Services müssen so geschrieben werden, dass immer nur minimale Funktionen erhalten bleiben - auch wenn kritische Komponenten ausfallen. Ilya Sidorov, der Leiter eines der Produktentwicklungsteams des Yandex.Taxi-Backends, erklärte in seinem Bericht, wie wir den Benutzer ein Auto bestellen lassen, wenn bestimmte Teile des Systems nicht funktionieren, und mit welcher Logik wir die vereinfachten Versionen des Dienstes aktivieren.
Es ist wichtig, nicht nur Dienste zu schreiben, die gut funktionieren, sondern auch Dienste, die gut funktionieren.
"Ich bin sehr froh, euch alle zu sehen." Heute werde ich über anmutige Erniedrigung sprechen. Wenn Sie in Yandex danach suchen, werden Sie höchstwahrscheinlich lernen, wie Sie Ihre Site ohne JS zum Laufen bringen. Ich erzähle dir etwas über etwas anderes. Über anmutige Verschlechterung in Bezug auf das Backend.

Beginnen wir mit der Definition. Wie sieht es in der Realität aus?
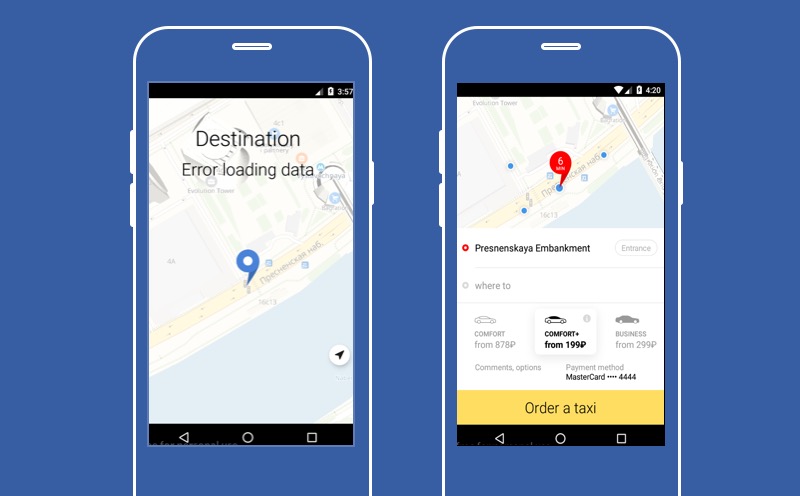
Hier wird unsere Yandex.Taxi-Anwendung vorgestellt, falls einer der Dienste nicht funktioniert - der Dienst zur Auswahl des Ziels, an das der Fahrer Sie bringen soll. Wie Sie sehen können, gibt es auf diesem Bildschirm keine große Schaltfläche „Taxi bestellen“, was bedeutet, dass der Benutzer den Dienst nicht nutzen kann. Sie können jedoch versuchen, Punkt B zu verschlechtern und dem Benutzer zu erlauben, Punkt B nicht zu wählen.
Dann kann er den genauen Preis der Reise nicht herausfinden, wir können keine Route erstellen, aber der Benutzer hat einen Button „Taxi bestellen“ und kann unseren Service nutzen. Die Hauptfunktion unserer Anwendung wird verfügbar sein. Darüber möchte ich heute sprechen. Informationen darüber, wie Sie sich ordnungsgemäß verschlechtern und was mit einem defekten Dienst getan werden kann.
Leistungsplan. Ich werde Ihnen sagen, wie Sie die Vorgehensweise mit dem Service verschlechtern können. Sie können es deaktivieren und auch ein anderes Verhalten verwenden. Dann erkläre ich Ihnen, wie Sie verstehen, wann es Zeit ist, unseren Service auszuschalten. Und am Ende werde ich über einige Nuancen sprechen, denen wir uns stellen mussten, als wir ein automatisches Degradationssystem für Yandex.Taxi entwickelten.
Was kann mit einem defekten Dienst getan werden? Sie können die Funktionalität deaktivieren. Wenn der Dienst zur Vorhersage einzelner Ziele nicht funktioniert, deaktivieren Sie diesen Dienst. Wenn der Chat zwischen Fahrer und Beifahrer nicht funktioniert, schalten Sie den Chat aus. Wenn Sie kein Auto bestellen können, deaktivieren Sie die Schaltfläche "Auto bestellen" - oh nein, das funktioniert nicht. Nicht alle Funktionen können deaktiviert werden. Und wenn Sie etwas nicht ausschalten können, müssen Sie einen anderen Ansatz verwenden. Sie können beispielsweise versuchen, ein Layout oder eine vereinfachte Funktionalität zu erstellen. Wir nennen ein so vereinfachtes Verhalten in Yandex einen Kürbis - wir sagen, dass der Service zu einem Kürbis geworden ist.
Lassen Sie uns diese Lösungen genauer betrachten.
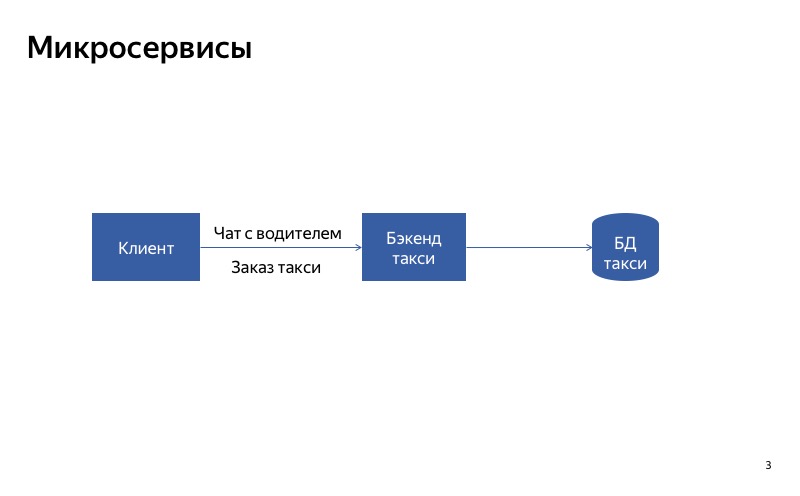
Wie deaktiviere ich Dienste? Sie können wahrscheinlich die richtige Architektur erstellen. Angenommen, wir haben einen monolithischen Dienst. Wenn eines seiner Teile ausfällt, wird der gesamte Service unterbrochen. Wenn wir den Service jedoch in Teile aufteilen, sodass Kunden unterschiedliche Services für unterschiedliche Anforderungen verwenden, wird er viel besser.
Wie wird das an einem Beispiel funktionieren? Es gibt einen Yandex.Taxi-Service, bei dem es zwei Hauptfunktionen gibt: ein Taxi bestellen und mit dem Fahrer chatten. Solange wir ein monolithisches Backend haben und der Chat mit dem Fahrer fehlschlägt, wird die grundlegende Funktionalität der Bestellung eines Taxis beeinträchtigt.
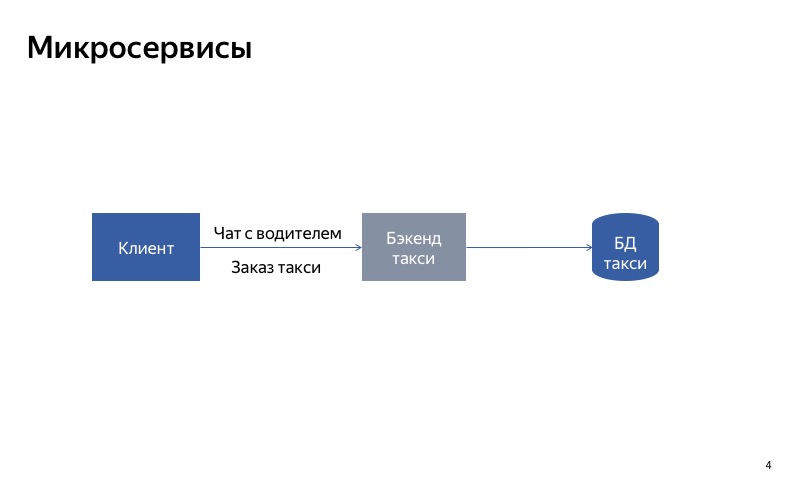
Was können Sie versuchen zu tun? Teilen Sie den monolithischen Dienst in zwei Teile. Ein Teil ist für die Bestellung eines Taxis verantwortlich, der andere für die Kommunikation mit dem Fahrer.
Jetzt sieht alles viel besser aus. Wenn der Chat mit dem Fahrer unterbrochen wird, funktioniert alles andere weiterhin ordnungsgemäß.
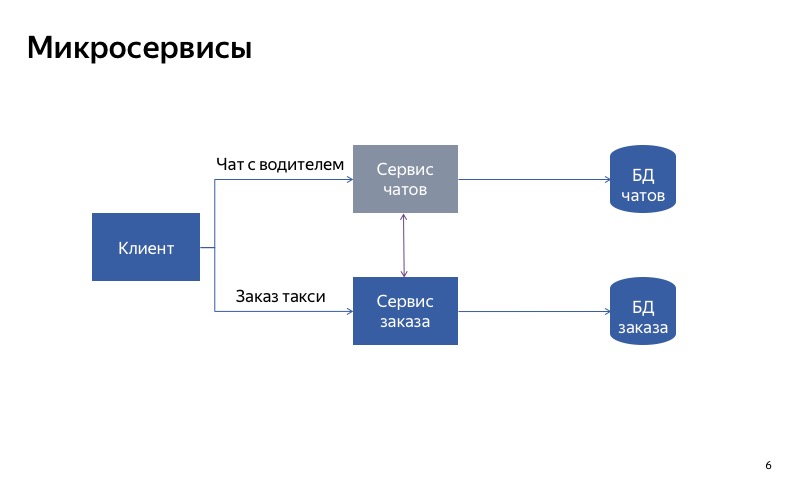
Wie Sie sehen können, verwendet der Client unterschiedliche APIs und Anforderungen, um eine Bestellung aufzugeben und mit dem Treiber zu kommunizieren.
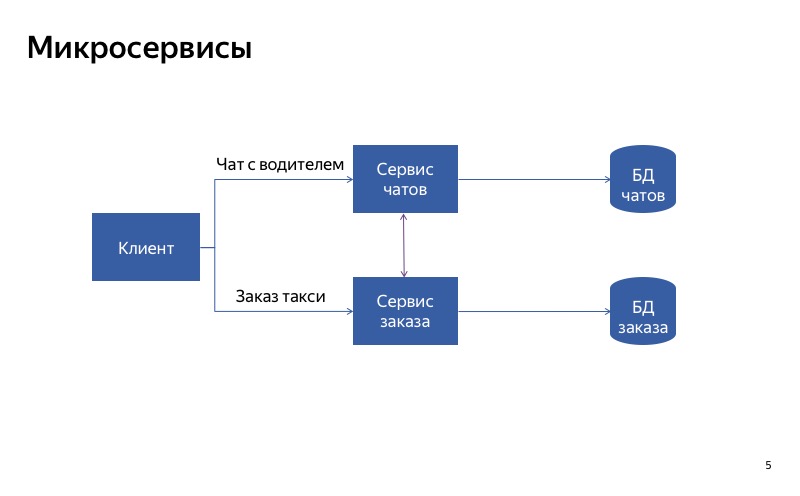
Tatsächlich scheint aber jetzt nicht alles so gut zu sein, da zwischen dem Chat-Service und dem Bestellservice eine falsche Verbindung besteht. Und es kann sich herausstellen, dass der Bestellservice einen Chat-Dienst im Leerlauf verwendet. In diesem Fall funktioniert die Hauptfunktionalität nicht.
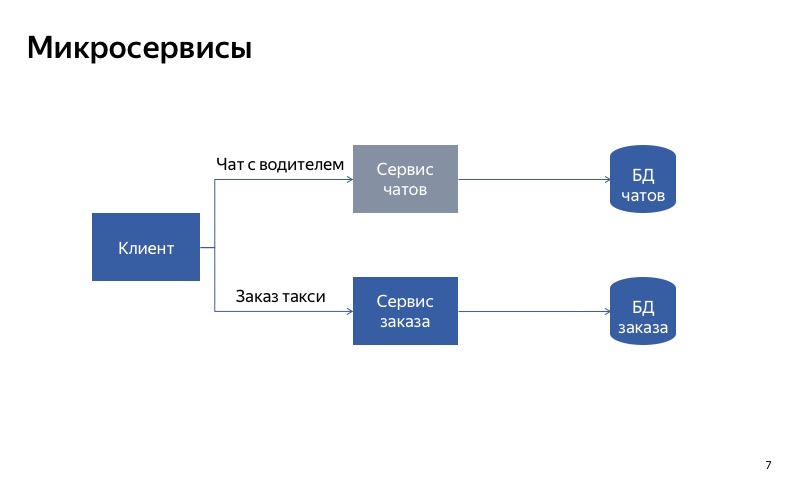
Und in diesem Fall ist alles viel besser. Die falsche Kommunikation ist verschwunden, und jetzt sind unsere Dienste wirklich unabhängig voneinander. Wenn der Chat-Service ausfällt, können Sie trotzdem ein Taxi nehmen.
Die Schlussfolgerung daraus lautet wie folgt: Wenn Sie die Trennung von Diensten beeinträchtigen möchten, ist es sehr wichtig, die Dienste unabhängig voneinander zu machen. Dies bedeutet, dass sie unterschiedliche Einstiegspunkte und Endpunkte haben müssen. Sie müssen unterschiedliche Laufzeiten haben. Und natürlich müssen sie unterschiedliche Datenbanken verwenden. Andernfalls kann ein unterbrochener Dienst alle anderen Dienste entlang der Kette unterbrechen.
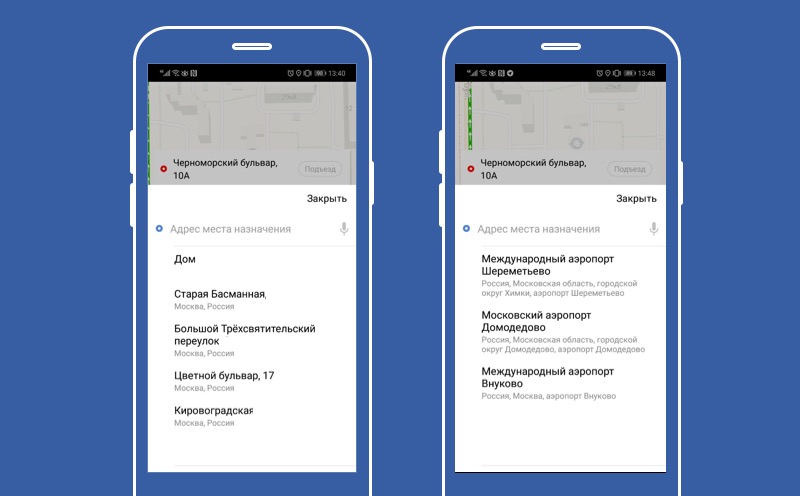
Nun, wir haben herausgefunden, wie die Funktionalität deaktiviert werden kann. Lassen Sie uns nun sehen, wie man Standardfunktionen erstellt und wie man Kürbis macht. Auf diesem Bildschirm unser Zielvorhersagedienst. Der Dienst verwendet eine intelligente KI, um dem Benutzer die derzeit besten Ziele für ihn vorherzusagen. Und wenn die KI müde ist, verwenden wir das Standardverhalten und bieten dem Benutzer an, Moskau zu verlassen.
Schauen wir uns an, wie das in der Praxis funktioniert.

Wir haben einen Kunden, er kontaktiert den Zieldienst und erhält eine Fehlermeldung.
Nun sind zwei Situationen möglich. Die erste Situation, wenn der Fehler ein einzelner war, ist nur eine fehlgeschlagene Anforderung. In diesem Fall werfen wir dem Kunden nur einen Fehler zu, er wird eine erneute Anfrage stellen und seine Lieblingsziele erhalten.
Wenn der Fehler jedoch massiv ist, schalten wir den Kürbis ein und der Benutzer erhält das Standardverhalten.

Ein solches harthäutiges Verhalten ist jedoch viel einfacher zu implementieren, und dieser Kürbis ist sehr zuverlässig, sodass wir auch dann arbeiten können, wenn die KI ausfällt. Wenn wir wissen, dass Benutzer häufig zu Flughäfen reisen, werden wir keine signifikante Verschlechterung im Leben der Benutzer feststellen.
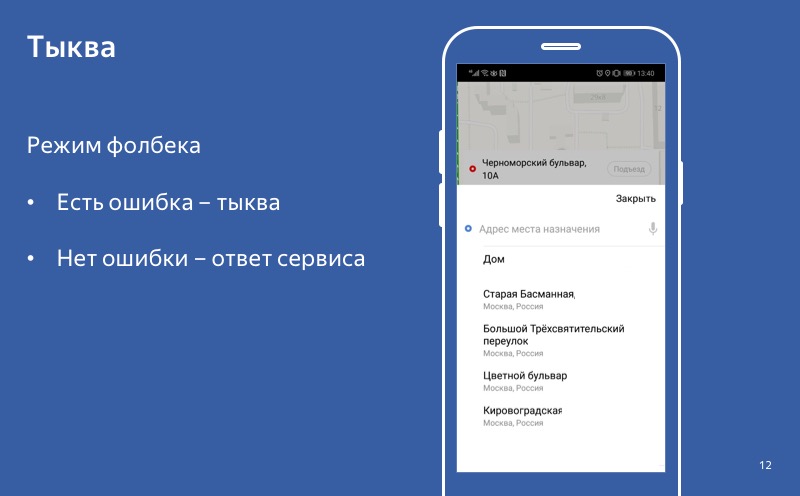
Selbst wenn der Degradationsmodus aktiviert ist, ist der Kürbis aktiviert, aber der Benutzer kontaktiert den Dienst und erhält eine erfolgreiche Antwort. Dann verwenden wir diese Antwort, nicht den Kürbis. Und dieses Verhalten - wenn wir es im Falle einer Antwort verwenden und im Fehlerfall einen Kürbis - nennen wir den Fallback-Modus.
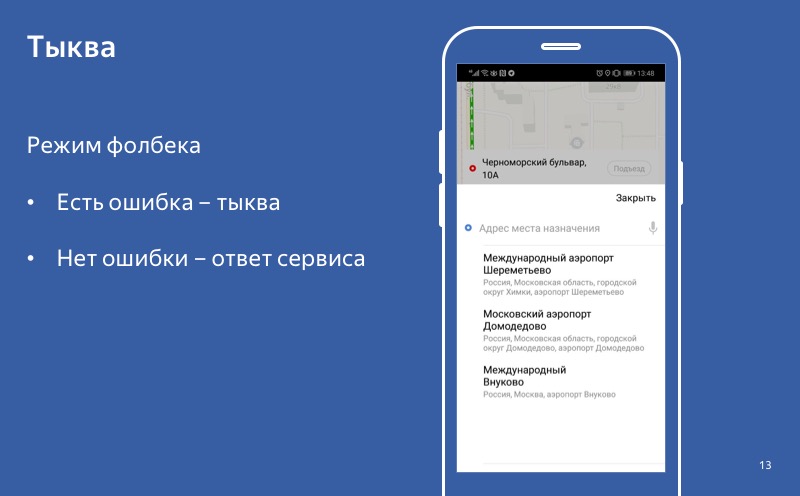
Kein Fehler - eine erfolgreiche Antwort. Es gibt einen Fehler - einen Kürbis. Wir sagen, dass der Fallback aktiviert wurde.
Ich habe herausgefunden, was mit einem defekten Dienst getan werden kann. Sie können es ausschalten oder den Kürbis einschalten. Fahren wir nun mit dem zweiten Teil fort und sehen, wie zu diagnostizieren ist.
Wir haben zwei große Fragen, die beantwortet werden müssen. Der erste ist, wenn Sie den Service ausschalten und den Kürbis einschalten müssen. Die zweite ist, wenn Sie den Kürbis ausschalten und den Service wieder einschalten müssen. Bevor wir diese Fragen beantworten können, müssen wir einen Punkt klarstellen.
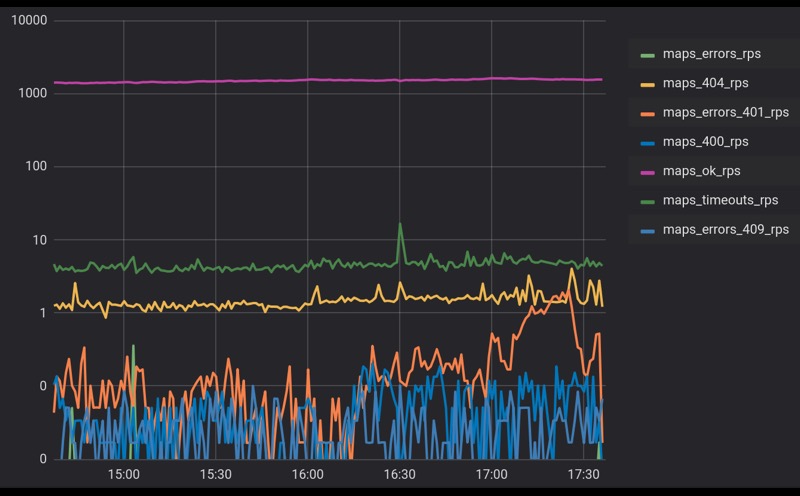
In jedem komplexen System, das mit einer großen Anzahl von Agenten interagiert, gibt es immer Hintergrundinformationen zu Fehlern. Auf dieser Folie sehen wir einen echten Zeitplan für Anrufe bei einem unserer Dienste. Mehrere tausend RPS kommen dazu, wir bekommen etwas weniger als 1% der Fehler. Hier ist die logarithmische Skala.
Fehler können durch verschiedene Dinge verursacht werden. Vielleicht ist dies eine Art interner Prozess, der eine Datenbank aktualisiert oder nur Hintergrundprozesse. Vielleicht gehen Kunden mit den falschen Anfragen, aber die Tatsache bleibt: Wir werden immer einen Hintergrund von Fehlern haben. Nehmen wir es und gehen wir weiter.
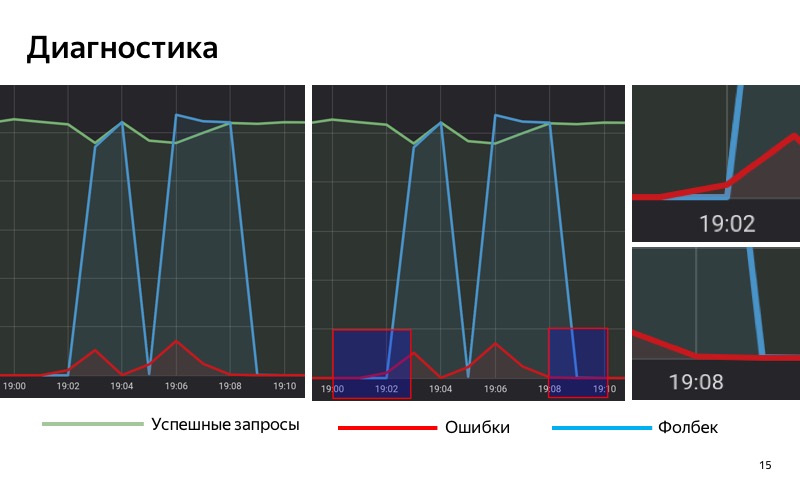
Daher verwenden wir die Lösung basierend auf Statistiken. Wir haben eine spezielle Datenbank, in der wir Statistiken speichern, die Anzahl erfolgreicher Abfragen, die Anzahl fehlerhafter Abfragen und Abfragen speichern, für die Fallback enthalten war. Wir erfassen und sammeln Statistiken über unseren Service über einen bestimmten Zeitraum mit einem Schiebefenster. Wenn der Anteil der Anfragen mit Fehlern in diesem Schiebefenster einen bestimmten Schwellenwert überschreitet, aktivieren wir den Fallback. Und wenn die Anzahl der Fehler unter dem Schwellenwert liegt, schalten wir ihn aus.
Achten Sie auf die ausgewählten Bereiche. Um 19:01 Uhr tauchten die ersten Fehler auf, aber bisher ist ihr Anteil recht gering, und bis 19:02 Uhr schließen wir keinen Fallback ein. Um 19:02 ist der Schwellenwert überschritten, wir haben den Fallback eingeschaltet. Um 19:08 Uhr der umgekehrte Vorgang: Die Fehler wurden beendet, aber seit einiger Zeit ist der Fallback aktiviert, da der Schwellenwert in unserem Schiebefenster immer noch überschritten wird. Um 19:09 Uhr schalteten wir den Fallback aus.
Wir haben herausgefunden, wann der Dienst ausgeschaltet werden muss. Die zweite Frage muss beantwortet werden: Wann soll sie eingeschaltet werden? Es ist ganz einfach: Wir verwenden dieselbe Lösung, die auf Statistiken basiert.
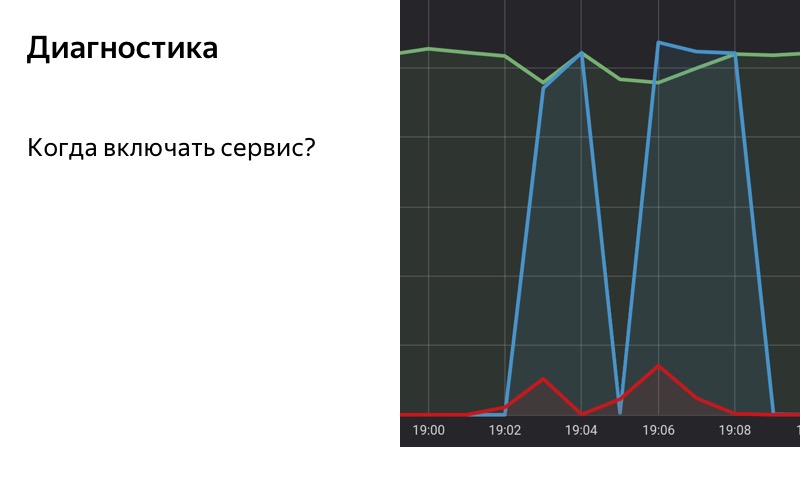
Es ist wichtig, dass wir die Last nicht aus dem Dienst entfernen, auch wenn wir den Verschlechterungsmodus aktivieren. Auf diese Weise können wir weiterhin Statistiken erhalten, auch wenn wir dem Benutzer einen Kürbis zeigen. Somit können wir feststellen, dass die Fehler behoben sind und der Service repariert wird. Sie können es also wieder voll einschalten.
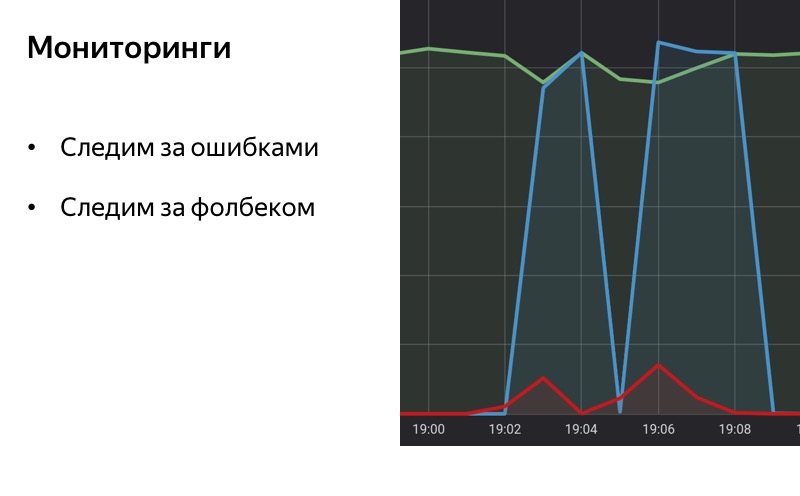
Wenn wir über Degradation sprechen, können wir nichts über Überwachung sagen. Eine gute Überwachung ist der halbe Erfolg, der halbe Weg zum automatischen Herunterfahren oder zur automatischen Verschlechterung. Für uns ist es wichtig zu verstehen, welche Probleme mit unserem Service auftreten, wie Fehler auftreten können und wie oft sie auftreten. Und vielleicht brauchen wir in der ersten Phase nicht einmal einen Leistungsschalter. Wenn die Überwachungsleuchte aufleuchtet, können wir den Dienst einfach manuell ein- und ausschalten. Wenn die Überwachungslampe erlischt, schalten wir den Dienst ein.
Wenn wir eine automatische Verschlechterung durchführen, einen automatischen Schalter, ist es wichtig, die Überwachung des Fallbacks selbst durchzuführen. Wenn das Degradationssystem gut genug funktioniert, bemerken Benutzer möglicherweise überhaupt nicht, dass etwas in uns kaputt gegangen ist. Wir selbst können es, wenn es keine Überwachung gibt, nicht bemerken. Es ist wichtig, den Fallback zu überwachen. Es ist wichtig zu verstehen, wann er aktiviert und wann deaktiviert ist, damit Statistiken verfügbar sind und wir verstehen können, wie lange die Funktionalität nicht funktioniert, ob unser Backend mit der Zeit schlechter oder besser wird, je nachdem, wie viel Zeit wir für einen Fallback halten .
Alles ist mit dem Hauptteil.
Am Ende möchte ich Ihnen einige Nuancen nennen, denen wir uns bei der Entwicklung eines automatischen Abbausystems in Yandex.Taxi stellen mussten.
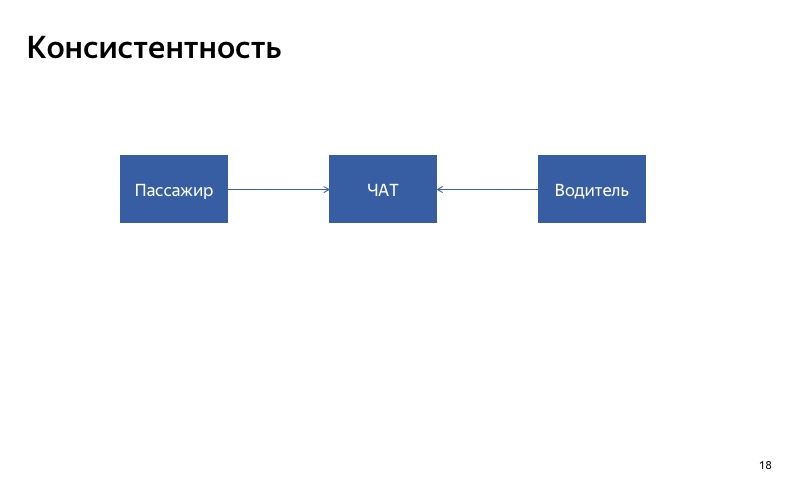
Das erste, worauf Sie achten sollten, ist die Konsistenz. Wenn Sie für einen bestimmten Dienst eine automatische Verschlechterung durchführen, ist es wichtig, dass der Dienst auf alle Kunden konsistent reagiert. Wenn Sie zwei Clients haben, die den Service nutzen, ist es wichtig, dass die Antworten für diese beiden Clients im Falle einer Verschlechterung konsistent sind. Und wenn Sie einen Dienst haben, der an einem längeren Prozess beteiligt ist, müssen Sie verstehen: Vielleicht funktioniert der Dienst zu Beginn und am Ende des Prozesses ordnungsgemäß und irgendwo in der Mitte wird der Fallback aktiviert.
Es klingt kompliziert, aber versuchen wir es mit einem Beispiel zu erklären. Vielleicht wird es klarer.
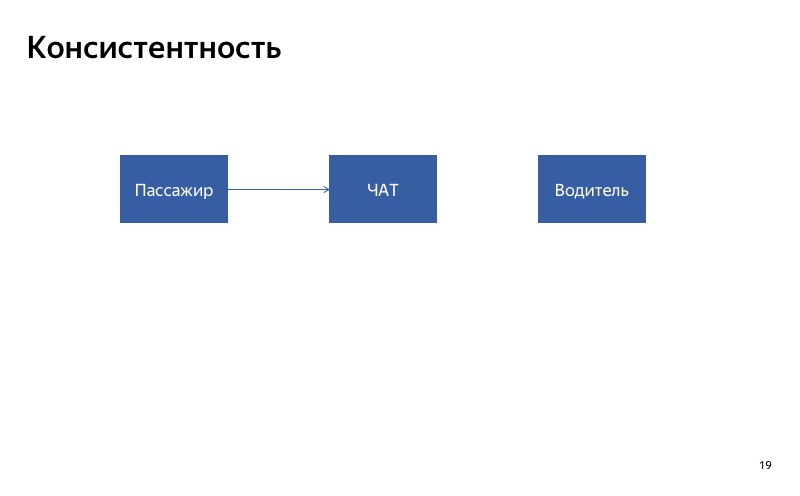
Hier ist unser Chat zwischen Fahrer und Beifahrer. Der einfachste Weg, es zu verschlechtern, besteht darin, es zu deaktivieren. Stellen wir uns vor, der Chat für den Fahrer ist unterbrochen. Was wird passieren? Der Client schreibt in den Chat, der Treiber sieht die Nachrichten jedoch nicht. Sie werden wahrscheinlich sehr unglücklich sein, werden bei unserer Bewerbung schwören, wenn sie sich treffen. In diesem Fall ist es wichtig, dass der Chat für alle Teilnehmer des Chats entweder gleichzeitig eingeschaltet oder gleichzeitig ausgeschaltet wird. Das nenne ich Konsistenz.

Die zweite Nuance betrifft die Tatsache, dass unsere Yandex.Taxi-Anwendung geoverteilt ist: Taxis können in Moskau, Krasnojarsk oder Helsinki bestellt werden. Dies muss auch bei der Entwicklung von Abbausystemen berücksichtigt werden. Stellen Sie sich vor, wir haben viele erfolgreiche Anfragen und nur sehr wenige Anfragen mit Fehlern. Es scheint, dass dies eine normale Situation ist, der Hintergrund von Fehlern ist immer vorhanden. Sie können das gleiche Bild jedoch auch anders betrachten.
Sie können sehen, dass der Dienst in Mytishchi nicht funktioniert, und Sie müssen den Fallback für diese Benutzer aktivieren. Die Schlussfolgerung lautet: Sie müssen die richtigen Statistiken erstellen. Für uns als geoverteilten Dienst bedeutet dies auch, dass wir Statistiken nach Städten erstellen müssen. Wenn wir die Statistiken korrekt erstellen, werden wir sofort feststellen, dass die meisten Anfragen von Mytishchi unterbrochen werden, und das Fallback speziell für Benutzer von Mytishchi aktivieren. Und für alle anderen Benutzer werden wir weiterhin im normalen Modus arbeiten, da für sie der Dienst korrekt funktioniert.

Vielleicht gibt es für andere Dienste andere Bedingungen und andere Nuancen.
Unsere Dienstleistungen werden immer komplexer. Oft hängen sie von der Außenwelt ab, die wir nicht vorhersagen können. Daher ist es wichtig, nicht nur Dienste zu schreiben, die gut funktionieren, sondern auch Dienste, die gut funktionieren. Wenn Sie etwas Neues lernen, sagen Sie es Ihren Kollegen und teilen Sie es. Teilen, neu posten. Richtig abbauen.