, dass die Komplexität des Algorithmus in diesem Fall zunehmen wird, es ist klar, wie oft. Um schneller zu sein, werden wir Cython verwenden.
%load_ext Cython %%cython -a import itertools import numpy as np cimport numpy as np from itertools import * cdef class RegressionTreeCython: cdef public int max_depth cdef public int feature_idx cdef public int min_size cdef public int averages cdef public np.float64_t feature_threshold cdef public np.float64_t value cpdef RegressionTreeCython left cpdef RegressionTreeCython right def __init__(self, max_depth=3, min_size=4, averages=1): self.max_depth = max_depth self.min_size = min_size self.value = 0 self.averages = averages self.feature_idx = -1 self.feature_threshold = 0 self.left = None self.right = None def data_transform(self, np.ndarray[np.float64_t, ndim=2] X, list index_tuples):
4. Vergleich der Ergebnisse
Vergleichen wir die Ergebnisse. Wir werden drei Algorithmen mit denselben Parametern vergleichen - einen Baum von Sklearn, unseren gewöhnlichen Baum und unseren Baum mit neuen Funktionen. Wir werden unseren Datensatz viele Male in Trainings- und Testsätze unterteilen und den Fehler berechnen.
from sklearn.model_selection import KFold def get_metrics(X,y,n_folds=2, model=None): kf = KFold(n_splits=n_folds, shuffle=True) kf.get_n_splits(X) er_list = [] for train_index, test_index in kf.split(X): X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] model.fit(X_train,y_train) predict = model.predict(X_test) er_list.append(mse(y_test, predict)) return er_list
Lassen Sie uns nun alle Algorithmen ausführen.
import matplotlib.pyplot as plt data = datasets.fetch_california_housing() X = np.array(data.data) y = np.array(data.target) er_sklearn_tree = get_metrics(X,y,30,DecisionTreeRegressor(max_depth=4, min_samples_leaf=10)) er_fast_mse_tree = get_metrics(X,y,30,RegressionTreeFastMse(4, min_size=10)) er_averages_tree = get_metrics(X,y,30,RegressionTreeCython(4, min_size=10)) %matplotlib inline data = [er_sklearn_tree, er_fast_mse_tree, er_averages_tree] fig7, ax7 = plt.subplots() ax7.set_title('') ax7.boxplot(data, labels=['Sklearn Tree', 'Fast Mse Tree', 'Averages Tree']) plt.grid() plt.show()
Ergebnisse:

Unser regulärer Baum ging an Sklearn verloren (was verständlich ist: Sklearn ist gut optimiert und standardmäßig gibt es noch viele Parameter im Baum, die wir nicht berücksichtigen), aber wenn wir Beträge hinzufügen, wird das Ergebnis angenehmer.
Zusammenfassend: Wir haben gelernt, entscheidende Bäume von Grund auf neu zu schreiben, ihre Leistung zu verbessern und ihre Wirksamkeit an realen Datensätzen zu testen, indem wir sie mit dem Algorithmus von Sklearn verglichen haben. Die hier vorgestellten Methoden schränken jedoch die Verbesserung der Algorithmen nicht ein. Beachten Sie daher, dass der vorgeschlagene Code noch besser gemacht werden kann. Im nächsten Artikel werden wir Boosting basierend auf diesen Algorithmen schreiben.
Alles Erfolg!