
Im vorherigen Artikel haben wir über ein solches Problem des maschinellen Lernens wie gegnerische Beispiele und einige Arten von Angriffen gesprochen, mit denen sie generiert werden können. Dieser Artikel konzentriert sich auf Schutzalgorithmen vor dieser Art von Effekten und Empfehlungen zum Testen von Modellen.
Schutz
Lassen Sie uns zunächst einen Punkt erklären: Es ist unmöglich, sich vollständig gegen einen solchen Effekt zu verteidigen, und das ist ganz natürlich. Wenn wir das Problem der gegnerischen Beispiele vollständig lösen würden, würden wir gleichzeitig das Problem der Konstruktion einer idealen Hyperebene lösen, was natürlich ohne einen allgemeinen Datensatz nicht möglich ist.
Die Verteidigung eines maschinellen Lernmodells besteht aus zwei Phasen:
Lernen - Wir bringen unserem Algorithmus bei, korrekt auf gegnerische Beispiele zu reagieren.
Operation - Wir versuchen, während der Operationsphase des Modells ein konträres Beispiel zu erkennen.
Erwähnenswert ist, dass Sie mit den in diesem Artikel vorgestellten Schutzmethoden mit der Adversarial Robustness Toolbox von IBM arbeiten können.
Widersprüchliches Training

Wenn Sie eine Person, die sich gerade mit dem Problem des Gegners vertraut gemacht hat, anhand von Beispielen die Frage stellen: „Wie können Sie sich vor diesem Effekt schützen?“, Sagen 9 von 10 Personen auf jeden Fall: „Fügen wir die generierten Objekte zum Trainingssatz hinzu.“ Dieser Ansatz wurde bereits 2013 in dem Artikel Faszinierende Eigenschaften neuronaler Netze vorgeschlagen. In diesem Artikel wurde dieses Problem zuerst beschrieben und der L-BFGS-Angriff, der das Empfangen von gegnerischen Beispielen ermöglicht.
Diese Methode ist sehr einfach. Wir generieren gegnerische Beispiele unter Verwendung verschiedener Arten von Angriffen und fügen sie bei jeder Iteration dem Trainingssatz hinzu, wodurch der „Widerstand“ des gegnerischen Modells gegenüber den Beispielen erhöht wird.
Der Nachteil dieser Methode liegt auf der Hand: Bei jeder Trainingsiteration können wir für jedes Beispiel eine sehr große Anzahl von Beispielen generieren, und die Zeit zum Modellieren des Trainings nimmt um ein Vielfaches zu.
Sie können diese Methode mithilfe der ART-IBM-Bibliothek wie folgt anwenden.
from art.defences.adversarial_trainer import AdversarialTrainer trainer = AdversarialTrainer(model, attacks) trainer.fit(x_train, y_train)
Gaußsche Datenerweiterung
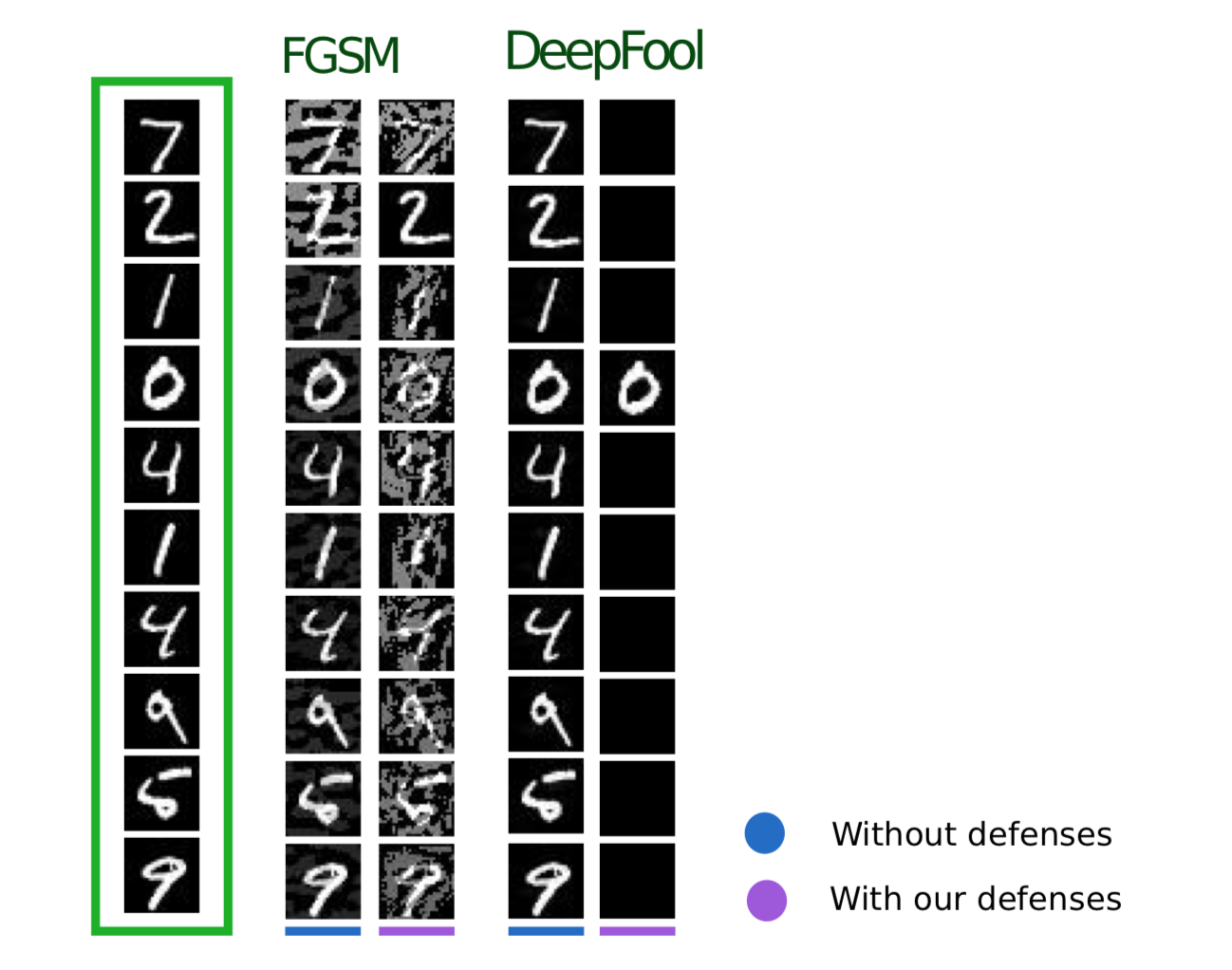
Die folgende Methode, die im Artikel Effiziente Verteidigung gegen gegnerische Angriffe beschrieben wird, verwendet eine ähnliche Logik: Sie schlägt auch vor, dem Trainingssatz zusätzliche Objekte hinzuzufügen. Im Gegensatz zum gegnerischen Training sind diese Objekte jedoch keine gegnerischen Beispiele, sondern leicht verrauschte Trainingssatzobjekte (Gauß wird als Rauschen verwendet Rauschen, daher der Name der Methode). Dies scheint in der Tat sehr logisch zu sein, da das Hauptproblem der Modelle genau ihre schlechte Störfestigkeit ist.
Diese Methode zeigt ähnliche Ergebnisse wie das gegnerische Training, während viel weniger Zeit für das Generieren von Objekten für das Training aufgewendet wird.
Sie können diese Methode mit der GaussianAugmentation-Klasse in ART-IBM anwenden
from art.defences.gaussian_augmentation import GaussianAugmentation GDA = GaussianAugmentation() new_x = GDA(x_train)
Etikettenglättung
Die Label Smoothing-Methode ist sehr einfach zu implementieren, hat jedoch eine große Wahrscheinlichkeitsbedeutung. Wir werden nicht näher auf die probabilistische Interpretation dieser Methode eingehen. Sie finden sie im Originalartikel Überdenken der Inception-Architektur für Computer Vision . Kurz gesagt, Label Smoothing ist eine zusätzliche Art der Regularisierung des Modells im Klassifizierungsproblem, wodurch es widerstandsfähiger gegen Rauschen wird.
Tatsächlich glättet diese Methode Klassenbeschriftungen. Machen Sie sie sagen, nicht 1, sondern 0,9. Trainingsmodelle werden daher für ein viel größeres "Vertrauen" in das Etikett für ein bestimmtes Objekt bestraft.
Die Anwendung dieser Methode in Python ist unten zu sehen.
from art.defences.label_smoothing import LabelSmoothing LS = LabelSmoothing() new_x, new_y = LS(train_x, train_y)
Begrenzte relu
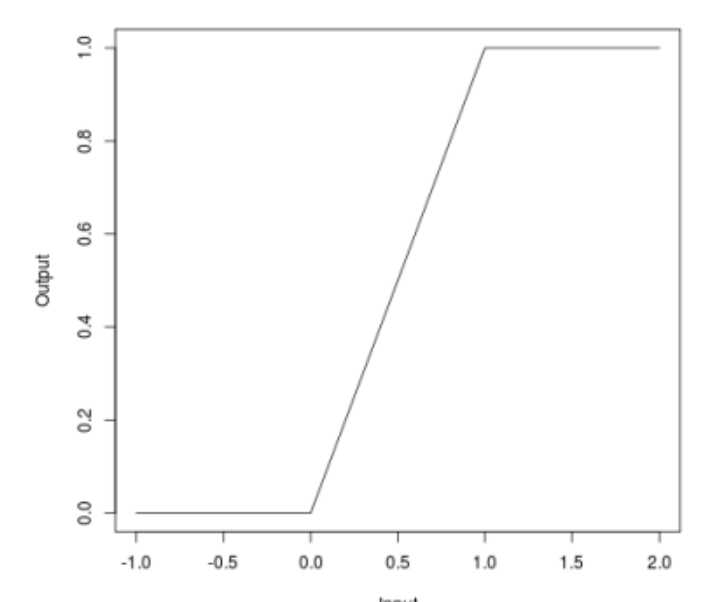
Wenn wir über Angriffe sprachen, konnten viele feststellen, dass einige Angriffe (JSMA, OnePixel) davon abhängen, wie stark der Gradient an der einen oder anderen Stelle im Eingabebild ist. Die einfache und "billige" Methode (in Bezug auf Rechenaufwand und Zeitaufwand) von Bounded ReLU versucht, dieses Problem zu lösen.
Das Wesentliche der Methode ist wie folgt. Ersetzen wir die Aktivierungsfunktion von ReLU in einem neuronalen Netzwerk durch dieselbe, die nicht nur von unten, sondern auch von oben begrenzt ist, wodurch Gradientenkarten geglättet werden. An bestimmten Stellen ist es nicht möglich, einen Splash zu erhalten, der es Ihnen nicht ermöglicht, den Algorithmus durch Ändern eines Pixels des Bildes zu täuschen.
\ begin {Gleichung *} f (x) =
\ begin {Fälle}
0, x <0
\\
x, 0 \ leq x \ leq t
\\
t, x> t
\ end {Fälle}
\ end {Gleichung *}
Diese Methode wurde auch im Artikel Effiziente Abwehr gegen gegnerische Angriffe beschrieben
Erstellen von Modellensembles
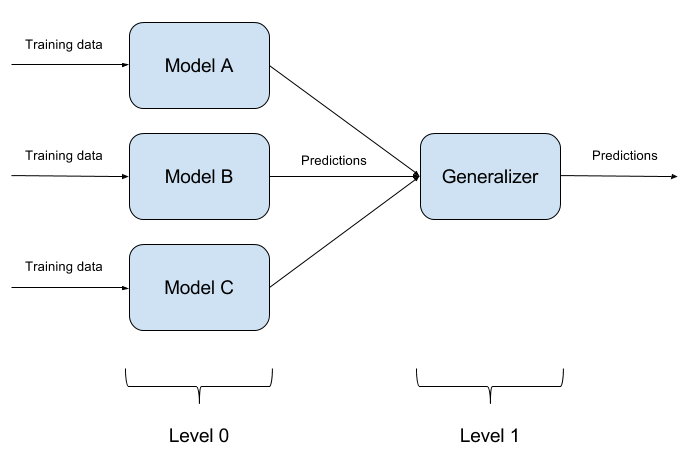
Es ist nicht schwer, ein trainiertes Modell zu täuschen. Noch schwieriger ist es, zwei Modelle gleichzeitig mit einem Objekt zu täuschen. Und wenn es N solche Modelle gibt? Darauf basiert die Ensemble-Methode der Modelle. Wir bauen einfach N verschiedene Modelle und fassen ihre Ausgabe zu einer einzigen Antwort zusammen. Wenn die Modelle auch durch unterschiedliche Algorithmen dargestellt werden, ist es äußerst schwierig, ein solches System zu täuschen, aber es ist äußerst schwierig!
Es ist ganz natürlich, dass die Implementierung von Modellensembles ein rein architektonischer Ansatz ist, der viele Fragen aufwirft (Welche Grundmodelle sind zu verwenden? Wie werden die Ergebnisse von Grundmodellen aggregiert? Gibt es eine Beziehung zwischen Modellen? Und so weiter). Aus diesem Grund ist dieser Ansatz in ART-IBM nicht implementiert
Feature quetschen
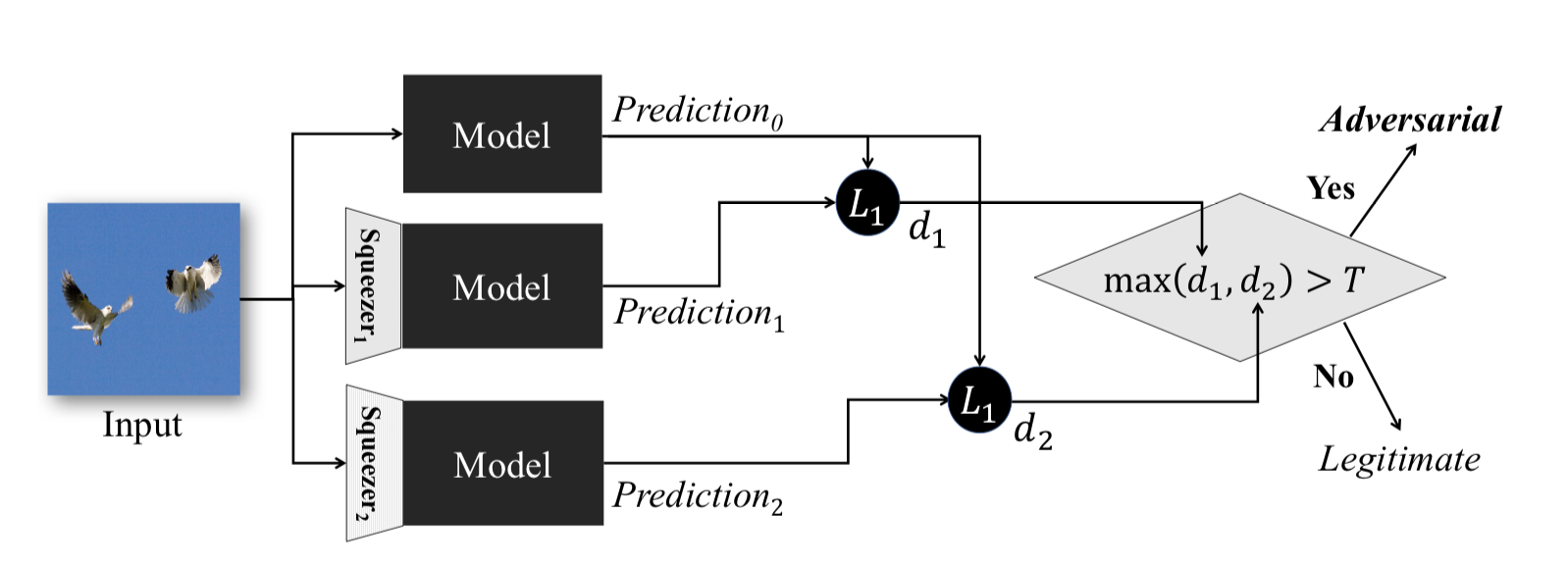
Diese Methode, die unter Feature Squeezing: Erkennen widersprüchlicher Beispiele in tiefen neuronalen Netzen beschrieben wird, funktioniert während der Betriebsphase des Modells. Sie können damit konträre Beispiele erkennen.
Die Idee hinter dieser Methode ist die folgende: Wenn Sie n Modelle mit denselben Daten, aber mit unterschiedlichen Komprimierungsverhältnissen trainieren, sind die Ergebnisse ihrer Arbeit immer noch ähnlich. Gleichzeitig wird das Adversarial-Beispiel, das im Quellnetzwerk funktioniert, höchstwahrscheinlich in zusätzlichen Netzwerken fehlschlagen. Nachdem wir den paarweisen Unterschied zwischen den Ausgängen des anfänglichen neuronalen Netzwerks und den zusätzlichen Ausgängen berücksichtigt, das Maximum daraus ausgewählt und mit einem vorgewählten Schwellenwert verglichen haben, können wir feststellen, dass das Eingabeobjekt entweder kontrovers oder absolut gültig ist.
Das Folgende ist eine Methode zum Abrufen komprimierter Objekte mit ART-IBM
from art.defences.feature_squeezing import FeatureSqueezing FS = FeatureSqueezing() new_x = FS(train_x)
Wir werden mit Schutzmethoden enden. Aber es wäre falsch, einen wichtigen Punkt nicht zu erfassen. Wenn ein Angreifer keinen Zugriff auf die Modelleingabe und -ausgabe hat, versteht er vor der Eingabe des Modells nicht, wie die Rohdaten in Ihrem System verarbeitet werden. Dann und nur dann werden alle seine Angriffe darauf reduziert, die Eingabewerte zufällig zu sortieren, was natürlich unwahrscheinlich ist, dass das gewünschte Ergebnis erzielt wird.
Testen
Lassen Sie uns nun über das Testen von Algorithmen sprechen, um den gegnerischen Beispielen entgegenzuwirken. Hier ist zunächst zu verstehen, wie wir unser Modell testen werden. Wenn wir davon ausgehen, dass ein Angreifer in irgendeiner Weise vollen Zugriff auf das gesamte Modell erhalten kann, muss unser Modell mithilfe von WhiteBox-Angriffsmethoden getestet werden.
In einem anderen Fall gehen wir davon aus, dass ein Angreifer niemals Zugriff auf die "Innenseiten" unseres Modells erhält. Er kann jedoch, wenn auch indirekt, die Eingabedaten beeinflussen und das Ergebnis des Modells sehen. Dann sollten Sie die Methoden von BlackBox-Angriffen anwenden.
Der allgemeine Testalgorithmus kann anhand des folgenden Beispiels beschrieben werden:
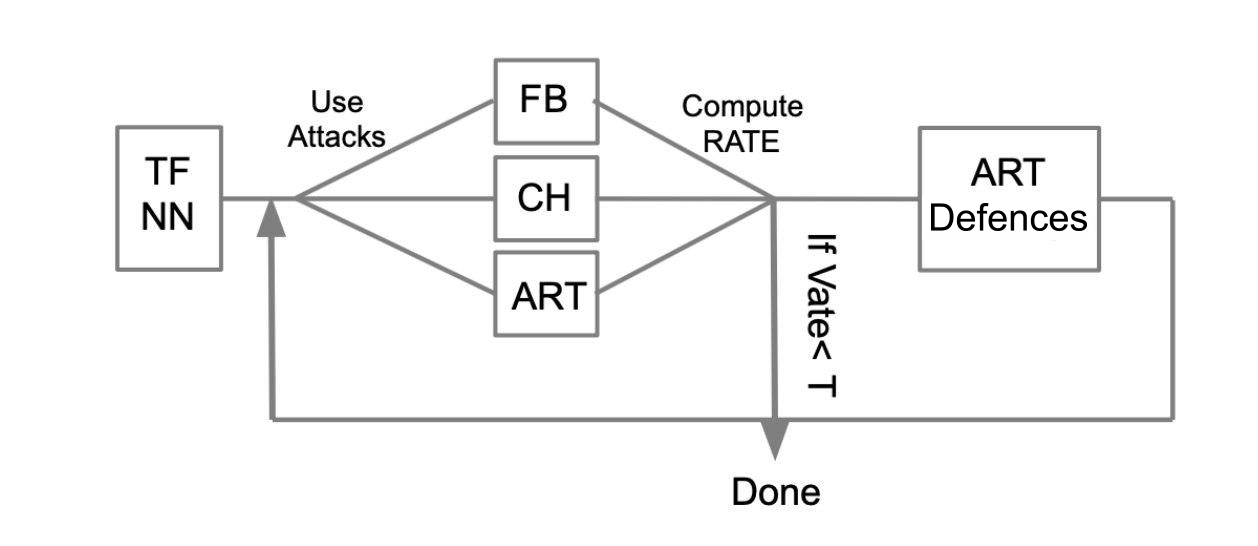
Es soll ein trainiertes neuronales Netzwerk in TensorFlow (TF NN) geschrieben sein. Wir behaupten fachmännisch, dass unser Netzwerk in die Hände eines Angreifers fallen kann, indem es in das System eindringt, in dem sich das Modell befindet. In diesem Fall müssen wir WhiteBox-Angriffe ausführen. Zu diesem Zweck definieren wir einen Angriffspool und Frameworks (FoolBox - FB, CleverHans - CH, Toolbox für konträre Robustheit - ART), mit denen diese Angriffe implementiert werden können. Wenn wir zählen, wie viele Angriffe erfolgreich waren, berechnen wir die Succes Rate (SR). Wenn SR zu uns passt, beenden wir den Test, andernfalls verwenden wir eine der Schutzmethoden, die beispielsweise in ART-IBM implementiert sind. Andererseits führen wir Angriffe durch und betrachten SR. Wir machen diesen Vorgang zyklisch, bis SR zu uns passt.
Schlussfolgerungen
Ich möchte hier mit allgemeinen Informationen zu Angriffen, Abwehrmaßnahmen und zum Testen von Modellen für maschinelles Lernen enden. Zusammenfassend können wir die beiden Artikel zusammenfassen:
- Glauben Sie nicht an maschinelles Lernen als eine Art Wunder, das all Ihre Probleme lösen kann.
- Denken Sie beim Anwenden von Algorithmen für maschinelles Lernen in Ihren Aufgaben daran, wie widerstandsfähig dieser Algorithmus gegen Bedrohungen wie Beispiele für Gegner ist.
- Sie können den Algorithmus sowohl von der Seite des maschinellen Lernens als auch von der Seite des Systems, in dem dieses Modell betrieben wird, schützen.
- Testen Sie Ihre Modelle, insbesondere in Fällen, in denen das Ergebnis des Modells die Entscheidung direkt beeinflusst
- Bibliotheken wie FoolBox, CleverHans und ART-IBM bieten eine praktische Schnittstelle zum Angreifen und Verteidigen von Modellen für maschinelles Lernen.
Auch in diesem Artikel möchte ich die Arbeit mit den Bibliotheken FoolBox, CleverHans und ART-IBM zusammenfassen:
FoolBox ist eine einfache und verständliche Bibliothek zum Angriff auf neuronale Netze, die viele verschiedene Frameworks unterstützt.
CleverHans ist eine Bibliothek, mit der Sie Angriffe ausführen können, indem Sie viele Parameter des Angriffs ändern. Diese ist etwas komplizierter als FoolBox und unterstützt weniger Frameworks.
ART-IBM ist die einzige Bibliothek der oben genannten Art, mit der Sie mit Sicherheitsmethoden arbeiten können. Bisher werden nur TensorFlow und Keras unterstützt, sie entwickeln sich jedoch schneller als andere.
An dieser Stelle gibt es eine weitere Bibliothek für die Arbeit mit gegnerischen Beispielen aus Baidu, die jedoch leider nur für Personen geeignet ist, die Chinesisch sprechen.
Im nächsten Artikel zu diesem Thema werden wir einen Teil der Aufgabe analysieren, die während des ZeroNights HackQuest 2018 gelöst werden soll, indem ein typisches neuronales Netzwerk mithilfe der FoolBox-Bibliothek getäuscht wird.