Lyrische Einführung
Eines Abends, als ich die Dinge in einem Wandschrank in Ordnung brachte, stieß ich auf einen großen Karton. Sie überlebte zwei Umzüge und öffnete sich so viele Jahre nicht, dass ich völlig vergaß, was darin gespeichert war. Es stellte sich heraus, dass es Fotos gab - in Alben, in Umschlägen aus einem Geschäft, und einige waren einfach so.
Viele Fotos wurden vor über siebzig Jahren aufgenommen. Einer war ein Großvater - in seiner Studienzeit noch jung und gutaussehend, in absolut
zerstörerischen Gläsern. „Wow, mein Großvater trug Hipster-Kleidung, noch bevor sie zum Mainstream wurde“, dachte ich und lächelte unwillkürlich. Ich erkannte ihn sofort, ging dann aber zu den Fotos von Menschen, an die ich mich an nichts mehr erinnere. Bei Gesichtszügen kann man die Beziehung vage erraten - und das war's.

Als ich fünfzehn war, zeigte meine Großmutter wiederholt diese Karten und sprach über diejenigen, die darauf abgebildet sind. Leider wird der Wert solcher Geschichten nur verstanden, wenn niemand da ist, der sie erzählt. Zu dieser Zeit war es für mich zum zehnten Mal absolut uninteressant, einige moosige Geschichten über die Vorkriegsjahre zu hören. Ich winkte ab und ging an den Ohren vorbei. Als mir plötzlich klar wurde, dass ein Teil meiner Familiengeschichte unwiederbringlich verloren war, kam mir die Idee, das, was noch übrig war, zu systematisieren und zu bewahren.
Die ideale Lösung zum Speichern von Familiendaten schien mir eine Mischung aus einer Wiki-Engine und einem Fotoalbum zu sein. Da es keine vorgefertigten geeigneten Lösungen gab, musste ich meine eigenen schreiben. Es heißt
Bonsai und ist Open Source unter der MIT-Lizenz. Dann wird es eine Geschichte darüber geben, wie es organisiert ist und wie man es benutzt, sowie die Geschichte seiner Entwicklung und ein bisschen
DRAMA .

Noch ein Fahrrad?
Heutzutage gibt es viele Tools, mit denen Sie Stammbäume erstellen und Informationen über Verwandte katalogisieren können. Sie sind bedingt in zwei große Kategorien unterteilt - Onlinedienste und Desktopanwendungen.
Bei einer Desktop-Anwendung wird die Datenbank normalerweise als Datei auf der Festplatte gespeichert. Sie öffnen die Anwendung und füllen sie im Einzelbenutzermodus auf. Bei Bedarf können Daten zur Sicherung exportiert oder auf ein anderes System übertragen werden (z. B. im
GEDCOM- Format). Von denen, die ich gesehen habe, schienen
Gramps (kostenlos) und der inländische
Lebensbaum (erfordert einen einmaligen Kauf) am angenehmsten zu verwenden.
Die andere Seite des Spektrums sind Webdienste. Sie speichern Ihre Daten auf Remote-Servern und erheben eine regelmäßige Nutzungsgebühr. Da es sich um ein kommerzielles Produkt mit zentraler Basis und guter Monetarisierung handelt, bieten Ihnen die Dienste dieses Plans die Möglichkeit, beispielsweise durch DNA-Tests oder Archivaufzeichnungen nach verlorenen Verwandten zu suchen.
Die Vor- und Nachteile beider Optionen liegen auf der Hand. Im ersten Fall speichern Sie die Datenbank lokal und steuern den Zugriff darauf und die Erstellung von Sicherungen vollständig. Wenn die Anwendung Open Source ist, können Sie sie bei Bedarf sogar um zusätzliche Funktionen erweitern. Es wird jedoch schwierig sein, mit einer solchen Datenbank zusammenzuarbeiten oder Daten von einem anderen Gerät anzuzeigen. Im zweiten Fall erfolgt der Zugriff im Gegenteil von jedem Gerät aus, aber Sie geben Ihre Daten an Dritte weiter und hoffen auf deren Anstand. In der Geschichte meiner Familie gibt es keine kompromittierenden und schrecklichen Geheimnisse. Ich betrachte diese Informationen jedoch immer noch als rein persönlich und möchte im Prinzip nicht, dass andere sie speichern oder analysieren.
Angesichts der Mängel dieser beiden Ansätze können wir eine Liste der Anforderungen für den "idealen" Motor formulieren:
- Webanwendung, die auf Ihrem eigenen Server gehostet wird
- Erstellen von Artikeln über Personen, Haustiere, Orte, Ereignisse usw. wie ein Wiki
- Medien herunterladen
- Markierungen von Personen in Fotos und Videos
- Automatischer Stammbaumaufbau
- Kalender mit allen wichtigen Daten.
- Werkzeuge zum Mitbearbeiten und Füllen
Fairerweise gelang es mir, mehrere Projekte mit einer selbst gehosteten Implementierung zu finden, die sich jedoch in einem bedauerlichen Zustand befanden: Das Erscheinungsbild war Mitte der 2000er Jahre eingefroren, es gab keinen vollständigen Satz der erforderlichen Funktionen, und ich wollte mich nicht mit den Legacy-Skripten in PHP befassen. Darüber hinaus war das vorherige Haustierprojekt beendet und es bestand der Wunsch, etwas Neues anzunehmen.
Die goldene Regel lautet:
Wenn Sie es gut machen wollen - machen Sie es selbst!Die verwendeten Technologien wurden nach drei Kriterien ausgewählt: Meine Erfahrung mit ihnen, Popularität und Offenheit. Hier ist das Ergebnis:
- Rantime : .NET Core 2.1
- Backend : ASP.NET Core MVC
- Datenbank : PostgreSQL
- Frontend-Logik : teilweise Vue, teilweise jQuery.
- Frontend-Stile : Bootstrap + Sass
Zu den unterstützenden Rollen gehören Elasticsearch für die Volltextsuche und ffmpeg für die Aufnahme von Screenshots aus dem Video.
Datenschema
Die Hauptobjekte in der Bonsai-Datenbank sind eine
Seite und eine
Mediendatei . Sie sind durch eine Viele-zu-Viele-Beziehung durch
Marken verbunden . Ein Tag kann einen Titel ohne Link haben - zum Beispiel, wenn Sie jemanden auf einem Foto markieren müssen, aber auf einer ganzen Seite keine Informationen dazu vorhanden sind.
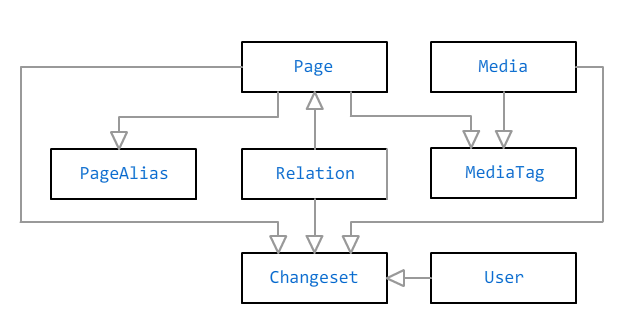
Zusätzlich zum freien Text kann die Seite
Fakten enthalten, die in speziellen Feldern im Admin-Bereich eingegeben werden. Zusätzliche Fakten werden anhand der Fakten berechnet: Wenn Sie beispielsweise das Geburtsdatum der Person angeben, wird es im Kalender markiert und auf seiner Seite wird das aktuelle Alter (oder die Lebenserwartung, wenn auch das Todesdatum angegeben ist) angezeigt. Das Geschlecht kann verwendet werden, um den korrekten Namen der Beziehung zu bestimmen („Vater“) "Oder" Mutter "anstelle der gemeinsamen" Eltern ") und so weiter. Die Fakten werden in der Datenbank als JSON-Dokument gespeichert.
Es stehen fünf Arten von Seiten zur Auswahl: Person, Haustier, Ereignis, Ort usw. Die Liste der verfügbaren Fakten hängt von der Art der Seite ab: Beispielsweise ist „Bildung“ nur für eine Person relevant, „Geburtsdatum“ - für eine Person und ein Tier - und „Adresse“ - nur für einen Ort.
Die Seiten sind durch
Beziehungen miteinander verbunden: "Eltern", "Ehepartner", "Freund", "Eigentümer", "Bewohner" und viele andere. Einige Beziehungen können zeitlich begrenzt sein (Ehepartner, Eigentümer, Einwohner), andere gelten als dauerhaft.
Wenn Sie eine Seite oder Beziehung speichern, wird das resultierende Modell auf Konsistenz überprüft. Zum Beispiel müssen sich
die Lebensjahre der Ehepartner überschneiden , eine Person kann nicht mehr als einen leiblichen Elternteil jedes Geschlechts haben und Sie können auch nicht
Ihr eigener Vater werden. Gleichgeschlechtliche Ehen sind jedoch zulässig.
Durch Bearbeiten einer Seite, Mediendatei oder Beziehung wird die
Änderung an der Datenbank gespeichert. Auf diese Weise können Sie den Bearbeitungsverlauf speichern und bei Bedarf zurücksetzen.
Beziehung
Verwandtschaft ist eines der ältesten Konzepte in der Gesellschaft. Bereits in der
vorindoeuropäischen Sprache gab es viele Namen für sie, die in leicht modifizierter Form in die modernen Sprachen verschiedener Gruppen migrierten: Das Wort „Mutter“ wird von Russisch, Englisch und Chinesisch verstanden.
Es gibt viele Möglichkeiten für Verwandtschaft, aber die grundlegenden sind drei:
Eltern ,
Kind und
Ehepartner . Mit ihnen können Sie ein gerichtetes Diagramm aus der Familie erstellen, in der diese Beziehungen Kanten und Personen Knoten sind. In dieser Spalte können Sie jede andere Beziehung ausdrücken, indem Sie den Pfad zwischen den Teilnehmern und ihrem Geschlecht kennen. Um beispielsweise den Großvater einer Person zu identifizieren, müssen Sie zuerst deren Eltern (beliebiges Geschlecht) und dann die Eltern dieses Elternteils (männlich) usw. finden.
Im Bonsai-Administrationsbereich können Sie die Beziehungen dieser drei Grundtypen eingeben. Das Gegenteil wird automatisch für jede Beziehung erstellt - Eltern für Kind, Ehepartner für Ehepartner, Besitzer für Haustier. Alle zusätzlichen Beziehungen werden von der Engine berechnet und in der Seitenleiste auf der Seite angezeigt:
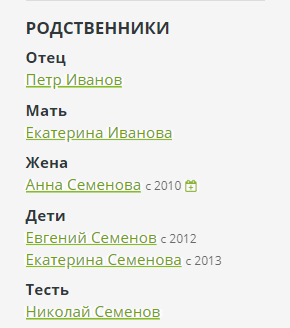
Zur Berechnung der Beziehung wird eine elementare Diagrammdurchquerung verwendet, und Beziehungsnamen werden in Form einer speziellen DSL festgelegt:
public static RelationDefinition[] ParentRelations = { new RelationDefinition("Parent:m", ""), new RelationDefinition("Parent:f", ""), new RelationDefinition("Parent Child:m", "", ""), new RelationDefinition("Parent Child:f", "", ""), new RelationDefinition("Parent Parent:m", "", ""), new RelationDefinition("Parent Parent:f", "", "") };
Sogar eine Person kann
viele direkte Verwandte haben. Bonsai unterteilt die Links in folgende Gruppen:
- Die engste Blutsverwandtschaft ist die Familie, in der die Person aufgewachsen ist: Mutter und Vater, Großeltern, Brüder und Schwestern. Wenn Sie sich die Grafik ansehen, ist dies der Pfad 1-2 Schritte nach oben und 1 seitwärts.
- Eigene Familie : eine Gruppe für jeden Ehepartner und Kinder von ihm. Dies schließt auch die Verwandten des Ehepartners ein - Schwiegermutter, Schwager und dergleichen.
- Sonstiges : entfernte Verwandte (Enkel, Onkel, Tanten) und nicht verwandte Verwandte (Freunde, Kollegen).
Manchmal reicht eine Möglichkeit, die Gruppenmitgliedschaft zu bestimmen, nicht aus. Die Daten sind möglicherweise unvollständig, müssen jedoch noch so angemessen wie möglich angezeigt werden. Betrachten Sie das folgende Geschwisterdiagramm:
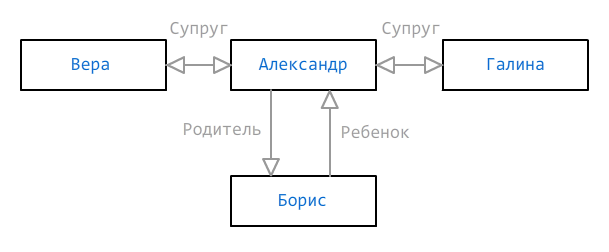
Wie wir sehen, sind zwei Frauen (Vera und Galina) und ein Sohn (Boris) für Alexander angegeben, aber wir wissen nicht, welche der Frauen die Mutter des Kindes ist - vielleicht ist dies eine Art dritte Frau, aber sie wurde noch nicht hinzugefügt. In solchen Fällen können mehrere Pfade angegeben werden, die existieren sollten oder nicht existieren, und sie sind mit
+ bzw.
- Zeichen gekennzeichnet:
new RelationDefinition("Spouse Child+Child", "||", "") new RelationDefinition("Spouse Child-Child:m", "") new RelationDefinition("Spouse Child-Child:f", "")
Stammbaum
Jede anständige Genealogie-Engine sollte in der Lage sein, einen Stammbaum zu erstellen. Dies ist die visuellste Möglichkeit, allgemeine Informationen über Personen und ihre familiären Beziehungen anzuzeigen. Die Daten werden in Form eines gerichteten Graphen in der Datenbank gespeichert und sollten theoretisch leicht zu visualisieren sein. In der Praxis traten die meisten Schwierigkeiten bei der Darstellung des Baumes auf.
Hier einige Beispiele, wie Stammbäume aussehen könnten:

Stammbaum von Targaryenov. Sehr kompakt, weil es von Hand gefertigt wird. Das Generieren eines solchen Baums aus beliebigen Daten ist automatisch äußerst schwierig.
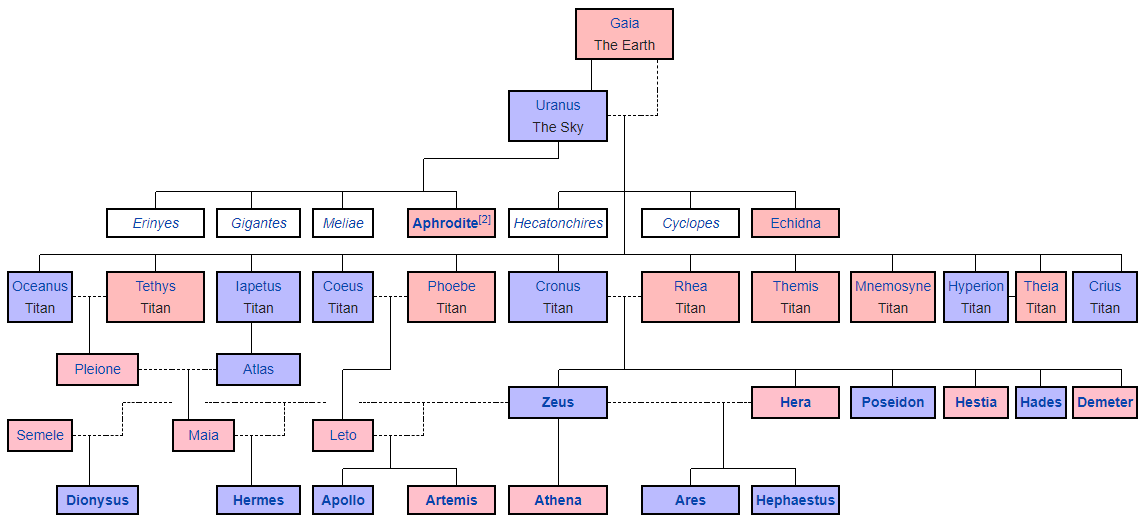
Griechische Götter. Die grafische Darstellung wird aus einer
speziellen Markdown-Syntax generiert, in der Sie noch alle Blöcke manuell anordnen und die Verknüpfungen zwischen ihnen zeichnen müssen. Ein bisschen wie ASCII-Kunst.

Darstellung eines Baumes in Form eines Halbkreisdiagramms. Leicht automatisch zu generieren, berücksichtigt aber nur direkte Vorfahren.
Ich habe viele Optionen durchgesehen. Das ästhetischste war auf der MyHeritage-Website:
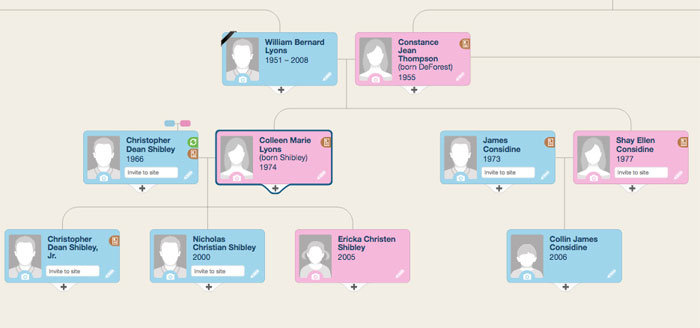
Das Rendern eines solchen Baums kann in drei bedingte Schritte unterteilt werden: Abrufen von Daten aus der Datenbank, Anordnen von Blöcken / Verbindungslinien und direktes Anzeigen dieser Blöcke auf der Seite. Wenn beim ersten und dritten Schritt alles trivial war, bin ich im zweiten gestolpert.
Versuche, eine selbstgemachte Lösung in Eile zu werfen, endeten in einem völligen Fiasko. Eine kompetente Anordnung von Graphenelementen ist ein so komplexer Bereich, dass
Dissertationen darauf geschrieben werden und die
fertigen Komponenten wie eine Wohnung in Moskau sind. Okay, Sie werden nicht in der Lage sein, selbst zu schreiben, aber es gibt sicherlich anständige kostenlose Lösungen?
Die meisten meiner Hoffnungen waren in der
D3.js-Bibliothek . Vielleicht ist dies das erste, was Ihnen in den Sinn kommt, wenn Sie ein Diagramm oder eine Grafik auf einer Webseite zeichnen müssen. Leider gab es unter mehr als dreihundert (!) Beispielen im Wiki kein einziges, das einem Baum mit MyHeritage mehr oder weniger ähnlich war.
Der nächste Schritt bestand darin, in Bibliotheken einzutauchen, die nicht am Rendern beteiligt waren, sondern die optimale Anordnung der Elemente im Diagramm berechneten. Die meisten von ihnen bieten das sogenannte
Force-Layout an . Dies ist ein sehr einfacher Ansatz, der auf physikalischen Formeln basiert: Die Knoten des Graphen werden durch elastische Körper dargestellt, und die Verbindungslinien werden durch Federn dargestellt. Es ist leicht an seiner charakteristischen Animation zu erkennen - der Graph scheint sich unterwegs zu „begradigen“, und dies ist kein zusätzliches Merkmal, sondern eine unvermeidliche Folge der Simulationscharakteristik des Algorithmus. Der Force-Layout-Ansatz eignet sich gut zur Visualisierung von Daten ohne klare Hierarchie (z. B. Verbindungen in sozialen Netzwerken), aber der Stammbaum in dieser Form sieht fehlerhaft aus.
Eine weitere Option ist die
Graphviz- Bibliothek. Das Ergebnis ihrer Arbeit ist leicht an den charakteristischen Pfeilen zu erkennen. Ein spezielles
DOT wird verwendet, um das Diagramm zu beschreiben. Testfälle sehen noch mehr oder weniger aus, aber es treten Probleme mit realen Daten auf: Die Pfeile „brechen“ und verbinden sich in seltsamen Winkeln, das Diagramm kriecht hoch und Sie können es nicht anpassen und Sie werden es nicht umgehen.
Nachdem ich selbst keine passende Lösung gefunden hatte, entschied ich mich, sie freiberuflich zu bestellen, und dann begann das
DRAMA .
Die Bestellung wurde am Morgen des 22. Oktober aufgegeben und erhielt innerhalb einer Stunde mehrere Antworten. Einer der Befragten hieß Vladislav; Er schickte ein Beispiel für eine ähnliche Lösung und versprach, die Aufgabe an
einem Tag zu erledigen. Diese Geschwindigkeit schien mir verdächtig, aber ich hoffte auf seine Erfahrung und gab dem Kerl einen Fehler von einer Woche. In den ersten Tagen stellte Vladislav zusätzliche Fragen, ohne mich mit einem tiefen Eintauchen in das Projekt und einer aufmerksamen Einstellung zu Details zu überraschen, und verschwand dann. Er wachte am 1. November auf, entschuldigte sich für das Verschwindenlassen aus familiären Gründen und schickte einen Link mit einer Beta-Version, die ziemlich ähnlich aussah, wie er es wollte, wenn nicht der Knoten in den Verbindungslinien in der Mitte wäre:
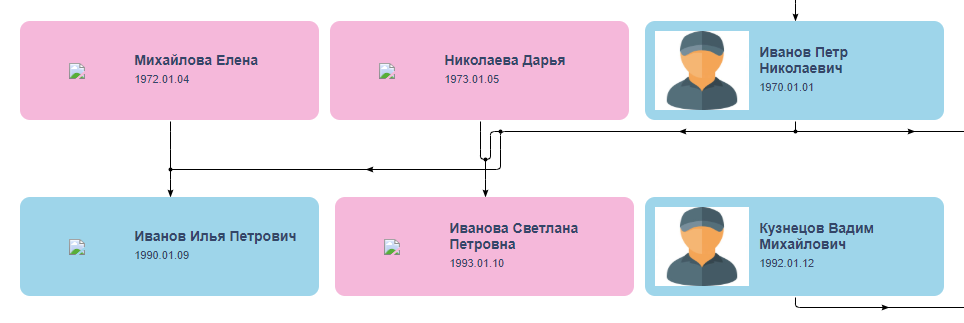
Das Verschwinden des Darstellers ist immer ein Weckruf, aber man weiß nie, dass etwas passiert, weil er etwas getan hat. Lass ihn weitermachen! Ich schickte eine Vorauszahlung und begann auf Verbesserungen zu warten. Nach ein paar Tagen schrieb Vladislav, dass er das Problem nicht beheben könne und verschwand dann wieder - diesmal für drei Wochen. Während dieser Zeit tat er nichts und weigerte sich, die Vorauszahlung zurückzugeben, weil "die Aufgabe tatsächlich von einem
dummen Ex-Freund erledigt wurde, der ihn im Stich ließ und kein Geld zurückgibt". Nach ein paar klärenden Fragen hörte der unglückliche Delegator auf, sich zu entschuldigen und hielt einfach die Klappe. Jetzt leben wir also - von Zeit zu Zeit erinnere ich ihn an die Schulden und als Antwort schickt er einen Screenshot aus der Bankanwendung - sie sagen: "Es gibt kein Geld, aber sobald - also sofort." Ich wünsche Vladislav viel Erfolg im Geschäft und werde schneller reich!
Warf das Kind - Minus im Karma auf!Geld zu verlieren war nicht so ärgerlich, aber ein Monat verging, und die Aufgabe ging nicht in Gang, und jetzt gab es keinen Ort, an dem man auf Hilfe warten konnte. Zuallererst war ich wütend auf mich selbst: Ich bin den Weg des geringsten Widerstands gegangen, habe gegen die
goldene Regel verstoßen - und hier ist das Ergebnis. Voller aufrichtiger Wut setzte ich mich wieder hin, um Bibliotheken zum Zeichnen von Grafiken zu studieren und - siehe da! - plötzlich genau das gefunden, was Sie brauchen.
Die Bibliothek wurde
Eclipse Layout Kernel genannt , abgekürzt ELK. Wie Sie vielleicht erraten haben, wird es zum Anzeigen von Diagrammen in der Eclipse-IDE verwendet, kann aber auch autonom verwendet werden. Im Allgemeinen ist es in Java geschrieben, aber es gibt eine Version, die in JS gesendet wird. Ja, ihr Code ist ein
Albtraum und wiegt eineinhalb Megabyte, aber diese Mängel können dafür vergeben werden, dass er
einfach funktioniert und genau das Richtige tut. Die Schnittstelle ist elementar: Knoten, Kanten und Einstellungen werden an den Eingang übertragen, und am Ausgang erhalten wir die Koordinaten. Sie können einen Baum mit ihnen auf jede bequeme Weise zeichnen: Ich habe SVG gewählt, um Linien und Divs mit absoluter Positionierung für Blöcke zu verbinden.
Die Integration der Bibliothek und die Auswahl der optimalen Einstellungen dauerte zwei Nächte. Dies ist natürlich nicht „ein Tag“, wie mein unglücklicher und arroganter Freiberufler versprochen hat, sondern ziemlich nahe. Infolgedessen konnte Bonsai den Baum in ungefähr folgender Form anzeigen:
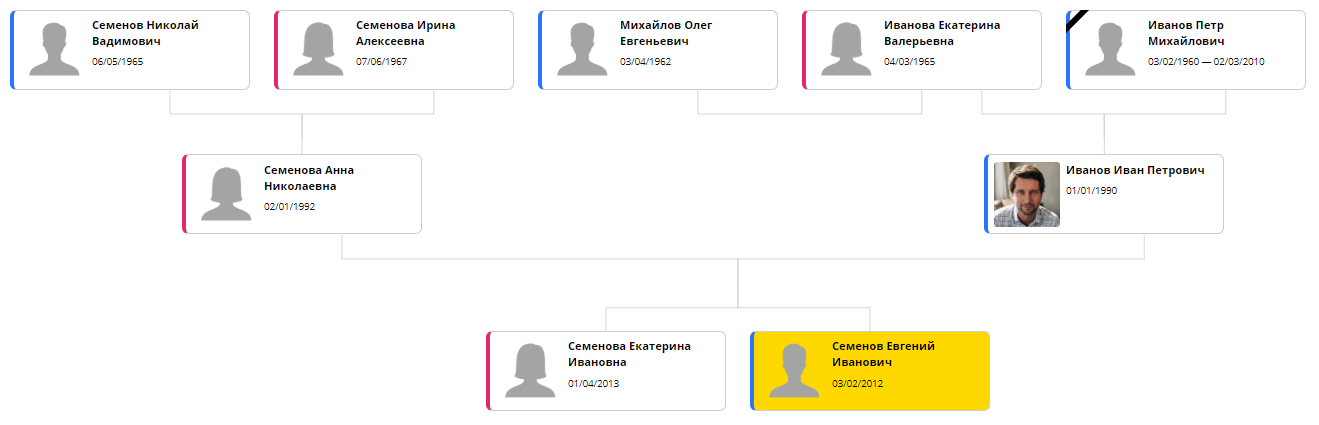
Jetzt bleibt nur noch die Bearbeitungszeit. ELK verwendet einen iterativen Algorithmus: Sie können der optimalen Platzierung näher kommen, indem Sie zusätzliche Zeit aufwenden. Bei einem Baum mit 20 bis 30 Elementen benötigt ein gutes Ergebnis etwa 5 Sekunden. Aus diesem Grund wird jedes Mal lange Zeit eine Seite mit einem Baum geöffnet, die schnell nervt. Ab der nächsten Version wird die Berechnung an das Backend übertragen, sodass sie beim Ändern der Seite und beim Zwischenspeichern einmal ausgeführt werden kann.
Volltextsuche
Ein System zum Speichern von Textinformationen wäre ohne eine bequeme Volltextsuche nutzlos. Bonsai verwendet die PostgreSQL-Datenbank. Als erstes habe ich mich entschlossen, zu prüfen, was sie sofort bieten kann. Eine weitere Enttäuschung:
tsvector mit gewöhnlichen Wörtern
tsvector , weigert sich jedoch, nach dem Wichtigsten zu suchen - Vor- und Nachnamen:
SELECT to_tsvector('') @@ to_tsquery(''),
Trigramme gaben auch nichts Gutes. Am Ende habe ich mich für eine eher erwartete Option entschieden: ElasticSearch +
Russian Morphology . Es stellte sich als sehr unpraktisch heraus, mit .NET damit zu arbeiten, er bewältigt jedoch die Suche nach einer soliden Fünf mit seinem vollständigen Namen.
Bewusste Unvollkommenheit
Bei der Arbeit an einem Projekt traten regelmäßig Situationen auf, in denen ein
interner Perfektionist über die gewählte Lösung wütend war. Der Themenbereich ist eher nicht standardisiert und die allgemein anerkannten „guten Manieren“ funktionieren nicht immer.
Was passiert zum Beispiel, wenn wir eine Seite öffnen?
- Der Seitentext wird von Markdown nach HTML kompiliert. Wenn der Text Links zu anderen Seiten und Mediendateien enthält, müssen Sie zur Datenbank gehen, um weitere Informationen zu erhalten.
- Die Fakten werden aus dem JSON deserialisiert, in dem sie in der Datenbank im Ansichtsmodell gespeichert sind.
- Beziehungen werden bestimmt. Zu diesem Zweck ist es aus der Datenbank mit dem langen Leiden erforderlich, den gesamten Verbindungsgraphen abzurufen und Knoten darin gemäß einer zuvor bekannten Liste von Pfaden zu finden.
Auf den ersten Blick scheint dies eine furchtbar schwierige Operation zu sein, aber tatsächlich liegt es nicht an der relativ geringen Datenmenge. An wie viele Verwandte können Sie sich erinnern und möchten sie aufschreiben? Versuchen Sie, sie aus Gründen des Interesses wiederzugeben, und stellen Sie fest, dass es sehr schwierig sein wird, mindestens hundert zu wählen. Und wie viele Menschen wollen Zugang gewähren? Selbst eine astronomisch große Zahl für eine Familie sind tausend Menschen! - Nach den Maßstäben moderner Datenbanken bleibt es lächerlich.
Natürlich wird das kompilierte Seitenansichtsmodell beim ersten Öffnen immer noch zwischengespeichert und bei nachfolgenden wiederverwendet, vor allem, weil es sehr einfach zu implementieren war. Die Regel der Cache-Ungültigmachung für Änderungen im Admin-Bereich ist ebenfalls so einfach wie möglich: Wenn wir nur den Text und einige
lokale Fakten (Liste der Sprachen, Blutgruppe, Haarfarbe usw.) ändern, setzen Sie einfach diese bestimmte Seite zurück. Bei jeder anderen Änderung - Seitenname, Geburtsdatum oder Geschlecht, Hinzufügen oder Ändern einer Verbindung - wird der Cache
vollständig zurückgesetzt. Ja, dies ist nicht die intelligenteste Art zu reinigen. Ja, natürlich könnten Sie einen komplexen Algorithmus schreiben, der nur das zurücksetzt, was Sie benötigen - aber für dieses Projekt würde dies die Kosten nicht rechtfertigen.
Das Projekt unterstützt keine Lokalisierung und Änderung des Erscheinungsbilds, die Autorisierung funktioniert bei OAuth auf Facebook \ Google, und das Admin-Panel wird in den üblichen Formularen erstellt und nicht in einem SPA-Framework, das auf der neuesten Mode basiert. All dies
könnte realisiert oder verbessert werden, aber es hätte kein Problem gelöst, und daher wäre Zeit verschwendet worden.
Ich freue mich auf die Zukunft
Ein weiterer Grund, warum es keinen Sinn macht, in die Komplexität des Motorgeräts zu investieren, ist die Vergänglichkeit der Implementierung im Vergleich zu den darin gespeicherten Daten. Denken Sie nur einen Moment darüber nach: Das Internet in seiner jetzigen Form gibt es seit fast zwanzig Jahren, und die Familiengeschichte gibt es seit
Jahrhunderten . Bisher hat noch niemand dieses Problem gelöst, nur weil die Informationstechnologiebranche selbst viel weniger existiert. Was kann getan werden?
Die Engine muss regelmäßig von Grund auf neu geschrieben werden - genau wie seit Tausenden von Jahren haben Mönche Schwierigkeiten, Texte aus heruntergekommenen Büchern in neue zu kopieren. Der einzige Unterschied besteht darin, dass das Buch bei richtiger Handhabung und Anwendung hundert Jahre liegen kann - auf der Stärke von 15 bis 20 Jahren. Ich hoffe, dass ich es in zwanzig Jahren noch selbst schaffen werde, aber in weiteren zwanzig Jahren müssen es meine Kinder oder Enkelkinder tun. Ich möchte ihnen eine einfache, verständliche und dokumentierte Quelle hinterlassen.
In den ersten Phasen des Entwurfs wollte ich eine bestimmte SQL-ähnliche Sprache in die Engine einbetten, mit deren Hilfe ich Antworten auf bestimmte Fragen erhalten konnte: „Wie viel Prozent meiner Vorfahren mit blauen Augen“, „als Ivan das erste Auto kaufte“ und so weiter. Diese Idee musste aufgegeben werden, da anstelle des Klartextes alle Informationen in einer bestimmten formalisierten Form eingegeben werden müssten und nur eine Beschreibung dieses Typs Jahre dauern würde. Auf der anderen Seite gewinnt das Verständnis der natürlichen Sprache an Dynamik. Es würde mich nicht wundern, wenn es in zehn oder zwei Jahren möglich sein wird, Siri zu bitten, den Text für Sie zu lesen, den Links zu folgen und als Ergebnis einen Auszug aus den Fakten zu präsentieren. Leute, drück!
Wie versuche ich es?
Leider kann ich keinen Link zur fertigen Demo bereitstellen: Es gibt keinen Server, der dem Habra-Effekt standhält. Es gibt jedoch einige visuelle Screenshots (Bilder können angeklickt werden).
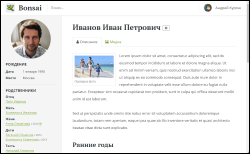

Wenn Ihnen Bonsai nützlich erschien und Sie es selbst ausführen möchten, kann der Quellcode von Github heruntergeladen werden:
https://github.com/impworks/bonsaiDetaillierte Installationsanweisungen finden Sie in der Readme-Datei. Sie benötigen Folgendes:
- .NET Core 2.1+
- PostgreSQL 10+
- ElasticSearch 5.x und das Plugin für russische Morphologie
- Facebook- oder Google-App zur oAuth-Autorisierung
Nach dem ersten Start werden mehrere Testseiten und Fotos in der Datenbank erstellt. Für die Produktion wird dieses Verhalten nicht benötigt und durch das Flag in den Einstellungen deaktiviert.
Vor einem Monat habe ich meine eigene Instanz gestartet und gestartet, um echte Daten zu erhalten. Es tritt eine gewisse Rauheit auf, aber ansonsten bin ich mit dem Ergebnis vollkommen zufrieden. Jetzt wird das Projekt schrittweise weiterentwickelt und abgeschlossen. Die Hauptaufgaben bestehen darin, die Anzeige des Baums zu beschleunigen, das Herunterladen von Dokumenten in Form von PDF zu ermöglichen und die Zugriffsrechte zu optimieren. Es wäre schön, die Benutzerfreundlichkeit des Admin-Panels an einigen Stellen zu verbessern oder Gesichter auf dem Foto automatisch zu erkennen -
dies ist jedoch nicht korrekt .